【spring】Spring Data --Spring Data JPA
Spring Data 的委托是为数据访问提供熟悉且符合 Spring 的编程模型,同时仍保留着相关数据存储的特殊特征。
它使使用数据访问技术、关系和非关系数据库、map-reduce 框架和基于云的数据服务变得容易。这是一个伞形项目,其中包含许多特定于给定数据库的子项目。这些项目是通过与这些令人兴奋的技术背后的许多公司和开发商合作开发的。
Spring Data特征
- 强大的存储库自状语从句:定义对象映射抽象艺术
- 从存储库方法名称派生的动态查询
- 提供基本属性的实现域基类
- 支持透明审计(创建、最后更改)
- 可以集成自定义存储库代码
- 通过 JavaConfig 和自定义 XML 特有的一个简单集成 Spring
- 与 Spring MVC 控制器的高级集成
- 跨店持久化实验支持
Spring Data主要模块
- Spring Data Commons - 支撑每个Spring Data模块的核心Spring概念。
- Spring Data JDBC - 对 JDBC 的 Spring Data 存储库支持。
- Spring Data JDBC Ext - 支持标准 JDBC 的数据库特定扩展,包括支持 Oracle RAC 快速连接故障转移、AQ JMS 支持和使用高级数据类型的支持。
- Spring Data JPA - 对 JPA 的 Spring Data 存储库支持。
- Spring Data KeyValue -Map基于存储库和SPI,可构建用于键值存储的Spring Data模块。
- Spring Data LDAP - Spring Data 存储的支持Spring Data LDAP。
- Spring Data MongoDB - 基于 Spring 的对象文档支持和 MongoDB 存储库。
- Spring Data Redis - 从 Spring 应用程序轻松配置和访问 Redis。
- Spring Data REST - 将 Spring Data 存储库导出为超媒体驱动的 RESTful 资源。
- Spring Data for Apache Cassandra - 轻松配置和访问Apache Cassandra或规模、高可用性、程序数据的Spring。
- Spring Data for Apache Geode - 轻松配置和访问Apache Geode,以实现高度一致性、低延迟、深度数据的Spring应用程序。
- Spring Data for Pivotal GemFire - 为您的高度一致性、低延迟/高吞吐量、数据的 Spring 应用程序简单配置和访问 Pivotal GemFire。
Spring Data社区模块
-
Spring Data Aerospike - Aerospike 的 Spring Data 模块。
-
Spring Data ArangoDB - ArangoDB 的 Spring Data 模块。
-
Spring Data Couchbase - Couchbase 的 Spring Data 模块。
-
Spring Data Azure Cosmos DB - Microsoft Azure Cosmos DB 的 Spring Data 模块。
-
Spring Data Cloud Datastore - Google Datastore 的 Spring Data 模块。
-
Spring Data Cloud Spanner - Google Spanner 的 Spring Data 模块。
-
Spring Data DynamoDB - DynamoDB 的 Spring Data 模块。
-
Spring Data Elasticsearch - 用于 Elasticsearch 的 Spring Data 模块。
-
Spring Data Hazelcast - 为 Hazelcast 提供 Spring Data 存储库支持。
-
Spring Data Jest - 基于 Jest REST 客户端的 Elasticsearch 的 Spring Data 模块。
-
Spring Data Neo4j - Neo4j 的基于 Spring 的对象图支持和存储库。
-
适用于 Spring Data 的 Oracle NoSQL 数据库 SDK - 适用于 Oracle NoSQL 数据库和 Oracle NoSQL 云服务的 Spring Data 模块。
-
Spring Data for Apache Solr - 为深入搜索的 Spring 应用程序轻松配置和访问 Apache Solr。
-
Spring Data Vault - 在 Spring Data KeyValue 以外的 Vault 存储库中建立。
