Opencv_CUDA实现推理图像前处理与后处理
Opencv_CUDA实现推理图像前处理与后处理
- 通过trt 或者 openvino部署深度学习算法时,往往会通过opencv的Mat及算法将图像转换为固定的格式作为输入
- openvino图像的前后处理后边将在单独的文章中写出
- 今晚空闲搜了一些opencv_cuda的使用方法,在此总结一下
- 前提是已经通过CMake将cuda和opencv重新编译好了C++库
1.前处理
- 参考:【基于opencv-cuda的常见图像预处理】
// -------------- opencv ----------------------- #
#include <opencv2/opencv.hpp>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
// ---------------- opencv-cuda ---------------- #
#include <opencv2/cudawarping.hpp>
#include <opencv2/cudaarithm.hpp>
#include <opencv2/cudaimgproc.hpp>// ------------ cuda ------------------------- #
#include <cuda_runtime_api.h>
// ------------------- nvinfer1 ------------------ #
#include "NvInfer.h"// ------------ standard libraries --------------- #
#include <iostream>
#include <assert.h>
#include <string>
#include <vector>// ---------------------------------------------- #void preprocessImage(const std::string& image_path, float* gpu_input,nvinfer1::Dims3& dims)
{// read imagecv::Mat frame = cv::imread(image_path);if(frame.empty()){std::cerr << "failed to load image: " << image_path << "!" << std::endl;return;}// uploadcv::cuda::GpuMat gpu_frame;gpu_frame.upload(frame);// resize// CHW orderauto input_width = dims.d[2];auto input_height = dims.d[1];auto channels = dims.d[0];auto input_size = cv::Size(input_width, input_height);cv::cuda::GpuMat resized;cv::cuda::resize(gpu_frame, resized, input_size, 0, 0, cv::INTER_LINEAR);//* ------------------------ Pytorch ToTensor and Normalize ------------------- */cv::cuda::GpuMat flt_image;resized.convertTo(flt_image, CV_32FC3, 1.f/255.f);cv::cuda::subtract(flt_image, cv::Scalar(0.485f, 0.346f, 0.406f), flt_image,cv::noArray(), -1);cv::cuda::divide(flt_image, cv::Scalar(0.229f, 0.224f, 0.225f), flt_image, 1, -1);//* ----------------------------------------------------------------------------------- /// BGR To RGBcv::cuda::GpuMat rgb;cv::cuda::cvtColor(flt_image, rgb, cv::COLOR_BGR2RGB);// toTensor(copy data to input float pointer channel by channel)std::vector<cv::cuda::GpuMat> rgb_out;for(size_t i=0; i<channels; ++i){rgb_out.emplace_back(cv::cuda::GpuMat(cv::Size(input_width, input_height), CV_32FC1, gpu_input + i * input_width * input_height));}cv::cuda::split(flt_image, rgb_out); // opencv HWC order -> CHW order
}// calculate size of tensor
size_t getSizeByDim(const nvinfer1::Dims& dims)
{size_t size = 1;for (size_t i = 0; i < dims.nbDims; ++i){size *= dims.d[i];}return size;
}int main()
{std::string image_path = "./turkish_coffee.jpg";// CHW ordernvinfer1::Dims3 input_dim(3, 640, 640);auto input_size = getSizeByDim(input_dim) * sizeof(float);// allocate gpu memory for network inference// 此处的buffer可以认为是TensorRT engine推理时在GPU上分配的输入显存std::vector<void*> buffers(1);cudaMalloc(&buffers[0], input_size);// preprocesspreprocessImage(image_path, (float*)buffers[0], input_dim);// downloadcv::cuda::GpuMat gpu_output;std::vector<cv::cuda::GpuMat> resized;for (size_t i = 0; i < 3; ++i){resized.emplace_back(cv::cuda::GpuMat(cv::Size(input_dim.d[2], input_dim.d[1]), CV_32FC1, (float*)buffers[0] + i * input_dim.d[2] * input_dim.d[1]));}cv::cuda::merge(resized, gpu_output);cv::cuda::GpuMat image_out;// normalizegpu_output.convertTo(image_out, CV_32FC3, 1.f * 255.f);// downloadcv::Mat dst;image_out.download(dst);cv::imwrite("../01_test_demo.jpg", dst);for(void* buf:buffers){cudaFree(buf);}return 0;
}
- 原图与结果图:
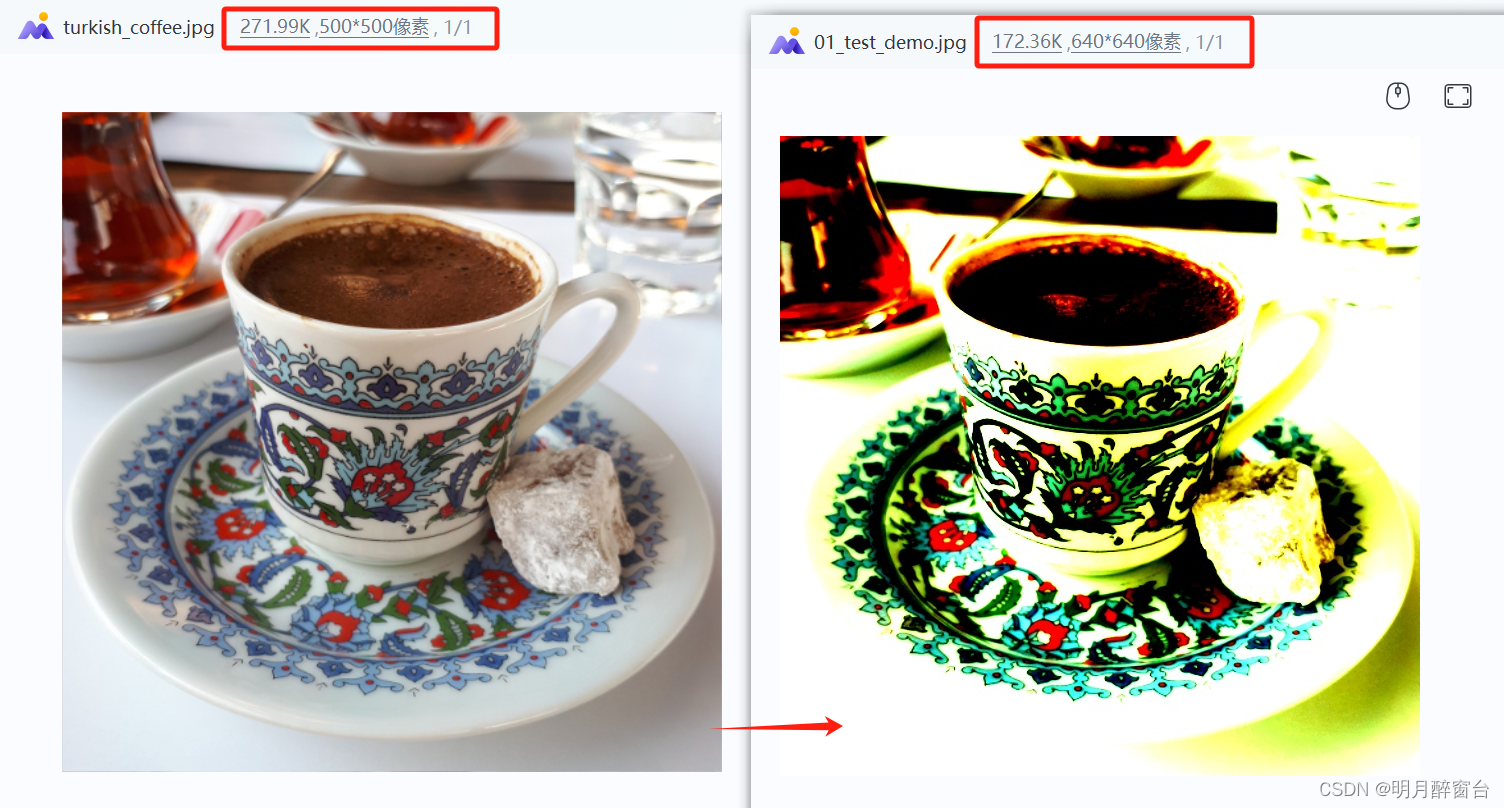
2. 输出后处理
- 下边通过一个trt demo展示一下后处理操作
- 源码实现如下:
#include <iostream>
#include <fstream>
#include <NvInfer.h>
#include <memory>
#include <NvOnnxParser.h>
#include <vector>
#include <cuda_runtime_api.h>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/core/cuda.hpp>
#include <opencv2/cudawarping.hpp>
#include <opencv2/core.hpp>
#include <opencv2/cudaarithm.hpp>
#include <algorithm>
#include <numeric>// destroy TensorRT objects if something goes wrong
struct TRTDestroy
{template <class T>void operator()(T* obj) const{if (obj){obj->destroy();}}
};template <class T>
using TRTUniquePtr = std::unique_ptr<T, TRTDestroy>;// calculate size of tensor
size_t getSizeByDim(const nvinfer1::Dims& dims)
{size_t size = 1;for (size_t i = 0; i < dims.nbDims; ++i){size *= dims.d[i];}return size;
}// get classes names
std::vector<std::string> getClassNames(const std::string& imagenet_classes)
{std::ifstream classes_file(imagenet_classes);std::vector<std::string> classes;if (!classes_file.good()){std::cerr << "ERROR: can't read file with classes names.\n";return classes;}std::string class_name;while (std::getline(classes_file, class_name)){classes.push_back(class_name);}return classes;
}// preprocessing stage ------------------------------------------------------------------------------------------------
void preprocessImage(const std::string& image_path, float* gpu_input, const nvinfer1::Dims& dims)
{// read input imagecv::Mat frame = cv::imread(image_path);if (frame.empty()){std::cerr << "Input image " << image_path << " load failed\n";return;}cv::cuda::GpuMat gpu_frame;// upload image to GPUgpu_frame.upload(frame);auto input_width = dims.d[2];auto input_height = dims.d[1];auto channels = dims.d[0];auto input_size = cv::Size(input_width, input_height);// resizecv::cuda::GpuMat resized;cv::cuda::resize(gpu_frame, resized, input_size, 0, 0, cv::INTER_NEAREST);// normalizecv::cuda::GpuMat flt_image;resized.convertTo(flt_image, CV_32FC3, 1.f / 255.f);cv::cuda::subtract(flt_image, cv::Scalar(0.485f, 0.456f, 0.406f), flt_image, cv::noArray(), -1);cv::cuda::divide(flt_image, cv::Scalar(0.229f, 0.224f, 0.225f), flt_image, 1, -1);// to tensorstd::vector<cv::cuda::GpuMat> chw;for (size_t i = 0; i < channels; ++i){chw.emplace_back(cv::cuda::GpuMat(input_size, CV_32FC1, gpu_input + i * input_width * input_height));}cv::cuda::split(flt_image, chw);
