【Java核心知识】spring boot整合Mybatis plus + Phoenix 访问Hbase与使用注意
为了Phoenix能让开发者通过SQL访问Hbase而不必使用原生的方式?引用Phoenix官网上的一句话:SQL is just a way of expressing what you want to get not how you want to get it. 即SQL不是一种数据操作技术,而是一种特殊的表达方式。只是表示你需要什么而不是你如何获得。
Phoenix
- 前提条件
- 项目集成
- phoenix使用
- 建SCHEMA
- 建表
- 不指定列族
- 指定列族
- 主键
- RowKey加盐
- 二级索引
- 全局索引
- 覆盖索引
- 本地索引
- explain
前提条件
一个集成了Phoenix的Hbase环境。搭建完成你会得到Phoenix地址和一个hbase-site.xml配置文件。
一个新的或者已有的要集成的项目。
项目集成
- 引入依赖。注意phoenix的版本号, 这个版本号要和你搭建的环境对应。 如5.0.0-HBase-2.0表示为5.0.0版本的phoenix和2.0版本的Hbase,如果不一致,很大可能报错。因此为了版本对应,最好还是先选定版本再搭建环境。
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.3.1</version>
</dependency>
<dependency><groupId>org.apache.phoenix</groupId><artifactId>phoenix-core</artifactId><version>5.0.0-HBase-2.0</version>
</dependency>
- phoenix数据源和mybatis plus配置
spring:datasource:#Phoenix,zookeeper 地址url: jdbc:phoenix:test-hbase.test.com:2181driver-class-name: org.apache.phoenix.jdbc.PhoenixDriver# 如果不想配置对数据库连接池做特殊配置的话,以下关于连接池的配置就不是必须的# spring-boot 2.X 默认采用高性能的 Hikari 作为连接池 更多配置可以参考 https://github.com/brettwooldridge/HikariCP#configuration-knobs-babytype: com.zaxxer.hikari.HikariDataSourcehikari:minimum-idle: 100maximum-pool-size: 300# 允许最长空闲时间idle-timeout: 30000# 数据库连接超时时间,默认 30 秒,即 30000connection-timeout: 30000# 连接测试 sql 这个地方需要根据数据库方言差异而配置 例如 oracle 就应该写成 select 1 from dualconnection-test-query: SELECT 1# mybatis 相关配置
mybatis-plus:mapper-locations: classpath*:mapper/**/*.xmltype-aliases-package: com.example.phoenixdemo.entityconfiguration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
- 配置文件
将hbase-site.xml文件放入项目的resource目录下。如果没有特殊的配置,可以直接用下面这个配置。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>phoenix.schema.isNamespaceMappingEnabled</name><value>true</value></property><property><name>phoenix.schema.mapSystemTablesToNamespace</name><value>true</value></property>
</configuration>
- 配置mybatis plus的Upsert操作
对于phoenix来说是没有单纯insert和update操作的,仅仅可以通过Upsert来进行(不存在新增,存在则更新)操作。因此需要配置mybatis plus的Upsert操作。
建立UpsertInjector类定义Upsert操作
public class UpsertInjector extends DefaultSqlInjector {@Overridepublic List<AbstractMethod> getMethodList(Class<?> mapperClass) {List<AbstractMethod> methodList = super.getMethodList(mapperClass);methodList.add(new Upsert());return methodList;}}
将UpsertInjector载入Spring容器
@Configuration
public class MybatisPlusHBasePhoenixConfig {@Beanpublic UpsertInjector upsertSqlInjector () {return new UpsertInjector();}
}
- 当作一个数据库来使用my baits plus操作phoenix,如定义一个mapper
@Mapper
public interface HBasePhoenixBaseMapper<TestBean> extends com.baomidou.mybatisplus.core.mapper.BaseMapper<TestBean> {/*** 不存在新增,存在则更新:因为已经载入,所以直接写个upsert方法就行* @see com.baomidou.mybatisplus.extension.injector.methods.Upsert* @param object 目标参数*/void upsert(TestBean object);void select(TestBean object)void delete(TestBean object)}
更多关于my baits plus的使用这里就不赘述了。只要记得phoenix无法使用insert和update即可。
tips: phoenix连接创建时会打印一个info级别的堆栈,看着很像一个报错。然而这个并不是。
phoenix使用
建SCHEMA
CREATE SCHEMA IF NOT EXISTS "DEV_DEMO";
建表
不指定列族
基于Phoenix创建表时,如果没有指定列族的话,会默认自动创建一个名字为0列族。
