大数据技术学习笔记(十一)—— Flume
目录
- 1 Flume 概述
- 1.1 Flume 定义
- 1.2 Flume 基础架构
- 2 Flume 安装
- 3 Flume 入门案例
- 3.1 监控端口数据
- 3.2 实时监控单个追加文件
- 3.3 实时监控目录下多个新文件
- 3.4 实时监控目录下的多个追加文件
- 4 Flume 进阶
- 4.1 Flume 事务
- 4.2 Flume Agent 内部原理
- 4.3 Flume 拓扑结构
- 4.3.1 简单串联
- 4.3.2 复制和多路复用
- 4.3.3 负载均衡和故障转移
- 4.3.4 聚合
- 4.4 企业开发案例
- 4.4.1 复制
- 4.4.2 负载均衡
- 4.4.3 故障转移
- 4.4.4 聚合
- 4.5 自定义 Interceptor
- 4.6 自定义 Source
- 4.7 自定义 Sink
- 4.8 Flume 数据流监控
- 4.8.1 Ganglia 的安装与部署
- 4.8.2 操作 Flume 测试监控
1 Flume 概述
1.1 Flume 定义
Flume 是 Cloudera 公司提供的一个 高可用 的, 高可靠 的,分布式 的 海量日志采集、聚合 和 传输 的系统。Flume 基于流式架构,灵活简单。
这里的日志不是指框架工作运行的日志,而是跟业务相关的日志数据,如用户行为数据等
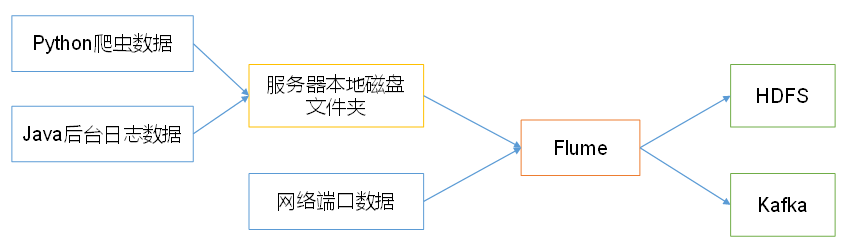
Flume 最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到 HDFS。
1.2 Flume 基础架构
Flume 组成架构如下图所示。
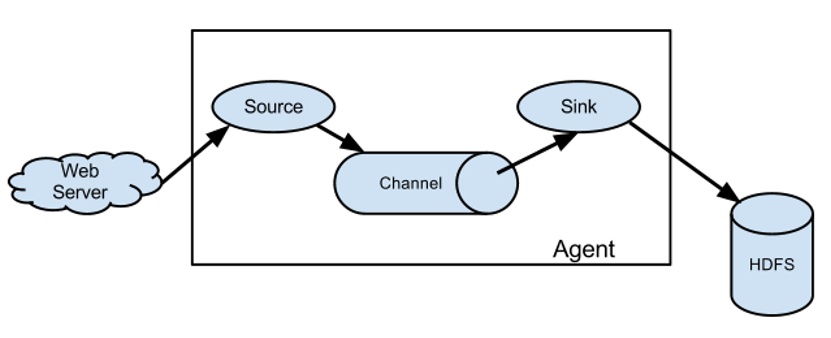
(1)Agent
Agent 是一个JVM 进程,它以 事件 的形式将数据从源头送至目的地。
Agent 主要有 3 个部分组成,Source、Channel、Sink。
(2)Source
Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、 taildir 、sequence generator、syslog、http、legacy。
Flume中有两种source
- Pullable Source,TailDirSource就是这种Source,这种Source是主动拉取数据,而不是由数据源推送过来的,这种Source在回滚等待的过程中source不会继续拉取数据。
- Eventdriven Source,这种Source中的数据是由数据源主动不停的提交数据,在事务回滚的时候,会停止接收数据,这时有可能会产生数据丢失,这种丢失并不是发生在Flume内部,而是发生在Flume和数据源之间。
(3)Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 组件目的地包括 hdfs、logger、avro、thrift、ipc、file、HBase、solr、自定义。
Flume 与 Flume 之间使用 avro
(4)Channel
Channel 是位于 Source 和 Sink 之间的 缓冲区。因此,Channel 允许 Source 和Sink 运作在不同的速率上。Channel 是线程安全的,可以同时处理几个 Source 的写入操作和几个 Sink 的读取操作。
Flume 自带两种 Channel:Memory Channel 和 File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
(5)Event
Event 是传输单元,Flume 数据传输的基本单元,以 Event 的形式将数据从源头送至目的地。Event 由 Header 和 Body 两部分组成,Header 用来存放该 event 的一些属性,为 K-V 结构,Body 用来存放该条数据,形式为 字节数组。

