PostgreSQL 可观测性最佳实践
简介
软件简述
PostgreSQL 是一种开源的关系型数据库管理系统 (RDBMS),它提供了许多可观测性选项,以确保数据库的稳定性和可靠性。
可观测性
可观测性(Observability)是指对数据库状态和操作进行监控和记录,以便在系统出现问题时能够快速诊断和修复。
数据采集
观测云提供了一套简单且高效的 PostgreSQL 观测方案,帮助客户快速定位及解决数据库相关问题。

DataKit 是观测云开发的一款开源、一体式的数据采集 Agent,它提供全平台操作系统支持,拥有全面数据采集能力,涵盖主机、容器、中间件、链路、日志以及安全等各种场景。通过其采集 PostgreSQL 数据只需要两步:
- 第一步:安装 DataKit 数据采集器
- 第二步:通过 DataKit 内置的 Postgresql 插件采集数据
配置示例:
[[inputs.postgresql]]address = "postgres://postgres@localhost/test?sslmode=disable"interval = "60s"[[inputs.postgresql.relations]]relation_regex = "test*"schemas = ["public"]relkind = ["r", "p"][inputs.postgresql.log]files = ["/var/log/pgsql/*.log""]pipeline = "postgresql.p"指标详解
PostgreSQL 拥有众多的监控指标,通过 SQL 命令可以查看系统变量、系统函数和系统视图等信息。观测云已经把这些 SQL 编写成内置的指标集形式,开箱即用。
1.pg_stat_database (datakit postgresql)
示例语句:
postgres=# select * from pg_stat_database where datname='postgres';
-[ RECORD 1 ]------------+------------------------------
datid | 14486
datname | postgres
numbackends | 2
xact_commit | 1406600
xact_rollback | 20720
blks_read | 1558
blks_hit | 48043798
tup_returned | 289085449
tup_fetched | 21237763
tup_inserted | 174
tup_updated | 5
tup_deleted | 41
conflicts | 0
temp_files | 0
temp_bytes | 0
deadlocks | 0
checksum_failures |
checksum_last_failure |
blk_read_time | 0
blk_write_time | 0
session_time | 1030041341.636
active_time | 1740209.944
idle_in_transaction_time | 879253.682
sessions | 15950
sessions_abandoned | 2
sessions_fatal | 0
sessions_killed | 4
stats_reset | 2023-04-06 11:04:11.693074+08
通过 pg_stat_database 可以基本了解数据库的整体运行情况。
- 当 tup_returned 值远大于 tup_fetched,说明数据库历史执行的 sql 很多都是全表扫描,存在很多没有走索引的 sql,这时候可以结合 pg_stat_statments 来查找慢 sql,也可以通过 pg_stat_user_tables 找到全表扫描次数和行数最多的表。
- 当 tup_updated 很高说明数据库有很频繁的更新,这个时候就需要关注一下 vacuum 相关的指标和长事务,如果没有及时进行垃圾回收会造成数据膨胀的比较厉害,一定程度会响应表查询效率。
- 当 temp_files 的数值比较大时,说明存在很多的排序 hash,或者聚合操作,可以通过增大 work_mem 减少临时文件的产生,并且同时这些操作的性能也会有较大的提升。
2.pg_stat_user_tables (datakit postgresql_stat)
