第4章 | 安徽某高校《统计建模与R软件》期末复习
第4章 参数估计
参数估计是统计建模的关键步骤之一,它涉及根据样本数据推断总体参数的过程。在统计学中,参数通常用于描述总体的特征,如均值、方差等。通过参数估计,我们可以利用样本信息对这些未知参数进行推断,从而对总体进行更深入的了解。
4.1 矩法
思想:当我们面对一个统计问题时,通常我们不能观察到整个总体的所有数据,而只能通过取一部分样本来进行研究。为了从这个样本中了解总体的性质,我们引入了一种思想,即使用样本的一些数字特征(矩)来估计总体相应的特征。在这个过程中,我们关注的是总体的矩,而这些矩与总体的参数有密切的关系,从而允许我们得出对总体参数的估计。
矩是描述数据分布的一种方式,例如均值和方差就是常见的矩。我们可以通过样本计算得到样本的矩,然后利用这些样本矩去估计总体的矩,进而得到总体参数的估计。
比如,如果我们想知道一个总体的平均值是多少,我们可以从样本中计算出样本均值,然后用样本均值去估计总体的平均值。这是因为,根据统计理论,样本均值与总体均值有一个紧密的关系,特别是在样本容量足够大的情况下。
这种思想的优势在于,通过研究样本矩与总体矩之间的关系,我们可以从有限的样本中获取关于总体特征的有用信息,而不必观察整个总体。这为我们提供了一种有效的方式,通过小规模的样本来推断和估计总体的性质。
4.1.1 矩法
矩法是一种矩估计法。矩法的核心思想是使用样本矩(样本的各阶矩)去估计总体矩,从而得到总体参数的估计。样本 阶矩的公式如下:
其中:
- n 是样本容量,表示样本中的观测值个数。
是第
个观测值。
是矩的阶数,表示对观测值取
举例:设总体的分布函数中有m个未知参数,假设总体样本的
阶原点矩存在,样本
,令总体的
阶原点矩等于样本的
阶原点矩。以一阶、二阶矩法估计参数举例:
我们可以解得均值和方差的矩法估计:
4.1.2 R语言实现
在二项分布B(k;p)中,求k和p的矩估计。
1)一阶二阶矩法
为样本均值:
为样本二阶中心矩:
解得: ,
# 模拟二项分布
# N=20,p=0.7,试验次数n=100
x <- rbinom(100, 20, 0.7)
# 计算样本均值
m1 <- mean(x)
# 计算样本方差
m2 <- sum((x - mean(x))^2) / 100
# 计算 N
N <- m1^2 / (m1 - m2)
# 计算 p
p <- (m1 - m2) / m12)Newton-Raphson 方法的矩估计
# 定义矩估计函数
moment_fun <- function(p) {# 计算方程组f <- c(p[1] * p[2] - M1, p[1] * p[2] - p[1] * p[2]^2 - M2)# 计算雅可比矩阵J <- matrix(c(p[2], p[1], p[2] - p[2]^2, p[1] - 2 * p[1] * p[2]), nrow = 2, byrow = TRUE)list(f = f, J = J)
}# 定义 Newton-Raphson 优化函数
Newtons <- function(fun, x, ep = 1e-5, it_max = 100) {index <- 0k <- 1while (k <= it_max) {x1 <- xobj <- fun(x)x <- x - solve(obj$J, obj$f)norm <- sqrt(sum((x - x1)^2))if (norm < ep) {index <- 1break}k <- k + 1}obj <- fun(x)list(root = x, it = k, index = index, FunVal = obj$f)
}# 生成二项分布样本
x <- rbinom(100, 20, 0.7)# 获取样本大小
n <- length(x)# 计算样本均值和样本方差
M1 <- mean(x)
M2 <- (n - 1) / n * var(x)# 初始猜测值
p <- c(10, 0.5)# 使用 Newton-Raphson 优化估计参数
result <- Newtons(moment_fun, p)# 输出估计的参数值和迭代次数
cat("估计的 n:", result$root[1], "\n")
cat("估计的 p:", result$root[2], "\n")
cat("迭代次数:", result$it, "\n")4.2 极大似然法
4.2.1 极大似然估计
极大似然估计是一种用于估计统计模型参数的方法。它基于观测到的样本数据,试图找到使得观测数据出现的概率最大的参数值。在讲解极大似然估计之前,我们先来了解一下一些基本的概念。
1)似然函数
似然函数是一个关于模型参数的函数,它描述了在给定模型下观测数据的可能性。对于参数为θ的模型,给定观测到的数据集X,似然函数表示为 L(θ|X)。对于离散型随机变量,似然函数通常是概率质量函数的乘积;对于连续型随机变量,似然函数是概率密度函数的乘积。
设总体X的概率密度函数或分布律为,
是来自总体X的样本,则
的似然函数为:
2)极大似然估计
极大似然估计的目标是找到使似然函数取最大值的参数值,即找到使得观测到的数据在给定模型下出现的概率最大的模型参数。通常我们会取对数似然函数,因为这样便于计算。
假设有一组观测数据X={x₁, x₂, ..., xₙ},且这些数据是从一个分布(比如正态分布、二项分布等)中产生的。该分布有一个参数θ,我们的目标是通过这组观测数据估计出θ。
-
写出似然函数: 建立观测数据的似然函数L(θ|X),表示观测数据在给定参数θ下的概率。
-
取对数: 通常取对数似然函数,因为对数函数的最大值点与原函数的最大值点是一样的,而且对数函数便于计算。
-
求导数: 对对数似然函数关于θ的导数,然后令导数等于零,解出参数θ。
-
解方程: 解出的θ值即为极大似然估计。
4.2.2 R语言实现
1)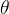 连续
连续
举例:正态分布