Spring Data相关模块
-
Spring Data JDBC Extensions - 为Spring Framework中提供的JDBC支持提供扩展。
-
Spring for Apache Hadoop——通过提供统一的配置模型和使用的API来简化Apache Hadoop,以使用HDFS、MapReduce、Pig和Hive。
-
Spring 内容 - 将内容与您的 Spring 数据实体相关联,将其存储在许多不同的存储中,包括文件系统、S3、数据库或 Mongo 的 GridFS。
Spring Data 发布模块
Spring Data R2DBC - R2DBC的Spring Data支持。
Spring Data JPA
ORM
在解释什么是JPA和Spring Data JPA之前我们应该先来了解一下什么是ORM。ORM(Object-Relational Mapping, 对象关系映射),是一种面向对象编程语言中的对象和数据库中的数据之间的映射。使用ORM工具、框架可以让应用程序操作数据库。
在过去,有很多针对Java的ORM框架,但是每一套框架都有自己的一套操作方法和规范,这就使得Java程序操作不同数据库时显得杂乱无章。于是乎,Sun公司推出了一套操作持久层(数据库)的规范(API)用于结束这种乱象,这套规范也就是JPA。
JPA
JPA(Java Persistence API,Java持久层API) 是Sun公司定义的一套基于ORM的接口规范,用于给Java程序操作数据库。JPA 通过 JDK 5.0 注解描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中 。在这之后很多ORM框架实现了JPA规范,其中最有名的有Hibernate、TopLink、JDO等。JPA 和 Hibernate 的关系就像 JDBC 和 JDBC 驱动的关系,JPA 是规范,Hibernate 除了作为 ORM 框架之外,它也是一种 JPA 实现。
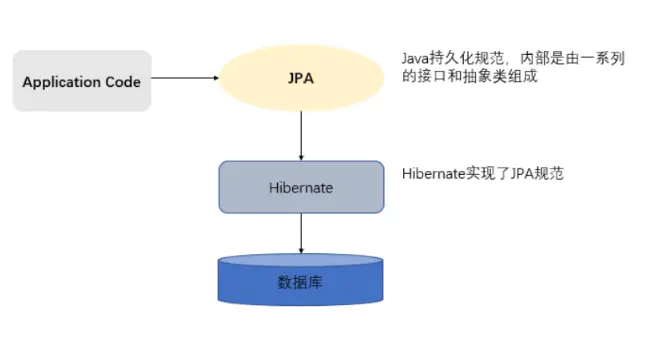
JPA的优势
标准化
JPA 是 JCP 组织发布的 Java EE 标准之一,因此任何声称符合 JPA 标准的框架都遵循同
样的架构,提供相同的访问API,这保证了基于JPA开发的企业应用能够经过少量的修改就能够在 不同的 JPA 框架下运行。
容器级特性的支持
JPA 框架中支持大数据集、事务、并发等容器级事务,这使得 JPA 超越了简单持久化框架的 局限,在企业应用发挥更大的作用。
简单方便
JPA 的主要目标之一就是提供更加简单的编程模型:在 JPA 框架下创建实体和创建 Java 类一样简单,没有任何的约束和限制,只需要使用 javax.persistence.Entity 进行注释,JPA的 框架和接口也都非常简单,没有太多特别的规则和设计模式的要求,开发者可以很容易的掌握。 JPA 基于非侵入式原则设计,因此可以很容易的和其它框架或者容器集成
查询能力
JPA 的查询语言是面向对象而非面向数据库的,它以面向对象的自然语法构造查询语句,可以看成是 Hibernate HQL 的等价物。JPA 定义了独特的 JPQL(Java Persistence Query Language),JPQL 是 EJB QL 的一种扩展,它是针对实体的一种查询语言,操作对象是实体,而 不是关系数据库的表,而且能够支持批量更新和修改、JOIN、GROUP BY、HAVING 等通常只有 SQL 才能够提供的高级查询特性,甚至还能够支持子查询
高级特性
JPA 中能够支持面向对象的高级特性,如类之间的继承、多态和类之间的复杂关系。这样的支持能够让开发者最大限度的使用面向对象的模型设计企业应用,而不需要自行处理这些特性。
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套 JPA 应用框架,可使开发者用极简的代码即可实现对数据库的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA 可以极大提高开发效率!
Spring Data JPA 让我们解脱了 DAO 层的操作,基本上所有 CRUD 都可以依赖于它来实现,在实际的工作工程中,推荐使用 Spring Data JPA + ORM(如:hibernate)完成操作,这样在切换不同的 ORM 框架时提供了极大的方便,同时也使数据库层操作更加简单,方便。
Spring Data JPA
Spring Data JPA 是 Spring 基于 ORM 框架、JPA 规范的基础上封装的一套 JPA 应用框架,可使开发者用极简的代码即可实现对数据库的访问和操作。它提供了包括增删改查等在内的常用功能,且易于扩展!学习并使用 Spring Data JPA 可以极大提高开发效率!
