FlinkSQL窗口实例分析
Windowing TVFs
Windowing table-valued functions (Windowing TVFs),即窗口表值函数
注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区,即存在:group by window_start,window_end
-
TUMBLE函数采用三个必需参数,一个可选参数:
TUMBLE(TABLE data, DESCRIPTOR(timecol), size [, offset ])
data:是一个表参数,可以是与时间属性列的任何关系。
timecol:是一个列描述符,指示数据的哪些时间属性列应映射到滚动窗口。
size:是指定翻滚窗口宽度的持续时间。
offset: 是一个可选参数,用于指定窗口开始移动的偏移量。 -
HOP采用 4 个必需参数和 1 个可选参数:
HOP(TABLE data, DESCRIPTOR(timecol), slide, size [, offset ])
data:是一个表参数,可以是与时间属性列的任何关系。
timecol:是一个列描述符,指示数据的哪些时间属性列应映射到跳跃窗口。
slide:是指定连续跳跃窗口开始之间的持续时间的持续时间
size:是指定跳跃窗口宽度的持续时间。
offset: 是一个可选参数,用于指定窗口开始移动的偏移量。 -
CUMULATE采用 4 个必需参数和 1 个可选参数:
CUMULATE(TABLE data, DESCRIPTOR(timecol), step, size)
data:是一个表参数,可以是与时间属性列的任何关系。
timecol:是一个列描述符,指示数据的哪些时间属性列应映射到累积窗口。
step:是指定连续累积窗口末尾之间增加的窗口大小的持续时间。
size:是指定累积窗口最大宽度的持续时间。size必须是 的整数倍step。
offset: 是一个可选参数,用于指定窗口开始移动的偏移量。
滚动窗口
CREATE TABLE kafka_table(mid bigint,db string,sch string,tab string,opt string,ts bigint,ddl string,err string,src map < string, string >,cur map < string, string >,cus map < string, string >,event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH ('connector' = 'kafka','topic' = 't0','properties.bootstrap.servers' = 'xx.xx.xx.xx:9092','scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset'format' = 'json'
);create view tmp as
selectCOALESCE(cur['group_name'], src['group_name']) group_name,COALESCE(cur['batch_number'], src['batch_number']) batch_number,event_time
from kafka_table
where UPPER(opt) <> 'DELETE';
--注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区select window_start,window_end,window_time,group_name,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,window_time,group_name滑动窗口
CREATE TABLE kafka_table(mid bigint,db string,sch string,tab string,opt string,ts bigint,ddl string,err string,src map < string, string >,cur map < string, string >,cus map < string, string >,event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH ('connector' = 'kafka','topic' = 't0','properties.bootstrap.servers' = 'xx.xx.xx.xx:9092','scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset'format' = 'json'
);create view tmp as
selectCOALESCE(cur['group_name'], src['group_name']) group_name,COALESCE(cur['batch_number'], src['batch_number']) batch_number,event_time
from kafka_table
where UPPER(opt) <> 'DELETE';
--注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区select window_start,window_end,window_time,group_name,count(*) as cnt from
TABLE(HOP(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '60' SECOND,INTERVAL '10' MINUTES))
group by window_start,window_end,window_time,group_name
累计窗口
CREATE TABLE kafka_table(mid bigint,db string,sch string,tab string,opt string,ts bigint,ddl string,err string,src map < string, string >,cur map < string, string >,cus map < string, string >,event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH ('connector' = 'kafka','topic' = 't0','properties.bootstrap.servers' = 'xx.xx.xx.xx:9092','scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset'format' = 'json'
);create view tmp as
selectCOALESCE(cur['group_name'], src['group_name']) group_name,COALESCE(cur['batch_number'], src['batch_number']) batch_number,event_time
from kafka_table
where UPPER(opt) <> 'DELETE';
--注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区select window_start,window_end,window_time,group_name,count(*) as cnt from
TABLE(CUMULATE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '1' HOUR,INTERVAL '24' HOURS)) --从零点开始累计
TABLE(CUMULATE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '60' SECOND,INTERVAL '10' MINUTES))
TABLE(CUMULATE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '1' MINUTE,INTERVAL '1' HOURS))
group by window_start,window_end,window_time,group_name窗口聚合-多维分析
CREATE TABLE kafka_table(mid bigint,db string,sch string,tab string,opt string,ts bigint,ddl string,err string,src map < string, string >,cur map < string, string >,cus map < string, string >,event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH ('connector' = 'kafka','topic' = 't0','properties.bootstrap.servers' = 'xx.xx.xx.xx:9092','scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset'format' = 'json'
);create view tmp as
selectCOALESCE(cur['group_name'], src['group_name']) group_name,COALESCE(cur['batch_number'], src['batch_number']) batch_number,event_time
from kafka_table
where UPPER(opt) <> 'DELETE';
--注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区--实例1:整体聚合
select window_start,window_end,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end--实例2:根据字段聚合,n个维度
select window_start,window_end,group_name,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,group_name--实例3:多维分析GROUPING SETS
select window_start,window_end,group_name,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,GROUPING SETS((group_name)) --等同于 实例2
group by window_start,window_end,GROUPING SETS((group_name), ()) --等同于 实例1 union all 实例2--实例4:多维分析GROUPING SETS,多个字段
select window_start,window_end,group_name,batch_number,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,GROUPING SETS((group_name,batch_number),(group_name),(batch_number),())--实例5:多维分析CUBE 2^n个维度
select window_start,window_end,group_name,batch_number,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,CUBE(group_name) --等同于group by window_start,window_end,GROUPING SETS((group_name), ())
group by window_start,window_end,CUBE(group_name,batch_number) --等同于实例4--实例6:多维分析ROLLUP n+1个维度
select window_start,window_end,group_name,batch_number,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '10' MINUTES))
group by window_start,window_end,ROLLUP(group_name) --等同于 实例1 union all 实例2
group by window_start,window_end,ROLLUP(group_name,batch_number) --等同于GROUPING SETS((group_name,batch_number),(group_name),())窗口topN
Window Top-N 语句的语法:
SELECT [column_list]
FROM (SELECT [column_list],ROW_NUMBER() OVER (PARTITION BY window_start, window_end [, col_key1...]ORDER BY col1 [asc|desc][, col2 [asc|desc]...]) AS rownumFROM table_name) -- relation applied windowing TVF
WHERE rownum <= N [AND conditions]
CREATE TABLE kafka_table(mid bigint,db string,sch string,tab string,opt string,ts bigint,ddl string,err string,src map < string, string >,cur map < string, string >,cus map < string, string >,event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH ('connector' = 'kafka','topic' = 't0','properties.bootstrap.servers' = 'xx.xx.xx.xx:9092','scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset'format' = 'json'
);create view tmp as
selectCOALESCE(cur['group_name'], src['group_name']) group_name,COALESCE(cur['batch_number'], src['batch_number']) batch_number,event_time
from kafka_table
where UPPER(opt) <> 'DELETE';
--注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区--方式1:窗口 Top-N 紧随窗口聚合之后
create view tmp_window as
select window_start,window_end,window_time,group_name,count(*) as cnt from
TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '24' HOURS))
group by window_start,window_end,window_time,group_name;--计算每个翻滚 24小时窗口内pv最高的前 3 名机构(即每天PV最高的前三名)
select * from(select * ,ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY cnt DESC) as rnfrom tmp_window) t
where rn <=3--计算每个机构pv最高的前 3天
select * from(select * ,ROW_NUMBER() OVER (PARTITION BY group_name ORDER BY cnt DESC) as rnfrom tmp_window) t
where rn <=3--方式2:窗口 Top-N 紧随窗口 TVF 之后
select *
from(selectwindow_start,window_end,window_time,group_name,ts,ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY ts DESC) AS rnfrom TABLE(TUMBLE(TABLE tmp, DESCRIPTOR(event_time), INTERVAL '24' HOURS)))
where rn <=3窗口去重
Flink使用去重的方式,就像Window Top-N查询ROW_NUMBER()的方式一样。理论上,
窗口重复数据删除是窗口 Top-N 的一种特殊情况,其中 N 为 1,并且按处理时间或事件时间排序
Window Deduplication 语句的语法:
SELECT [column_list]
FROM (SELECT [column_list],ROW_NUMBER() OVER (PARTITION BY window_start, window_end [, col_key1...]ORDER BY time_attr [asc|desc]) AS rownumFROM table_name) -- relation applied windowing TVF
WHERE (rownum = 1 | rownum <=1 | rownum < 2) [AND conditions]
CREATE TABLE kafka_table(mid bigint,db string,sch string,tab string,opt string,ts bigint,ddl string,err string,src map < string, string >,cur map < string, string >,cus map < string, string >,group_name as COALESCE(cur['group_name'], src['group_name']),batch_number as COALESCE(cur['batch_number'], src['batch_number']),event_time as cast(TO_TIMESTAMP_LTZ(ts,3) AS TIMESTAMP(3)), -- TIMESTAMP(3)/TIMESTAMP_LTZ(3)WATERMARK FOR event_time AS event_time - INTERVAL '2' MINUTE --SECOND
) WITH ('connector' = 'kafka','topic' = 't0','properties.bootstrap.servers' = 'xx.xx.xx.xx:9092','scan.startup.mode' = 'earliest-offset', --group-offsets/earliest-offset/latest-offset'format' = 'json'
);select *
from(selectwindow_start,window_end,group_name,event_time,ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY event_time DESC) AS rnfrom TABLE(TUMBLE(TABLE kafka_table, DESCRIPTOR(event_time), INTERVAL '24' HOURS)))
where rn =1
相关文章:

