Hadoop入门学习笔记——二、在虚拟机里部署HDFS集群
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7
课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd=5ay8
Hadoop入门学习笔记(汇总)
目录
- 二、在虚拟机里部署HDFS集群
- 2.1. 部署node1虚拟机
- 2.2. 部署node2和node3虚拟机
- 2.3. 初始化并启动Hadoop集群(格式化文件系统)
- 2.4. 快照部署好的集群
- 2.5. 部署过程中可能会遇到的问题
- 2.5. Hadoop HDFS集群启停脚本
二、在虚拟机里部署HDFS集群
下载Hadoop:https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
本次演示部署结构如下图所示:
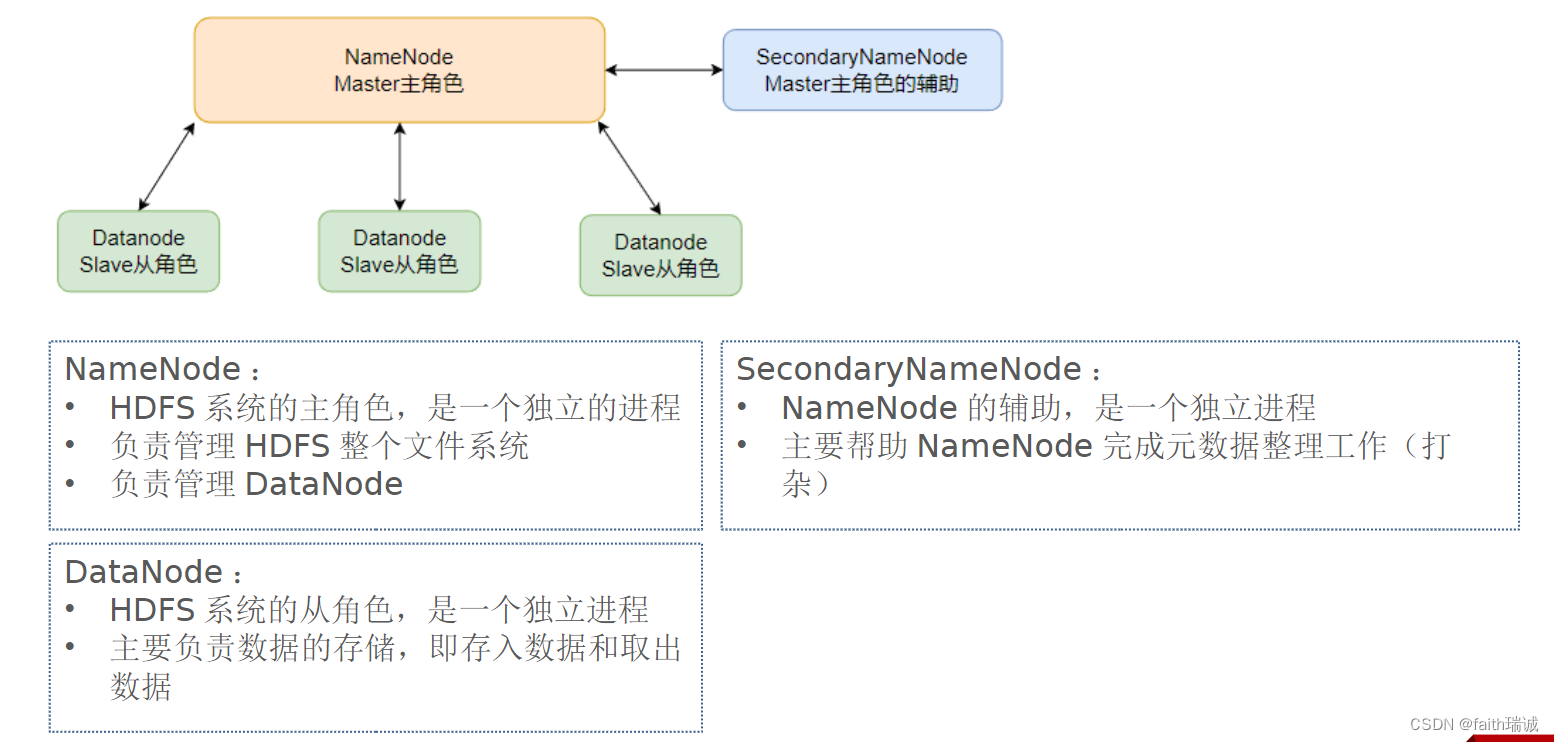
本次部署服务清单如下表所示:
| 节点 | 部署的服务 |
|---|---|
| node1 | NameNode、DataNode、SecondaryNameNode |
| node2 | DataNode |
| node3 | DataNode |
2.1. 部署node1虚拟机
1、将下载好的Hadoop压缩包上传至node1虚拟机的root目录;
2、将Hadoop压缩包解压至/export/server目录下
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server/
3、创建hadoop目录的软链接
# 切换工作目录
cd /export/server/
# 创建软连接
ln -s /export/server/hadoop-3.3.4/ hadoop
4、hadoop目录结构如下

