模型量化 | Pytorch的模型量化基础
官方网站:Quantization — PyTorch 2.1 documentation
Practical Quantization in PyTorch | PyTorch
量化简介
量化是指执行计算和存储的技术 位宽低于浮点精度的张量。量化模型 在张量上执行部分或全部操作,精度降低,而不是 全精度(浮点)值。这允许更紧凑的模型表示和 在许多硬件平台上使用高性能矢量化操作。 与典型的 FP32 模型相比,PyTorch 支持 INT8 量化,
- 模型大小减少 4 倍
- 内存带宽减少 4 倍
- INT8 计算的硬件支持通常为 2 到 4 个 与 FP32 计算相比,速度快几倍
量化主要是一种技术 加速推理,量化仅支持前向传递 运营商。
PyTorch 支持多种量化深度学习模型的方法。在 大多数情况下,模型在 FP32 中训练,然后将模型转换为 INT8 中。此外,PyTorch 还支持量化感知训练,这 使用以下方法对前向和后向传递中的量化误差进行建模 假量化模块。请注意,整个计算是在 浮点。在量化感知训练结束时,PyTorch 提供 转换函数,用于将训练好的模型转换为较低精度的模型。
在较低级别,PyTorch 提供了一种表示量化张量和 使用它们执行操作。它们可用于直接构建模型 以较低的精度执行全部或部分计算。更高级别 提供了包含转换 FP32 模型的典型工作流的 API 以最小的精度损失降低精度。
pytorch从1.3 版开始,提供了量化功能,PyTorch 1.4 发布后,在 PyTorch torchvision 0.5 库中发布了 ResNet、ResNext、MobileNetV2、GoogleNet、InceptionV3 和 ShuffleNetV2 的量化模型。
PyTorch 量化 API 摘要
PyTorch 提供了两种不同的量化模式:Eager Mode Quantization 和 FX Graph Mode Quantization。
Eager Mode Quantization 是一项测试版功能。用户需要进行融合并指定手动进行量化和反量化的位置,而且它只支持模块而不是功能。
FX Graph Mode Quantization 是 PyTorch 中一个新的自动化量化框架,目前它是一个原型功能。它通过添加对函数的支持和自动化量化过程来改进 Eager Mode Quantization,尽管人们可能需要重构模型以使模型与 FX Graph Mode Quantization 兼容(符号上可追溯到 )。请注意,FX Graph Mode Quantization 预计不适用于任意模型,因为该模型可能无法符号跟踪,我们将它集成到 torchvision 等域库中,用户将能够量化类似于 FX Graph Mode Quantization 支持的域库中的模型。对于任意模型,我们将提供一般准则,但要真正使其工作,用户可能需要熟悉,尤其是如何使模型具有符号可追溯性。torch.fxtorch.fx