# 安装并加载 rootSolve 包
# install.packages("rootSolve") # 如果未安装,需要先运行这行代码安装包
library(rootSolve)# 生成样本
x <- rnorm(10)# 定义似然函数和 multiroot 求解模型
model <- function(e, x) {n <- length(x)F1 <- sum(x - e[1])F2 <- -n / (e[2])^2 + sum((x - e[1])^2) / e[2]^4c(F1, F2)
}# 使用 multiroot 函数计算似然方程组的根(即估计的参数)
result <- multiroot(f = model, start = c(0, 1), x = x)# 输出结果
cat("估计的均值:", result$root[1], "\n")
cat("估计的标准差:", result$root[2], "\n")
4) 离散
# 生成 Cauchy 分布的样本
x <- rcauchy(100, 1)# 定义对数似然函数
loglike <- function(p) {n <- length(x)log(3.14159) * n + sum(log(1 + (x - p)^2))
}# 使用 optimize 函数找到对数似然函数的最大值
result <- optimize(loglike, interval = c(0, 5))# 输出结果
cat("估计的参数 p:", result$maximum, "\n")
cat("对数似然函数的最大值:", result$objective, "\n")
4.3 区间估计
4.3.1 区间估计
设总体X的分布函数F(x,θ)含有未知参数θ,对于给定值α(0< α<1),若由样本确定的两个统计量,
和
满足:
则称随机区间是参数
的置信度为
的置信区间。
4.3.2 一个正态总体的区间估计
1)均值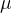 的估计
的估计
已知时:参数
的双侧置信区间:
推出:
推出:
在R语言中,我们可以引入interval_esitimate11函数来做估计:
# 定义函数 interval_estimate11
# 参数:
# x: 数据向量
# sigma: 总体标准差,如果为正值则使用,否则使用样本标准差
# alpha: 置信水平,默认为 0.05
interval_estimate11 <- function(x, sigma = -1, alpha = 0.05) { n <- length(x)xb <- mean(x)# 根据 sigma 是否为正值选择使用 Z 分布或者 t 分布if (sigma >= 0) { tmp <- sigma / sqrt(n) * qnorm(1 - alpha / 2) # Z 分布的临界值df <- n} else {# 当 sigma 为负值时,根据样本大小选择使用 Z 分布或者 t 分布if (n >= 30) { tmp <- sd(x) / sqrt(n) * qnorm(1 - alpha / 2) # Z 分布的临界值df <- n} else { tmp <- sd(x) / sqrt(n) * qt(1 - alpha / 2, n - 1) # t 分布的临界值df <- n - 1}}# 构建结果数据框result <- data.frame(mean = xb, df = df, a = xb - tmp, b = xb + tmp)return(result)
}# 生成样本数据
x <- rnorm(20, 1, 0.04)# 调用函数并输出结果
interval_estimate11(x)在R语言中,函数 t.test() 也提供了 t 检验和相应的区间估计的功能:
t.test(x, # 第一个样本或一组观测值y = NULL, # 第二个样本,如果只有一个样本则为 NULLalternative = c("two.sided", "less", "greater"),# 假设检验的方向,可选值为 "two.sided"(双侧检验,默认)、"less"(左侧检验)、"greater"(右侧检验)mu = 0, # 要检验的假设均值,默认为 0paired = FALSE, # 是否为配对样本(paired samples),默认为 FALSEvar.equal = FALSE, # 是否假设两个总体方差相等,默认为 FALSEconf.level = 0.95) # 置信水平,默认为 0.95
2)方差的估计
在R语言中,我们可以引入函数interval_var1来求解:
# 定义函数 interval_var1
# 参数:
# x: 数据向量
# mu: 假设的总体方差值,默认为 Inf 表示不指定
# alpha: 置信水平,默认为 0.05
interval_var1 <- function(x, mu = Inf, alpha = 0.05) { n <- length(x)# 根据 mu 是否为无穷选择使用总体方差估计还是样本方差估计if (mu < Inf) {S2 <- sum((x - mu)^2) / ndf <- n} else {S2 <- var(x)df <- n - 1}# 计算置信区间的上下界a <- df * S2 / qchisq(1 - alpha / 2, df)b <- df * S2 / qchisq(alpha / 2, df)# 构建结果数据框result <- data.frame(var = S2, df = df, a = a, b = b)return(result)
}# 生成样本数据
x <- c(23, 25, 28, 22, 20)# 调用函数并输出结果
interval_var1(x)
4.3.3 两个正态总体的区间估计
解决两个正态总体的区间估计时,我们可以引入函数interval_estimate2:
# 定义函数 interval_estimate2
# 参数:
# x: 第一个样本数据向量
# y: 第二个样本数据向量
# sigma: 总体标准差,如果为正值则使用,否则使用样本标准差
# var.equal: 是否假设两个总体方差相等,默认为 FALSE
# alpha: 置信水平,默认为 0.05
interval_estimate2 <- function(x, y, sigma = c(-1, -1), var.equal = FALSE, alpha = 0.05) { n1 <- length(x)n2 <- length(y)xb <- mean(x)yb <- mean(y)if (all(sigma >= 0)) { # 均值差μ1- μ2的区间估计(置信度为1-α)tmp <- qnorm(1 - alpha / 2) * sqrt(sigma[1]^2 / n1 + sigma[2]^2 / n2)df <- n1 + n2} else {if (var.equal == TRUE) {Sw <- ((n1 - 1) * var(x) + (n2 - 1) * var(y)) / (n1 + n2 - 2)tmp <- sqrt(Sw * (1 / n1 + 1 / n2)) * qt(1 - alpha / 2, n1 + n2 - 2)df <- n1 + n2 - 2} else {S1 <- var(x)S2 <- var(y)nu <- (S1 / n1 + S2 / n2)^2 / (S1 / n1^2 / (n1 - 1) + S2 / n2^2 / (n2 - 1))tmp <- qt(1 - alpha / 2, nu) * sqrt(S1 / n1 + S2 / n2)df <- nu}}# 构建结果数据框result <- data.frame(mean = xb - yb, df = df, a = xb - yb - tmp, b = xb - yb + tmp)return(result)
}# 生成两个样本数据
x <- c(23, 25, 28, 22, 20)
y <- c(29, 31, 30, 32, 27)# 调用函数并输出结果
interval_estimate2(x, y)
4.3.4 配对数据均值差的区间估计
我们可以用 t.test() 函数直接求解:
# 定义两组观测值
x <- c(11.3, 15.0, 15.0, 13.5, 12.8, 10.0, 11.0, 12.0, 13.0, 12.3)
y <- c(14.0, 13.8, 14.0, 13.5, 13.5, 12.0, 14.7, 11.4, 13.8, 12.0)# 执行独立样本 t 检验
result <- t.test(x - y)# 输出检验结果
print(result)
也可以引入前面的interval_estimate1函数:
# 定义函数 interval_estimate1
# 参数:
# x: 数据向量
# mu: 假设的总体均值,默认为 Inf 表示不指定
# alpha: 置信水平,默认为 0.05
interval_estimate1 <- function(x, mu = Inf, alpha = 0.05) { n <- length(x)# 根据 mu 是否为无穷选择使用总体均值估计还是样本均值估计if (mu < Inf) {mean_val <- mutmp <- qnorm(1 - alpha / 2) * sqrt(var(x) / n)df <- n} else {mean_val <- mean(x)tmp <- qt(1 - alpha / 2, df = n - 1) * sqrt(var(x) / n)df <- n - 1}# 计算置信区间的上下界a <- mean_val - tmpb <- mean_val + tmp# 构建结果数据框result <- data.frame(mean = mean_val, df = df, a = a, b = b)return(result)
}# 定义两组观测值
x <- c(11.3, 15.0, 15.0, 13.5, 12.8, 10.0, 11.0, 12.0, 13.0, 12.3)
y <- c(14.0, 13.8, 14.0, 13.5, 13.5, 12.0, 14.7, 11.4, 13.8, 12.0)# 计算差异向量
z <- x - y# 调用函数并输出结果
interval_estimate1(z)4.3.5 方差比的区间估计
# 定义函数 interval_var2
# 参数:
# x: 第一个样本数据向量
# y: 第二个样本数据向量
# mu: 假设的总体方差比率,默认为 Inf 表示不指定
# alpha: 置信水平,默认为 0.05
interval_var2 <- function(x, y, mu = c(Inf, Inf), alpha = 0.05) { n1 <- length(x)n2 <- length(y)if (all(mu < Inf)) {Sx2 <- 1 / n1 * sum((x - mu[1])^2)Sy2 <- 1 / n2 * sum((y - mu[2])^2)df1 <- n1df2 <- n2} else if (mu[1] < Inf && mu[2] == Inf) {Sx2 <- 1 / n1 * sum((x - mu[1])^2)Sy2 <- var(y)df1 <- n1df2 <- n2 - 1} else if (mu[1] == Inf && mu[2] < Inf) {Sx2 <- var(x)Sy2 <- 1 / n2 * sum((y - mu[2])^2)df1 <- n1 - 1df2 <- n2} else {Sx2 <- var(x)Sy2 <- var(y)df1 <- n1 - 1df2 <- n2 - 1}r <- Sx2 / Sy2a <- r / qf(1 - alpha / 2, df1, df2)b <- r / qf(alpha / 2, df1, df2)# 构建结果数据框result <- data.frame(rate = r, df1 = df1, df2 = df2, a = a, b = b)return(result)