FlinkSQL窗口实例分析
Windowing TVFs Windowing table-valued functions (Windowing TVFs),即窗口表值函数 注意:窗口函数不可以单独使用,需要聚合函数,按照 window_start、window_end 分区,即存在:group by window_start,wind…...
18-网络安全框架及模型-信息系统安全保障模型
信息系统安全保障模型 1 基本概念 信息系统安全保障是针对信息系统在运行环境中所面临的各种风险,制定信息系统安全保障策略,设计并实现信息系统安全保障架构或模型,采取工程、技术、管理等安全保障要素,将风险减少至预定可接受的…...
apk(安装包))
Android 提取(备份)apk(安装包)
Android 提取(备份)apk(安装包) 一、通过安卓代码的方式 主要分三步: 根据应用找到包名根据包名获得apk提取apk 提取apk代码 private static final String BACKUP_PATH "/sdcard/backup1/"; private static final String APK ".apk";pri…...
metadata和超时设置)
gRPC-Go基础(4)metadata和超时设置
文章目录 0. 简介1. metadata1.1 metadata结构1.2 metadata创建1.3 客户端处理metadata1.4 服务端处理metadata1.5 metadata的传输 2. 超时设置2.1 客户端输出超时信息2.2 服务端端接收超时信息 3. 小结 0. 简介 Go在多个go routine之间传递数据使用的是Go SDK提供的context包…...