PyTorch量化结构
- PyTorch 具有与量化张量对应的数据类型,这些张量具有许多张量的特征。
- 人们可以编写具有量化张量的内核,就像浮点张量的内核一样,以自定义其实现。PyTorch 支持将常见操作的量化模块作为 和 name-space 的一部分。
torch.nn.quantizedtorch.nn.quantized.dynamic - 量化与 PyTorch 的其余部分兼容:量化模型是可跟踪和可编写脚本的。服务器和移动后端的量化方法几乎相同。可以轻松地在模型中混合量化和浮点运算。
- 浮点张量到量化张量的映射可以使用用户定义的观察者/假量化模块进行自定义。PyTorch 提供了适用于大多数用例的默认实现。
【量化张量,量化模型 ,工具上的量化】
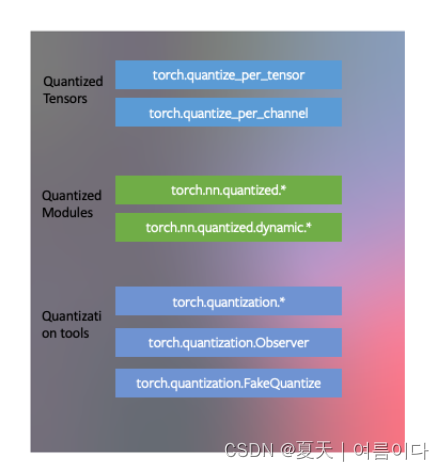
PYTORCH的三种量化模式
🫧动态量化 Dynamic qunatization:使权重为整数(训练后)
🤖训练后静态量化 Static quantization:使权值和激活值为整数(训练后)
量化感知训练 Quantization aware training:以整数精度对模型进行训练
🫧动态量化
PyTorch 支持的最简单的量化方法称为动态量化。这不仅涉及将权重转换为 int8(就像所有量化变体一样),还涉及在进行计算之前将激活转换为 int8(因此是“动态”的)。因此,计算将使用高效的 int8 矩阵乘法和卷积实现来执行,从而加快计算速度。但是,激活以浮点格式读取和写入内存。
🤖训练后静态量化
可以通过将网络转换为同时使用整数算术和 int8 内存访问来进一步提高性能(延迟)。静态量化执行额外的步骤,即首先通过网络提供批量数据并计算不同激活的结果分布(具体来说,这是通过在记录这些分布的不同点插入“观察者”模块来完成的)。此信息用于确定在推理时应如何具体量化不同的激活
量化感知训练
量化感知训练 (QAT) 是第三种方法,也是这三种方法中通常最准确的一种方法。使用 QAT,在训练的前向和后向传递期间,所有权重和激活都是“假量化”的:也就是说,浮点值被舍入以模仿 int8 值,但所有计算仍然使用浮点数完成。因此,训练期间的所有权重调整都是在“意识到”模型最终将被量化的事实的情况下进行的;因此,在量化后,该方法通常比其他两种方法产生更高的准确度。
官网中提供的一些建议,不同的网络选择不同的量化模式:
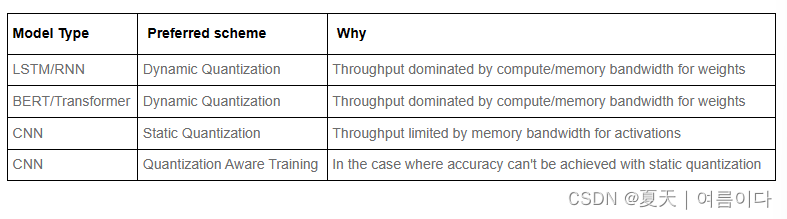 结果显示在性能和精度上都有提高
结果显示在性能和精度上都有提高
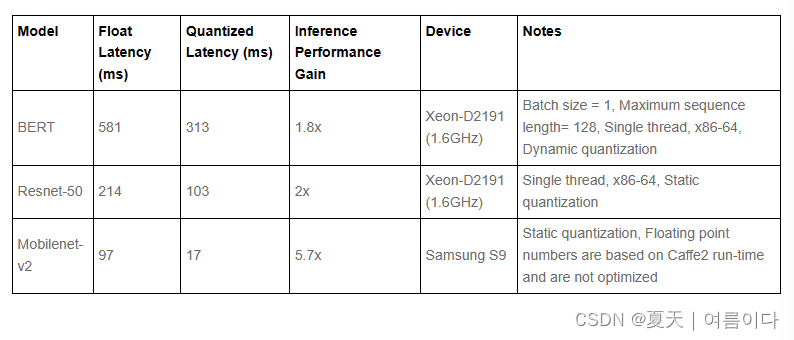
计算机视觉模型精度
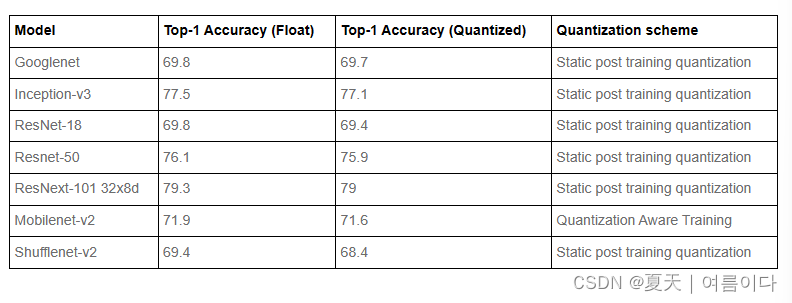
语音和自然语言处理精度

