(2021|CVPR,XMC-GAN,对比学习,注意力自调制)用于文本到图像生成的跨模态对比学习
Cross-Modal Contrastive Learning for Text-to-Image Generation
公众:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料)
目录
0. 摘要
1. 简介
2. 相关工作
3. 基础
4. 方法
4.1 用于文本到图像合成的对比损失
4.2 注意力自调制生成器
4.3 对比鉴别器
5. 评估
5.1 数据
5.2 评估指标
6. 实验
6.1 结果
6.2 消融
7. 结论
S. 总结
S.1 主要贡献
S.2 架构和方法
0. 摘要
文本到图像合成系统的输出应该是连贯、清晰、具有高语义保真度的照片逼真场景,与其条件文本描述相一致。我们的跨模态对比生成对抗网络(Cross-Modal Contrastive Generative Adversarial Network,XMC-GAN)通过最大化图像和文本之间的相互信息来应对这一挑战。它通过多个对比损失来捕捉跨模态和内部模态的对应关系。XMC-GAN 使用一种注意力自调制生成器,强化文本与图像的对应关系,以及一种对比鉴别器,既充当评论家又作为对比学习的特征编码器。XMC-GAN的输出质量明显优于先前的模型,如我们在三个具有挑战性的数据集上展示的。在 MS-COCO 上,XMC-GAN 不仅将最先进的 FID 从 24.70 提高到 9.33,而且更重要的是,人们更倾向于选择XMC-GAN,对于图像质量为 77.3%,对于图像文本对齐为 74.1%,相较于其他三个近期的模型。XMC-GAN 还推广到具有更长、更详细描述的具有挑战性的 Localized Narratives 数据集,将最先进的FID从 48.70 提高到 14.12。最后,我们在具有挑战性的 Open Images 数据上训练和评估XMC-GAN,建立了一个强大的基准 FID 分数为 26.91。
1. 简介
与其他类型的输入(例如素描和物体掩模)相比,描述性句子是一种直观且灵活的表达视觉概念以生成图像的方式。文本到图像合成的主要挑战在于从非结构化的描述中学习,并处理视觉和语言输入之间的不同统计属性。
生成对抗网络(GANs)[12] 使用了条件 GAN 的表述 [11] 在文本到图像生成方面取得了令人期待的结果[44,61,62]。AttnGAN [58] 提出了一个多阶段的细化框架,通过关注描述中的相关单词生成细致的细节。这些模型在单一领域数据集(例如鸟类 [56] 和花卉 [35])上生成高保真度的图像,但在包含许多对象的复杂场景(例如 MS-COCO [30] 中的场景)上表现困难。近期的方法[18,27,16,22] 提出了以对象驱动的层次化方法,明确地对图像中的对象实例进行建模。在给定文本描述的情况下,它们首先推断出一个语义布局(例如对象边界框、分割掩模或其组合),然后从布局生成图像。这些层次化方法在应用于现实场景时很繁琐;生成变成了一个多步骤的过程(从框到掩模到图像),模型需要更多精细的对象标签来训练。
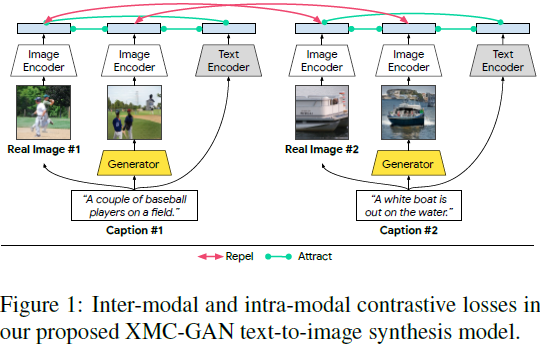
我们研究在文本到图像合成的背景下进行对比学习,并证明一个简单的一阶段 GAN 在没有对象级注释的情况下可以胜过先前的以对象为驱动和多阶段方法。除了生成逼真的图像外,我们还希望(1)图像应该整体上与描述相匹配;(2)当它们以相同描述为条件时,生成的图像应该与真实图像相匹配;(3)单个图像区域应该是可识别的,并与句子中的词语一致。为了实现这些愿望并实现强大的语言对齐,我们提出通过对比学习最大化相应对之间的相互信息的方法。我们的方法,跨模态对比生成对抗网络(XMC-GAN),使用图像到句子、图像区域到单词以及图像到图像的对比损失,以强化生成图像与其标题之间的对齐关系(图 1)。我们的主要贡献包括:
- 我们提出了 XMC-GAN,这是一个简单的一阶段 GAN,采用了几个对比损失。XMC-GAN 在先前的模型上取得了显著的改进,例如在 MSCOCO 上将 FID [15] 从 24.70 降至 9.33,在 LN-COCO(Localized Narratives [40] 的 MS-COCO 部分)上从 48.70 降至 14.12。
- 我们进行了彻底的人工评估,将 XMC-GAN 与三个近期模型进行比较。结果显示,77.3% 的人更喜欢 XMC-GAN 的图像逼真度,以及 74.1% 的人更喜欢其图像文本对齐性。
- 我们在具有挑战性的 LN-OpenImages(Localized Narratives 的 Open Images 子集)上建立了一个强大的基准。据我们所知,这是首次对 Open Images 的多样化图像和描述进行文本到图像结果的训练和测试。
- 我们对 XMC-GAN 中使用的对比损失进行了彻底的分析,为条件 GAN 中的对比学习提供了一般性的建模见解。
XMC-GAN 一贯产生比先前模型更连贯和详细的图像。除了更大的逼真度(具有更清晰、更明确的对象),它们更好地捕捉了完整的图像描述,包括命名对象的存在和背景组合。
2. 相关工作
文本到图像合成。文本到图像合成通过深度生成模型,包括 pixelCNN [55, 45]、近似 Langevin 采样 [34]、变分自动编码器(VAEs) [21, 13] 和生成对抗网络(GANs) [12, 44],得到了迅速改进。GAN-based 模型特别展示了更好的样本质量 [61, 64, 58, 66, 59, 26, 52, 42, 24]。GAN-INT-CLS [44] 是第一个使用条件 GAN 进行文本到图像生成的模型。StackGAN [61, 62] 通过渐进生成不同分辨率的图像的粗到细的框架,提高了高分辨率合成的质量。AttnGAN [58] 引入了跨模态注意力以更好地捕捉细节。DM-GAN [66] 通过一个内存模块自适应地完善生成的图像,该模块写入和读取文本和图像特征。MirrorGAN [43] 通过在生成的图像上进行标题生成来强化文本-图像一致性。SD-GAN [59] 提出了单词级条件 batch normalization 和双编码器结构,并使用三元损失来改善文本-图像对齐。与三元损失相比,我们的对比损失不需要寻找信息丰富的负例,因此降低了训练复杂性。CP-GAN [28] 提出了一个以对象为导向的图像编码器和细粒度鉴别器。它生成的图像获得了高 Inception Score [46];然而,我们展示了当用更强大的FID [15] 指标和人工评估进行评估时其性能较差(见 Sec. 6.1)。为了创建最终的高分辨率图像,这些方法依赖于多个生成器和鉴别器以在不同分辨率生成图像。其他人提出了明确在推断语义布局之后生成不同对象的分层模型 [18, 16, 22]。这些方法的缺点是它们需要细粒度的对象标签(例如对象边界框或分割地图),因此生成是一个多步骤的过程。与这些多阶段和多步骤的框架相比,我们提出的 XMC-GAN 只有一个单一的生成器和鉴别器进行端到端训练,并生成质量更高的图像。