CREATE TABLE DEV_DEMO.DEV_DEMO_TABLE (ID UNSIGNED_LONG NOT NULL,NAME VARCHAR,AGE UNSIGNED_INT,DELETED BOOLEAN,CONSTRAINT K_DEV_DEMO_TABLE_PK PRIMARY KEY (ID)
);
指定列族
指定列族的时候需要注意,主键列不能指定,否则会报错。
CREATE TABLE DEV_DEMO.DEV_DEMO_TABLE ("ID" UNSIGNED_LONG NOT NULL,"person"."NAME" VARCHAR,"person"."AGE" UNSIGNED_INT,"person"."DELETED" BOOLEAN,CONSTRAINT K_DEV_DEMO_TABLE_PK PRIMARY KEY (ID)
);
访问控制、磁盘和内存的使用统计都是在列族层面进行的,列族越多,在取一行数据时所需要参与 I/O、搜寻的文件就越多,所以,如果没有必要,不要设置太多的列族 官方推荐不要超过3个。(数据页的概念)
层级是 table-> region server(一个hbase集群有多个region server,类似于分库) -> region(类似于对表做的水平拆分,也就是分表) -> 列族(类似db做了垂直拆分,一个列族一个垂直表,对应hbase一个列族一个Store,同时他也对应数据页,也会发生类似页分类和页合并的flush和compaction 操作)
一个Region Server可以管理多个Region, 一个Region只由一个Region Server管理。
大小写敏感的phoenix
注意,phoenix对大小写敏感。且phoenix客户端会自动转大写。因此如果你的schema名,表名或者字段名定义存在小写。则在指定schema名,表名,字段名时则需要加双引号(phoenix会自动将表名库名等转大写)。
因此这里建议无论大小写都加上双引号。 例:@TableName(“\“TEST_schema\”.\“test_table\””)
主键
每个主键都会产生成本,因为整个行键都附加到内存和磁盘上的每条数据。行键越大,存储开销越大
不同于数据库一个列只会记录一个主键,最多包含索引。 Hbase的列式存储使得每个列都会记录一份主键。
数据的存储是按照RowKey进行字典方式升序存储
范围查询hbase有scan的startrow endrow。
RowKey加盐
RowKey是按照字典序方式排序存储的,因此如果我们的主键定义本身就带有字典序的话,那么在写入时就会出现在某个阶段是一直在写入同一个region,而其它region则处于空闲状态。读取时同样可能出现由相关数据导致的热点。
为了避免这种热点,phoenix提供通过为主键自动加盐生成新的RowKey的方式来分散数据。在建表时指定盐桶大小(限制在1-256)即可(默认不执行加盐操作,id就是rowkey)。
CREATE TABLE DEV_DEMO.DEV_DEMO_TABLE (ID UNSIGNED_LONG NOT NULL,NAME VARCHAR,AGE UNSIGNED_INT,DELETED BOOLEAN,CONSTRAINT K_DEV_DEMO_TABLE_PK PRIMARY KEY (ID)
) SALT_BUCKETS = 4;
加盐就是在原来key的基础上增加一个byte作为前缀,新rowKey的计算方式为
new_row_key = ((byte) (hash(original_key) % BUCKETS_NUMBER) + original_key
加盐的注意事项:
1)创建加盐表时不能再指定split key
2)加盐会影响根据RowKey的范围查询,因为数据分散到了不同的region
3)当可用block cache的大小>表数据大小时,slated buckett和region server数量相同,这样可以得到更好的读写性能。 但当表的数量很大时,基本上会忽略blcok cache的优化收益,大部分数据仍然需要走磁盘IO。比如对于10个region server集群的大表,可以考虑设计64~128个slat buckets。
二级索引
全局索引
和mysql创建索引的方式一致
create index indexName on tbName(colName1,colName2);
限制上同样有最左前缀限制。多列索引在满足前缀式的情况才会用到,如创建了A,B,C顺序的多列索引,当在where条件指定A条件、A B条件或者A B C条件均会走索引,但是 B C条件则无法走索引。
实现上:phoenix的全局索引,就是在HBase中创建一个真实的表,该索引表的rowkey是原表的索引列和rowkey组合而来的。
注意:当我们对原表进行select查询时,只有索引列中包含要查询的列时,才会走索引,phoenix没有二次查询,如果查询语句包含非索引列,就会直接去原表全表扫描而不是先走索引拿到原表的rowkey,再拿rowKey去原表查!
覆盖索引
所谓覆盖索引就是,就是把原数据再索引表中也存储一份,这样仅扫描索引表就可以读取到我们所需要的全部数据,不必再对原表进行扫描,只有从索引表中拿不到的数据,才会去原表中获取,从而提高检索速度。
create index indexName on tbName(colName1,colName2) include (colName3);
include的就是像通过索引查询的字段,但是这个字段又不想作为索引字段的处理。
全局索引适用于写少读多的情况,因为每个索引都是一个新表,写要操作n(索引数目)+1个表
本地索引
本地索引数据存储在同一数据表中的单独影子列族中。
RegionStartKey-索引名-索引键-索引值, 以列的值为键+记录的RowKey为新的RowKey,当以这些列为条件进行查询时,引擎可以通过检索相应的“键-值”数据快速找到目标记录
新增的这行数据的rowkey是由原表中的rowkey,索引列组成的。这个rowKey通过前缀设置为原rowkey的一部分来保证索引和数据在同一个region(类似于db中的数据页)中。
查询时可以通过rowkey加元数据得到具体的Region,但是使用索引时因为没有rowkey,所以在使用本地索引的读取时,必须检查每个Region(所有region server的所有Region)的数据,因为无法预先确定索引数据的确切Region。
本地索引适合写多读少的场景,因为索引数据和真实数据都是在同一张表中的。
本地索引的特点就是不管查询的数据索引表中有没有,都会先走索引。
create local index indexName on tbName(colName1,colName2);
可以看到,hbase本身并不擅长,因此查询方面方面如果有复杂查询,尽量引入其它组件(如es)记录 条件–>rowKey的映射关系。
explain
phoenix也能用explain来查看执行计划。
参考资料:
phoenix官网
Spring/Spring Boot 整合 Mybatis + Phoenix
Phoenix加盐表
shell命令
DBEAVER连接PHOENIX
相关文章:

【Java核心知识】spring boot整合Mybatis plus + Phoenix 访问Hbase与使用注意
为了Phoenix能让开发者通过SQL访问Hbase而不必使用原生的方式?引用Phoenix官网上的一句话:SQL is just a way of expressing what you want to get not how you want to get it. 即SQL不是一种数据操作技术,而是一种特殊的表达方式。只是表示…...
lua实现游戏全局鼠标点击效果
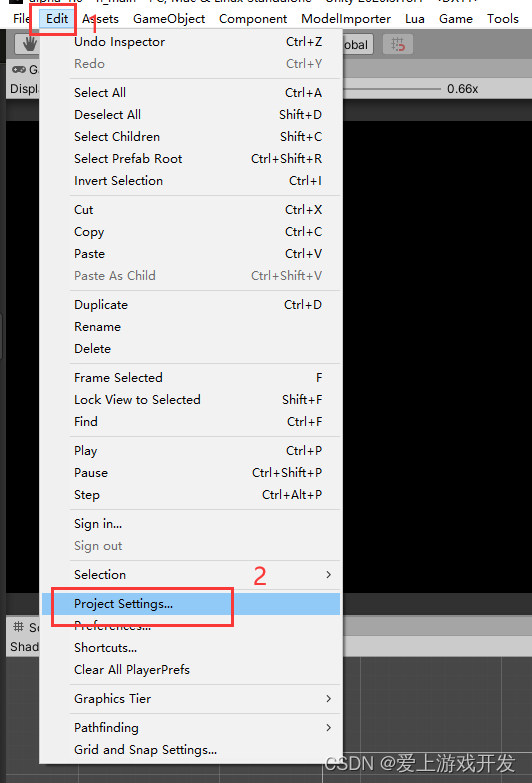
前言 最近在优化项目,策划提了一个需求,需要实现一个通用点击特效。 尝试1 首先想到的是改变鼠标指针样式,这个以前学过,还有点印象,以前刚开始学unity的时候,记得看到过一个方法可以改变游戏中鼠标指针样式。 方法如下:选择“Edit”——>“Project Setting”,打…...

