【SpringCache】SpringCache详解及其使用,Redis控制失效时间
一、使用
在 Spring 中,使用缓存通常涉及以下步骤:
1、添加缓存依赖: 确保项目中添加了缓存相关的依赖。如果使用 Maven,可以在项目的 pom.xml 文件中添加 Spring Cache 的依赖。
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId>
</dependency>
2、配置缓存: 在 Spring 配置文件中进行缓存的基本配置。如果是使用 Spring Boot,通常无需额外配置,因为 Spring Boot 提供了默认的缓存配置。
第1步:在启动类上加注解@EnableCaching
第2步:在具体方法上加注解【@CachePut、@CacheEvict、@Caching】或者在方法上添加 @Cacheable 注解: 在需要缓存的方法上使用 @Cacheable 注解,指定缓存的名称、键等信息。
3、触发缓存: 调用带有 @Cacheable 注解的方法时,Spring 会检查缓存中是否已经有了相应的结果。如果有,则直接返回缓存结果;如果没有,则执行方法体,计算结果并将结果缓存起来。
二、详解
1、@Cacheable
@Cacheable 是 Spring Framework 中的一个注解,用于声明某个方法的结果应该被缓存,以便在后续调用中可以直接返回缓存的结果,而不需要再次执行方法体。这个注解通常用于提高方法的执行效率,尤其是对于那些计算成本较高的方法。
基本用法
import org.springframework.cache.annotation.Cacheable;public class MyService {@Cacheable(value = "myCache", key = "#input")public String getResult(String input) {// 如果缓存中存在以input为key的结果,则直接返回缓存结果// 否则,执行方法体,并将结果缓存起来// ...}
}在上述例子中:
@Cacheable 注解标注在 getResult 方法上,表示该方法的结果将会被缓存。
value 属性指定了缓存的名称(可以有多个缓存,每个缓存有一个名称)。
key 属性指定了缓存的键,这里使用了 SpEL(Spring Expression Language)表达式,表示使用 input 参数的值作为缓存的键。有时候会按照下方书写方式:
@Cacheable(value = "myCache", key = "#p0+','+#p1")
key = “#p0+‘,’+#p1” :指定缓存的键,使用了 Spring Expression Language(SpEL)的语法。#p0 表示方法的第一个参数,#p1 表示方法的第二个参数。在这个例子中,键由第一个参数和第二个参数以逗号连接而成。这意味着如果两次调用方法的时候,这两个参数的值相同,那么它们会共享相同的缓存结果。如果想要每次调用方法都修改缓存值,可以用其他拼接符连接,比如横杠、空格、冒号或者将方法名作为key值一部分。
key = "#p0 + '_' + #p1" // 使用下划线key = "#p0 + ',' + #p1 + ',' + #p2" // 添加额外的参数或常量key = "methodName + ',' + #p0 + ',' + #p1" //使用方法名作为一部分注意事项:
@Cacheable 注解需要在 Spring 环境中生效,因此通常需要在 Spring 的配置文件中启用缓存功能。
方法的返回值类型应该是可序列化的,以便能够存储在缓存中。
缓存的键是根据 key 属性生成的,所以确保它能够唯一标识方法的输入参数。
@Cacheable 是 Spring Cache 抽象的一部分,而具体的缓存实现可以是基于不同的后端,比如基于内存、Redis、Ehcache 等。
我们在使用的时候常常会和@SqlQuery注解一块使用,如果一个方法同时使用了 @Cacheable 注解和 @SqlQuery 注解,那么其执行流程通常如下:
-
首次调用: 当方法被首次调用时,Spring 会先检查缓存(由 @Cacheable
注解管理)。如果缓存中存在对应的结果,则直接从缓存中取出并返回,而不会执行实际的 SQL 查询。 -
缓存未命中: 如果缓存中不存在对应的结果,那么方法体会被执行。在方法体中,可能会执行 SQL 查询(由 @SqlQuery
注解管理),并将查询结果映射为方法的返回类型。 -
结果缓存: 如果启用了 @Cacheable
注解,方法执行完毕后,计算得到的结果会被缓存起来,以便下次相同的方法调用可以直接从缓存中获取。
所以,如果缓存中已有相应的结果,实际的 SQL 查询可能不会执行。这样可以有效减轻对数据库的访问压力,提高方法的执行效率。在使用这两个注解时,确保缓存的键和 SQL 查询的参数不会引起混淆,以便正确地识别和管理缓存。
2、@CacheEvict
@CacheEvict 是 Spring 框架中用于清除缓存的注解。它用于标记一个方法,在方法执行时会清除指定缓存中的数据。以下是 @CacheEvict 注解的主要属性和用法:
主要属性:
value(或 cacheNames): 指定要清除的缓存的名称,可以是一个字符串数组。例如:@CacheEvict(value = “myCache”) 或 @CacheEvict(cacheNames = {“cache1”, “cache2”})。
key: 指定用于生成缓存键的 SpEL 表达式。例如:@CacheEvict(value = "myCache", key = "#userI
condition: 指定清除缓存的条件,是一个 SpEL 表达式,如果表达式的值为 false,则不会清除缓存。例如:@CacheEvict(value = "myCache", condition = "#userId > 0")。
allEntries: 如果设置为 true,则会清除指定缓存中的所有条目。例如:@CacheEvict(value = "myCache", allEntries = true)。
beforeInvocation: 如果设置为 true,则在方法调用之前清除缓存;如果设置为 false(默认),则在方法调用之后清除缓存。例如:@CacheEvict(value = "myCache", beforeInvocation = true)。
示例用法:
@Service
public class MyService {@CacheEvict(value = "myCache", key = "#userId")public void clearCacheByUserId(long userId) {// 此方法执行时,会清除名为 "myCache" 中 key 为 userId 的缓存条目}@CacheEvict(value = "myCache", allEntries = true)public void clearEntireCache() {// 此方法执行时,会清除名为 "myCache" 中的所有缓存条目}
}
在上述例子中,clearCacheByUserId 方法用于清除名为 “myCache” 中 key 为 userId 的缓存条目,而 clearEntireCache 方法用于清除 “myCache” 中的所有缓存条目。
请注意,@CacheEvict 注解通常用于在方法执行时清除缓存。如果方法执行抛出异常,缓存清除可能不会发生,除非设置了 beforeInvocation = true。因此,要确保清除缓存的操作是安全的,不会因为异常而导致缓存清除失败。
3、@CachePut