对比学习及其在 GAN 中的应用。对比学习是一种强大的自监督表示学习方案 [36, 14, 5, 57]。它通过将正对和负对进行对比,强制在不同的增强下图像表示的一致性。在几个对抗训练场景下进行了探索 [25, 65, 9, 41]。Cntr-GAN [65] 在无条件图像生成中使用对比损失作为图像增强的正则化。ContraGAN [20] 探讨了类别条件图像生成的对比学习。DiscoFaceGAN [9] 引入对比学习以强化面部生成的解缠。CUT [39] 提出了基于补丁的对比学习,通过使用输入和输出图像中相同位置的正对来进行图像到图像的转换。与先前的工作不同,我们在文本到图像合成中使用了模态内(图像-图像)和跨模态(图像-文本和区域-单词)的对比学习(图 1)。
3. 基础
4. 方法
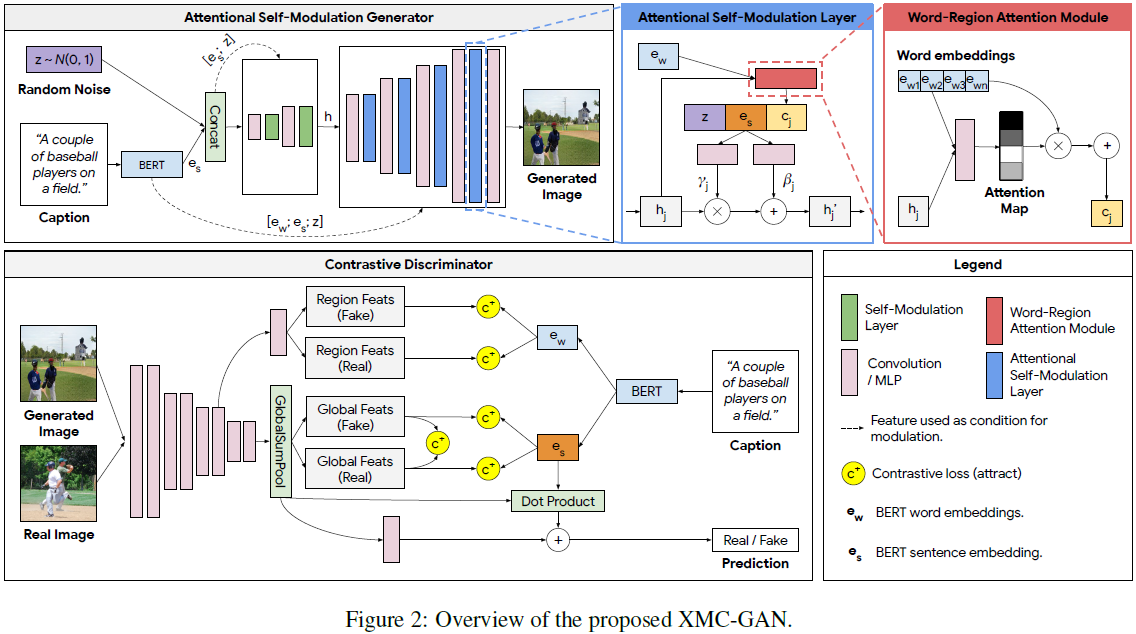
我们在下面描述 XMC-GAN 的损失和组件。请参见图 2。
4.1 用于文本到图像合成的对比损失
文本到图像合成是一项有条件的生成任务。生成的图像应该既逼真又与给定的描述对齐。为了实现这一目标,我们建议最大化相应对之间的相互信息:(1) 图像和句子,(2) 生成的图像和具有相同描述的真实图像,以及(3) 图像区域和单词。直接最大化相互信息是困难的(参见 Sec. 3.1),因此我们通过优化对比(即 InfoNCE)损失来最大化相互信息的下限。
图像-文本对比损失。给定图像 x 及其相应的描述 s,基于余弦相似度,我们定义得分函数,按照先前对比学习中的工作 [14, 5, 36] 进行:
![]()
并且 τ 表示一个温度超参数。f_img 是一个图像编码器,用于提取整体图像特征向量,而 f_sent 是一个句子编码器,用于提取全局句子特征向量。这将图像和句子的表示映射到一个共同的嵌入空间 R^D。图像 x_i 和其配对的句子 s_i 之间的对比损失计算如下:
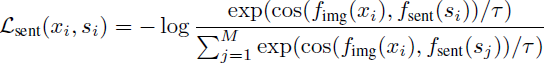
这种形式的对比损失也被称为归一化的温度缩放交叉熵损失(normalized temperature-scaled cross entropy loss,NT-Xent)[5]。
具有相同描述的生成图像和真实图像之间的对比损失。该损失也与 NT-Xent 有关。主要的区别在于共享的图像编码器 f'_img 提取了实际图像和生成图像的特征。两个图像之间的得分函数为 S_img(x, ~x) = cos(f'_img(x), f'_img(~x)) / τ。实际图像 x_i 和生成图像 G(z_i, s_i) 之间的图像-图像对比损失为:
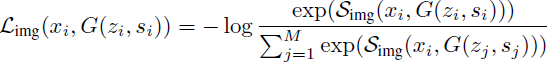
图像区域和单词之间的对比损失。各个图像区域应该与输入描述中对应的单词一致。我们使用注意力 [58] 来学习图像 x 中的区域与句子 s 中的单词之间的连接,而无需需要将单词和区域对齐的细粒度注释。首先,我们计算句子中所有单词与图像中所有区域之间的成对余弦相似性矩阵;然后,我们计算单词 w_i 对区域 r_j 的软注意力 α_i,j 如下:
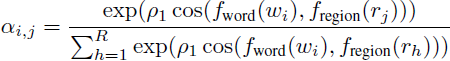
其中,f_word 和 f_region 分别代表单词和区域特征编码器,R 是图像中的总区域数,而 ρ_1 是一个用于减少软注意力熵的锐化超参数。第 i 个单词的对齐区域特征定义为
![]()
然后,图像 x 中所有区域与句子 s 中所有单词之间的得分函数可以定义为:
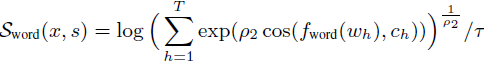
其中,T 是句子中的总单词数。 ρ_2 是一个超参数,用于确定最对齐的单词-区域对的权重,例如,当 ρ_2 → ∞ 时,得分函数近似为
![]()
最后,图像 x_i 中的单词和区域与其对齐的句子 s_i 之间的对比损失可以定义为:
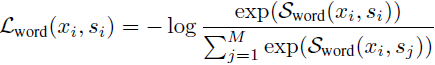
4.2 注意力自调制生成器
我们提出了一个一阶段的生成器,直接生成所需分辨率的图像。这比以前的多阶段生成器要简单得多,因为它们在多个不同的分辨率上创建图像。我们首先从标准的高斯分布中采样噪声 z。我们从预训练的 BERT [10] 模块中获得全局句子嵌入 e_s 和单词嵌入 e_w。将 e_s 和 z 连接起来形成全局条件,然后通过多个上采样块(详见附录)生成一个 16 x 16 的特征图。全局条件也用作计算条件批量归一化层中的尺度参数 γ 和偏移参数 β 的条件。这个公式也被称为自调制 [6]。
自调制层提高了隐特征与条件输入的一致性,但对于每个子区域缺乏更细致的细节。为了生成细粒度、可识别的区域,我们提出了注意力自调制层。具体来说,除了随机噪声 z 和全局句子嵌入 e_s 外,我们修改了注意机制 [58] 以计算单词-上下文向量作为每个子区域的附加调制参数。对于具有特征 h_j 的第 j 个区域,单词-上下文向量 c_j 为:
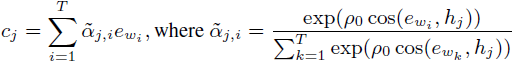
其中,T 是句子中的总单词数, ρ_0 是一个锐化的超参数。然后,第 j 个区域的调制特征 h'_j 可以定义为:
![]()
其中,μ 和 σ 是从聚合 batch 和空间维度得出的估计均值和标准差。γ_j(·) 和 β_j(·) 代表任何函数逼近器;在我们的工作中,我们简单地使用线性投影层。生成器的更多细节可以在附录中找到。
4.3 对比鉴别器
我们提出的鉴别器有两个角色:(1) 充当评论家,确定输入图像是真实的还是虚构的;(2) 充当编码器,计算全局图像和区域特征以用于对比损失。图像通过几个下采样块传递,直到其空间尺寸缩小到 16x16(见图 2,左下角)。然后,应用 1x1 卷积以获得区域特征,其中特征维度与单词嵌入的维度一致。原始图像特征通过另外两个下采样块和一个全局池化层。最后,一个投影头计算对抗损失的 logit,另一个投影头计算图像-句子和图像-图像对比损失的图像特征。请注意,仅使用真实图像及其描述来训练这些鉴别器投影头是重要的。原因是生成的图像有时是不可识别的,尤其是在训练开始时。使用这样的生成图像和句子对会损害图像特征编码器投影头的训练。因此,对来自虚构图像的对比损失仅应用于生成器。除了鉴别器投影层之外,我们还使用一个预训练的 VGG 网络 [49] 作为图像编码器,用于额外的监督图像-图像对比损失(见 Sec. 6.2)。算法1 总结了XMC-GAN的训练过程。为简单起见,在我们的实验中,我们将所有对比损失系数(算法 1 中的 λ_1、λ_2、λ_3)设置为 1.0。