示例语句:
select * from pg_stat_user_tables where relname='test';
-[ RECORD 1 ]-------+--------
relid | 16455
schemaname | public
relname | test
seq_scan | 1
seq_tup_read | 0
idx_scan | 0
idx_tup_fetch | 0
n_tup_ins | 7
n_tup_upd | 0
n_tup_del | 0
n_tup_hot_upd | 0
n_live_tup | 7
n_dead_tup | 0
n_mod_since_analyze | 7
n_ins_since_vacuum | 7
last_vacuum |
last_autovacuum |
last_analyze |
last_autoanalyze |
vacuum_count | 0
autovacuum_count | 0
analyze_count | 0
autoanalyze_count | 0
通过 pg_stat_user_tables ,可以知道当前数据库下哪些表发生全表扫描频繁,哪些表变更比较频繁,对于变更较频繁的表可多关注其 vacuum 相关的指标,避免表膨胀。
3.pg_stat_user_indexes (datakit postgresql_index)
示例语句:
select * from pg_stat_user_indexes where relname='test';
-[ RECORD 1 ]-+-------------
relid | 16455
indexrelid | 16460
schemaname | public
relname | test
indexrelname | test_pkey
idx_scan | 0
idx_tup_read | 0
idx_tup_fetch | 0
通过 pg_stat_user_indexes 可以查看对应索引的使用情况,协助我们判断哪些索引当前基本不使用,对这些无效的冗余索引,可进行删除。
4.pg_statio_user_tables (datakit postgresql_statio)
示例语句:
select * from pg_statio_user_tables where relname='test';
-[ RECORD 1 ]---+--------
relid | 16455
schemaname | public
relname | test
heap_blks_read | 1
heap_blks_hit | 6
idx_blks_read | 2
idx_blks_hit | 8
toast_blks_read | 0
toast_blks_hit | 0
tidx_blks_read | 0
tidx_blks_hit | 0
通过对 pg_statio_user_tables 的查询,如果 heap_blks_read,idx_blks_read 很高说明 shared_buffer 较小,存在频繁需要从磁盘或者 page cache 读取到 shared_buffer 中。
5.pg_stat_bgwriter (datakit postgresql_bgwriter)
示例语句:
select * from pg_stat_bgwriter;
-[ RECORD 1 ]---------+------------------------------
checkpoints_timed | 14438
checkpoints_req | 14
checkpoint_write_time | 64064
checkpoint_sync_time | 83
buffers_checkpoint | 656
buffers_clean | 0
maxwritten_clean | 0
buffers_backend | 220
buffers_backend_fsync | 0
buffers_alloc | 4674
stats_reset | 2023-04-06 11:00:39.227749+08
通过对 pg_stat_bgwriter 的查询,可以查看后端写进程活动的统计信息。bgwriter、checkpointer 和 backend 都可能把脏数据回写到存储上。正常情况下,我们希望大部分的脏数据都是 bgwriter 写回存储的,少量的脏数据是 checkpoint 写入的,更少的数据是 backend 写入的。因为 backend 写入数据是十分高成本的,不过好像事实上并非如此,backend 写入的比例很高。
