Mysql Nested-Loop Join算法和MRR
MySQL8之前仅支持一种join 算法—— nested loop,在 MySQL8 中推出了一种新的算法 hash join,比 nested loop 更加高效。(后面有时间介绍这种join算法)
1、mysql驱动表与被驱动表及join优化
先了解在join连接时哪个表是驱动表(也叫外表),哪个表是被驱动表(也叫内内表):
- 当使用left join时,左表是驱动表,右表是被驱动表
- 当使用right join时,右表时驱动表,左表是驱动表
- 当使用join时,mysql优化器会选择数据量比较小的表作为驱动表,大表作为被驱动表
1.1)join查询如何选择驱动表与被驱动表
在sql优化中,永远是以小表驱动大表。例如: A是小表,B是大表,使用left join 时,则应该这样写:
select * from A a left join B b on a.code=b.code这样A表时驱动表,B表是被驱动表。
1)驱动表的含义:
在嵌套循环连接和哈希连接中,用来最先获得数据,并以此表的数据为依据,逐步获得其他表的数据,直至最终查询到所有满足条件的数据的第一个表,叫做驱动表。
驱动表不一定是表,有可能是数据集,即由某个表中满足条件的数据行,组成子集合后,再以此子集合作为连接其他表的数据来源。这个子集合,才是真正的驱动表,有时候为了简洁,直接将最先按照条件或得子集合的那张表叫做驱动表。
如果有三个及以上的表,则会先使用join算法得到一、二个表的结果集,并将该结果集作为外层数据,遍历结果集到后第三个表中查询数据。
2)小表作为驱动表:
我们常说,驱动表一定是小表,指的是根据条件获得的子集合一定要小,而不是说实体表本身一定要小,大表如果获得的子集合小,一样可以简称这个大表为驱动表。因为:
小表驱动大表:需要通过140多次的扫描
for(140条){for(20万条){}
}
大表驱动小表:要通过20万次的扫描
for(20万条){for(140条){}
}所以也可以得出结论:如果A表,B表数据量差不多大的时候,那么选择谁作为驱动表也是无所谓了。
看一个例子:A表140多条数据,B表20万左右的数据量
select * from A a left join B b on a.code=b.code
执行时间:7.5sselect * from B b left join A a on a.code=b.code
执行时间:19s3)通过explain查看谁是驱动表:
可以通过EXPLAIN分析来判断在sql中谁是驱动表,EXPLAIN语句分析出来的第一行的表即是驱动表。
1.2)驱动表和被驱动表索引是用情况:
join查询在有索引条件下:
- 驱动表有索引不会使用到索引
- 被驱动表建立索引会使用到索引
在以小表驱动大表的情况下,再给大表建立索引会大大提高执行速度。
测试1:给A表,B表建立索引
分析:EXPLAIN select * from A a left join B b on a.code=b.code
只有B表code使用到索引
测试2:如果只给A表的code建立索引会是什么情况?
在这种情况下,A表索引失效。
结论:
- 以小表驱动大表
- 给被驱动表建立索引
2、Nested-Loop Join
MySQL8.0之前只支持一种JOIN算法Nested-Loop Join(嵌套循环链接),Nested-Loop Join是有很多变种,能够帮助MySQL更高效的执行JOIN操作。
2.1)Simple Nested-Loop Join(简单的嵌套循环连接)
简单来说嵌套循环连接算法就是一个双层for 循环 ,通过循环外层表的行数据,逐个与内层表的所有行数据进行比较来获取结果,伪代码如下:
select * from user tb1 left join level tb2 on tb1.id=tb2.user_idfor (user_table_row ur : user_table) {for (level_table_row lr : level_table) {if (ur.id == lr.user_id)) {//返回匹配成功的数据}}
}特点:
Nested-Loop Join 简单粗暴容易理解,就是通过双层循环比较数据来获得结果,但是这种算法显然太过于粗鲁,如果每个表有1万条数据,那么对数据比较的次数=1万 * 1万 =1亿次,很显然这种查询效率会非常慢。
当然mysql 肯定不会这么粗暴的去进行表的连接,所以就出现了后面的两种对Nested-Loop Join 优化算法,在执行join 查询时mysql 会根据情况选择 后面的两种优join优化算法的一种进行join查询。
2.2)Index Nested-Loop Join(索引嵌套循环连接)
Index Nested-Loop Join其优化的思路 主要是为了减少内层表数据的匹配次数, 简单来说Index Nested-Loop Join 就是通过外层表匹配条件 直接与内层表索引进行匹配,避免和内层表的每条记录去进行比较, 这样极大的减少了对内层表的匹配次数,从原来的匹配次数=外层表行数 * 内层表行数,变成了 外层表的行数 * 内层表索引的高度,极大的提升了 join的性能。
select * from user tb1 left join level tb2 on tb1.id=tb2.user_id
# 伪代码
for (user_table_row ur : user_table) {lookup level_user_id_index {if (ur.id == lr.user_id)) {//返回匹配成功的数据}}
