学习笔记:数据挖掘与机器学习
文章目录
- 一、数据挖掘、机器学习、深度学习的区别
- (一)数据挖掘
- (二)机器学习
- (三)深度学习
- (四)总结
- 二、数据挖掘体系
- 三、数据挖掘的流程
- 四、典型的数据挖掘系统
一、数据挖掘、机器学习、深度学习的区别
(一)数据挖掘
-
数据挖掘,或者说Data Mining,是一个涵盖广泛且充满活力的学术领域,其核心目标在于揭示隐藏在海量数据背后的有价值信息和知识。这一过程涵盖了多种方法和技术,包括但不限于商业智能(BI)、统计分析、大数据处理技术以及市场运营策略。
-
在实际应用中,数据挖掘的工作形式多样,可以是通过复杂的BI工具对数据进行深度剖析,也可以是运用统计学原理对数据进行精细化解读。甚至,简单的Excel数据分析,只要能从中发现有助于业务决策的信息和规律,都可以被视为数据挖掘的一种表现形式。
-
随着科技的发展,机器学习算法模型在数据挖掘中的应用越来越普遍。这些模型能够自动学习数据的内在规律,并通过分类、聚类、回归等手段提取出有价值的信息。例如,在互联网广告领域,通过机器学习算法对PB级别的点击日志进行分析,可以构建出预测点击率的模型,从而提高广告的效果和回报率。在个性化推荐系统中,机器学习算法通过对用户行为数据的深入分析,能够精准预测用户的喜好,提供个性化的商品或服务推荐。
-
总的来说,数据挖掘是一个多元化、综合性强的领域,其目标是借助各种工具和技术,从大规模数据中挖掘出有价值的信息和知识,为业务决策、产品研发、市场营销等提供有力的支持和指导。而在这个过程中,机器学习算法模型以其强大的自动化学习和预测能力,成为了现代数据挖掘不可或缺的重要工具。
(二)机器学习
-
机器学习,这一术语源于计算机科学和统计学的深度融合,是一门致力于研究和开发算法的交叉学科,其核心目标是通过学习从输入数据(x)到输出结果(y)的映射函数,以实现诸如分类、聚类、回归等复杂任务。由于其强大的数据处理和模式识别能力,机器学习在众多领域中都展现出了不可替代的作用。
-
特别是在数据挖掘领域,机器学习的应用尤为广泛且关键。许多数据挖掘的工作流程和解决方案都是借助于机器学习所提供的各种算法工具得以实现的。例如,在互联网广告行业中,通过运用机器学习技术对海量的用户点击数据进行分析和建模,可以精准预估广告的点击率(CTR),从而优化广告投放策略,提高点击率和投资回报率。
-
另一方面,个性化推荐也是机器学习在数据挖掘中的一大应用实例。通过深入分析用户的购买历史、浏览行为和收藏记录等数据,机器学习算法能够构建出高度个性化的推荐模型,准确预测用户可能感兴趣的商品或服务,大幅提升用户体验和商业效益。
-
总的来说,机器学习以其强大的数据处理能力和智能化的决策支持,在数据挖掘领域发挥着至关重要的作用。无论是提升广告效果、优化推荐系统,还是解决其他各种数据驱动的问题,机器学习都为我们提供了强大而有效的工具和方法。随着数据量的持续增长和计算能力的不断提升,我们有理由相信,机器学习在数据挖掘领域的应用将更加深入和广泛。
(三)深度学习
-