2 Flume 安装
请移步 Flume 安装与部署
3 Flume 入门案例
Flume 官方文档
3.1 监控端口数据
案例需求
使用 Flume 监听一个端口,收集该端口数据,并打印到控制台。
需求分析
确定每一个组件的类型

实现步骤
(1)在 flume 目录下创建 jobs 文件夹并进入 jobs 文件夹
[huwei@hadoop101 ~]$ cd /opt/module/flume-1.9.0/
[huwei@hadoop101 flume-1.9.0]$ mkdir jobs
[huwei@hadoop101 flume-1.9.0]$ cd jobs
(2)新建并编辑 flume-netcat-logger.conf 文件
[huwei@hadoop101 jobs]$ vim flume-netcat-logger.conf
添加如下内容
# Named
# a1表示agent的名称
a1.sources = r1 # r1表示a1的Source的名称
a1.channels = c1 # c1表示a1的channel的名称
a1.sinks = k1 # k1表示a1的Sink的名称# Source
a1.sources.r1.type = netcat # 表示a1的输入源类型为netcat端口类型
a1.sources.r1.bind = localhost # 表示a1的监听主机
a1.sources.r1.port = 6666 # 表示a1的监听端口号# Channel
a1.channels.c1.type = memory # 表示a1的channel类型是memory内存型
a1.channels.c1.capacity = 10000 # 表示a1的channel总容量是10000个event
a1.channels.c1.transactionCapacity = 100 # 表示a1的channel传输时收集到了100条event以后再去提交事务# Sink
a1.sinks.k1.type = logger # 表示a1的输出目的地是控制台logger类型# Bind
a1.sources.r1.channels = c1 # 表示将r1和c1连接起来
a1.sinks.k1.channel = c1 # 表示将k1和c1连接起来
(3)安装 netcat 工具(实现客户端发送数据到端口)
[huwei@hadoop101 jobs]$ sudo yum install -y nc
(4)开启 flume 监听端口
[huwei@hadoop101 jobs]$ flume-ng agent --conf $FLUME_HOME/conf --conf-file $FLUME_HOME/jobs/flume-netcat-logger.conf --name a1
也可以简写为
[huwei@hadoop101 jobs]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/flume-netcat-logger.conf -n a1
Logger Sink 本质上就是 log4j 的实现,默认是往文件里存日志
(5)使用 netcat 工具向本机的 6666 端口发送内容
重新开启一个 shell 窗口
[huwei@hadoop101 ~]$ nc localhost 6666
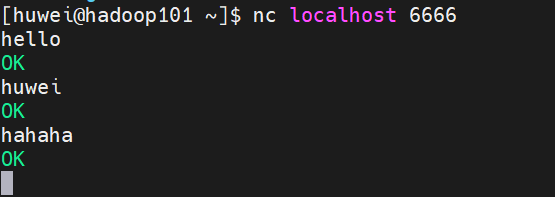
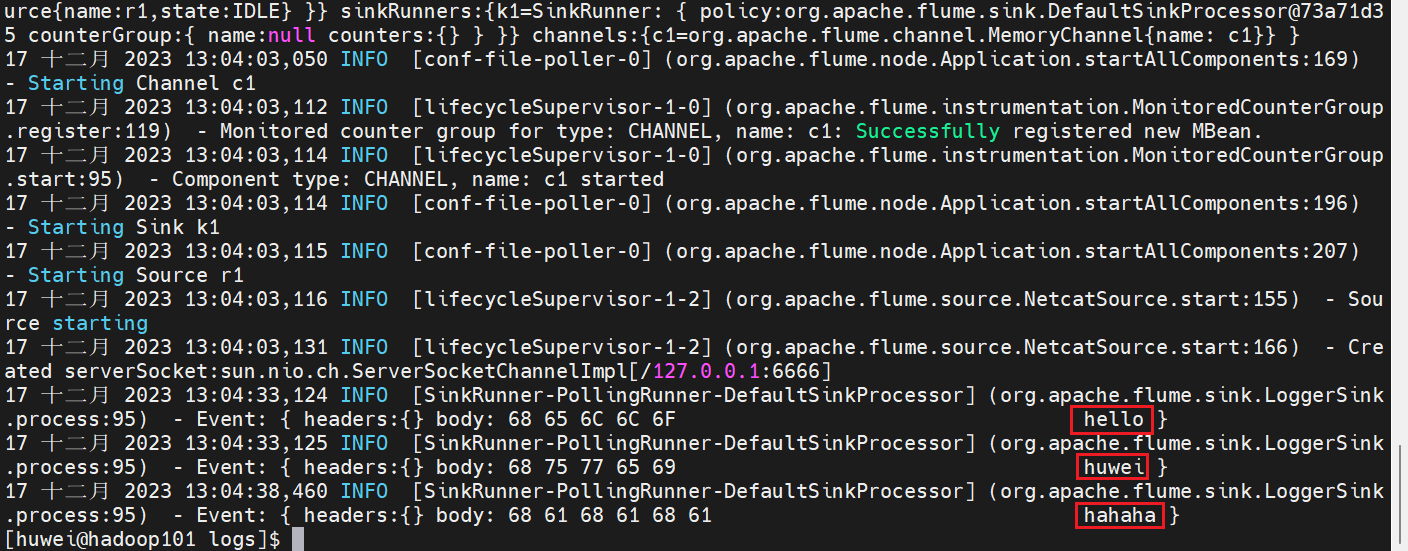
(6)查看日志
jobs 文件夹下会多一个 logs 文件夹
[huwei@hadoop101 jobs]$ cd /opt/module/flume-1.9.0/jobs/logs/
[huwei@hadoop101 logs]$ cat flume.log
(7)设置将日志打印到控制台
[huwei@hadoop101 flume-1.9.0]$ cd conf
[huwei@hadoop101 conf]$ vim log4j.properties
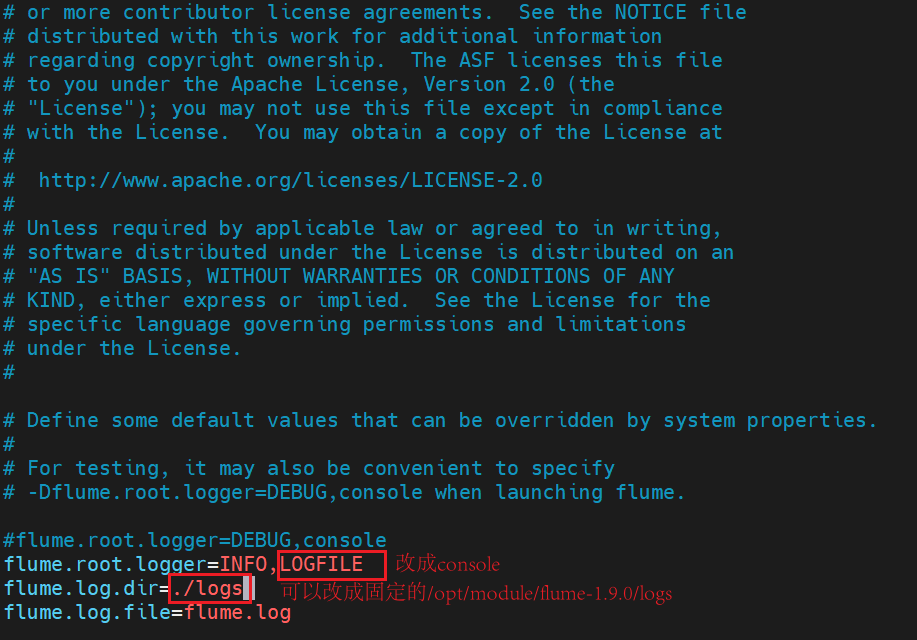
但是上述通过配置文件将日志打印控制台的方式并不推荐,因为我们并不是每次都需要打印控制台,推荐指定参数动态修改
修改(4)中的命令,添加参数 -Dflume.root.logger=INFO,console
[huwei@hadoop101 jobs]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/flume-netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
此时重新启动(5)中的窗口再次发送数据,就可以在监听窗口的控制台看到发送的数据了
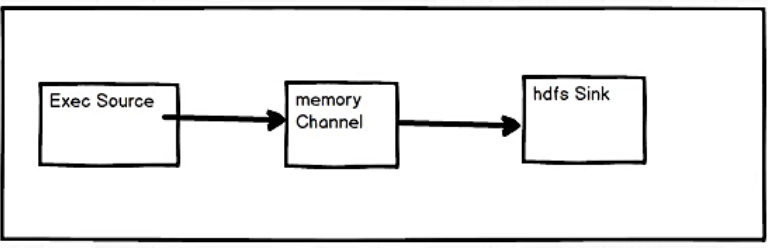
3.2 实时监控单个追加文件
案例需求
实时 监控单个追加文件,并将监控到的内容上传到 HDFS 中
需求分析
确定每一个组件的类型
实现步骤
(1)在 flume 目录下 jobs 文件夹下,新建一个要监控文件
[huwei@hadoop101 jobs]$ touch tail.txt
(2)新建并编辑 flume-exec-hdfs.conf 文件
[huwei@hadoop101 jobs]$ vim flume-exec-hdfs.conf
添加如下内容
#Named
a1.sources = r1
a1.channels = c1
a1.sinks = k1 #Source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /opt/module/flume-1.9.0/jobs/tail.txt#Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100#Sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop101:9820/flume/%Y%m%d/%H
#上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a1.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a1.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a1.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a1.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a1.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a1.sinks.k1.hdfs.rollCount = 0#Bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
这里 Sink 的端口号是
9820,跟着教程走写的8020报错了,参考 flume 中sink用hdfs sink报拒绝连接错误hdfs-io
(3)开启 flume 监听端口
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/flume-exec-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
建议加上
-Dflume.root.logger=INFO,console,方便直观地观察
(4)向监控文件追加数据
[huwei@hadoop101 ~]$ cd /opt/module/flume-1.9.0/jobs/
[huwei@hadoop101 jobs]$ echo a >> tail.txt
[huwei@hadoop101 jobs]$ echo b >> tail.txt
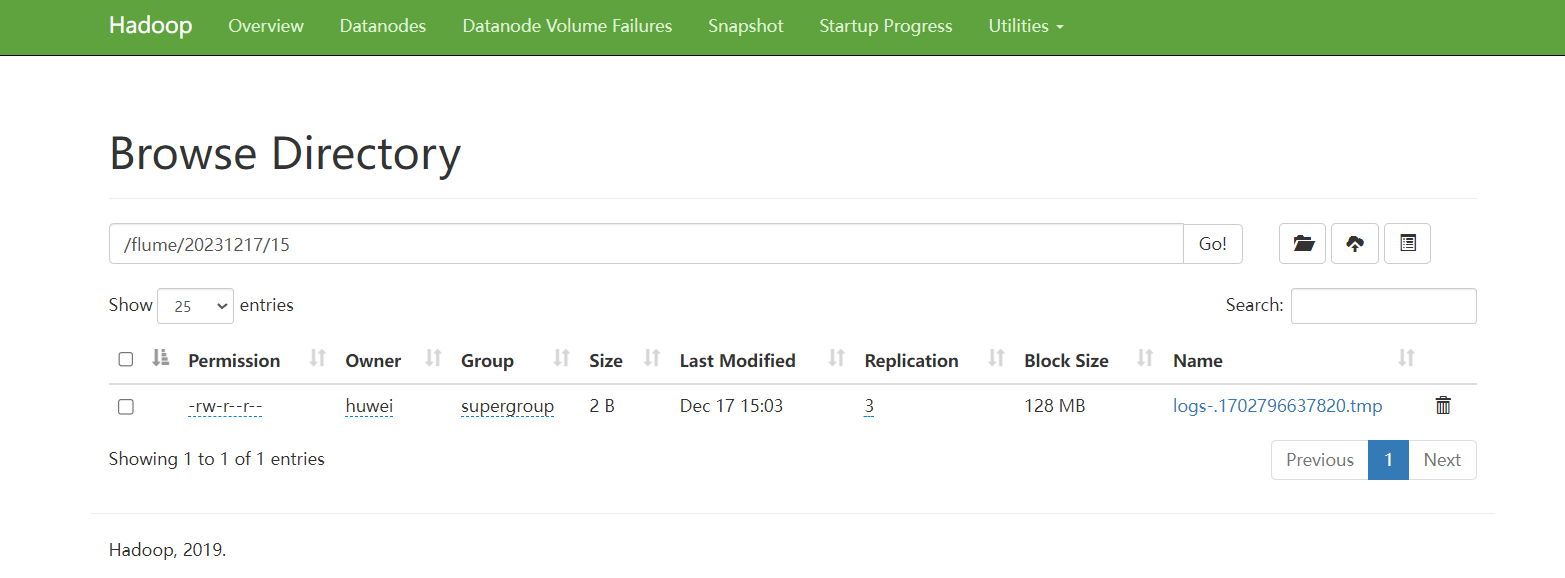
观察 hdfs 文件系统 http://hadoop101:9870
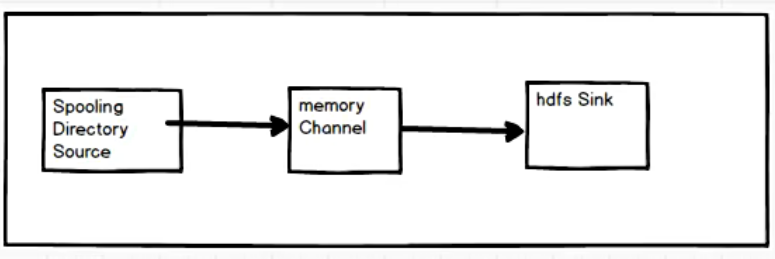
3.3 实时监控目录下多个新文件
案例需求
实时监控目录下多个新文件,并上传到 HDFS 。
需求分析
确定每一个组件的类型
实现步骤
(1)在 flume 目录下 jobs 文件夹下,新建一个要监控目录
[huwei@hadoop101 jobs]$ mkdir spooling
(2)新建并编辑 flume-spooling-hdfs.conf 文件
[huwei@hadoop101 jobs]$ vim flume-spooling-hdfs.conf
添加如下内容
#Named
a1.sources = r1
a1.channels = c1
a1.sinks = k1 #Source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /opt/module/flume-1.9.0/jobs/spooling
a1.sources.r1.fileSuffix = .COMPLETED
a1.sources.r1.ignorePattern = .*\.tmp # 忽略后缀名是.tmp的文件#Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100#Sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop101:9820/flume/%Y%m%d/%H
#上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a1.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a1.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a1.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a1.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a1.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a1.sinks.k1.hdfs.rollCount = 0#Bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(3)开启 flume 监听端口
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/flume-spooling-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
(4)新建文件向监控目录中逐个增加文件
[huwei@hadoop101 jobs]$ touch file1.txt
[huwei@hadoop101 jobs]$ touch file2.txt
[huwei@hadoop101 jobs]$ echo file1 > file1.txt
[huwei@hadoop101 jobs]$ echo file2 > file2.txt
[huwei@hadoop101 jobs]$ mv file1.txt ./spooling/
[huwei@hadoop101 jobs]$ mv file2.txt ./spooling/
观察 hdfs 文件系统 http://hadoop101:9870