}注意:使用Index Nested-Loop Join 算法的前提是匹配的字段,在被驱动表(内表)上必须建立了索引。
2.3)Batched Key Access join(简称BKA)
在上面描述的INLJ算法中有一个问题,如果和被驱动表关联的索引是辅助索引,并且查询字段无法做到索引覆盖,那么在组装数据的时候就需要回表操作。而如果匹配每条记录都去回表,效率肯定不高,虽然回表能够使用到主键索引,但是因为这里id不一定有序,所以也属于随机分散读取。对于这种情况,MySQL提供了一种优化措施,提供了一种叫做Batched Key Access join的算法,即批量主键访问连接算法。
1)BKA算法:
BKA算法的原理是,先在驱动表中根据条件查询出符合条件的记录存入join buffer中,然后根据索引获取被驱动表的索引记录,将其存入read_rnd_buffer中。如果join buffer或read_rnd_buffer有一个满了,那么就先处理buffer中的数据:将read_rnd_buffer中的被驱动表索引记录按照主键进行升序排序,然后依赖这个有序的记录去回表查询,由于主键索引中的记录是按照主键升序排序的,这样能提高回表效率。要启用BKA算法,需要开启batched_key_access。
说明:可以先了解MRR后再看BKA就会很清晰(下面)。默认BKA是关闭的,若要开启需要执行。
mysql> SET optimizer_switch='mrr=on,mrr_cost_based=on,batched_key_access=on';这里测试一下:
set optimizer_switch='batched_key_access=off';
explain select a.*,b.* from b join a on b.key = a.key
这里没有开启batched_key_access,可以看到,a是驱动表,b.key字段上有索引,查询字段使用的是a.*,b.*,所需数据需要回表,但是还是使用的是INLJ算法,现在开启batched_key_access试试:
set optimizer_switch='batched_key_access=on';
explain select a.*,b.* from b join a on b.key = a.key 可以看到这次使用了BKA算法,使用到了join buffer,那么如果我们查询字段不选择b.*,只返回b.id字段,这样能用到覆盖索引:
可以看到这次使用了BKA算法,使用到了join buffer,那么如果我们查询字段不选择b.*,只返回b.id字段,这样能用到覆盖索引:
set optimizer_switch='batched_key_access=on';
explain select a.*,b.id from b join a on b.key = a.key  发现没有再使用BKA算法了。
发现没有再使用BKA算法了。
2.4)Block Nested-Loop Join(缓存块嵌套循环连接,简称BNL)
如果被驱动表关联字段没有可用的索引,那么就要使用BNL算法了,这个算法和BKA算法一样需要用到join buffer,但是没有使用read_rnd_buffer。到底选择BNL还是BKA,关键点在于被驱动表是否有可用的索引,如果没有则直接使用BNL,如果有索引,但是需要回表则使用BKA。
1)BNL 算法:
先根据条件查出驱动表中符合条件的记录,存入join buffer中,如果join buffer只能存100条数据,但是驱动表符合条件的就结果集超过100条,那么也只能取到100条,称为一个批次(batch),然后全表扫描被驱动表,将被驱动表的每行记录都和join buffer中的记录进行匹配,将匹配到的记录放到最终结果集中。被驱动表扫描完之后,清空join buffer,再次重复从驱动表中获取剩余记录存入join buffer,然后全表扫描被驱动表,到join buffer中进行匹配,依次循环直到数据匹配完毕。
说明:在 MySQL 8.0.18之前,当join时无法使用被驱动表的索引时,就会是用BNL进行join。在MySQL 8.0.18 及更高版本中,在这种情况下采用了 Hash 连接优化算法。从 MySQL 8.0.20 开始,MySQL 不再使用 BNL 算法,并且在以前使用过 BNL 的所有情况下都使用 Hash Join 算法。
# SQL
select * from R join S on R.r=S.s
# 伪代码
for each tuple r in R do # 扫描外表Rstore used columns as p from R in join buffer # 将部分或者全部R记录保存到join buffer中,记为pfor each tuple s in S do # 扫描内表Sif p and s satisfy the join buffer # p与s满足join条件then output the tuple <p,s> # 返回结果集处理流程:
- 遍历满足过滤条件的驱动表中所有的记录(SQL 查询的所有字段),并放入至 join buffer
- 若所有驱动表满足条件记录放入 join buffer,遍历被驱动表所有记录,获取满足join 条件的记录结果集
- 若join buffer 无法一次性存储全部驱动表记录,可分批读取记录至join buffer, 重复第二步骤
注意:5.6版本及以后,优化器管理参数optimizer_switch中中的block_nested_loop参数控制着BNL是否被用于优化器。默认条件下是开启,若果设置为off,优化器在选择 join方式的时候会选择NLJ算法。
