kafka发送大消息
1 kafka消息压缩
kafka关于消息压缩的定义(来源于官网):
此为 Kafka 中端到端的块压缩功能。如果启用,数据将由 producer 压缩,以压缩格式写入服务器,并由 consumer 解压缩。压缩将提高 consumer 的吞吐量,但需付出一定的解压成本。
压缩就是用时间换空间,其基本理念是基于重复,将重复的片段编码为字典,字典的 key 为重复片段,value 为更短的代码,比如序列号,然后将原始内容中的片段用代码表示,达到缩短内容的效果,压缩后的内容则由字典和代码序列两部分组成。解压时根据字典和代码序列可无损地还原为原始内容。通常来讲,重复越多,压缩效果越好。比如 JSON 是 Kafka 消息中常用的序列化格式,单条消息内可能并没有多少重复片段,但如果是批量消息,则会有大量重复的字段名,批量中消息越多,则重复越多,这也是为什么 Kafka 更偏向块压缩,而不是单条消息压缩。
2 kafka的消息压缩类型对比
目前 Kafka 共支持四种主要的压缩类型:Gzip、Snappy、Lz4 和 Zstd。关于这几种压缩的特性。
| 压缩类型 | 压缩率 | CPU 使用率 | 压缩速度 | 带宽使用率 |
|---|---|---|---|---|
| Gzip | Highest | Highest | Slowest | Lowest |
| Snappy | Medium | Moderate | Moderate | Medium |
| Lz4 | Low | Lowest | Fastest | Highest |
| Zstd | Medium | Moderate | Moderate | Medium |
从上表可知,Snappy 在 CPU 使用率、压缩比、压缩速度和网络带宽使用率之间实现良好的平衡,我们最终也是采用的该类型进行压缩试点。这里值得一提的是,Zstd 是 Facebook 于 2016 年开源的新压缩算法,压缩率和压缩性能都不错,具有与 Snappy(Google 杰作)相似的特性,直到 Kafka 的 2.1.0 版本才引入支持。
3 何时需要压缩
压缩是需要额外的 CPU 代价的,并且会带来一定的消息分发延迟,因而在压缩前要慎重考虑是否有必要。
- 压缩带来的磁盘空间和带宽节省远大于额外的 CPU 代价,这样的压缩是值得的。
- 数据量足够大且具重复性。消息压缩是批量的,低频的数据流可能都无法填满一个批量,会影响压缩比。数据重复性越高,往往压缩效果越好,例如 JSON、XML 等结构化数据;但若数据不具重复性,例如文本都是唯一的 md5 或 UUID 之类,违背了压缩的重复性前提,压缩效果可能不会理想。
- 系统对消息分发的延迟没有严苛要求,可容忍轻微的延迟增长。
4 如何开启压缩
Kafka 通过配置属性 compression.type 控制是否压缩。该属性在 producer 端和 broker 端各自都有一份,也就是说,我们可以选择在 producer 或 broker 端开启压缩,对应的应用场景各有不同。目前没有尝试在broker段开启压缩。
4.1 在broker端开启解压缩
Broker 端的 compression.type 属性默认值为 producer,即直接继承 producer 端所发来消息的压缩方式,无论消息采用何种压缩或者不压缩,broker 都原样存储。、
4.1.1 broker 和 topic 两个级别
在 broker 端的压缩配置分为两个级别:全局的 broker 级别 和 局部的 topic 级别。顾名思义,如果配置的是 broker 级别,则对于该 Kafka 集群中所有的 topic 都是生效的。但如果 topic 级别配置了自己的压缩类型,则会覆盖 broker 全局的配置,以 topic 自己配置的为准。
broker级别:要配置 broker 级别的压缩类型,可通过 configs 命令修改 compression.type 配置项取值。此处要使修改生效,是否需要重启 broker 取决于 Kafak 的版本,在 1.1.0 之前,任何配置项的改动都需要重启 broker 才生效,而从 1.1.0 版本开始,Kafka 引入了动态 broker 参数,将配置项分为三类:read-only、per-broker 和 cluster-wide,第一类跟原来一样需重启才生效,而后面两类都是动态生效的,只是影响范围不同,关于 Kafka 动态参数,以后单开博文介绍。从 官网 可以看到,compression.type 是属于 cluster-wide 的,如果是 1.1.0 及之后的版本,则无需重启 broker。
topic级别:topic 的配置分为两部分,一部分是 topic 特有的,如 partitions 等,另一部分则是默认采用 broker 配置,但也可以覆盖。如果要定义 topic 级别的压缩,可以在 topic 创建时通过 --config 选项覆盖配置项 compression.type 的取值,命令如下:
sh bin/kafka-topics.sh \
--create \
--topic my-topic \
--replication-factor 1 \
--partitions 1 \
--config compression.type=snappy也可以通过 configs 命令修改 topic 的 compression.type 取值,命令如下:
bin/kafka-configs.sh \
--entity-type topics \
--entity-name my-topic \
--alter \
--add-config compression.type=snappy4.2 在 Producer 端压缩
跟 broker 端一样,producer 端的压缩配置属性依然是 compression.type,只不过默认值和可选值有所不同。默认值为 none,表示不压缩。直接在代码层面更改 producer 的 config。但需要注意的是,改完 config 之后,需要重启 producer 端的应用程序,压缩才会生效。
代码示例如下:
public class KafkaProducerTest {public static void main(String[] args) {String brokerList = "127.0.0.1:9092";Properties properties = new Properties();properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG,"2097245");properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"gzip");KafkaProducer<String, String> producer = new KafkaProducer<>(properties);String topic = "mytestTopic1";int sizeInMb = 2; // 设置字符串大小为2MBint sizeInBytes = sizeInMb * 1024 * 1024; // 转换为字节数StringBuilder largeString = new StringBuilder(sizeInBytes);largeString.append(":");for (int i = 0; i < sizeInBytes; i++) {largeString.append("A"); // 使用大写字母"A"来构建字符串}String msg = largeString.toString();try {for (int i = 0; i < 100; i++) {String msg1 = i+msg;producer.send(new ProducerRecord<>(topic, msg1));Thread.sleep(500);}}catch (Exception e){e.printStackTrace();}}
}上面示例特意制造了一个大字符串作为消息,测试压缩,需要注意的是,配置压缩的时候同时也需要配置消息的最大值。即:max.request.size。
5 解压缩
可能发生解压的地方依然是两处:consumer 端和 broker 端。
consumer端:consumer 端发生解压的唯一条件就是从 broker 端拉取到的消息是带压缩的。此时,consumer 会根据 recordBatch 中 compressionType 来对消息进行解压。
broker端:broker 端是否发生解压取决于 producer 发过来的批量消息 recordBatch 是否是压缩的:如果 producer 开启了压缩,则会发生解压,否则不会。原因简单说下,在 broker 端持久化消息前,会对消息做各种验证,此时必然会迭代 recordBatch,而在迭代的过程中,会直接采用 recordBatch 上的 compressionType 对消息字节流进行处理,是否解压取决于 compressionType 是否是压缩类型。关于这点,可以在 LogValidator 的 validateMessagesAndAssignOffsets 方法实现中可以看到,在 convertAndAssignOffsetsNonCompressed、assignOffsetsNonCompressed 和 validateMessagesAndAssignOffsetsCompressed 三个不同的分支中,都会看到 records.batches.forEach {...} 的身影,而在后面的源码分析中会发现,在 recordBatch 的迭代器逻辑中,直接采用的 compressionType 的解压逻辑对消息字节流读取的。也就是说,如果 recordBatch 是压缩的 ,只要对其进行了迭代访问,则会自动触发解压逻辑。
通俗一点讲:producer端配置了压缩,consumer自动解压缩。
相关文章:

kafka发送大消息
1 kafka消息压缩 kafka关于消息压缩的定义(来源于官网): 此为 Kafka 中端到端的块压缩功能。如果启用,数据将由 producer 压缩,以压缩格式写入服务器,并由 consumer 解压缩。压缩将提高 consumer 的吞吐量…...

React AntDesign form表单文件上传 nodejs formidable 接受参数并把文件放置后端项目相对目录指定文件夹下面
@umijs/max 请求方法 // 上传文件改成form表单 export async function uploadFile(data, options) {return request(CMMS_UI_HOST + /api/v1/uploadFile, {method: POST,data,requestType: form,...(options || {}),}); }前端调用方法 注意upload组件上传 onChange的如下方法,…...

设计模式之-6大设计原则简单易懂的理解以及它们的适用场景和代码示列
系列文章目录 设计模式之-6大设计原则简单易懂的理解以及它们的适用场景和代码示列 设计模式之-单列设计模式,5种单例设计模式使用场景以及它们的优缺点 设计模式之-3种常见的工厂模式简单工厂模式、工厂方法模式和抽象工厂模式,每一种模式的概念、使用…...

css 实现满屏升空的气球动画
最终实现效果 demo放在最后了。。。。 问题一 怎么实现满屏气球?简单理解就是多个气球的合并,难道要写多个盒子吗?确实是这样子,但可以有更好的办法,其实就是通过原生操作多个盒子生成,所以只需要实现一个…...
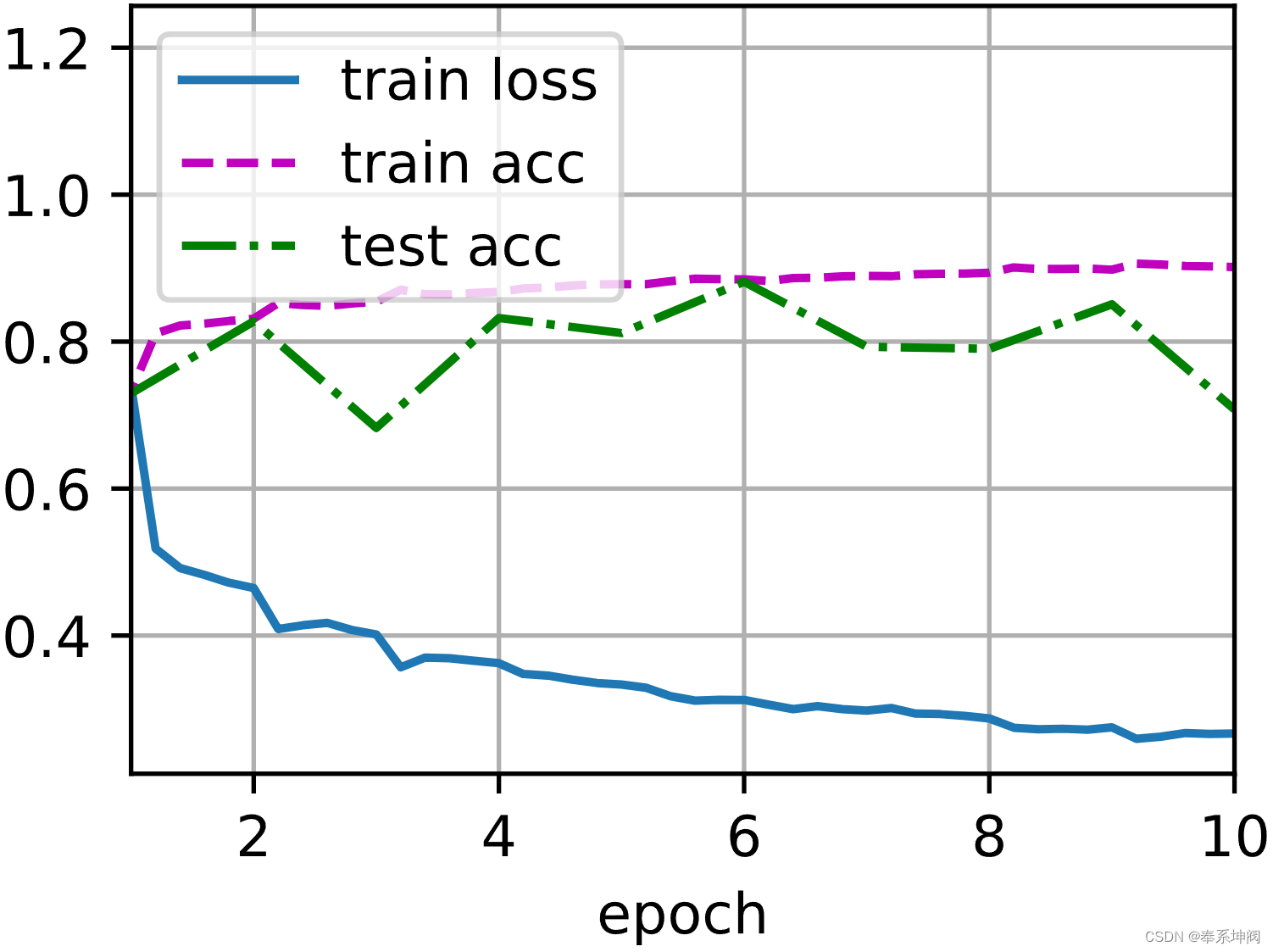
批量归一化
目录 一、BN层介绍 1、深层神经网络存在的问题 2、批量归一化公式的数学推导 3、BN层的作用位置 4、 预测过程中的批量归一化 5、BN层加速模型训练的原因 6、总结 二、批量归一化从零实现 1、实现批量归一化操作 2、创建BN层 3、对LeNet加入批量归一化 4、开始训练…...
C语言:字符串字面量及其保存位置
相关阅读 C语言https://blog.csdn.net/weixin_45791458/category_12423166.html?spm1001.2014.3001.5482 虽然C语言中不存在字符串类型,但依然可以通过数组或指针的方式保存字符串,但字符串字面量却没有想象的这么简单,本文就将对此进行讨论…...