MyBatis源码分析(二、续)SqlSource创建流程,SQL如何解析?如何将#{id}变成?的
文章目录实例一、SqlSource处理入口二、SqlSource处理逻辑1、XMLScriptBuilder 构造方法2、解析动态sql3、DynamicSqlSource4、RawSqlSource解析sql(1)parse方法解析sql写在后面实例 此处我们分析的sql: <select id"selectBlog&quo…...

用 C 语言开发一门编程语言 — 函数库的设计与实现
目录 文章目录目录前言前文列表基础功能演示数字运算变量与代数运算列表处理Lambda 函数条件分支字符串源文件加载函数库列表处理函数库条件分支函数库数学库前言 通过开发一门类 Lisp 的编程语言来理解编程语言的设计思想,本实践来自著名的《Build Your Own Lisp》…...
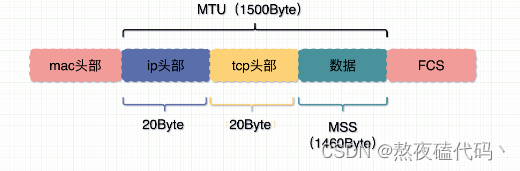
网络层IP协议与数据链路层以太网协议
文章目录一、IP协议IP地址地址管理路由选择DNS二、以太网协议以太网帧MTU一、IP协议 IP协议是我们网络层的代表协议,今天我们就来一起学习一下吧,我们这里介绍的主要是IPv4协议。 版本:指定IP协议的版本,版本的取值只有4&#x…...
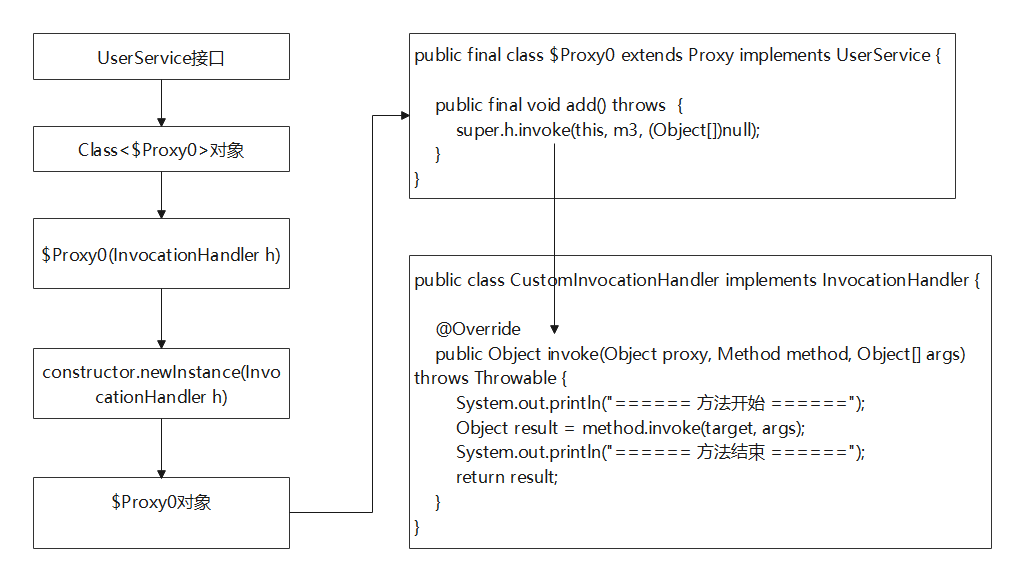
JDK动态代理详解
1.什么是动态代理 可能很多小伙伴首次接触动态代理这个名词的时候,或者是在面试过程中被问到动态代理的时候,不能很好的描述出来,动态代理到底是个什么高大上的技术。不方,其实动态代理的使用非常广泛,例如我们平常使用…...