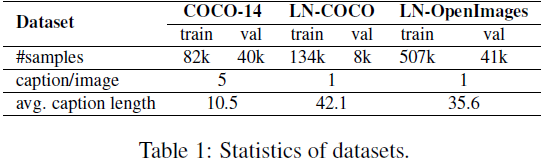
5. 评估
5.1 数据
我们在三个具有挑战性的数据集上对XMC-GAN进行了全面评估(见表1概述)。
MS-COCO [30] 常用于文本到图像合成。每个图像配有 5 个简短的标题。我们遵循大多数先前的工作,使用 2014 年的划分(COCO-14)进行评估。

Localized Narratives [40] 包含了几个图像集的长篇图像描述。我们在 LN-COCO 上进行了结果基准测试,其中包含了 MS-COCO(COCO-17)2017 年划分中图像的叙述。这些叙述平均比 MS-COCO 标题长四倍,并且它们更加描述性(见图 4)。叙述还包含了口语转录所存在的不流畅之处。这些因素使得对于 LN-COCO 的文本到图像合成比 MS-COCO 更具挑战性。
我们还使用 LN-OpenImages 进行训练和评估,这是 Localized Narratives 的 Open Images [23] 划分。其图像既多样又复杂(平均有 8.4 个对象)。LN-OpenImages 也比 MS-COCO 和 LN-COCO 大得多(见表 1)。据我们所知,我们是第一个为 Open Images 训练和评估文本到图像生成模型的研究者。XMC-GAN 能够生成高质量的结果,并为这项非常具有挑战性的任务设立了强有力的基准。
5.2 评估指标
我们遵循先前的工作,通过生成 30,000 个随机标题的图像来报告验证结果。我们使用多个度量综合评估。
图像质量。我们使用标准的自动化指标来评估图像质量。Inception Score(IS)[46] 计算了在给定预训练图像分类器的条件类分布和边际类分布之间的 KL 散度。Fr´echet Inception Distance(FID)[15] 是生成图像和真实图像的 Inception [51] 特征拟合的两个多变量高斯分布之间的 Fr´echet 距离。虽然 IS 和 FID 都已被证明与人类对生成图像质量的判断相关,但 IS 可能不够信息丰富,因为它容易过拟合,并且可以通过简单的技巧进行操纵,以实现更高的分数 [2, 17]。我们的结果进一步强调了这一点(Sec. 6.1),显示 FID 与人类对逼真度的判断更好地相关。
文本-图像对齐。遵循先前的工作 [58, 27],我们使用 R-precision 来评估生成的图像是否可以用于检索其条件描述。然而,我们注意到先前的工作使用来自 AttnGAN [58] 的图像-文本编码器计算 R-precision,并且许多其他方法在训练期间将这些编码器作为优化函数的一部分使用。这会使结果出现偏差:许多生成的模型报告的 R-precision 分数明显高于真实图像。为了缓解这个问题,我们使用在 Conceptual Captions 数据集 [48] 中对真实图像进行预训练的图像-文本双编码器 [38],该数据集与 MS-COCO 不相交。我们发现使用独立编码器计算 R-precision 更好地与人类判断相关。
标题检索指标评估整个图像是否与标题匹配。相反,语义对象准确性(Semantic Object Accuracy,SOA)[17] 评估图像中各个区域和对象的质量。与先前的工作一样,我们报告 SOA-C(即每个类别的图像中检测到所需对象的百分比)和 SOA-I(即检测到所需对象的图像的百分比)。SOA 的更多细节可以在 [17] 中找到。SOA 最初是为 COCO-14 设计的,它可能需要很长时间来计算,因为它需要为每个 MS-COCO 类标签生成多个样本。我们使用官方代码来计算表 2 中报告的指标,但在我们计算 30,000 个随机样本的结果的 LN-COCO 和其他消融实验中,我们进行了结果的近似。
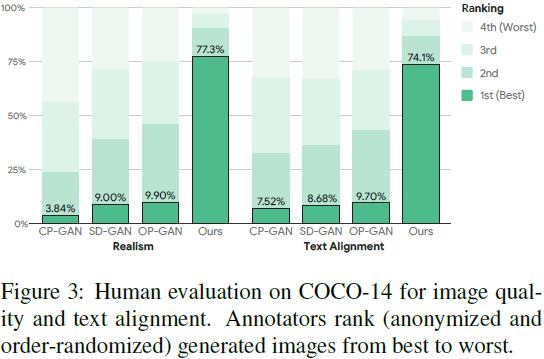
人工评估。自动化指标在实验过程中对模型进行迭代时很有用,但它们不能替代人眼。我们对从1000 个随机选择的标题生成的图像进行了彻底的人工评估。对于每个标题,我们请 5 名独立的人类标注员根据(1)逼真度和(2)语言对齐性对生成的图像进行排名,从最好到最差。
6. 实验
6.1 结果
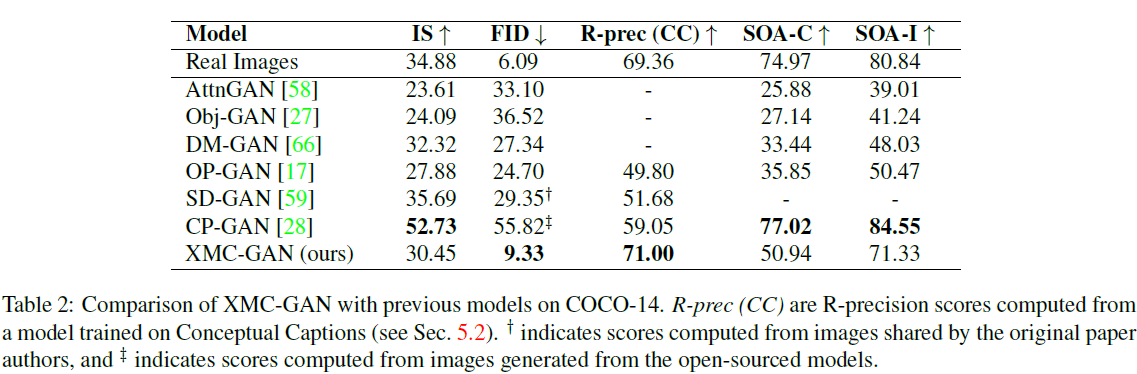
COCO-14。图 3 显示了人工评估,将 XMC-GAN 与三个最近的强模型进行比较:CP-GAN [28]、SD-GAN [59] 和 OP-GAN [17]。给定由这四个模型生成的图像(匿名化并随机排序),注释员被要求根据质量从最好到最差对它们进行排名。逼真度和文本对齐性的判断是独立收集的。在这两个方面,XMC-GAN 都是明显的赢家:在逼真度比较中,其输出在 77.3% 的情况下被评为最佳,在文本对齐比较中为 74.1%。OP-GAN 排名第二,分别为 9.90% 和 9.70%。XMC-GAN 实现了这一点,同时它是一个更简单的单阶段模型,而 OP-GAN 是多阶段模型,需要对象边界框。对选定的图像的视觉检查(图 4)有力地显示了质量的大幅提升。与其他模型相比,XMC-GAN 的图像保真度更高,描绘的对象更清晰,场景更连贯。这也适用于更多的随机样本(请参阅附录)。
表 2 提供了全面的 COCO-14 自动化指标结果。XMC-GAN 将 FID 从 24.70 提高到 9.33,相对于排名第二的模型 OP-GAN [17],相对提高了 62.2%。在我们独立训练的编码器计算的 R-precision中,XMC-GAN 也优于其他模型(71% 对 59%),表明生成的图像对其所依赖的标题的保真度有很大提高,并与人类判断一致。尽管 CP-GAN 获得了更高的 IS 和 SOA 分数,但我们的人工评估和对随机选择的图像的视觉检查都表明,XMC-GAN 的图像质量要高得多。这可能是由于 IS 和SOA 不惩罚类内模态丢失(类内低多样性)的问题,即生成每个类别的 “完美” 样本的模型可以在IS 和 SOA 上取得良好的分数。我们的发现与其他研究 [27, 2] 一致,表明 FID 可能是衡量文本到图像合成质量的更可靠的度量标准。
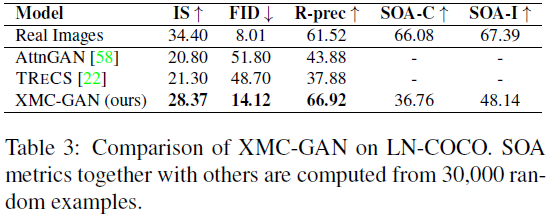
