【ChatGPT 默认强化学习策略】PPO 近端策略优化算法
PPO 近端策略优化算法
- PPO = 概率比率裁剪 + 演员-评论家算法
- 演员-评论家算法:多智能体强化学习核心框架
- 概率比率裁剪:逐步进行变化的方法
- PPO 目标函数的设计
- 重要性采样
- KL散度
PPO = 概率比率裁剪 + 演员-评论家算法
论文链接:https://arxiv.org/abs/1707.06347
OpenAI 提出 PPO 旨在解决一些在策略梯度方法中常见的问题,特别是与训练稳定性和样本效率有关的问题。
能在提高学习效率和保持训练稳定性之间找到平衡。
策略梯度方法的问题:
-
策略更新过快:
在传统的策略梯度方法中,如果每次更新都大幅度改变策略,可能会导致学习过程变得非常不稳定。
这种大幅更新可能会使得智能体忘记之前有效的策略,或者探索到低效的行为区域。 -
数据利用率低:
许多强化学习算法,特别是那些基于样本的算法,需要大量的数据才能学到有效的策略。
PPO试图通过更有效地使用数据来缓解这个问题,使得从每个数据样本中学到更多信息。 -
训练周期长:
由于数据利用率低,传统的强化学习算法通常需要很长的训练周期才能收敛到一个好的策略。
PPO通过改进学习算法来减少所需的训练时间。
PPO算法在演员-评论家的框架基础上,使用了 概率比率裁剪 技巧来控制策略更新的幅度,以确保训练的稳定性和性能。
演员-评论家算法:多智能体强化学习核心框架
请猛击:演员-评论家算法:多智能体强化学习核心框架
概率比率裁剪:逐步进行变化的方法
想象你有两个不同的蛋糕配方,这个比率就像是告诉你,使用新配方做蛋糕的可能性与旧配方相比有多大的变化。
如果我们的新策略和旧策略差别太大,那就像是突然完全改变蛋糕的配方,可能会做出一个很不一样的蛋糕,我们不确定它会好吃,还是不好吃。
所以,PPO通过计算概率比率来确保新策略不会偏离旧策略太远。
在每次策略更新时,它计算新策略和旧策略之间的比率,并通过限制这个比率的大小来裁剪更新幅度,以防止过大的改变。
解决如何安全地逐步进行变化,控制变化的方法。
具体请见目标函数的设计。
PPO 目标函数的设计
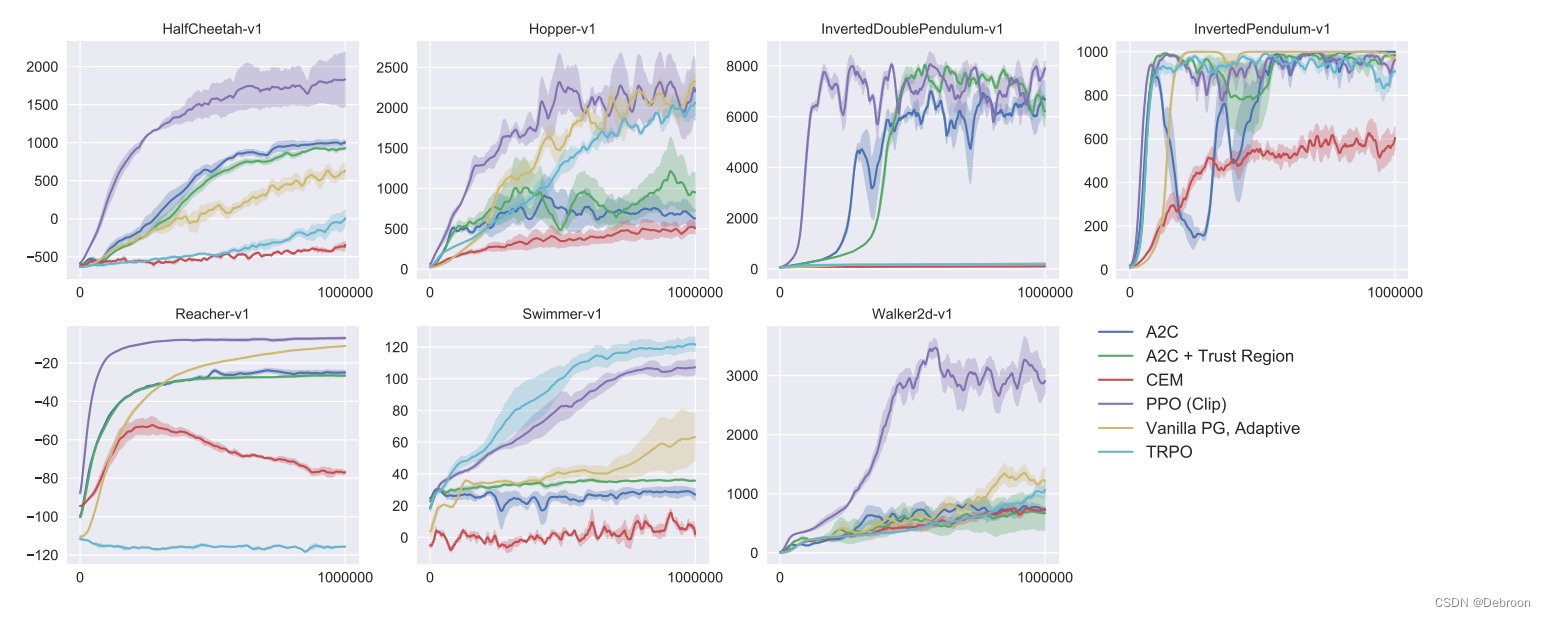
在测试中,PPO 基本在每个任务都是第一梯队。
那我们说一下 PPO 到底做了什么,居然比 A2C (另一种演员-评论家的改进算法)还要好。
近端,主要体现在其目标函数的设计上。
在PPO(近端策略优化)算法中,结合使用重要性采样和KL散度实现了主要的目标。
重要性采样:
- 探索与利用的平衡:重要性采样帮助算法判断新策略(新动作)与旧策略(旧动作)相比的效果。如果新策略比旧的好,算法会更倾向于采用新策略(这是“利用”)。但同时,算法也会尝试一些不同的策略(这是“探索”),以找到可能更好的解决方案。
- 渐进式更新:通过重要性采样,PPO能够逐渐、小心地改进策略,而不是一次性做出巨大的改变。这样的逐步改进有助于算法稳定地学习和适应新策略。
KL散度:
- 防止过度探索:KL散度用于确保新策略不会偏离旧策略太远。这个约束防止了算法在探索新策略时过度激进,从而避免了可能导致性能下降的大幅度策略变动。
- 维持学习的稳定性:通过限制新旧策略之间的差异,KL散度有助于保持学习过程的稳定性。这种稳定性对于复杂的学习任务特别重要,因为它减少了学习过程中的不确定性和波动。
