labelme标注的json文件数据转成coco数据集格式(可处理目标框和实例分割)
这里主要是搬运一下能找到的 labelme标注的json文件数据转成coco数据集格式(可处理目标框和实例分割)的代码,以供需要时参考和提供相关帮助。
1、官方labelme实现
如下是labelme官方网址,提供了源代码,以及相关使用方法,包括数据集格式转换,要仔细了解的可以细看。
网址:https://github.com/wkentaro/labelme

其中,官网也提供了打包成exe可执行文件的方法。 如果自己使用后有其他可改进的想法,可以尝试看源码修改增加相关功能, 然后打包成exe可执行文件,使用会更方便。

可以看到相关工作的介绍,里面提供了把实例分割标注文件转成COCO格式的功能。网址:https://github.com/wkentaro/labelme/tree/main/examples/instance_segmentation

进入网址如下:

labelme提供的 标注文件json 转成coco数据集格式的代码,可以包含水平框和实例分割的目标轮廓,代码如下:
#!/usr/bin/env pythonimport argparse
import collections
import datetime
import glob
import json
import os
import os.path as osp
import sys
import uuidimport imgviz
import numpy as npimport labelmetry:import pycocotools.mask
except ImportError:print("Please install pycocotools:\n\n pip install pycocotools\n")sys.exit(1)def main():parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)parser.add_argument("input_dir", help="input annotated directory")parser.add_argument("output_dir", help="output dataset directory")parser.add_argument("--labels", help="labels file", required=True)parser.add_argument("--noviz", help="no visualization", action="store_true")args = parser.parse_args()if osp.exists(args.output_dir):print("Output directory already exists:", args.output_dir)sys.exit(1)os.makedirs(args.output_dir)os.makedirs(osp.join(args.output_dir, "JPEGImages"))if not args.noviz:os.makedirs(osp.join(args.output_dir, "Visualization"))print("Creating dataset:", args.output_dir)now = datetime.datetime.now()data = dict(info=dict(description=None,url=None,version=None,year=now.year,contributor=None,date_created=now.strftime("%Y-%m-%d %H:%M:%S.%f"),),licenses=[dict(url=None, id=0, name=None,)],images=[# license, url, file_name, height, width, date_captured, id],type="instances",annotations=[# segmentation, area, iscrowd, image_id, bbox, category_id, id],categories=[# supercategory, id, name],)class_name_to_id = {}for i, line in enumerate(open(args.labels).readlines()):class_id = i - 1 # starts with -1class_name = line.strip()if class_id == -1:assert class_name == "__ignore__"continueclass_name_to_id[class_name] = class_iddata["categories"].append(dict(supercategory=None, id=class_id, name=class_name,))out_ann_file = osp.join(args.output_dir, "annotations.json")label_files = glob.glob(osp.join(args.input_dir, "*.json"))for image_id, filename in enumerate(label_files):print("Generating dataset from:", filename)label_file = labelme.LabelFile(filename=filename)base = osp.splitext(osp.basename(filename))[0]out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")img = labelme.utils.img_data_to_arr(label_file.imageData)imgviz.io.imsave(out_img_file, img)data["images"].append(dict(license=0,url=None,file_name=osp.relpath(out_img_file, osp.dirname(out_ann_file)),height=img.shape[0],width=img.shape[1],date_captured=None,id=image_id,))masks = {} # for areasegmentations = collections.defaultdict(list) # for segmentationfor shape in label_file.shapes:points = shape["points"]label = shape["label"]group_id = shape.get("group_id")shape_type = shape.get("shape_type", "polygon")mask = labelme.utils.shape_to_mask(img.shape[:2], points, shape_type)if group_id is None:group_id = uuid.uuid1()instance = (label, group_id)if instance in masks:masks[instance] = masks[instance] | maskelse:masks[instance] = maskif shape_type == "rectangle":(x1, y1), (x2, y2) = pointsx1, x2 = sorted([x1, x2])y1, y2 = sorted([y1, y2])points = [x1, y1, x2, y1, x2, y2, x1, y2]else:points = np.asarray(points).flatten().tolist()segmentations[instance].append(points)segmentations = dict(segmentations)for instance, mask in masks.items():cls_name, group_id = instanceif cls_name not in class_name_to_id:continuecls_id = class_name_to_id[cls_name]mask = np.asfortranarray(mask.astype(np.uint8))mask = pycocotools.mask.encode(mask)area = float(pycocotools.mask.area(mask))bbox = pycocotools.mask.toBbox(mask).flatten().tolist()data["annotations"].append(dict(id=len(data["annotations"]),image_id=image_id,category_id=cls_id,segmentation=segmentations[instance],area=area,bbox=bbox,iscrowd=0,))if not