(5)再去看 spooling 文件夹下的文件
文件已被添加后缀 .COMPLETED,用来区分是不是新文件,当添加的文件后缀本身就是.COMPLETED,flume 就不会认为它是新文件就不会采集
[huwei@hadoop101 jobs]$ cd spooling/
[huwei@hadoop101 spooling]$ ll
总用量 8
-rw-rw-r--. 1 huwei huwei 6 12月 17 15:20 file1.txt.COMPLETED
-rw-rw-r--. 1 huwei huwei 6 12月 17 15:20 file2.txt.COMPLETED
3.4 实时监控目录下的多个追加文件
案例需求
实时监控目录下多个追加文件,将内容上传到 HDFS 中。
需求分析
确定每一个组件的类型
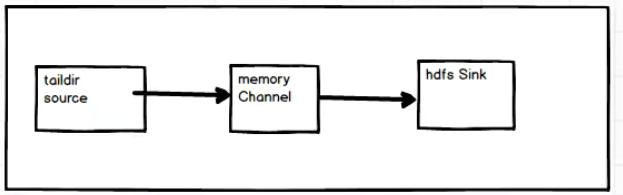
实现步骤
(1)在 flume 目录下 jobs 文件夹下,新建一个要监控目录,并在其中创建一些文件
[huwei@hadoop101 jobs]$ mkdir taildir
[huwei@hadoop101 jobs]$ cd taildir
[huwei@hadoop101 taildir]$ touch file1.txt
[huwei@hadoop101 taildir]$ touch file2.txt
[huwei@hadoop101 taildir]$ touch log1.log
[huwei@hadoop101 taildir]$ touch log2.log
(2)新建一个存放每一个文件所采集到数据的位置的文件夹
[huwei@hadoop101 jobs]$ mkdir position
(3)新建并编辑 flume-taildir-hdfs.conf 文件
[huwei@hadoop101 jobs]$ vim flume-taildir-hdfs.conf
添加如下内容
#Named
a1.sources = r1
a1.channels = c1
a1.sinks = k1 #Source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1 f2 # 将文件分组
a1.sources.r1.filegroups.f1 = /opt/module/flume-1.9.0/jobs/taildir/.*\.txt # f1组负责监控.txt文件
a1.sources.r1.filegroups.f2 = /opt/module/flume-1.9.0/jobs/taildir/.*\.log # f2组负责监控.log文件
a1.sources.r1.positionFile = /opt/module/flume-1.9.0/jobs/position/position.json # 断点续传#Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100#Sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://hadoop101:9820/flume/%Y%m%d/%H
#上传文件的前缀
a1.sinks.k1.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a1.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a1.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a1.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a1.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a1.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a1.sinks.k1.hdfs.rollInterval = 60
#设置每个文件的滚动大小
a1.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a1.sinks.k1.hdfs.rollCount = 0#Bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(4)开启 flume 监听端口
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/flume-taildir-hdfs.conf -n a1 -Dflume.root.logger=INFO,console
(5)开始逐个往监控目录中的文件中追加数据
[huwei@hadoop101 taildir]$ echo file1 > file1.txt
[huwei@hadoop101 taildir]$ echo file2 > file2.txt
[huwei@hadoop101 taildir]$ echo log1 > log1.log
[huwei@hadoop101 taildir]$ echo log2 > log2.log
观察 hdfs 文件系统 http://hadoop101:9870
(6)查看 position.json 文件
[huwei@hadoop101 position]$ cat position.json
{"inode":535145,"pos":6,"file":"/opt/module/flume-1.9.0/jobs/taildir/file1.txt"},
{"inode":535146,"pos":6,"file":"/opt/module/flume-1.9.0/jobs/taildir/file2.txt"},
{"inode":535147,"pos":5,"file":"/opt/module/flume-1.9.0/jobs/taildir/log1.log"},
{"inode":535148,"pos":5,"file":"/opt/module/flume-1.9.0/jobs/taildir/log2.log"}
Taildir Source 维护了一个 json 格式的 position File,其会定期的往 position File 中更新每个文件读取到的最新的位置,因此能够实现断点续传。
注意:Linux中储存文件元数据的区域就叫做 inode,每个 inode 都有一个号码,操作系统用 inode 号码来识别不同的文件,Unix/Linux 系统内部不使用文件名,而使用 inode 号码来识别文件。
4 Flume 进阶
4.1 Flume 事务
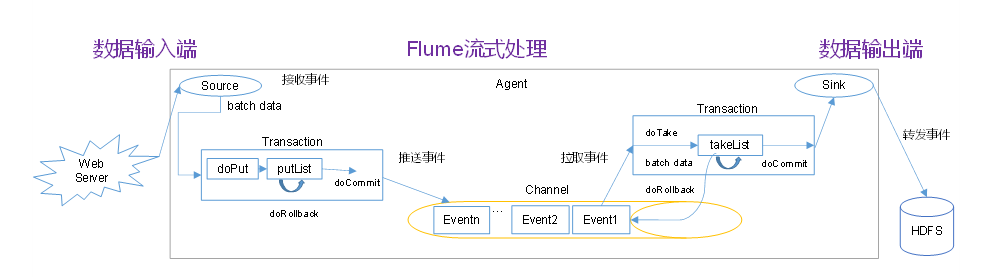
Put 事务流程
- doPut:将批数据先写入临时缓冲区 putList
- doCommit:检查channel 内存队列是否足够
- doRollback:channel 内存队列空间不足,回滚数据(把数据直接丢掉,给Source端抛出异常,Source端会重新采集这一批数据)
Take 事务
- doTake:将数据提取到临时缓冲区 takeList,并将数据发送到 HDFS
- doCommit:如果数据全部发送成功,则清除临时缓冲区 takeList
- doRollback:数据发送过程中如果出现异常,回滚数据,将临时缓冲区 takeList 中的数据归还给 channel 内存队列(如果 takeList处理到一半出现异常,则可能会导致数据重复)
4.2 Flume Agent 内部原理
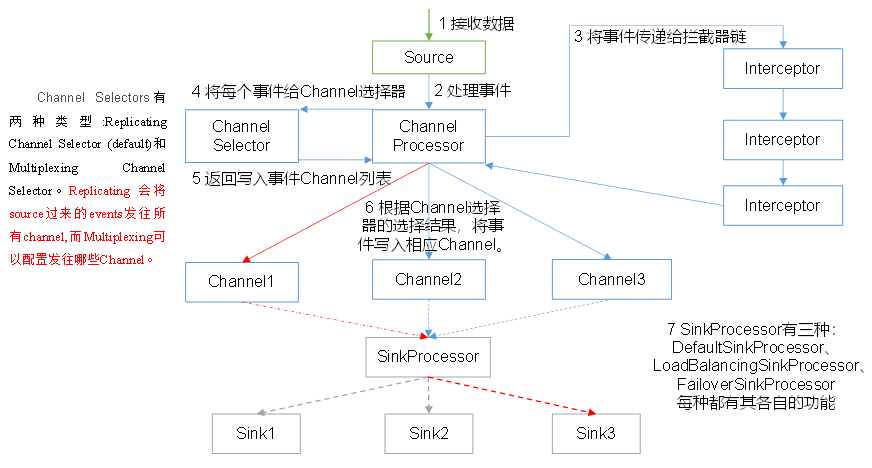
(1)Channel Selector
ChannelSelector 的作用就是选出 Event 将要被发往哪个 Channel。其共有两种类型,分别是 Replicating(复制)和 Multiplexing(多路复用)。
ReplicatingChannelSelector(默认)会将同一个 Event 发往所有的 ChannelMultiplexingChannelSelector会根据相应的原则,将不同的 Event 发往不同的 Channel。
(2)SinkProcessor
SinkProcessor 共有三种类型,分别是DefaultSinkProcessor、LoadBalancingSinkProcessor和 FailoverSinkProcessor
DefaultSinkProcessor(默认)对应的是单个的SinkLoadBalancingSinkProcessor和FailoverSinkProcessor对应的是Sink GroupLoadBalancingSinkProcessor可以实现负载均衡的功能FailoverSinkProcessor可以错误恢复的功能(对应单个的Sink,当该Sink出错,选择其他的Sink代替其工作)
4.3 Flume 拓扑结构
4.3.1 简单串联
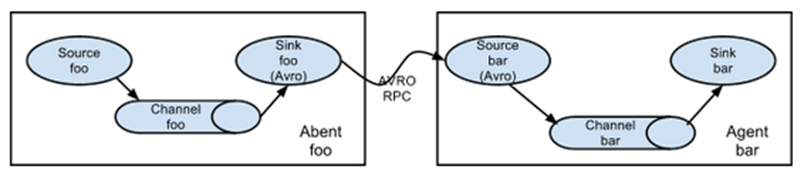
这种模式是将多个 flume 顺序连接起来了,从最初的 source 开始到最终 sink 传送的目的存储系统。
此模式不建议桥接过多的 flume 数量, flume 数量过多不仅会影响传输速率,而且一旦传输过程中某个节点 flume 宕机,会影响整个传输系统。
上游的是客户端,下游的是服务端,所有启动的时候,先启动下游的服务端
简单串联的结构我们一般不用
4.3.2 复制和多路复用
单source,多channel、sink
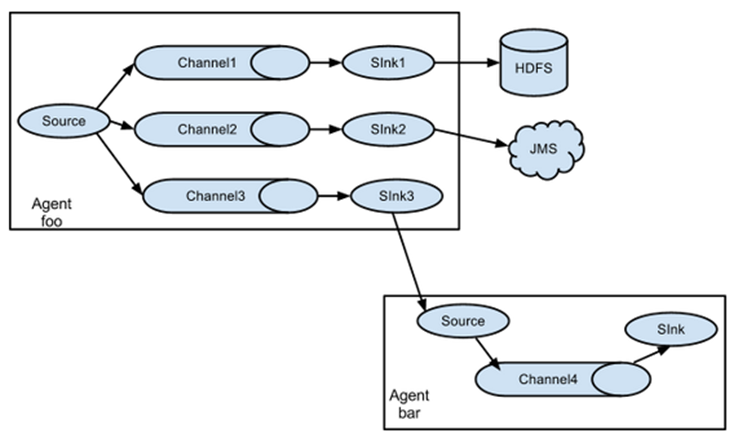
Flume 支持将事件流向一个或者多个目的地。这种模式可以将相同数据复制到多个channel 中,或者将不同数据分发到不同的 channel 中,sink 可以选择传送到不同的目的地。
4.3.3 负载均衡和故障转移
Flume负载均衡或故障转移
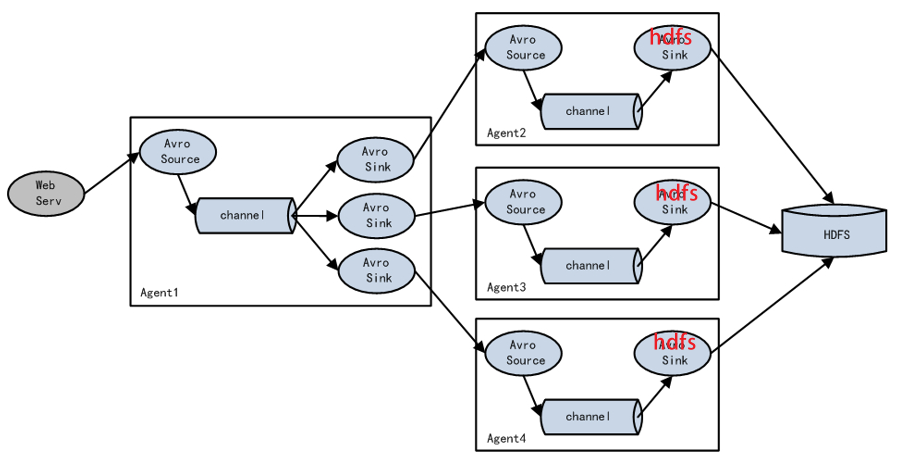
Flume 支持使用将多个 sink 逻辑上分到一个 sink 组,sink 组配合不同的 SinkProcessor 可以实现负载均衡和错误恢复的功能。
4.3.4 聚合
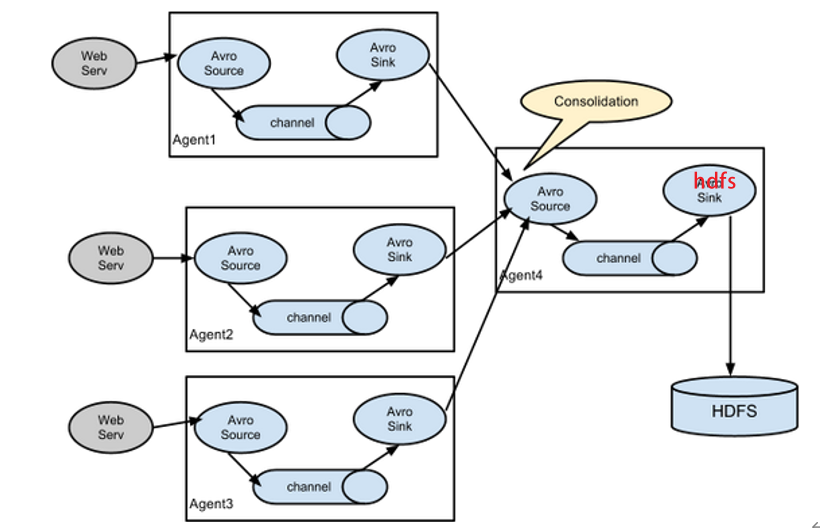
这种模式是我们最常见的,也非常实用,日常 web 应用通常分布在上百个服务器,大者甚至上千个、上万个服务器。产生的日志,处理起来也非常麻烦。用 flume 的这种组合方式能很好的解决这一问题,每台服务器部署一个 flume 采集日志,传送到一个集中收集日志的 flume,再由此 flume 上传到 hdfs、hive、hbase 等,进行日志分析。
4.4 企业开发案例
4.4.1 复制
案例需求
使用 Flume-1 监控文件变动,Flume-1 将变动内容传递给 Flume-2,Flume-2 负责存储到 HDFS。同时 Flume-1 将变动内容传递给 Flume-3,Flume-3 负责输出到 Local FileSystem。
需求分析
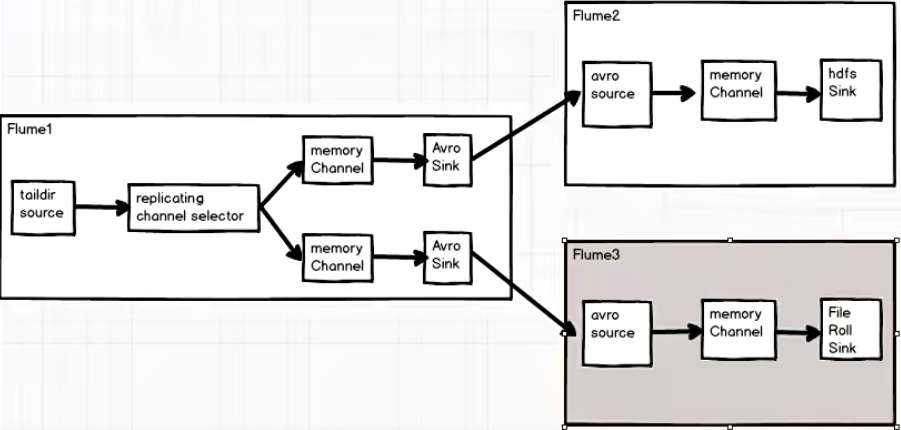
实现步骤
(1)在 flume 目录的 jobs 文件夹下 fileroll 文件夹作为 flume3 写入本地文件系统重的路径
[huwei@hadoop101 ~]$ cd /opt/module/flume-1.9.0/jobs
[huwei@hadoop101 jobs]$ mkdir fileroll
(2)在 flume 目录的 jobs 文件夹下创建 replication 文件夹