深度学习,又称Deep Learning,是机器学习领域中一个备受瞩目和迅速发展的分支。它本质上是对传统神经网络算法的一种革新和深化,通过模拟人脑神经元的工作原理,构建多层非线性处理单元,实现对复杂数据的高效学习和理解。
-
在深度学习的框架下,算法模型能够自动从原始数据中提取高级特征,并逐步构建出越来越抽象的表示。这一特性使得深度学习在处理图像、语音等富媒体信息时表现出卓越的性能。例如,在图像分类和识别任务中,深度学习模型能够通过卷积神经网络(CNN)捕捉到图像中的细微纹理和形状特征,从而准确区分不同的物体类别。在语音识别方面,长短期记忆网络(LSTM)等递归神经网络结构则能够有效处理语音的时间序列特性,实现高精度的语音转文字转化。
-
由于其在处理复杂问题上的出色表现,深度学习吸引了全球众多顶级研究机构和科技公司的广泛关注和投入。无论是学术界的基础理论研究,还是工业界的实际应用开发,深度学习都展现出了巨大的潜力和价值。目前,深度学习已经被广泛应用于诸如自动驾驶、医疗诊断、金融风控、自然语言处理等诸多领域,不断推动着人工智能技术的进步和发展。随着计算能力的提升和数据量的增长,深度学习的影响力和应用范围有望进一步扩大,为人类社会带来更多的创新和变革。
(四)总结
- 数据挖掘、机器学习和深度学习是现代数据分析领域的三大关键技术。数据挖掘旨在从海量数据中揭示有价值信息,涉及多种方法如BI、统计分析和市场运营策略,而机器学习算法模型的广泛应用使其成为数据挖掘的重要工具。机器学习通过学习输入到输出的映射函数,实现分类、聚类、回归等任务,在数据挖掘中起到关键作用,如优化广告效果和个性化推荐。深度学习作为机器学习的分支,通过模拟神经元工作原理处理复杂数据,尤其在图像、语音等领域表现出色。随着技术的发展,这三种技术将在更多领域展现其价值,推动人工智能的进步和社会的创新变革。
二、数据挖掘体系
- 业界数据挖掘方法论
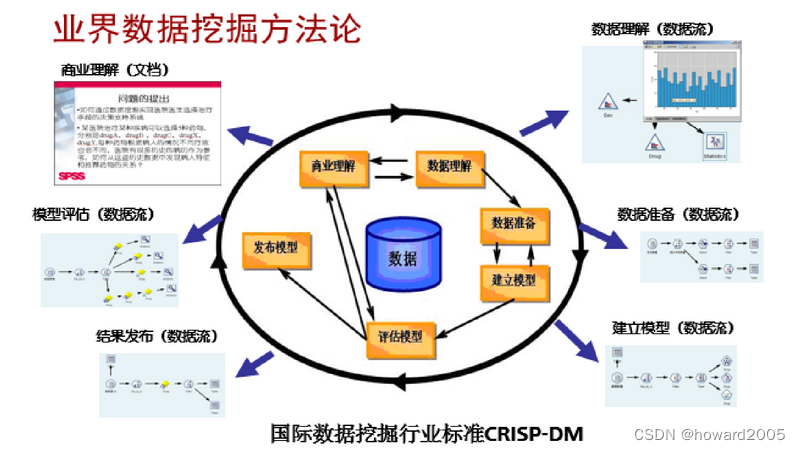
-
数据挖掘的体系是一个综合且多元的知识领域,它深度融合了多个学科和技术领域的精华。首先,统计学在数据挖掘中扮演着至关重要的角色,通过运用各种统计理论和方法,数据挖掘能够从大量数据中发现并验证模式、趋势和关联。
-
其次,数据库系统和数据仓库是数据挖掘的基础支撑。数据库系统用于存储和管理数据,而数据仓库则专门设计用于支持决策分析,它们为数据挖掘提供了稳定可靠的数据源。
-
信息检索技术在数据挖掘中也发挥着重要作用,它帮助我们在海量数据中快速准确地找到所需信息,这对于提升数据挖掘的效率和精度至关重要。
-
机器学习作为数据挖掘的核心工具,通过一系列算法模型自动学习数据的内在规律,并通过分类、聚类、回归等手段提取出有价值的信息和知识。
-
应用领域则是数据挖掘的实际落地,包括但不限于市场营销、金融风控、医疗诊断、社交网络分析等,数据挖掘的应用极大地推动了这些领域的创新和发展。
-
模式识别是数据挖掘中的关键技术之一,它旨在从数据中自动识别和提取具有意义的模式和结构。
-
可视化是数据挖掘的重要组成部分,通过图表、图像等形式将复杂的数据和分析结果呈现出来,使得非专业人员也能理解和利用数据挖掘的结果。