【开源】基于Vue+SpringBoot的新能源电池回收系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 用户档案模块2.2 电池品类模块2.3 回收机构模块2.4 电池订单模块2.5 客服咨询模块 三、系统设计3.1 用例设计3.2 业务流程设计3.3 E-R 图设计 四、系统展示五、核心代码5.1 增改电池类型5.2 查询电池品类5.3 查询电池回…...

共享和独享的区别是什么?有必要用独享IP吗?
通俗地讲,共享IP就像乘坐公共汽车一样,您可以到达目的地,但将与其他乘客共享旅程,座位很可能是没有的。独享IP就像坐出租车一样,您可以更快到达目的地,由于车上只有您一个人,座位是您一个人专用…...
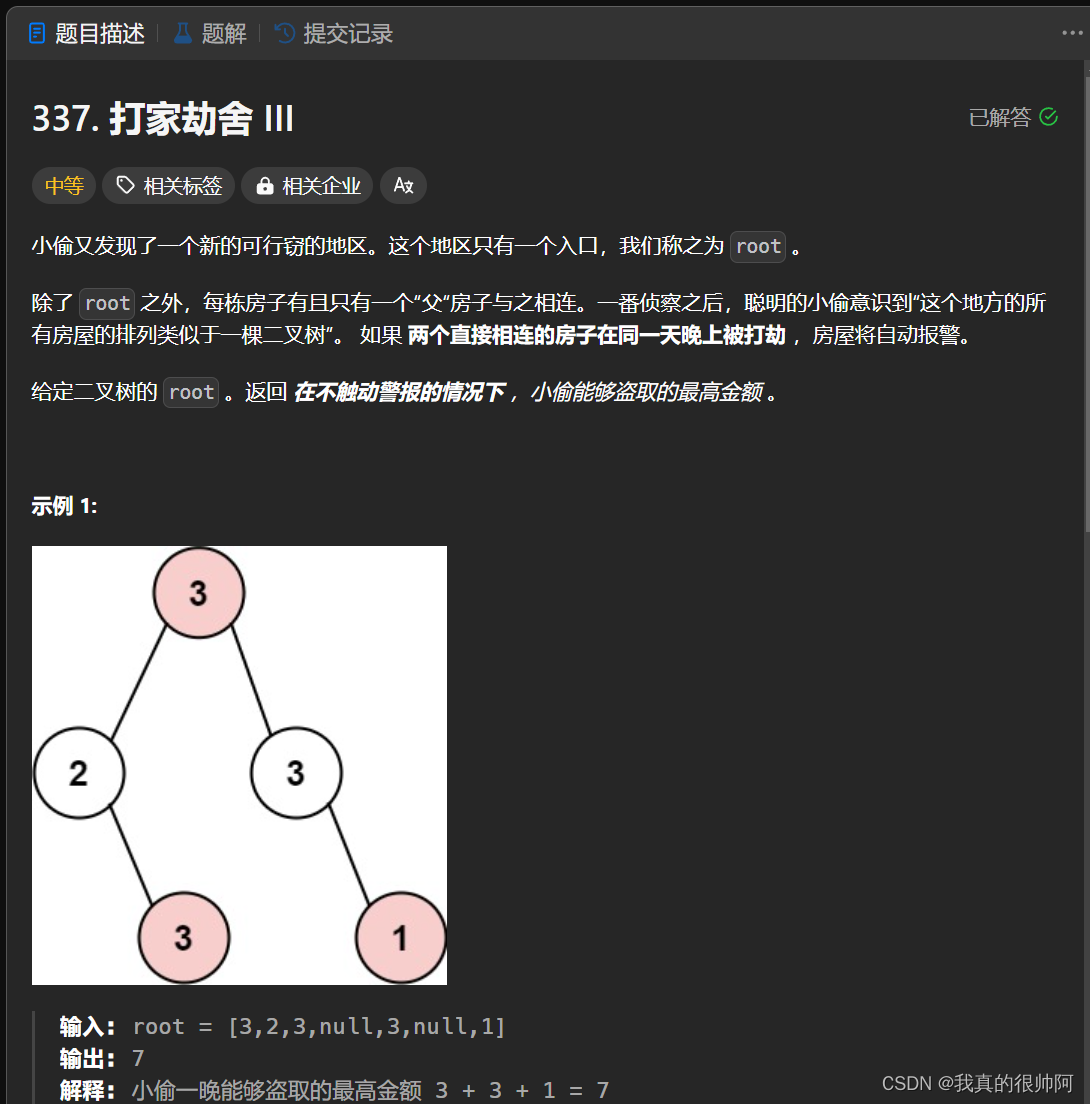
