基于Python的车牌识别系统实现

本文将以基于Python的车牌识别系统实现为方向,介绍车牌识别技术的基本原理、常用算法和方法,并详细讲解如何利用Python语言实现一个完整的车牌识别系统。
精彩专栏持续更新推荐订阅,收藏关注不迷路
微信小程序实战开发专栏

目录
- 引言
- 车牌识别技术的应用场景
- Python在车牌识别领域的优势
- 车牌识别技术概述
- 图像处理和计算机视觉的基本原理
- 车牌识别的基本流程
- 常用的车牌识别算法和方法
- 准备工作
- 安装和配置Python环境
- 数据集准备
- 图像预处理
- 图像读取与灰度转换
- 图像增强与滤波
- 边缘检测与轮廓提取
- 字符识别
- 特征提取与选择
- 分类器的训练与优化
- 字符识别实现与性能评估
引言
车牌识别技术的应用场景
车牌识别技术具有广泛的应用场景,其在交通管理、安防监控以及智慧城市建设等领域都发挥着重要的作用。
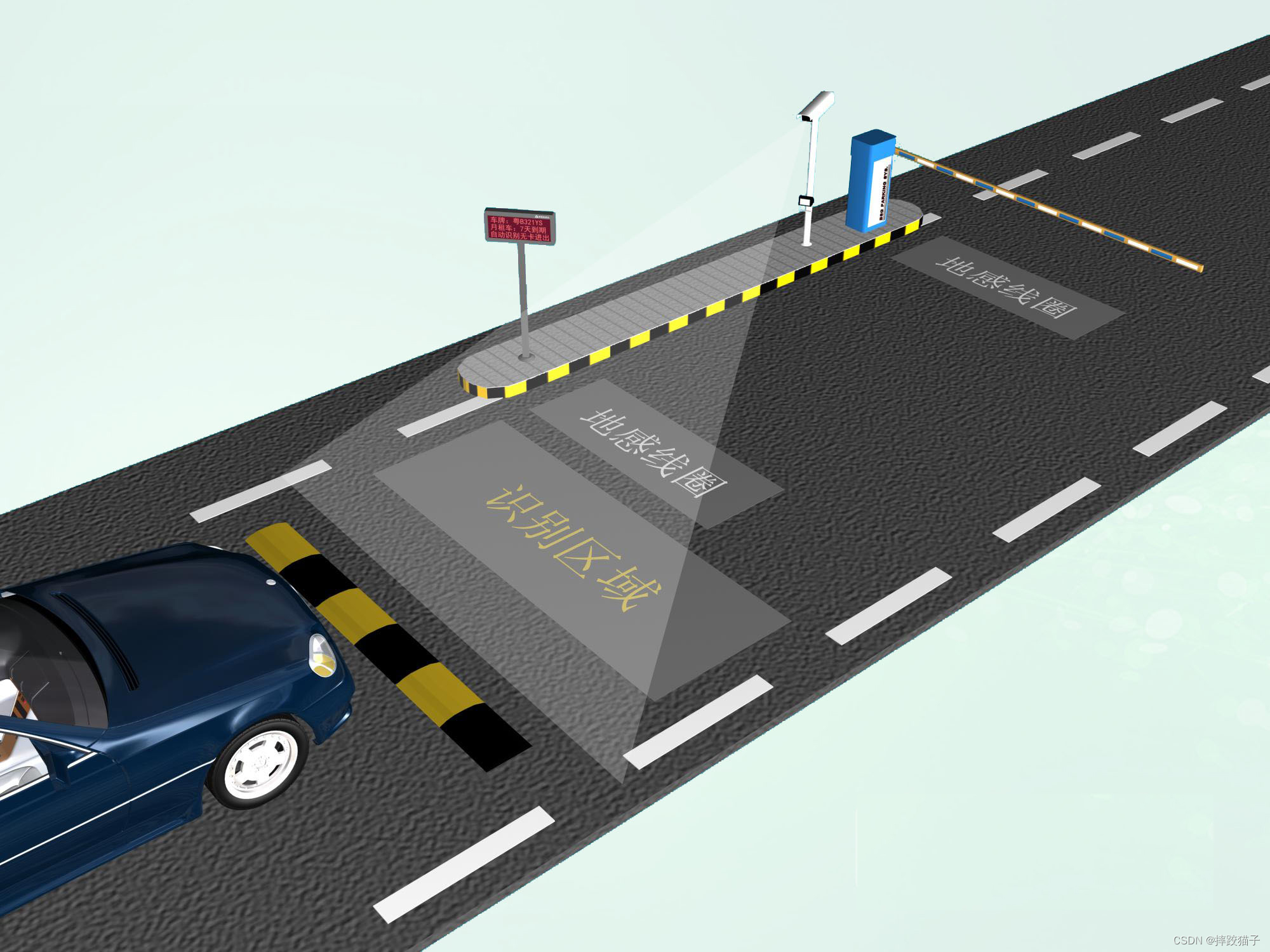
- 交通管理:车牌识别技术在交通管理中起到了至关重要的作用。通过实时自动识别车辆的车牌号码,交通管理部门可以准确记录每辆车的信息,实现违章监测和电子收费等功能,提高交通流程的效率和安全性。
- 智能停车系统:车牌识别技术可应用于智能停车系统中,通过识别车辆的车牌号码,实现车辆进出场的自动识别和计费,并提供导航引导服务,简化停车过程,提升停车管理的便利性和效率。
- 安防监控:车牌识别技术在安防监控领域被广泛使用。通过检测和识别车辆的车牌信息,可以实现对车辆进出口的实时监控和记录,辅助安保人员对可疑车辆进行追踪和调查,提高社会治安维护的效果。
- 物流管理:车牌识别技术可以应用于物流管理中,帮助物流公司实现对运输车辆的自动识别和追踪,提高货物配送的准确性和及时性,优化物流运输过程。
- 智慧城市建设:车牌识别技术是智慧城市建设中的重要组成部分。通过大规模应用车牌识别技术,可以实现交通拥堵监测与调控、智能红绿灯控制、智能化停车管理等功能,为城市交通运行和管理提供更加高效和智能的解决方案。
Python在车牌识别领域的优势
Python在车牌识别领域具有丰富的开源资源、简洁易读的语法、跨平台性、强大的社区支持以及可扩展性等优势。这些特点使得使用Python进行车牌识别系统的开发变得更加高效、灵活和方便。
- 丰富的开源库和工具:Python拥有众多优秀的开源图像处理和机器学习库,如OpenCV、Pillow、Scikit-learn等,这些库提供了丰富的图像处理和机器学习算法,使得开发者能够轻松实现车牌识别系统的各项功能和流程。
- 简洁易读的语法:Python语言以其简洁易读的语法著称,这使得开发和调试车牌识别系统变得更加高效和便捷。Python的代码对于初学者和新手来说也更易于理解和掌握,降低了学习和使用门槛。
- 跨平台性:Python是一种跨平台的编程语言,在不同操作系统(如Windows、Linux和MacOS)上都能很好地运行。这意味着开发者可以在不同的环境中进行车牌识别系统的开发和部署,提供了更大的灵活性和适应性。
- 强大的社区支持:Python拥有庞大而活跃的开发者社区,提供了丰富的教程、文档和示例代码。无论是初学者还是有经验的开发者,都可以从社区中获取支持和解决问题,加快开发进程并提升系统性能。
- 可扩展性:Python是一种可扩展的语言,可以集成其他编程语言(如C++)编写的模块和库。对于需要处理大规模数据和复杂算法的车牌识别系统,开发者可以通过调用底层C/C++库,提高系统的运行效率和性能。
车牌识别技术概述
图像处理和计算机视觉的基本原理
图像处理和计算机视觉的基本原理是相互关联和互补的,在车牌识别等应用中,常常结合使用以提取、分析和识别图像中的车牌信息。这些原理为实现精确、高效的图像处理和计算机视觉应用提供了重要的方法和技术支持。

图像处理的基本原理:
-
图像获取:通过摄像头或其他设备获取到的图像数据。
-
图像预处理:对原始图像进行去噪、增强、调整亮度对比度等操作,以优化图像质量,方便后续处理。
-
特征提取:从图像中提取有用的特征信息,如边缘、角点、纹理等。常用的方法包括Canny边缘检测、Harris角点检测、Gabor滤波等。
-
图像分割:将图像分为不同的区域或对象。常见的方法有阈值分割、边缘检测、区域生长等。