}// post-processing stage ----------------------------------------------------------------------------------------------
void postprocessResults(float *gpu_output, const nvinfer1::Dims &dims, int batch_size)
{// get class namesauto classes = getClassNames("imagenet_classes.txt");// copy results from GPU to CPUstd::vector<float> cpu_output(getSizeByDim(dims) * batch_size);cudaMemcpy(cpu_output.data(), gpu_output, cpu_output.size() * sizeof(float), cudaMemcpyDeviceToHost);// calculate softmaxstd::transform(cpu_output.begin(), cpu_output.end(), cpu_output.begin(), [](float val) {return std::exp(val);});auto sum = std::accumulate(cpu_output.begin(), cpu_output.end(), 0.0);// find top classes predicted by the modelstd::vector<int> indices(getSizeByDim(dims) * batch_size);std::iota(indices.begin(), indices.end(), 0); // generate sequence 0, 1, 2, 3, ..., 999std::sort(indices.begin(), indices.end(), [&cpu_output](int i1, int i2) {return cpu_output[i1] > cpu_output[i2];});// print resultsint i = 0;while (cpu_output[indices[i]] / sum > 0.005){if (classes.size() > indices[i]){std::cout << "class: " << classes[indices[i]] << " | ";}std::cout << "confidence: " << 100 * cpu_output[indices[i]] / sum << "% | index: " << indices[i] << "\n";++i;}
}// main pipeline ------------------------------------------------------------------------------------------------------
int main(int argc, char* argv[])
{if (argc < 3){std::cerr << "usage: " << argv[0] << " model.onnx image.jpg\n";return -1;}std::string model_path(argv[1]);std::string image_path(argv[2]);int batch_size = 1;// initialize TensorRT engine and parse ONNX modelTRTUniquePtr<nvinfer1::ICudaEngine> engine{nullptr};//初始化engine.........省略// get sizes of input and output and allocate memory required for input data and for output datastd::vector<nvinfer1::Dims> input_dims; // we expect only one inputstd::vector<nvinfer1::Dims> output_dims; // and one outputstd::vector<void*> buffers(engine->getNbBindings()); // buffers for input and output datafor (size_t i = 0; i < engine->getNbBindings(); ++i){auto binding_size = getSizeByDim(engine->getBindingDimensions(i)) * batch_size * sizeof(float);cudaMalloc(&buffers[i], binding_size);if (engine->bindingIsInput(i)){input_dims.emplace_back(engine->getBindingDimensions(i));}else{output_dims.emplace_back(engine->getBindingDimensions(i));}}if (input_dims.empty() || output_dims.empty()){std::cerr << "Expect at least one input and one output for network\n";return -1;}// preprocess input datapreprocessImage(image_path, (float *) buffers[0], input_dims[0]);// inferencecontext->enqueue(batch_size, buffers.data(), 0, nullptr);// postprocess resultspostprocessResults((float *) buffers[1], output_dims[0], batch_size);for (void* buf : buffers){cudaFree(buf);}return 0;
}相关文章:
Opencv_CUDA实现推理图像前处理与后处理
Opencv_CUDA实现推理图像前处理与后处理 通过trt 或者 openvino部署深度学习算法时,往往会通过opencv的Mat及算法将图像转换为固定的格式作为输入openvino图像的前后处理后边将在单独的文章中写出今晚空闲搜了一些opencv_cuda的使用方法,在此总结一下前…...