mysql> show variables like 'optimizer_switch'\G;
block_nested_loop=on # BNL优化,默认打开mysql> set optimizer_switch='block_nested_loop=on'; # 开启BNL2)BNL介绍:
BNL 主要针对被驱动表关联字段无索引时的优化,(当被驱动表没有索引或索引失效时,无法是用INLJ,mysql就会通过BNL进行优化)如果在EXPLAIN输出中,当Extra值包含Using join buffer(Block Nested Loop)且type值为ALL,index或range时,表示使用BNL;也说明被驱动表的表关联字段缺少索引或索引失效无法有效利用索引。
BNL 算法是对 SNLJ 算法的优化,并且可将该算法 BNL 提升至 INLJ 进行优化。 对 SQL 的扫描数据来讲,驱动表扫描次数为1 ,被驱动表扫描次数为 驱动表记录大小/ join_buffer_size ; 对于 SQL 的扫描记录来讲, SQL 执行扫描行数 = 驱动表记录数 + (驱动表记录 / join_buffer_size) * 被驱动表记录数。
在一定程度上,提高 join_buffer_size 的大小是可以提高使用 BNL 算法 SQL的执行效率:
# 手动调整 join_buffer_size 的大小
mysql> show variables like '%join_buffer_size%';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| join_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.04 sec)mysql> set join_buffer_size=1024;
Query OK, 0 rows affected (0.04 sec)mysql> show variables like '%join_buffer_size%';
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| join_buffer_size | 1024 |
+------------------+-------+
1 row in set (0.03 sec)3)BNL特点:
- join_buffer_size变量决定buffer大小。
- 只有在join类型为all, index, range的时候才可以使用join buffer。
- 能够被buffer的每一个join都会分配一个buffer, 也就是说一个query最终可能会使用多个join buffer。
- 第一个nonconst table不会分配join buffer, 即便其扫描类型是all或者index。
- 在join之前就会分配join buffer, 在query执行完毕即释放。
- join buffer中只会保存参与join的列, 并非整个数据行。
3、MRR
MRR,全称「Multi-Range Read Optimization」,是MySQL 5.6的新特性,简单说:MRR 通过把「随机磁盘读」,转化为「顺序磁盘读」,从而提高了索引查询的性能。
3.1)mysql是如何从磁盘上读取数据的?
执行一个范围查询:
mysql > explain select * from stu where age between 10 and 20;
+----+-------------+-------+-------+------+---------+------+------+-----------------------+
| id | select_type | table | type | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+----------------+------+------+-----------------------+
| 1 | SIMPLE | stu | range | age | 5 | NULL | 960 | Using index condition |
+----+-------------+-------+-------+----------------+------+------+-----------------------+当这个 sql 被执行时,MySQL 会按照下图的方式,去磁盘读取数据(假设数据不在数据缓冲池里):
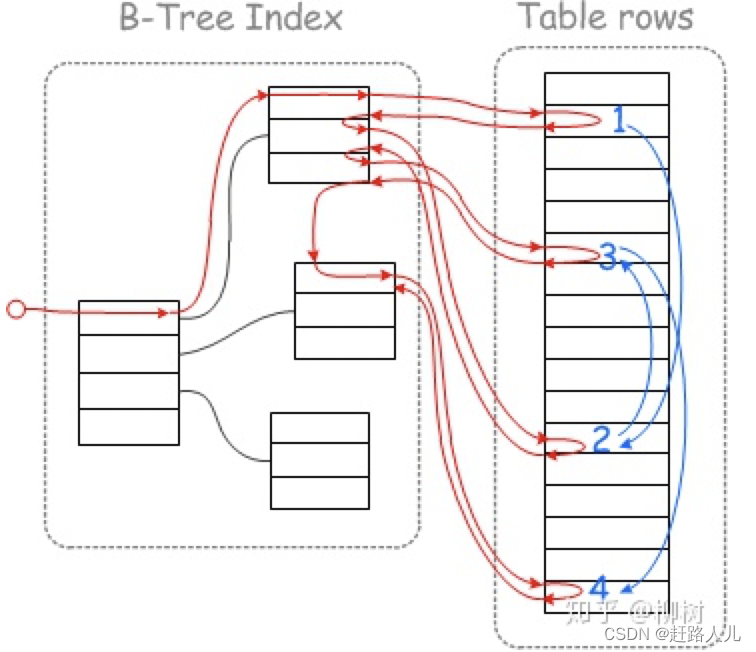
图中红色线就是整个的查询过程,蓝色线则是磁盘的运动路线。
这张图是按照 Myisam 的索引结构画的,不过对于 Innodb 也同样适用。对于 Myisam,左边就是字段 age 的二级索引,右边是存储完整行数据的地方。对于 Innodb也是一样的,Innodb 是聚簇索引(cluster index),所以只需要把右边也换成一颗叶子节点带有完整数据的 B+ tree 就可以了。
下面一Myisam引擎分析:
- 先到左边的二级索引找,找到第一条符合条件的记录(实际上每个节点是一个页,一个页可以有很多条记录,这里我们假设每个页只有一条),接着到右边去读取这条数据的完整记录。
- 读取完后,回到左边,继续找下一条符合条件的记录,找到后,再到右边读取,这时发现这条数据跟上一条数据,在物理存储位置上,离的贼远!