-
目标识别与跟踪:在图像中识别和跟踪感兴趣的目标或区域。常用的方法有模板匹配、特征匹配、目标检测算法(如Haar特征、HOG特征、深度学习)等。
-
图像重建与合成:根据已有的图像信息,重建出完整或高分辨率的图像,或者通过将多个图像合成成一幅图像。
计算机视觉的基本原理: -
特征提取与描述:从图像中提取有用的特征并进行描述,如角点、边缘、纹理等。常见的特征描述算法包括SIFT、SURF、ORB等。
-
物体检测与识别:在图像中自动检测和识别物体。常用的方法有基于特征的分类器(如支持向量机、随机森林)、级联分类器、深度学习(如卷积神经网络)等。
-
三维重建与摄像测量:通过多个视角的图像,推导出物体的三维结构或重建出三维场景。常用的方法有立体匹配、结构光、视差法、多视几何等。
-
运动分析与跟踪:对图像序列进行运动分析和目标跟踪。常见的方法有光流法、卡尔曼滤波、粒子滤波等。
-
图像检索与分类:根据图像的内容进行检索和分类,以实现图像库管理和图像信息的快速检索。常见的方法有颜色直方图、局部二值模式、深度学习特征等。
车牌识别的基本流程
车牌识别的基本流程可以分为图像获取、预处理、车牌定位、字符分割、字符识别等步骤,实际应用中还需要考虑各种异常情况的处理,如光照、遮挡、车牌变形等因素。同时,不同的算法和技术在各个步骤中也有差异,需要根据具体场景和应用需求选择合适的方法和参数进行调节。
常用的车牌识别算法和方法
车牌识别算法和方法有很多种,不同的算法和方法适用于不同的应用场景和数据集,需要根据实际需求进行选择和优化,这里简要介绍几种常用的:
-
基于颜色特征的车牌定位算法:
该算法通过提取车牌区域的颜色特征,如蓝色、黄色等,然后对图像进行二值化和形态学变换,最后选取符合条件的区域作为车牌区域。该算法简单易懂,但对颜色和光照变化敏感。 -
基于深度学习的车牌定位和识别算法:
深度学习方法在图像处理和计算机视觉领域中得到广泛应用,其基本思想是通过对海量数据的学习,自动生成特征表示或者建立模型来实现目标检测或者识别等任务。在车牌识别中,可以使用卷积神经网络(CNN)等深度学习模型实现车牌定位和字符识别。该算法具有较高的识别精度,但需要大量的训练数据和计算资源。 -
基于形态学变换的车牌字符分割算法:
车牌字符分割是车牌识别中的关键步骤,目的是将车牌上的字符分割开来,方便后续的字符识别。基于形态学变换的方法是一种常用的字符分割算法,其基本思想是在图像中使用不同的形态学结构元素对字符区域进行膨胀和腐蚀操作,从而得到清晰的字符轮廓,再通过垂直投影点数或其他特征对字符进行分割。 -
基于SVM和特征提取的字符识别算法:
支持向量机(SVM)是一种常用的分类算法,其可以通过对数据进行特征提取和训练,实现对车牌字符的分类和识别。常用的特征提取算法有灰度共生矩阵(GLCM)、局部二值模式(LBP)等,这些特征主要描述字符的纹理和形状信息,对于字符的识别具有较高的鲁棒性和准确性。
准备工作
安装和配置Python环境
安装和配置Python环境的步骤如下:
-
下载Python:首先需要从Python官方网站(https://www.python.org)下载Python的安装包。根据操作系统选择对应的版本,一般建议下载最新的稳定版本。
-
运行安装程序:双击下载的安装包并运行,会打开Python安装向导。
-
选择安装选项:在安装向导中,可以选择自定义安装路径、添加Python到系统环境变量等选项。如果不熟悉,可以使用默认选项进行安装。
-
完成安装:等待安装程序完成安装过程,可能需要一些时间。
-
验证安装:安装完成后,打开命令行工具(如Windows的命令提示符或PowerShell,或者Mac/Linux的终端),输入以下命令验证是否成功安装:
python --version
如果显示Python的版本号,则说明安装成功。
-
配置环境变量(可选):如果在安装时没有选择添加Python到系统环境变量,可以手动配置。将Python的安装路径添加到系统的PATH环境变量中,这样就可以在任何位置直接使用python命令。
-
安装第三方库(可选):根据具体需求,可以使用pip工具安装Python的第三方库。例如,使用以下命令安装常用的科学计算库NumPy:
pip install numpy