| 目录 | 存放内容 |
|---|---|
| bin | 存放Hadoop的各类程序(命令) |
| etc | 存放Hadoop的配置文件 |
| include | 存放Hadopp用到的C语言的头文件 |
| lib | 存放Linux系统的动态链接库(.so文件) |
| libexec | 存放配置Hadoop系统的脚本文件(.sh和.cmd文件) |
| licenses_binary | 存放许可证文件 |
| sbin | 管理员程序(super bin) |
| share | 存放二进制源码(jar包) |
5、配置workers文件
cd etc/hadoop/
vim workers
将workers文件原有的内容删掉,改为
node1
node2
node3
保存即可;
6、配置hadoop-env.sh文件,使用vim hadoop-env.sh打开,修改以下配置:
# 指明JDK安装目录
export JAVA_HOME=/export/server/jdk
# 指明HADOOP安装目录
export HADOOP_HOME=/export/server/hadoop
# 指明HADOOP配置文件的目录
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#指明HADOOP运行日志文件的目录
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
7、配置core-site.xml文件,使用vim core-site.xml打开文件,修改以下配置:
<configuration><property><!--HDFS 文件系统的网络通讯路径--><name>fs.defaultFS</name><value>hdfs://node1:8020</value></property><property><!--io 操作文件缓冲区大小--><name>io.file.buffer.size</name><value>131072</value></property>
</configuration>
8、配置hdfs-site.xml文件,修改以下配置:
<configuration><property><!--hdfs 文件系统,默认创建的文件权限设置--><name>dfs.datanode.data.dir.perm</name><!-- 700权限即rwx------ --><value>700</value></property><property><!--NameNode 元数据的存储位置--><name>dfs.namenode.name.dir</name><!-- 在 node1 节点的 /data/nn 目录下 --><value>/data/nn</value></property><property><!--NameNode 允许哪几个节点的 DataNode 连接(即允许加入集群)--><name>dfs.namenode.hosts</name><value>node1,node2,node3</value></property><property><!--hdfs 默认块大小--><name>dfs.blocksize</name><!--268435456即256MB--><value>268435456</value></property><property><!--namenode 处理的并发线程数--><name>dfs.namenode.handler.count</name><value>100</value></property><property><!--从节点 DataNode 的数据存储目录,即数据存放在node1、node2、node3三台机器中的路径--><name>dfs.datanode.data.dir</name><value>/data/dn</value></property>