-
算法是数据挖掘的灵魂,包括关联规则学习、聚类分析、决策树、神经网络等各种算法,它们是实现数据挖掘功能的关键手段。
-
高性能计算,特别是分布式计算和GPU计算,为处理大规模数据和复杂算法提供了强大的计算能力,使得数据挖掘能够在短时间内处理和分析海量数据。
-
综上所述,数据挖掘的体系是一个涵盖了统计学、数据库系统、数据仓库、信息检索、机器学习、应用、模式识别、可视化、算法、高性能计算等多个领域的综合性知识体系,这些元素相互融合、相互促进,共同推动了数据挖掘技术的发展和应用。
三、数据挖掘的流程
- 目前,越来越多的人认为数据挖掘应该被视为一种知识发现过程(KDD:Knowledge Discovery in Database)。
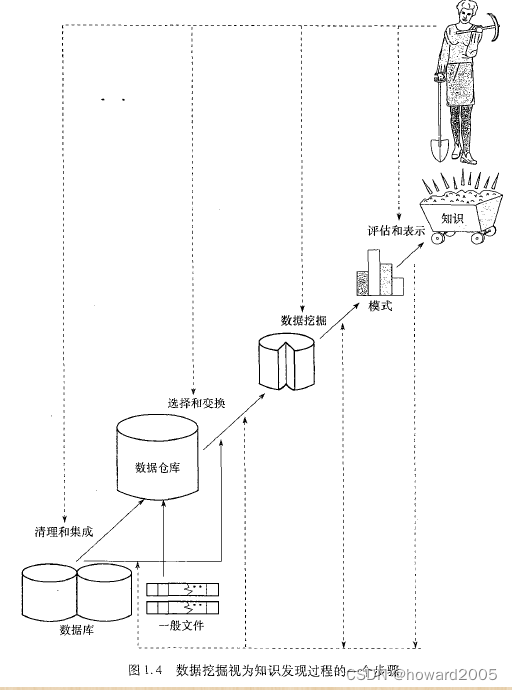
- KDD(Knowledge Discovery in Databases)过程是一个系统化、迭代的序列,旨在从大量数据中挖掘出有价值的知识和模式。
-
数据清理:这是数据挖掘的第一步,其目标是消除数据中的噪声和删除不一致的数据。噪声可以是由于数据采集错误、设备故障或其他原因导致的异常值或错误记录。不一致数据可能是由于数据源的不同、数据录入错误或者数据更新不及时等原因造成的。数据清理阶段需要对数据进行预处理,确保后续分析的准确性和可靠性。
-
数据集成:在实际应用中,数据往往来自多个不同的数据源。数据集成阶段的目标是将这些数据源组合在一起,形成一个统一的数据视图。这可能涉及到数据格式的转换、数据冲突的解决以及数据冗余的消除等问题。
-
数据选择:数据选择阶段的目标是从数据库中提取与分析任务相关的数据。这可能涉及到对数据字段的选择、数据子集的抽取以及数据过滤等操作。数据选择阶段的目的是减少数据的维度,提高数据挖掘的效率和效果。
-
数据变换:数据变换阶段的目标是通过汇总或聚集操作,将数据变换和统一成适合挖掘的形式。这可能包括数据规范化、数据标准化、数据离散化以及数据聚类等操作。数据变换的目的是使得数据满足算法模型的输入要求,同时也可以提高数据挖掘的精度和稳定性。
-
数据挖掘:数据挖掘阶段是KDD过程的核心环节,其目标是使用一定的模型算法提取数据模式。这可能包括分类、聚类、关联规则、序列模式、异常检测等多种数据挖掘任务。数据挖掘阶段需要选择合适的算法模型,并调整参数以优化模型的性能。
-
模式评估:模式评估阶段的目标是根据某种兴趣度度量,识别代表知识的真正有趣的模式。这可能涉及到模式的筛选、排序、验证以及解释等操作。模式评估的目的是确保挖掘出来的模式具有实际意义和价值。
-
知识表示:知识表示阶段的目标是使用可视化和知识表示技术,向用户提供挖掘的知识。这可能包括图表、报表、仪表盘等多种形式。知识表示的目的是使得用户能够理解和利用挖掘出来的知识,从而支持决策和行动。