数据集准备
要基于Python实现车牌识别,首先需要准备训练和测试所需的数据集。
-
收集车牌图像数据:收集包含车牌的图像数据,可以通过不同的方式获取,如现场拍摄、公开数据集等。确保数据集包含多种类型和角度的车牌图像,以提高算法的鲁棒性。
-
数据集划分:将收集到的数据集划分为训练集和测试集。通常,大部分数据用于训练模型,少量数据用于评估模型的性能。可以按照70-30或80-20的比例划分数据集,也可以使用交叉验证等更复杂的划分方式。
-
标注数据:对每张图像进行标注,将车牌区域框出来,并提供对应的车牌字符标签。可以使用图像处理工具或专门的标注工具进行标注。确保标注准确且一致,以便模型学习车牌的位置和字符信息。
-
数据增强(可选):对训练集进行数据增强操作,以扩充数据集并增加数据的多样性。例如,可以进行旋转、平移、缩放、亮度调整等操作,以提高模型的泛化能力。
-
数据预处理:对图像数据进行预处理操作,如调整大小、归一化、灰度化等。确保所有图像的尺寸和格式与模型要求相符。
-
数据加载:编写Python代码,使用合适的库(如OpenCV、PIL)加载图像数据,并将其转换为模型可接受的输入格式(如NumPy数组或张量)。
图像预处理
图像读取与灰度转换
可以使用Python的OpenCV库来读取图像并进行灰度转换。
import cv2# 读取图像
img = cv2.imread('image.jpg')# 将图像转换为灰度图像
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
在代码中,cv2.imread('image.jpg')函数用于读取名为’image.jpg’的图像,可以根据自己的实际情况修改文件名和路径。cv2.cvtColor()函数用于将读取到的彩色图像转换为灰度图像,第一个参数为原始图像,第二个参数为转换方式。cv2.COLOR_BGR2GRAY表示将BGR色彩空间的图像转换为灰度图像。
在灰度图像中每个像素只有一个值,范围为0~255,所以输出的灰度图像应该是单通道的。而且,在进行图像处理时,最好使用灰度图像进行处理,因为灰度图像计算量较小,处理速度较快。
图像增强与滤波
图像增强和滤波是图像处理中常用的技术,可以使用OpenCV库来实现。
图像增强:
import cv2
import numpy as np# 读取图像
img = cv2.imread('image.jpg')# 增加对比度和亮度
alpha = 1.5 # 对比度增加的倍数
beta = 30 # 亮度增加的值
enhanced_img = cv2.convertScaleAbs(img, alpha=alpha, beta=beta)在代码中,cv2.convertScaleAbs()函数用于增加图像的对比度和亮度。alpha参数表示对比度的倍数,越大对比度越高;beta参数表示亮度的增加值,越大亮度越高。
图像滤波:
import cv2
import numpy as np# 读取图像
img = cv2.imread('image.jpg')# 使用均值滤波
kernel_size = (5, 5) # 滤波器大小
filtered_img = cv2.blur(img, kernel_size)在代码中,cv2.blur()函数用于进行均值滤波。kernel_size参数表示滤波器的大小,其中(5, 5)表示滤波器为5x5大小的方形滤波器。均值滤波通过计算图像中每个像素周围邻域的平均值来实现平滑(模糊)图像。
边缘检测与轮廓提取
边缘检测:
import cv2# 读取图像并进行灰度转换
img = cv2.imread('image.jpg')
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 使用Canny算法进行边缘检测
edges = cv2.Canny(gray_img, threshold1=30, threshold2=100)在代码中,cv2.Canny()函数用于进行边缘检测。gray_img是输入的灰度图像,threshold1和threshold2是阈值参数,用于控制边缘检测的灵敏度。根据实际情况调整这两个阈值以得到合适的边缘图像。
轮廓提取:
import cv2# 读取图像并进行灰度转换
img = cv2.imread('image.jpg')
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 使用Canny算法进行边缘检测
edges = cv2.Canny(gray_img, threshold1=30, threshold2=100)# 寻找轮廓
contours, _ = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)# 绘制轮廓
contour_img = cv2.drawContours(img.copy(), contours, -1, (0, 255, 0), 2)
在代码中,cv2.findContours()函数用于寻找图像的轮廓。第一个参数是边缘图像,一般使用经过边缘检测后的图像作为输入;第二个参数是轮廓的检索模式,cv2.RETR_EXTERNAL表示只提取最外层的轮廓;第三个参数是轮廓的近似方法,cv2.CHAIN_APPROX_SIMPLE表示使用简化的轮廓表示。函数返回的contours是一个包含所有轮廓的列表。
然后,可以使用cv2.drawContours()函数将轮廓绘制到原始图像上,以便可视化。img.copy()用于创建绘制轮廓的图像副本,(0, 255, 0)表示绘制轮廓的颜色,2表示绘制轮廓线的粗细。
对于OpenCV版本4及以上,cv2.findContours()函数的返回值略有不同,需要对返回值进行修改:
contours, _ = cv2.findContours(edges, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
字符识别
特征提取与选择
特征提取和选择是机器学习和数据挖掘领域中的重要步骤,可以通过不同的方法来完成。
特征提取:
-
直接提取:直接从原始数据中提取特定的特征。例如,对于图像数据可以使用颜色直方图、纹理特征或形状描述符等提取特征。
-
统计特征:通过对数据进行统计分析,提取统计特征。例如,平均值、方差、最大值、最小值等。
-
频域特征:将数据转换到频域,提取频域特征。常用的方法包括快速傅里叶变换(FFT)和小波变换。
-
基于模型的特征提取:通过训练一个模型来提取特征。例如,使用卷积神经网络(CNN)的卷积层输出作为图像特征。
特征选择:
-
过滤方法:通过对特征进行评估和排序,选择与目标变量相关性高的特征。常用的指标包括互信息、卡方检验、相关系数等。
-
包裹方法:将特征选择看作是一个子集选择的问题,通过尝试不同的特征子集并评估模型性能来选择最佳特征子集。常用的方法包括递归特征消除(RFE)、遗传算法等。
-
嵌入方法:将特征选择嵌入到模型训练中,在训练过程中选择最佳的特征。常用的方法包括L1正则化、决策树的特征重要性等。
示例代码,演示使用sklearn库进行特征提取和选择:
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline# 假设有X和y作为输入数据和目标变量# 创建特征选择器
feature_selector = SelectKBest(score_func=chi2, k=10)# 创建分类器
classifier = LogisticRegression()# 创建流水线,结合特征选择和分类器
pipeline = Pipeline([('selector', feature_selector), ('classifier', classifier)])# 训练模型
pipeline.fit(X, y)# 使用选择好的特征进行预测
predictions = pipeline.predict(X)
在代码中,SelectKBest被用作特征选择器,chi2作为评估指标。k参数表示选择的特征数量。然后,通过Pipeline将特征选择器和分类器结合在一起,形成一个流水线,可以直接对数据进行训练和预测。
分类器的训练与优化
分类器的训练和优化是机器学习中的关键步骤,通过示例代码,演示使用sklearn库进行分类器的训练和优化:
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier# 假设有X和y作为输入数据和目标变量# 创建分类器