args.noviz:labels, captions, masks = zip(*[(class_name_to_id[cnm], cnm, msk)for (cnm, gid), msk in masks.items()if cnm in class_name_to_id])viz = imgviz.instances2rgb(image=img,labels=labels,masks=masks,captions=captions,font_size=15,line_width=2,)out_viz_file = osp.join(args.output_dir, "Visualization", base + ".jpg")imgviz.io.imsave(out_viz_file, viz)with open(out_ann_file, "w") as f:json.dump(data, f)if __name__ == "__main__":main()
代码执行需要导入相关库,缺少相关库自行下载安装。然后是看代码执行命令:
python ./labelme2coco.py --input_dir xxx --output_dir xxx --labels labels.txt
其中:
--input_dir 表示输入路径,包含标注的 json和图片
--output_dir 表示输出路径,用以保存图片和转化的coco文件
--labels 表示标签类别文件
生成文件夹内容:
It generates:- data_dataset_coco/JPEGImages- data_dataset_coco/annotations.json
2、其他代码实现
代码也很好理解,就是把相关功能集成到一起
import os
import argparse
import jsonfrom labelme import utils
import numpy as np
import glob
import PIL.Imageclass labelme2coco(object):def __init__(self, labelme_json=[], save_json_path="./coco.json"):""":param labelme_json: the list of all labelme json file paths:param save_json_path: the path to save new json"""self.labelme_json = labelme_jsonself.save_json_path = save_json_pathself.images = []self.categories = []self.annotations = []self.label = []self.annID = 1self.height = 0self.width = 0self.save_json()def data_transfer(self):for num, json_file in enumerate(self.labelme_json):with open(json_file, "r") as fp:data = json.load(fp)self.images.append(self.image(data, num))for shapes in data["shapes"]:label = shapes["label"].split("_")if label not in self.label:self.label.append(label)points = shapes["points"]self.annotations.append(self.annotation(points, label, num))self.annID += 1# Sort all text labels so they are in the same order across data splits.self.label.sort()for label in self.label:self.categories.append(self.category(label))for annotation in self.annotations:annotation["category_id"] = self.getcatid(annotation["category_id"])def image(self, data, num):image = {}img = utils.img_b64_to_arr(data["imageData"])height, width = img.shape[:2]img = Noneimage["height"] = heightimage["width"] = widthimage["id"] = numimage["file_name"] = data["imagePath"].split("/")[-1]self.height = heightself.width = widthreturn imagedef category(self, label):category = {}category["supercategory"] = label[0]category["id"] = len(self.categories)category["name"] = label[0]return categorydef annotation(self, points, label, num):annotation = {}contour = np.array(points)x = contour[:, 0]y = contour[:, 1]area = 0.5 * np.abs(np.dot(x, np.roll(y, 1)) - np.dot(y, np.roll(x, 1)))annotation["segmentation"] = [list(np.asarray(points).flatten())]annotation["iscrowd"] = 0annotation["area"] = areaannotation["image_id"] = numannotation["bbox"] = list(map(float, self.getbbox(points)))annotation["category_id"] = label[0] # self.getcatid(label)annotation["id"] = self.annIDreturn annotationdef getcatid(self, label):for category in self.categories:if label == category["name"]:return category["id"]print("label: {} not in categories: {}.".format(label, self.categories))exit()return -1def getbbox(self, points):polygons = pointsmask = self.polygons_to_mask([self.height, self.width], polygons)return self.mask2box(mask)def mask2box(self, mask):index = np.argwhere(mask == 1)rows = index[:, 0]clos = index[:, 1]left_top_r = np.min(rows) # yleft_top_c = np.min(clos) # xright_bottom_r = np.max(rows)right_bottom_c = np.max(clos)return [left_top_c,left_top_r,right_bottom_c - left_top_c,right_bottom_r - left_top_r,]def polygons_to_mask(self, img_shape, polygons):mask = np.zeros(img_shape, dtype=np.uint8)mask = PIL.Image.fromarray(mask)xy = list(map(tuple, polygons))PIL.ImageDraw.Draw(mask).polygon(xy=xy, outline=1, fill=1)mask = np.array(mask, dtype=bool)return maskdef data2coco(self):data_coco = {}data_coco["images"] = self.imagesdata_coco["categories"] = self.categoriesdata_coco["annotations"] = self.annotationsreturn data_cocodef save_json(self):print("save coco json")self.data_transfer()self.data_coco = self.data2coco()print(self.save_json_path)os.makedirs(os.path.dirname(os.path.abspath(self.save_json_path)), exist_ok=True)json.dump(self.data_coco, open(self.save_json_path, "w"), indent=4)if __name__ == "__main__":import argparseparser = argparse.ArgumentParser(description="labelme annotation to coco data json file.")parser.add_argument("labelme_images",help="Directory to labelme images and annotation json files.",type=str,)parser.add_argument("--output", help="Output json file path.", default="trainval.json")args = parser.parse_args()labelme_json = glob.glob(os.path.join(args.labelme_images, "*.json"))labelme2coco(labelme_json, args.output)
代码执行命令:
python labelme2coco.py labelme_images
其中,labelme_images 表示 放标注文件json和图片的文件夹路径,结果默认在当前路径下生成 trainval.json文件
相关文章:
labelme标注的json文件数据转成coco数据集格式(可处理目标框和实例分割)
这里主要是搬运一下能找到的 labelme标注的json文件数据转成coco数据集格式(可处理目标框和实例分割)的代码,以供需要时参考和提供相关帮助。 1、官方labelme实现 如下是labelme官方网址,提供了源代码,以及相关使用方…...

MySQL报错:1366 - Incorrect integer value: ‘xx‘ for column ‘xx‘ at row 1的解决方法
我在插入表数据时遇到了1366报错,报错内容:1366 - Incorrect integer value: Cindy for column name at row 1,下面我演示解决方法。 根据上图,原因是Cindy’对应的name字段数据类型不正确。我们在左侧找到该字段所在的grade_6表&…...
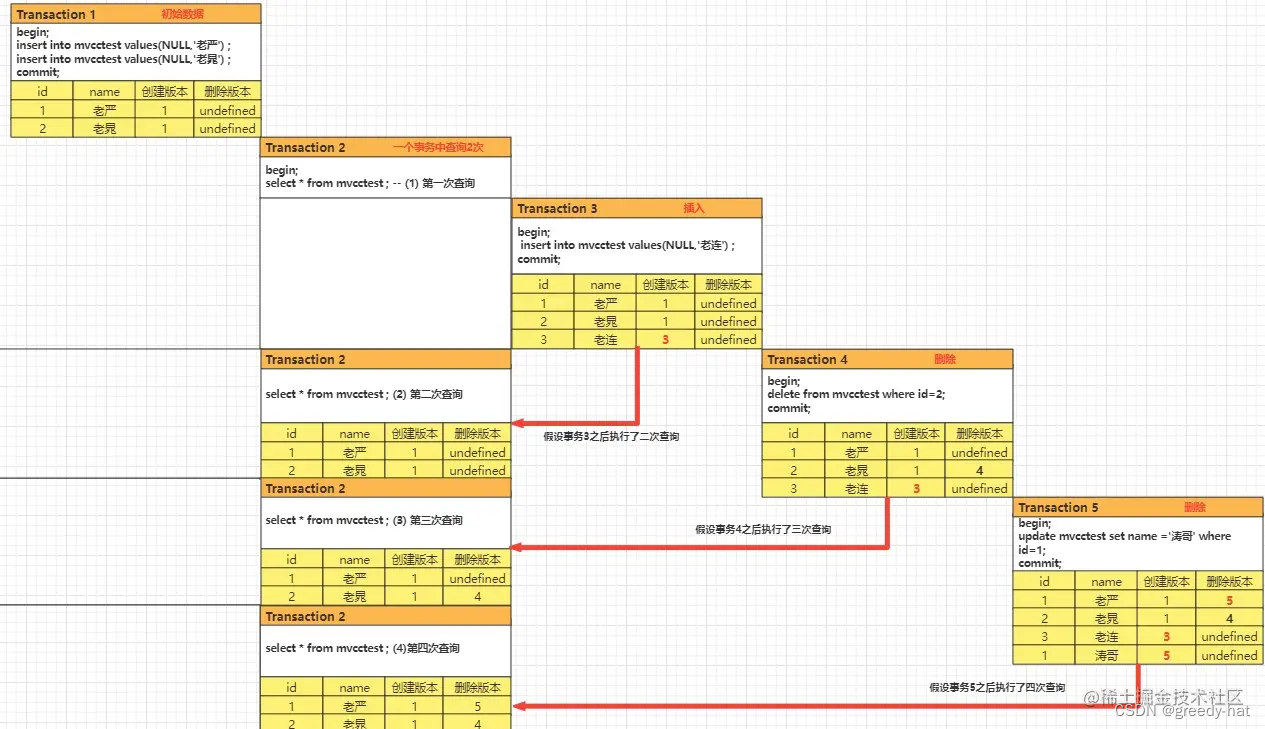
MySQL中MVCC的流程
参考文章一 参考文章二 当谈到数据库的并发控制时,多版本并发控制(MVCC)是一个重要的概念。MVCC 是一种用于实现数据库事务隔离性的技术,常见于像 PostgreSQL 和 Oracle 这样的数据库系统中。 MVCC 的核心思想是为每个数据行维护…...

朴素贝叶斯法_naive_Bayes
朴素贝叶斯法(naive Bayes)是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入输出的联合概率分布;然后基于此模型,对给定的输入 x x x,利用贝叶斯定理…...
Windows下安装MongoDB实践总结
本文记录Windows环境下的MongoDB安装与使用总结。 【1】官网下载 官网下载地址:Download MongoDB Community Server | MongoDB 这里可以选择下载zip或者msi,zip是解压后自己配置,msi是傻瓜式一键安装。这里我们分别对比进行实践。 【2】ZI…...
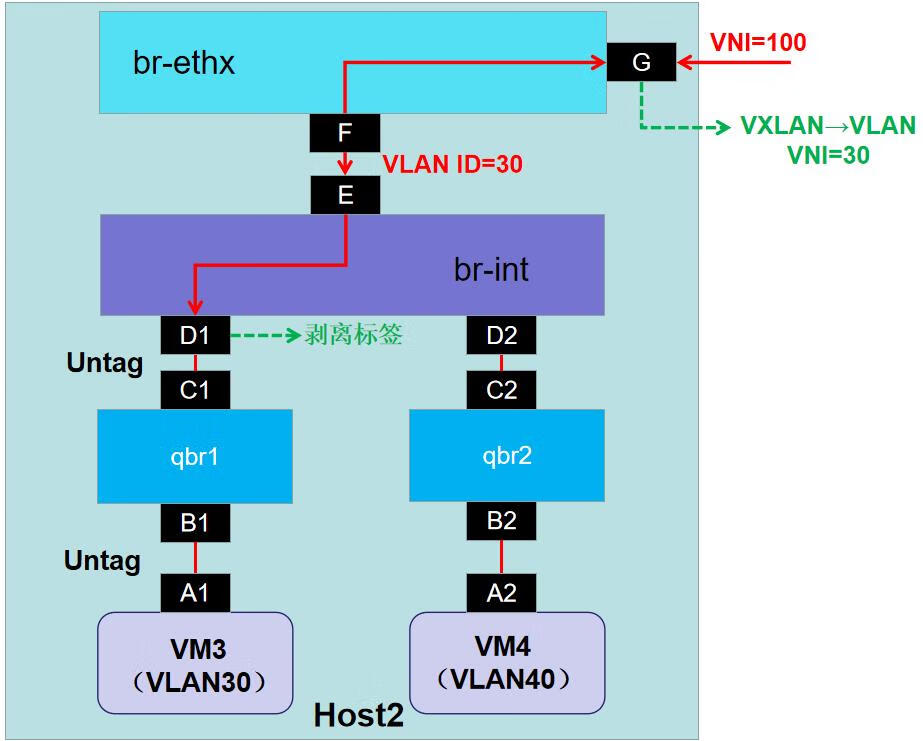
华为云Stack 8.X 流量模型分析(二)
二、流量模型分析相关知识 1.vNIC 虚拟网络接口卡(vNIC)是基于主机物理 NIC 的虚拟网络接口。每个主机可以有多个 NIC,每个 NIC 可以是多个 vNIC 的基础。 将 vNIC 附加到虚拟机时,Red Hat Virtualization Manager 会在虚拟机之间创建多个关联的…...
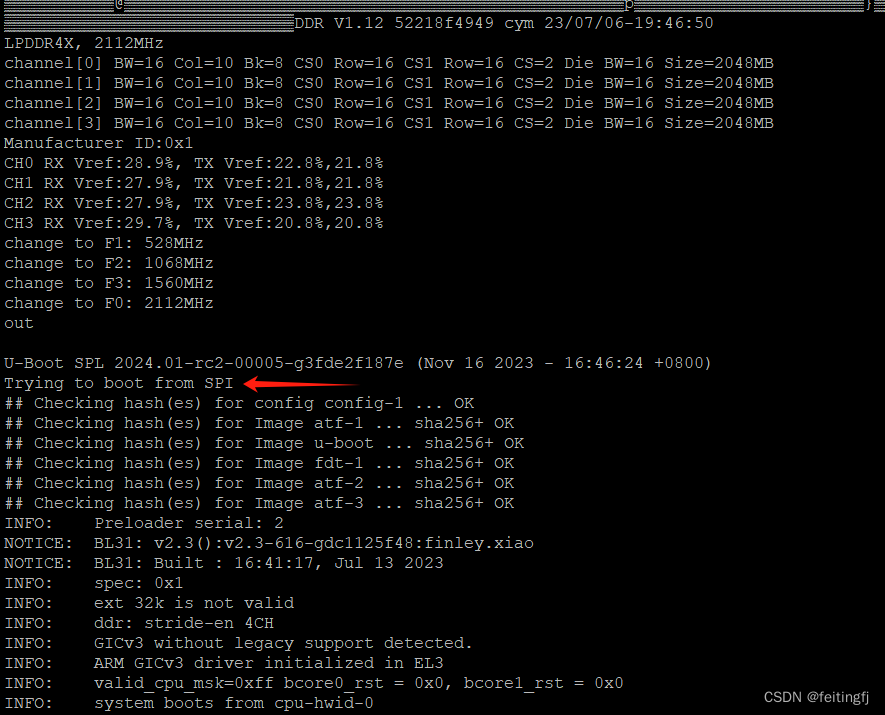
rk3588 之启动
目录 uboot版本配置修改编译 linux版本配置修改编译 启动sd卡启动制作spi 烧录 参考 uboot 版本 v2024.01-rc2 https://github.com/u-boot/u-boot https://github.com/rockchip-linux/rkbin 配置修改 使用这两个配置即可: orangepi-5-plus-rk3588_defconfig r…...