重要性采样
你正在玩一个跳舞游戏。
在这个游戏里,你有一系列的舞蹈动作可以选择。
刚开始时,你只会一些基础的动作(这是你的“旧策略”)。
现在,你学会了一些新的、酷炫的舞蹈动作(这是你的“新策略”)。
在这个游戏里,你想要知道这些新动作是否真的比旧的好。
但是,你不能一次就完全改变你的舞蹈风格,因为这样你可能会跳得很差。
所以,你需要一种方法来慢慢地、安全地加入新动作。
使用重要性采样,你可以基于旧动作的经验来估计新动作的效果。
比如,如果新动作只是在旧动作的基础上做了一些小改动(比如多举了一下手),你可以推测这个新动作会有类似的效果。
通过比较,你可以决定哪些新动作真的相似,值得加入到你的舞蹈里,同时确保你的整体舞蹈还是很流畅。
不仅链接了新旧动作,还是渐进式更新。
在这个过程中,你不需要每次都完全重新学习动作。
相反,你只是在旧动作的基础上做一些小的调整。
这样,你可以逐渐地、稳步地改进你的动作,而不是一下子完全改变。
KL散度
你的舞蹈老师给了你一个规则:虽然可以尝试新动作,但是不能让你的舞蹈风格变化太大,否则会失去控制,可能跳得一团糟。
KL散度就像是舞蹈老师的一条规则,它告诉你新舞蹈和旧舞蹈之间的差别。
如果差别太大,就意味着你可能偏离了舞蹈的基本风格太远,需要调整一下。
这样,你就可以在尝试新动作的同时,保持你的舞蹈整体风格和质量。
仅仅使用重要性采样可能会导致策略变化过大,特别是在新策略与旧策略差异显著时。
KL散度提供了一种衡量策略之间差异的方法。
通过限制新旧策略之间的KL散度,PPO能够保证学习过程的连续性和平滑性,减少策略更新的剧烈波动。
数学公式:
- J P P O θ ′ ( θ ) = J θ ′ ( θ ) − β K L ( θ , θ ′ ) ⏟ Regularization = E ( s t , a t ) ∼ π θ ′ [ p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) A θ ′ ( s t , a t ) ] − β K L ( θ , θ ′ ) \begin{aligned} J_{\mathrm{PPO}}^{\theta^{\prime}}(\theta)& =J^{\theta^{\prime}}(\theta)-\underbrace{\beta\mathrm{KL}(\theta,\theta^{\prime})}_{\text{Regularization}} \\ &=\mathbb{E}_{(s_t,a_t)\sim\pi_{\theta^{\prime}}}\left[\frac{p_\theta\left(a_t\mid s_t\right)}{p_{\theta^{\prime}}\left(a_t\mid s_t\right)}A^{\theta^{\prime}}\left(s_t,a_t\right)\right]-\beta\mathrm{KL}(\theta,\theta^{\prime}) \end{aligned} JPPOθ′(θ)=Jθ′(θ)−Regularization βKL(θ,θ′)=E(st,at)∼πθ′[pθ′(at∣st)pθ(at∣st)Aθ′(st,at)]−βKL(θ,θ′)