classifier = RandomForestClassifier()# 设置待调优的参数范围
param_grid = {'n_estimators': [100, 200, 300],'max_depth': [None, 5, 10],'min_samples_split': [2, 5, 10]
}# 使用GridSearchCV进行参数优化和模型选择
grid_search = GridSearchCV(classifier, param_grid=param_grid, cv=5)
grid_search.fit(X, y)# 输出最佳参数和对应的模型性能
print("Best Parameters: ", grid_search.best_params_)
print("Best Score: ", grid_search.best_score_)# 使用最佳参数的模型进行训练和预测
best_classifier = grid_search.best_estimator_
best_classifier.fit(X, y)
predictions = best_classifier.predict(X_new)
在代码中,创建一个分类器对象RandomForestClassifier()。然后,定义待调优的参数范围param_grid,包含了希望优化的参数及其可能取值的列表。
接下来,使用GridSearchCV类进行参数优化和模型选择。cv参数用于指定交叉验证的折数,这里选择了5折交叉验证。GridSearchCV会自动遍历所有参数组合,并使用交叉验证评估模型性能。
在调用fit()方法进行训练之后,可以通过best_params_和best_score_属性获取最佳参数和对应的模型性能。
可以使用最佳参数的模型进行训练和预测。best_estimator_属性返回了具有最佳参数的分类器对象。使用该对象的fit()方法训练模型,然后可以使用predict()方法进行预测。
字符识别实现与性能评估
字符识别是一个常见的机器学习任务,可以使用交叉验证来更准确地评估模型性能,还可以尝试不同的特征提取方法、调整分类器超参数等来提高性能。
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.svm import SVC# 假设有X和y作为输入数据和目标变量# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建分类器
classifier = SVC()# 训练模型
classifier.fit(X_train, y_train)# 在测试集上进行预测
predictions = classifier.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, predictions)
print("Accuracy: ", accuracy)在代码中,首先将数据集划分为训练集和测试集,其中test_size参数用于控制测试集的比例,这里设置为0.2表示将20%的数据作为测试集。
创建一个分类器对象SVC(),这里选择了支持向量机作为分类器,你也可以选择其他的分类器(如决策树、随机森林等)。
接下来,使用训练集调用fit()方法对模型进行训练。利用训练好的模型对测试集进行预测,并使用accuracy_score()函数计算分类器在测试集上的准确率,最后,输出准确率即可评估分类器的性能。
相关文章:
基于Python的车牌识别系统实现
本文将以基于Python的车牌识别系统实现为方向,介绍车牌识别技术的基本原理、常用算法和方法,并详细讲解如何利用Python语言实现一个完整的车牌识别系统。 精彩专栏持续更新推荐订阅,收藏关注不迷路 微信小程序实战开发专栏 目录 引言车牌识别…...
时间序列预测模型介绍及使用经验总结
1. 时序预测背景 时序数据,就是序列随时间变化的数据。时间序列分析,一般有时域和频域两种分析方法。时序预测的本质是在时域和频域层面探索时间序列变化的内在规律。 下图描述的是时域(temporal domain),横坐标是时…...