- 咋办,没办法,只能让磁盘和磁头一起做机械运动,去给你读取这条数据。第三条、第四条,都是一样,每次读取数据,磁盘和磁头都得跑好远一段路。
说明:MySQL 其实是以「页」为单位读取数据的,这里咱们假设这几条数据都恰好位于不同的页上。另外「页」的思想其实是来源于操作系统的非连续内存管理机制,类似的还有「段」。
注意:10,000 RPM(Revolutions Per Minute,即转每分) 的机械硬盘,每秒大概可以执行 167 次磁盘读取,所以在极端情况下,MySQL 每秒只能给你返回 167 条数据,这还不算上 CPU 排队时间。
3.2)顺序读
到这里你知道了磁盘随机访问是多么奢侈的事了,所以,很明显,要把随机访问转化成顺序访问:
mysql > set optimizer_switch='mrr=on';
Query OK, 0 rows affected (0.06 sec)mysql > explain select * from stu where age between 10 and 20;
+----+-------------+-------+-------+------+---------+------+------+----------------+
| id | select_type | table | type | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+------+---------+------+------+----------------+
| 1 | SIMPLE | tbl | range | age | 5 | NULL | 960 | ...; Using MRR |
+----+-------------+-------+-------+------+---------+------+------+----------------+我们开启了 MRR,重新执行 sql 语句,发现 Extra 里多了一个「Using MRR」。
这下 MySQL 的查询过程会变成这样:
- 对于 Myisam,在去磁盘获取完整数据之前,会先按照 rowid 排好序,再去顺序的读取磁盘。
- 对于 Innodb,则会按照聚簇索引键值排好序,再顺序的读取聚簇索引。
顺序读带来了几个好处:
- 磁盘和磁头不再需要来回做机械运动;
- 可以充分利用磁盘预读:比如在客户端请求一页的数据时,可以把后面几页的数据也一起返回,放到数据缓冲池中,这样如果下次刚好需要下一页的数据,就不再需要到磁盘读取。这样做的理论依据是计算机科学中著名的局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用。
- 在一次查询中,每一页的数据只会从磁盘读取一次:MySQL 从磁盘读取页的数据后,会把数据放到数据缓冲池,下次如果还用到这个页,就不需要去磁盘读取,直接从内存读。但是如果不排序,可能你在读取了第 1 页的数据后,会去读取第2、3、4页数据,接着你又要去读取第 1 页的数据,这时你发现第 1 页的数据,已经从缓存中被剔除了,于是又得再去磁盘读取第 1 页的数据。而转化为顺序读后,你会连续的使用第 1 页的数据,这时候按照 MySQL 的缓存剔除机制,这一页的缓存是不会失效的,直到你利用完这一页的数据,由于是顺序读,在这次查询的余下过程中,你确信不会再用到这一页的数据,可以和这一页数据说告辞了。
顺序读就是通过这三个方面,最大的优化了索引的读取。别忘了,索引本身就是为了减少磁盘 IO,加快查询,而 MRR,则是把索引减少磁盘 IO 的作用,进一步放大。
3.3)关于MRR的配置
和 MRR 相关的配置有两个:
- mrr: on/off
- mrr_cost_based: on/off
1)mrr=on/off
用来打开 MRR 的开关,如果你不打开,是一定不会用到 MRR 的。
mysql > set optimizer_switch='mrr=on';
2)mrr_cost_based=on/off
用来告诉优化器,要不要基于使用 MRR 的成本,考虑使用 MRR 是否值得(cost-based choice),来决定具体的 sql 语句里要不要使用 MRR。很明显,对于只返回一行数据的查询,是没有必要 MRR 的,而如果你把 mrr_cost_based 设为 off,那优化器就会通通使用 MRR,这在有些情况下是很 stupid 的,所以建议这个配置还是设为 on,毕竟优化器在绝大多数情况下都是正确的。
3)read_rnd_buffer_size
另外还有一个配置 read_rnd_buffer_size ,是用来设置用于给 rowid 排序的内存的大小。显然,MRR 在本质上是一种用空间换时间的算法。MySQL 不可能给你无限的内存来进行排序,如果 read_rnd_buffer 满了,就会先把满了的 rowid 排好序去磁盘读取,接着清空,然后再往里面继续放 rowid,直到 read_rnd_buffer 又达到 read_rnd_buffe 配置的上限,如此循环。
另外 MySQL 的其中一个分支 Mariadb 对 MySQL 的 MRR 做了很多优化,有兴趣的同学可以看下文末的推荐阅读。
3.4)尾声
你也看出来了,MRR 跟索引有很大的关系。
索引是 MySQL 对查询做的一个优化,把原本杂乱无章的数据,用有序的结构组织起来,让全表扫描变成有章可循的查询。而我们讲的 MRR,则是 MySQL 对基于索引的查询做的一个的优化,可以说是对优化的优化了。
要优化 MySQL 的查询,就得先知道 MySQL 的查询过程;而要优化索引的查询,则要知道 MySQL 索引的原理。就像之前在「如何学习 MySQL」里说的,要优化一项技术、学会调优,首先得先弄懂它的原理,这两者是不同的 Level。
推荐阅读:
- MySQL MRR
- Mariadb MRR
- MySQL索引背后的数据结构及算法原理
- MySQl MRR 源码分析
相关文章:
Mysql Nested-Loop Join算法和MRR
MySQL8之前仅支持一种join 算法—— nested loop,在 MySQL8 中推出了一种新的算法 hash join,比 nested loop 更加高效。(后面有时间介绍这种join算法) 1、mysql驱动表与被驱动表及join优化 先了解在join连接时哪个表是驱动表&a…...