这个公式是近端策略优化(PPO)算法中的一个重要部分,它包含了重要性采样和KL散度。
-
重要性采样:
- 公式的这部分: p θ ( a t ∣ s t ) p θ ′ ( a t ∣ s t ) \frac{p_\theta(a_t | s_t)}{p_{\theta'}(a_t | s_t)} pθ′(at∣st)pθ(at∣st),表示的是重要性采样比率。
- 这里, p θ ′ ( a t ∣ s t ) p_{\theta'}(a_t | s_t) pθ′(at∣st) 是旧策略(即上一次更新前的策略)在状态(s_t)下选择动作(a_t)的概率。
- p θ ( a t ∣ s t ) p_\theta(a_t | s_t) pθ(at∣st) 是新策略(即当前更新的策略)在相同状态下选择同一动作的概率。
- 通过这个比率,我们可以量化新旧策略之间在选择特定动作上的差异。
-
优势函数 A θ ′ ( s t , a t ) A^{\theta'}(s_t, a_t) Aθ′(st,at):
- 公式中的 A θ ′ ( s t , a t ) A^{\theta'}(s_t, a_t) Aθ′(st,at) 是优势函数,它评估在特定状态下采取某个动作相对于平均情况的好坏。
- 优势函数用于量化一个特定动作比平均情况要好或坏多少。
-
期望值 E \mathbb{E} E:
- E ( s t , a t ) ∼ π θ ′ [ … ] \mathbb{E}_{(s_t,a_t)\sim\pi_{\theta'}}[…] E(st,at)∼πθ′[…] 表示对于由旧策略 π θ ′ \pi_{\theta'} πθ′ 生成的状态和动作的期望值。
- 这意味着我们在计算这个公式时,考虑的是在旧策略下可能发生的所有状态和动作组合。
-
KL散度:
- 公式中的 K L ( θ , θ ′ ) \mathrm{KL}(\theta, \theta') KL(θ,θ′) 代表KL散度,它是一种衡量两个概率分布差异的方法。
- 在这里,它用来衡量新策略和旧策略之间的差异。
- β \beta β是一个调节参数,它控制了我们对策略变化的惩罚强度。KL散度越大,意味着新旧策略差异越大。
-
整体公式:
- 整个公式的第一部分, E ( s t , a t ) ∼ π θ ′ [ … ] \mathbb{E}_{(s_t,a_t)\sim\pi_{\theta'}}[…] E(st,at)∼πθ′[…],计算的是在旧策略下,采用新策略能带来多少优势。
- 第二部分, − β K L ( θ , θ ′ ) -\beta\mathrm{KL}(\theta, \theta') −βKL(θ,θ′),则是在控制新策略不要偏离旧策略太远的约束。
所以,这个公式基本上是在做两件事:
- 一方面,它试图找到一个新策略,使得在旧策略下的表现更好;
- 另一方面,它确保新策略不会与旧策略差异太大,从而保持学习的稳定性。
相关文章:
【ChatGPT 默认强化学习策略】PPO 近端策略优化算法
PPO 近端策略优化算法 PPO 概率比率裁剪 演员-评论家算法演员-评论家算法:多智能体强化学习核心框架概率比率裁剪:逐步进行变化的方法PPO 目标函数的设计重要性采样KL散度 PPO 概率比率裁剪 演员-评论家算法 论文链接:https://arxiv.org…...