@CachePut 是 Spring 框架中用于更新缓存的注解。它用于标记一个方法,在方法执行时会将结果放入缓存中。与 @Cacheable 不同,@CachePut 不会先检查缓存中是否已有结果,而是直接将方法的返回值放入缓存中。
以下是 @CachePut 注解的主要属性和用法:
主要属性:
value(或 cacheNames): 指定要更新的缓存的名称,可以是一个字符串数组。例如:@CachePut(value = "myCache") 或 @CachePut(cacheNames = {"cache1", "cache2"})。
key: 指定用于生成缓存键的 SpEL 表达式。例如:@CachePut(value = "myCache", key = "#userId")。
condition: 指定放入缓存的条件,是一个 SpEL 表达式,如果表达式的值为 false,则不会放入缓存。例如:@CachePut(value = "myCache", condition = "#userId > 0")。
unless: 与 condition 相反,如果表达式的值为 true,则不会放入缓存。例如:@CachePut(value = "myCache", unless = "#result == null")。
示例用法:
@Service
public class MyService {@CachePut(value = "myCache", key = "#userId")public String updateCacheByUserId(long userId) {// 此方法执行时,会将返回值放入名为 "myCache" 中 key 为 userId 的缓存条目// 注意:不会先检查缓存中是否已有结果,直接将方法的返回值放入缓存中// ...return "Updated Value";}
}
在上述例子中,updateCacheByUserId 方法用于将返回值放入名为 “myCache” 中 key 为 userId 的缓存条目。这个方法在执行时,不会先检查缓存中是否已有结果,而是直接将方法的返回值放入缓存中。
@CachePut 通常用于在更新操作之后,将最新的结果放入缓存,以保持缓存的一致性。需要注意的是,与 @Cacheable 不同,@CachePut 不会阻止方法的执行,即使缓存操作失败也不会影响方法的正常执行。
4、@Caching
@Caching 是 Spring 框架中用于组合多个缓存注解的注解。它允许同时在一个方法上使用多个缓存相关的注解,包括 @Cacheable、@CachePut、@CacheEvict 等,从而提供更灵活的缓存配置。
示例用法:
@Service
public class MyService {@Caching(cacheable = {@Cacheable(value = "cache1", key = "#userId")},put = {@CachePut(value = "cache2", key = "#result.id")})public User getUserById(long userId) {// 先尝试从 "cache1" 缓存中获取结果// 如果获取成功,则返回结果,不执行方法体// 如果获取失败,则执行方法体,并将结果放入 "cache1" 和 "cache2" 缓存中// ...return new User(userId, "John Doe");}
}
在上述例子中,@Caching 注解用于同时使用 @Cacheable 和 @CachePut 注解。具体来说:
@Cacheable 注解用于尝试从名为 “cache1” 的缓存中获取结果,如果获取成功,则直接返回结果,不执行方法体。
@CachePut 注解用于将方法的返回值放入名为 “cache2” 的缓存中,不论缓存中是否已有相同的键。
通过 @Caching 注解,可以更灵活地组合多个缓存注解,以满足复杂的缓存需求。
三、cache失效时间配置
1、注解属性中设置
在使用 @Cacheable 注解时,你可以通过设置 expire 或 expireAfterWrite 属性来配置缓存的失效时间。这取决于使用的缓存管理器,因为不同的缓存管理器可能支持不同的配置。
例如,如果你使用的是 Spring Boot,并且底层的缓存管理器是基于 Caffeine 的,你可以使用 expireAfterWrite 属性来设置失效时间。以下是一个示例:
@Cacheable(value = "myCache", key = "#input", expireAfterWrite = 5, timeUnit = TimeUnit.MINUTES)
public String getResult(String input) {// 如果缓存中存在以 input 为 key 的结果,则直接返回缓存结果// 否则,执行方法体,并将结果缓存起来,缓存时间为 5 分钟// ...
}
在上述示例中:
expireAfterWrite = 5 表示缓存项在写入后经过 5 分钟过期。
timeUnit = TimeUnit.MINUTES 表示时间单位是分钟。
具体的配置方式取决于使用的缓存管理器。如果你使用的是其他缓存管理器,例如 EhCache、Redis 等,具体的配置方式可能会有所不同。在配置文件或注解中查看相关属性,以确保正确地设置缓存的失效时间。
2、redis管理器设置
当使用 Redis 作为缓存管理器时,可以通过 Spring Boot 的配置文件或 Java 配置来设置 Redis 缓存的失效时间。以下是一个示例:
-
在 Spring Boot 的配置文件中设置 Redis 缓存失效时间: 在 application.properties 或
application.yml 文件中添加以下配置:# Redis 服务器地址 spring.redis.host=localhost # Redis 服务器端口 spring.redis.port=6379 # 缓存的默认失效时间,单位秒 spring.cache.redis.time-to-live=600 -
上述配置中的 spring.cache.redis.time-to-live
表示缓存的默认失效时间为600秒(10分钟)。这个值会应用于所有通过 @Cacheable、@CachePut 注解配置的缓存。在 Java 配置中设置 Redis 缓存失效时间: 如果你使用 Java 配置类,可以在配置类中通过
RedisCacheConfiguration 来设置缓存的失效时间。以下是一个示例:java @Configuration @EnableCaching public class CacheConfigextends CachingConfigurerSupport {@Beanpublic RedisCacheManager cacheManager(RedisConnectionFactory connectionFactory) {RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofSeconds(600)); // 设置缓存失效时间为600秒(10分钟)return RedisCacheManager.builder(connectionFactory).cacheDefaults(config).build();} }在上述配置中,
entryTtl(Duration.ofSeconds(600))表示设置缓存的失效时间为600秒。这个值同样会应用于所有通过 @Cacheable、@CachePut 注解配置的缓存。
根据具体的需求,你可以根据缓存的特定性配置不同的失效时间。上述示例中仅作为演示,实际应用中可以根据业务需求来设置合适的缓存失效时间。
相关文章:

【SpringCache】SpringCache详解及其使用,Redis控制失效时间
一、使用 在 Spring 中,使用缓存通常涉及以下步骤: 1、添加缓存依赖: 确保项目中添加了缓存相关的依赖。如果使用 Maven,可以在项目的 pom.xml 文件中添加 Spring Cache 的依赖。 <dependency><groupId>org.spring…...

MyBatis的基本使用及常见问题
MyBatis 前言MyBatis简介MyBatis快速上手Mapper代理开发增删改查环境准备配置文件完成增删改查查询添加修改删除 参数传递注解完成增删改查 前言 JavaWeb JavaWeb是用Java技术来解决相关Web互联网领域的技术栈。 MySQL数据库与SQL语言 MySQL:开源的中小型数据库。…...

[RoarCTF2019] TankGame
不多说,用dnspy反编译data文件夹中的Assembly-CSharp文件 使用分析器分析一下可疑的FlagText 发现其在WinGame中被调用,跟进WinGame函数 public static void WinGame(){if (!MapManager.winGame && (MapManager.nDestroyNum 4 || MapManager.n…...

相比于其他流处理技术,Flink的优点在哪?
Apache Flink 是一个开源的流处理框架,用于在高吞吐量和低延迟的情况下进行大规模数据流的处理。Flink 以其在流处理领域的性能而闻名,相比于其他流处理技术,Flink 提供了一些独特的特性和优化,使其在某些情况下更快。以下是 Flin…...

react中使用ref属性获取元素,并判断该元素内是否含有子元素
在react中,可以使用ref属性来获取到一个元素的引用,然后再使用ref.current来访问该元素的DOM节点,使用DOM API来判断这个元素是否含有子元素,要判断一个元素是否含有子元素,可以使用hasChildNodes(),其返回…...
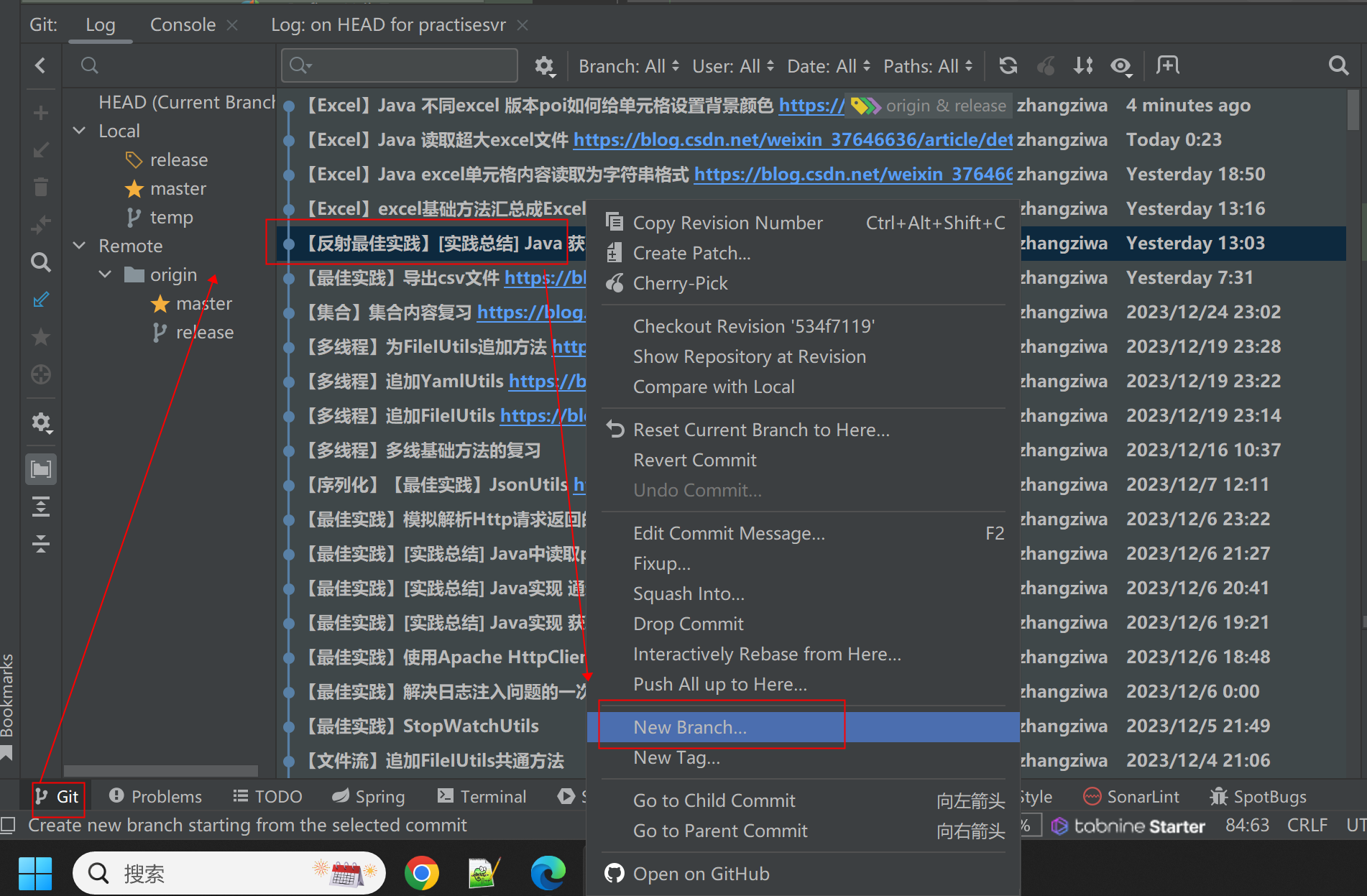
idea 如何快速拉取新分支
方式1 (快捷键:CtrlShift~) 方式2:(快捷键:Alt9)...