Spring Data JPA 让我们解脱了 DAO 层的操作,基本上所有 CRUD 都可以依赖于它来实现,在实际的 工作工程中,推荐使用 Spring Data JPA + ORM(如:hibernate)完成操作,这样在切换不同的 ORM 框架时提供了极大的方便,同时也使数据库层操作更加简单,方便解耦。
III. 第一个Spring Data JPA项目
步骤如下
- 在pom.xml中导入依赖
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope>
</dependency>
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope>
</dependency>
- 配置application.yml
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://localhost:3306/jpa_study?useUnicode=true&characterEncoding=utf8username: rootpassword: 123456data:rest:basePath: /apijpa:hibernate:ddl-auto: updateshow-sql: trueserver:port: 8080
- 编写实体类
package com.soul.jpastudy.domain;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;import javax.persistence.*;@Data
@NoArgsConstructor
@AllArgsConstructor/*** 客户的实体类* 配置映射关系* 1. 实体类和表的映射关系* 2. 实体类中属性和表中字段的映射关系* @Entity:声明实体类* @Table: 配置实体类和表的映射关系* name: 配置数据库表的名称*/@Entity
@Table(name = "cst_customer")
public class Customer {@Id // 声明主键的配置@GeneratedValue(strategy = GenerationType.IDENTITY) // 自增@Column(name = "cust_id") // 映射数据库表中的字段private Long custId;@Column(name = "cust_name")private String custName;@Column(name = "cust_source")private String custSource;@Column(name = "cust_level")private String custLevel;@Column(name = "cust_industry")private String custIndustry;@Column(name = "cust_phone")private String custPhone;@Column(name = "cust_address")private String custAddress;}
- 编写Repository
package com.soul.jpastudy.repository;import com.soul.jpastudy.domain.Customer;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Modifying;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import org.springframework.data.rest.core.annotation.RepositoryRestResource;
import org.springframework.transaction.annotation.Transactional;import java.util.List;@RepositoryRestResource(collectionResourceRel = "customers", path = "customers")
public interface CustomerRepository extends JpaRepository<Customer, Long>{Customer findByCustName(String custName);@Query("select c from Customer c")List<Customer> findAll();@Transactional@Modifying@Query("update Customer c set c.custName = ?1 where c.custId = ?2")int updateCustomer(@Param("custName") String custName, @Param("custId") Long custId);@Transactional@Modifying@Query("delete from Customer c where c.custId = :custId and c.custIndustry = :custIndustry")int deleteCustomer(@Param("custId") Long custId, @Param("custIndustry") String custIndustry);}
- 单元测试
@SpringBootTest
class JpaStudyApplicationTests {@Autowiredprivate CustomerRepository customerRepository;@Testvoid testFindByCustName(){Customer customer = customerRepository.findByCustName("testName");System.out.println(customer);}@Testvoid testFindAll() {List<Customer> all = customerRepository.findAll();for (Customer customer : all) {System.out.println(customer);}}@Testvoid testUpdateCustomer() {int row = customerRepository.updateCustomer("testUpdate", 1L);System.out.println(row);testFindAll();}@Testvoid testDeleteCustomer() {int row = customerRepository.deleteCustomer(1L, "testIndustry");System.out.println(row);testFindAll();}@Testvoid testSaveCustomer() {Customer customer = new Customer();customer.setCustName("save test");customer.setCustLevel("save level");
// customer.setCustId(1L); // 加上是更新某某,不加是添加新的一行数据customerRepository.save(customer);testFindAll();}
IV. JPQL
基于首次在 EJB2.0 中引入的 EJB 查询语言(EJB QL),Java JPQL(Java Persistence Query Language)是一种可移植的查询语言,旨在以面向对象表达式语言的表达式,将 SQL 语法和简单查询语义绑定在一起使用这种语言编写的查询是可移植的,可以被编译成所有主流数据库服务器上的 SQL。