【银行测试】金融银行-理财项目面试/分析总结(二)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 银行理财相关的项…...

张江智荟毁约offer
毕业8年后,找工作被国企歧视学历!已经收到了offer,在入职前一周被通知要撤回offer,拒绝录用,理由居然是他们只要本科211以上的人 这是我今天(2023-12-26)亲身经历的事,听说过面试前…...

ubuntu 系统终端颜色设置
1 开启终端颜色 # 第一步: 在 ~/.bashrc 中设置 force_color_promptyes# 第二步: 执行 source ~/.bashrc2 对于精减的 .bashrc 在 ~/.bashrc 中添加以下内容,再执行 source ~/.bashrc : # uncomment for a colored prompt, if…...
【Vue】class与style绑定
✨ 专栏介绍 在当今Web开发领域中,构建交互性强、可复用且易于维护的用户界面是至关重要的。而Vue.js作为一款现代化且流行的JavaScript框架,正是为了满足这些需求而诞生。它采用了MVVM架构模式,并通过数据驱动和组件化的方式,使…...

大厂前端面试题总结(百度、字节跳动、腾讯、小米.....),附上热乎面试经验!
先简单介绍下自己,我“平平无奇小天才”一枚,毕业于南方普通985普通学生,有幸去百度、字节面试,感觉大公司就是不一样,印象最深的是字节,所以有必要总结一下面试经验,以及面试中遇到的一些问题&…...
EXPLORING DIFFUSION MODELS FOR UNSUPERVISED VIDEO ANOMALY DETECTION 论文阅读
EXPLORING DIFFUSION MODELS FOR UNSUPERVISED VIDEO ANOMALY DETECTION 论文阅读 ABSTRACT1. INTRODUCTION2. RELATEDWORK3. METHOD4. EXPERIMENTAL ANALYSIS AND RESULTS4.1. Comparisons with State-Of-The-Art (SOTA)4.2. Diffusion Model Analysis4.3. Qualitative Result…...

当 ML 遇到 DevOps:如何理解 MLOps
近年来,人工智能 (AI) 和机器学习 (ML) 已经席卷全球,几乎成为任何行业的重要组成部分,从零售和娱乐到医疗保健和银行业。这些技术能够通过分析大量数据实现运营自动化、降低成本和促进决策&…...