}# 定义两组观测值
a <- c(79.98, 80.04, 80.02, 80.04, 80.03, 80.03, 80.04, 79.97, 80.05, 80.03, 80.02, 80.00, 80.02)
b <- c(80.02, 79.94, 79.98, 79.97, 79.97, 80.03, 79.95, 79.97)# 调用函数并输出结果
interval_var2(a, b, mu = c(80, 60))
interval_var2(a, b, mu = c(Inf, Inf))
interval_var2(a, b, mu = c(80, Inf))
interval_var2(a, b, mu = c(Inf, 60))
4.3.6 非正态总体的区间估计
# 定义函数 interval_estimate3
# 参数:
# x: 数据向量
# sigma: 总体标准差的估计值,默认为 -1,表示使用样本标准差
# alpha: 置信水平,默认为 0.05
interval_estimate3 <- function(x, sigma = -1, alpha = 0.05) { n <- length(x)xb <- mean(x)if (sigma >= 0) {tmp <- sigma / sqrt(n) * qnorm(1 - alpha / 2)} else {tmp <- sd(x) / sqrt(n) * qnorm(1 - alpha / 2)}# 构建结果数据框result <- data.frame(mean = xb, a = xb - tmp, b = xb + tmp)return(result)
}# 使用示例:
# 定义一个数据向量
x <- c(11.3, 15.0, 15.0, 13.5, 12.8, 10.0, 11.0, 12.0, 13.0, 12.3)# 调用函数并输出结果
interval_estimate3(x)4.3.7 单侧置信区间估计
# 定义函数 interval_estimate4
# 参数:
# x: 数据向量
# sigma: 总体标准差的估计值,默认为 -1,表示使用样本标准差
# side: 置信区间的一侧,默认为 0 表示双侧置信区间,<0 表示左侧,>0 表示右侧
# alpha: 置信水平,默认为 0.05
interval_estimate4 <- function(x, sigma = -1, side = 0, alpha = 0.05) { n <- length(x)xb <- mean(x)if (sigma >= 0) { # 总体标准差已知if (side < 0) { # 左侧置信区间tmp <- sigma / sqrt(n) * qnorm(1 - alpha)a <- -Infb <- xb + tmp} else if (side > 0) { # 右侧置信区间tmp <- sigma / sqrt(n) * qnorm(1 - alpha)a <- xb - tmpb <- Inf} else { # 双侧置信区间tmp <- sigma / sqrt(n) * qnorm(1 - alpha / 2)a <- xb - tmpb <- xb + tmp}df <- n} else { # 总体标准差未知if (side < 0) { # 左侧置信区间tmp <- sd(x) / sqrt(n) * qt(1 - alpha, n - 1)a <- -Infb <- xb + tmp} else if (side > 0) { # 右侧置信区间tmp <- sd(x) / sqrt(n) * qt(1 - alpha, n - 1)a <- xb - tmpb <- Inf} else { # 双侧置信区间tmp <- sd(x) / sqrt(n) * qt(1 - alpha / 2, n - 1)a <- xb - tmpb <- xb + tmp}df <- n - 1}# 构建结果数据框result <- data.frame(mean = xb, df = df, a = a, b = b)return(result)
}# 使用示例:
# 定义一个数据向量
x <- c(11.3, 15.0, 15.0, 13.5, 12.8, 10.0, 11.0, 12.0, 13.0, 12.3)# 调用函数并输出结果
# 默认为双侧置信区间
interval_estimate4(x)# 左侧置信区间
interval_estimate4(x, side = -1)# 右侧置信区间
interval_estimate4(x, side = 1)
(个人总结,如有谬误或需要改进之处欢迎联系作者)
相关文章:
第4章 | 安徽某高校《统计建模与R软件》期末复习
第4章 参数估计 参数估计是统计建模的关键步骤之一,它涉及根据样本数据推断总体参数的过程。在统计学中,参数通常用于描述总体的特征,如均值、方差等。通过参数估计,我们可以利用样本信息对这些未知参数进行推断,从而…...
)
localforage本地存储(融合Web Storage,Web SQL Database,ndexedDB三种前端存储)
介绍 localForage 是一个快速而简单的 JavaScript 存储库。通过使用异步存储(IndexedDB 或 WebSQL)和简单的类 localStorage 的 API ,localForage 能改善 Web 应用的离线体验。 在不支持 IndexedDB 或 WebSQL 的浏览器中,localF…...