[huwei@hadoop101 jobs]$ mkdir replication
[huwei@hadoop101 jobs]$ cd replication
(3)在replication 文件夹中新建并编辑配置文件
flume1.conf
[huwei@hadoop101 replication]$ vim flume1.conf
添加如下内容
#Named
a1.sources = r1
a1.channels = c1 c2
a1.sinks = k1 k2#Source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/flume-1.9.0/jobs/taildir/.*\.txt
a1.sources.r1.positionFile = /opt/module/flume-1.9.0/jobs/position/position.json#channel selector
a1.sources.r1.selector.type = replicating#Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100a1.channels.c2.type = memory
a1.channels.c2.capacity = 10000
a1.channels.c2.transactionCapacity = 100#Sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = localhost
a1.sinks.k1.port = 7777a1.sinks.k2.type = avro
a1.sinks.k2.hostname = localhost
a1.sinks.k2.port = 8888#Bind
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
flume2.conf
[huwei@hadoop101 replication]$ vim flume2.conf
添加如下内容
a2.sources = r1
a2.channels = c1
a2.sinks = k1 #Source
a2.sources.r1.type = avro
a2.sources.r1.bind = localhost
a2.sources.r1.port = 7777#Channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 10000
a2.channels.c1.transactionCapacity = 100#Sink
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://hadoop101:9820/flume/%Y%m%d/%H
a2.sinks.k1.hdfs.filePrefix = logs-
a2.sinks.k1.hdfs.round = true
a2.sinks.k1.hdfs.roundValue = 1
a2.sinks.k1.hdfs.roundUnit = hour
a2.sinks.k1.hdfs.useLocalTimeStamp = true
a2.sinks.k1.hdfs.batchSize = 100
a2.sinks.k1.hdfs.fileType = DataStream
a2.sinks.k1.hdfs.rollInterval = 60
a2.sinks.k1.hdfs.rollSize = 134217700
a2.sinks.k1.hdfs.rollCount = 0#Bind
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
flume3.conf
[huwei@hadoop101 replication]$ vim flume3.conf
添加如下内容
#Named
a3.sources = r1
a3.channels = c1
a3.sinks = k1 #Source
a3.sources.r1.type = avro
a3.sources.r1.bind = localhost
a3.sources.r1.port = 8888#Channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 10000
a3.channels.c1.transactionCapacity = 100#Sink
a3.sinks.k1.type = file_roll
a3.sinks.k1.sink.directory = /opt/module/flume-1.9.0/jobs/fileroll#Bind
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
(4)启动 flume
开启三个 shell 窗口,分别启动 flume3、flume2、flume1
注意先启动下游后启动上游
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/replication/flume3.conf -n a3 -Dflume.root.logger=INFO,console
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/replication/flume2.conf -n a2 -Dflume.root.logger=INFO,console
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/replication/flume1.conf -n a1 -Dflume.root.logger=INFO,console
(5)向 Flume-1 的监控文件中追加内容
[huwei@hadoop101 ~]$ cd /opt/module/flume-1.9.0/jobs/taildir/
[huwei@hadoop101 taildir]$ echo abcdef >> file1.txt
[huwei@hadoop101 taildir]$ echo 123456 >> file2.txt
(6)查看 flume2、flume3 的输出
观察 hdfs 文件系统 http://hadoop101:9870
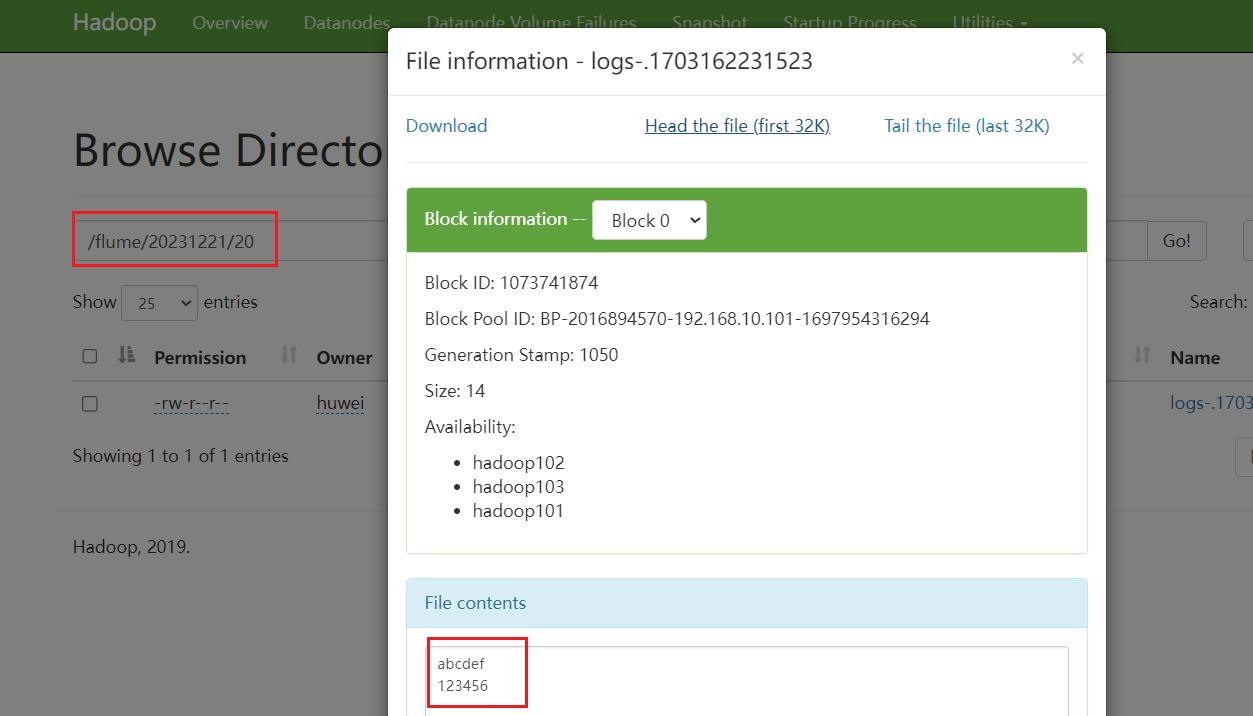
观察本地文件系统
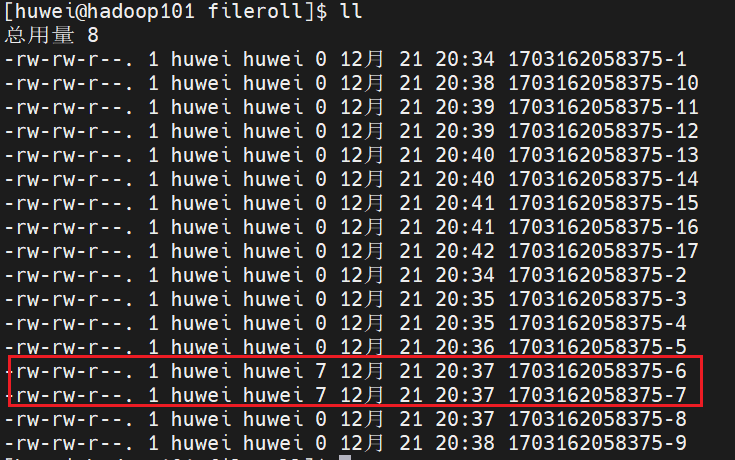
每隔30秒就会生成新的文件(不管有没有新的数据)
4.4.2 负载均衡
案例需求
Flume1 监控端口数据,将监控到的内容通过轮询或者随机的方式给到Flume2、Flume3,Flume2、Flume3 将内容打印到控制台
需求分析
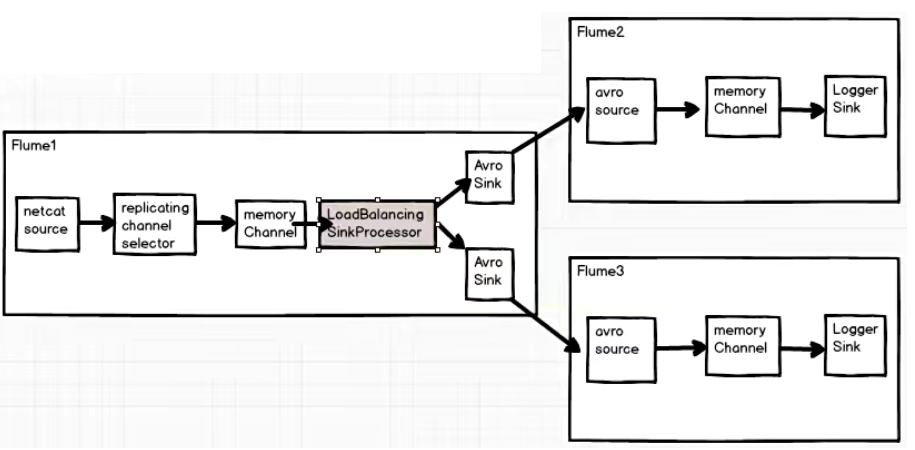
实现步骤
(1)在 flume 目录的 jobs 文件夹下创建 loadbalance 文件夹
[huwei@hadoop101 jobs]$ mkdir loadbalance
(2)在 loadbalance 文件夹中新建并编辑配置文件
flume1.conf
[huwei@hadoop101 loadbalance]$ vim flume1.conf
添加如下内容
#Named
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2#Source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 6666#channel selector
a1.sources.r1.selector.type = replicating#Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100#Sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = localhost
a1.sinks.k1.port = 7777a1.sinks.k2.type = avro
a1.sinks.k2.hostname = localhost
a1.sinks.k2.port = 8888#Sink processor
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.selector = random #Bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
flume2.conf
[huwei@hadoop101 loadbalance]$ vim flume2.conf
添加如下内容
a2.sources = r1
a2.channels = c1
a2.sinks = k1 #Source
a2.sources.r1.type = avro
a2.sources.r1.bind = localhost
a2.sources.r1.port = 7777#Channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 10000
a2.channels.c1.transactionCapacity = 100#Sink
a2.sinks.k1.type = logger#Bind
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
flume3.conf
[huwei@hadoop101 loadbalance]$ vim flume3.conf
添加如下内容
#Named
a3.sources = r1
a3.channels = c1
a3.sinks = k1 #Source
a3.sources.r1.type = avro
a3.sources.r1.bind = localhost
a3.sources.r1.port = 8888#Channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 10000
a3.channels.c1.transactionCapacity = 100#Sink
a3.sinks.k1.type = logger#Bind
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
(3)启动 flume
开启三个 shell 窗口,分别启动 flume3、flume2、flume1
注意先启动下游后启动上游
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/loadbalance/flume3.conf -n a3 -Dflume.root.logger=INFO,console
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/loadbalance/flume2.conf -n a2 -Dflume.root.logger=INFO,console
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/loadbalance/flume1.conf -n a1 -Dflume.root.logger=INFO,console
(4)使用 netcat 工具向本机的 6666 端口发送内容
[huwei@hadoop101 loadbalance]$ nc localhost 6666

