hive sql常用函数
目录
一、数据类型
二、基础运算
三、字符串函数
1、字符串长度函数: length()
2、字符串反转函数:reverse
3、字符串连接函数
4、字符串截取函数
5、字符串分割函数:split
6、字符串查找函数
7、ascii
8、base64
9、character_length
10、chr
11、decode
12、encode
13、sentences
14、ngrams
15、context_ngrams
16、elt
17、field
18、soundex
19、find_in_set
20、format_number
21、in_file
22、locate
23、lpad
24、rpad
25、ltrim
26、trim
27、rtrim
28、octet_length
29、parse_url
30、printf
31、repeat
32、replace
33、reverse
34、space
35、split
36、str_to_map
37、sustring_index
38、translate
39、unbase64
40、initcap
41、levenshtein
四、数学函数
1、round()
2、floor()
3、ceil()
4、rand()
5、exp()
6、pow()
7、sqrt()
8、abs()
9、acos()
10、asin()
11、atan()
12、bin()
13、ceiling()
14、conv()
15、cbrt()
16、degrees()
17、radians()
18、factorial()
20、hex()
21、least()
22、ln()
23、bround()
24、log2()
25、log10()
26、log()
27、negative()
28、pi()
29、pmod()
30、positive()
31、rand()
32、round()
33、shiftleft()
34、shiftright()
35、shiftrightunsigned()
36、sign()
37、sin()
38、cos()
39、tan()
40、unhex()
41、width_bucket()
五、条件判断函数
1、if 函数
2、非空查找函数
3、条件判断函数
4、nvl(a,b)
5、nullif(a,b)
6、isnotnull
7、isnull
8、assert_true
六、正则表达式及解析函数
1、regexp_replace(str, regexp, rep)
2、regexp_extract(str, regexp[, idx])
3、parse_url。
4、get_json_object()。
5、rlike /regexp
6、like
七、日期函数
1.unix_timestamp()。
2、unix_timestamp(String date)
3、unix_timestamp(string date, string pattern)
4、from_unixtime
5、current_timestamp
6、to_date
7、日期转年/月/日/小时/分钟/秒/周函数
8、datediff
9、date_add
10、date_sub
11、extract
12、from_utc_timestamp
13、to_utc_timestamp
14、current_date
15、add_months
16、last_day
17、next_day
18、trunc
19、months_between
20、date_format
八、UDAF 函数(用户自定义聚合函数,user defined aggregation function.多对一的输入输出)
1、dense_rank()
2、rank()
3、row_number()
4、sum()
5、avg()
6、max()
7、min()
8、count()
9、ntile()
10、lag()
11、lead()
12、first_value()
13、last_value
14、variance
15、var_samp
16、stddev_pop
17、stddev_samp
18、covar_pop
19、covar_samp
20、corr
21、perccentile
22、percentile_approx
23、regr_avgx
24、regr_avgy
25、regr_count
26、regr_intercept
27、regr_r2
28、regr_slope
29、regr_sxy
30、regr_syy
31、regr_sxx
32、histogram_numeric
33、collect_set
34、collect_list
九、UDTF(User-Defined Table-Generating Functions)表生成函数
1、explode()
2、posexploed()
3、inline()
4、stack()
5、json_tuple()
6、parse_url()
十、集合类函数
1、grouping sets
2、grouping_id
3、cube
4、rollup
5、size
6、map_keys
7、map_values
8、array_contains
9、sort_array
十一、类型转换函数
1、cast()
2、binary()
一、数据类型
hive 的数据类型有原始数据类型和复杂类型,原始类型包括 TINYINT,SMALLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE,STRING,BINARY,TIMESTAMP,DECIMAL,CHAR,VARCHAR,DATE。复杂类型包括 ARRAY,MAP,STRUCT,UNION,这些复杂类型是由基础类型组成的。
二、基础运算
聚合函数 Hive 支持 count(),max(),min(),avg()等常用的聚合函数。 关系函数 =, !=, <>, < , >, <= , >, >= 空值判断:is null, is not null. 数学运算:支持所有的数值类型: + , - , * , /, % ,& , | , ^, ~等。 逻辑运算:逻辑与:and;逻辑或:or;逻辑非:not。
三、字符串函数
1、字符串长度函数: length()
length(string a): 返回字符串 a 的长度 。
2、字符串反转函数:reverse
reverse(string a) :返回字符串 a 的反转结果
3、字符串连接函数
(1)不带分隔符的字符串连接函数
concat() 语法:concat(string A, string B,........):返回输入字符串连接后的结果,支持任意个输入字符串 concat(string|binary A, string|binary B…) 将传入的字符串 A,B 合并为新的字符串,concat(‘foo’, ‘bar’)结果为’foobar’
(2)带分隔符字符串连接函数
concat_ws() concat_ws(String SEP, string a, string b):返回输入字符串连接后的结果,sep 表示各个字符串之间的分隔符。 concat_ws(string SEP, string A, string B…)或 concat_ws(string SEP, array) 与 concat 作用类似,但是支持自定义的分隔符 SEP
4、字符串截取函数
(1)substr(string a, int start, int len) 返回字符串 a 从 start 位置开始,长度为 len 的字符串。
(2)substring(string a, int start, int len) 返回字符串 a 从 start 位置开始,长度为 len 的字符串。
5、字符串分割函数:split
功能:split(string str, string pat)
用法:按照正则表达式 pat 拆分字符串 str。例如:split(‘a,b,c,d’,’,’)返回[“a”,“b”,“c”,“d”]
6、字符串查找函数
功能:instr(string str, string substr)
用法:返回 str 中第一个 substr 的位置。如果其中 str 为 null,则返回 null;如果在 str 中找不到 substr,则返回 0 。
7、ascii
用法:ascii(string str)。
功能:返回字符串的第一个字符的 ascii 数字。
8、base64
用法:base64(binary bin)。
功能:将二进制格式转成 base64 位的字符串,返回值是字符串。
9、character_length
用法:character_length(string str)。
功能:返回 str 中包含的 UTF-8 字符数,返回值为 int。
10、chr
用法:chr(bigint 或 double num)。
功能:返回指定数字对应的 ASCII 字符,如果指定的数字大于 256,将对该数字对 256 取模。
11、decode
用法:decode(binary bin, string charset)
功能:使用 charset 方式,将二进制 bin 解码为字符串。支持的字符集有:‘US-ASCII’, ‘ISO-8859-1’, ‘UTF-8’, ‘UTF-16BE’, ‘UTF-16LE’, ‘UTF-16’ 。
12、encode
用法:encode(str1,str2)