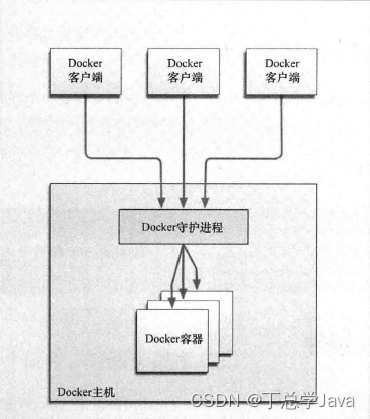
Docker知识总结
文章目录 Docker1 Docker简介1.1 什么是虚拟化1.2 什么是Docker1.3 容器与虚拟机比较1.4 Docker 组件1.4.1 Docker服务器与客户端1.4.2 Docker镜像与容器1.4.3 Registry(注册中心) 2 Docker安装与启动2.1 安装Docker2.2 设置ustc的镜像2.3 Docker的启动与…...

算法训练营Day25
#Java #回溯 开源学习资料 Feeling and experiences: 复原IP地址:力扣题目链接 有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 . 分隔。 例如࿱…...
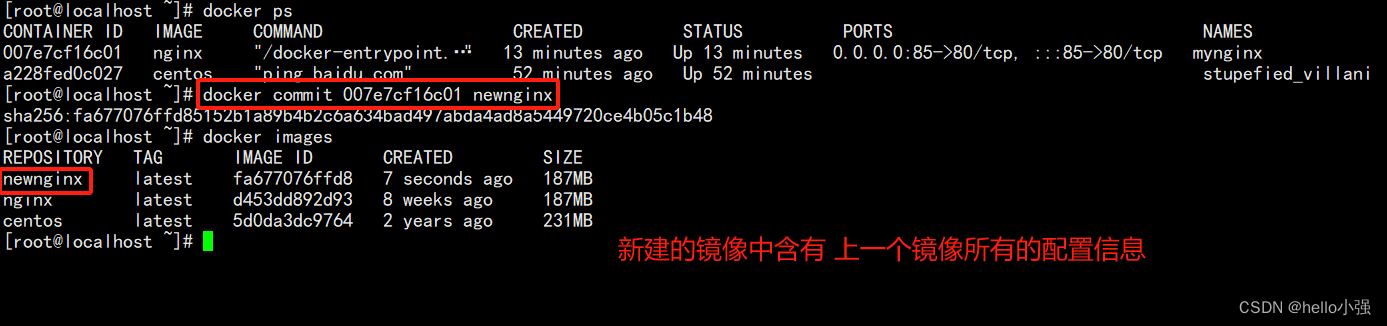
docker笔记2-docker 容器
docker 容器的运行 docker run 镜像名:版本标签: 创建 启动容器 docker run 镜像名 ,如果镜像不存在,则会在线下载镜像。 注意事项: 容器内的进程必须处于前台运行状态,不能后台(守护进程运行…...
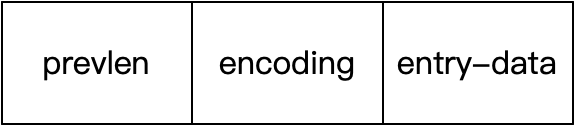
redis 从0到1完整学习 (七):ZipList 数据结构
文章目录 1. 引言2. redis 源码下载3. zipList 数据结构3.1 整体3.2 entry 数据结构分析3.3 连锁更新 4. 参考 1. 引言 前情提要: 《redis 从0到1完整学习 (一):安装&初识 redis》 《redis 从0到1完整学习 (二&am…...

2015年第四届数学建模国际赛小美赛C题科学能解决恐怖主义吗解题全过程文档及程序
2015年第四届数学建模国际赛小美赛 C题 科学能解决恐怖主义吗 原题再现: 为什么人们转向恐怖主义,特别是自杀性恐怖主义?主要原因是什么?这通常是大问题和小问题的结合,或者是一些人所说的“推拉”因素。更大的问题包…...
基于Java开发的微信约拍小程序
一、系统架构 前端:vue | element-ui 后端:springboot | mybatis 环境:jdk8 | mysql8 | maven | mysql 二、代码及数据库 三、功能说明 01. 首页 02. 授权登录 03. 我的 04. 我的-编辑个人资料 05. 我的-我的联系方式 06. …...

蓝桥杯的学习规划
c语言基础: Python语言基础 学习路径:画框的要着重学习...