量化实例
目前torchvision【2】中提供的7个量化模型如图(截止20231227)
实例1:量化resnet18网络
(beta) Quantized Transfer Learning for Computer Vision Tutorial — PyTorch Tutorials 2.2.0+cu121 documentation
实例2:量化MobileNet v2 网络
양자화 레시피 — 파이토치 한국어 튜토리얼 (PyTorch tutorials in Korean)
Q&A
【Q&A1】模型量化,剪枝的区别是什么?
模型量化和剪枝是两种不同的技术,用于减小神经网络模型的大小、加速推理过程并降低模型的计算复杂度。它们的主要区别在于优化模型的方式和目标。
模型量化(Quantization):
- 定义:模型量化是通过减少模型中参数的表示精度来实现模型压缩的过程。通常,神经网络模型中的参数是使用浮点数表示的,而量化则将这些参数表示为更少比特的定点数或整数,从而减小了内存占用和计算成本。
- 目标:减小模型的存储空间和加速推理过程。通过使用较少位数的表示来存储权重和激活值,模型的存储需求减少,且在硬件上执行推理时,可以更快地进行计算。
剪枝(Pruning):
- 定义:剪枝是一种技术,通过减少神经网络中的连接或参数来减小模型的大小。在剪枝过程中,通过将权重较小或对模型贡献较小的连接移除或设为零,从而减少模型的复杂度。
- 目标:减小模型的尺寸和计算负载。剪枝不仅可以减少模型的存储需求,还可以在推理时减少乘法操作,因为移除了部分连接或参数,从而提高推理速度。
虽然两者都致力于减小模型的大小和计算复杂度,但方法和实现方式略有不同。模型量化侧重于减小参数表示的精度,而剪枝则专注于减少模型的连接或参数数量。通常,这两种技术可以结合使用,以更大程度地减小神经网络模型的尺寸和提高推理效率。
【Q&A2】减小模型的大小的方法有什么?
深度压缩(Deep Compression):
- 这是一种综合性的方法,包括剪枝、权重共享和 Huffman 编码等步骤。它不仅剪枝模型中的连接,还可以通过权重共享和 Huffman 编码来进一步减小模型的大小。这种方法通常能够在保持模型性能的同时大幅减小模型大小。
知识蒸馏(Knowledge Distillation):
- 这是一种将大型模型中的信息转移到小型模型的技术。通过训练一个较小的模型去模仿大型模型的行为,以捕捉大型模型的复杂性和性能。这样可以在不损失太多性能的情况下使用更小的模型。
低秩近似(Low-Rank Approximation):
- 通过矩阵分解等方法将模型中的权重矩阵近似为低秩矩阵,从而减少模型参数数量。这种方法可以有效地减小模型的尺寸,但有时会对模型性能产生一定影响。
网络架构优化:
- 重新设计模型架构以减少参数数量和计算量。可以通过精心设计模型结构,如使用轻量级网络、深度可分离卷积等技术,来降低模型的复杂度。
权重量化和编码:
- 类似于模型量化,可以对权重进行更复杂的编码或量化方式,以更有效地表示权重并减少模型大小。
这些方法可以单独使用,也可以组合使用,根据具体的情况和需求来选择合适的技术来减小模型的大小。常常需要在压缩模型尺寸和保持模型性能之间找到平衡。
参考文献
【1】Introduction to Quantization on PyTorch | PyTorch
【2】vision/torchvision/models/quantization at main · pytorch/vision (github.com)
【3】量化自定义PyTorch模型入门教程 - 知乎 (zhihu.com)
【4】 深度学习知识六:(模型量化压缩)----pytorch自定义Module,并通过其理解DoReFaNet网络定义方法。_pytorch dorefa save_for_backward-CSDN博客
【5】端到端Transformer模型的混合精度后量化_量化 端到端-CSDN博客
【6】transformers 保存量化模型并加载_from transformers import autotokenizer, automodel-CSDN博客 【7】使用 Transformers 量化 Meta AI LLaMA2 中文版大模型 - 苏洋博客 (soulteary.com)
【8】Model Compression - 'Quantization' | LeijieZhang (leijiezhang001.github.io)
相关文章:
模型量化 | Pytorch的模型量化基础
官方网站:Quantization — PyTorch 2.1 documentation Practical Quantization in PyTorch | PyTorch 量化简介 量化是指执行计算和存储的技术 位宽低于浮点精度的张量。量化模型 在张量上执行部分或全部操作,精度降低,而不是 全精度…...