功能:将 str1 用 str2 设置的编码格式进行编码。
13、sentences
用法:sentences(string str, string lang, string locale)
功能:将 str 拆分成句子数组,其中每个句子都是一个单词数组。‘lang’和’locale’参数是可选的,如果省略,则使用默认语言环境。
14、ngrams
用法:ngrams(array> arr,int n,int k)。
功能:按 n 个单词出现频次,倒序取 top k。
15、context_ngrams
用法:context_ngrams(array, array, int K, int pf)
功能:从一组标记化的句子中返回前 k 个文本。例如 select context_ngrams(sentences(‘hello word!hello hive,hi hive,hello hive’),array(‘hello’,null),4) from A,会返回[{“ngram”:[“hive”],“estfrequency”:7141046.0},{“ngram”:[“word”],“estfrequency”:3570523.0}],即最经常在"hello"后出现的单词,并统计其频次,有统计聚合作用。
16、elt
用法:elt(N int,str1 string,str2 string,str3 string,…)
功能:返回给定字符串集中的第 N 个,若不存在则返回 null。例如 elt(2,‘hello’,‘world’) 返回’world’ 。
17、field
用法:field(val T,val1 T,val2 T,val3 T,…)
功能:返回 val 在 val1,val2…的位置。若不存在则返回 0。例如 field(‘world’,‘say’,‘hello’,‘world’),返回值为 3 。
18、soundex
用法:soundex(string A)
功能:返回字符串的 soundex 代码。例如:soundex(‘Miller’)返回 M460
19、find_in_set
用法:find_in_set(string str, string strList)
功能:返回 str 在 strList 中的位置。若不存在或 str 中存在",",则返回 0;若 str 为 null,则返回 null。
20、format_number
用法:format_number(number x, int d)
功能:将数字精确到 d 位小数,例如 format_number(5.123456, 4),返回值为 5.1234。
21、in_file
用法:in_file(string str, string filename)
功能:如果 str 以整行的方式出现在 filename 中,则返回 True。必须存在 filename 文件,否则会报错 。
22、locate
用法:locate(string substr, string str, int pos)
功能:返回 substr 在 str 的 pos 位置后,第一次出现的位置,pos 非必传。例如 locate(‘a’, ‘abcabc’),返回 1;locate(‘a’, ‘abcabc’,1),返回 1;locate(‘a’, ‘abcabc’,2),返回 4。
23、lpad
用法:lpad(string str, int len, string pad)
功能:将 str 截取长度 len 位,若 str 长度不足 len 则,左侧用 pad 补充。例如 lpad(‘abcdef’, 5, ‘a’)返回’abcde’;lpad(‘abc’, 5, ‘a’)返回’aaabc’。
24、rpad
用法:rpad(string str, int len, string pad)
功能:与 lpad 对应,将 str 截取长度 len 位,若 str 长度不足 len 则,右用 pad 补充。例如 rpad(‘abcdef’, 5, ‘a’)返回’abcde’;rpad(‘abc’, 5, ‘a’)返回’abcaa’。
25、ltrim
用法:ltrim(string A)
功能:删除字符串 A 左边的空格
26、trim
用法:trim(string A)
功能:返回出现在字符串 A 两端的空格。例如 trim(’ foo bar ‘),返回’foo bar’。
27、rtrim
用法:rtrim(string A)
功能:与 ltrim 对应,删除字符串 A 右边的空格。
28、octet_length
用法:octet_length(string str)
功能:返回以 UTF-8 编码保存字符串 str 所需的八位字节数。
29、parse_url
用法:parse_url(string urlString, string partToExtract [, string keyToExtract])
功能:解析 url,并返回需要抽取的部分,(可能抽取的部分 partToExtract 为 HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE)。 例如:parse_url(‘http://facebook.com/path1/p.php?k1=v1&k2=v2#Ref1’, ‘HOST’) 返回 ‘http://facebook.com’
30、printf
用法:printf(String format, Obj… args)
功能:按照指定的 format 进行输出。例如 printf(“Hello World %d %s”, 100, “days”),返回值为"Hello World 100 days”
31、repeat
用法:repeat(string str, int n)
功能:将字符串 str 重复 n 次。
32、replace
用法:replace(string A, string OLD, string NEW) 。
功能:将字符串 str 中的 OLD 子串替换为 NEW 。
33、reverse
用法:reverse(string A)
功能:对字符串 A 进行翻转
34、space
用法:space(int n)
功能:返回 n 个空格的字符串
35、split
用法:split(string str, string pat)
功能:按照正则表达式 pat 拆分字符串 str。例如:split(‘a,b,c,d’,’,’)返回[“a”,“b”,“c”,“d”]
36、str_to_map
用法:str_to_map(text, delimiter1, delimiter2)
功能:将 text 分割为数个键值对。其中 delimiter1 和 delimiter2 为可选参数。delimiter1(默认为’:’)代表键 k 与值 v 的分隔符。delimiter2(默认为’,’)代表键值对 k-v 之间的分隔符。例如 str_to_map({“column1:1,column2:2”)返回值为{“column1”:“1”,“column2”:“2”}
37、sustring_index
用法:substring_index(string A, string delim, int count)
功能:delim 为分隔符,返回 delim 将 A 分割后的前 count 部分。若 count 为负,则返回分割的最后一部分。例如:substring_index(‘http://www.apache.org’, ‘.’, 2) 返回 ‘www.apache’。
38、translate
用法:translate(string|char|varchar input, string|char|varchar from, string|char|varchar to)
功能:将 input 字符串中出现在 from 中的每个字符替换为 to 中的相应字符以后的字符串。 若 from 比 to 字符串长,那么在 from 中比 to 中多出的字符将会被删除。与 PostgreSQL 中对应函数等价。例如 translate(‘abcdefga’,‘abc’,‘wo’)返回’wodefgw’。
39、unbase64
用法:unbase64(string str)
功能:将 64 位的字符串转换二进制值
40、initcap
用法:initcap(string A)
功能:返回字符串,每个单词的第一个字母为大写,所有其他字母为小写。单词由空格分隔。
41、levenshtein
用法:levenshtein(string A, string B)
功能:返回两个字符串之间的 Levenshtein 距离。例如 levenshtein(‘kitten’, ‘sitting’)返回值为 3。 (Levenshtein 距离,又称编辑距离,指的是两个字符串之间,由一个转换成另一个所需的最少编辑操作次数。编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符)
四、数学函数
1、round()
用法:round(double a)。
功能:返回值 bigint,返回 double 类型的整数值部分(遵循四舍五入)。
用法:round(double a, int d)。 功能:返回值 double,返回指定指定精度 d 的 double 类型。
2、floor()
用法:floor(double a ),向下取整函数。
功能:返回等于或者小于该 double 变量的最小的整数。