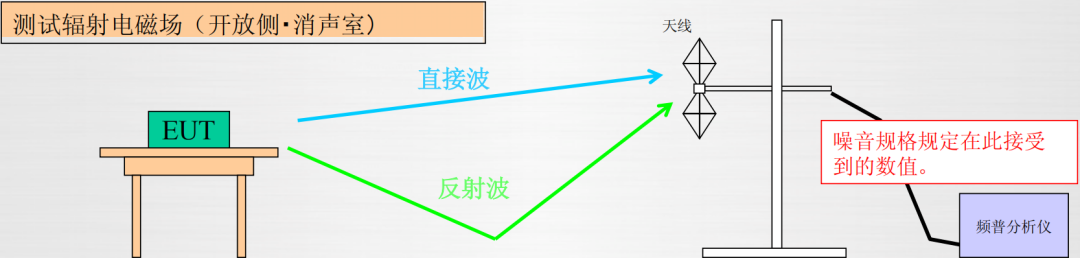
EMC噪声的本质
01 频谱的含义 频谱是将电磁波分解为正弦波分量,并按波长顺序排列的波谱,就是将具有复杂组成的东西分解(频谱分析仪)为单纯成分,并把这些成分按其特征量的大小依序排列(部分不计),…...
)
Redis遇到过的问题 (Could not get a resource from the pool )
生产上通过scan命令,查询一个大key耗时40s后,报 Could not get a resource from the pool,初步报错是连接池的连接数不够,从网上搜了一些解决方案。 排查过程: 一、首先需要先尝试连接redis,如果连接不上那…...

Spring Boot 3.2 新特性之 HTTP Interface
SpringBoot 3.2引入了新的 HTTP interface 用于http接口调用,采用了类似 openfeign 的风格。 具体的代码参照 示例项目 https://github.com/qihaiyan/springcamp/tree/master/spring-http-interface 一、概述 HTTP Interface 是一个类似于 openfeign 的同步接口调…...
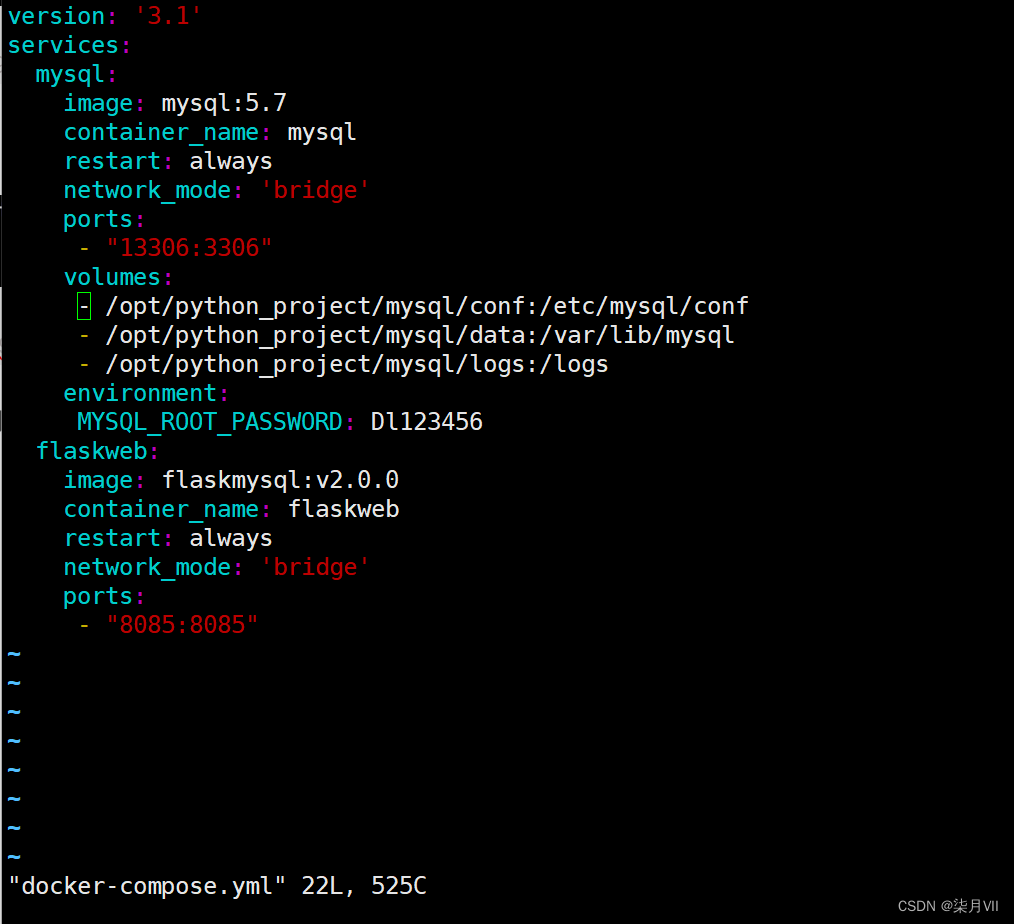
Flask+Mysql项目docker-compose部署(Pythondocker-compose详细步骤)
一、前言 环境: Linux、docker、docker-compose、python(Flask)、Mysql 简介: 简单使用Flask框架写的查询Mysql数据接口,使用docker部署,shell脚本启动 优势: 采用docker方式部署更加便于维护,更加简单快…...