leetcode——打家劫舍问题汇总
本章汇总一下leetcode中的打家劫舍问题,使用经典动态规划算法求解。 1、梦开始的地方——打家劫舍(★) 本题关键点就是不能在相邻房屋偷东西。 采用常规动态规划做法: 根据题意设定dp数组,dp[i]的含义为:…...
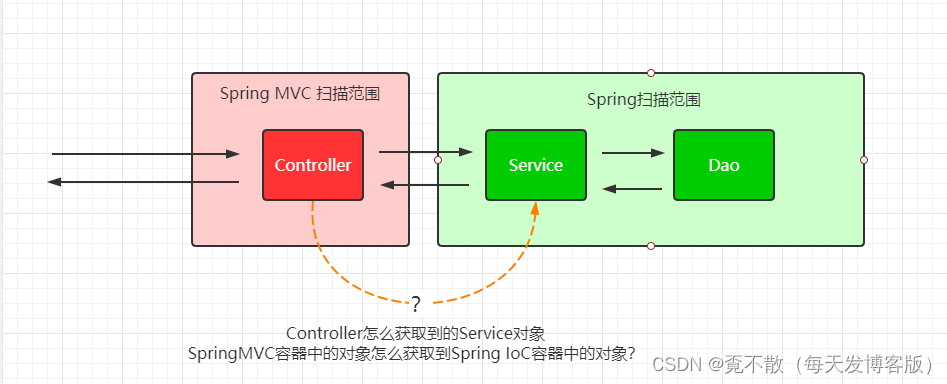
Java经典框架之Spring MVC
Spring MVC Java 是第一大编程语言和开发平台。它有助于企业降低成本、缩短开发周期、推动创新以及改善应用服务。如今全球有数百万开发人员运行着超过 51 亿个 Java 虚拟机,Java 仍是企业和开发人员的首选开发平台。 课程内容的介绍 1. Spring MVC 入门案例 2. 基…...