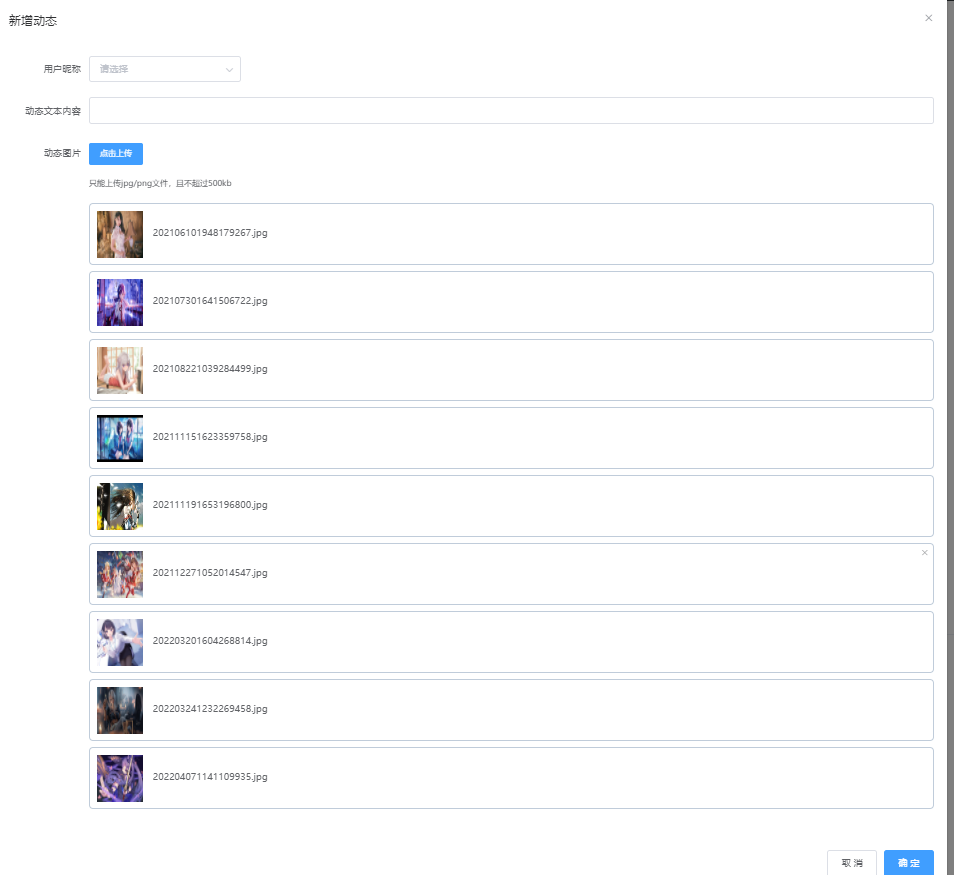
vue+element+springboot实现多张图片上传
1.需求说明 2.实现思路 3.el-upload组件主要属性说明 4.前端传递MultipartFile数组与服务端接收说明 5.完整代码 1.需求说明 动态模块新增添加动态功能,支持多张图片上传.实现过程中对el-upload组件不是很熟悉,踩了很多坑,当然也参考过别的文章,发现处理很…...

react使用useState更新数组失败
失败案例: const [addBox, setAddBox] useState([])const itemAdd (item) >{addBox.push(item);setAddBox(addBox)console.log(addBox,点击添加按钮)} 原因:react的useState hook监听的是浅监听 在 React 中,使用 useState Hook 来更新…...

《LIO-SAM阅读笔记》3.后端优化
前言: LIO-SAM后端优化部分写在了mapOptimization.cpp文件中,本部分主要进行了激光帧的scan-to-map匹配,回环检测以及关键帧的因子图优化。本部分主要有两个环节同步进行,一个单独开辟了回环检测线程,另外一个是lidar…...

mac下jd-gui提示没有找到合适的jdk版本
mac下jd-gui提示jdk有问题 背景解决看一下是不是真有问题了方法一:修改启动脚本方法二:设置launchd环境变量 扩展动态切jdk脚本(.bash_profile) 背景 配置了动态jdk后,再次使用JD-GUI提示没有找到合适的jdk版本。 解决 看一下是不是真有问题…...

FlinkSQL窗口实例分析
Windowing TVFs Windowing table-valued functions (Windowing TVFs),即窗口表值函数 注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区,即存在:group by window_start,wind…...
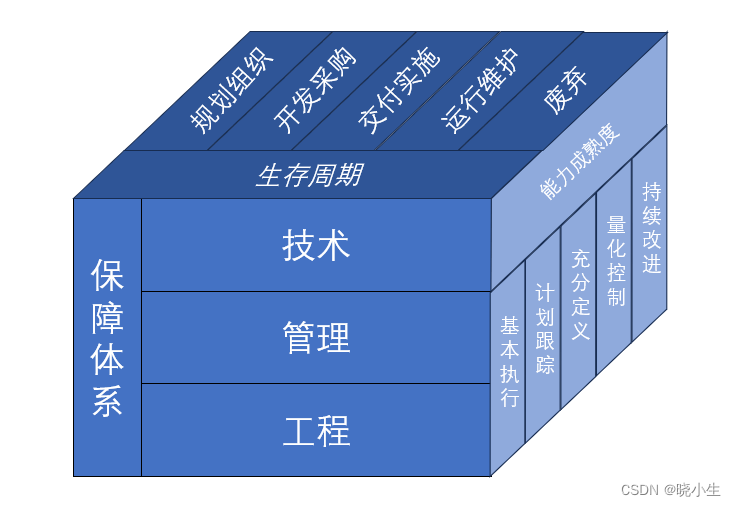
18-网络安全框架及模型-信息系统安全保障模型
信息系统安全保障模型 1 基本概念 信息系统安全保障是针对信息系统在运行环境中所面临的各种风险,制定信息系统安全保障策略,设计并实现信息系统安全保障架构或模型,采取工程、技术、管理等安全保障要素,将风险减少至预定可接受的…...