6.pg_stat_replication (datakit postgresql_replication)
示例语句:
select * from pg_stat_replication;
-[ RECORD 1 ]----+-----------------------------
pid | 1492
usesysid | 12849
usename | guance
application_name | walreceiver
client_addr | 192.168.0.187
client_hostname |
client_port | 41760
backend_start | 2023-05-12 16:41:09.54947+08
backend_xmin |
state | streaming
sent_lsn | 2/100001B0
write_lsn | 2/100001B0
flush_lsn | 2/100001B0
replay_lsn | 2/100001B0
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | async
pg_stat_replication 仅仅在主从架构下才会显示相关数据,根据对 pg_stat_replication 表的查询可以查看当前复制的模式、复制配置信息、复制位点信息等。
例如 sync_state 可以分为 :
- async:表示备库为异步同步模式
- potential :表示备库当前为异步同步模式,如果当前的同步备库宕机,异步备库可升级成为同步备库
- sync : 表示当前备库为同步模式
- quorum :表示备库为 quorumstandbys 的候选
日志相关
PostgreSQL 有 3 种日志,分别是:
| 日志目录 | 作用 | 可读性 | 默认状态 |
|---|---|---|---|
| pg_log | 数据库运行日志 | 内容可读 | 默认关闭,需要设置参数启动 |
| pg_xlog | WAL 日志,即重做日志 | 内容一般不具有可读性 | 强制开启 |
| pg_clog | 事务提交日志,记录的是事务的元数据 | 内容一般不具有可读性 | 强制开启 |
日志路径
pg_xlog 和 pg_clog 一般是在 postgresql 安装目录的文件夹下。
pg_log 默认路径是 postgresql 安装目录下的 pg_log,实际路径可以在 postgresql.conf 文件中设置。
日志解析
1.pg_log
这个日志一般是记录服务器与 DB 的状态,比如各种 Error 信息,定位慢查询 SQL,数据库的启动关闭信息,发生 checkpoint 过于频繁等的告警信息,诸如此类。该日志有 .csv 格式和 .log。建议使用 .csv 格式,因为它一般会按大小和时间自动切割,毕竟查看一个巨大的日志文件比查看不同时间段的多个日志要难得多。
清理原则:pg_log 是可以被 清理删除,压缩打包或者转移,同时并 不影响 数据库的正常运行。
2.pg_xlog
这个日志是记录的 Postgresql 的 WAL 信息,也就是一些事务日志信息 (transaction log)。这种日志形如 ‘00000001000000000000008E’,包含的是最近失误的数据镜像,这些日志会在定时回滚恢复(PITR),流复制(Replication Stream)以及归档时能被用到。
当你的归档或者流复制发生异常的时候,事务日志会不断地生成,有可能会造成你的磁盘空间被塞满,最终导致数据库挂掉或者起不来。遇到这种情况不用慌,可以先关闭归档或者流复制功能,备份 pg_xlog 日志到其他地方,但不要删除,然后删除较早时间的的 pg_xlog,有一定空间后再试着启动 Postgresql。
清理原则:这些日志 非常重要 ,记录着数据库发生的各种事务信息,不得随意删除 或者移动这类日志文件,不然你的数据库会有 无法恢复 的风险。
什么是 WAL ?
PostgreSQL 在将缓存的数据刷入到磁盘之前,先写日志,这就是PostgreSQL WAL ( Write-Ahead Log ) 方式,也就是预写日志方式 。
3.pg_clog