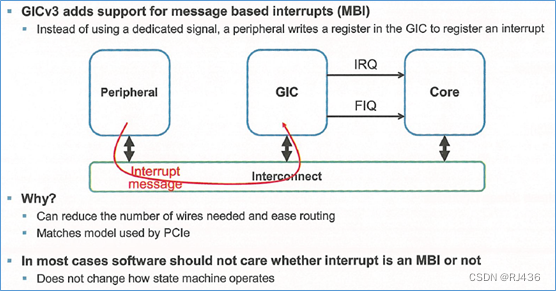
ARM GIC (五)gicv3架构-LPI
在gicv3中,引入了一种新的中断类型。message based interrupts,消息中断。 一、消息中断 外设,不在通过专用中断线,向gic发送中断,而是写gic的寄存器,来发送中断。 这样的一个好处是,可以减少中断线的个数。 为了支持消息中断,gicv3,增加了LPI,来支持消息中断。并且…...
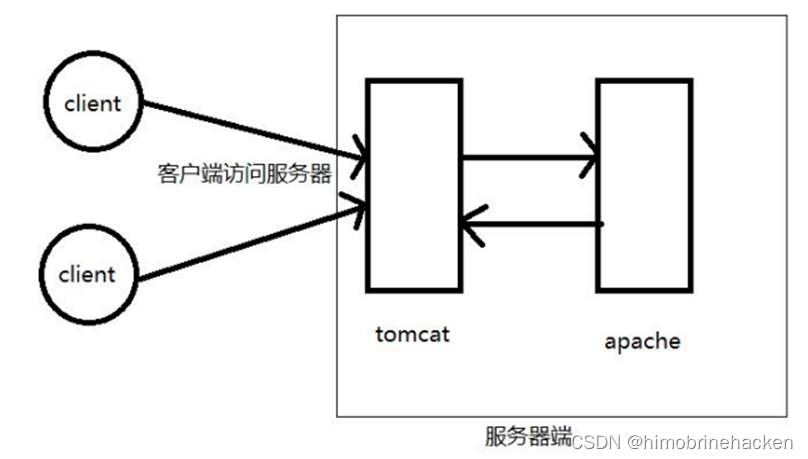
sql-labs服务器结构
双层服务器结构 一个是tomcat的jsp服务器,一个是apache的php服务器,提供服务的是php服务器,只是tomcat向php服务器请求数据,php服务器返回数据给tomcat。 此处的29-32关都是这个结构,不是用docker拉取的镜像要搭建一下…...
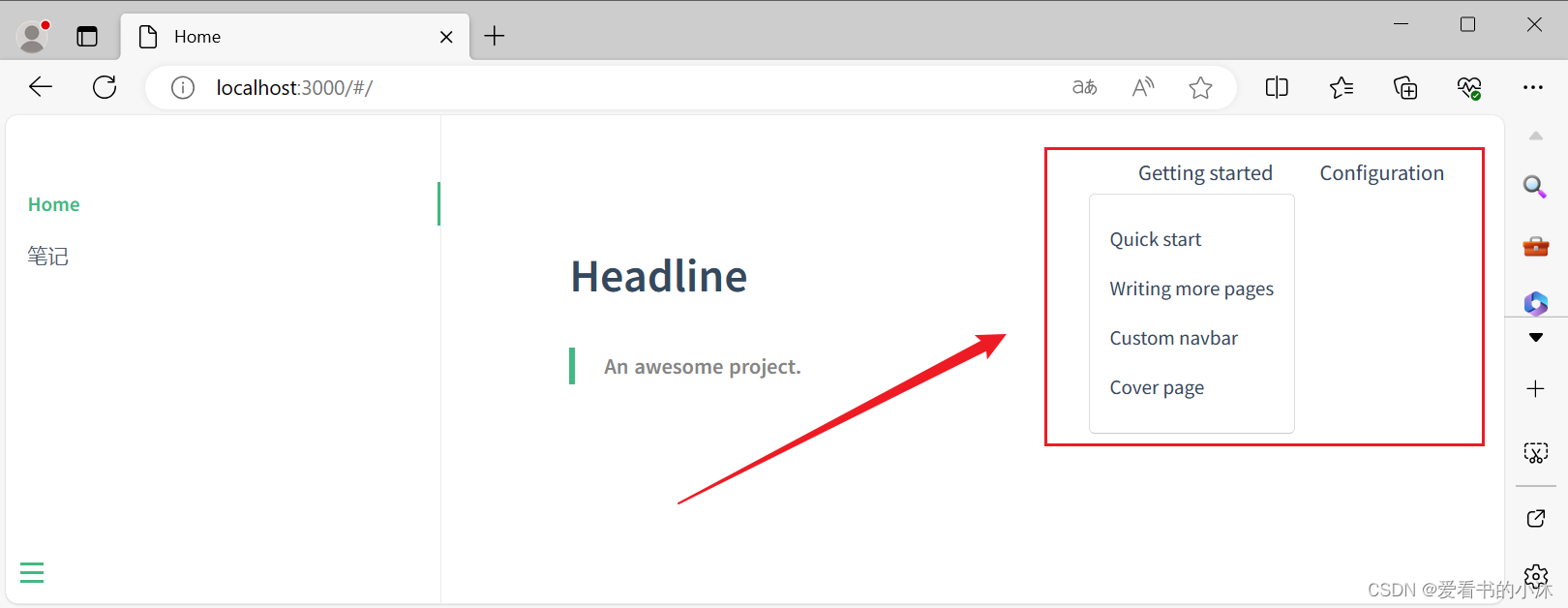