观察 flume2、flume3
4.4.3 故障转移
案例需求
Flume1 监控端口数据,将监控到的内容发送给 active 的 sink,Flume2、Flume3 将内容打印到控制台
需求分析
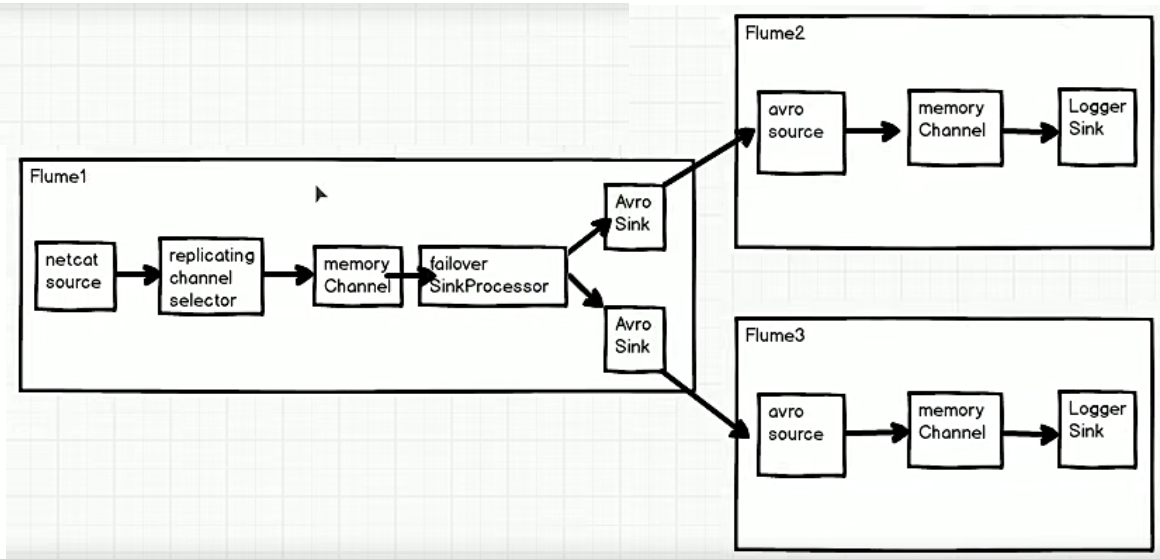
实现步骤
(1)在 flume 目录的 jobs 文件夹下创建 failover 文件夹
[huwei@hadoop101 jobs]$ mkdir failover
(2)在 failover 文件夹中新建并编辑配置文件
flume1.conf
[huwei@hadoop101 failover]$ vim flume1.conf
添加如下内容
#Named
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2#Source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 6666#channel selector
a1.sources.r1.selector.type = replicating#Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100#Sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = localhost
a1.sinks.k1.port = 7777a1.sinks.k2.type = avro
a1.sinks.k2.hostname = localhost
a1.sinks.k2.port = 8888#Sink processor
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10#Bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
sink 代表优先级的数字越大,其优先级就越高, 优先级高的就是那个 active 的 sink。这里设置 flume3 的优先级更高,即 flume3 的输入为 active 的 sink 输出
flume2.conf
[huwei@hadoop101 failover]$ vim flume2.conf
添加如下内容
a2.sources = r1
a2.channels = c1
a2.sinks = k1 #Source
a2.sources.r1.type = avro
a2.sources.r1.bind = localhost
a2.sources.r1.port = 7777#Channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 10000
a2.channels.c1.transactionCapacity = 100#Sink
a2.sinks.k1.type = logger#Bind
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
flume3.conf
[huwei@hadoop101 failover]$ vim flume3.conf
添加如下内容
#Named
a3.sources = r1
a3.channels = c1
a3.sinks = k1 #Source
a3.sources.r1.type = avro
a3.sources.r1.bind = localhost
a3.sources.r1.port = 8888#Channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 10000
a3.channels.c1.transactionCapacity = 100#Sink
a3.sinks.k1.type = logger#Bind
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
(3)启动 flume
开启三个 shell 窗口,分别启动 flume3、flume2、flume1
注意先启动下游后启动上游
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/failover/flume3.conf -n a3 -Dflume.root.logger=INFO,console
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/failover/flume2.conf -n a2 -Dflume.root.logger=INFO,console
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/failover/flume1.conf -n a1 -Dflume.root.logger=INFO,console
(4)使用 netcat 工具向本机的 6666 端口发送内容
[huwei@hadoop101 loadbalance]$ nc localhost 6666
可以发现只有 flume3 可以接收到发送的数据,当 flume3 故障后,再发送数据时,此时只有 flume2 可以接收到数据,再次启动 flume3 ,数据又要给到 flume3 了,因为其优先级更高。
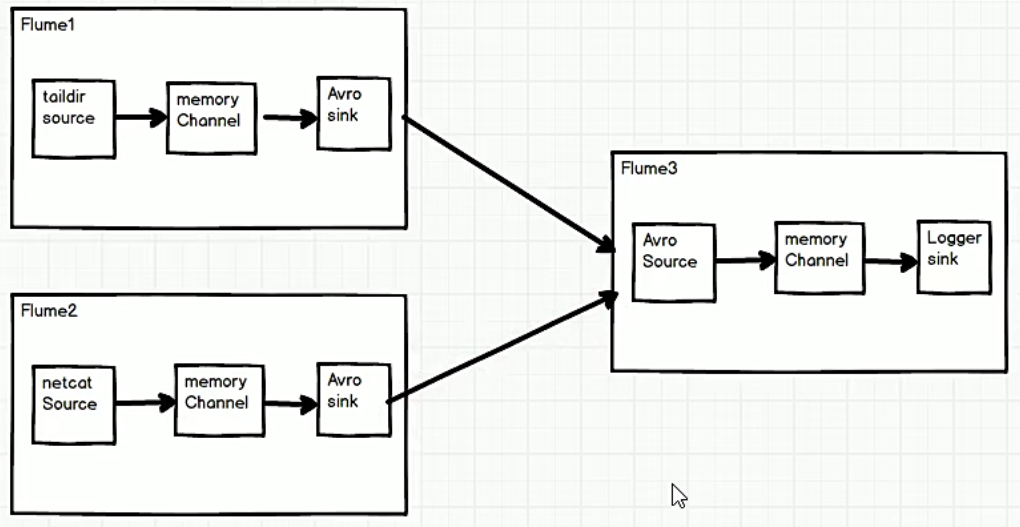
4.4.4 聚合
案例需求
Flume1 (hadoop101)监控文件内容,Flume2 (hadoop102)监控端口数据,Flume1 和 Flume 2 将监控到的数据发往 Flume3(hadoop103), Flume3 将内容打印到控制台。
需求分析
实现步骤
(1)在 flume 目录的 jobs 文件夹下创建 aggre 文件夹
[huwei@hadoop101 jobs]$ mkdir aggre
(2)在 failover 文件夹中新建并编辑配置文件
flume1.conf
[huwei@hadoop101 aggre]$ vim flume1.conf
添加如下内容
#Named
a1.sources = r1
a1.channels = c1
a1.sinks = k1#Source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/flume-1.9.0/jobs/taildir/.*\.txt
a1.sources.r1.positionFile = /opt/module/flume-1.9.0/jobs/position/position.json#Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100#Sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop103
a1.sinks.k1.port = 8888#Bind
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
flume2.conf
[huwei@hadoop101 aggre]$ vim flume2.conf
添加如下内容
a2.sources = r1
a2.channels = c1
a2.sinks = k1 #Source
a2.sources.r1.type = netcat
a2.sources.r1.bind = localhost
a2.sources.r1.port = 6666#Channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 10000
a2.channels.c1.transactionCapacity = 100#Sink
a2.sinks.k1.type = avro
a2.sinks.k1.hostname = hadoop103
a2.sinks.k1.port = 8888#Bind
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
flume3.conf
[huwei@hadoop101 aggre]$ vim flume3.conf
添加如下内容
#Named
a3.sources = r1
a3.channels = c1
a3.sinks = k1 #Source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop103
a3.sources.r1.port = 8888#Channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 10000
a3.channels.c1.transactionCapacity = 100#Sink
a3.sinks.k1.type = logger#Bind
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
(3)向其他机器分发 flume
[huwei@hadoop101 ~]$ xsync /opt/module/flume-1.9.0
这里使用的是大数据技术学习笔记(三)—— Hadoop 的运行模式中编写集群分发脚本
xsync
同时发送环境变量配置
[huwei@hadoop101 ~]$ sudo xsync /etc/profile.d/my_env.sh
使得环境变量生效
[huwei@hadoop102 ~]$ source /etc/profile
[huwei@hadoop103 ~]$ source /etc/profile
(3)启动 flume
在 hadoop103、hadoop102、hadoop101,分别启动 flume3、flume2、flume1
注意先启动下游后启动上游
[huwei@hadoop103 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/aggre/flume3.conf -n a3 -Dflume.root.logger=INFO,console
[huwei@hadoop102 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/aggre/flume2.conf -n a2 -Dflume.root.logger=INFO,console
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/aggre/flume1.conf -n a1 -Dflume.root.logger=INFO,console
后续测试同前文,不再赘述
4.5 自定义 Interceptor
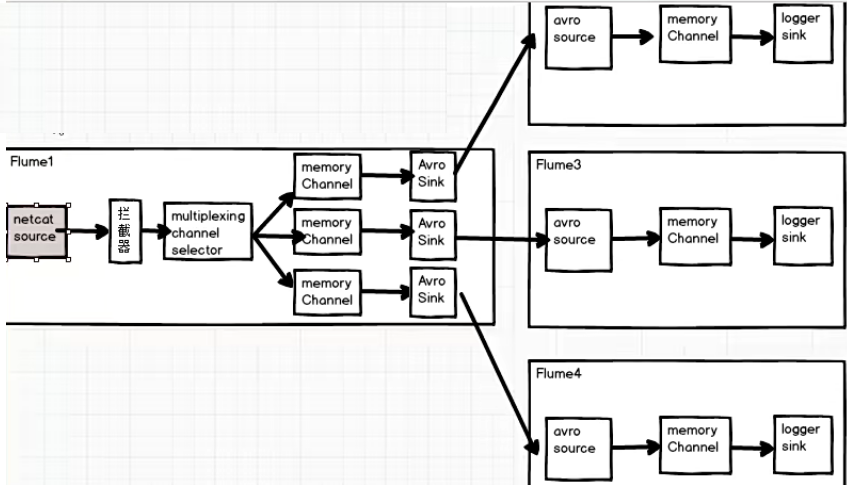
案例需求
Flume1 监控端口数据,将监控到的数据发往 Flume2 、Flume3 、Flume4 ,包含“flume”的数据发往 Flume2,包含“hadoop”的数据发往 Flume 3,其他的数据发往Flume 4
需求分析
在实际的开发中,一台服务器产生的日志类型可能有很多种,不同类型的日志可能需要发送到不同的分析系统。此时会用到 Flume 拓扑结构中的 Multiplexing 结构,Multiplexing 的原理是,根据 event 中 Header 的某个 key 的值,将不同的event 发送到不同的 Channel 中,所以我们需要 自定义一个 Interceptor,为不同类型的 event 的 Header 中的 key 赋予不同的值。
实现步骤
(1)创建一个 maven 项目,并引入以下依赖。
<dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.9.0</version>
</dependency>
(2)定义 CustomInterceptor 类并实现 Interceptor 接口,然后再定义一个静态内部类用来返回自定义的拦截器对象
public class CustomInterceptor implements Interceptor {@Overridepublic void initialize() {}/*** 一个event的处理*/@Overridepublic Event intercept(Event event) {// 1. 获取event的headersMap<String, String> headers = event.getHeaders();// 2. 获取event的bodyString body = new String(event.getBody());// 3. 判断event的body中是否包含"flume"、"hadoop"if (body.contains("flume")){headers.put("title","flume");}else if (body.contains("hadoop")){headers.put("title","hadoop");}return event;}/*** 迭代每一个event进行处理*/@Overridepublic List<Event> intercept(List<Event> events) {for (Event event : events) {intercept(event);}return events;}@Overridepublic void close() {}/*** 定义一个静态内部类用来返回自定义的拦截器对象*/public static class MyBuilder implements Builder{@Overridepublic Interceptor build() {return new CustomInterceptor();}@Overridepublic void configure(Context context) {}}
}
(3)package 打成 jar 包
(4)将打好的 jar 包上传到 flume 目录下的 lib 文件夹下