- 总结来说,数据挖掘是从大量数据中挖掘有趣模式和知识的过程。在这个过程中,数据清理、数据集成、数据选择、数据变换、数据挖掘、模式评估和知识表示等步骤相互交织、相互依赖,共同构成了KDD过程的完整链条。从算法模型的角度来看,数据挖掘主要依赖于统计学和机器学习算法来实现。统计学提供了丰富的理论和方法来描述和分析数据的分布、关联和趋势,而机器学习则提供了一系列强大的工具和模型来自动学习和预测数据的规律和模式。通过结合这两种方法,数据挖掘可以有效地发现和利用数据中的价值和知识,为各种领域和应用提供有力的支持和指导。
四、典型的数据挖掘系统
- 典型的数据挖掘系统主要包括以下几种:
- WEKA:WEKA是一款开源的数据挖掘工具,它提供了丰富的数据预处理、分类、聚类、回归、关联规则学习等算法。WEKA的用户界面友好,支持多种数据格式,适合科研和教学使用。
- Weka学习笔记01:初探Weka世界
- Weka学习笔记02:数据准备
- Weka学习笔记03:基于关联规则的数据挖掘
-
RapidMiner:RapidMiner是一款商业化的数据挖掘软件,它提供了全面的数据挖掘功能,包括数据预处理、可视化、机器学习、深度学习等。RapidMiner具有直观的图形化界面和强大的编程能力,适用于企业级的数据分析和预测。
-
SAS Enterprise Miner:SAS Enterprise Miner是SAS公司推出的一款高级数据挖掘工具,它集成了数据清洗、探索性分析、预测模型构建、模型评估和部署等功能。SAS Enterprise Miner适用于大型企业的复杂数据分析和决策支持。
-
IBM SPSS Modeler:IBM SPSS Modeler是一款强大的数据挖掘和预测分析软件,它提供了拖放式的工作流界面和丰富的算法库,支持数据预处理、分类、聚类、关联规则、序列发现等多种任务。IBM SPSS Modeler适用于各种行业和应用场景的数据分析。
-
KNIME:KNIME是一款开源的数据科学平台,它提供了数据集成、数据预处理、机器学习、深度学习、可视化等模块。KNIME支持灵活的工作流设计和扩展插件机制,适用于科研和企业级的数据分析。
- 这些典型的数据挖掘系统各有特点和优势,可以根据实际需求和应用场景选择合适的数据挖掘工具。同时,随着大数据和人工智能技术的发展,新的数据挖掘系统和工具也在不断涌现,为数据挖掘领域的研究和应用提供了更多的可能性和机遇。
相关文章:
学习笔记:数据挖掘与机器学习
文章目录 一、数据挖掘、机器学习、深度学习的区别(一)数据挖掘(二)机器学习(三)深度学习(四)总结 二、数据挖掘体系三、数据挖掘的流程四、典型的数据挖掘系统 一、数据挖掘、机器学…...
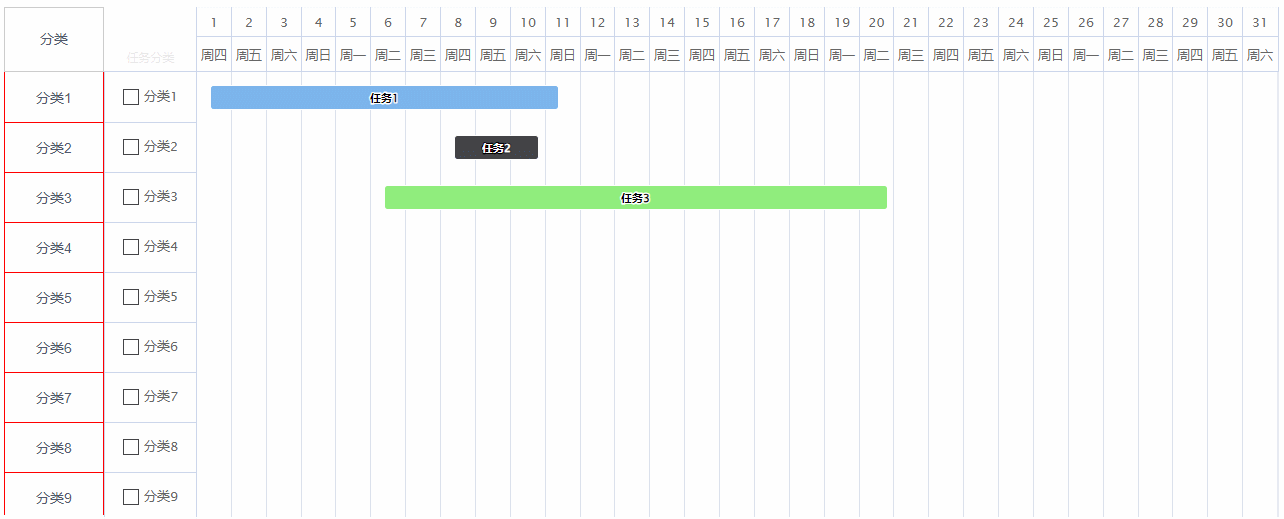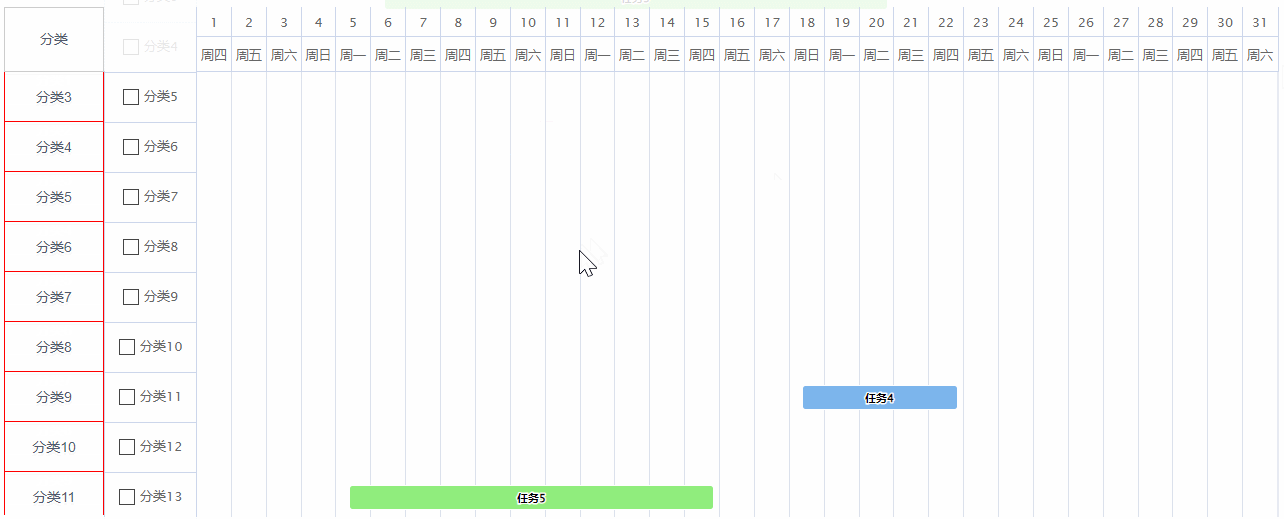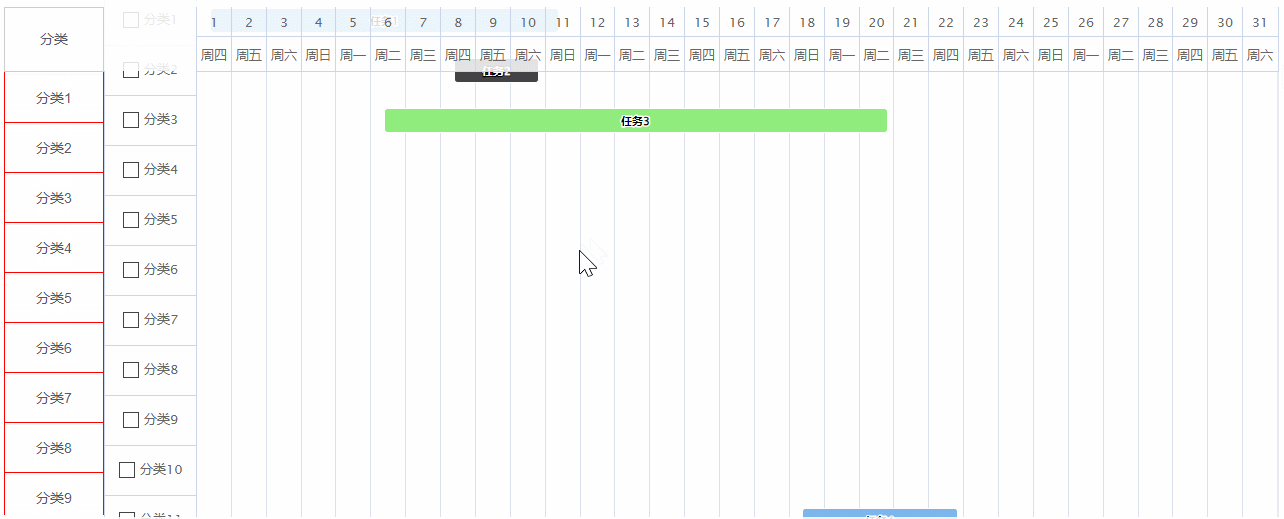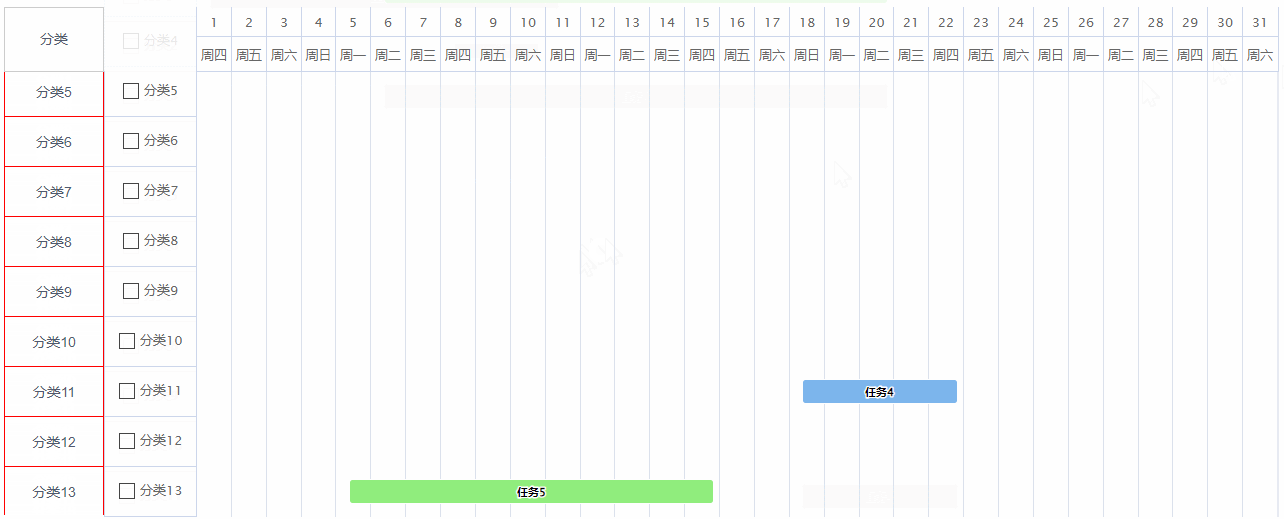
highcharts的甘特图设置滚动时表头固定,让其他内容跟随滚动
效果图:最左侧的分类列是跟随甘特图滚动的,因为这一列如果需要自定义,比如表格的话可能会存在行合并的情况,这个时候甘特图是没有办法做的,然后甘特图的表头又需要做滚动时固定,所以设置了甘特图滚动时&…...