Spark 广播/累加
Spark 广播/累加广播变量普通变量广播分布式数据集广播克制 Shuffle强制广播配置项Join Hintsbroadcast累加器Spark 提供了两类共享变量:广播变量(Broadcast variables)/累加器(Accumulators) 广播变量 创建广播变量…...

飞天云动,站在下一个商业时代的门口
ChatGPT的爆火让AIGC再度成为热词,随之而来的是对其商业化的畅想——不是ChatGPT自身如何盈利,而是它乃至整个AIGC能给现在的商业环境带来多大改变。 这不由得令人想起另一个同样旨在改变世界的概念,元宇宙。不同的是,元宇宙更侧…...
上海分时电价机制调整对储能项目的影响分析
安科瑞 耿敏花 2022年12月16日,上海市发改委发布《关于进一步完善我市分时电价机制有关事项的通知》(沪发改价管〔2022〕50号)。通知明确上海分时电价机制,一般工商业及其他两部制、大工业两部制用电夏季(7、8、9月)和冬季&#x…...

产品新人如何快速上手工作
三百六十行,行行出产品经理:上至封神的乔布斯,下至卖鸡蛋罐饼的阿姨,他们对如何打造自己的产品都会有一套完整的产品思路,这也是为什么说“人人都是产品经理”。这个看似光鲜的“经理”有时也会被戏称产品汪࿰…...
Linux: ARM GIC仅中断CPU 0问题分析
文章目录1. 前言2. 分析背景3. 问题4. 分析4.1 ARM GIC 中断芯片简介4.1.1 中断类型和分布4.1.2 拓扑结构4.2 问题根因4.2.1 设置GIC SPI中断的CPU亲和性4.2.2 GIC初始化:缺省的CPU亲和性4.2.2.1 boot CPU亲和性初始化流程4.2.2.1 其它非 boot CPU亲和性初始化流程5…...
)
第20篇:Java运算符全面总结(系列二)
目录 4、逻辑运算符 4.1 逻辑运算符 4.2 代码示例 5、赋值运算符 5.1 赋值运算符...
)
OpenCV4.x图像处理实例-OpenCV两小时快速入门(基于Python)
OpenCV两小时快速入门(基于Python) 文章目录 OpenCV两小时快速入门(基于Python)1、OpenCV环境安装2、图像读取与显示3、图像像素访问、操作与ROI4、图像缩放5、几何变换5.1 平移5.2 旋转6、基本绘图6.1 绘制直线6.2 绘制圆6.3 绘制矩形6.4 绘制文本7、剪裁图像8、图像平滑与…...

【Git】Mac忽略.DS_Store文件
我们在github上经常看到某些仓库里面包含了.DS_Store文件,或者某些sdk的压缩包里面可以看到,这都是由于随着git的提交把这类文件也提交到仓库,压缩也是一样,压缩这个先留着后面处理。 Mac上的.DS_Store文件 .DS_Store 文件&#…...