LN-COCO。Localized Narratives [40] 包含更长的描述,这增加了文本到图像合成的难度(见 Sec. 5.1)。表 3 显示 XMC-GAN 相对于先前的工作提供了巨大的改进。与 TReCS [22] 相比,XMC-GAN 将 IS 和 FID 分别提高了 7.07 和 34.58。相对于 AttnGAN [58],它还将 R-precision 提高了 23.04%,表明文本对齐性更好。通过随机选择的输出的定性比较来支持这一点:XMC-GAN 的图像明显更清晰、更连贯(见图 4)。我们强调,TReCS 利用了 LN-COCO 的鼠标轨迹注释,将这种训练信号纳入 XMC-GAN 中将在未来进一步提升性能。
LN-OpenImages。我们在 Open Images 数据集上训练 XMC-GAN,该数据集比 MS-COCO 更具挑战性,因为图像和描述更加多样化。XMCGAN 实现了 IS 为 24.90,FID 为 26.91,和 R-precision 为 57.55,并成功生成高质量图像(见附录)。据我们所知,XMC-GAN 是第一个在 Open Images 上训练和评估的文本到图像模型。其强大的自动化评分为这个具有挑战性的数据集建立了强有力的基准结果。
6.2 消融
我们彻底评估了 XMC-GAN 的不同组件并分析了它们的影响。表 4 总结了我们在 COCO-14 验证集上的消融。为了研究 XMC-GAN 中使用的每个对比损失组件的影响,我们尝试了四种损失:(1)图像-句子,(2)区域-词,(3)使用鉴别器特征的图像-图像,以及(4)使用 VGG 特征的图像-图像。对于(3),我们使用鉴别器编码器投影(在表 4 中用 D 表示)提取图像特征。对于(4),我们从在 ImageNet 上预训练的 VGG-19 网络[49] 中提取图像特征。
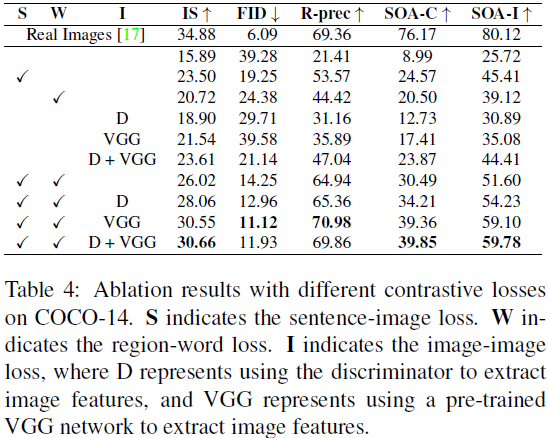
个体对比损失。表 4 显示,与基线相比,使用任何对比损失都改善了所有指标。在实验过程中,我们还发现包括任何对比损失都极大地改善了训练稳定性。最大的改进来自跨模态图像-句子和区域-词对比损失,分别将 FID 从 39.28 提高到 19.25 和 24.38。与图像-图像内模态对比损失相比,例如仅包括鉴别器特征编码器(D)的损失仅将 FID 提高到 29.71。这些消融突显了跨模态对比损失的有效性:句子和词对比损失分别极大地改善了文本对齐度指标,同时提高了图像质量。
组合对比损失。组合对比损失提供了进一步的增益。例如,同时使用图像-句子和区域-词损失比单独使用(分别为 FID 19.25 和 24.38)获得更好的性能(FID 14.25)。这表明局部和全局条件是互补的。此外,同时使用跨模态损失(句子和单词)胜过内模态损失(D + VGG):FID 得分分别为14.25 和 21.14。这些结果进一步强调了跨模态对比学习的有效性。然而,跨模态和内模态对比损失也相辅相成:最佳的 FID 分数来自结合图像-句子、区域-词和图像-图像(VGG)损失。在使用图像-图像(D + VGG)损失时,IS 和文本对齐性能进一步提高。为了获得我们的最终结果(表2),我们使用所有 4 个对比损失训练一个模型(基础通道维度为 96)。
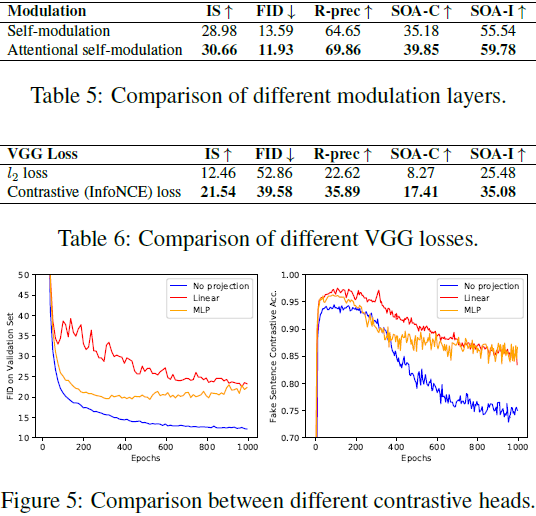
更深的对比头。在无监督表示学习中 [5, 7],通常通过添加非线性层来提高性能。为了研究这一点,我们增加了鉴别器中投影头的深度。在假图像上的 FID 和对比准确度 [5] 的训练曲线如图 5 所示,跨足 1000 个时代。我们发现不使用额外的投影层可以获得最佳的 FID(12.61,与 2 层 MLP的 19.42 相比)。此外,我们还发现在投影头中添加更多层时,假图像上的对比准确度也会提高(从 76.56% 到 88.55%)。我们假设在这种配置中,鉴别器对对比学习任务过拟合,导致在对抗任务中表现较差,因此作为生成器的监督信号也更差。
注意力自调制。我们比较了两种生成器设置:(1) 在所有残差块中使用自调制层 [6],和 (2) 在输入分辨率大于 16x16 的块中使用注意力自调制层(见第 4.2 节)。表 5 显示,提出的注意力自调制层在所有指标上优于自调制层。
损失类型。在生成模型中经常使用的损失函数是在假图像和相应真实图像之间的 VGG [49] 输出上的 L2 损失。这也通常被称为感知损失 [19]。表 6 显示,对比损失在性能上优于这种感知损失。这表明,远离不匹配的样本比简单地拉近对齐的样本更有效。鉴于这种卓越的性能,用对比损失替代感知损失可能有助于其他生成任务。
7. 结论
在这项工作中,我们提出了一种跨模态对比学习框架,用于训练文本到图像合成的 GAN 模型。我们研究了几种跨模态对比损失,以强制图像和文本之间的对应关系。通过在多个数据集上进行人工和自动评估,XMC-GAN 相比先前的模型取得了显著的改进:它生成了更高质量的图像,更好地匹配其输入描述,包括对于长篇、详细的叙述。而且,它是一个更简单的端到端模型。我们相信这些进展是朝着从自然语言描述生成图像的创造性应用迈出的重要一步。
S. 总结
S.1 主要贡献
为改进本文到图像对齐,本文提出跨模态对比生成对抗网络(Cross-Modal Contrastive Generative Adversarial Network,XMC-GAN)。它通过多个对比损失(图像-文本,真实图-生成图,图像区域-句中词语)来捕捉模态间和模态内的对应关系。XMC-GAN 使用一种注意力自调制生成器,强化文本与图像的对应关系,以及一种对比鉴别器,既进行评判又作为对比学习的特征编码器。
S.2 架构和方法
XMC-GAN 的架构如图 2 所示。本文使用如下损失来生成与描述对齐且逼真的图像:
- 图像文本对比损失:计算通过图像编码器获得的图像特征与通过文本编码器获得的文本嵌入之间的对比损失。
- 具有相同描述的生成图像和真实图像之间的对比损失。
- 图像区域和单词之间的对比损失。
相关文章:
(2021|CVPR,XMC-GAN,对比学习,注意力自调制)用于文本到图像生成的跨模态对比学习
Cross-Modal Contrastive Learning for Text-to-Image Generation 公众:EDPJ(添加 VX:CV_EDPJ 或直接进 Q 交流群:922230617 获取资料) 目录 0. 摘要 1. 简介 2. 相关工作 3. 基础 4. 方法 4.1 用于文本到图像…...