【经验分享】日常开发中的故障排查经验分享(一)
目录 简介CPU飙高问题1、使用JVM命令排查CPU飙升100%问题2、使用Arthas的方式定位CPU飙升问题3、Java项目导致CPU飙升的原因有哪些?如何解决? OOM问题(内存溢出)1、如何定位OOM问题?2、OOM问题产生原因 死锁问题的定位…...
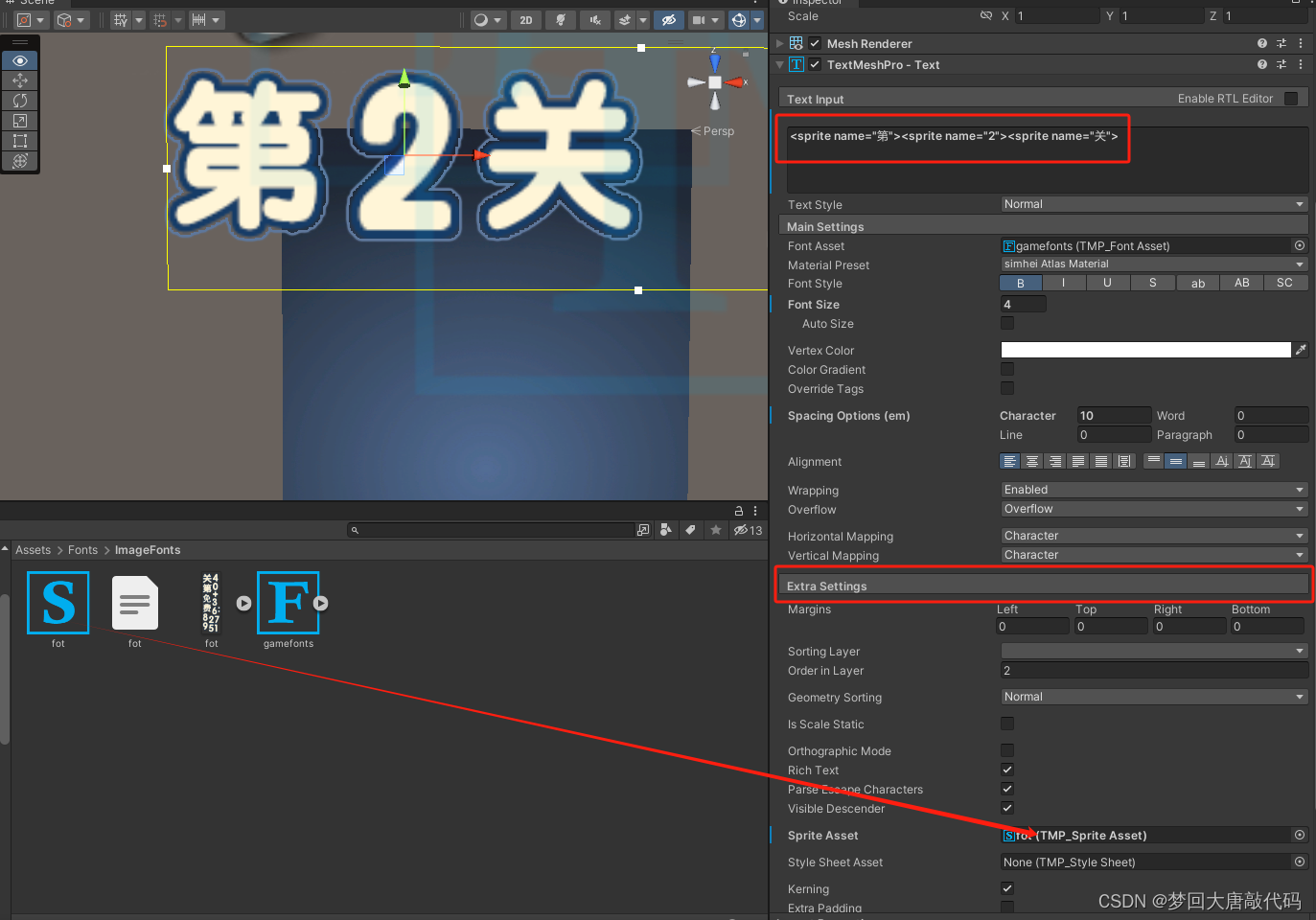
关于Unity使用图片字体示例
1.使用TexturePacker打包图集 下载地址 TexturePacker - Create Sprite Sheets for your game! 2.准备好数字图 3. 导入图片 4. 打包图集需要的设置 将重心点设置为左下方 点击回车 > 后点击回 >到精灵列表 选择导出的格式 导出后的内容 >导入unity 导入 >…...