其特征与原生SQL语句类似,并且完全面向对象,通过类名和属性访问,而不是表名和表的属性。
基本语法
select 实体别名.属性名,
from 实体名 as 实体别名
where 实体别名.实体属性 op 比较值# example
update Customer c set c.custName = ?1 where c.custId = ?2 # ?后跟变量序号(详见第一个Spring Data JPA项目)
delete from Customer c where c.custId = :custId and c.custIndustry = :custIndustry # :后跟变量名(详见第一个Spring Data JPA项目)
动态查询
在Spring Data JPA中,可以使用匿名内部类的方式添加动态条件,实现动态查询。步骤如下:
- 通过匿名内部类的方式创建一个Specification对象
- 编写toPredicate方法(
- root: Table对应的Entity
- CriteriaBuilder用于创建条件
- 编写具体的条件
示例代码:
@Test
public void testDynamicQuery() {List<User> users = userRepository.findAll(new Specification<User>() {@Overridepublic Predicate toPredicate(Root<User> root, CriteriaQuery<?> query, CriteriaBuilder criteriaBuilder) {Predicate predicate = null;Path<String> pwdPath = root.get("pwd");Predicate pwdPredicate = criteriaBuilder.equal(pwdPath, "123");predicate = criteriaBuilder.and(predicate, pwdPredicate);Path<String> namePath = root.get("name");Predicate namePredicate = criteriaBuilder.like(namePath, "%Jack%");predicate = criteriaBuilder.and(pwdPredicate, namePredicate);Path<Integer> idPath = root.get("id");Predicate idPredicate = criteriaBuilder.equal(idPath, 2);predicate = criteriaBuilder.and(predicate, idPredicate);return predicate;}});// print resultsfor (User user : users) {System.out.println(user);}
}
一对多、多对一、多对多
Spring Data JPA中可以在实体类属性上添加@ManyToOne、@OneToMany、@ManyToMany注解配置多对一、一对多和多对多。
1. 一对多、多对一
@OneToMany:
作用:建立一对多的关系映射
属性:
- targetEntityClass:指定多的多方的类的字节码
- mappedBy:指定从表实体类中引用主表对象的名称。
- cascade:指定要使用的级联操作
- fetch:指定是否采用延迟加载
- orphanRemoval:是否使用孤儿删除
@ManyToOne
作用:建立多对一的关系
属性:
- targetEntityClass:指定一的一方实体类字节码
- cascade:指定要使用的级联操作
- fetch:指定是否采用延迟加载
- optional:关联是否可选。如果设置为 false,则必须始终存在非空关系。
@JoinColumn
作用:用于定义主键字段和外键字段的对应关系。
属性:
- name:指定外键字段的名称
- referencedColumnName:指定引用主表的主键字段名称
- unique:是否唯一。默认值不唯一
- nullable:是否允许为空。默认值允许。
- insertable:是否允许插入。默认值允许。
- updatable:是否允许更新。默认值允许。
- columnDefinition:列的定义信息。
级联操作
级联操作:指操作一个对象同时操作它的关联对象
使用方法:只需要在操作主体的注解上配置 cascade
/*** cascade:配置级联操作 * CascadeType.MERGE 级联更新 * CascadeType.PERSIST 级联保存:* CascadeType.REFRESH 级联刷新:* CascadeType.REMOVE 级联删除: * CascadeType.ALL 包含所有
*/
@OneToMany(mappedBy="customer",cascade=CascadeType.ALL)
示例代码
@Entity
@Table(name = "article")
@IdClass(ArticlePrimaryKey.class)
@DynamicUpdate
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Article implements Serializable {@ManyToOne(targetEntity = User.class)@JoinColumn(name = "user_id", referencedColumnName = "id")private User user;@Id@Column(name = "article_id", nullable = false)private Integer articleId;@Column(name = "article_name")private String articleName;
}
@Entity
@Table(name = "user")
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)@Column(name = "id")private int id;@Column(name = "name")private String name;@Column(name = "pwd")private String pwd;@Column(name = "country_id")private int countryId;@OneToMany(targetEntity = Article.class, cascade = CascadeType.ALL, fetch = FetchType.EAGER)@JoinColumn(name = "user_id", referencedColumnName = "id")private Set<Article> articles;
}
2. 多对多
@ManyToMany
作用:用于映射多对多关系
属性: cascade:配置级联操作。
- fetch:配置是否采用延迟加载。
- targetEntity:配置目标的实体类。映射多对多的时候不用写。
@JoinTable
作用:针对中间表的配置
属性:
- name:配置中间表的名称
- joinColumns:中间表的外键字段关联当前实体类所对应表的主键字段
- inverseJoinColumn:中间表的外键字段关联对方表的主键字段
@JoinColumn
作用:用于定义主键字段和外键字段的对应关系。
属性:
- name:指定外键字段的名称
- referencedColumnName:指定引用主表的主键字段名称
- unique:是否唯一。默认值不唯一
- nullable:是否允许为空。默认值允许。
- insertable:是否允许插入。默认值允许。
- updatable:是否允许更新。默认值允许。