Golang make vs new
文章目录 1.简介2.区别3.new 可以初始化 slice,map 和 channel 吗?4.make 可以初始化其他类型吗?5.小结参考文献 1.简介 在 Go 语言中,make 和 new 是两个用于创建对象的内建函数,但它们有着不同的用途和适用范围。 …...

Arthas
概述 Arthas(阿尔萨斯) 能为你做什么? Arthas 是Alibaba开源的Java诊断工具,深受开发者喜爱。 当你遇到以下类似问题而束手无策时,Arthas可以帮助你解决: 这个类从哪个 jar 包加载的?为什么会…...

IP代理科普| 共享IP还是独享IP?两者的区别与优势
通俗地讲,共享IP就像乘坐公共汽车一样,您可以到达目的地,但将与其他乘客共享旅程,座位很可能是没有的。独享IP就像坐出租车一样,您可以更快到达目的地,由于车上只有您一个人,座位是您一个人专用…...
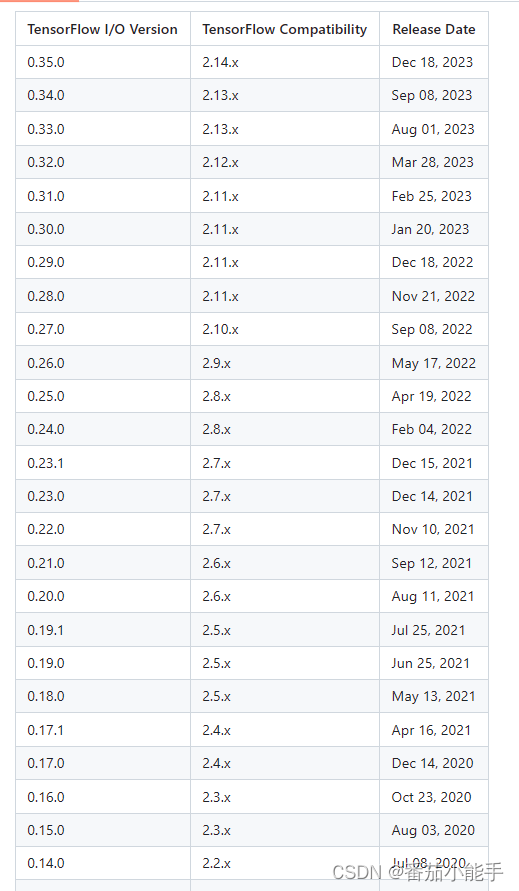
龙芯loongarch64服务器编译安装tensorflow-io-gcs-filesystem
前言 安装TensorFlow的时候,会出现有些包找不到的情况,直接使用pip命令也无法安装,比如tensorflow-io-gcs-filesystem,安装的时候就会报错: 这个包需要自行编译,官方介绍有限,这里我讲解下 编译 准备 拉取源码:https://github.com/tensorflow/io.git 文章中…...

开源持续测试平台Linux MeterSphere本地部署与远程访问
文章目录 前言1. 安装MeterSphere2. 本地访问MeterSphere3. 安装 cpolar内网穿透软件4. 配置MeterSphere公网访问地址5. 公网远程访问MeterSphere6. 固定MeterSphere公网地址 前言 MeterSphere 是一站式开源持续测试平台, 涵盖测试跟踪、接口测试、UI 测试和性能测试等功能&am…...