</configuration>
9、根据上一步的配置项,在node1节点创建/data/nn和/data/dn目录,在node2和node3节点创建/data/dn目录;
10、将已配置好的hadoop程序从node1分发到node2和node3:
# 切换工作目录
cd /export/server/
# 将node1的hadoop-3.3.4/目录复制到node2的同样的位置
scp -r hadoop-3.3.4/ node2:`pwd`/
# 将node1的hadoop-3.3.4/目录复制到node3的同样的位置
scp -r hadoop-3.3.4/ node3:`pwd`/
11、将Hadoop加入环境变量,使用vim /etc/profile打开环境变量文件,将以下内容添加在文件末尾:
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行source /etc/profile命令使环境变量配置生效;
12、修改相关目录的权限:
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export/
2.2. 部署node2和node3虚拟机
本小节内容如无特殊说明,均需在node2和node3虚拟机分别执行!
1、为hadoop创建软链接,命令都是一样的,如下所示:
cd /export/server/
ln -s /export/server/hadoop-3.3.4/ hadoop
2、将Hadoop加入环境变量,使用vim /etc/profile打开环境变量文件,将以下内容添加在文件末尾:
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行source /etc/profile命令使环境变量配置生效;
3、修改相关目录的权限:
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export/
2.3. 初始化并启动Hadoop集群(格式化文件系统)
1、在node1虚拟机上执行以下命令:
# 切换为hadoop用户
su - hadoop
# 格式化namenode
hadoop namenode -format
2、启动集群,在node1虚拟机上执行以下命令:
# 一键启动整个集群,包括namenode、secondarynamenode和所有的datanode
start-dfs.sh
# 查看当前系统中正在运行的Java进程,可以看到每台虚拟机上hadoop的运行情况
jps
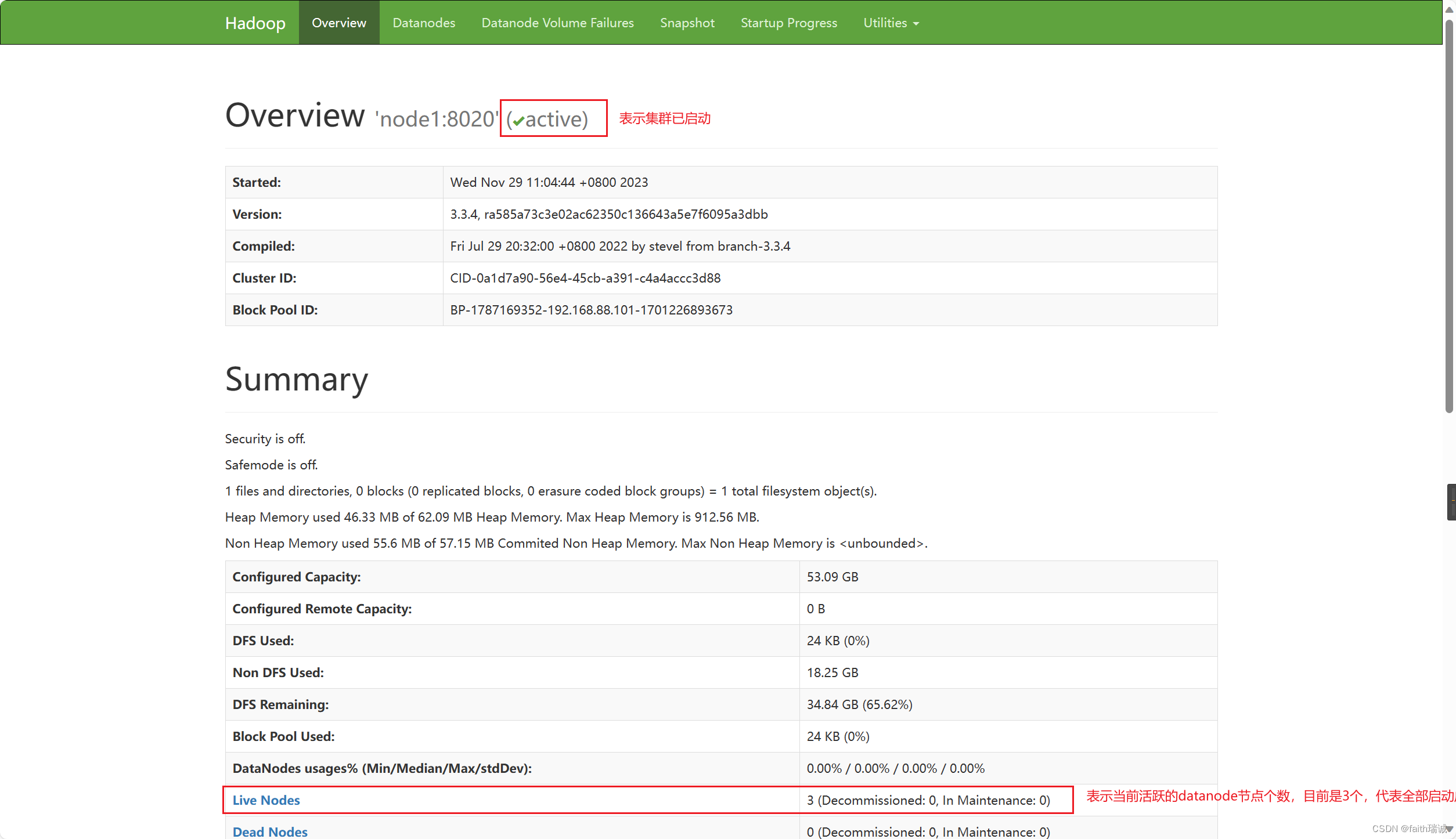
3、执行上述步骤之后,我们可以在我们自己的电脑(非虚拟机)上查看 HDFS WEBUI(即HADOOP管理页面),可以通过访问namenode所在服务器的9870端口查看,在本案例中因为namenode处于node1虚拟机上,所以可以访问http://node1:9870/打开。PS:因为之前我们已经配置了本机的hosts文件,所以这里可以使用node1访问,其实这个地址对应的就是http://192.168.88.101:9870/。
4、如果看到以下界面,代表Hadoop集群启动成功了。
2.4. 快照部署好的集群
为了保存刚部署好的集群,在后续如果出现无法解决的问题,不至于重新部署一遍,使用虚拟机快照的方式进行备份。
1、一键关闭集群,在node1虚拟机执行以下命令:
# 切换为hadoop用户
su - hadoop
# 一键关闭整个集群
stop-dfs.sh
关闭完成后,可以在node1、node2、node3虚拟机中使用jps命令查看相应Java进程是否已消失。
2、关闭三台虚拟机;