- columnDefinition:列的定义信息。
多表+动态查询
步骤
1. 创建结果实体类
package com.soul.entity;import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;@Data
@NoArgsConstructor
@AllArgsConstructor
public class UserArticleDTO {private Integer id;private String name;private String articleName;
}
2. 编写Repository
package com.soul.repository;import com.soul.entity.Article;
import com.soul.entity.User;
import com.soul.entity.UserArticleDTO;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;import javax.persistence.EntityManager;
import javax.persistence.PersistenceContext;
import javax.persistence.TypedQuery;
import javax.persistence.criteria.*;
import java.util.ArrayList;
import java.util.List;@Repository
public class UserArticleDao {@Autowired@PersistenceContextprivate EntityManager em;static final Integer PAGE_SIZE = 2;public List<UserArticleDTO> findUserArticle(int currentPage) {CriteriaBuilder builder = em.getCriteriaBuilder();CriteriaQuery<UserArticleDTO> query = builder.createQuery(UserArticleDTO.class);// from tableRoot<User> rootUser = query.from(User.class);Root<Article> rootArticle = query.from(Article.class);// where conditionsList<Predicate> predicates = new ArrayList<>();Predicate predicate1 = builder.equal(rootUser.get("id"), rootArticle.get("userId"));Predicate predicate2 = builder.equal(rootArticle.get("articleName"), "macbook");Predicate predicate3 = builder.like(rootArticle.get("articleName"), "%ms surface%");Predicate predicateOr = builder.or(predicate2, predicate3);predicates.add(predicate1);predicates.add(predicateOr);Predicate finalPredicate = builder.and(predicates.toArray(new Predicate[predicates.size()]));query.multiselect(rootUser.get("id").as(Integer.class), rootUser.get("name").as(String.class),rootArticle.get("articleName").as(String.class)).where(finalPredicate);// no paging// List<UserArticleDTO> resultList = em.createQuery(query).getResultList();// return resultList;// add paging to queryTypedQuery<UserArticleDTO> typedQuery = em.createQuery(query);typedQuery.setFirstResult((currentPage - 1) * PAGE_SIZE);typedQuery.setMaxResults(PAGE_SIZE);// execute queryList<UserArticleDTO> resultList = typedQuery.getResultList();return resultList;}
}
3. 测试
@Testpublic void testUserArticleDao() {List<UserArticleDTO> userArticle = userArticleDao.findUserArticle(1);for (UserArticleDTO userArticleDTO : userArticle) {System.out.println(userArticleDTO);}}
Spring Data JPA 对比 MyBatis
比较
-
hibernate是面向对象的,而MyBatis是面向关系的
-
数据分析型的OLAP应用适合用MyBatis,事务处理型OLTP应用适合用JPA
-
项目维护迭代维度比较(长期快速迭代类、变动较小的类型)
追求快速迭代,需求快速变更,灵活的 mybatis 修改起来更加方便,而且一般每一次的改动不会带来性能上的下降。JPA经常因为添加关联关系或者开发者不了解优化导致项目越来越糟糕(这里可能要考研功力了)
比较总结
-
表关联较多的项目,优先使用mybatis
-
持续维护开发迭代较快的项目建议使用mybatis,因为一般这种项目需要变化很灵活,对sql的灵活修改要求较高
-
对于传统项目或者关系模型较为清晰稳定的项目,建议JPA(比如DDD设计中的领域层)
-
目前微服务比较火,基于其职责的独立性,如果模型清晰,可以考虑使用JPA,但如果数据量较大全字段返回数据量大的话可能在性能有影响,需要根据实际情况进行分析
总结
Spring Data JPA 是Spring Data中一款强大的用于操作关系型数据库的技术。它的出现,省去了我们编写Dao层的步骤。在业务逻辑相对简单的时候,使用它会极大的提高开发效率。但是当业务逻辑太过复杂时,Spring Data JPA缺乏灵活性的问题就会暴露出来,这个时候MyBatis反而是更好的选择。
相关文章:
【spring】Spring Data --Spring Data JPA
Spring Data 的委托是为数据访问提供熟悉且符合 Spring 的编程模型,同时仍保留着相关数据存储的特殊特征。 它使使用数据访问技术、关系和非关系数据库、map-reduce 框架和基于云的数据服务变得容易。这是一个伞形项目,其中包含许多特定于给定数据库…...

mysql数据库之视图
视图(view)是一种虚拟的存在,视图中的数据并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的。 通俗的讲,视图之保存了查询的sql逻辑,不保存查询结…...
数据库事务详解
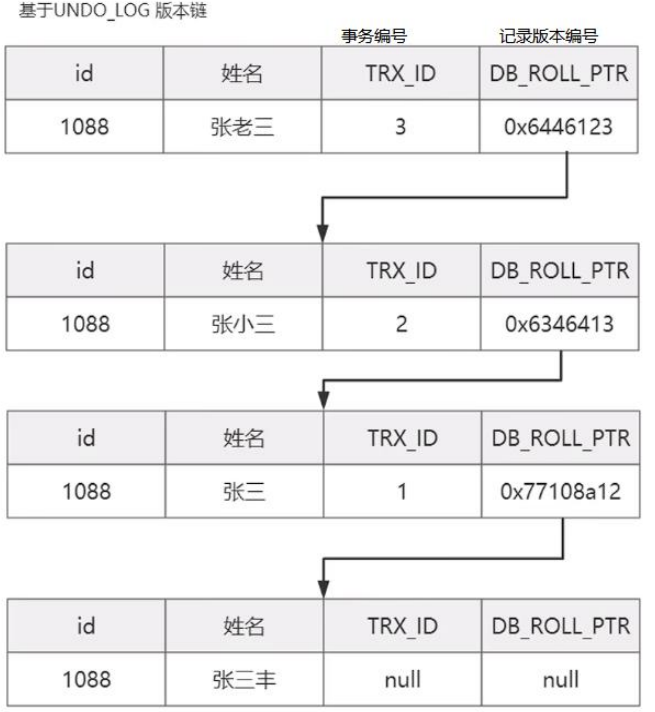
概述事务就是数据库为了保证数据的原子性,持久性,隔离性,一致性而提供的一套机制, 在同一事务中, 如果有多条sql执行, 事务可以确保执行的可靠性.数据库事务的四大特性一般来说, 事务是必须满足 4 个条件(ACID):原子性(Atomicity&…...