Android.bp 和 Android.mk 的对应关系
参考 Soong 构建系统 Android.mk 转为 Android.bp 没有分支、循环等流程控制的简单的 Android.mk ,可以通过 androidmk 命令转化为 Android.bp source 、lunch 之后执行即可。 androidmk Android.mk > Android.bp对应关系 Android 13 ,build/soon…...

力扣-收集足够苹果的最小花园周长[思维+组合数]
题目链接 题意: 给你一个用无限二维网格表示的花园,每一个 整数坐标处都有一棵苹果树。整数坐标 (i, j) 处的苹果树有 |i| |j| 个苹果。 你将会买下正中心坐标是 (0, 0) 的一块 正方形土地 ,且每条边都与两条坐标轴之一平行。 给你一个整…...

【C语言】自定义类型:结构体深入解析(三)结构体实现位段最终篇
文章目录 📝前言🌠什么是位段?🌉 位段的内存分配🌉VS怎么开辟位段空间呢?🌉位段的跨平台问题🌠 位段的应⽤🌠位段使⽤的注意事项🚩总结 📝前言 本…...
基于Hexo+GitHub Pages 的个人博客搭建
基于HexoGitHub Pages 的个人博客搭建 步骤一:安装 Node.js 和 Git步骤二:创建Github Pages 仓库步骤二:安装 Hexo步骤三:创建 Hexo 项目步骤四:配置 Hexo步骤五:创建新文章步骤六:生成静态文件…...

7. 结构型模式 - 代理模式
亦称: Proxy 意图 代理模式是一种结构型设计模式, 让你能够提供对象的替代品或其占位符。 代理控制着对于原对象的访问, 并允许在将请求提交给对象前后进行一些处理。 问题 为什么要控制对于某个对象的访问呢? 举个例子ÿ…...