【JavaWeb学习笔记】17 - ThreadLocal
项目代码 https://github.com/yinhai1114/JavaWeb_LearningCode/tree/main/threadlocal/src/com/yinhai/thread 目录 项目代码 一、什么是ThreadLocal? 二、ThreadLocal快速入门 三、源码解读 一、什么是ThreadLocal? 1. ThreadLocal的作用,可以实现在同一个线…...

【ARMv8M Cortex-M33 系列 1 -- SAU 介绍】
文章目录 Cortex-M33 SAU 介绍SAU 的主要功能包括SAU 寄存器配置示例 Cortex-M33 SAU 介绍 在 ARMv8-M 架构中,SAU(Security Attribution Unit)是安全属性单元,用于配置和管理内存区域的安全属性。SAU 是 ARM TrustZone 技术的一…...

sklearn 逻辑回归Demo
逻辑回归案例 假设表示 基于上述情况,要使分类器的输出在[0,1]之间,可以采用假设表示的方法。 设 h θ ( x ) g ( θ T x ) h_θ (x)g(θ^T x) hθ(x)g(θTx), 其中 g ( z ) 1 ( 1 e − z ) g(z)\frac{1}{(1e^{−z} )} g(z)(1e−z)1…...

什么是众创空间?他有什么特点?
众创空间,是一种为大众创新创业提供专业化服务的创业服务平台,是顺应网络时代创新创业特点和需求,通过市场化机制、专业化服务和资本化途径构建的低成本、便利化、全要素、开放式的新型创业服务平台的统称。众创空间包括创客空间、联合办公空…...

什么是数据分析思维
参考 一文学会如何做电商数据分析(附运营分析指标框架) 电子商务该如何做数据分析?如何数据分析入门(从各项指标表象进入) https://www.processon.com/outline/6589838c3129f1550cc69950 数据分析步骤 什么是数据分析…...
利用Milvus Cloud和LangChain构建机器人:一种引人入胜且通俗易懂的方法
一、引言 机器人已经深入我们的日常生活,从家庭服务到工业生产,再到医疗和运输等领域。然而,这些机器人往往需要复杂的算法和数据处理技术才能有效地执行任务。在这个过程中,人工智能(AI)和机器学习&#…...

数据结构-如何实现一个队列?逐步解析与代码示例(超详细)
文章目录 前言1.队列的基本概念2.链表与数组实现队列的区别2.1数据存储结构2.2性能2.3内存使用 3.为什么选择链表实现队列?4.结构定义函数声明 5.核心操作5.1初始化 (QInit)5.2销毁 (QDestroy)5.3入队 (QPush)5.4出队 (QPop) 6.队列的查询操作6.1队首元素 (QueueFro…...
爬虫工作量由小到大的思维转变---<第二十三章 Scrapy开始很快,越来越慢(医病篇)>
诊断篇https://blog.csdn.net/m0_56758840/article/details/135170994?ops_request_misc%257B%2522request%255Fid%2522%253A%2522170333243316800180644102%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id1703332433168001806441…...
.Net7.0 或更高版本 System.Drawing.Common 上传图片跨平台方案
项目升级.Net7.0以后,System.Drawing.Common开关已经被删除,且System.Drawing.Common仅在 Windows 上支持 ,于是想办法将原来上传图片验证文件名和获取图片扩展名方法替换一下,便开始搜索相关解决方案。 .Net6.0文档:…...

【MySQL】InnoDB和MyISAM区别
文章目录 一、索引不同1 InnoDB聚簇索引,MyISAM非聚簇索引1 InnoDB聚簇索引2 MyISAM非聚簇索引 2 InnoDB必须要有主键,MyISAM允许没有主键3 InnoDB支持外键4 InnoDB不支持全文索引5 索引保存位置不同 二、对事物的支持三、存储结构不同四、存储空间不同五…...

3分钟了解安全数据交换系统有什么用!
企业为了保护核心数据安全,都会采取一些措施,比如做网络隔离划分,分成了不同的安全级别网络,或者安全域,接下来就是需要建设跨网络、跨安全域的安全数据交换系统,将安全保障与数据交换功能有机整合在一起&a…...