开源大语言模型简记
文章目录 开源大模型LlamaChinese-LLaMA-AlpacaLlama2-ChineseLinlyYaYiChatGLMtransformersGPT-3(未完全开源)BERTT5QwenBELLEMossBaichuan其他...

python高级代码
目录 列表推导式和生成器表达式:使用简洁的语法来生成列表和生成器。 装饰器:用于修改函数行为的函数。 上下文管理器:用于管理资源的对象,可以使用with语句来自动管理资源的分配和释放。 多线程和多进程编程:使用…...
透彻掌握GIT基础使用
网址 https://learngitbranching.js.org/?localezh_CN 清屏 clear重新开始reset...

二、类与对象(三)
17 初始化列表 17.1 初始化列表的引入 之前我们给成员进行初始化时,采用的是下面的这种方式: class Date { public:Date(int year, int month, int day)//构造函数{_year year;_month month;_day day;} private:int _year;int _month;int _day; };…...
CentOS 7 Tomcat服务的安装
前提 安装java https://blog.csdn.net/qq_36940806/article/details/134945175?spm1001.2014.3001.5501 1. 下载 wget https://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-9/v9.0.84/bin/apache-tomcat-9.0.84.tar.gzps: 可选择自己需要的版本下载安装https://mir…...
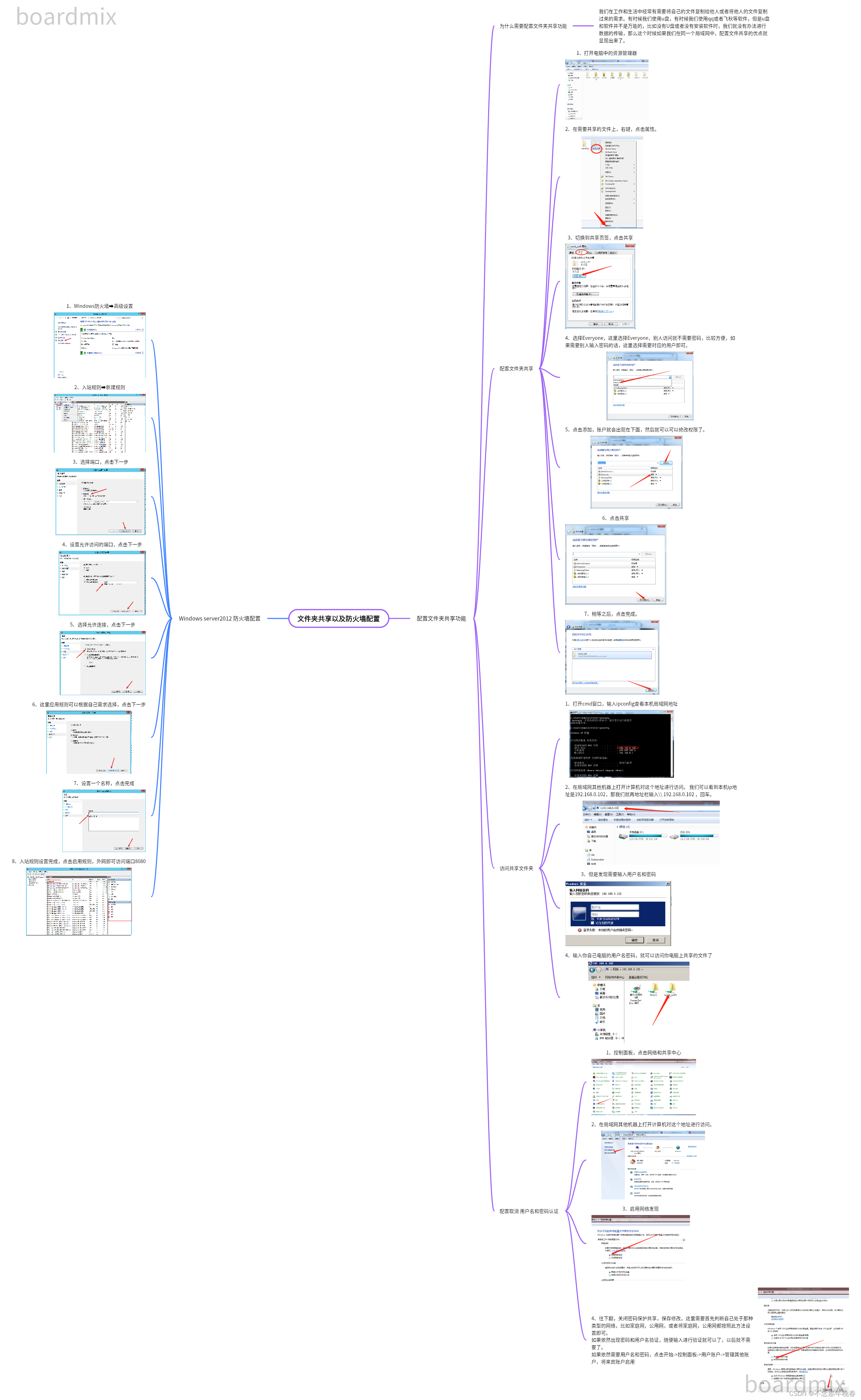
文件夹共享功能的配置 以及Windows server2012防火墙的配置
目录 一. 配置文件夹共享功能 1.1 为什么需要配置文件夹共享功能 1.2 配置文件夹共享 1.3 访问共享文件夹 1.4 配置取消 用户名和密码认证 二. windows server 2012防火墙配置 思维导图 一. 配置文件夹共享功能 1.1 为什么需要配置文件夹共享功能 我们在工作和生活中经…...