挑战Python100题(6)
100+ Python challenging programming exercises 6 Question 51 Define a class named American and its subclass NewYorker. Hints: Use class Subclass(ParentClass) to define a subclass. 定义一个名为American的类及其子类NewYorker。 提示:使用class Subclass(Paren…...

gin实现登录逻辑,包含cookie,session
users/login.html {{define "users/login.html"}} <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>登录页面</title> </head> <body><form method"post" a…...
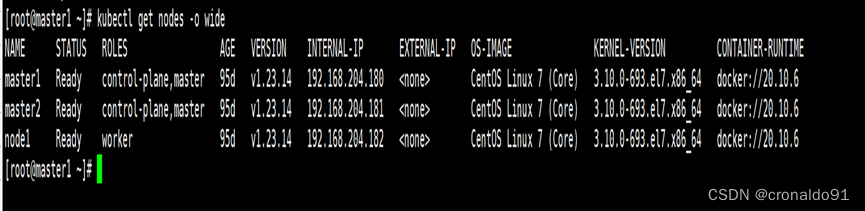
云原生Kubernetes:K8S集群版本升级(v1.22.14 - v1.23.14)
目录 一、理论 1.K8S集群升级 2.环境 3.升级集群(v1.23.14) 4.验证集群(v1.23.14) 二、实验 1. 环境 2.升级集群(v1.23.14) 2.验证集群(v1.23.14) 一、理论 1.K8S集群升级 …...
编程-位运算详解)
C++面向对象(OOP)编程-位运算详解
本文主要介绍原码、位运算的种类,以及常用的位运算的使用场景。 目录 1 原码、反码、补码 2 有符号和无符号数 3 位运算 4 位运算符使用规则 4.1 逻辑移位和算术移位 4.1.1 逻辑左移和算法左移 4.1.2 逻辑右移和算术右移 4.1.3 总结 4.2 位运算的应用场景 …...

linux运行服务提示报错/usr/bin/java: 没有那个文件或目录
如果是直接从官网下载的jdk解压安装,那么/usr/bin/没有java的软连接,即/usr/bin/java,所以即使在/etc/profile中配置了jdk的环境变量也没用,识别不到。 方法一:用java的执行路径配置/usr/bin/java软连接(优…...

一篇文章教会你数据仓库之详解拉链表怎么做
前言 本文将会谈一谈在数据仓库中拉链表相关的内容,包括它的原理、设计、以及在我们大数据场景下的实现方式。 全文由下面几个部分组成: 先分享一下拉链表的用途、什么是拉链表。通过一些小的使用场景来对拉链表做近一步的阐释,以及拉链表和…...

C/S医院检验LIS系统源码
一、检验科LIS系统概述: LIS系统即实验室信息管理系统。LIS系统能实现临床检验信息化,检验科信息管理自动化。其主要功能是将检验科的实验仪器传出的检验数据经数据分析后,自动生成打印报告,通过网络存储在数据库中ÿ…...
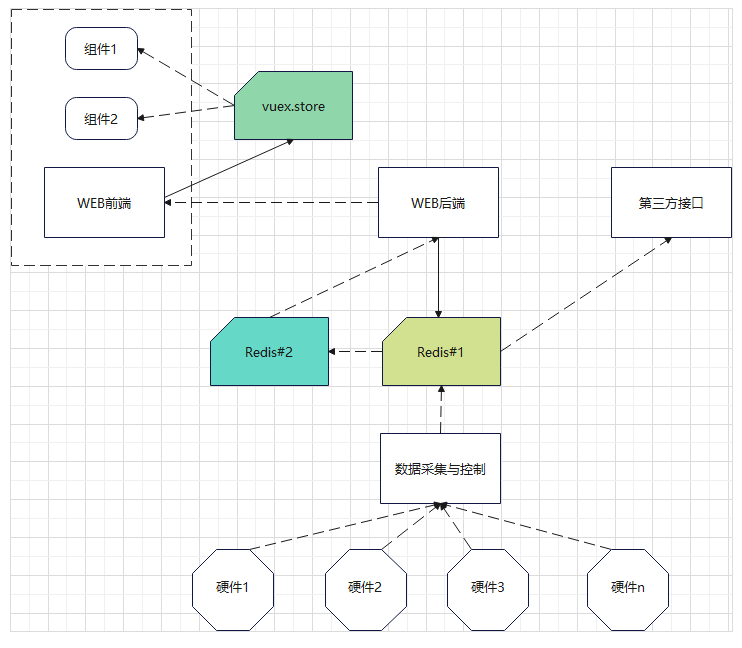
项目应用多级缓存示例
前不久做的一个项目,需要在前端实时展示硬件设备的数据。设备很多,并且每个设备的数据也很多,总之就是数据很多。同时,设备的刷新频率很快,需要每2秒读取一遍数据。 问题来了,我们如何读取数据,…...