(5)在 flume 目录的 jobs 文件夹下创建 multi 文件夹
[huwei@hadoop101 jobs]$ mkdir multi
(6)在 multi 文件夹中新建并编辑配置文件
flume1.conf
[huwei@hadoop101 multi]$ vim flume1.conf
添加如下内容
#Named
a1.sources = r1
a1.channels = c1 c2 c3
a1.sinks = k1 k2 k3#Source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 5555#channel selector
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = title
a1.sources.r1.selector.mapping.flume = c1
a1.sources.r1.selector.mapping.hadoop = c2
a1.sources.r1.selector.default = c3# Interceptor
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.huwei.flume.CustomInterceptor$MyBuilder#Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 100a1.channels.c2.type = memory
a1.channels.c2.capacity = 10000
a1.channels.c2.transactionCapacity = 100a1.channels.c3.type = memory
a1.channels.c3.capacity = 10000
a1.channels.c3.transactionCapacity = 100#Sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = localhost
a1.sinks.k1.port = 6666a1.sinks.k2.type = avro
a1.sinks.k2.hostname = localhost
a1.sinks.k2.port = 7777a1.sinks.k3.type = avro
a1.sinks.k3.hostname = localhost
a1.sinks.k3.port = 8888#Bind
a1.sources.r1.channels = c1 c2 c3
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
a1.sinks.k3.channel = c3
flume2.conf
[huwei@hadoop101 failover]$ vim flume2.conf
添加如下内容
a2.sources = r1
a2.channels = c1
a2.sinks = k1 #Source
a2.sources.r1.type = avro
a2.sources.r1.bind = localhost
a2.sources.r1.port = 6666#Channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 10000
a2.channels.c1.transactionCapacity = 100#Sink
a2.sinks.k1.type = logger#Bind
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
flume3.conf
[huwei@hadoop101 multi]$ vim flume3.conf
添加如下内容
#Named
a3.sources = r1
a3.channels = c1
a3.sinks = k1 #Source
a3.sources.r1.type = avro
a3.sources.r1.bind = localhost
a3.sources.r1.port = 7777#Channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 10000
a3.channels.c1.transactionCapacity = 100#Sink
a3.sinks.k1.type = logger#Bind
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
flume4.conf
[huwei@hadoop101 multi]$ vim flume4.conf
添加如下内容
#Named
a4.sources = r1
a4.channels = c1
a4.sinks = k1 #Source
a4.sources.r1.type = avro
a4.sources.r1.bind = localhost
a4.sources.r1.port = 8888#Channel
a4.channels.c1.type = memory
a4.channels.c1.capacity = 10000
a4.channels.c1.transactionCapacity = 100#Sink
a4.sinks.k1.type = logger#Bind
a4.sources.r1.channels = c1
a4.sinks.k1.channel = c1
(7)启动 Flume
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/multi/flume4.conf -n a4 -Dflume.root.logger=INFO,console
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/multi/flume3.conf -n a3 -Dflume.root.logger=INFO,console
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/multi/flume2.conf -n a2 -Dflume.root.logger=INFO,console
[huwei@hadoop101 ~]$ flume-ng agent -c $FLUME_HOME/conf -f $FLUME_HOME/jobs/multi/flume1.conf -n a1 -Dflume.root.logger=INFO,console
(8)发送数据
输入要发送的数据进行测试
[huwei@hadoop101 ~]$ nc localhost 5555
4.6 自定义 Source
Source 是负责接收数据到 Flume Agent 的组件。Source 组件可以处理各种类型、各种格式的日志数据,包括 avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。官方提供的 source 类型已经很多,但是有时候并不能满足实际开发当中的需求,此时我们就需要根据实际需求自定义某些source。
4.7 自定义 Sink
Sink 不断地轮询 Channel 中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个 Flume Agent。
Sink 是完全事务性的。在从 Channel 批量删除数据之前,每个 Sink 用 Channel 启动一个事务。批量事件一旦成功写出到存储系统或下一个 Flume Agent,Sink 就利用 Channel 提交事务。事务一旦被提交,该 Channel 从自己的内部缓冲区删除事件。
Sink组件目的地包括 hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义。官方提供的Sink类型已经很多,但是有时候并不能满足实际开发当中的需求,此时我们就需要根据实际需求自定义某些 Sink。
4.8 Flume 数据流监控
4.8.1 Ganglia 的安装与部署
Ganglia 由gmond、gmetad 和 gweb 三部分组成。
- gmond(Ganglia Monitoring Daemon)是一种轻量级服务,安装在每台需要收集指标数据的节点主机上。使用 gmond,你可以很容易收集很多系统指标数据,如CPU、内存、磁盘、网络和活跃进程的数据等。
- gmetad(Ganglia Meta Daemon)整合所有信息,并将其以 RRD 格式存储至磁盘的服务。
- gweb(Ganglia Web)Ganglia 可视化工具,gweb 是一种利用浏览器显示gmetad 所存储数据的PHP前端。在 Web 界面中以图表方式展现集群的运行状态下收集的多种不同指标数据。
(1)集群规划
hadoop101:gweb gmetad gmod
hadoop102:gmod
hadoop103:gmod
(2)在101 102 103 分别安装 epel-release
[huwei@hadoop101 ~]$ sudo yum -y install epel-release
[huwei@hadoop102 ~]$ sudo yum -y install epel-release
[huwei@hadoop103 ~]$ sudo yum -y install epel-release
(3)在101安装
[huwei@hadoop101 ~]$ sudo yum -y install ganglia-gmetad
[huwei@hadoop101 ~]$ sudo yum -y install ganglia-web
[huwei@hadoop101 ~]$ sudo yum -y install ganglia-gmond
(4)在102 和 103 安装
[huwei@hadoop102 ~]$ sudo yum -y install ganglia-gmond
[huwei@hadoop103 ~]$ sudo yum -y install ganglia-gmond
(5)在101修改配置文件 /etc/httpd/conf.d/ganglia.conf
[huwei@hadoop101 ~]$ sudo vim /etc/httpd/conf.d/ganglia.conf
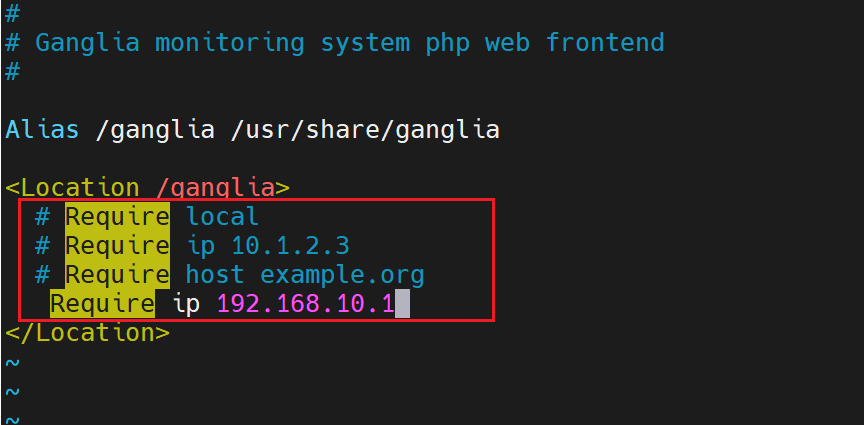
通过windows访问ganglia,需要配置Linux对应的主机(windows)ip地址,这里需要根据自己的电脑 ip 来配置
(6)在 101 修改配置文件 /etc/ganglia/gmetad.conf
[huwei@hadoop101 ~]$ sudo vim /etc/ganglia/gmetad.conf
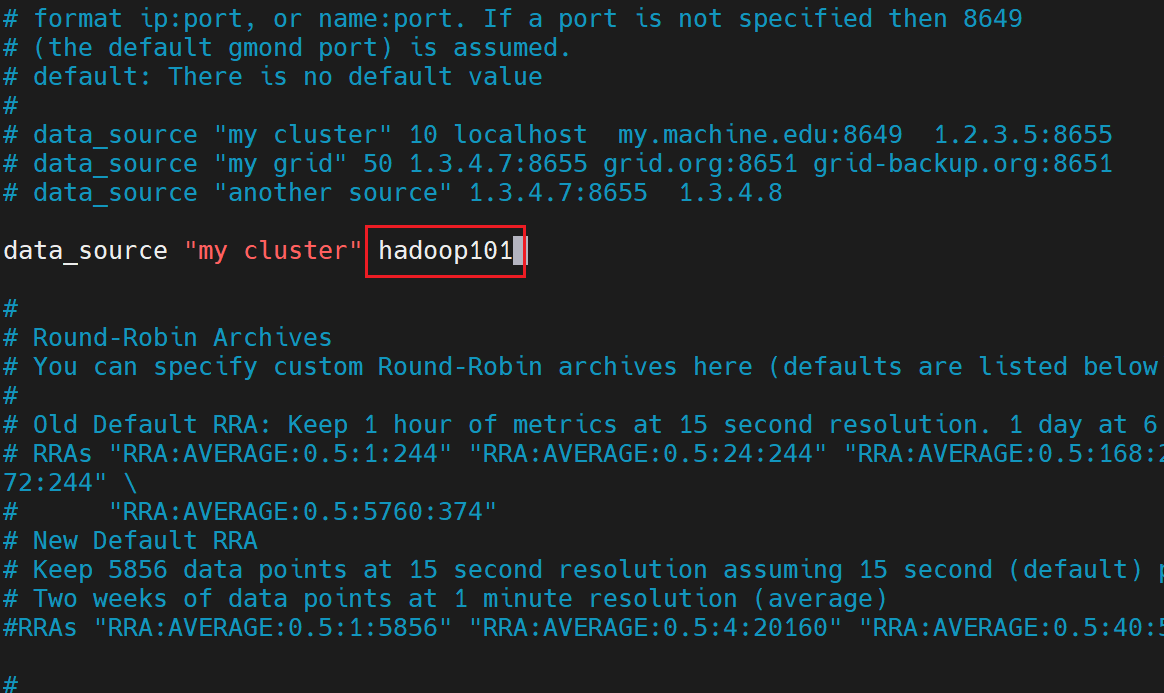
同时注意集群名称“my cluster”
(7)在101 102 103 修改配置文件 /etc/ganglia/gmond.conf
[huwei@hadoop101 ~]$ sudo vim /etc/ganglia/gmond.conf
[huwei@hadoop102 ~]$ sudo vim /etc/ganglia/gmond.conf
[huwei@hadoop103 ~]$ sudo vim /etc/ganglia/gmond.conf
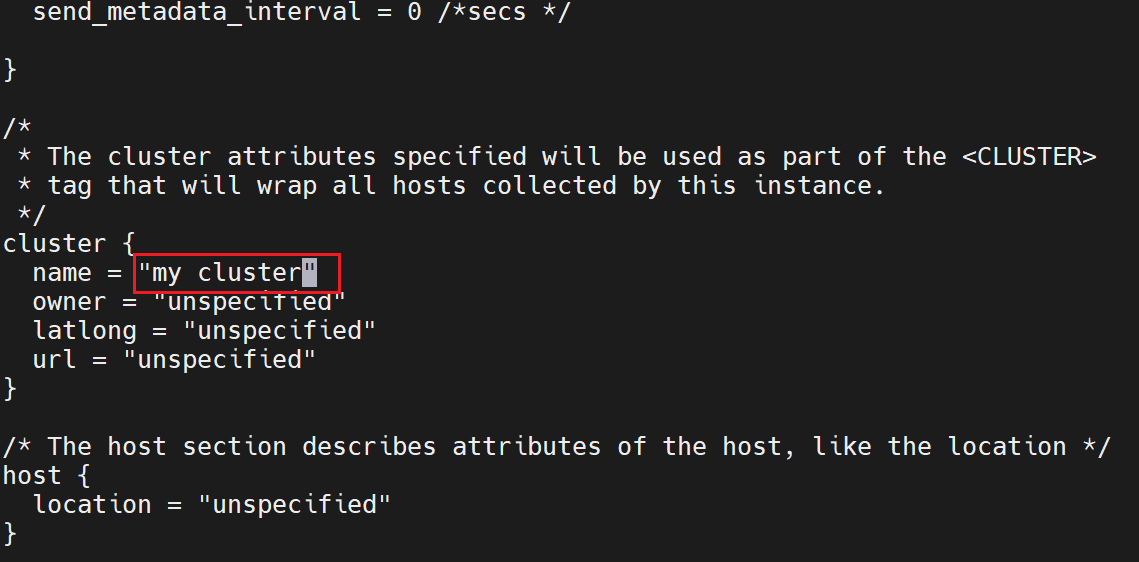
数据发送给 hadoop101
接收来自任意连接的数据
(8)在101 修改配置文件 /etc/selinux/config
[huwei@hadoop101 ~]$ sudo vim /etc/selinux/config
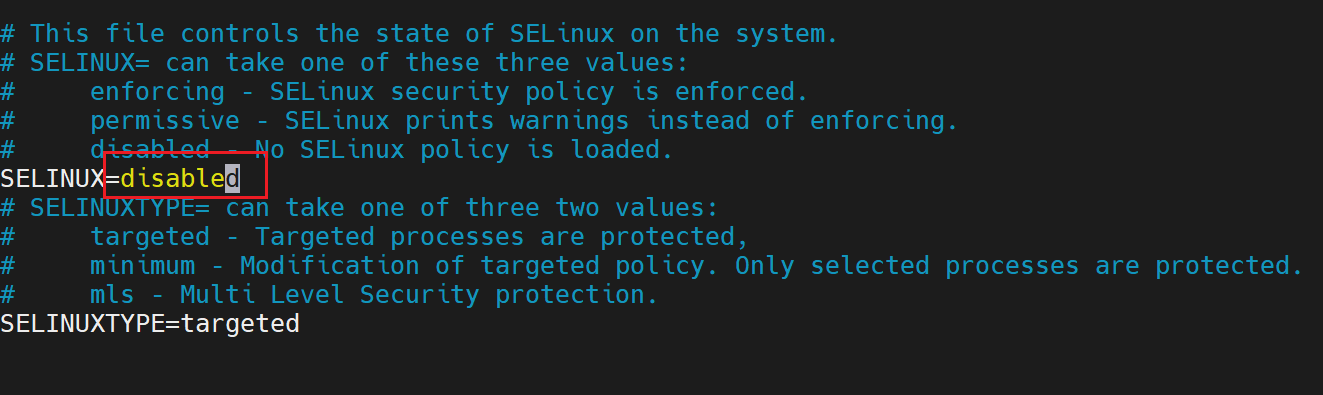
selinux 本次生效关闭必须重启,如果此时不想重启,可以临时生效之
sudo setenforce 0
(9)启动 ganglia
在101 102 103 启动
[huwei@hadoop101 ~]$ sudo systemctl start gmond
[huwei@hadoop102 ~]$ sudo systemctl start gmond
[huwei@hadoop103 ~]$ sudo systemctl start gmond
查看服务状态
systemctl status gmond
在101 启动
[huwei@hadoop101 ~]$ sudo systemctl start httpd
[huwei@hadoop101 ~]$ sudo systemctl start gmetad
(10)打开网页浏览 ganglia 页面
http://hadoop101/ganglia
4.8.2 操作 Flume 测试监控
(1)启动 flume
[huwei@hadoop101 ~]$ flume-ng agent \
> -c $FLUME_HOME/conf \
> -n a1 \
> -f $FLUME_HOME/jobs/flume-netcat-logger.conf \
> -Dflume.root.logger=INFO,console \
> -Dflume.monitoring.type=ganglia \
> -Dflume.monitoring.hosts=hadoop101:8649
(2)发送数据,观察 web 界面变化
[huwei@hadoop101 ~]$ nc localhost 6666
相关文章:
大数据技术学习笔记(十一)—— Flume
目录 1 Flume 概述1.1 Flume 定义1.2 Flume 基础架构 2 Flume 安装3 Flume 入门案例3.1 监控端口数据3.2 实时监控单个追加文件3.3 实时监控目录下多个新文件3.4 实时监控目录下的多个追加文件 4 Flume 进阶4.1 Flume 事务4.2 Flume Agent 内部原理4.3 Flume 拓扑结构4.3.1 简单…...