前端使用高德api的AMap.Autocomplete无效,使用AMap.Autocomplete报错
今天需要一个坐标拾取器,需要一个输入框输入模糊地址能筛选的功能 查看官方文档,有一个api可以直接满足我们的需求 AMap.Autocomplete 上代码 AMapLoader.load({"key": "你的key", // 申请好的Web端开发者Key,首次调…...

反转链表、链表的中间结点、合并两个有序链表(leetcode 一题多解)
一、反转链表 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 思路一:翻转单链表指针方向 这里解释一下三个指针的作用: n1࿱…...
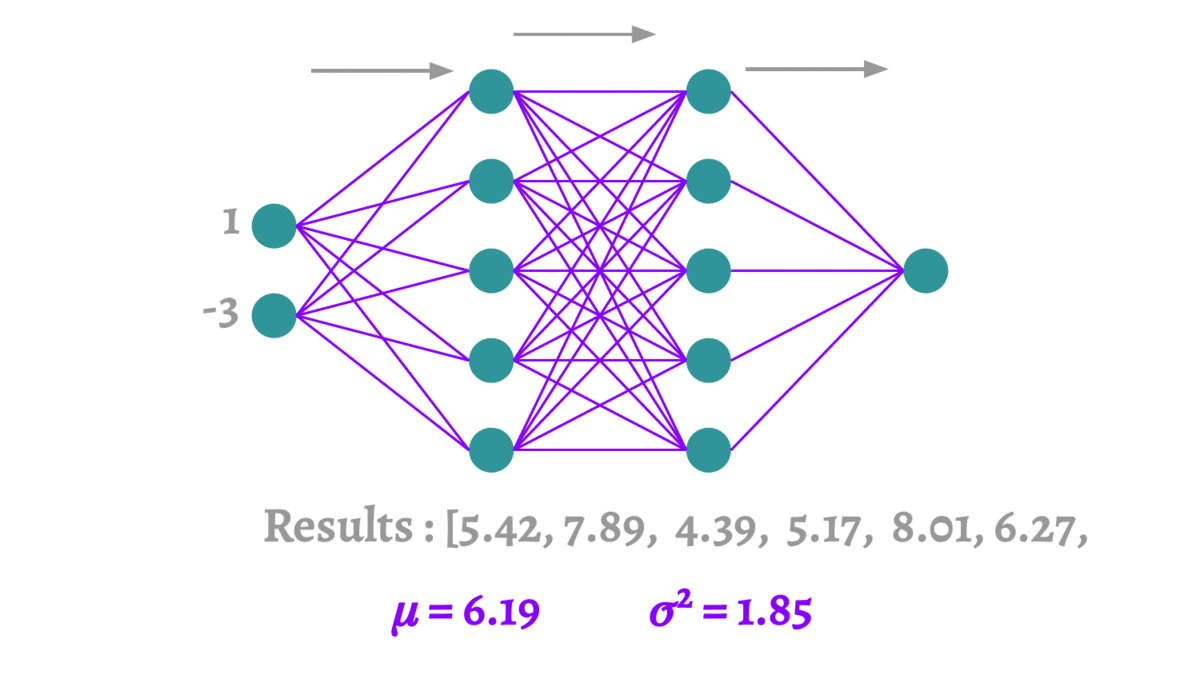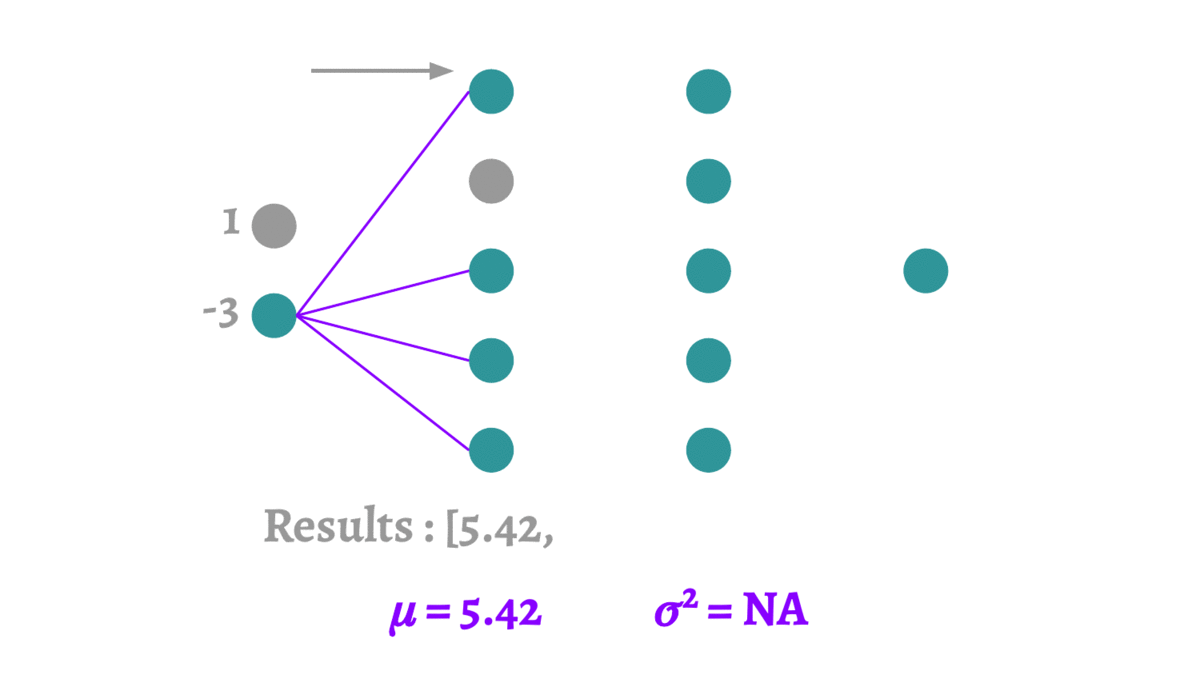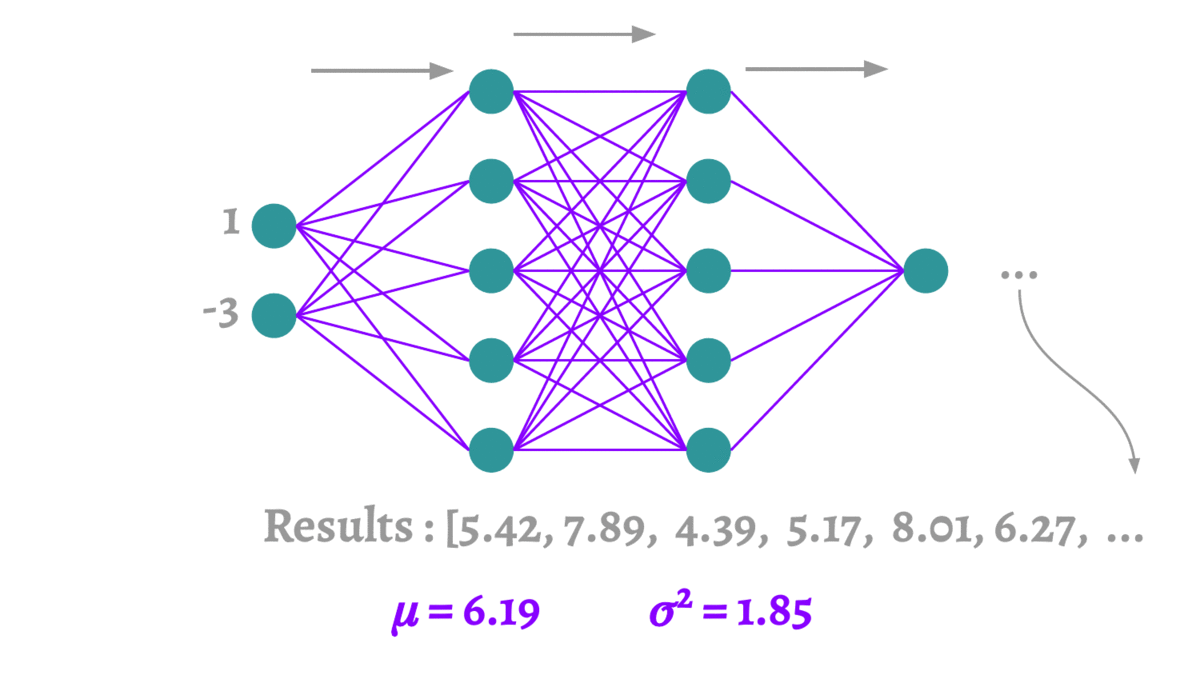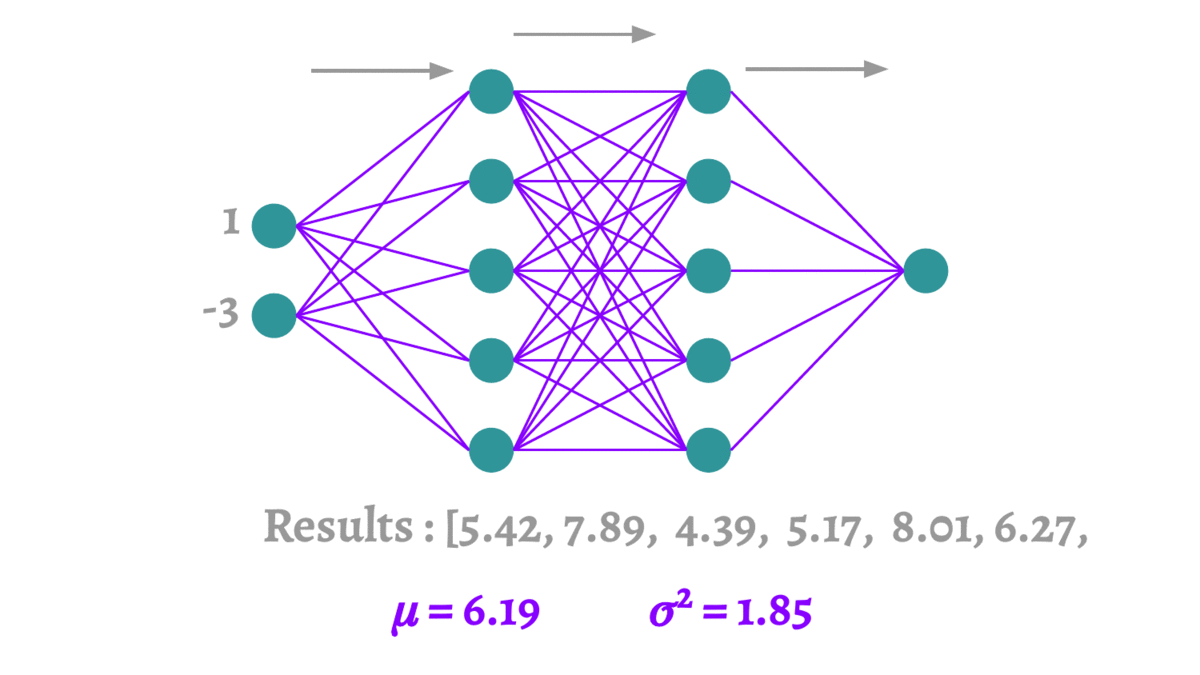
深度学习中的Dropout
1 Dropout概述 1.1 什么是Dropout 在2012年,Hinton在其论文《Improving neural networks by preventing co-adaptation of feature detectors》中提出Dropout。当一个复杂的前馈神经网络被训练在小的数据集时,容易造成过拟合。为了防止过拟合ÿ…...