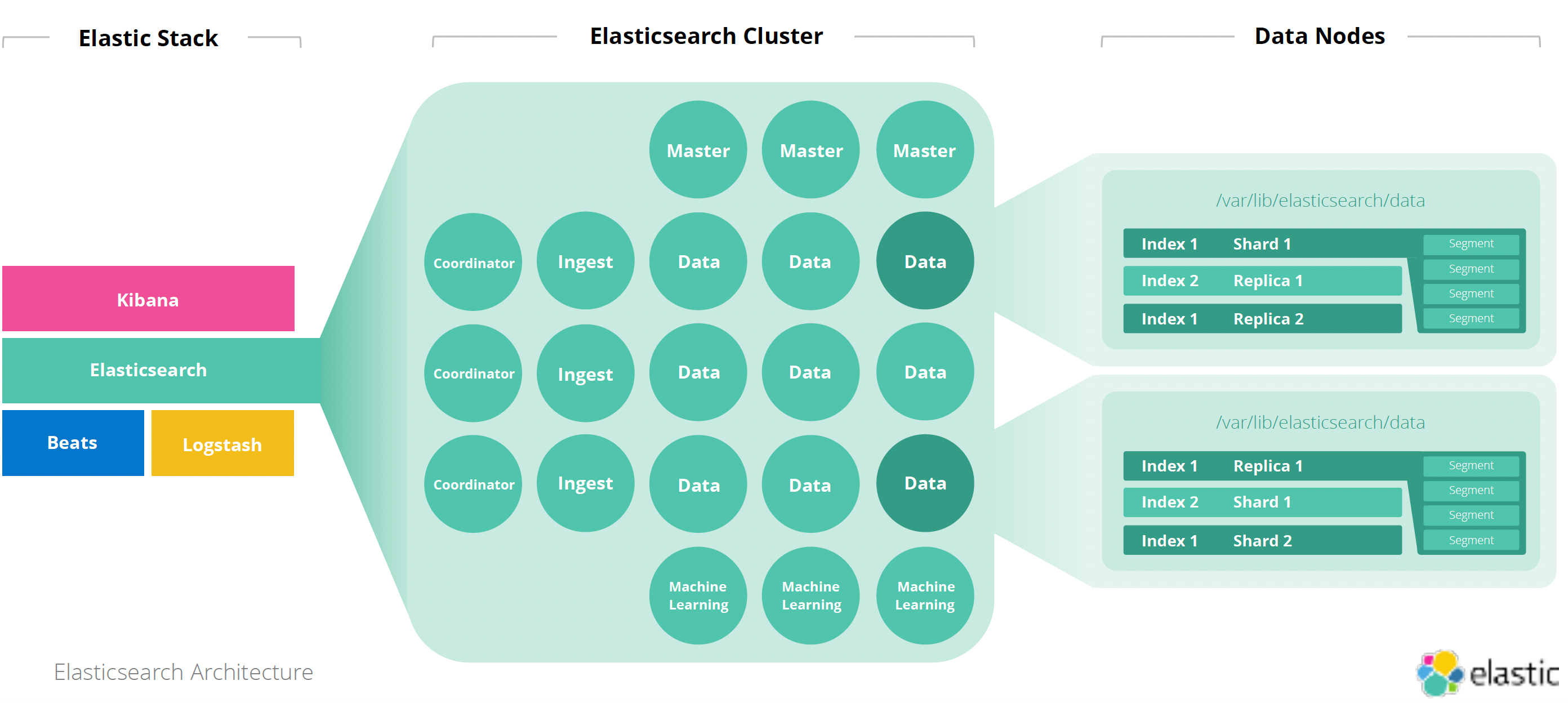
ElasticSearch 架构设计
介绍 ElasticSearchMySQLIndexTableDocumentRowFieldColumnMappingSchemaQuery DSLSQLaggregationsgroup by,avg,sumcardinality去重 distinctreindex数据迁移 ElasticSearch 中的一个索引由一个或多个分片组成 每个分片包含多个 segment(分…...
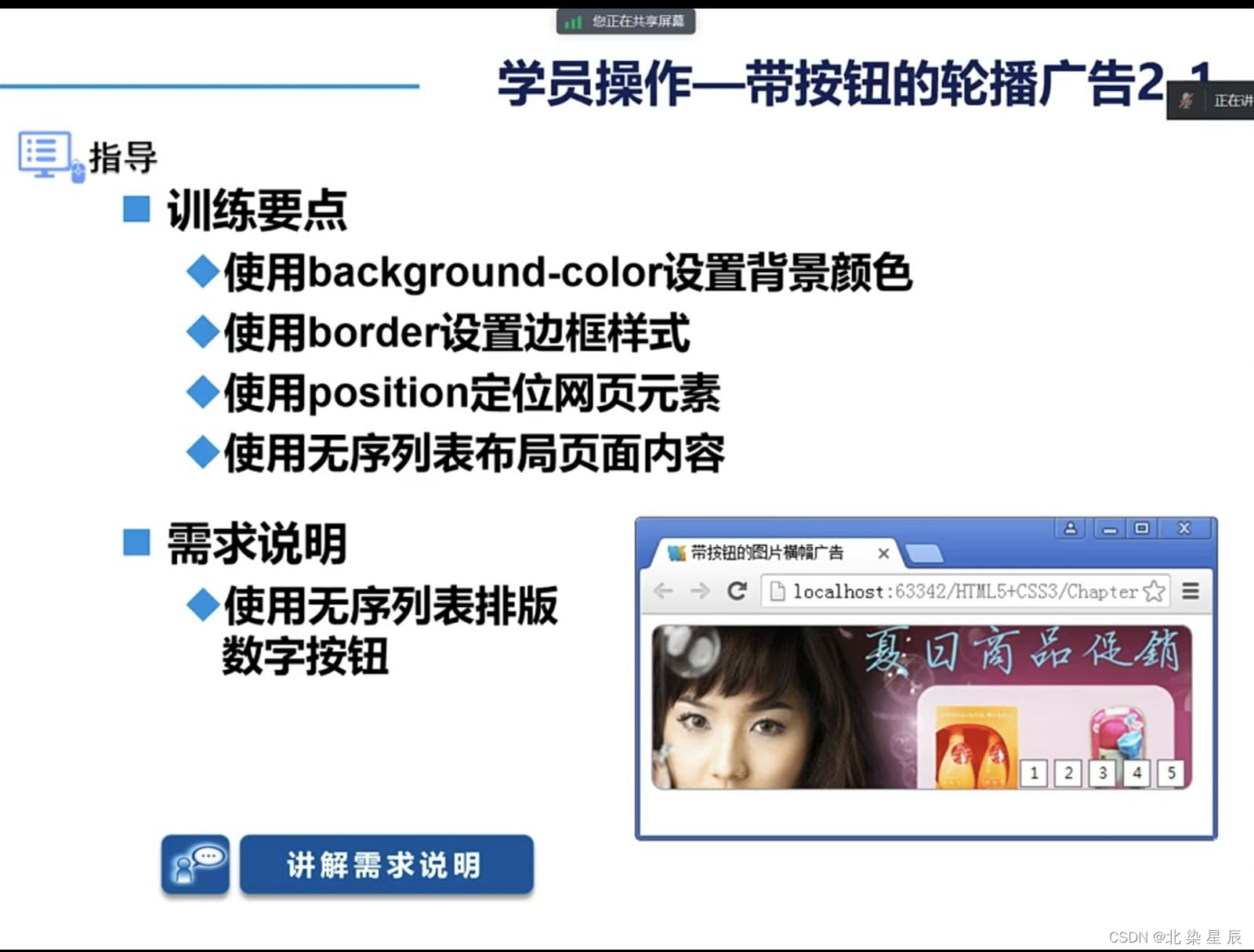
HTML---定位
目录 文章目录 一.定位属性概述 二.position 基础数值 三.z-index属性 网页元素透明度 练习 一.定位属性概述 HTML中的定位属性指的是用来控制HTML元素在页面中的位置和布局的属性,包括position、top、bottom、left和right等。 position属性指定了元素的定位方式&a…...

JVM高频面试题(2023最新版)
JVM面试题 1、JVM内存区域 Jvm包含两个子系统和两个组件。 1.1子系统 Class loader(类加载器):根据给定的全限定名类名(java.lang.object)来装载class文件到Runtime data area(运行时数据区)…...