pg_clog 这个文件也是事务日志文件,但与 pg_xlog 不同的是它记录的是事务的元数据 (metadata),这个日志告诉我们哪些事务完成了,哪些没有完成。
清理原则:这个日志文件一般非常小,但是 重要性 也是相当高,不得随意删除 或者对其更改信息。
日志配置
可以通过配置文件 postgresql.conf 进行设置
主要参数说明:
- logging_collector = on/off
是否将日志重定向至文件中,默认是 off。 - log_directory =
pg_log
日志文件目录,默认是 pgdata 的相对路径,即 pgdata 的相对路径,即 {pgdata}/pg_log,也可以改为绝对路径。日志文件可能会非常多,建议将日志重定向到其他目录或分区。将此配置修改其他目录时,必须先创建此目录,并修改权限,使得 postgres 用户对该目录有写权限。 - log_filename =
postgresql-%Y-%m-%d*%H%M%S.log
日志文件命名形式,使用默认即可 - log_rotation_age = 1d
单个日志文件的生存期,默认 1 天,在日志文件大小没有达到 log_rotation_size 时,一天只生成一个日志文件。 - log_rotation_size = 10MB
单个日志文件的大小,如果时间没有超过 log_rotation_age,一个日志文件最大只能到 10M,否则将新生成一个日志文件。 - log_truncate_on_rotation = off
当日志文件已存在时,该配置如果为 off,新生成的日志将在文件尾部追加,如果为 on,则会覆盖原来的日志。 - log_lock_waits = off
控制当一个会话等待时间超过 deadlock_timeout 而被锁时是否产生一个日志信息。在判断一个锁等待是否会影响性能时是有用的,缺省是 off。 - log_statement =
none# none, ddl, mod, all
控制记录哪些 SQL 语句。none 不记录,ddl 记录所有数据定义命令,比如 CREATE,ALTER 和 DROP 语句。mod 记录所有 ddl 语句,加上数据修改语句 INSERT,UPDATE 等。all 记录所有执行的语句,将此配置设置为 all 可跟踪整个数据库执行的 SQL 语句。 - log_duration = off
记录每条 SQL 语句执行完成消耗的时间,将此配置设置为 on ,用于统计哪些 SQL 语句耗时较长。 - log_min_duration_statement = -1
-1 表示关闭记录。0 表示记录所有 statements 的执行时间按,若为>0(单位为 ms)的一个值,则记录执行时间大于该值的 statements。可以使用该配置来跟踪那些耗时较长,可能存在性能问题的 SQL 语句。虽然使用 log_statement 和 log_duration 也能够统计 SQL 语句及耗时,但是 SQL 语句和耗时统计结果可能相差很多行,或在不同的文件中,但是 log_min_duration_statement 会将 SQL 语句和耗时在同一行记录,更方便阅读。 - log_connections = off
是否记录连接日志 - log_disconnections = off
是否记录连接断开日志 - log_line_prefix =
%m %p %u %d %r
日志输出格式(%m,%p 实际意义配置文件中有解释),可根据自己需要设置(能够记录时间,用户名称,数据库名称,客户端 IP 和端口,方便定位问题)。 - log_timezone =
Asia/Shanghai
日志时区,最好和服务器设置同一个时区,方便问题定位
场景视图
观测云已经内置了 PostgreSQL 的场景视图,直接使用即可,用户也可以自定义修改任何想要的指标视图。
添加方式
登录「观测云控制台」-「场景」-「仪表板」-「新建仪表板」-「系统视图」,搜索“PostgreSQL”,添加即可。
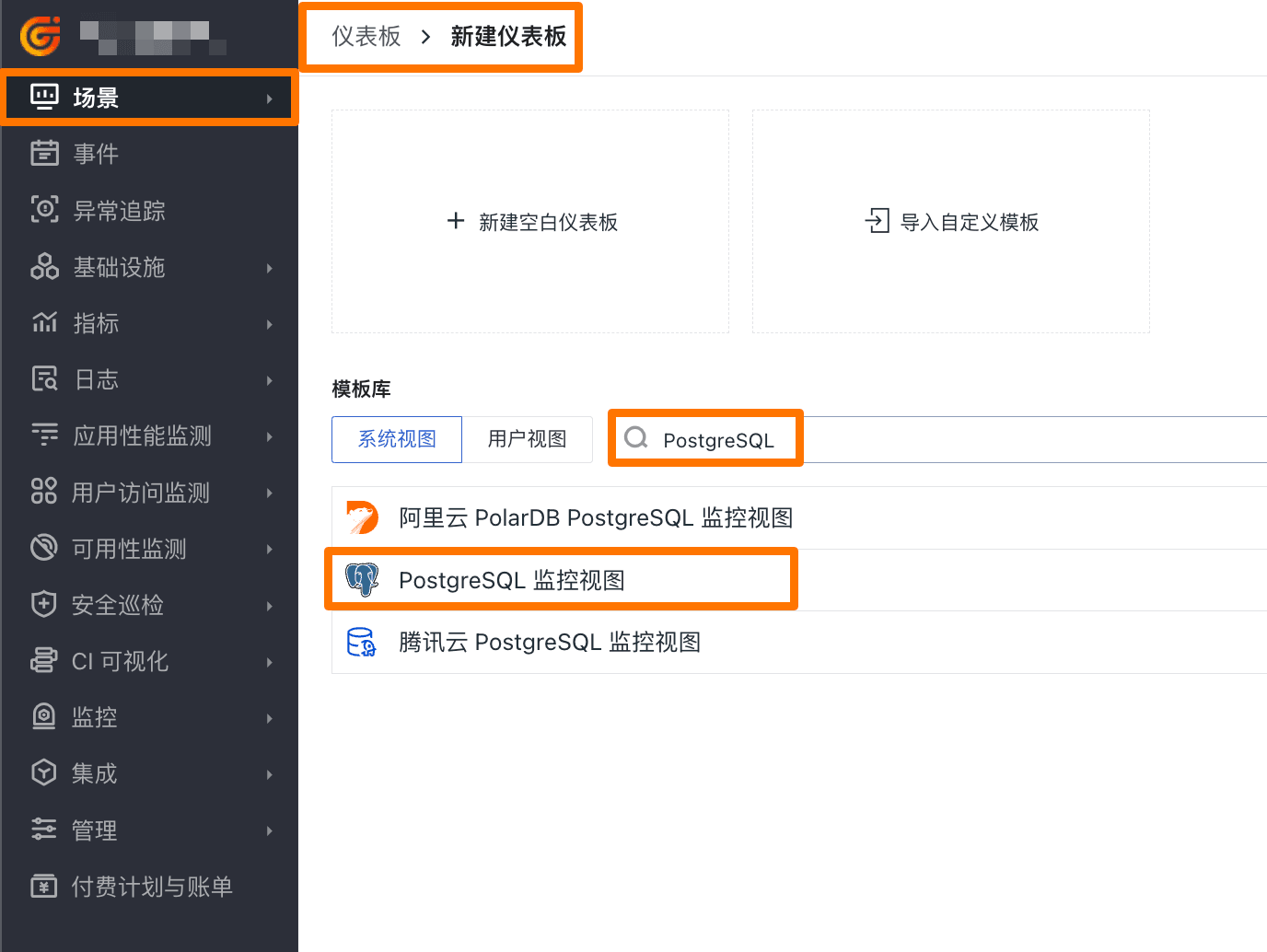
效果展示
若想要在此基础上自定义图表,可以参考《观测云文档:可视化图表》。



相关文章:
PostgreSQL 可观测性最佳实践
简介 软件简述 PostgreSQL 是一种开源的关系型数据库管理系统 (RDBMS),它提供了许多可观测性选项,以确保数据库的稳定性和可靠性。 可观测性 可观测性(Observability)是指对数据库状态和操作进行监控和记录,以便在…...