实时的软件生成 —— Prompt 编程打通低代码的最后一公里?
PS:这也是一篇畅想,虽然经过了一番试验,依旧有一些不足,但是大体上站得住脚。传统的软件生成方式需要程序员编写大量的代码,然后进行测试、发布等一系列繁琐的流程。而实时生成技术则是借助人工智能技术,让…...
互联网工程师 1480 道 Java 面试题及答案整理 ( 2023 年 整理版)
最近很多粉丝朋友私信我说:熬过了去年的寒冬却没熬过现在的内卷;打开 Boss 直拒一排已读不回,回的基本都是外包,薪资还给的不高,对技术水平要求也远超从前;感觉 Java 一个初中级岗位有上千人同时竞争&#…...

Spark开发
第一步:创建RDD Spark提供三种创建RDD方式:** 集合、本地文件、HDFS文件** 使用程序中的集合创建RDD,主要用于进行测试,可以在实际部署到集群运行之前,自己使用集合构造一些测试数据,来测试后面的spark应…...

Tornado异步框架
简介: tornado是Python的web框架。tornado和主流的web服务器框架有明显的区别:它是非阻塞式服务器,而且速度非常快,得力于其非阻塞的方式和epoll的运用tornado可以每秒处理数以千计的连接(号称) 基本配置 …...

openpnp - error - 吸嘴没下降到板子上, 就将元件松开
文章目录openpnp - error - 吸嘴没下降到板子上, 就将元件松开概述笔记ENDopenpnp - error - 吸嘴没下降到板子上, 就将元件松开 概述 以前用过国内一家openpnp厂家出的设备, 他们家的openpnp是自己改过的. 贴片流程已经走过一遍. 这次还是按照以前记录的笔记, 按照国内那家的…...

【Java】yyyy-MM-dd HH:mm:ss 时间格式 时间戳 全面解读超详细
时间格式 时间格式(协议)描述gg时期或纪元。y不包含纪元的年份。不具有前导零。yy不包含纪元的年份。具有前导零。yyyy包含纪元的四位数的年份。M月份数字。一位数的月份没有前导零。MM月份数字。一位数的月份有一个前导零。MMM月份的缩写名称,在AbbreviatedMonthN…...

快鲸SCRM发布口腔企业私域运营解决方案
口腔企业普遍面临着以下几方面运营痛点问题 1、获客成本居高不下,恶性竞争严重 2、管理系统落后,人员流失严重 3、客户顾虑多、决策时间长 4、老客户易流失,粘性差 以上这些痛点,不得不倒逼口腔企业向精细化运营客户迈进。 …...
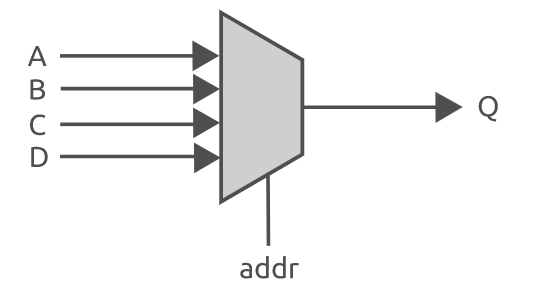
Verilog实现组合逻辑电路
在verilog 中可以实现的数字电路主要分为两类----组合逻辑电路和时序逻辑电路。组合逻辑电路比较简单,仅由基本逻辑门组成---如与门、或门和非门等。当电路的输入发生变化时,输出几乎(信号在电路中传递时会有一小段延迟)立即就发生…...