【Linux基本命令】
文章目录 一. Linux基本命令第三回二. 结束语 一. Linux基本命令第三回 cal指令,命令格式:cal 【参数】【月份】【年份】 功能,用于查看日历等时间信息,如只有一个参数,则表示年份,有两个参数则表示月份和…...

Wi-Fi、蓝牙、ZigBee等多类型无线连接方式的安全物联网网关设计
随着物联网和云计算技术的飞速发展.物联网终端的数量越来越多,终端的连接方式也更趋多样化,比如 Wi-Fi蓝牙和 ZigBee 等。现有的物联网网关大多仅支持一种或者几种终端的接人方式。无法满足终端异构性的需求。同时,现有的物联网网关与终端设备…...

华清远见嵌入式学习——ARM——作业4
作业要求: 代码运行效果图: 代码: do_irq.c: #include "key_it.h" extern void printf(const char *fmt, ...); unsigned int i 0;//延时函数 void delay(int ms) {int i,j;for(i0;i<ms;i){for(j0;j<2000;j);} }void do_i…...
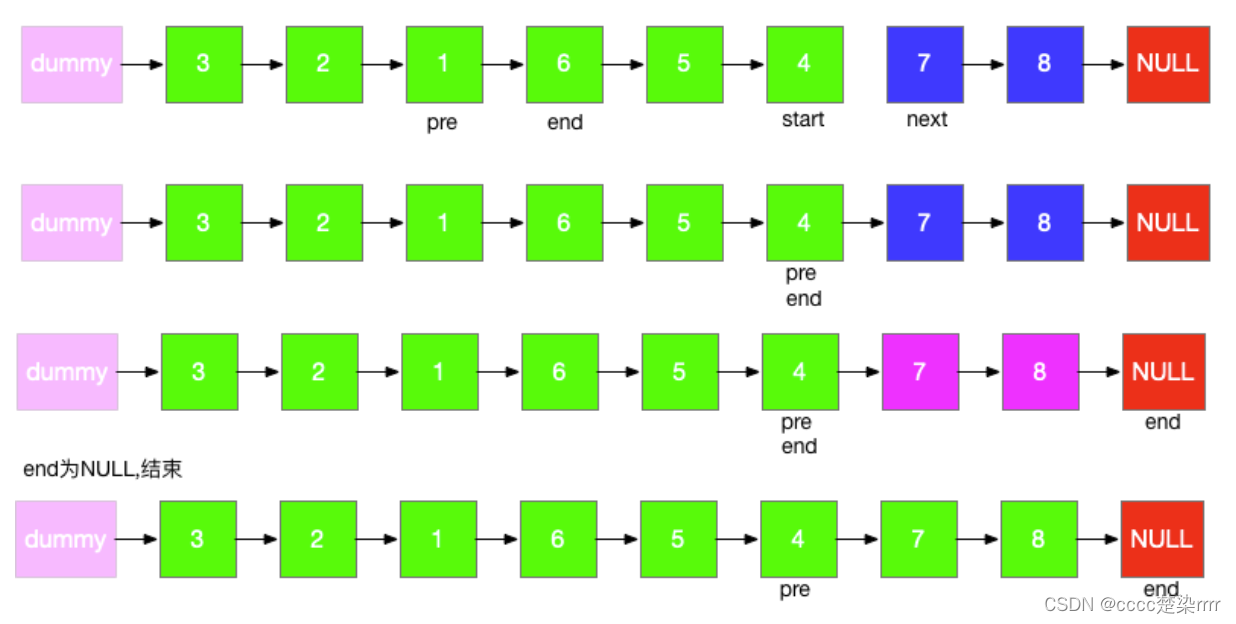
25. K 个一组翻转链表
题解参考:https://leetcode.cn/problems/reverse-nodes-in-k-group/solutions/10416/tu-jie-kge-yi-zu-fan-zhuan-lian-biao-by-user7208t/ 设置dummy虚拟头节点,pre为待翻转部分的前驱(用于连接),end为待翻转部分中的…...

jQuery的事件-动画-AJAX和插件
一、jQuery事件处理 1.认识事件(Event) Web页面经常需要和用户之间进行交互,而交互的过程中我们可能想要捕捉这个交互的过程: 比如用户点击了某个按钮、用户在输入框里面输入了某个文本、用户鼠标经过了某个位置;浏…...

【开源】基于JAVA语言的企业项目合同信息系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 合同审批模块2.3 合同签订模块2.4 合同预警模块2.5 数据可视化模块 三、系统设计3.1 用例设计3.2 数据库设计3.2.1 合同审批表3.2.2 合同签订表3.2.3 合同预警表 四、系统展示五、核心代码5.1 查询合同…...
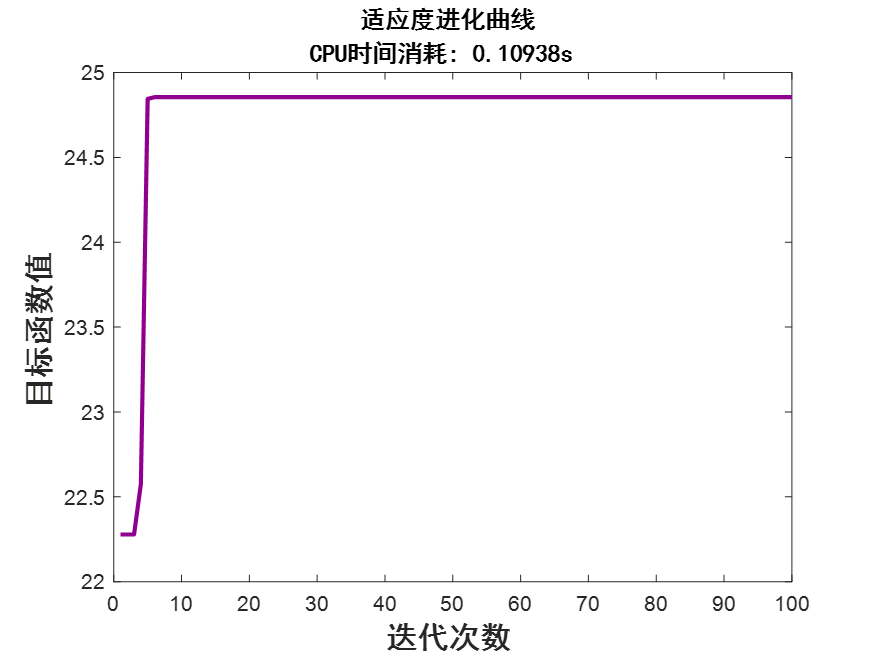
遗传算法的应用——求解一元函数的极值
遗传算法的应用——求解一元函数的极值 1 基本概念2 预备知识3.1 模拟二进制转化为十进制的方法3.2 轮盘赌选择算法 3 问题4 Matlab代码5 运行效果6 总结 1 基本概念 遗传算法(Genetic Algorithm,GA)是模拟生物在自然环境中遗传和进化过程从而形成的随机全局搜索和优化方法&am…...
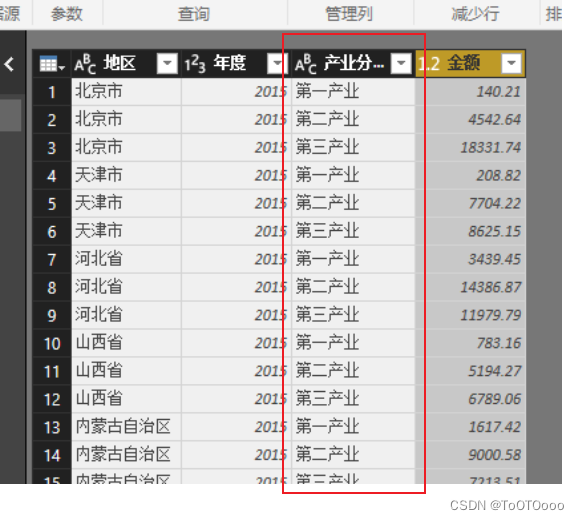
Power BI 学习
数据获取 数据清洗 对导入的数据进行数据整理的过程一般称为「数据清洗」,之所以称之为清洗,是因为在数据分析师眼中,杂乱的数据就是脏数据,只有被清洗成干净的数据后才可以进行分析使用。 数据丰富 操作 1.复制列 点击列名选…...