音视频技术开发周刊 | 325
每周一期,纵览音视频技术领域的干货。 新闻投稿:contributelivevideostack.com。 AI读心术震撼登顶会!模型翻译脑电波,人类思想被投屏|NeurIPS 2023 在最近举办的NeurIPS大会上,研究人员展示了当代AI更震撼…...
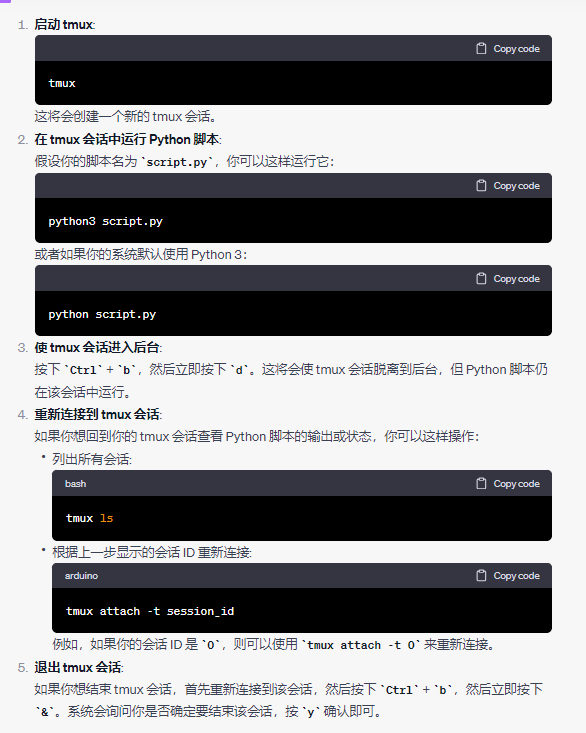
量化服务器 - 后台挂载运行
服务器 - 后台运行 pip3命令被kill 在正常的pip命令后面加上 -no-cache-dir tmux 使用教程 https://codeleading.com/article/40954761108/ 如果你希望在 tmux 中后台执行一个 Python 脚本,你可以按照以下步骤操作: 启动 tmux: tmux这将会创建一个新…...
使用tesla gpu 加速大模型,ffmpeg,unity 和 UE等二三维应用
我们知道tesla gpu 没有显示器接口,那么在windows中怎么使用加速unity ue这种三维编辑器呢,答案就是改变注册表来加速相应的三维渲染程序. 1 tesla gpu p40 p100 加速 在windows中使用regedit 来改变 核显配置, 让p100 p40 等等显卡通过核显…...
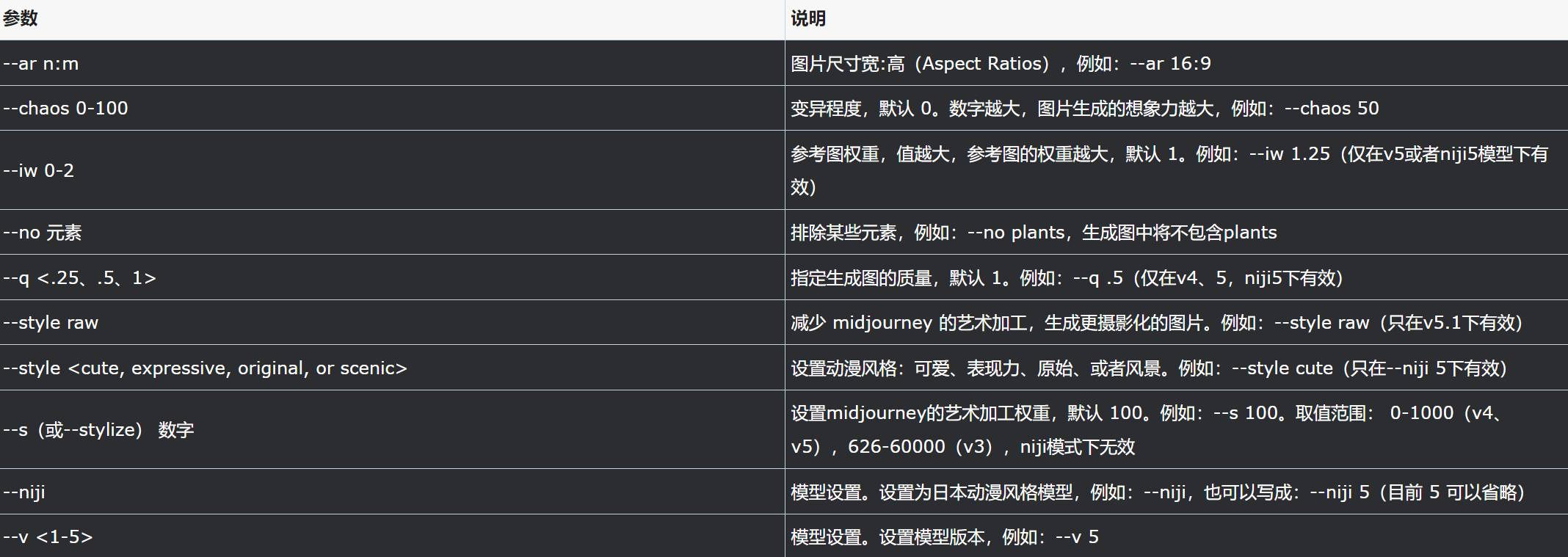
巅峰画师Midjourney:新时代的独角兽
介绍 AI绘画领域中,Midjourney处于绝对地位,并且一年时间就登顶。 Midjourney是一家独立的AI研究实验室,探索新的思维媒介,拓展人类的想象力。 它由一个小型的自筹资金团队组成,专注于设计、人类基础设施和AI。 在AI绘画领域,Midjourney取得了非常突出…...