语言模型:从n-gram到神经网络的演进
目录 1 前言2 语言模型的两个任务2.1 自然语言理解2.2 自然语言生成 3 n-gram模型4 神经网络语言模型5 结语 1 前言 语言模型是自然语言处理领域中的关键技术之一,它致力于理解和生成人类语言。从最初的n-gram模型到如今基于神经网络的深度学习模型,语言…...
docker compose 部署 grafana + loki + vector 监控kafka消息
Centos7 随笔记录记录 docker compose 统一管理 granfana loki vector 监控kafka 信息。 当然如果仅仅是想通过 Grafana 监控kafka,推荐使用 Grafana Prometheus 通过JMX监控kafka 目录 1. 目录结构 2. 前提已安装Docker-Compose 3. docker-compose 自定义服…...
kubeadm创建k8s集群
kubeadm来快速的搭建一个k8s集群: 二进制搭建适合大集群,50台以上。 kubeadm更适合中下企业的业务集群。 部署框架 master192.168.10.10dockerkubelet kubeadm kubectl flannelnode1192.168.10.20dockerkubelet kubeadm kubectl flannelnode2192.168.1…...
鸿蒙开发之android对比开发《基础知识》
基于华为鸿蒙未来可能不再兼容android应用,推出鸿蒙开发系列文档,帮助android开发人员快速上手鸿蒙应用开发。 1. 鸿蒙使用什么基础语言开发? ArkTS是鸿蒙生态的应用开发语言。它在保持TypeScript(简称TS)基本语法风…...
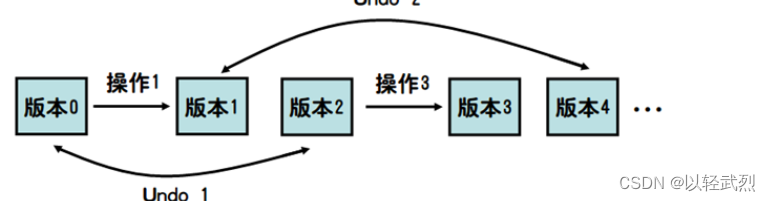
2702 高级打字机
因为Undo操作只能撤销Type操作,所以Undo x 实际上就是删除文章末尾x个字母。用一个栈即可解决(每个字母最多进出一次)。 这种情况下只需要设计一个合理的数据结构依次执行操作即可。 版本树:Undo x撤销最近的x次修改操作…...