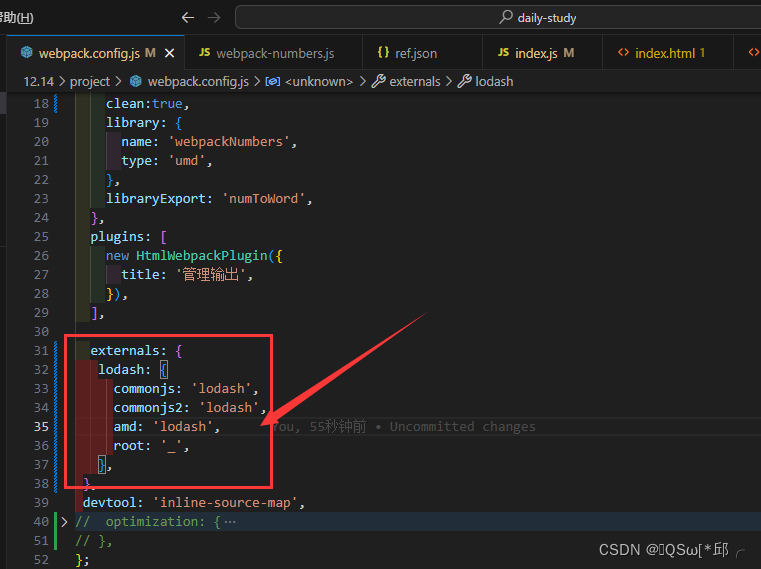
webpack学习-7.创建库
webpack学习-7.创建库 1.暴露库1.1概念1.2验证1.2.1 不导出方法1.2.2 导出方法 2.外部化 lodash3.外部化的限制4.最终步骤5.使用自己的库5.1坑 6.总结 1.暴露库 这个模块学习有点坑。看名字就是把自己写的个包传到npm,而且还要在项目中使用到它,支持各种…...

MQTT - 笔记
1 Mosquitto 官网 https://mosquitto.org/ 2 Windows环境下安装配置Mosquitto服务及入门操作介绍 Windows环境下安装配置Mosquitto服务及入门操作介绍-CSDN博客 3 开源:MQTT安装与配置使用 【C++】开源:MQTT安装与配置使用_c++ mqtt-CSDN博客 4 一文搞懂Qt-MQTT开发...

Django 安装
各位小伙伴想要博客相关资料的话,关注公众号:chuanyeTry即可领取相关资料! Django 安装 在安装 Django 前,系统需要已经安装了 Python 的开发环境。 如果你还没有安装 Python,请先从 Python 官网 https://www.python…...