51单片机相关寄存器
前言 单片机复习的时候对应寄存器的记忆感觉很混乱,这里进行一下整理,后面的单词是我用来辅助记忆的,可能并不是表示原本的含义。 P3口的第二功能 0RXD 串行数据输入口 1TXD串行数据输出口2INT0外部中断0输入3INT1外部中断1输入4T0定时器0外部计数输入…...

二叉树进阶题目(超详解)
文章目录 前言根据二叉树创建字符串题目分析写代码 二叉树的层序遍历题目分析 写代码二叉树的层序遍历II题目分析写代码 二叉树的最近公共祖先题目分析写代码时间复杂度 优化思路优化的代码 二叉搜索树与双向链表题目分析写代码 从前序与中序遍历序列构造二叉树题目分析写代码从…...
W6100-EVB-Pico评估版介绍
文章目录 1 简介2 硬件资源2.1 硬件规格2.2 引脚定义2.3 工作条件 3 参考资料3.1 Datasheet3.2 原理图3.3 尺寸图(尺寸:mm)3.4 参考例程 4 硬件协议栈优势 1 简介 W6100-EVB-Pico是一款基于树莓派RP2040和全硬件TCP/IP协议栈以太网芯片W6100的…...
嵌入式面试准备
题目都摘于网上 嵌入式系统中经常要用到无限循环,如何用C编写死循环 while(1){}或者for(;😉 内存分区 代码区,全局区(全局变量,静态变量,以及常量),栈区,堆区 const关键…...

在Linux Docker中部署RStudio Server,实现高效远程访问
🌈个人主页:聆风吟 🔥系列专栏:网络奇遇记、Cpolar杂谈 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 📋前言一. 安装RStudio Server二. 本地访问三. Linux 安装cpolar四. 配置RStudio serv…...
EternalBlue【永恒之蓝】漏洞详解(复现、演示、远程、后门、入侵、防御)内容丰富-深入剖析漏洞原理-漏洞成因-以及报错解决方法-值得收藏!
漏洞背景: 1.何为永恒之蓝? 永恒之蓝(Eternal Blue)爆发于2017年4月14日晚,是一种利用Windows系统的SMB协议漏洞来获取系统的最高权限,以此来控制被入侵的计算机。甚至于2017年5月12日, 不法分子…...