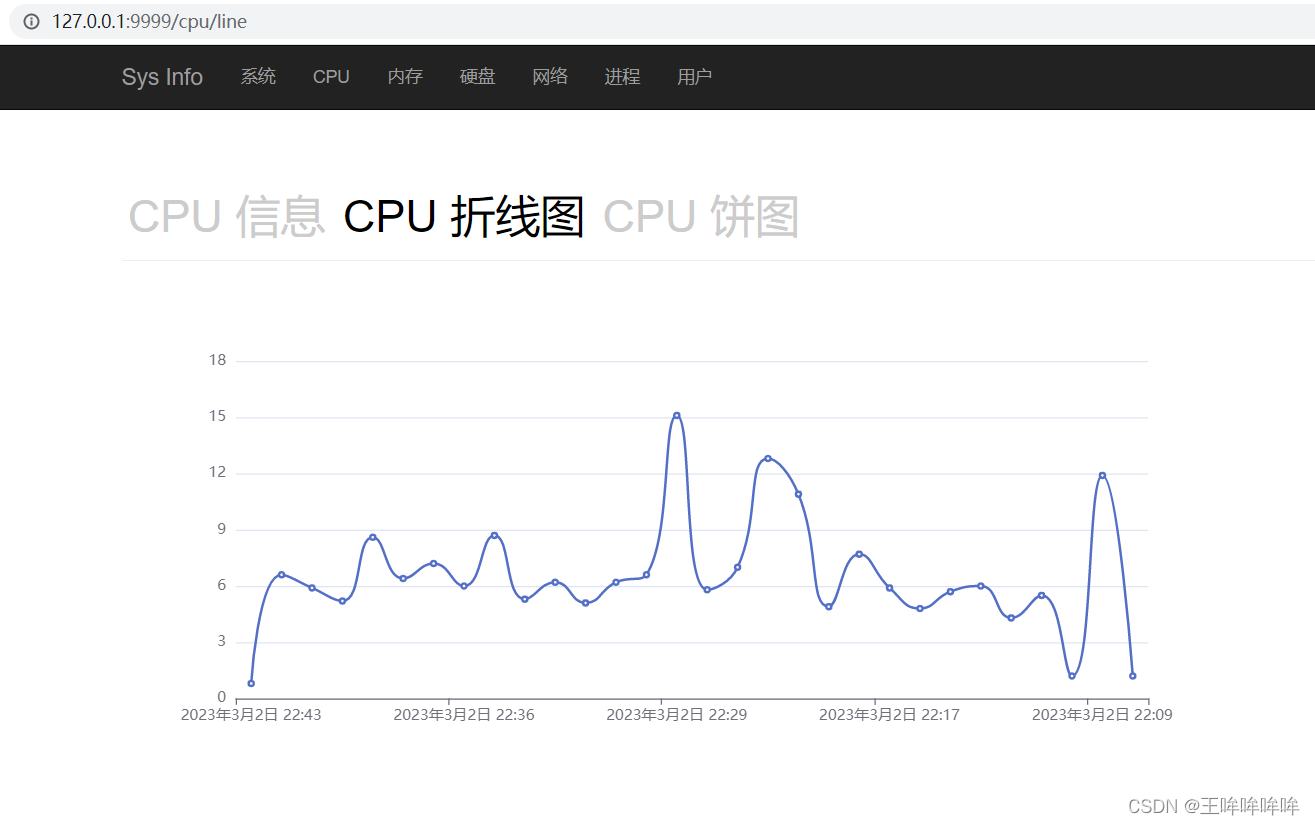
12.2 基于Django的服务器信息查看应用(CPU信息)
文章目录CPU信息展示图表展示-视图函数设计图表展示-前端界面设计折线图和饼图展示饼图测试折线图celery和Django配合实现定时任务Windows安装redis根据数据库中的数据绘制CPU折线图CPU信息展示 图表展示-视图函数设计 host/views.py def cpu(request):logical_core_num ps…...

【软件测试】接口测试总结
本文主要分为两个部分: 第一部分:主要从问题出发,引入接口测试的相关内容并与前端测试进行简单对比,总结两者之前的区别与联系。但该部分只交代了怎么做和如何做?并没有解释为什么要做? 第二部分࿱…...

代码随想录算法训练营第52天 || 300.最长递增子序列 || 674. 最长连续递增序列 || 718. 最长重复子数组
代码随想录算法训练营第52天 || 300.最长递增子序列 || 674. 最长连续递增序列 || 718. 最长重复子数组 300.最长递增子序列 题目介绍 给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 子序列 是由数组派生而来的序列,删除(或…...
gitblit 安装使用
1 安装服务端 简而言之:需要安装 java,gitblit, git 三个软件 Windows 10环境使用Gitblit搭建局域网Git服务器 前言 安装Java并配置环境安装gitblit并配置启动gitblit为windows服务使用gitblit创建repository并管理用户 1.1 安装Java并配…...

使用 TensorFlow、Keras-OCR 和 OpenCV 从技术图纸中获取信息
简单介绍输入是技术绘图图像。对象检测模型获取图像后对其进行分类,找到边界框,分配维度,计算属性。示例图像(输入)分类后,找到“IPN”部分。之后,它计算属性,例如惯性矩。它适用于不…...

ESP32设备驱动-GUVA-S12SD紫外线检测传感器驱动
GUVA-S12SD紫外线检测传感器驱动 文章目录 GUVA-S12SD紫外线检测传感器驱动1、GUVA-S12SD介绍2、硬件准备3、软件准备4、驱动实现1、GUVA-S12SD介绍 GUVA-S12SD 紫外线传感器芯片适用于检测太阳光中的紫外线辐射。 它可用于任何需要监控紫外线量的应用,并且可以简单地连接到任…...

WIN7下 program file 权限不足?咋整?!!
在WIN7下对Program Files目录的权限问题 [问题点数:40分,结帖人mysunck] 大部分人说要使用manifest,但是其中一个人说: “安装程序要求管理员很正常,你的程序可以在programfiles,但用户数据不能放那里,因…...