Kubernetes(K8S)快速入门
概述 在本门课程中,我们将会学习K8S一些非常重要和核心概念,已经操作这些核心概念对应组件的相关命令和方式。比如Deploy部署,Pod容器,调度器,Service服务,Node集群节点,Helm包管理器等等。 在…...
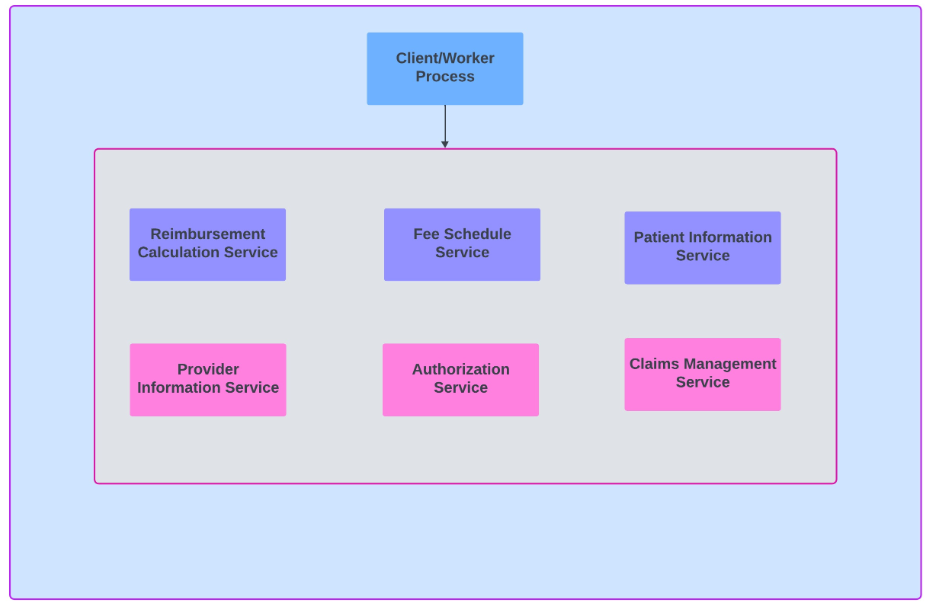
将遗留系统分解为微服务:第 2 部分
在当今不断发展的技术环境中,从整体架构向微服务的转变对于许多企业来说都是一项战略举措。这在报销计算系统领域尤其重要。正如我在上一篇文章第 1 部分应用 Strangler 模式将遗留系统分解为微服务-CSDN博客中提到的,让我们探讨如何有效管理这种转变。 …...

RK3588平台开发系列讲解(AI 篇)RKNN-Toolkit2 模型的加载转换
文章目录 一、Caffe 模型加载接口二、TensorFlow 模型加载接口三、TensorFlowLite 模型加载接口四、ONNX 模型加载五、DarkNet 模型加载接口六、PyTorch 模型加载接口沉淀、分享、成长,让自己和他人都能有所收获!😄 📢 RKNN-Toolkit2 目前支持 Caffe、TensorFlow、Tensor…...
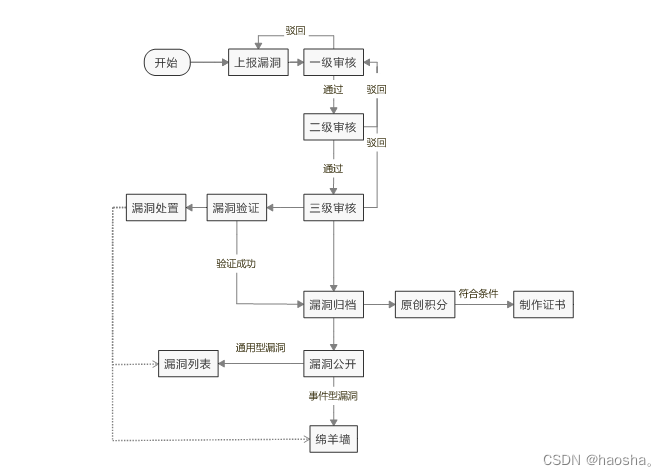
CNVD原创漏洞审核和处理流程
一、CNVD原创漏洞审核归档和发布主流程 (一)审核和归档流程 审核流程分为一级、二级、三级审核,其中一级审核主要对提交的漏洞信息完整性进行审核,漏洞符合可验证(通用型漏洞有验证代码信息或多个互联网实例、事件型…...
【java爬虫】基于springboot+jdbcTemplate+sqlite+OkHttp获取个股的详细数据
注:本文所用技术栈为:springbootjdbcTemplatesqliteOkHttp 前面的文章我们获取过沪深300指数的成分股所属行业以及权重数据,本文我们来获取个股的详细数据。 我们的数据源是某狐财经,接口的详细信息在下面的文章中,本…...