Nessus: 漏洞扫描器-网络取证工具
Nessue 要理解网络漏洞攻击,应该理解攻击者不是单独攻击,而是组合攻击。因此,本文介绍了关于Nessus历史的研究,它是什么以及它如何与插件一起工作。研究了Nessus的特点,使其成为网络取证中非常推荐的网络漏洞扫描工具…...

操作系统实战45讲之现代计算机组成
我以前觉得计算机理论不让我感兴趣,而比较喜欢实践,即敲代码,现在才发现理论学好了,实践才能有可能更顺利,更重要的是理论与实践相结合。 在现代,几乎所有的计算机都是遵循冯诺依曼体系结构,而遵…...

Simple Baselines for Image Restoration
Abstract.尽管近年来在图像恢复领域取得了长足的进步,但SOTA方法的系统复杂性也在不断增加,这可能会阻碍对方法的分析和比较。在本文中,我们提出了一个简单的基线,超过了SOTA方法,是计算效率。为了进一步简化基线&…...
)
Python数据可视化:局部整体图表可视化(基础篇—6)
目录 1、饼图 2、圆环图 3、马赛克图 4、华夫饼图 5、块状/点状柱形图 在学习本篇博文之前请先看一看之前发过的关联知识:...
CSDN新星计划新玩法、年度勋章挑战赛开启
文章目录🌟 写在前面🌟 逐步亮相的活动🌟 勋章挑战赛🌟 新星计划🌟 有付费课程才可参与?🌟 成就铭牌🌟 博客跟社区的关系🌟 写在最后🌟 写在前面 哈喽&#…...
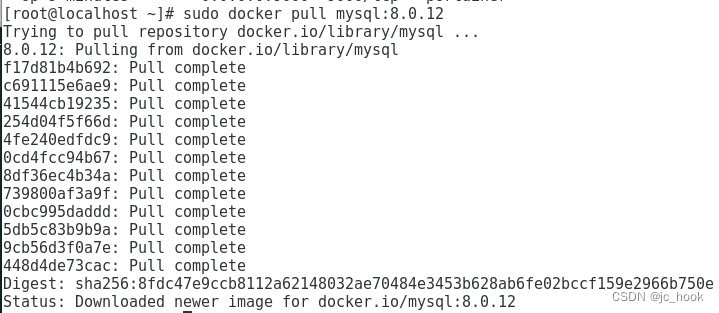
Docker之部署Mysql
通过docker对Mysql进行部署。 如果没有部署过docker,看我之前写的目录拉取镜像运行容器开放端口拉取镜像 前往dockerHub官网地址,搜索mysql。 找到要拉取的镜像版本,在tag下找到版本。 拉取mysql镜像,不指定版本数,…...
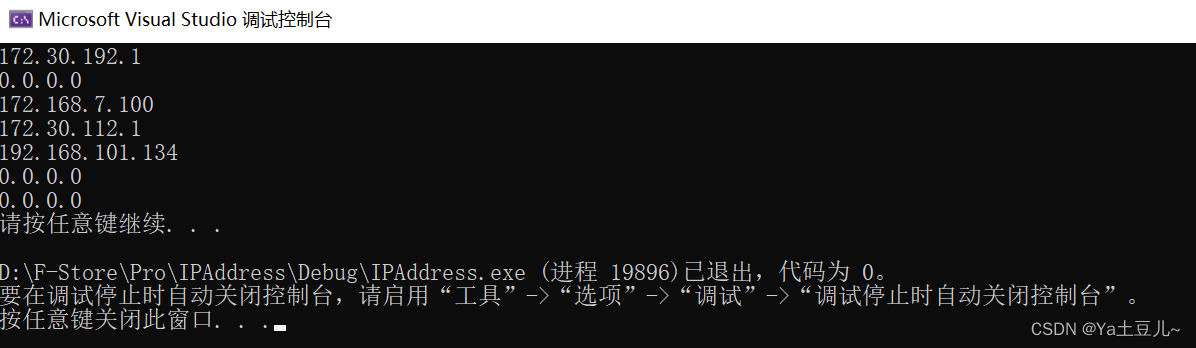
基于C/C++获取电脑网卡的IP地址信息
目录 前言 一、网卡是什么? 二、实现访问网卡信息 1.引入库及相关的头文件 2.操作网卡数据 3. 完整代码实现 4.结果验证 总结 前言 简单示例如何在windows下使用c/c代码实现 ipconfig/all 指令 提示:以下是本篇文章正文内容,下面案例可供参考…...