【小沐学写作】Docsify制作在线电子书、技术文档(Docsify + Markdown + node)
文章目录 1、简介2、安装2.1 node2.2 docsify-cli 3、配置3.1 初始化3.2 预览效果3.3 加载对话框3.4 更多页面3.5 侧 栏3.6 自定义导航栏 结语 1、简介 https://docsify.js.org/#/?iddocsify 一个神奇的文档网站生成器。 简单轻巧没有静态构建的 html 文件多个主题 Docsify…...
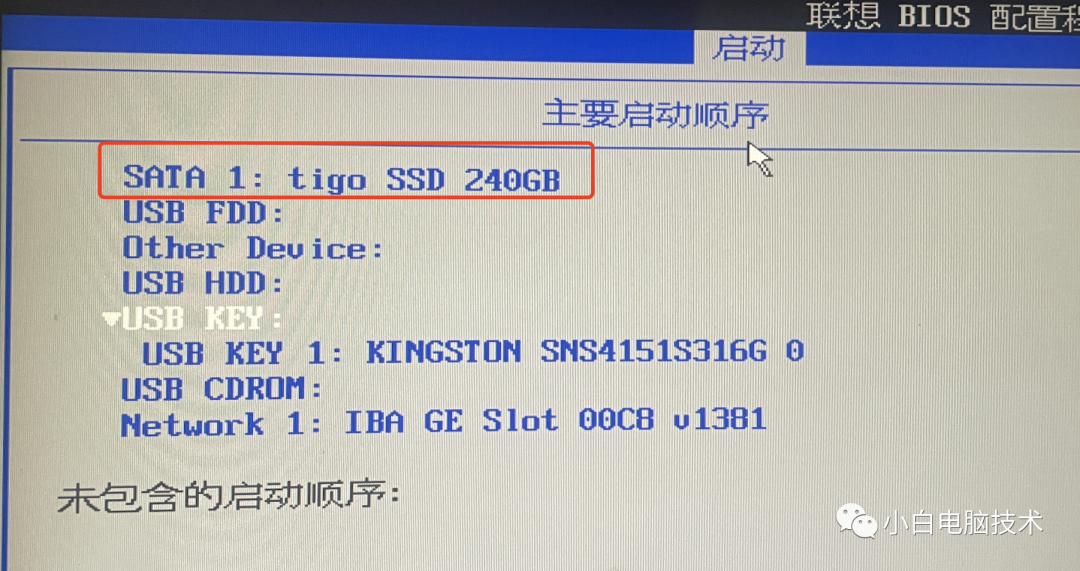
电脑完全重装教程——原版系统镜像安装
注意事项 本教程会清除所有个人文件 请谨慎操作 请谨慎操作 请谨慎操作 前言 本教程是以系统安装U盘为介质进行系统重装操作,照着流程操作会清除整个硬盘里的文件,请考虑清楚哦~ 有些小伙伴可能随便在百度上找个WinPE作为启动盘就直接…...