3、ceil()
用法:ceil(double a),向上取整函数。
功能:返回等于或者大于该 double 变量的最小的整数。同 ceiling。
4、rand()
用法:取随机函数,rand(int seed)。
功能:返回一个 0 到 1 范围内的随机数。
5、exp()
用法:自然指数函数,exp(double a)。
功能:返回自然对数 e 的 a 次方。
6、pow()
用法:幂运算函数,pow(double a, double p)。同 power()。
功能:返回 a 的 p 次幂。
7、sqrt()
用法:开平方函数,sqrt(double a)。
功能:返回 a 的平方根。
8、abs()
用法:绝对值函数,abs(x)。
功能:返回 x 绝对值。
9、acos()
用法:反余弦值,acos(X),X 是数值型字符。
功能:如果-1<=X<=1,返回 X 的反余弦值。否则返回 NaN。
10、asin()
用法:反余弦值,asin(X),X 是数值型字符。
功能:如果-1<=X<=1,返回 X 的反正弦值。否则返回 NaN。
11、atan()
用法:反正切值,atan(X),X 是数值型字符。
功能:返回 X 的反正切值。
12、bin()
用法:bin(X),X 是整型。
功能:返回 X 的二进制表示。
13、ceiling()
用法:ceiling(X),X 是数值型字符。
功能:向上取整,返回大于或等于 X 最小整数。
14、conv()
用法:conv(X,from,to),X 是整型,from、to 也是整型。
功能:进制转换函数,将 X 从 from 进制转换成 to 进制。
15、cbrt()
用法:cbrt(DOUBLE a)。
功能:返回类型 DOUBLE,返回 a 的立方根。
16、degrees()
用法:degrees(double/decimal a)。
功能:将弧度 a 转化为角度。
17、radians()
用法:radians(double/decimal a)
功能:将角度 a 转化为弧度。
18、factorial()
用法:factorial(INT a)。
功能:返回类型是 BIGINT,返回 a 的阶乘(n!=1×2×3×...×(n-1)×n) 19、greatest() 语法:greatest(T v1, T v2, …)。 功能:返回 N 个数的最大值。
20、hex()
用法:hex(X),X 可以是整型,也可以是 string 型。
功能:返回 X 的十六进制表示。
21、least()
用法:least(T v1, T v2, …)。
功能:返回 N 个数的最小值。
22、ln()
用法: ln(double a)。
功能: double 说明: 返回 a 的自然对数。
23、bround()
用法:bround(double a)。
功能:银行家舍入法,四舍六入五成双。返回数字 a 高斯舍入后的值高斯舍入也称银行家舍入。简单的说就是四舍六入五考虑,五后非空就进一,五后为空看奇偶,五前为偶应舍去,五前为奇要进一。 银行家舍入法(1~4:舍,6~9:进,5->前位数是偶:舍,5->前位数是奇:进) bround(DOUBLE a)
24、log2()
用法:log2(X),X 是数值型字符。
功能:返回以 2 为底的 X 的对数。
25、log10()
用法:log10(X),X 是数值型字符。
功能:返回以 10 为底的 X 的对数。
26、log()
用法:log(X,Y),X、Y 是数值型字符。
功能:返回以 X 为底的 Y 的对数。
27、negative()
用法:negative(X),X 是数值型字符。
功能:返回 X 的相反数。
28、pi()
用法法: pi(),数学常数 π。
功能:返回值是 double 类型。
29、pmod()
用法:pmod(X,Y),X,Y 是数值型字符。
功能:返回 X 除以 Y 的余数。
30、positive()
用法:positive(X),X 是任意字符。
功能:返回 X 本身。
31、rand()
用法:rand(X),X 是整型。
功能:返回 0 到 1 之间的随机数。
32、round()
用法:round(X,Y),X 是数值型字符,Y 是整型。
功能:对 X 进行四舍五入,Y 是要保留的小数位数,Y 如果省略则表示对 X 进行四舍五入取整。
33、shiftleft()
用法:shiftleft(BIGINT a, INT b)。
功能:返回类型:INT or BIGINT,按位左移。
34、shiftright()
用法:shiftright(BIGINT a, INT b)。
功能:返回类型 INT or BIGINT,按位右移。
35、shiftrightunsigned()
用法:shiftrightunsigned(BIGINT a, INT b)。
功能:返回类型 DOUBLE,按位无符号右移。
36、sign()
用法:SIGN(number)。
功能:SIGN 函数用于返回数字的符号。当数字大于 0 时返回 1,等于 0 时返回 0,小于 0 时返回 -1。
37、sin()
用法:sin(X),X 是数值型字符。
功能:返回 X 的正弦值,X 是弧度制。
38、cos()
用法:cos(X),X 是数值型字符。
功能:返回 X 的余弦值,X 是弧度制。
39、tan()
用法:tan(X),X 是数值型字符。
功能:返回 X 的正切值,X 是弧度制。
40、unhex()
用法:unhex(X),X 是 string 型。
功能:X 代表十六进制的字串,返回此十六进制的二进制表示。
41、width_bucket()
用法:width_bucket(NUMERIC expr, NUMERIC min_value, NUMERIC max_value, INT num_buckets)。
功能:分桶值,按 min_value/max_value 创建 num_buckets+1 个相同大小的桶,返回当前值所在的桶编号。
五、条件判断函数
1、if 函数
if(boolean testCondition,T valueTrue, T valueFalseOrNull) 当条件 testCondition 为 True 时候,返回 valueTrue,否则返回 valueFalseOrNull
2、非空查找函数
coalesce coalesce(T v1, T v2,.....),返回参数中第一个非空值,如果所有值都为 null,那么返回 Null。
3、条件判断函数
case when case when 写法一: case sex when ‘1’ then ‘男’ when ‘2’ then ‘女’ else ‘其他’ end
case when 写法二: case when sex = ‘1’ then ‘男’ when sex = ‘2’ then ‘女’ else ‘其他’ end
4、nvl(a,b)
判空函数,若 a 为空,则返回 b,否则为 a
5、nullif(a,b)
若 a=b 时,返回 null,否则为 a
6、isnotnull
isnull 判断输入参数是否不为空,不为空返回 ture;反之,返回 false
7、isnull
isnull 判断输入参数是否为空,为空返回 ture;反之,返回 false
8、assert_true
assert_true(BOOLEAN condition) 如果 condition 不为 true,则抛出异常,否则返回 null。
六、正则表达式及解析函数
1、regexp_replace(str, regexp, rep)
将字符串 str 中符合正则表达式 regexp 的部分替换成字符串 rep.
样例:select regexp_replace(‘fooball’, ‘oo|al’ , ‘’) from table_Name; regexp_extract(string subject, string pattern, int index) 返回字符串 subject 与正则表达式 pattern 匹配后的 index 部分。
例如 regexp_extract(‘100-300’, ‘(d+)-(d+)’, 2) 的返回值为 300
2、regexp_extract(str, regexp[, idx])
将字符串 str 按照正则表达式 regexp 的规则拆分,返回 idx 指定位置的字符。
样例:select regexp_extract(‘foothebar’, ‘foo(.*?(bar)’, 1) from tableName; regexp_replace(string INITIAL_STRING, string PATTERN, string REPLACEMENT) 将字符串 subject 与正则表达式 pattern 匹配上部分用 REPLACEMENT 进行替换并返回。
例如 regexp_replace(‘100-200’, ‘(d+)’, ‘num’)返回值为‘num-num’
3、parse_url。
url 解析函数,返回 url 中指定的部分。
样例:parse_url(string urlString, string partToExtract [, string keyToExtract] )
4、get_json_object()。
json 解析,get_json_object(string json_string, string path) 样例:select get_json_object(‘{......}’, ‘$.owner’) from tableName;