28相似矩阵和若尔当标准型
一、关于正定矩阵的一些补充 在此之前,先讲一下对称矩阵中那些特征值为正数的矩阵,这样特殊的矩阵称为正定矩阵。其更加学术的定义是: SSS 是一个正定矩阵,如果对于每一个非零向量xxx,xTSx>0x^TSx>0xTSx>0 正…...

springboot操作MongoDB
启动类及配置import com.mongodb.client.MongoClient;import com.mongodb.client.MongoClients;import com.mongodb.client.internal.MongoClientImpl;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplicatio…...
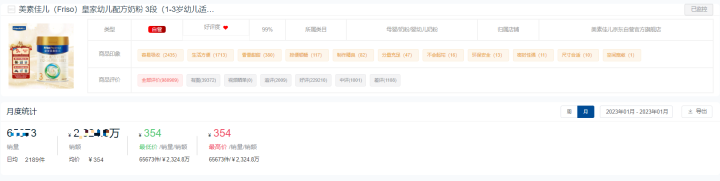
1月奶粉电商销售数据榜单:销售额约20亿,高端化趋势明显
鲸参谋电商数据监测的2023年1月份京东平台“奶粉”品类销售数据榜单出炉! 根据鲸参谋数据显示,1月份京东平台上奶粉的销量约675万件,销售额约20亿元,环比均下降19%左右。与去年相比,整体也下滑了近34%。可以看出&#…...
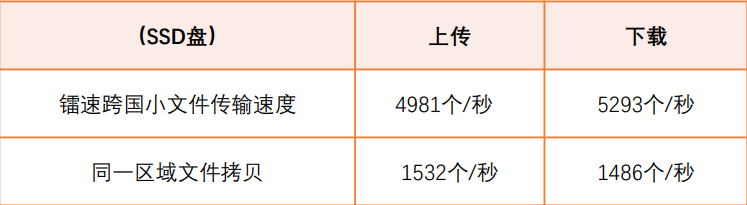
跨境数据传输是日常业务中经常且至关重要的组成部分
跨境数据传输是日常业务中经常且至关重要的组成部分。在过去的20年中,由于全球通信网络和业务流程的发展,全球数据流的模式已迅速发展。随着数据从数据中心移到数据中心和/或跨边界移动,安全漏洞已成为切实的风险。有可能违反国家和国际数据传…...

错误: tensorflow.python.framework.errors_impl.OutOfRangeError的解决方案
近日,在使用CascadeRCNN完成目标检测任务时,我在使用这个模型训练自己的数据集时出现了如下错误: tensorflow.python.framework.errors_impl.OutOfRangeError: PaddingFIFOQueue _1_get_batch/batch/padding_fifo_queue is closed and has in…...

springboot项目初始化执行sql
Sprint Boot应用可以在启动的时候自动执行项目根路径下的SQL脚本文件。我们需要先将sql脚本写好,并将这些静态资源都放置在src/main/resources文件夹下。 再配置application.yml: spring.datasource.initialization-mode 必须配置初始化模式initializa…...

Kubernetes之存储管理(中)
NFS网络存储 emptyDir和hostPath存储,都仅仅是把数据存储在pod所在的节点上,并没有同步到其他节点,如果pod出现问题,通过deployment会产生一个新的pod,如果新的pod不在之前的节点,则会出现问题,…...
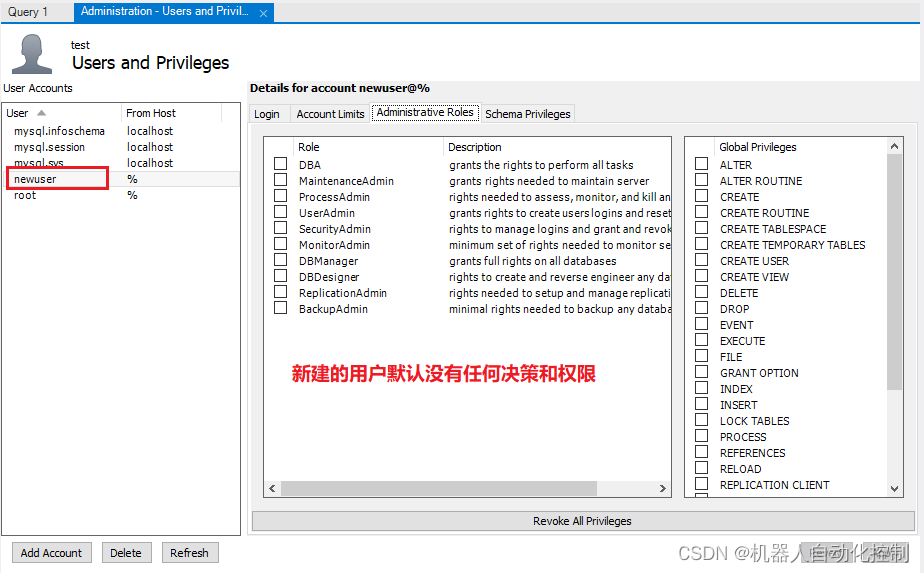
MySQL workbench的基本操作
1. 创建新的连接 hostname主机名输入“local host”和“127.0.0.1”效果是一样的,指的是本地的服务器。 需要注意的是,此处的密码在安装软件的时候已经设定。 点击【Test Connection】,测试连接是否成功。 创建完的连接可以通过,…...