DDOS攻击简介——什么是DDOS
DDoS是什么? DDoS是分布式拒绝服务攻击(Distributed denial of service attack)的简称。 分布式拒绝服务器攻击(以下均称作DDoS)是一种可以使很多计算机(或服务器)在同一时间遭受攻击,使被攻击的目标无法正常使用的一种网络攻击方式。DDoS攻击在互联网上已经出现过…...

龙蜥开源操作系统能解决CentOS 停服造成的空缺吗?
龙蜥开源操作系统能解决CentOS 停服造成的空缺吗? 本文图片来源于龙蜥,仅做介绍时引用用途,版权归属龙蜥和相关设计人员。 一、《国产服务器操作系统发展报告(2023)》称操作系统已步入 2.0 时代,服务器操作…...
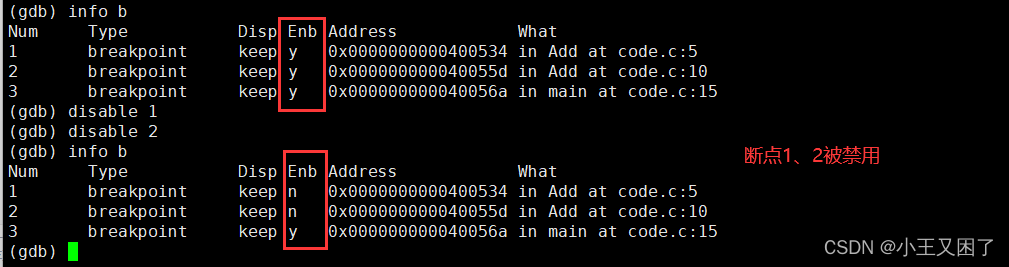
『Linux升级路』基础开发工具——gdb篇
🔥博客主页:小王又困了 📚系列专栏:Linux 🌟人之为学,不日近则日退 ❤️感谢大家点赞👍收藏⭐评论✍️ 目录 一、背景知识介绍 二、gdb指令介绍 一、背景知识介绍 在软件开发中,…...

边缘计算云边端全览—边缘计算系统设计与实践【文末送书-10】
文章目录 一.边缘计算1.1边缘计算的典型应用 二.边缘计算 VS 云计算三.边缘计算系统设计与实践【文末送书-10】3.1 粉丝福利:文末推荐与福利免费包邮送书! 一.边缘计算 边缘计算是指在靠近物或数据源头的一侧,采用网络、计算、存储、应用核心…...
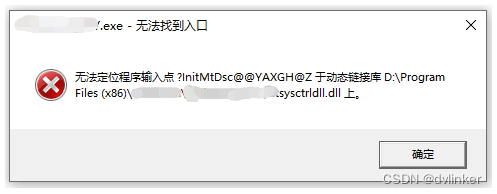
使用PE信息查看工具和Dependency Walker工具排查因为库版本不对导致程序启动报错的问题
目录 1、问题说明 2、问题分析思路 3、问题分析过程 3.1、使用Dependency Walker打开软件主程序,查看库与库的依赖关系,找出出问题的库 3.2、使用PE工具查看dll库的时间戳 3.3、解决办法 4、最后 VC常用功能开发汇总(专栏文章列表&…...

Servlet技术之Cookie对象与HttpSession对象
系列文章目录 提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加 Servlet技术之Cookie对象与HttpSession对象 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前…...

winlogbeat收集Windows事件日志传给ELK
服务器部署winlogbeat后,修改winlogbeat.yml: ###################### Winlogbeat Configuration Example ######################### This file is an example configuration file highlighting only the most common # options. The winlogbeat.reference.yml fi…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

(二)TensorRT-LLM | 模型导出(v0.20.0rc3)
0. 概述 上一节 对安装和使用有个基本介绍。根据这个 issue 的描述,后续 TensorRT-LLM 团队可能更专注于更新和维护 pytorch backend。但 tensorrt backend 作为先前一直开发的工作,其中包含了大量可以学习的地方。本文主要看看它导出模型的部分&#x…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...

从面试角度回答Android中ContentProvider启动原理
Android中ContentProvider原理的面试角度解析,分为已启动和未启动两种场景: 一、ContentProvider已启动的情况 1. 核心流程 触发条件:当其他组件(如Activity、Service)通过ContentR…...
0609)
书籍“之“字形打印矩阵(8)0609
题目 给定一个矩阵matrix,按照"之"字形的方式打印这个矩阵,例如: 1 2 3 4 5 6 7 8 9 10 11 12 ”之“字形打印的结果为:1,…...