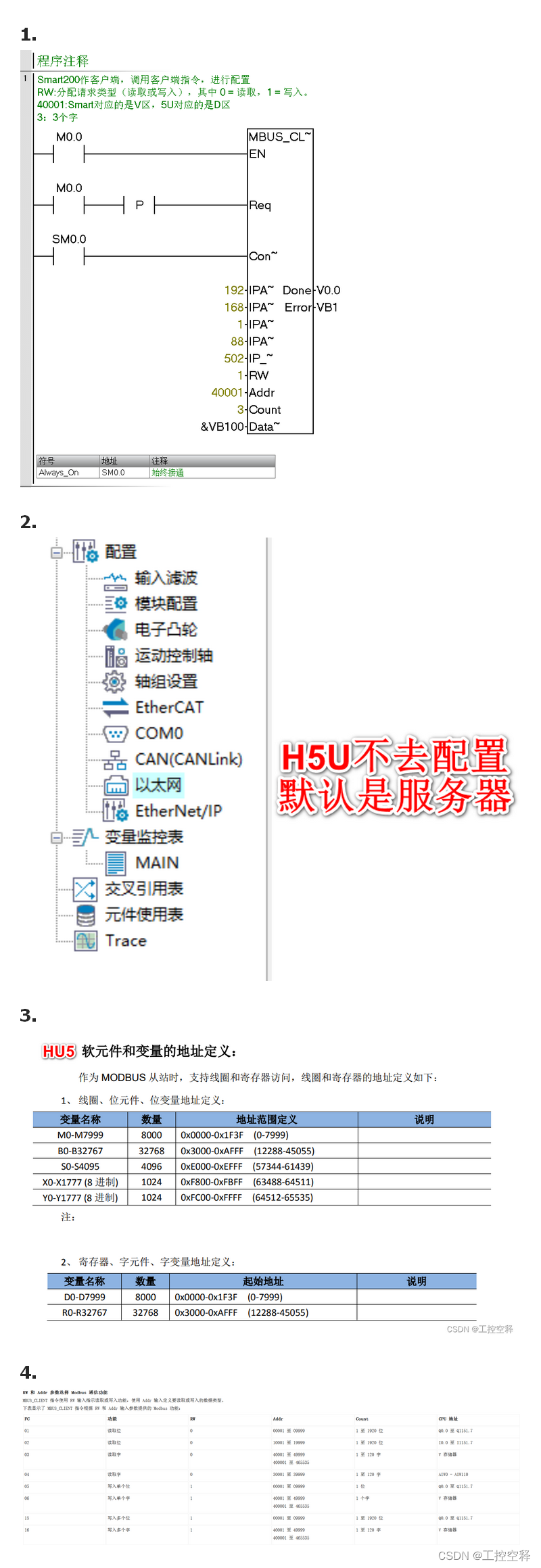
记录汇川:MODBUS TCP-梯形图
H5U的MODBUS通信不需要编写程序,通过组态MODBUS通信配置表,实现数据通信。 Modbus-TCP 主站即Modbus-TCP客户端,通过Modbus-TCP配置,可最多支持同时与31个 Modbus-TCP服务器(从站)进行通讯。 …...

electron + sqlite3 解决打包后无法写入数据库
前言 window环境。 electron28.0.0 sqlite35.1.6 使用 electron-builder 打包。 本文旨在解决打包后无法写入数据库的问题。 但如果你是打包后无法访问sqlite,且有报错弹窗,不妨也看看本文。 也许是同一种原因。 错误原因分析 打包后无法创建db文件&…...

【uniapp小程序-生成二维码+多个图片文字合并一张图】
<!-- 二维码 --><canvas id"qrcode" canvas-id"qrcode" width"120" ></canvas><!-- 生成带小程序码的分享图片 --><canvas canvas-id"shareCanvas" class"share-canvas"></canvas>#qrc…...
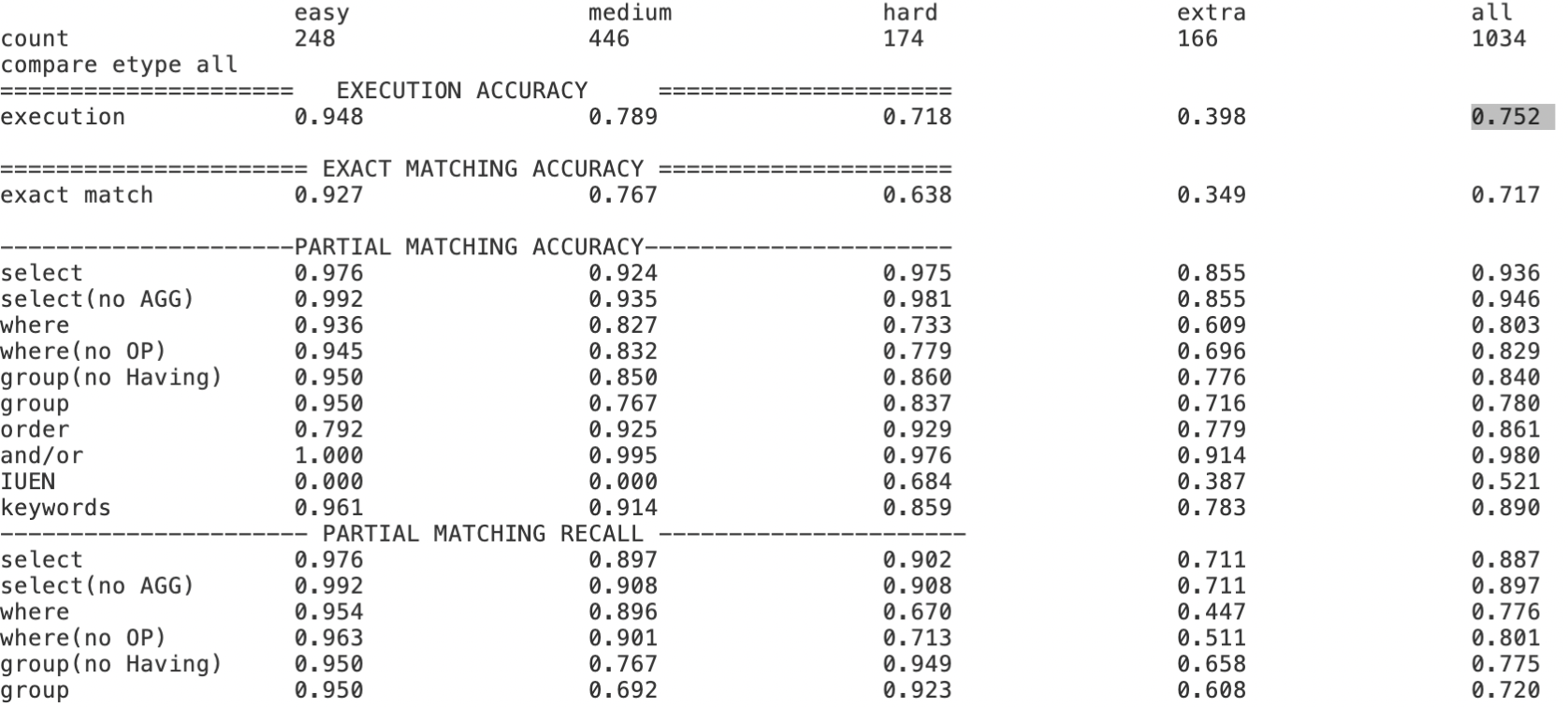