TwinCAT3实战指南:PLC变量与硬件IO的高效绑定技巧
1. TwinCAT3环境搭建与基础概念 第一次接触TwinCAT3的工程师常常会被各种专业术语搞得晕头转向。其实可以把TwinCAT3想象成一个"翻译官",它负责把PLC程序中的变量指令"翻译"成硬件能听懂的电信号。我刚开始使用时,最头疼的就是变量定…...

GPEN部署教程:使用Podman替代Docker,在RHEL/CentOS安全环境中运行
GPEN部署教程:使用Podman替代Docker,在RHEL/CentOS安全环境中运行 1. 为什么选择Podman部署GPEN? 在企业级环境中,安全性和稳定性往往是首要考虑因素。传统的Docker虽然方便,但在安全隔离和权限管理方面存在一些局限…...

OpenPLC Editor:重新定义工业自动化编程的开源解决方案
OpenPLC Editor:重新定义工业自动化编程的开源解决方案 【免费下载链接】OpenPLC_Editor 项目地址: https://gitcode.com/gh_mirrors/ope/OpenPLC_Editor 在工业自动化领域,传统PLC编程软件往往面临高昂的授权费用、封闭的生态系统和有限的技术支…...

低代码不是妥协,而是进化:.NET 9 AOT+Hot Reload双模引擎深度解析,上线周期压缩至72小时以内
第一章:低代码不是妥协,而是进化:.NET 9 AOTHot Reload双模引擎深度解析,上线周期压缩至72小时以内在传统认知中,“低代码”常被误读为牺牲可控性与性能的权宜之计。而.NET 9通过原生AOT编译与Hot Reload能力的深度融合…...
)
告别虚拟机!在Windows 11上零配置搭建Masm汇编实验环境(附保姆级图文教程)
在Windows 11上零配置搭建Masm汇编实验环境的完整指南 对于计算机专业的学生和汇编语言初学者来说,搭建一个可用的实验环境往往是第一道门槛。传统方法要么需要配置复杂的虚拟机,要么依赖过时的DOS模拟器,这些方案不仅占用系统资源࿰…...

深入解析POODLE漏洞:SSL3.0的CBC模式安全隐患与防御策略
1. POODLE漏洞的前世今生 第一次听说POODLE漏洞时,我还以为是什么可爱的狗狗品种。后来才发现,这个听起来萌萌的名字背后,隐藏着一个足以让整个互联网颤抖的安全威胁。POODLE全称Padding Oracle On Downgraded Legacy Encryption,…...

DeerFlow智能客服应用:多轮对话系统实战
DeerFlow智能客服应用:多轮对话系统实战 1. 引言 想象一下这样的场景:一位顾客在电商平台咨询商品信息,客服机器人不仅能准确回答产品参数,还能根据对话历史推荐相关配件,甚至在用户表达不满时自动生成工单并转接人工…...

Blue-Topaz主题快速上手:打造个性化Obsidian笔记环境
Blue-Topaz主题快速上手:打造个性化Obsidian笔记环境 【免费下载链接】Blue-Topaz_Obsidian-css A blue theme for Obsidian. 项目地址: https://gitcode.com/gh_mirrors/bl/Blue-Topaz_Obsidian-css Blue-Topaz是一款为Obsidian设计的蓝色主题,…...

Python数据分析实战:用np.random.normal生成正态分布数据的5个实用场景
Python数据分析实战:用np.random.normal生成正态分布数据的5个实用场景 正态分布作为统计学中最基础也最重要的概率分布之一,在数据分析、机器学习、金融建模等领域无处不在。许多自然现象和人类行为都呈现出正态分布的特征,比如身高、考试成…...

55、RAII技术---------多线程、竟态条件和同步
RAII技术RAII(Resource Acquisition Is Initialization,资源获取即初始化)是一种C编程技术,它将资源的获取(例如分配的堆内存、打开的文件、锁定的互斥量等)与对象的生命周期绑定在一起。具体来说ÿ…...