5、rlike /regexp
(A)str rlike (B),能否用 B 去正则匹配 A 的内容。
6、like
(A)str like (B)pattern,能否用 B 去完全匹配 A 的内容。 7、regexp 功能语法同 rlike 一样,只是名字不同。
七、日期函数
1.unix_timestamp()。
用法:unix_timestamp();
返回值:bigint ,获得当前时区的 unix 时间戳
2、unix_timestamp(String date)
用法:unix_timestamp(String date)
功能:将格式为”yyyy-MM-dd HH:ss”的日期转换到 unix 时间戳,返回 bigint 如果转换失败,则返回 0.
3、unix_timestamp(string date, string pattern)
用法:unix_timestamp(string date, string pattern)
功能:转换 pattern 格式日期到 unix 时间戳。如果转化失败,则返回 0. 样例:select unix_timestamp(‘2021-03-08 14:21:11’,’yyyy-MM-dd HH:mm:ss’) from table
4、from_unixtime
用法:from_unixtime(bigint unixtime,string pattern)
功能:unix 时间戳转日期函数,返回值 string,把具体的秒转化为时间日期。
5、current_timestamp
用法:current_timestamp()
功能:获取当前的时间精确到毫秒,样例:select current_timestamp() -- 2011-09-02 10:11:09.234212000
6、to_date
用法:to_date(string timestamp)
功能:日期时间转日期函数,年月日时分秒只取其中的年月日部分。
7、日期转年/月/日/小时/分钟/秒/周函数
(1)日期转年函数 year()
用法:year(String date)
功能:返回值为 int,返回日期中的年。样例:select year(‘2021-03-21 10:11:02’) from table
(2)日期转月函数 month(STRING date)
用法:unix 时间戳转日期函数
功能:返回日期中的月
(3)日期转天函数 day(STRING date)
用法:返回日期中的天。
功能:返回类型 int。
(4)日期转小时函数:hour(STRING date)
用法:返回日期中小时函数。
功能:返回类型 int。
(5)日期转分钟函数 minute(STRING date)
用法:返回日期中的分钟。
功能:返回类型 int。
(6)日期转秒函数 second(STRING date)
用法:返回日期中的秒。
功能:返回类型 int。
(7)日期转周函数 weekofyear,weekofyear(string date)
用法:返回日期在当前的周数。
功能:返回值为 int。
8、datediff
用法:datediff(string enddate, string startdate)
功能:返回值 int,返回结束日期减去开始日期。
9、date_add
用法:date_add(string startdate, int days)
功能:返回值 string,日期增加函数,返回开始日期 startdate 增加 days 天的日期。
10、date_sub
用法:date_sub(string startdate, int days)
功能:返回值 string. 日期减少函数,返回开始日期 startdate 减少 days 天后的日期。
11、extract
用法:extract(date,integer)
功能:EXTRACT(year from '2015-01-15'),抽取日期类型中的年/月/日。
12、from_utc_timestamp
用法:from_utc_timestamp(timestamp, timezone)
功能:把 UTC 时间转换成 timezone 时间。
13、to_utc_timestamp
用法:to_utc_timestamp(timestamp, timezone)
功能:将 timestamp 转换成 UTC 时间。
14、current_date
用法:current_date()
功能:当前日期 。
15、add_months
用法:add_months(date,integer)
功能:返回 date 加上 integer 个月后的日期。
16、last_day
用法:last_day(date)。
功能:返回某个月的最后一天。
17、next_day
用法:next_day(start_date,day_of_week)。
功能:求当前日期的下一个周几。 next_day(current_date(),'mo')。
18、trunc
用法:trunc(date,fmt)
功能:date:日期时间类型 fmt:MONTH/MON/MM OR YEAR/YYYY/YY 截断指定格式,后补初始时间,如果为 YEAR 则返回 year(date)-01-01,如果为 MM 则返回 year(date)+month(date)-01
19、months_between
用法:months_between(‘date1’,‘date2’)。
功能:返回两个日期之间的月份差。
20、date_format
用法:date_format(date, format)
功能:date 参数是合法的日期,format 参数是规定日期输出的格式。
八、UDAF 函数(用户自定义聚合函数,user defined aggregation function.多对一的输入输出)
分析函数名(参数) OVER (PARTITION BY 子句 ORDER BY 子句 ROWS/RANGE 子句)。 即由以下三部分组成:
分析函数名: 如 sum、max、min、count、avg 等聚集函数以及 lead、lag 行比较函数等;
over: 关键字,表示前面的函数是分析函数,不是普通的集合函数;
分析子句: over 关键字后面挂号内的内容; 分析子句又由下面三部分组成: partition by :分组子句,表示分析函数的计算范围,不同的组互不相干; ORDER BY: 排序子句,表示分组后,组内的排序方式; ROWS/RANGE:窗口子句,是在分组(PARTITION BY)后,组内的子分组(也称窗口),此时分析函数的计算范围窗口,而不是 PARTITON。窗口有两种,ROWS 和 RANGE;
1、dense_rank()
用法:dense_rank()。
功能:有并列,相同名次不空位,总数会变。122345
2、rank()
用法:rank()
功能:有并列,相同名次空位,总数不会变。12245
3、row_number()
用法:row_number()
功能:没有并列,相同名次按顺序排(同分不同名)
4、sum()
用法:sum(column) 。
功能:用于计算指定列的总和。
5、avg()
用法:avg(column)
功能:用于计算指定列的平均值。
6、max()
用法:max(column)。
功能:用于计算指定列的最大值。
7、min()
用法:min(column) 。
功能:用于计算指定列的最大值。
8、count()
用法:count(column)
功能:用于计算指定列的最大值。
9、ntile()
用法:NTILE(n)。
功能:用于将分组数据按照顺序切分成 n 片,返回当前切片值,如果切片不均匀,默认增加第一个切片的分布
10、lag()
用法:lag(exp_str,offset,defval) over(partion by ..order by …)
功能:可以在 Hive 中轻松地查找前一行或前 N 行的数据,如果没有行,则返回 null。
11、lead()
用法:lead(exp_str,offset,defval) over(partion by ..order by …)
功能:可以在 Hive 中轻松地查找后一行或后 N 行的数据,如果没有行,则返回 null。
12、first_value()
用法:first_value() over(partion by ..order by …)
功能:取分组内排序后,截止到当前行,第一个值。
13、last_value
用法:last_value() over(partion by ..order by …)
功能:取分组内排序后,截止到当前行,最后一个值。
14、variance
用法:variance(col)
功能:返回组内查询列的方差(也可称为总体方差),也可写成 var_pop(col)。
15、var_samp
用法:var_samp(col)
功能:返回组内查询列方差的无偏估计(方差无偏估计中,因为估计期望损失了一个自由度,估计的分母为 n-1,也可称为样本方差)。
16、stddev_pop
用法:stddev_pop(col)
功能:返回组内查询列的标准差
17、stddev_samp
用法:stddev_samp(col)
功能:返回组内查询列标准差的无偏估计方差(无偏估计中,因为估计期望损失了一个自由度,估计的分母为 n-1)
18、covar_pop
用法:covar_pop(col1, col2)
功能:返回组内查询列 col1 和 col2 的总体协方差。