电路设计时,继电器线圈、风扇电机绕组等感性负载必须有续流二极管。
续流二极管(也常被称为“自由轮流二极管”或“反向并联二极管”)在感性负载电路中的应用非常重要,尤其是在继电器线圈、风扇电机绕组等设备中。感性负载是指那些在其线圈中会产生感应电动势的负载,例如电动机、变压器和继电器等。当这些设备的电源被切断时,它们的线圈会因…...
Mongodb基础介绍与应用场景
NoSql 解决方案第二种 Mongodb MongoDB 是一款开源 高性能 无模式的文档型数据库 当然 它是NoSql数据库中的一种 是最像关系型数据库的 非关系型数据库 首先 最需要注意的是 无模式的文档型数据库 这个需要后面我们看到它的数据才能明白 其次是 最像关系型数据库的非关系型数据…...

mysql参数配置binlog
官网地址: MySQL :: MySQL Replication :: 2.6.4 Binary Logging Options and Variables 欢迎关注留言,我是收集整理小能手,工具翻译,仅供参考,笔芯笔芯. MySQL 复制 / ... / 二进制日志记录选项和变量 2.6.4 二进…...

pytorch常用的几个函数详解
文章目录 view基本用法自动计算维度保持原始数据不变 t函数功能语法返回值示例注意事项 permute() 函数基本概念permute() 函数的使用 unsqueeze() 函数基本概念unsqueeze() 函数的使用 squeeze() 函数基本概念squeeze() 函数的使用 transpose() 函数基本概念transpose() 函数的…...