PPT中加入页码
PPT中加入页码 文章目录 简单版本样式更改 简单版本 PPT中插入页码,基础的就是在“插入”选项卡中单机“幻灯片编号”即可 样式更改 然而,就像我们做幻灯片不满足于白底黑字一样,页码也总不能是默认的样式。 比如,在页码下面…...

xxl-job使用笔记
文章目录 xxl-job配置文件新增XxlJobConfig类JobHandler例子xxl-job机制xxl-job-admin配置XxlJob 和 JobHandler(过时了) 其他报错 msg:job handler [demoJobHandler] not found.xxl-job报错 xxl-job registry fail, registryParam:RegistryParam{registryGroup‘EX…...

微短剧,会成为长视频的“救命稻草”吗?
职场社畜秒变霸道总裁,普通女孩穿越成为艳丽皇妃.......这样“狗血”的微短剧,最近不仅在国内各大视频平台上异常火爆,而且还直接火出了国外。 所谓微短剧,就是单集时长从几十秒到十几分钟的剧集,有着相对明确的主题和…...

web架构师编辑器内容-创建业务组件和编辑器基本行为
编辑器主要分为三部分,左侧是组件模板库,中间是画布区域,右侧是面板设置区域。 左侧是预设各种组件模板进行添加 中间是使用交互手段来更新元素的值 右侧是使用表单的方式来更新元素的值。 大致效果: 左侧组件模板库 最初的模板…...

力扣刷题记录(18)LeetCode:474、518、377、322
目录 474. 一和零 518. 零钱兑换 II 377. 组合总和 Ⅳ 322. 零钱兑换 总结: 474. 一和零 这道题和前面的思路一样,就是需要将背包扩展到二维。 class Solution { public:int findMaxForm(vector<string>& strs, int m, int n) {vector&l…...
)
MongoDB创建和查询视图(一)
目录 限制和注意事项 应用两种方式创建视图 本文整理mongodb的官方文档,介绍mongodb的视图创建和查询。 Mongodb中,允许使用两种方式来创建视图。 //使用db.createCollection()来创建视图 db.createCollection("<viewName>",{"…...
)
paddle 53 基于PaddleClas2.5训练自己的数据(训练|验证|推理|c++ 部署)
项目地址:https://github.com/PaddlePaddle/PaddleClas 文档地址:https://paddleclas.readthedocs.io/zh-cn/latest/tutorials/install.html paddleclas的最新项目已经不适应其官网的使用案例(训练、验证、推理命令均不适用),为此博主对其进行命令重新进行修改。同时padd…...

智能优化算法应用:基于卷积优化算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于卷积优化算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于卷积优化算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.卷积优化算法4.实验参数设定5.算法结果6.…...

项目中日期封装
官网:Moment.js 中文网项目中安装:npm install moment --save封装:创建一个.js文件 // 日期、时间封装 import moment from moment moment.locale("zh-cn"); const formatTime {getTime: (date) > {return moment().format(YY…...

7.仿若依后端系统业务实践
目录 概述项目实践mybatis 反向生成代码有覆盖问题解决pom.xmlbootstrap.ymlapplication.ymlmaven测试各种校验问题实践单个属性校验级联属性校验接口实体类测试结果自定义关联属性校验接口...

java:4-9键盘输入
文章目录 键盘输入.1 定义.2 步骤.3 演示 键盘输入 .1 定义 在编程中,需要接收用户输入的数据,就可以使用键盘输入语句来获取。Input.java , 需要一个 扫描器(对象), 就是 Scanner .2 步骤 导入该类的所在包package, java.util.*创建该类对象(声明变…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

如何通过git命令查看项目连接的仓库地址?
要通过 Git 命令查看项目连接的仓库地址,您可以使用以下几种方法: 1. 查看所有远程仓库地址 使用 git remote -v 命令,它会显示项目中配置的所有远程仓库及其对应的 URL: git remote -v输出示例: origin https://…...