19、covar_samp
用法:covar_samp(col1, col2)
功能:返回组内查询列 col1 和 col2 的样本协方差
20、corr
用法:corr(col1, col2)
功能:返回组内查询列 col1 和 col2 的相关系数 。
21、perccentile
用法:percentile(BIGINT col, p)
功能:返回组内查询整数列 col 所在的分位数,p 可以为浮点数或数组,且其中元素大小必须在 0-1 之间。若 col 不是整数,需使用 percentile_approx 。
22、percentile_approx
用法:percentile_approx(DOUBLE col, array(p1[, p2]…) [, B])
功能:返回组内查询列 col 所在的分位数,p 可以为浮点数或数组,且其中元素大小必须在 0-1 之间。B 为可选参数,为精度控制参数
23、regr_avgx
用法:regr_avgx(independent, dependent)
功能:计算自变量的平均值。该函数将任意一对数字类型作为参数,并返回一个 double。任何具有 null 的对都将被忽略。如果应用于空集:返回 null。否则,它计算以下内容:avg(dependent)
24、regr_avgy
用法:regr_avgy(independent, dependent) 。
功能:计算因变量的平均值。该函数将任意一对数字类型作为参数,并返回一个 double。任何具有 null 的对都将被忽略。如果应用于空集:返回 null。否则,它计算以下内容:avg(independent)。
25、regr_count
用法:regr_count(independent, dependent)
功能:返回 independent 和 dependent 都非空的对数 。
26、regr_intercept
用法:regr_intercept(independent, dependent)
功能:返回线性回归的截距项 。
27、regr_r2
用法:regr_r2(independent, dependent)
功能:返回线性回归的判决系数(R 方,coefficient of determination)
28、regr_slope
用法:regr_slope(independent, dependent)
功能:返回线性回归的斜率系数 。
29、regr_sxy
用法:regr_sxy( [ALL | DISTINCT] yExpr, xExpr) [FILTER ( WHERE cond ) ]
参数说明:yExpr:一个数值表达式,因变量。
xExpr:一个数值表达式,自变量。
cond:一个可选的布尔表达式,可筛选用于函数的行。
功能:返回根据 xExpr 和 yExpr 不为 NULL 的组的值计算出的 yExpr 和 xExpr 乘积的和。
30、regr_syy
用法:regr_syy( [ALL | DISTINCT] yExpr, xExpr) [FILTER ( WHERE cond ) ]
参数说明:yExpr:一个数值表达式,因变量。
xExpr:一个数值表达式,自变量。
cond:一个可选的布尔表达式,可筛选用于函数的行。
功能:返回 xExpr 和 yExpr 不为 NULL 的组中 yExpr 值的平方和。
31、regr_sxx
用法:regr_sxx( [ALL | DISTINCT] yExpr, xExpr) [FILTER ( WHERE cond ) ]
参数说明:yExpr:一个数值表达式,因变量。
xExpr:一个数值表达式,自变量。
cond:一个可选的布尔表达式,可筛选用于函数的行。
功能:返回 xExpr 和 yExpr 不为 NULL 的组中 xExpr 值的平方和。
32、histogram_numeric
用法:histogram_numeric(col, b)
功能:用于画直方图。返回一个长度为 b 的数组,数组中元素为(x,y)形式的键值对,x 代表了直方图中该柱形的中心,y 代表可其高度。
33、collect_set
用法:collect_set(col)
功能:返回查询列 col 去重后的集合,与 distinct 不同,distinct 查询结果为一列数据,collect_set 查询后结果为一个集合形式的元素
34、collect_list
用法:collect_list(col)
功能:返回查询列 col 的列表
九、UDTF(User-Defined Table-Generating Functions)表生成函数
1、explode()
用法:explode(col)。
功能:explode()函数可以将数组(array 类型)的元素分隔成多行,或将映射(map 类型)的元素分隔为多行和多列。
2、posexploed()
用法:posexplode(col)。
功能:posexplode 只能用于 array。
3、inline()
用法:inline(ARRAY)
功能:inline 一般结合 lateral view 使用
4、stack()
用法:stack(int r,T1 V1,...,Tn/r Vn)
功能:即分解 n 个值 V1…Vn 转化成 r 行。每一行将有 n/r 列(向上取整)。
5、json_tuple()
用法:json_tuple(string jsonStr, string key1, string key2, …)
功能:返回 key1,key2 键对应的值。
6、parse_url()
用法:parse_url(URL,parts[HOST/PATH/QUERY])
功能:parse_url 函数是 Hive 中提供的最基本的 url 解析函数,可以根据指定的参数,从 url 解析出对应的参数值进行返回,函数为普通的一对一函数类型。
十、集合类函数
1、grouping sets
用法:group by k1,k2,k3 grouping sets((组合 1),(组合 2),(组合 3)) 对于 grouping sets 后的组合,应该是 group by 后的子集,没有使用到的 group by 字段,会自动使用 null 值填充 功能:根据不同的维度组合进行聚合,等价于将不同维度的 GROUP BY 结果集进行 UNION ALL 对于多个维度聚合问题,grouping sets 不用像 cube 方式将分组字段排列组合列出全部维度的结果,能够实现更灵活的组合。
2、grouping_id
用法:grouping sets 中的每一种粒度,都对应唯一的 groupingid 值,其计算公式与 group by 的顺序、当前粒度的字段有关。
功能:它是根据 group by 后面声明的顺序字段是否存在于当前 group by 中的一个二进制位组合数据,若组合中出现即为 1,反正则为 0,group by 后字段先出现的放在最低位,依次排开:比如 group by class,sex,course,则二进制的顺序为:course sex class ,grouping sets 字段出现则为 1,反之则为 0, 比如(class, course), 二进制为 101,十进制则为 5,则 groupingid 为 5,同理 grouping__id 为 6,则组合为(sex,course),二进制为 110。
3、cube
用法:为指定表达式集的每个可能组合创建分组集。首先会对(A、B、C)进行 group by,然后依次是(A、B),(A、C),(A),(B、C),(B),(C),最后对全表进行 group by 操作。
功能:cube 简称数据魔方,可以实现 hive 多个任意维度的查询,cube(a,b,c)则首先会对(a,b,c)进行 group by,然后依次是(a,b),(a,c),(a),(b,c),(b),(c),最后在对全表进行 group by,cube 会统计所选列中值的所有组合的聚合。
4、rollup
用法:rollup 的含义是卷曲的意思,顾名思义,就是会从右向左的组合字段,得到聚合结果。 group by A,B,C with rollup 首先会对(A、B、C)进行 group by,然后对(A、B)进行 group by,然后是(A)进行 group by,最后对全表进行 group by 操作。可以看出 group by A,B,C with rollup;是上述几种 group by 的并集。 功能: rollup 可以实现从右到做递减多级的统计,显示统计某一层次结构的聚合。
5、size
用法:size(Map/ARRAY)
功能:返回数组类型中的元素数。
6、map_keys
用法:map_values(Map)
功能:返回一个无序数组,该数组包含输入映射的键。
7、map_values
用法:返回一个无序数组,该数组包含输入映射的值。
功能:map_values(Map)。
8、array_contains
用法:array_contains(Array, value)。
功能:如果数组包含值,则返回 TRUE。
9、sort_array
用法:sort_array(array, [asc|desc])
功能:它可以根据指定的排序规则对数组进行排序,并返回一个排好序的新数组。
十一、类型转换函数
1、cast()
用法:cast (字段名 as 转换的类型)
功能:基础类型之间强制转换。
2、binary()
用法:binary(string|binary)。
功能:binary,将 string 类型转换为二进制。
相关文章:

hive sql常用函数
目录 一、数据类型 二、基础运算 三、字符串函数 1、字符串长度函数: length() 2、字符串反转函数:reverse 3、字符串连接函数 4、字符串截取函数 5、字符串分割函数:split 6、字符串查找函数 7、ascii 8、base64 9、character_length 10、c…...

Spark系列之:使用spark合并hive数据库多个分区的数据到一个分区中
Spark系列之:使用spark合并hive数据库多个分区的数据到一个分区中 把两个分区的数据合并到同一个分区下把其中一个分区的数据通过append方式添加到另一个分区即可 %spark val df spark.sql("select * from optics_prod.product_1h_a where datetime202311142…...

《重构-改善既有代
重要列表 1、如果你发现自己需要为程序添加一个特性,而代码结构使你无法很方便地达成目的,那就先重构哪个程序,使特性的添加比较容易的进行,然后再添加特性 2、重构前,先检查自己是否有一套可靠的测试机制࿰…...
vue3(七)-基础入门之事件总线与动态组件
一、事件总线 事件总线使用场景: 两个兄弟组件之间的传参,或者两个没有关联的组件之间的传参 html :引入 publicmsg 与 acceptmsg 自定义组件 (自定义组件名称必须小写) <body><div id"app"><publicmsg></…...