Linux下安装Flume
1 下载Flume Welcome to Apache Flume — Apache Flume 下载1.9.0版本 2 上传服务器并解压安装 3 删除lib目录下的guava-11.0.2.jar (如同服务器安装了hadoop,则删除,如没有安装hadoop则保留这个文件,否则无法启动flume&#…...

20231225使用BLE-AnalyzerPro WCH升级版BLE-PRO蓝牙分析仪抓取BLE广播数据
20231225使用BLE-AnalyzerPro WCH升级版BLE-PRO蓝牙分析仪抓取BLE广播数据 2023/12/25 20:05 结论:硬件蓝牙分析仪 不一定比 手机端的APK的效果好! 亿佰特E104-2G4U04A需要3片【单通道】,电脑端的UI为全英文的。 BLE-AnalyzerPro WCH升级版B…...
.net6使用Sejil可视化日志
(关注博主后,在“粉丝专栏”,可免费阅读此文) 之前介绍了这篇.net 5使用LogDashboard_.net 5logdashboard rootpath-CSDN博客 这篇文章将会更加的简单,最终的效果都是可视化日志。 在程序非常庞大的时候&…...
 : 大数据导出为insert)
mysql(51) : 大数据导出为insert
代码 import java.io.BufferedWriter; import java.io.File; import java.io.FileWriter; import java.math.BigDecimal; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.util.Objects;public class 大数据导出为insert {public …...

MFC查找错误的方法
在visual studio2005上Debug总是会出现各种问题,比如指针错误,乱码等,无法正确查看变量的值,这时候可以使用AfxMessageBox()方法对数据进行弹窗输出,但AfxMessageBox()函数只支持CString数据输出,我们就需要…...
Jave EE 网络原理之网络层与数据链路层
文章目录 1. 网络层1.1 IP 协议1.1.1 协议头格式1.1.2 地址管理1.1.2.1 认识 IP 地址 1.1.3 路由选择 2. 数据链路层2.1 认识以太网2.1.1 以太网帧格式2.1.2 DNS 应用层协议 1. 网络层 网络层要做的事情,主要是两个方面 地址管理 (制定一系列的规则&am…...

ElasticSearch 使用映射定义索引结构
动态映射 dynamic 可选值解释true默认值,启用动态映射,新增的字段会添加到映射中runtime查询时动态添加到映射中false禁用动态映射,忽略未知字段strict发现未知字段,抛出异常 显示映射 创建映射 PUT user {"mappings&qu…...

HTML---网页布局
目录 文章目录 一.常见的网页布局 二.标准文档流 标准文档流常见标签 三.display属性 四.float属性 总结 一.常见网页布局 二.标准文档流 标准文档流常见标签 标准文档流的组成 块级元素<div>、<p>、<h1>-<h6>、<ul>、<ol>等内联元素<…...
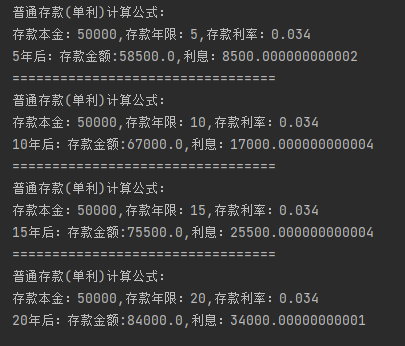
python 普通存款(单利)计算公式:
python 普通存款(单利)计算公式: 代码如下: #普通存款 单利计算公式:a:原值,n:计算年限,li:利率(小数), def danli(a,n,li):print("普通存款(单利)计…...

什么是 PHP 内存溢出 ?遇到了要如何解决呢 ?
PHP内存溢出指的是在PHP应用程序中,分配给脚本执行的内存超出了PHP配置文件中设置的限制。当脚本尝试使用比可用内存更多的内存时,就会发生内存溢出错误。 一、内存溢出可能由以下几个原因引起: 循环引用:如果存在循环引用&#…...
本地使用 docker 运行OpenSearch + Dashboard + IK 分词插件
准备基础镜像 注意一定要拉取和当前 IK 分词插件版本一致的 OpenSearch 镜像: https://github.com/aparo/opensearch-analysis-ik/releases 写这篇文章的时候 IK 最新版本 2.11.0, 而 dockerhub 上 OpenSearch 最新版是 2.11.1 如果版本不匹配的话是不能用的, 小版本号对不上…...
【JavaEE初阶一】线程的概念与简单创建
1. 认识线程(Thread) 1.1 关于线程 1.1.1 线程是什么 由前一节的内容可知,进程在进行频繁的创建和销毁的时候,开销比较大(主要体现在资源的申请和释放上),线程就是为了解决上述产生的问题而提…...
三叠云工程劳务管理,优化建筑施工管理,提升效率与质量
随着建筑行业的蓬勃发展,工程施工现场管理变得愈发复杂。传统的人员管理方式已经无法满足企业快速发展的需求。如何提高施工效率、优化人力资源管理成为了建筑企业亟待解决的问题。逐渐走向数字化的工程建设行业,急需一种足以匹配这一时代变革、高效管理…...

RocketMQ连接报错RemotingConnectException: connect to <192.168.57.129:9876>解决
文章目录 前言一、RocketMQ 连接报错处理1.1 报错信息1.2 修改 broker.conf 文件1.3 Linux 开放端口1.4 项目启动成功 前言 上一篇文章:基于SpringBoot整合RocketMQ异步发送短信功能在项目启动的过程中报了 RocketMQ 连接错误。针对这个问题,本文给予记…...

设计模式--桥接模式
实验9:桥接模式 本次实验属于模仿型实验,通过本次实验学生将掌握以下内容: 1、理解桥接模式的动机,掌握该模式的结构; 2、能够利用桥接模式解决实际问题。 [实验任务]:两个维度的桥接模式 用桥接模式…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

golang循环变量捕获问题
在 Go 语言中,当在循环中启动协程(goroutine)时,如果在协程闭包中直接引用循环变量,可能会遇到一个常见的陷阱 - 循环变量捕获问题。让我详细解释一下: 问题背景 看这个代码片段: fo…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

【学习笔记】深入理解Java虚拟机学习笔记——第4章 虚拟机性能监控,故障处理工具
第2章 虚拟机性能监控,故障处理工具 4.1 概述 略 4.2 基础故障处理工具 4.2.1 jps:虚拟机进程状况工具 命令:jps [options] [hostid] 功能:本地虚拟机进程显示进程ID(与ps相同),可同时显示主类&#x…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

JavaScript 数据类型详解
JavaScript 数据类型详解 JavaScript 数据类型分为 原始类型(Primitive) 和 对象类型(Object) 两大类,共 8 种(ES11): 一、原始类型(7种) 1. undefined 定…...
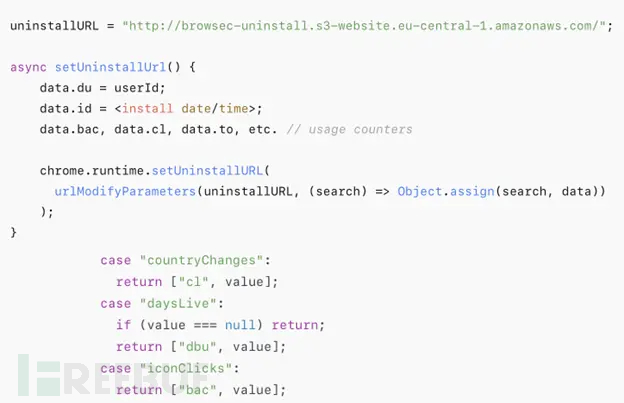
热门Chrome扩展程序存在明文传输风险,用户隐私安全受威胁
赛门铁克威胁猎手团队最新报告披露,数款拥有数百万活跃用户的Chrome扩展程序正在通过未加密的HTTP连接静默泄露用户敏感数据,严重威胁用户隐私安全。 知名扩展程序存在明文传输风险 尽管宣称提供安全浏览、数据分析或便捷界面等功能,但SEMR…...