边缘计算网关提升水产养殖尾水处理的远程运维效率
一、项目背景 随着水产养殖行业的快速发展,养殖尾水的处理成为了一个亟待解决的环保问题。传统的尾水处理方式不仅效率低下,而且难以实现精准监控和管理。为了提升尾水处理的效果和效率,同时降低人力成本,某大型水产养殖企业决定…...
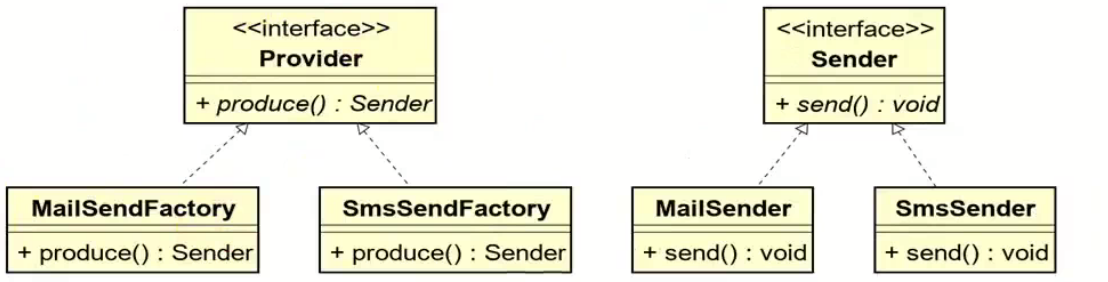
工厂方法模式和抽象工厂方法模式的battle
1.案例直接上手 在这个案例里面,我们会实现这个普通的工厂方法,并且对比这个普通工厂方法和我们直接创建对象的差别在哪里,为什么需要一个工厂: 下面的这个是我们的这个案例里面涉及到的接口和对应的实现类: 两个发…...