【计算机网络】网络层——IP协议
目录 一. 基本概念 二. 协议报文格式 三. 网段划分 1. 第一次划分 2. CIDR方案 3. 特殊的IP地址 四. IP地址不足 1. 私有IP和公网IP 2. DHCP协议 3. 路由器 4. NAT技术 内网穿透(NAT穿透) 五. 路由转发 路由表生成算法 结束语 一. 基本概念 IP指网络互连协议…...

《钢结构设计标准》中抗震性能化设计的概念
文章目录 0. 背景1. 前言2. 什么是抗震性能化设计3. 我国规范是如何实现性能化设计的4. 从能量角度理解性能化设计05. 《钢结构设计标准》抗震性能化设计的思路06. 《钢结构设计标准》抗震性能化设计的步骤 0. 背景 关于抗震性能化设计,之前一直理解的很模糊&#…...

【算法】【动规】回文串系列问题
文章目录 跳转汇总链接3.1 回文子串3.2 最长回文子串3.3 分割回文串 IV3.4 分割回文串II(hard) 跳转汇总链接 👉🔗动态规划算法汇总链接 3.1 回文子串 🔗题目链接 给定一个字符串 s ,请计算这个字符串中有多少个回文子字符串。 …...

4-Docker命令之docker logs
1.docker logs介绍 docker logs命令是用来获取docker容器的日志 2.docker logs用法 docker logs [参数] CONTAINER [root@centos79 ~]# docker logs --helpUsage: docker logs [OPTIONS] CONTAINERFetch the logs of a containerAliases:docker container logs, docker lo…...

svelte基础语法学习
官网文档地址:绑定 / Each 块绑定 • Svelte 教程 | Svelte 中文网 1、样式 一般情况下父子组件内样式隔离、同级组件间样式隔离 2、页面布局 <style>P{color: red;} </stye><script> // 类似data let name ‘jiang’ let countVal 0 let s…...

Node.js教程-mysql模块
概述 在Node.js中,mysql模块是实现MySQL协议的JavaScript客户端工具。Node.js程序通过与MySQL建立链接,然后可对数据进行增、删、改、查等操作。 安装 由于mysql模块不是Node.js内置模块,需手动安装 npm i mysql注意:若MySQL服…...
网络通信协议
WebSocket通信 WebSocket是一种基于TCP的网络通信协议,提供了浏览器和服务器之间的全双工通信(full-duplex)能力。在WebSocket API中,浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接ÿ…...
Spark集群部署与架构
在大数据时代,处理海量数据需要分布式计算框架。Apache Spark作为一种强大的大数据处理工具,可以在集群中高效运行,处理数十TB甚至PB级别的数据。本文将介绍如何构建和管理Spark集群,以满足大规模数据处理的需求。 Spark集群架构…...
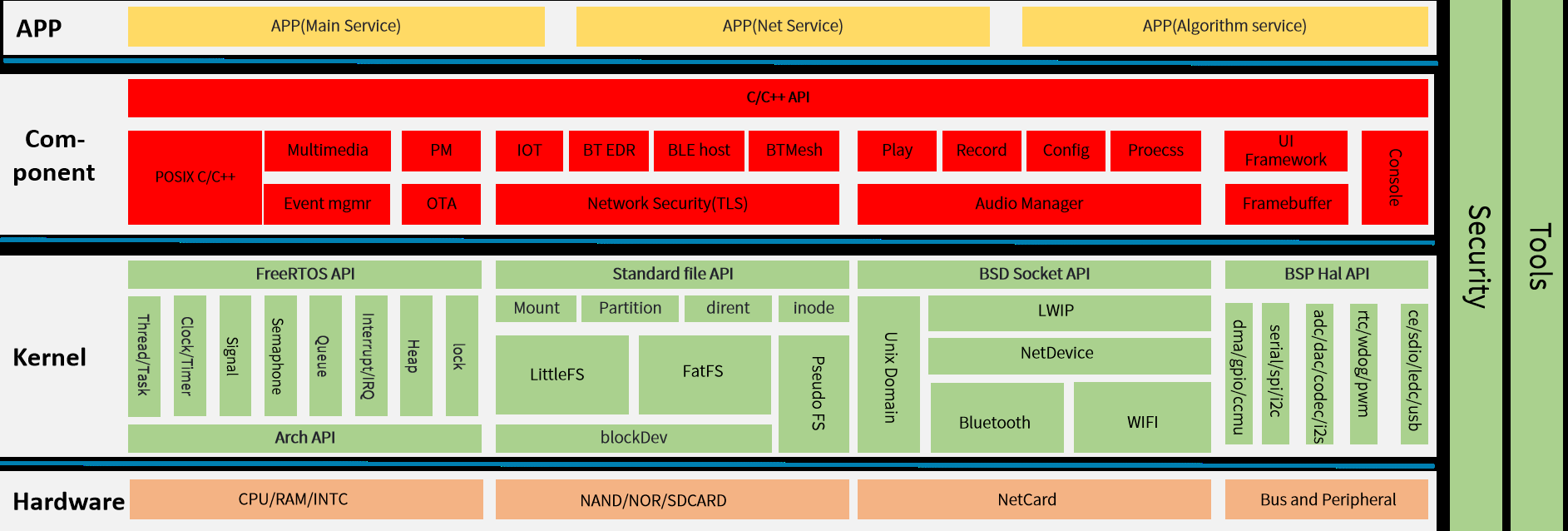
DshanMCU-R128s2 SDK 架构与目录结构
R128 S2 是全志提供的一款 M33(ARM)C906(RISCV-64)HIFI5(Xtensa) 三核异构 SoC,同时芯片内部 SIP 有 1M SRAM、8M LSPSRAM、8M HSPSRAM 以及 16M NORFLASH。 本文档作为 R128 FreeRTOS SDK 开发指南,旨在帮助软件开发工程师、技术支持工程师快速上手&am…...