apk(安装包))
Android 提取(备份)apk(安装包)
Android 提取(备份)apk(安装包) 一、通过安卓代码的方式 主要分三步: 根据应用找到包名根据包名获得apk提取apk 提取apk代码 private static final String BACKUP_PATH "/sdcard/backup1/"; private static final String APK ".apk";pri…...
metadata和超时设置)
gRPC-Go基础(4)metadata和超时设置
文章目录 0. 简介1. metadata1.1 metadata结构1.2 metadata创建1.3 客户端处理metadata1.4 服务端处理metadata1.5 metadata的传输 2. 超时设置2.1 客户端输出超时信息2.2 服务端端接收超时信息 3. 小结 0. 简介 Go在多个go routine之间传递数据使用的是Go SDK提供的context包…...

语言模型:从n-gram到神经网络的演进
目录 1 前言2 语言模型的两个任务2.1 自然语言理解2.2 自然语言生成 3 n-gram模型4 神经网络语言模型5 结语 1 前言 语言模型是自然语言处理领域中的关键技术之一,它致力于理解和生成人类语言。从最初的n-gram模型到如今基于神经网络的深度学习模型,语言…...
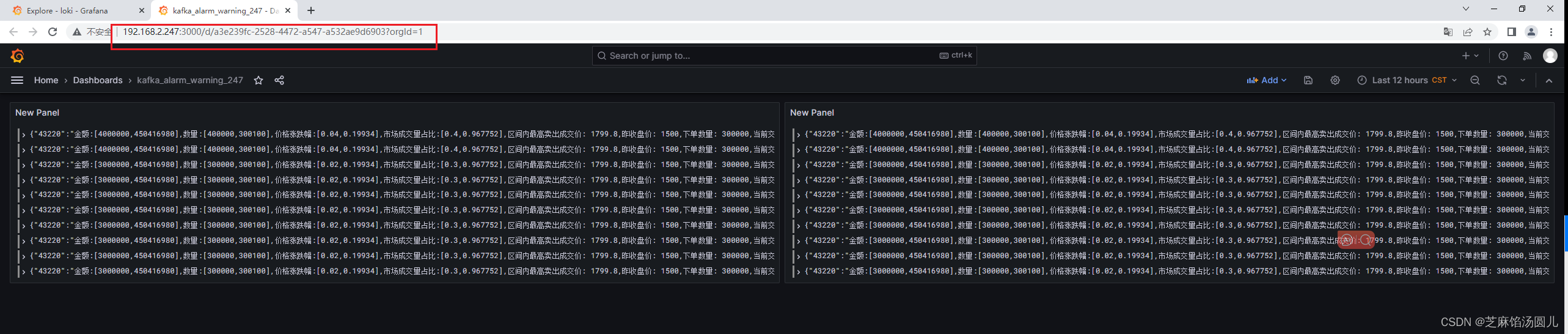
docker compose 部署 grafana + loki + vector 监控kafka消息
Centos7 随笔记录记录 docker compose 统一管理 granfana loki vector 监控kafka 信息。 当然如果仅仅是想通过 Grafana 监控kafka,推荐使用 Grafana Prometheus 通过JMX监控kafka 目录 1. 目录结构 2. 前提已安装Docker-Compose 3. docker-compose 自定义服…...