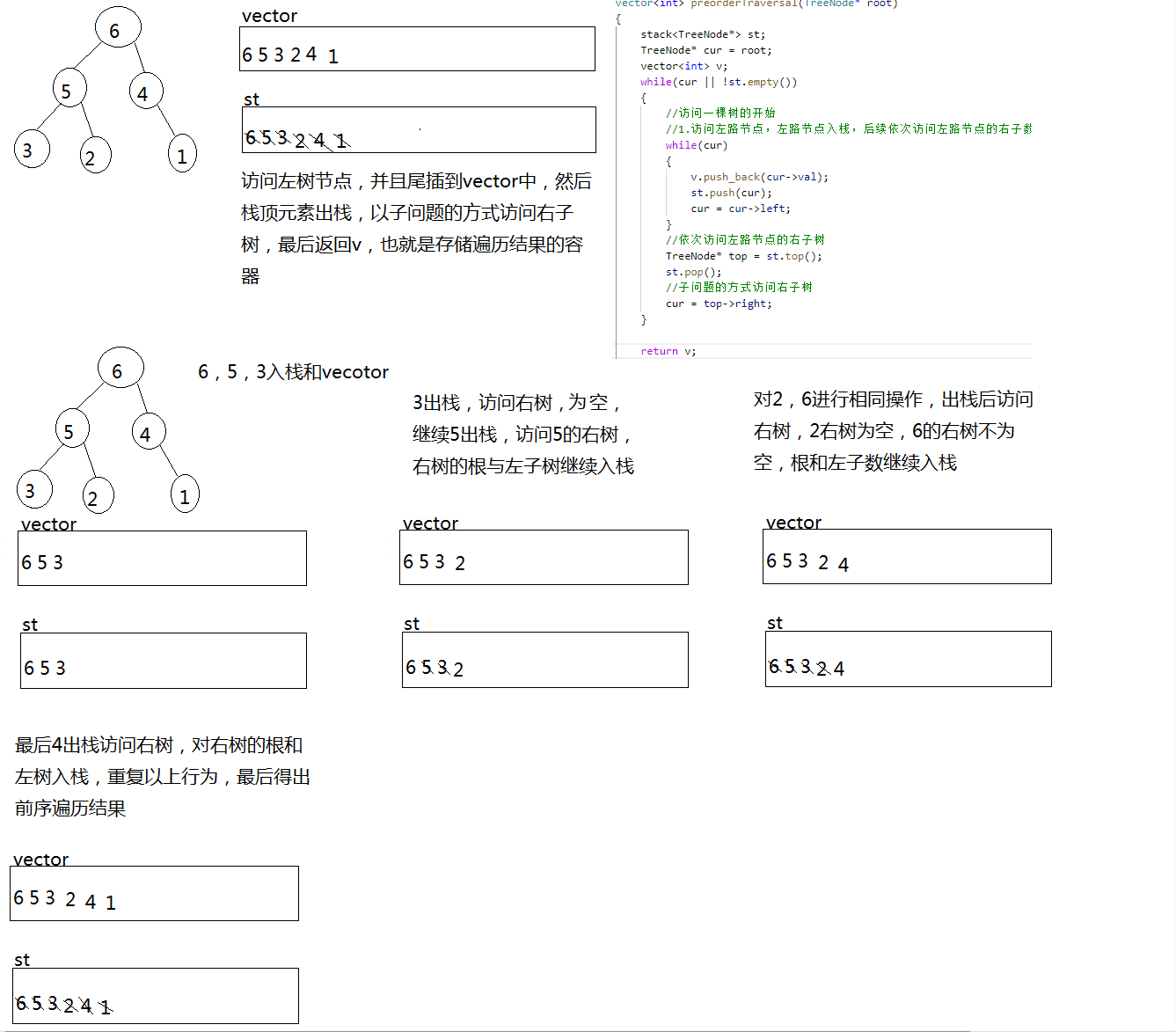
二叉树-144.二叉树的前序遍历-力扣(LeetCode)
一、题目解析 对于递归方法的前序遍历十分简单,但对于一位合格的程序猿而言,需要掌握将递归转化为非递归的能力,毕竟递归调用的时候会调用大量的栈帧,存在栈溢出风险。 二、算法原理 递归调用本质是系统建立栈帧,而非…...
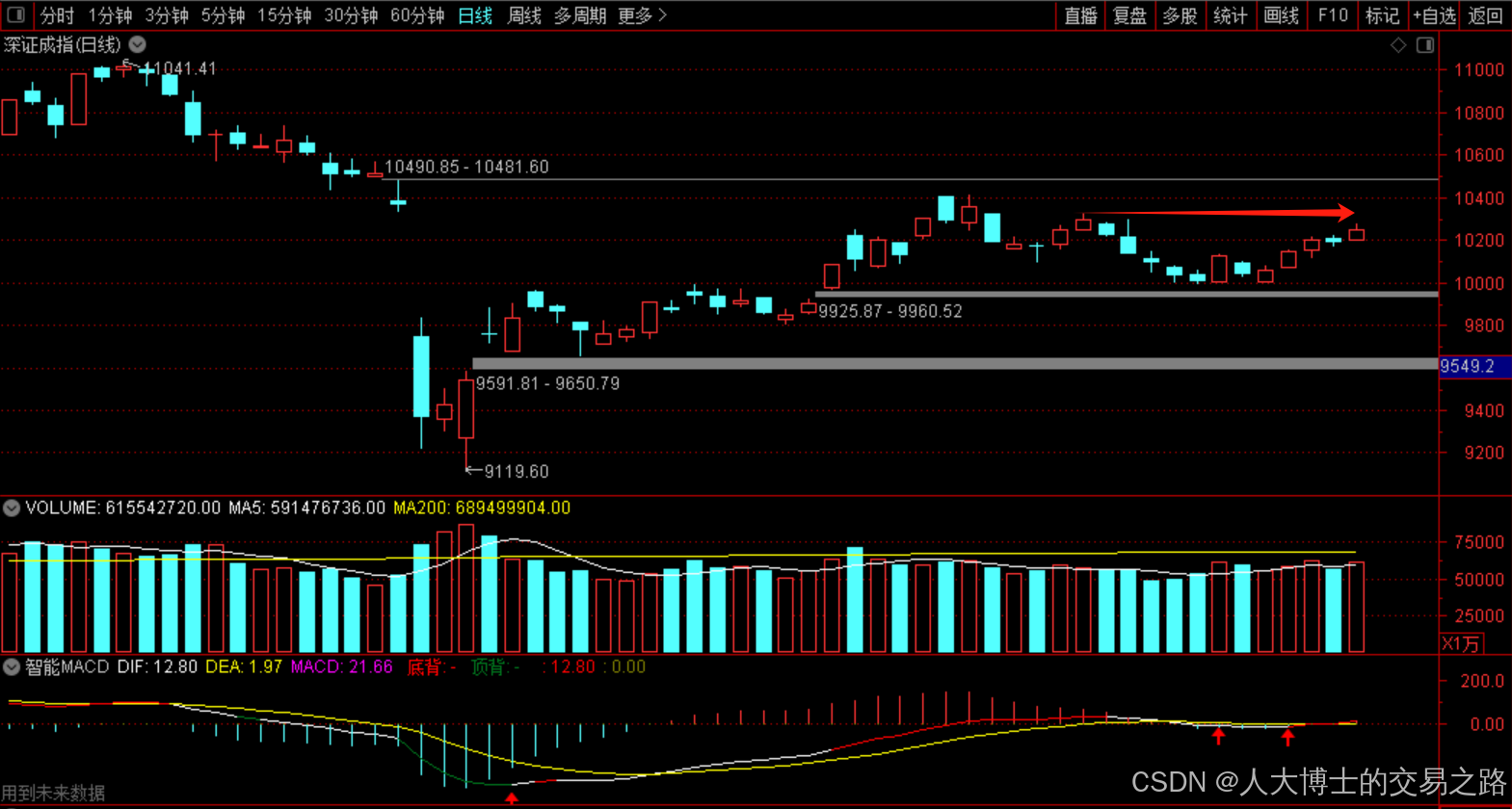
今日行情明日机会——20250609
上证指数放量上涨,接近3400点,个股涨多跌少。 深证放量上涨,但有个小上影线,相对上证走势更弱。 2025年6月9日涨停股主要行业方向分析(基于最新图片数据) 1. 医药(11家涨停) 代表标…...