adb和logcat常用命令
adb的作用 adb构成 client端,在电脑上,负责发送adb命令daemon守护进程adbd,在手机上,负责接收和执行adb命令server端,在电脑上,负责管理client和daemon之间的通信 adb工作原理 client端将命令发送给ser…...
千巡翼X4轻型无人机 赋能智慧矿山
千巡翼X4轻型无人机 赋能智慧矿山 传统的矿山测绘需要大量测绘员通过采用手持RTK、全站仪对被测区域进行外业工作,再通过方格网法、三角网法、断面法等进行计算,需要耗费大量人力和时间。随着无人机航测技术的不断发展,利用无人机作业可以大…...
:编译服务器的配置、AOSP源码的下载、编译、运行)
【Android 13】使用Android Studio调试系统应用之Settings移植(一):编译服务器的配置、AOSP源码的下载、编译、运行
文章目录 1. 篇头语2. 系列文章3. ubuntu 最佳版本3.1 下载并安装3.2 配置AOSP工具链3.3 配置Python多版本支持4. AOSP源码下载4.1 配置repo工具4.2 源码下载5. AOSP编译5.1 添加emulator模拟器配置5.1.1 哪些是支持模拟器的Products?5.1.2 添加方法5.2 编译...

【1】Docker详解与部署微服务实战
Docker 详解 Docker 简介 Docker 是一个开源的容器化平台,可以帮助开发者将应用程序和其依赖的环境打包成一个可移植、可部署的容器。Docker 的主要目标是通过容器化技术实现应用程序的快速部署、可移植性和可扩展性,从而简化应用程序的开发、测试和部…...

C# JsonString转Object以及Object转JsonString
主要讲述了两种方法的转换,最后提供了格式化输出JsonString字符串。 需要引用程序集 System.Web.Extensions.dll、Newtonsoft.Json.dll System.Web.Extensions.dll可直接在程序集中引用,Newtonsoft.Json.dll需要在NuGet中下载引用。 详细代码…...
)
华为OD机试真题-中文分词模拟器-2023年OD统一考试(C卷)
题目描述: 给定一个连续不包含空格字符串,该字符串仅包含英文小写字母及英文文标点符号(逗号、分号、句号),同时给定词库,对该字符串进行精确分词。 说明: 1.精确分词: 字符串分词后,不会出现重叠。即“ilovechina” ,不同词库可分割为 “i,love,china” “ilove,c…...

【并发设计模式】聊聊 基于Copy-on-Write模式下的CopyOnWriteArrayList
在并发编程领域,其实除了使用上一篇中的属性不可变。还有一种方式那就是针对读多写少的场景下。我们可以读不加锁,只针对于写操作进行加锁。本质上就是读写复制。读的直接读取,写的使用写一份数据的拷贝数据,然后进行写入。在将新…...

OpenCV中使用Mask R-CNN实现图像分割的原理与技术实现方案
本文详细介绍了在OpenCV中利用Mask R-CNN实现图像分割的原理和技术实现方案。Mask R-CNN是一种先进的深度学习模型,通过结合区域提议网络(Region Proposal Network)和全卷积网络(Fully Convolutional Network)…...