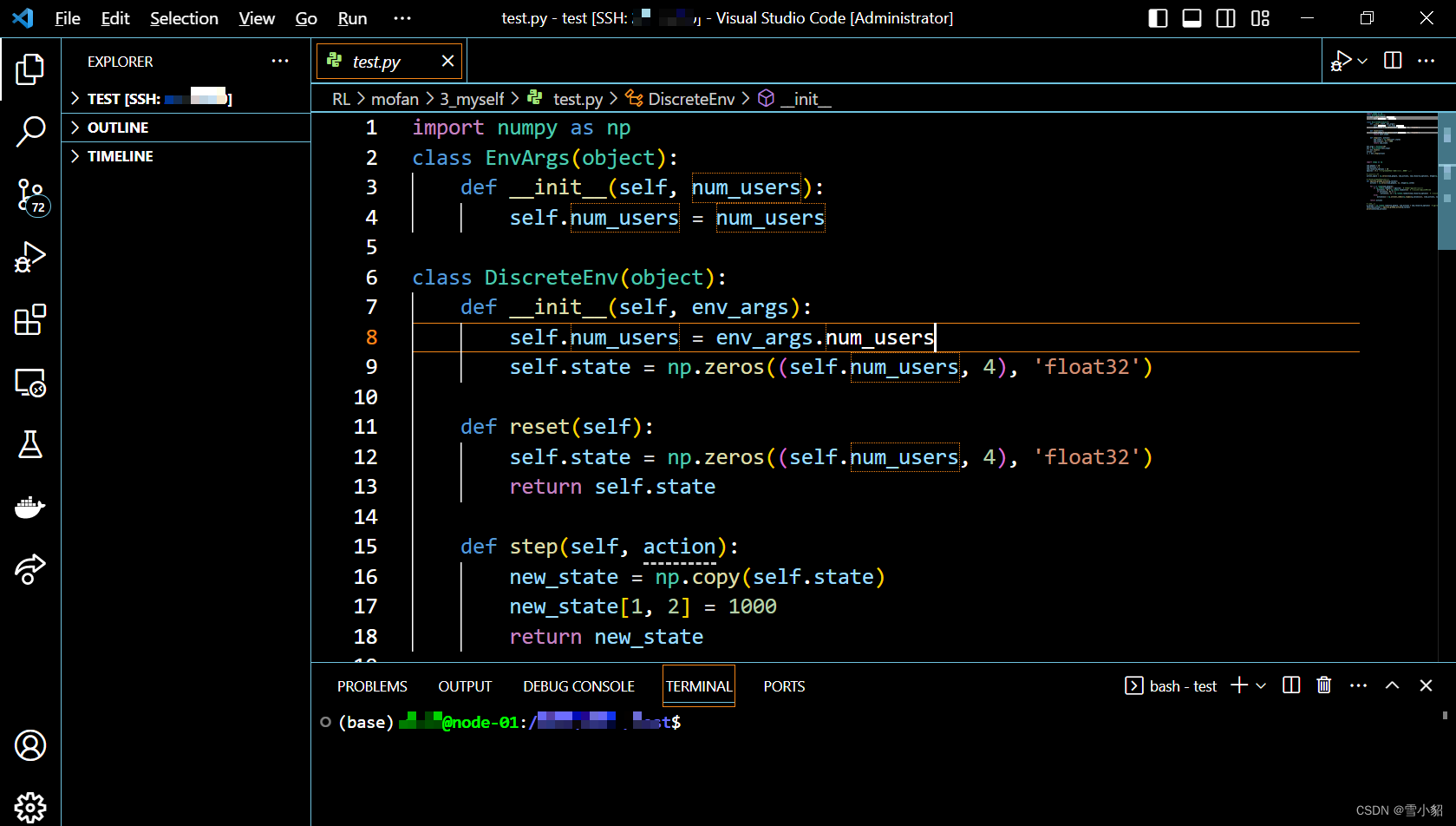
推荐一个vscode看着比较舒服的主题:Dark High Contrast
主题名称:Dark High Contrast (意思就是,黑色的,高反差的) 步骤:设置→Themes→Color Theme→Dark High Contrast 效果如下: 感觉这个颜色的看起来比较舒服。...

YCSB 测试表预分区
最近使用 YCSB 测试时,一直使用如下方法创建预分区: TABLE_NAME"usertable" REGIN_SPLITS$((510-1)) cat << EOF | sudo -u hbase hbase shell create ${TABLE_NAME}, cf, {SPLITS > (1..${REGIN_SPLITS}).map {|i| "user#{100…...

K8s 教程
一文让你全面了解K8s(Kubernetes) - 知乎 Install and Set Up kubectl on Linux | Kubernetes阿里巴巴开源镜像站-OPSX镜像站-阿里云开发者社区 留存一份地址...
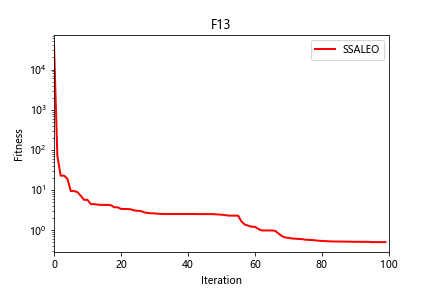
python:改进型鳟海鞘算法(SSALEO)求解23个基本函数
一、改进型鳟海鞘算法SSALEO 改进型鳟海鞘算法(SSALEO)由Mohammed Qaraad等人于2022年提出。 参考文献:M. Qaraad, S. Amjad, N. K. Hussein, S. Mirjalili, N. B. Halima and M. A. Elhosseini, "Comparing SSALEO as a Scalable Larg…...
)
Hive-数据模型详解(超详细)
文章目录 一、Hive数据模型1. 概述2. 数据库和表(1) 创建数据库(2) 使用数据库(3) 创建表格(4) 查看表结构 3. 分区与桶(1) 分区(2) 桶 4. 数据加载与查询(1) 数据导入(2) 查询语句 5. 总结 一、Hive数据模型 1. 概述 Hive是基于Hadoop的数据仓库工具,它提供了类似…...

docker的常规使用总结
不安装docker下载镜像,或者下载异构镜像,模拟docker客户端 https://pull.7ii.win/ 1、启动docker服务 systemctl start docker 设置开机自启 systemctl enable docker 2、查看镜像 docker images --查看下载镜像架构 docker inspect 镜像名字 |…...

CSS 文字弹跳效果
鼠标移过去 会加快速度 <template><div class"bounce"><p class"text" :style"{animationDuration: animationDuration}">欢迎使用UniApp Vue3!</p></div> </template><script> export d…...

什么是动态IP?静态IP和动态IP有什么区别?
动态IP(Dynamic IP)和静态IP(Static IP)它是指在计算机网络中分配给设备的两种不同类型的IP地址。 动态IP是指每次设备连接到网络时,网络服务提供商(ISP)IP地址的动态分配。当设备重新连接到网络时,它可能会被分配到不同的IP地址。动态IP适用于传统的家…...
Linux 与 Shell
Linux系统的四部分:Linux系统的核心是内核。内核主要负责四种功能: 系统内存管理 操作系统内核的主要功能之一:内存管理。(物理内存 虚拟内存)内核通过硬盘上称为交换空间(swap space)的存储区…...