3、在VMware中,分别在三台虚拟机上右键,“快照”-“拍摄快照”功能创建快照。
2.5. 部署过程中可能会遇到的问题
- 在以Hadoop用户身份执行
start-dfs.sh命令时,提示Permission denied。此时需要检查三台虚拟机上相关路径(/data、/export/server及其子路径)上hadoop用户是否具有读、写、执行的权限。 - 在执行
start-dfs.sh命令后,使用jps命令可以查看已启动的服务,若发现有服务未启动成功的,可以查看/export/server/hadoop/logs目录下的日志文件,若在日志文件中看到类似于无权限、不可访问等报错信息,同样需要检查对应机器的相关路径权限。 - 执行
hadoop namenode -format、start-dfs.sh、stop-dfs.sh等Hadoop相关命令时,若提示command not found,则代表着环境变量没配置好,需要检查三台机器的/etc/profile文件的内容(需要使用source命令使环境变量生效)以及hadoop的软连接是否正确。 - 执行
start-dfs.sh命令后,node1的相关进程启动成功,但node2和node3没有启动的,需要检查workers文件的配置是否有node2和node3。 - 若在日志文件中看到WstxEOFException或Unexpected EOF等信息,大概率是xml配置文件有问题,需要仔细检查core-site.xml和hdfs-site.xml文件里面的内容(少了某个字母或字符、写错了某个字母或字符),尤其是符号。
综上,常见出错点总结为:
- 权限未正确配置;
- 配置文件错误;
- 未格式化
2.5. Hadoop HDFS集群启停脚本
注意:在使用以下命令前,一定要确保当前是hadoop用户,否则将报错或没有效果!!!
-
Hadoop HDFS 组件内置了HDFS集群的一键启停脚本。
-
$HADOOP_HOME/sbin/start-dfs.sh,一键启动HDFS集群
执行流程:- 在执行此脚本的机器上,启动SecondaryNameNode;
- 读取
core-site.xml内容(fs.defaultFS项),确定NameNode所在机器,启动NameNode; - 读取
workers内容,确定DataNode所在机器,启动全部DataNode。
-
$HADOOP_HOME/sbin/stop-dfs.sh,一键关闭HDFS集群
执行流程:- 在执行此脚本的机器上,关闭SecondaryNameNode;
- 读取
core-site.xml内容(fs.defaultFS项),确定NameNode所在机器,关闭NameNode; - 读取
workers内容,确认DataNode所在机器,关闭全部NameNode。
-
-
除了一键启停外,也可以单独控制某个进程的启停。
-
$HADOOP_HOME/sbin/hadoop-daemon.sh,此脚本可以单独控制所在机器的进程启停
用法:hadoop-daemon.sh (start|status|stop) (namenode|secondarynamenode|datanode) -
$HADOOP_HOME/sbin/hdfs,此程序也可以单独控制所在机器的进程启停
用法:hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)
-
相关文章:
Hadoop入门学习笔记——二、在虚拟机里部署HDFS集群
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7 课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd5ay8 Hadoop入门学习笔记(汇总) 目录 二、在虚拟机里部署HDFS集群2.1. 部署node1虚拟机2.2. 部…...