论文阅读《Rethinking Efficient Lane Detection via Curve Modeling》
目录 Abstract 1. Introduction 2. Related Work 3. BezierLaneNet 3.1. Overview 3.2. Feature Flip Fusion 3.3. End-to-end Fit of a Bezier Curve 4. Experiments 4.1. Datasets 4.2. Evalutaion Metics 4.3. Implementation Details 4.4. Comparisons 4.5. A…...
Leetcode—2660.保龄球游戏的获胜者【简单】
2023每日刷题(七十二) Leetcode—2660.保龄球游戏的获胜者 实现代码 class Solution { public:int isWinner(vector<int>& player1, vector<int>& player2) {long long sum1 0, sum2 0;int n player1.size();for(int i 0; i &…...

ubuntu服务器上安装KVM虚拟化
今天想着在ubuntu上来安装一个windwos操作系统,原因是因为我们楼上有几台不错的服务器,但是都是linux系统的。 今天我想着要给同事们搭建一个chatgpt环境,用来开发程序,但是ubuntu上其实也可以安装我嫌麻烦,刚好想折腾…...
SpreadJS 集成使用案例
SpreadJS 集成案例 介绍: SpreadJS 基于 HTML5 标准,支持跨平台开发和集成,支持所有主流浏览器,无需预装任何插件或第三方组件,以原生的方式嵌入各类应用,可以与各类后端技术框架相结合。SpreadJS 以 纯前…...
SQL题:534. 游戏玩法分析 III(难度:中等))
单挑力扣(LeetCode)SQL题:534. 游戏玩法分析 III(难度:中等)
题目:534. 游戏玩法分析 III (通过次数23,825 | 提交次数34,947,通过率68.17%) Table:Activity----------------------- | Column Name | Type | ----------------------- | player_id | int | | device_id | int…...

【OpenCV】告别人工目检:深度学习技术引领工业品缺陷检测新时代
目录 前言 机器视觉 缺陷检测 工业上常见缺陷检测方法 内容简介 作者简介 目录 读者对象 如何阅读本书 获取方式 前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。 点击跳转到网站 机器视觉…...

VR全景图片制作时有哪些技巧,VR全景图片能带来哪些好处
引言: VR全景图片是通过虚拟现实技术制作出的具有沉浸感的图片,能够提供给用户一种身临其境的感觉。在宣传方面,它有着独特的优势和潜力,能够帮助吸引更多的潜在客户,那么VR全景图片制作时有哪些技巧,VR全…...

【VUE】Flask+vue-element-admin前后端分离项目发布到linux服务器操作指南
目录 一、Flask后端发布环境搭建1.1 python环境第一步:安装python环境第二步:配置python虚拟环境 1.2 uwsgi环境1.3 nginx配置1.4 测试 二、VUE前端发布环境搭建2.1 配置修改2.2 打包上传服务器2.3 nginx配置2.3 测试 三、联合调试 一、Flask后端发布环境…...

django的gunicorn的异步任务执行
gunicorn 本身是一个WSGI HTTP服务器,用于运行Python的web应用,如Django项目。它并不直接提供执行异步任务的功能。异步任务通常是指那些你想要在web请求之外执行的后台任务,如发送电子邮件、处理长时间运行的计算或与外部API交互等。 在Dja…...

KEPServerEX 6 之【外篇-2】PTC-ThingWorx服务端软件安装 PostgreSQL本地安装
---------------------------安装相关信息--------------- 默认用户角色 : Postgres 密码:root@123 localhost 用户角色 :postgres_tw 密码 root@123 端口 5432 ------------------------------------------------------------------ 1. WIN 安装 Postgre…...

websocket 介绍
目录 1,前端如何实现即时通讯短轮询长轮询 2,websocket2.1,握手2.2,握手过程举例2.3,socket.io 3,websocket 对比 http 的优势 1,前端如何实现即时通讯 在 websocket 协议出现之前,…...

IDEA运行Tomcat出现乱码问题解决汇总
最近正值期末周,有很多同学在写期末Java web作业时,运行tomcat出现乱码问题,经过多次解决与研究,我做了如下整理: 原因: IDEA本身编码与tomcat的编码与Windows编码不同导致,Windows 系统控制台…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

C++ 设计模式 《小明的奶茶加料风波》
👨🎓 模式名称:装饰器模式(Decorator Pattern) 👦 小明最近上线了校园奶茶配送功能,业务火爆,大家都在加料: 有的同学要加波霸 🟤,有的要加椰果…...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...