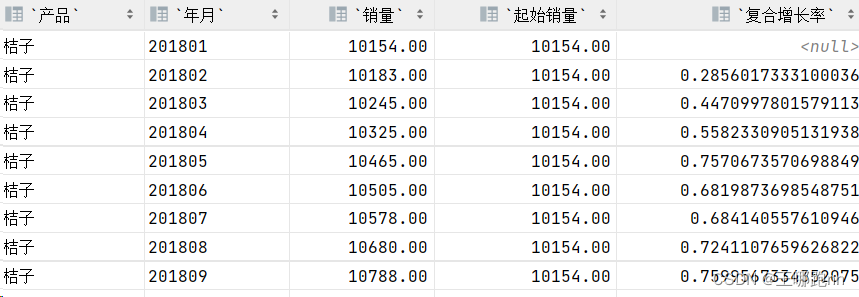
大数据-Hive练习-环比增长率、同比增长率、复合增长率
目录 🥙12.1 环比增长率 1. 概述 2. 公式 3. 示例 4.练习-需求:计算各类商品的月环比增长率 🥙12.2 同比增长率 1. 概述 2. 公式 3. 示例 4. 练习-需求:计算各类商品的月同比增长率 🥙12.3 复合增长率 1. 概述 2. 公式 3. 示例…...
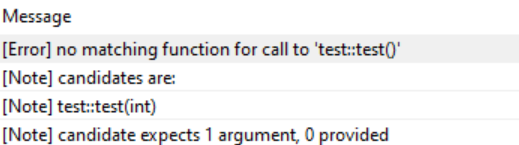
C++ 考前难点总结
前言 后天考c,但这几天得甲流了,特别难受!复习c的时候复习着忘着,所以用csdn记录一下不熟悉的知识点,等后天考前再看一遍! 函数模板 #include <iostream>// 定义一个模板类 template <class T1…...
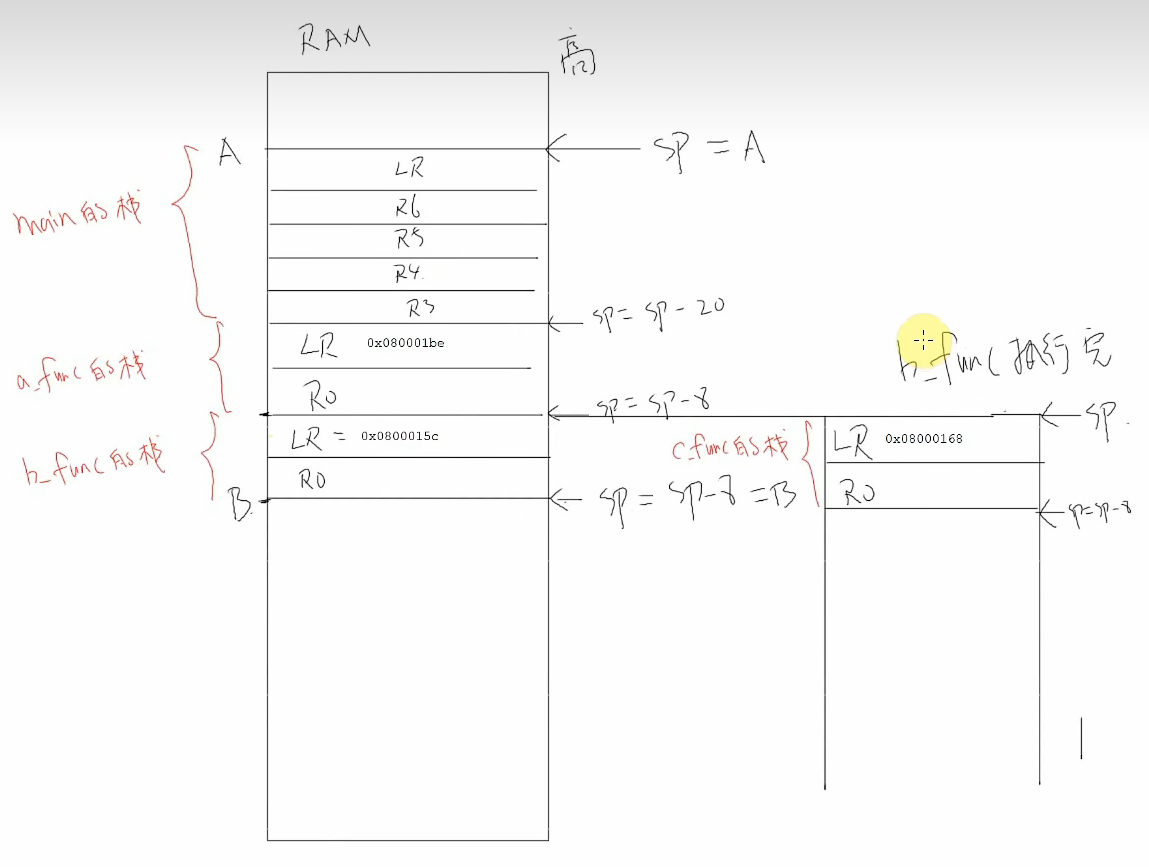
ARM 汇编语言知识积累
博文参考: arm中SP,LR,PC寄存器以及其它所有寄存器以及处理器运行模式介绍 arm平台根据栈进行backtrace的方法-腾讯云开发者社区-腾讯云 (tencent.com) 特殊功能寄存器: SP: 即 R13,栈指针,…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

Python爬虫(一):爬虫伪装
一、网站防爬机制概述 在当今互联网环境中,具有一定规模或盈利性质的网站几乎都实施了各种防爬措施。这些措施主要分为两大类: 身份验证机制:直接将未经授权的爬虫阻挡在外反爬技术体系:通过各种技术手段增加爬虫获取数据的难度…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

SpringTask-03.入门案例
一.入门案例 启动类: package com.sky;import lombok.extern.slf4j.Slf4j; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; import org.springframework.cache.annotation.EnableCach…...