Spring之国际化:i18n
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。各位小伙伴,如果您: 想系统/深入学习某技术知识点… 一个人摸索学习很难坚持,想组团高效学习… 想写博客但无从下手,急需…...

Java读取类路径下的JSON文件并转换为实体列表
使用 Jackson 库来读取类路径下的 JSON 文件并将其转换为对应实体列表。 在实际开发中可能在本地环境中需要调用别人的接口,别人的接口如果还没开发好或者本地环境不支持外部接口调用的时候,可以读取json文件来造数据,方便调试。 以Student…...
复分析——第1章——复分析准备知识(E.M. Stein R. Shakarchi)
第一章 复分析准备知识 (Preliminaries to Complex Analysis) The sweeping development of mathematics during the last two centuries is due in large part to the introduction of complex numbers; paradoxically, this is based on the seemingly absurd no…...

C++ 继承方式
C++ 继承方式 实验介绍 本章节将学习权限关键字的使用,并将一一举例验证 public、protected、private 的使用,学完本小节实验后将彻底掌握权限关键字的使用。 知识点 权限关键字使用位置继承中的权限关键字public 继承protected 继承private 继承权限关键字使用位置 示例…...
华为云Windows Server服务器下,Node使用pm2-logrotate分割pm2日志,解决pm2日志内存占用过高的问题。
一、简介 PM2 是一个守护进程管理器,它将帮助您管理和保持您的应用程序在线。PM2 入门很简单,它以简单直观的 CLI 形式提供,可通过 NPM 安装。官网地址:https://pm2.keymetrics.io/ 二、问题:pm2日志内存占用过高&am…...
web3风险投资公司之Electric Capital
文章目录 什么是 Electric CapitalElectric团队 Electric Capital 开发者报告参考 什么是 Electric Capital 官网:https://www.electriccapital.com/ 官方github:https://github.com/electric-capital Electric Capital 是一家投资于加密货币、区块链企…...

为什么员工都非常抵触「绩效考核」,该怎么办呢?
员工抵制绩效考核的原因可能有很多,其中一些常见的原因包括: 考核方式不公正:如果考核方式不够客观、公正,或者与员工的实际工作情况不符,员工就会对绩效考核产生不信任感,从而产生抵触情绪。 工作压力增大…...
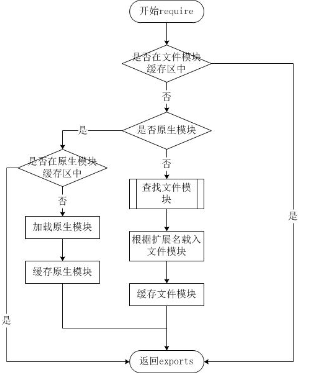
[node]Node.js 模块系统
[node]模块系统 Node.js中的模块系统模块的使用模块的导入模块的导出导出多个值导出默认值导出可传参的函数 文件查找策略从文件模块缓存中加载从原生模块加载从文件加载 Node.js中的模块系统 为了让Node.js的文件可以相互调用,Node.js提供了一个简单的模块系统。 …...