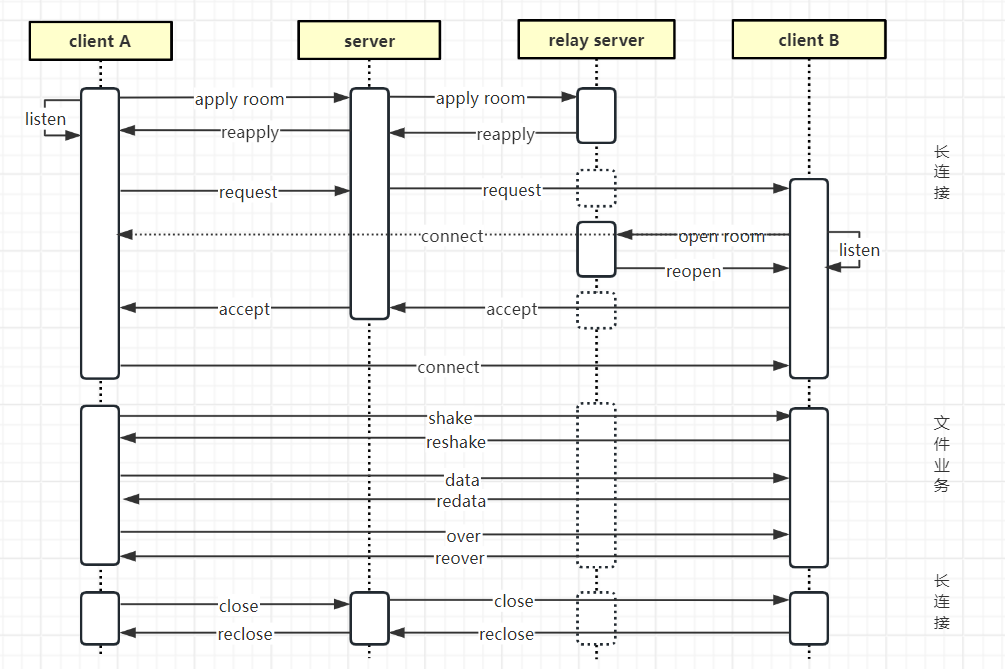
长链接与在线文件
什么是在线文件 常见的聊天工具,比如。。。微信,你可以发送一个文件给对端,即使对端不在线,这个文件也可以暂存在服务器上面,直到接收端上线消费或者超时,这个叫离线文件。与之对应的,在线文件要…...
法)
Python内置数据类型等入门语(句)法
内置数据类型 数字(Number)关键字: int 、float、complex字符串(String)关键字:单引号,双引号 三引号都可以表示,8 种内置类型都可转为字符串类型列表(List) 关键符号 […...
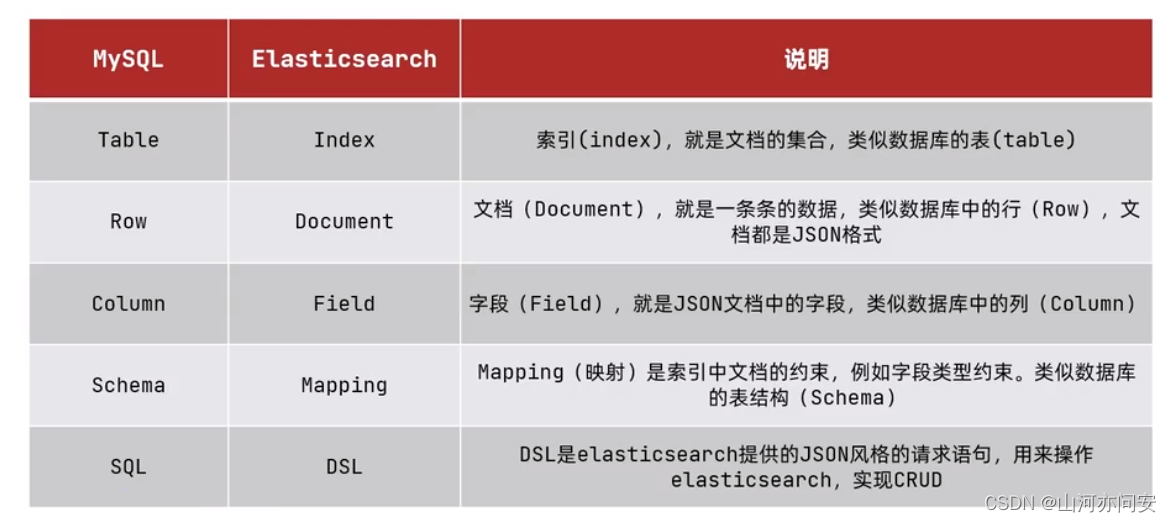
ElasticSearch之RestClient笔记
1. ElasticSearch 1.1 倒排索引 1.2 ElasticSearch和Mysql对比 1.3 RestClient操作 导入依赖 <dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.15.…...