yolov5旋转目标检测-遥感图像检测-无人机旋转目标检测-附代码和原理
综述 为了解决旋转目标检测问题,研究者们提出了多种方法和算法。以下是一些常见的旋转目标检测方法: 基于滑动窗口的方法:在图像上以不同的尺度和角度滑动窗口,通过分类器判断窗口中是否存在目标。这种方法简单直观,…...
Qt学习:Qt的意义安装Qt
Qt 的简介 QT 是一个跨平台的 C图形用户界面应用程序框架。它为程序开发者提供图形界面所需的所有功能。它是完全面向对象的,很容易扩展,并且允许真正地组件编程。 支持平台 xP 、 Vista、Win7、win8、win2008、win10Windows . Unix/Linux: Ubuntu 等…...
Anylogic Pro 8.8.x for Mac / for Linux Crack
Digital twins – a step towards a digital enterprise AnyLogic是唯一一个支持创建模拟模型的方法的模拟建模工具:面向过程(离散事件)、系统动态和代理,以及它们的任何组合。AnyLogic提供的建模语言的独特性、灵活性和强大性使…...

ROS无人机初始化GPS定位漂移误差,确保无人机稳定飞行
引言: 由于GPS在室外漂移的误差比较大,在长时间静止后启动,程序发布的位置可能已经和预期的位置相差较大,导致无法完成任务,尤其是气压计的数据不准,可能会导致无人机不能起飞或者一飞冲天。本文主要是在进…...
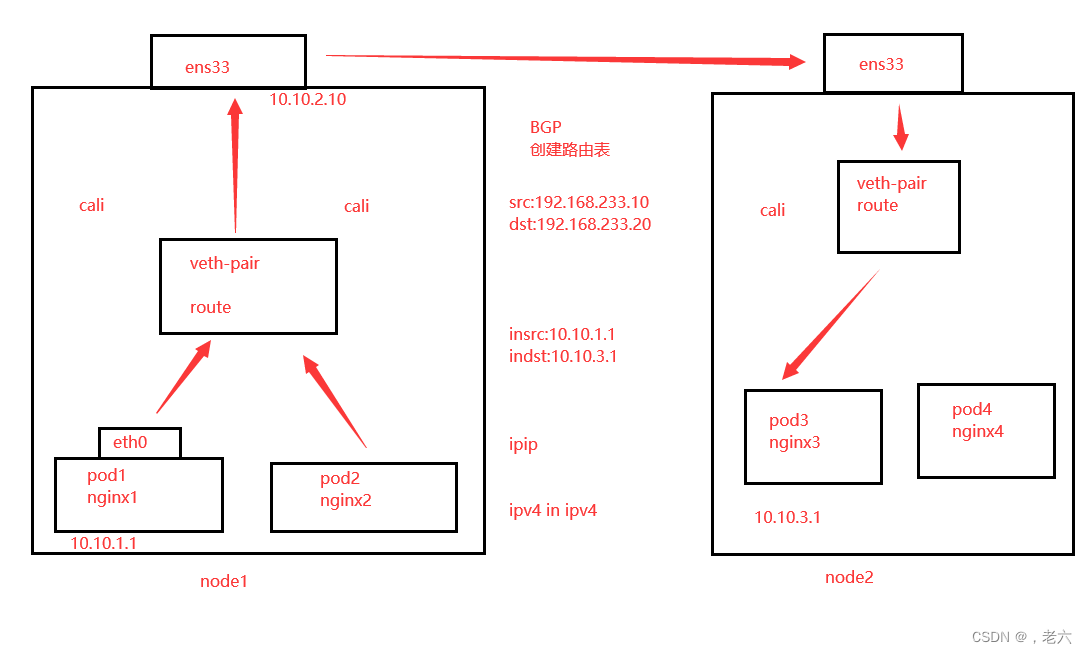
k8s网络类型
k8s中的通信模式: pod内部之间容器与容器之间的通信。 在同一个pod中的容器共享资源和网络,使用同一个网络命名空间。可以直接通信的。 同一个node节点之内,不同pod之间的通信。 每一个pod都有一个全局的真实的IP地址,同一个n…...
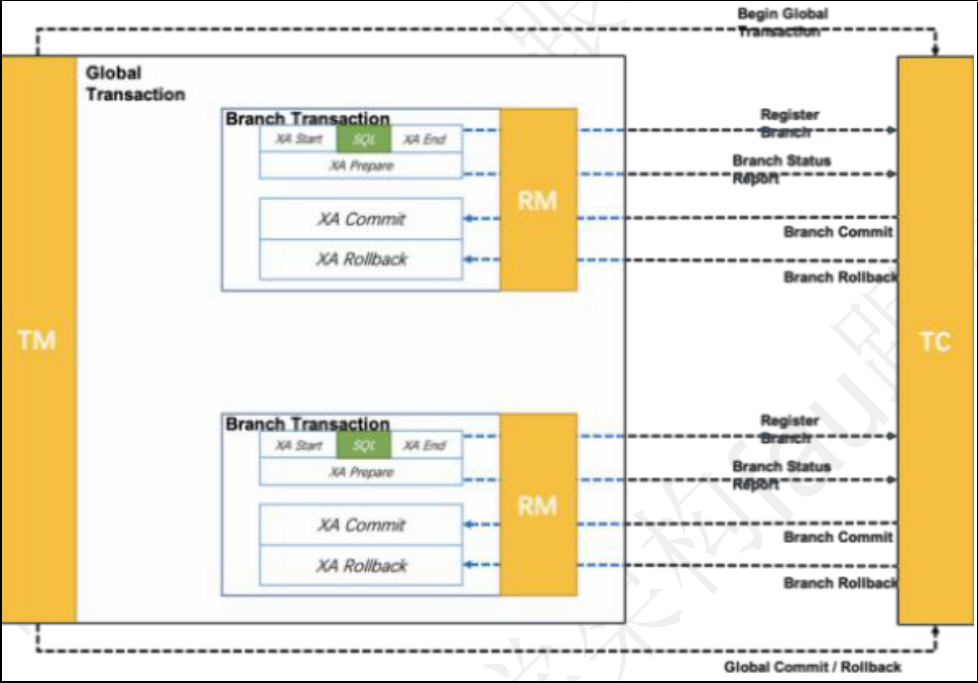
Seata 中封装了四种分布式事务模式,分别是: AT 模式, TCC 模式, Saga 模式, XA 模式,
文章目录 seata概述Seata 中封装了四种分布式事务模式,分别是:AT 模式,TCC 模式,Saga 模式,XA 模式, 今天我们来聊聊seata seata 概述 在微服务架构下,由于数据库和应用服务的拆分,…...