MySQL 中的 ibdata1 文件过大如何处理?
ibdata1 是什么文件? ibdata1 是InnoDB的共有表空间,默认情况下会把表空间存放在一个名叫 ibdata1的文件中,日积月累会使该文件越来越大。 ibdata1 文件过大的解决办法 使用独享表空间,将表空间分别单独存放。MySQL开启独享表空…...

Weblogic反序列化远程命令执行(CVE-2019-2725)
漏洞描述: CVE-2019-2725是一个Oracle weblogic反序列化远程命令执行漏洞,这个漏洞依旧是根据weblogic的xmldecoder反序列化漏洞,通过针对Oracle官网历年来的补丁构造payload来绕过。 复现过程: 1.访问ip:port 2.可…...

鸿蒙组件数据传递:ui传递、@prop、@link
鸿蒙组件数据传递方式有很多种,下面详细罗列一下: 注意: 文章内名词解释: 正向:父变子也变 逆向:子变父也变 **第一种:直接传递 - 特点:1、任何数据类型都可以传递 2、不能响应式…...

QWEN-AUDIO与其他AI工具共存:如何合理分配GPU资源?
QWEN-AUDIO与其他AI工具共存:如何合理分配GPU资源? 1. 多AI工具共存的挑战与解决方案 在当前的AI应用场景中,单一GPU服务器往往需要同时运行多个AI模型。QWEN-AUDIO作为一款高性能语音合成系统,如何与其他视觉、语言模型和谐共存…...

nix 项目贡献指南:从代码提交到发布的完整流程
nix 项目贡献指南:从代码提交到发布的完整流程 【免费下载链接】nix Rust friendly bindings to *nix APIs 项目地址: https://gitcode.com/gh_mirrors/nix/nix nix 是一个为 Rust 开发者提供友好的 *nix 系统 API 绑定的开源项目。本指南将带你了解从发现问…...

OpenClaw v2026.4.1 深度剖析报告:任务系统、协作生态与安全范式的全面跃迁
摘要本报告旨在对 OpenClaw 于 2026 年 4 月 2 日发布的 v2026.4.1 版本进行一次全面、深入、颗粒度至极的技术与战略解构。该版本由 30 余位社区贡献者共同完成,标志着 OpenClaw 在经历了 3 月份“架构重塑”与“安全加固”的底层革命后,正式迈入“体验…...

小杰云商城系统源码/小程序源码平台/电商系统源码/完整版/全开源
小杰云商城系统源码 完整版 全开源 基于多款经典商城深度优化重构,不管是功能、颜值、安全、流畅度,直接给你干到天花板! 完美适配易支付V2和mapi支付,拿到手简单配置就能上线运营,不用你再费劲改接口! 功能多到爆炸࿰…...
)
Qwen3.5-9B部署教程:CentOS 7兼容方案(glibc升级+systemd服务模板)
Qwen3.5-9B部署教程:CentOS 7兼容方案(glibc升级systemd服务模板) 1. 项目概述 Qwen3.5-9B是一款拥有90亿参数的开源大语言模型,具备强大的逻辑推理、代码生成和多轮对话能力。该模型支持多模态理解(图文输入&#x…...

墨语灵犀网络安全知识库:基于AI的威胁情报分析与解读
墨语灵犀网络安全知识库:让AI成为你的安全分析师 最近和几个做安全运营的朋友聊天,他们都在抱怨同一件事:每天面对海量的安全告警和晦涩的漏洞报告,眼睛都快看花了。一份新的漏洞描述扔过来,光是理解它到底在说什么、…...

万象视界灵坛实操手册:使用Prometheus+Grafana监控CLIP推理延迟、GPU利用率、QPS指标
万象视界灵坛实操手册:使用PrometheusGrafana监控CLIP推理延迟、GPU利用率、QPS指标 1. 监控系统概述 在现代AI应用部署中,实时监控系统性能指标是确保服务稳定运行的关键。对于万象视界灵坛这样的多模态智能感知平台,我们需要重点关注三个…...

Qwen3.5-9B企业应用:法务合同关键条款提取+风险点标注案例
Qwen3.5-9B企业应用:法务合同关键条款提取风险点标注案例 1. 项目背景与价值 在法务工作中,合同审查是一项耗时且容易出错的任务。传统的人工审查方式需要律师逐条阅读合同文本,识别关键条款并标注潜在风险点,这个过程通常需要数…...

复古计算机复兴:OpenClaw+Qwen3-14B驱动命令行工作流
复古计算机复兴:OpenClawQwen3-14B驱动命令行工作流 1. 当AI遇见Unix哲学 我的书桌上至今保留着一台1984年的IBM PC/AT,那厚重的机械键盘和闪烁的绿色光标总能唤起某种仪式感。最近在调试OpenClaw对接Qwen3-14B时,突然意识到:我…...
)
Python数据分析实战:用Seaborn绘制炫酷相关性热力图(附完整代码)
Python数据分析实战:用Seaborn绘制炫酷相关性热力图 数据分析工作中,相关性分析是理解变量间关系的核心技能。而热力图作为直观展示相关性的工具,已经成为数据科学家和商业分析师的标准配置。本文将带你从零开始,掌握用Seaborn绘…...