饥荒Mod 开发(二二):显示物品信息
饥荒Mod 开发(二一):超大便携背包,超大物品栏,永久保鲜 饥荒Mod 开发(二三):显示物品栏详细信息 饥荒中的物品没有详细信息,基本上只有一个名字,所以很多物品的功能都不知道,比如浆果吃了也不知…...

Microsoft Edge使用方法和心得
Microsoft Edge使用方法和心得 大家好,我是豪哥,一名来自杭州的Java程序员,今天我想分享一下我对Microsoft Edge的使用方法和心得。作为一名热爱编程的程序员,我发现一个高效的浏览器对于我们的工作和学习至关重要。而Microsoft …...

Kafka操作指令笔记
查堆积用命令查: ./kafka-consumer-groups.sh --bootstrap-server {kafka集群地址} --describe --group {消费组名称}bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --all-groups #查看所有组别的积压情况可以通过grep、awk或其他文…...

WAVE SUMMIT+ 2023倒计时2天,传文心一言将曝最新进展!
传文心一言将曝最新进展! 亮点一:趋势引领,“扛把子”文心一言将曝新进展亮点二:干货十足,硬核低门槛开发秘籍大放送亮点三:蓄势待发,大模型赋能产业正当时亮点四:群星闪耀ÿ…...

Crow:Middlewares 庖丁解牛5 context
Crow:Middlewares 庖丁解牛4 partial_context-CSDN博客 基于partial_context再来解释context namespace detail {template<typename... Middlewares>struct partial_context : public pop_back<Middlewares...>::template rebind<partial_context>, public…...
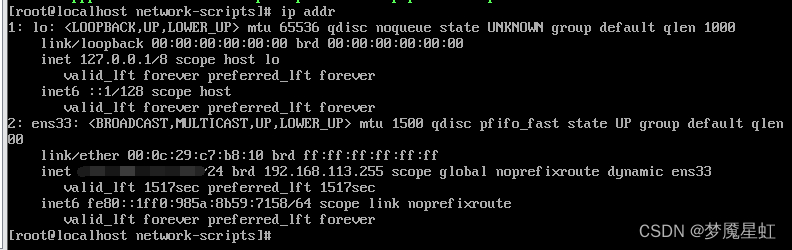
CentOS 7 设置网络
CentOS 7 设置网络 正常情况 ①登陆进去之后使用下面的命令修改文件 echo ONBOOTyes >> /etc/sysconfig/network-scripts/ifcfg-ens33②如果是虚拟机重启后使用如下命令进行查看IP地址 ip addr注:到这里如果显示有两部分,则代表网络设置成功&a…...
)
装饰器模式(Decorator)
装饰器模式(Decorator Pattern)是一种结构型设计模式,用于动态地给一个对象添加额外的职责。装饰器提供了一个灵活的替代扩展功能的方案,相比继承更加灵活。 在Java中,装饰器模式通常涉及以下几个部分: 组件(Component):定义一个对象接口,可以给这些对象动态添加职责…...

关于“Python”的核心知识点整理大全34
目录 第13 章 外星人 13.1 回顾项目 game_functions.py 13.2 创建第一个外星人 13.2.1 创建 Alien 类 alien.py 13.2.2 创建 Alien 实例 alien_invasion.py 13.2.3 让外星人出现在屏幕上 game_functions.py 13.3 创建一群外星人 13.3.1 确定一行可容纳…...
设计模式--抽象工厂模式
实验4:抽象工厂模式 本次实验属于模仿型实验,通过本次实验学生将掌握以下内容: 1、理解抽象工厂模式的动机,掌握该模式的结构; 2、能够利用抽象工厂模式解决实际问题。 [实验任务]:人与肤色 使用抽象…...
浅析海博深造
文章目录 深造作用 留学种类 选专业 择校 申请流程 申请方式 深造作用 1、个人能力提升(学术专业、语言、新文化或新生活方式) 2、更好的职业发展(起点更高、结交新朋友或扩大社交圈) 3、北京上海落户优惠 4、海外居留福…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...