2023前端菜鸟笔试血泪史html5-one--找到工作前都更新
1.说说对html语义化的理解 什么的HTML语义化,顾名思义,HTML语义化就是可以不通过了解HTML的内容,就可以知道这个部分所代表的的意义。 HTML语义化的意义:在使用HTML标签构建页面时,避免大篇幅的使用无语义的标签。 …...
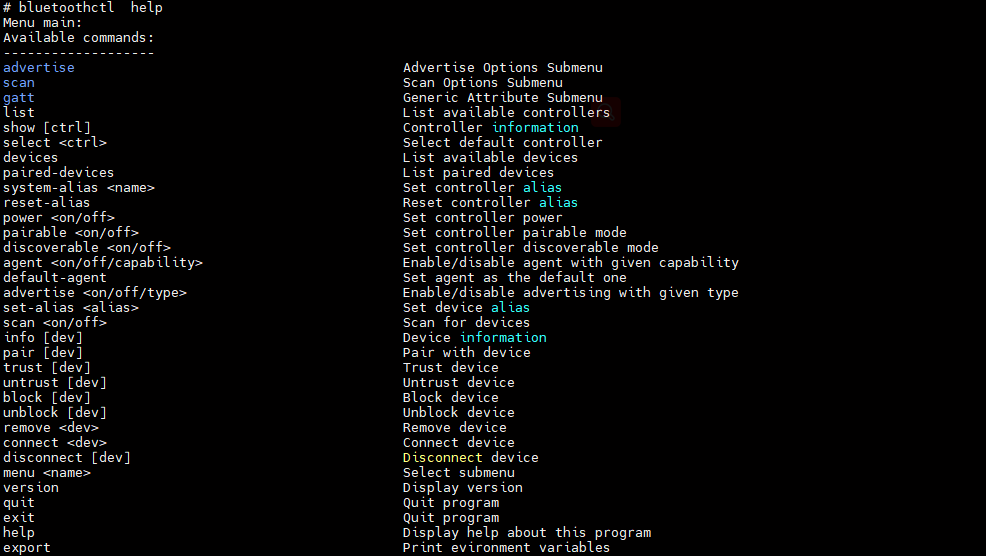
蓝牙调试工具集合汇总
BLE 该部分主要分享一下常用的蓝牙调试工具,方便后续蓝牙抓包及分析。 目录 1 hciconfig 2 hcitool 3 hcidump 4 hciattach 5 btmon 6 bluetoothd 7 bluetoothctl 1 hciconfig 工具介绍:hciconfig,HCI 设备配置工具 命令格式&…...

Java 获取文件后缀名【一文总结所有方法】
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
UML常见图的总结
一、概述 UML:Unified Modeling Language,统一建模语言,支持从需求分析开始的软件开发的全过程。是一个支持模型化和软件系统开发的图形化语言、为软件开发的所有阶段提供模型化和可视化支持,包括由需求分析到规格,到…...

WebRTC系列-工具系列之音频相关工具
文章目录 1. audio_util数据格式转换类2. WavFile文件读写类2.1 读取wav文件2.2 写入wav文件这篇文章主要介绍WebRTC中一些音频工具这些,大部分都在 common_audio目录下,这个文件夹下提供音频的大量算法,包括sinc重采样算法,音频数据格式的转换:例如 float转int16_t格式等…...
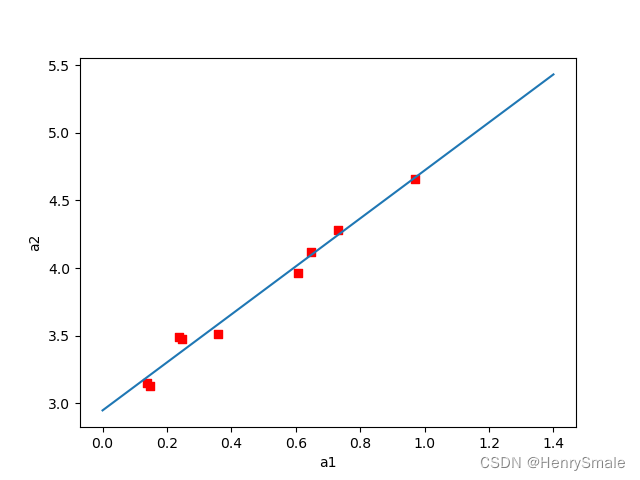
7 线性回归及Python实现
1 统计指标 随机变量XXX的理论平均值称为期望: μE(X)\mu E(X)μE(X)但现实中通常不知道μ\muμ, 因此使用已知样本来获取均值 X‾1n∑i1nXi.\overline{X} \frac{1}{n} \sum_{i 1}^n X_i. Xn1i1∑nXi.方差variance定义为: σ2E(∣X−μ∣2).\sigma^2 E(|…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...