【5G PHY】NR参考信号功率和小区总传输功率的计算
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持! 博主链接 本人就职于国际知名终端厂商,负责modem芯片研发。 在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。 博客…...

k8s学习 — 各知识点快捷入口
k8s学习 — 各知识点快捷入口 k8s学习 — 第一章 核心概念 k8s学习 — 第一章 核心概念 命名空间 实践: k8s学习 — (实践)第二章 搭建k8s集群k8s学习 — (实践)第三章 深入Podk8s学习 — (实践࿰…...

【Python】Python 批量转换PDF到Excel
PDF是面向展示和打印使用的,并未考虑编辑使用,所以缺少了很多编辑属性且非常难修改PDF里面的数据。当您需要分析或修改PDF文档数据时,可以将PDF保存为Excel工作簿,实现轻松编辑数据的需求。PDF转Excel,技术关键就是提取…...

Python并行计算和分布式任务全面指南
更多Python学习内容:ipengtao.com 大家好,我是彭涛,今天为大家分享 Python并行计算和分布式任务全面指南。全文2900字,阅读大约8分钟 并发编程是现代软件开发中不可或缺的一部分,它允许程序同时执行多个任务࿰…...

微信小程序promise封装
一. 在utils文件夹内创建一个request.js 写以下封装的 wx.request() 方法 const baseURL https:// 域名 ; //公用总路径地址 export const request (params) > { //暴露出去一个函数,并且接收一个外部传入的参数let dataObj params.data || {}; //…...

hash长度扩展攻击
作为一个信息安全的人,打各个学校的CTF比赛是比较重要的! 最近一个朋友发了道题目过来,发现有道题目比较有意思,这里跟大家分享下 这串代码的大致意思是: 这段代码首先引入了一个名为"flag.php"的文件&am…...
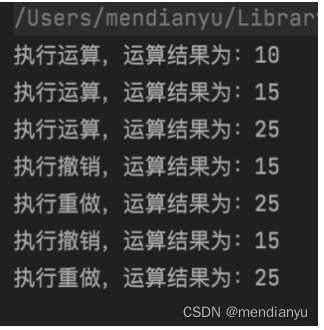
设计模式--命令模式
实验16:命令模式 本次实验属于模仿型实验,通过本次实验学生将掌握以下内容: 1、理解命令模式的动机,掌握该模式的结构; 2、能够利用命令模式解决实际问题。 [实验任务]:多次撤销和重复的命令模式 某系…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

libfmt: 现代C++的格式化工具库介绍与酷炫功能
libfmt: 现代C的格式化工具库介绍与酷炫功能 libfmt 是一个开源的C格式化库,提供了高效、安全的文本格式化功能,是C20中引入的std::format的基础实现。它比传统的printf和iostream更安全、更灵活、性能更好。 基本介绍 主要特点 类型安全:…...
)
华为OD最新机试真题-数组组成的最小数字-OD统一考试(B卷)
题目描述 给定一个整型数组,请从该数组中选择3个元素 组成最小数字并输出 (如果数组长度小于3,则选择数组中所有元素来组成最小数字)。 输入描述 行用半角逗号分割的字符串记录的整型数组,0<数组长度<= 100,0<整数的取值范围<= 10000。 输出描述 由3个元素组成…...

加密通信 + 行为分析:运营商行业安全防御体系重构
在数字经济蓬勃发展的时代,运营商作为信息通信网络的核心枢纽,承载着海量用户数据与关键业务传输,其安全防御体系的可靠性直接关乎国家安全、社会稳定与企业发展。随着网络攻击手段的不断升级,传统安全防护体系逐渐暴露出局限性&a…...
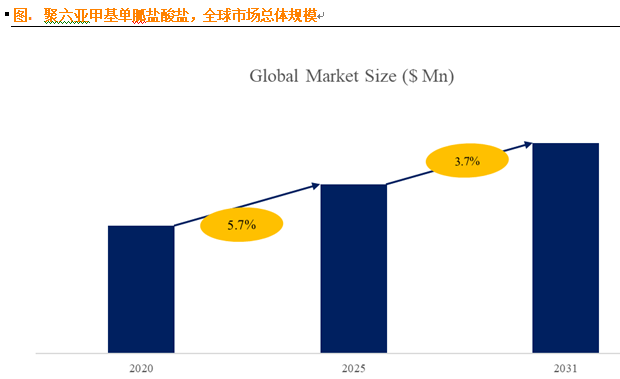
聚六亚甲基单胍盐酸盐市场深度解析:现状、挑战与机遇
根据 QYResearch 发布的市场报告显示,全球市场规模预计在 2031 年达到 9848 万美元,2025 - 2031 年期间年复合增长率(CAGR)为 3.7%。在竞争格局上,市场集中度较高,2024 年全球前十强厂商占据约 74.0% 的市场…...

「Java基本语法」变量的使用
变量定义 变量是程序中存储数据的容器,用于保存可变的数据值。在Java中,变量必须先声明后使用,声明时需指定变量的数据类型和变量名。 语法 数据类型 变量名 [ 初始值]; 示例:声明与初始化 public class VariableDemo {publi…...