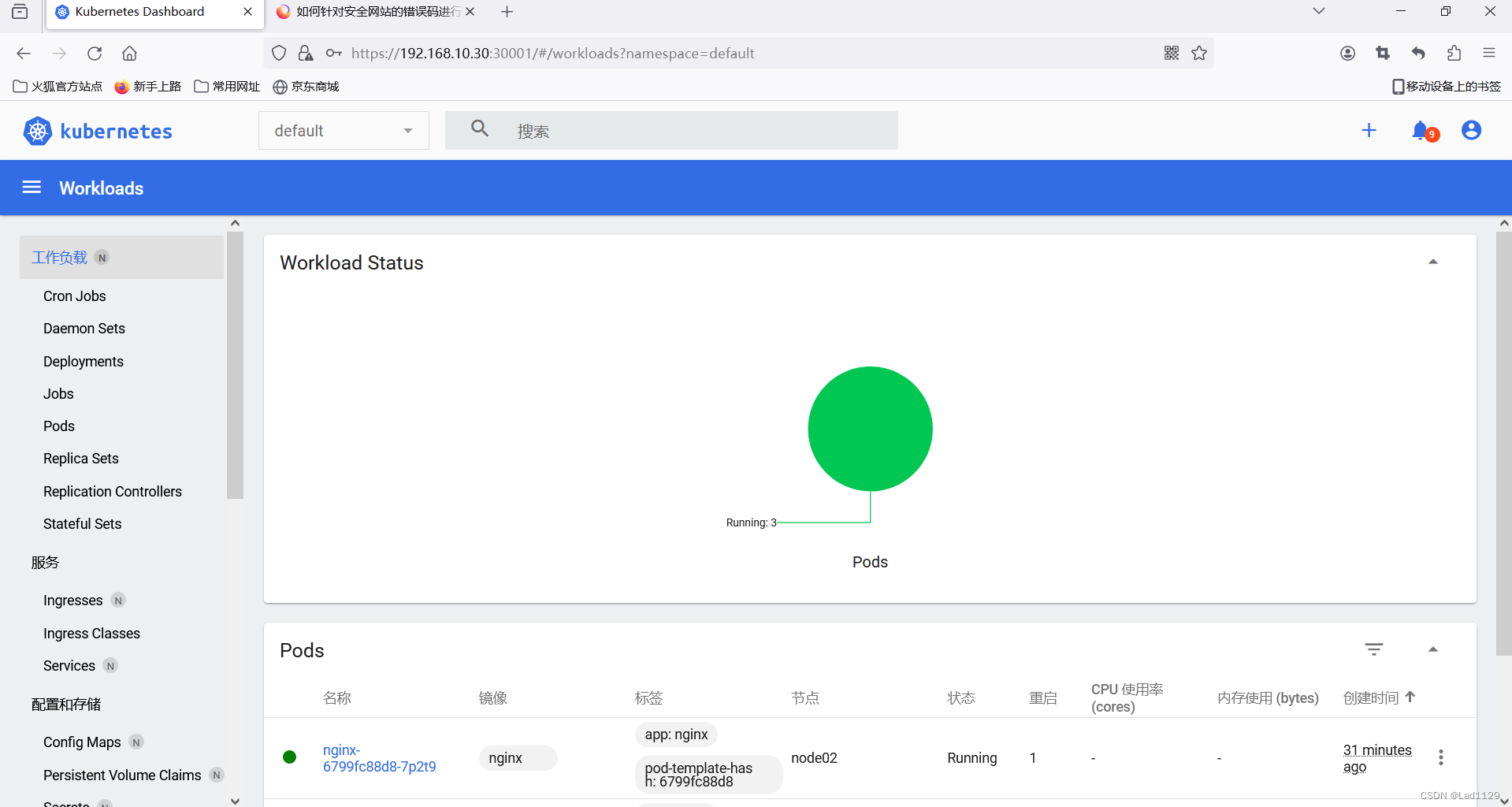
kubeadm创建k8s集群
kubeadm来快速的搭建一个k8s集群: 二进制搭建适合大集群,50台以上。 kubeadm更适合中下企业的业务集群。 部署框架 master192.168.10.10dockerkubelet kubeadm kubectl flannelnode1192.168.10.20dockerkubelet kubeadm kubectl flannelnode2192.168.1…...
鸿蒙开发之android对比开发《基础知识》
基于华为鸿蒙未来可能不再兼容android应用,推出鸿蒙开发系列文档,帮助android开发人员快速上手鸿蒙应用开发。 1. 鸿蒙使用什么基础语言开发? ArkTS是鸿蒙生态的应用开发语言。它在保持TypeScript(简称TS)基本语法风…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...