【数据结构】什么是二叉树?
🦄个人主页:修修修也 🎏所属专栏:数据结构 ⚙️操作环境:Visual Studio 2022 目录 📌二叉树的定义 📌二叉树的特点 📌特殊二叉树 📌二叉树的性质 📌二叉树的存储结构 📌二叉树…...
C#教程(四):多态
1、介绍 1.1 什么是多态 在C#中,多态性(Polymorphism)是面向对象编程中的一个重要概念,它允许不同类的对象对同一消息做出响应,即同一个方法可以在不同的对象上产生不同的行为。C#中的多态性可以通过以下几种方式实现…...
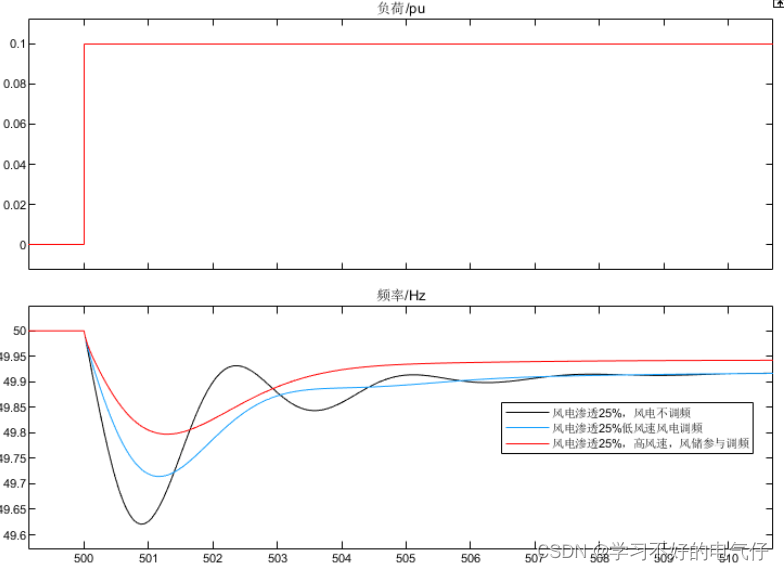
电力系统风储联合一次调频MATLAB仿真模型
微❤关注“电气仔推送”获得资料(专享优惠) 简介: 同一电力系统在不同风电渗透率下遭受同一负荷扰动时,其频率变化规律所示: (1)随着电力系统中风电渗透率的不断提高,风电零惯性响…...

《PCI Express体系结构导读》随记 —— 内容与作者简介
本书内容介绍 本书讲述了PCI与PCI Express总线相关的最为基础的内容,并介绍了一些必要的、与PCI总线相关的处理器体系结构知识,这也是本书的重点所在。深入理解处理器体系结构是理解PCI与PCI Express总线的重要基础。 读者通过对本书的学习,…...