为什么设计制造行业需要数据加密?
设计制造行业是一个涉及多种技术、工艺、材料和产品的广泛领域,它对经济和社会的发展有着重要的影响。然而,随着数字化、智能化和网络化的发展,设计制造行业也面临着越来越多的数据安全风险,如数据泄露、数据篡改、数据窃取等。这…...

查看ios app运行日志
摘要 本文介绍了一款名为克魔助手的iOS应用日志查看工具,该工具可以方便地查看iPhone设备上应用和系统运行时的实时日志和奔溃日志。同时还提供了奔溃日志分析查看模块,可以对苹果奔溃日志进行符号化、格式化和分析,极大地简化了开发者的调试…...

怎么卸载macOS上的爱思助手如何卸载macOS上的logitech g hub,如何卸载顽固macOS应用
1.在App Store里下载Cleaner One Pro (注意,不需要订阅付费!!!白嫖基础功能就完全够了!!!) 2.运行软件,在左侧目录中选择“应用程序管理”,然后点…...

侦探IP“去推理化”:《名侦探柯南》剧场版走过26年
2023年贺岁档,柯南剧场版的第26部《黑铁的鱼影》如期上映。 这部在日本狂卷票房128亿日元的作品,被誉为有史以来柯南剧场版在商业成绩上最好的一部。 但该作在4月份日本还未上映前,就于国内陷入了巨大的争议。 试映内容里,灰原…...

图论 经典例题
1 拓扑排序 对有向图的节点排序,使得对于每一条有向边 U-->V U都出现在V之前 *有环无法拓扑排序 indegree[], nxs[];//前者表示节点 i 的入度,后者表示节点 i 指向的节点 queue [] for i in range(n):if indege[i] 0: queue.add(i)// 入度为0的节…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

高防服务器能够抵御哪些网络攻击呢?
高防服务器作为一种有着高度防御能力的服务器,可以帮助网站应对分布式拒绝服务攻击,有效识别和清理一些恶意的网络流量,为用户提供安全且稳定的网络环境,那么,高防服务器一般都可以抵御哪些网络攻击呢?下面…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...

PostgreSQL——环境搭建
一、Linux # 安装 PostgreSQL 15 仓库 sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-$(rpm -E %{rhel})-x86_64/pgdg-redhat-repo-latest.noarch.rpm# 安装之前先确认是否已经存在PostgreSQL rpm -qa | grep postgres# 如果存在࿰…...