Text-to-SQL小白入门(十)RLHF在Text2SQL领域的探索实践
本文内容主要基于以下开源项目探索实践, Awesome-Text2SQL:GitHub - eosphoros-ai/Awesome-Text2SQL: Curated tutorials and resources for Large Language Models, Text2SQL, Text2DSL、Text2API、Text2Vis and more.DB-GPT-Hub:GitHub - eosphoros-ai…...
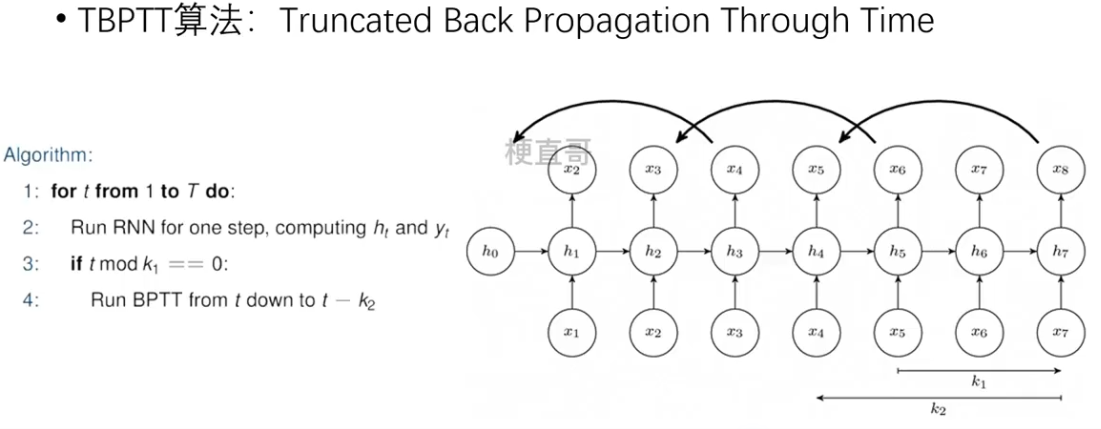
深度学习 | 基本循环神经网络
1、序列建模 1.1、序列数据 序列数据 —— 时间 不同时间上收集到的数据,描述现象随时间变化的情况。 序列数据 —— 文本 由一串有序的文本组成的序列,需要进行分词。 序列数据 —— 图像 有序图像组成的序列,后一帧图像可能会受前一帧的影响…...

VSCode 加Cortex-Debug嵌入式调试方法
简介 当使用ARM Cortex-M微控制器时,Cortex-Debug是一个Visual Studio Code的扩展,以简化调试过程。本文档介绍了如何编写启动配置(launch.json)。 settings.json配置 打开VSCode用户设置文件settings.json: 文件→偏好→设置选择用户设置: 在搜索栏中…...