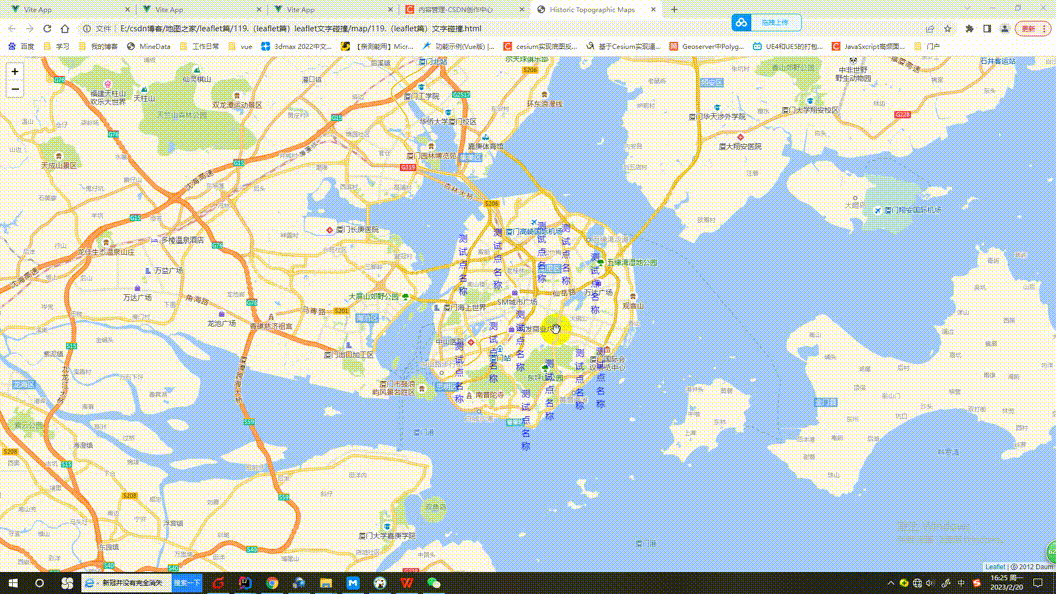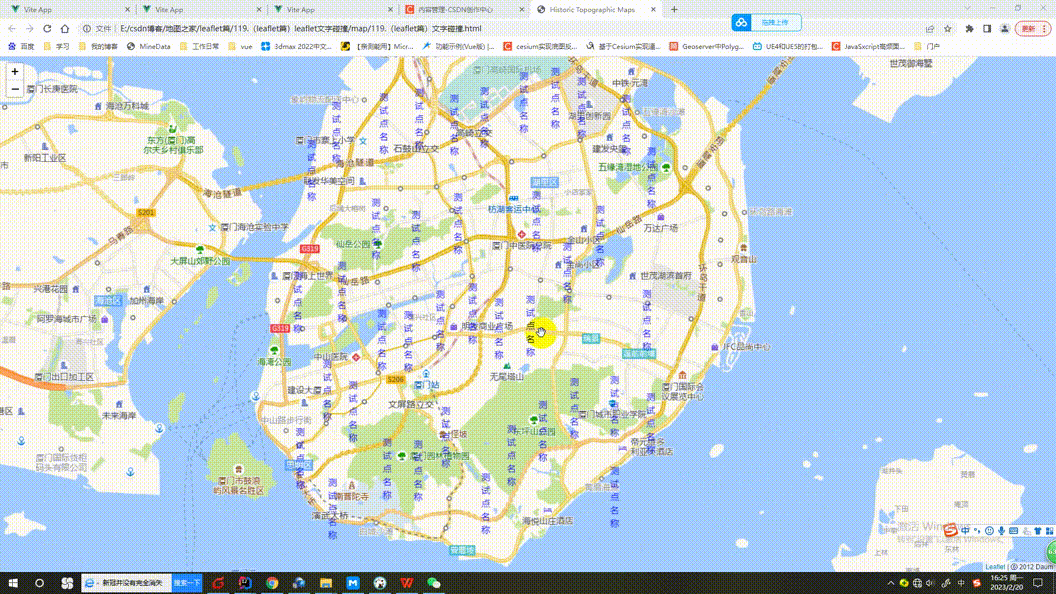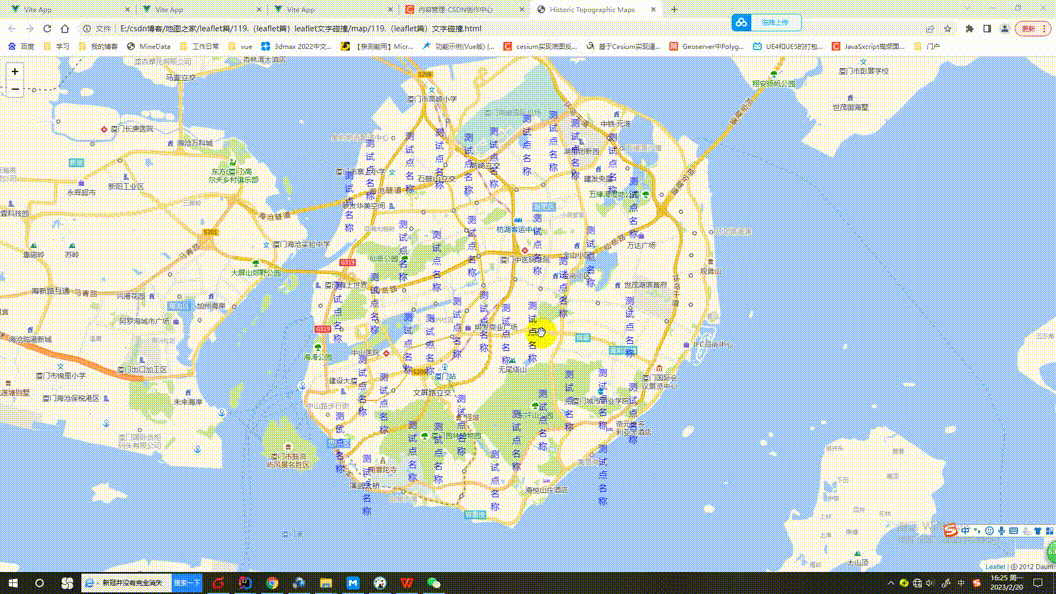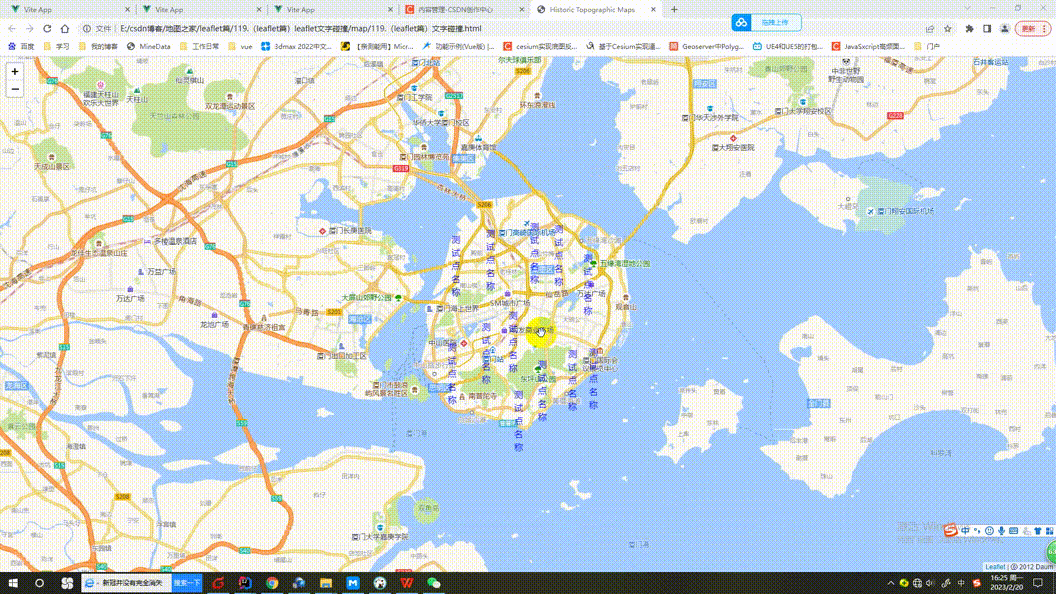
119.(leaflet篇)文字碰撞
听老人家说:多看美女会长寿 地图之家总目录(订阅之前建议先查看该博客) 文章末尾处提供保证可运行完整代码包,运行如有问题,可“私信”博主。 效果如下所示: 下面献上完整代码,代码重要位置会做相应解释 <!DOCTYPE html> <html>...

cuda编程以及GPU基本知识
目录CPU与GPU的基本知识CPU特点GPU特点GPU vs. CPU什么样的问题适合GPU?GPU编程CUDA编程并行计算的整体流程CUDA编程术语:硬件CUDA编程术语:内存模型CUDA编程术语:软件线程块(Thread Block)网格(…...

Python 机器学习/深度学习/算法专栏 - 导读目录
目录 一.简介 二.机器学习 三.深度学习 四.数据结构与算法 五.日常工具 一.简介 Python 机器学习、深度学习、算法主要是博主从研究生到工作期间接触的一些机器学习、深度学习以及一些算法的实现的记录,从早期的 LR、SVM 到后期的 Deep,从学习到工…...
Springboot怎么实现restfult风格Api接口
前言在最近的一次技术评审会议上,听到有同事发言说:“我们的项目采用restful风格的接口设计,开发效率更高,接口扩展性更好...”,当我听到开头第一句,我脑子里就开始冒问号:项目里的接口用到的是…...

阿里云ACP云计算备考笔记 (5)——弹性伸缩
目录 第一章 概述 第二章 弹性伸缩简介 1、弹性伸缩 2、垂直伸缩 3、优势 4、应用场景 ① 无规律的业务量波动 ② 有规律的业务量波动 ③ 无明显业务量波动 ④ 混合型业务 ⑤ 消息通知 ⑥ 生命周期挂钩 ⑦ 自定义方式 ⑧ 滚的升级 5、使用限制 第三章 主要定义 …...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...