【智慧办公】如何让智能会议室的电子标签实现远程、批量更新信息?东胜物联网硬件网关让解决方案更具竞争力
近年来,为了减少办公耗能、节能环保、降本增效,越来越多的企业开始从传统的办公模式转向智慧办公。 以智能会议室为例,会议是企业业务中不可或缺的一部分,但在传统办公模式下,一来会议前行政人员需要提前准备会议材料…...
静态工厂方法模式)
面向对象设计与分析40讲(16)静态工厂方法模式
前面我们介绍了简单工厂模式,在创建对象前,我们需要先创建工厂,然后再通过工厂去创建产品。 如果将工厂的创建方法static化,那么无需创建工厂即可通过静态方法直接调用的方式创建产品: // 工厂类,定义了静…...

【贪心】买卖股票的最佳时机含手续费
/** 贪心:每次选取更低的价格买入,遇到高于买入的价格就出售(此时不一定是最大收益)。* 使用buy表示买入股票的价格和手续费的和。遍历数组,如果后面的股票价格加上手续费* 小于buy,说明有更低的买入价格更新buy。如…...

Altium Designer入门到就业【目录】
🏡《AD目录》 欢迎大家来到《Altium Designer入门到就业》该专栏包括【电路设计篇】【PCB设计篇】【电路仿真篇】【PCB仿真篇】四个部分,以供大家参考。大家直接点击大纲中蓝色标题即可轻松传送。 【电路设计篇】 Altium Designer(AD24&#…...

cmake 查看编译命令,以及在vscode中如何使用cmke
通过设置如下配置选项,可以生成compile_commands.json 文件,记录使用的编译命令 set(CMAKE_EXPORT_COMPILE_COMMANDS ON)获得现有模块列表 cmake --help-module-list查看命令文档 cmake --help-command find_file查看模块的详细信息 cmake --help-mo…...

玩转 Scrapy 框架 (一):Scrapy 框架介绍及使用入门
目录 一、Scrapy 框架介绍二、Scrapy 入门 一、Scrapy 框架介绍 简介: Scrapy 是一个基于 Python 开发的爬虫框架,可以说它是当前 Python 爬虫生态中最流行的爬虫框架,该框架提供了非常多爬虫的相关组件,架构清晰,可扩…...
node.js mongoose index(索引)
目录 简介 索引类型 单索引 复合索引 文本索引 简介 在 Mongoose 中,索引(Index)是一种用于提高查询性能的数据结构,它可以加速对数据库中文档的检索操作 索引类型 单索引、复合索引、文本索引、多键索引、哈希索引、地理…...

谷歌推大语言模型VideoPoet:文本图片皆可生成视频和音频
Google Research最近发布了一款名为VideoPoet的大型语言模型(LLM),旨在解决当前视频生成领域的挑战。该领域近年来涌现出许多视频生成模型,但在生成连贯的大运动时仍存在瓶颈。现有领先模型要么生成较小的运动,要么在生…...

ES-mapping
类似数据库中的表结构定义,主要作用如下 定义Index下的字段名( Field Name) 定义字段的类型,比如数值型、字符串型、布尔型等定义倒排索引相关的配置,比如是否索引、记录 position 等 index_options 用于控制倒排索记录的内容,有如…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

vue3 定时器-定义全局方法 vue+ts
1.创建ts文件 路径:src/utils/timer.ts 完整代码: import { onUnmounted } from vuetype TimerCallback (...args: any[]) > voidexport function useGlobalTimer() {const timers: Map<number, NodeJS.Timeout> new Map()// 创建定时器con…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...