C#字典和列表转LuaTable
C#字典和列表转LuaTable 将C#Dictionary转成luaTable将C#List转成luaTable 将C#Dictionary转成luaTable function DicToLuaTable(Dic)--将C#的Dic转成Lua的Tablelocal dic {}if Dic thenlocal iter Dic:GetEnumerator()while iter:MoveNext() dolocal k iter.Current.Keylo…...
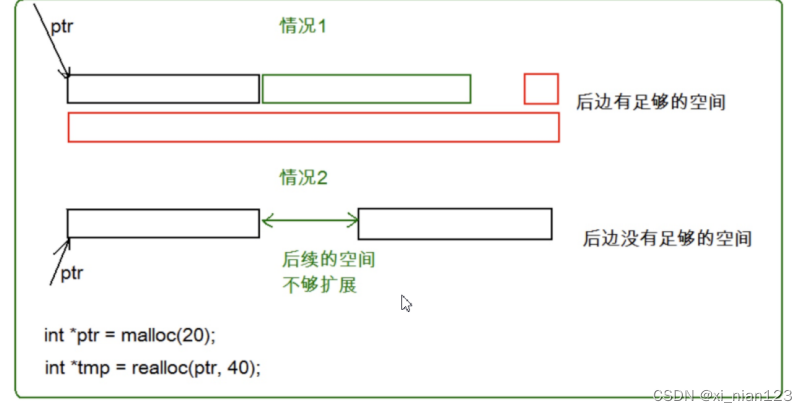
动态内存管理(1)
目录 1. 为什么存在动态内存分配 2. 动态内存函数的介绍 2.2 calloc 2.3 realloc 3. 常见的动态内存错误 3.1 对NULL指针的解引用操作 3.2 对动态开辟空间的越界访问 3.3 对非动态开辟内存使用free释放 3.4 使用free释放一块动态开辟内存的一部分 3.5 对同一块动…...
ThunderSearch(闪电搜索器)_网络空间搜索引擎工具_信息收集
文章目录 ThunderSearch简介1 项目地址2 使用方式2.1 配置文件config.json说明2.2 构建和运行 3 使用式例 ThunderSearch简介 ThunderSearch(闪电搜索器)是一款使用多个(【支持Fofa、Shodan、Hunter、Zoomeye、360Quake网络空间搜索引擎】网络空间搜索引…...
Topaz Video AI 视频修复工具(内附安装压缩包win+Mac)
目录 一、Topaz Video AI 简介 二、Topaz Video AI 安装下载 三、Topaz Video AI 使用 最近玩上了pika1.0和runway的图片转视频,发现生成出来的视频都是有点糊的,然后就找到这款AI修复视频工具 Topaz Video AI。 一、Topaz Video AI 简介 Topaz Video…...

android内存管理机制概览
关于作者:CSDN内容合伙人、技术专家, 从零开始做日活千万级APP。 专注于分享各领域原创系列文章 ,擅长java后端、移动开发、人工智能等,希望大家多多支持。 目录 一、导读二、概览三、相关概念3.1 垃圾回收3.2 应用内存的分配与回…...

下载MySQL Connector/C++
MySQL :: Download Connector/C...

ai gpt 鸡皮剔提问技巧
请将如下AB两组信息逐个匹配上的进行同类归类,用json格式输出: A:苹果 电脑 汽车 B: 猕猴桃 笔记本 根据你的要求,逐个匹配 A 组和 B 组的元素,并以 JSON 格式输出同类的归类信息: json { "匹配信息"…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

视频行为标注工具BehaviLabel(源码+使用介绍+Windows.Exe版本)
前言: 最近在做行为检测相关的模型,用的是时空图卷积网络(STGCN),但原有kinetic-400数据集数据质量较低,需要进行细粒度的标注,同时粗略搜了下已有开源工具基本都集中于图像分割这块,…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

DeepSeek源码深度解析 × 华为仓颉语言编程精粹——从MoE架构到全场景开发生态
前言 在人工智能技术飞速发展的今天,深度学习与大模型技术已成为推动行业变革的核心驱动力,而高效、灵活的开发工具与编程语言则为技术创新提供了重要支撑。本书以两大前沿技术领域为核心,系统性地呈现了两部深度技术著作的精华:…...

消防一体化安全管控平台:构建消防“一张图”和APP统一管理
在城市的某个角落,一场突如其来的火灾打破了平静。熊熊烈火迅速蔓延,滚滚浓烟弥漫开来,周围群众的生命财产安全受到严重威胁。就在这千钧一发之际,消防救援队伍迅速行动,而豪越科技消防一体化安全管控平台构建的消防“…...

【FTP】ftp文件传输会丢包吗?批量几百个文件传输,有一些文件没有传输完整,如何解决?
FTP(File Transfer Protocol)本身是一个基于 TCP 的协议,理论上不会丢包。但 FTP 文件传输过程中仍可能出现文件不完整、丢失或损坏的情况,主要原因包括: ✅ 一、FTP传输可能“丢包”或文件不完整的原因 原因描述网络…...

多元隐函数 偏导公式
我们来推导隐函数 z z ( x , y ) z z(x, y) zz(x,y) 的偏导公式,给定一个隐函数关系: F ( x , y , z ( x , y ) ) 0 F(x, y, z(x, y)) 0 F(x,y,z(x,y))0 🧠 目标: 求 ∂ z ∂ x \frac{\partial z}{\partial x} ∂x∂z、 …...