【Flink】FlinkSQL中Table和DataStream互转
在我们实际使用Flink的时候会面临很多复杂的需求,很可能需要FlinkSQL和DataStream互相转换的情况,这就需要我们熟练掌握Table和DataStream互转,本篇博客给出详细代码以及执行结果,可直接使用,通过例子可学会Table和DataStream互转,具体步骤如下: maven如下<?xml ver…...
一)
网络总结知识点(网络工程师必备)一
♥️作者:小刘在C站 ♥️个人主页:小刘主页 ♥️每天分享云计算网络运维课堂笔记,努力不一定有收获,但一定会有收获加油!一起努力,共赴美好人生! ♥️夕阳下,是最美的绽放,树高千尺,落叶归根人生不易,人间真情 目录 1.TCP UDP协议的区别 2.ARP是第几层协议,其作用...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...
使用rpicam-app通过网络流式传输视频)
树莓派超全系列教程文档--(62)使用rpicam-app通过网络流式传输视频
使用rpicam-app通过网络流式传输视频 使用 rpicam-app 通过网络流式传输视频UDPTCPRTSPlibavGStreamerRTPlibcamerasrc GStreamer 元素 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 使用 rpicam-app 通过网络流式传输视频 本节介绍来自 rpica…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...

【Linux】自动化构建-Make/Makefile
前言 上文我们讲到了Linux中的编译器gcc/g 【Linux】编译器gcc/g及其库的详细介绍-CSDN博客 本来我们将一个对于编译来说很重要的工具:make/makfile 1.背景 在一个工程中源文件不计其数,其按类型、功能、模块分别放在若干个目录中,mak…...
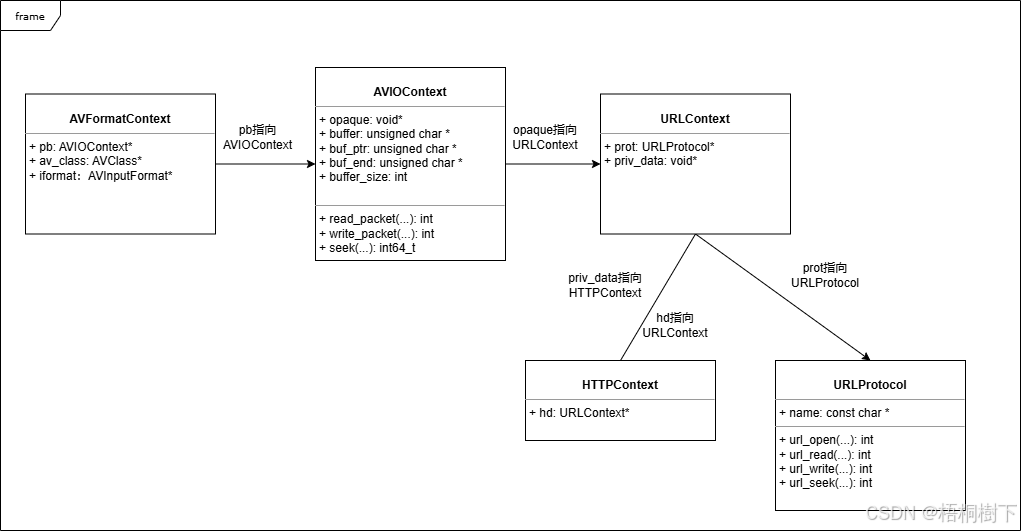
FFmpeg avformat_open_input函数分析
函数内部的总体流程如下: avformat_open_input 精简后的代码如下: int avformat_open_input(AVFormatContext **ps, const char *filename,ff_const59 AVInputFormat *fmt, AVDictionary **options) {AVFormatContext *s *ps;int i, ret 0;AVDictio…...

flow_controllers
关键点: 流控制器类型: 同步(Sync):发布操作会阻塞,直到数据被确认发送。异步(Async):发布操作非阻塞,数据发送由后台线程处理。纯同步(PureSync…...
GraphRAG优化新思路-开源的ROGRAG框架
目前的如微软开源的GraphRAG的工作流程都较为复杂,难以孤立地评估各个组件的贡献,传统的检索方法在处理复杂推理任务时可能不够有效,特别是在需要理解实体间关系或多跳知识的情况下。先说结论,看完后感觉这个框架性能上不会比Grap…...