Scrapy-Redis分布式爬虫架构的可扩展性与容错性增强:基于微服务与容器化的解决方案
在大数据时代,海量数据的采集与处理成为企业和研究机构获取信息的关键环节。Scrapy-Redis作为一种经典的分布式爬虫架构,在处理大规模数据抓取任务时展现出强大的能力。然而,随着业务规模的不断扩大和数据抓取需求的日益复杂,传统…...

wpf在image控件上快速显示内存图像
wpf在image控件上快速显示内存图像https://www.cnblogs.com/haodafeng/p/10431387.html 如果你在寻找能够快速在image控件刷新大图像(比如分辨率3000*3000的图像)的办法,尤其是想把内存中的裸数据(只有图像的数据,不包…...

Chrome 浏览器前端与客户端双向通信实战
Chrome 前端(即页面 JS / Web UI)与客户端(C 后端)的交互机制,是 Chromium 架构中非常核心的一环。下面我将按常见场景,从通道、流程、技术栈几个角度做一套完整的分析,特别适合你这种在分析和改…...
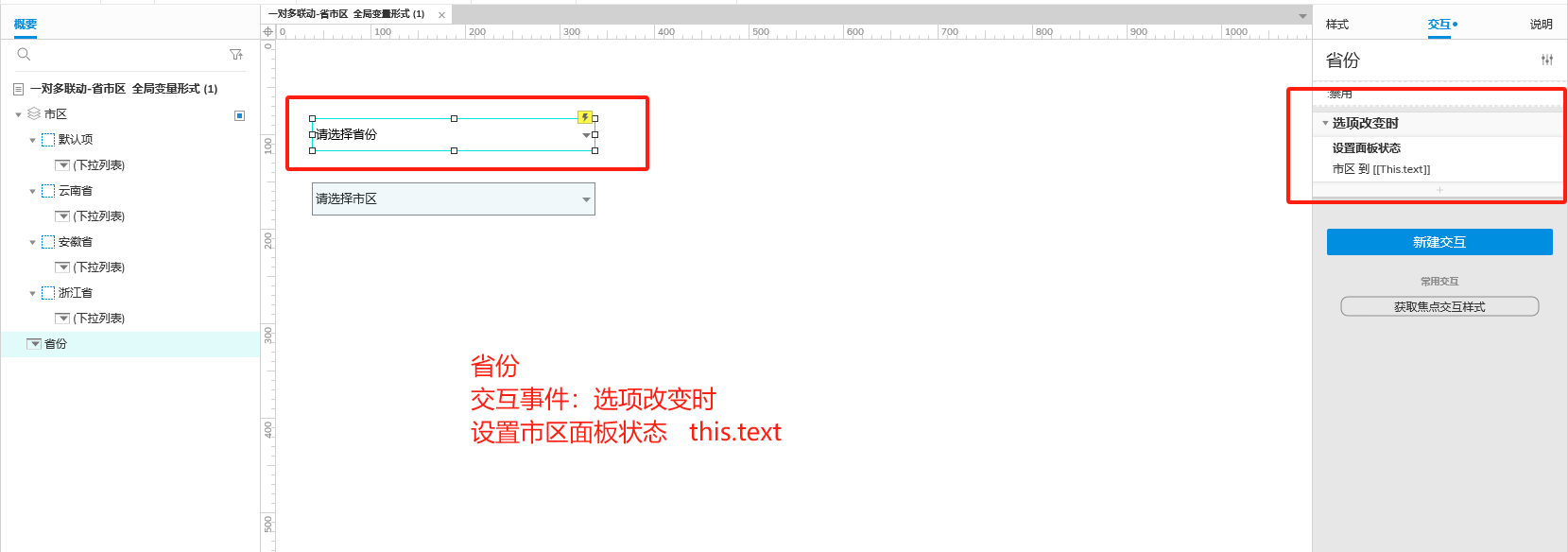
Axure 下拉框联动
实现选省、选完省之后选对应省份下的市区...