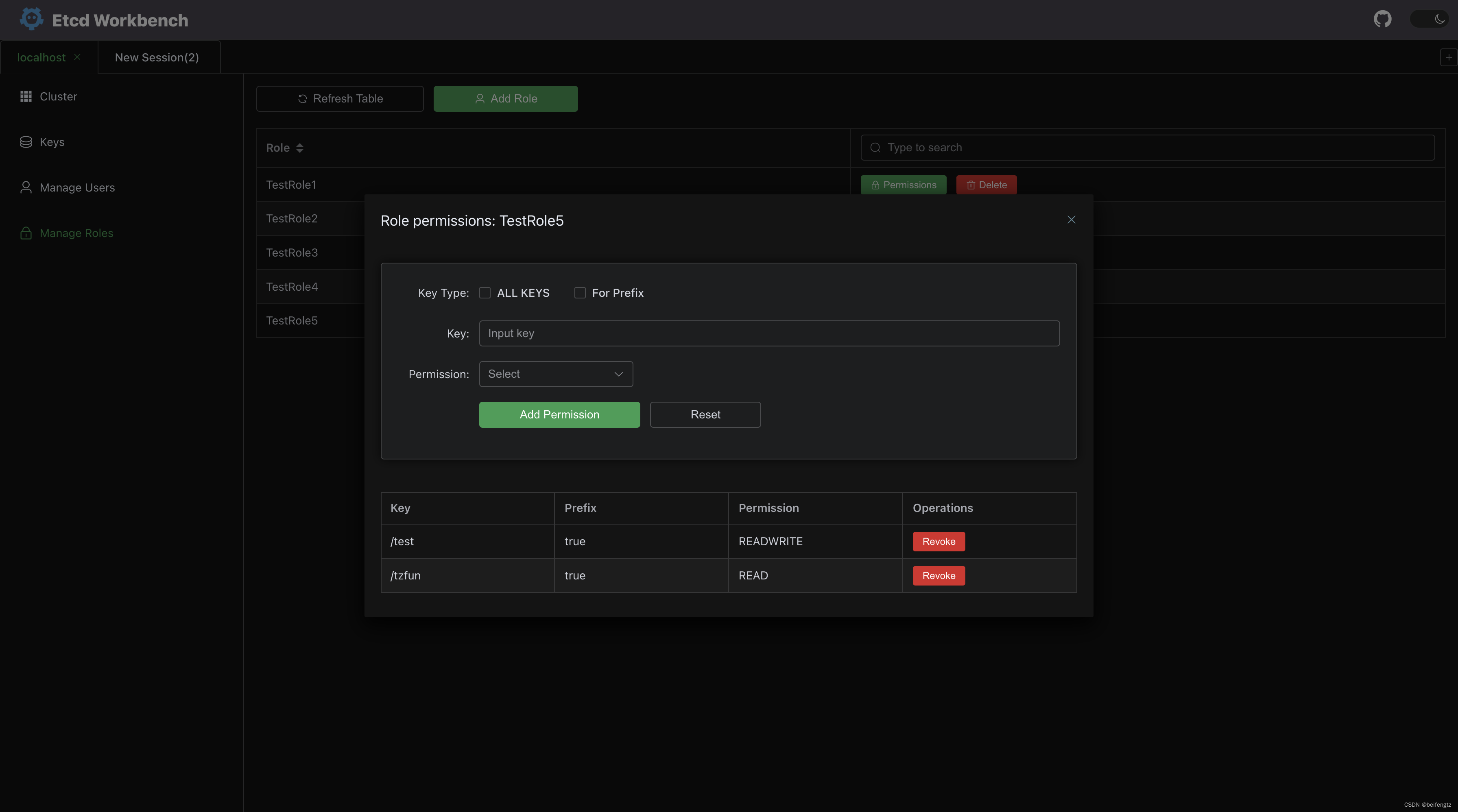
etcd-workbench一款免费好用的ETCD客户端,支持SSHTunnel、版本对比等功能
介绍 今天推荐一款完全免费的ETCD客户端,可以私有化部署: etcd-workbench 开源地址:https://github.com/tzfun/etcd-workbench Gitee地址:https://gitee.com/tzfun/etcd-workbench 下载 本地运行 从 官方Release 下载最新版的 jar 包&am…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

Neo4j 集群管理:原理、技术与最佳实践深度解析
Neo4j 的集群技术是其企业级高可用性、可扩展性和容错能力的核心。通过深入分析官方文档,本文将系统阐述其集群管理的核心原理、关键技术、实用技巧和行业最佳实践。 Neo4j 的 Causal Clustering 架构提供了一个强大而灵活的基石,用于构建高可用、可扩展且一致的图数据库服务…...

反射获取方法和属性
Java反射获取方法 在Java中,反射(Reflection)是一种强大的机制,允许程序在运行时访问和操作类的内部属性和方法。通过反射,可以动态地创建对象、调用方法、改变属性值,这在很多Java框架中如Spring和Hiberna…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...