入行 4 年,跳槽 2 次,我摸透了软件测试这一行!
最近几年行业在如火如荼的发展壮大,以及其他传统公司都需要大批量的软件测试人员,但是最近几年的疫情导致大规模裁员,让人觉得行业寒冬已来,软件测试人员的职业规划值得我们深度思考。 大家都比较看好软件测试行业,只是…...

Hive01_安装部署
Hive的安装 上传安装包 解压 tar zxvf apache-hive-3.1.2-bin.tar.gz mv apache-hive-3.1.2-bin hive解决Hive与Hadoop之间guava版本差异 cd /export/software/hive/ rm -rf lib/guava-19.0.jarcp cp /export/software/hadoop/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

oracle与MySQL数据库之间数据同步的技术要点
Oracle与MySQL数据库之间的数据同步是一个涉及多个技术要点的复杂任务。由于Oracle和MySQL的架构差异,它们的数据同步要求既要保持数据的准确性和一致性,又要处理好性能问题。以下是一些主要的技术要点: 数据结构差异 数据类型差异ÿ…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

如何在最短时间内提升打ctf(web)的水平?
刚刚刷完2遍 bugku 的 web 题,前来答题。 每个人对刷题理解是不同,有的人是看了writeup就等于刷了,有的人是收藏了writeup就等于刷了,有的人是跟着writeup做了一遍就等于刷了,还有的人是独立思考做了一遍就等于刷了。…...

A2A JS SDK 完整教程:快速入门指南
目录 什么是 A2A JS SDK?A2A JS 安装与设置A2A JS 核心概念创建你的第一个 A2A JS 代理A2A JS 服务端开发A2A JS 客户端使用A2A JS 高级特性A2A JS 最佳实践A2A JS 故障排除 什么是 A2A JS SDK? A2A JS SDK 是一个专为 JavaScript/TypeScript 开发者设计的强大库ÿ…...

Razor编程中@Html的方法使用大全
文章目录 1. 基础HTML辅助方法1.1 Html.ActionLink()1.2 Html.RouteLink()1.3 Html.Display() / Html.DisplayFor()1.4 Html.Editor() / Html.EditorFor()1.5 Html.Label() / Html.LabelFor()1.6 Html.TextBox() / Html.TextBoxFor() 2. 表单相关辅助方法2.1 Html.BeginForm() …...