elasticsearch系列七:聚合查询
概述
今天咱们来看下es中的聚合查询,在es中聚合查询分为三大类bucket、metrics、pipeline,每一大类下又有十几种小类,咱们各举例集中,有兴许的同学可以参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.10/search-aggregations.html 本次基于es7.10.2版本编写。
metics聚合
常用指标类的聚合无外乎这几种:Avg、Min、Max、Sum、Cardinality、Percentile ranks。咱们来看下具体语法:
Avg、Min、Max、Sum这几个雷同只需要换函数名即可,假如我们有一个日志索引,其索引mapping如下:
{"mappings": {"properties": {"routePath": {"type":"keyword"},"serverCode": {"type":"keyword"},"taskTime": {"type":"long"},"reuqestMsg": {"type":"text"},"responseMsg": {"type":"text"}}}}
我们想看下近一月的接口某接口平均耗时、最小耗时、最大耗时等指标,此时dsl可以如下编写:
GET /log-2023-02/_serach{"size": 0,"query": {"bool": {"filter": [{"term": {"routePath": "/user/getUserInfo"}}]}},"aggs": {"avg": {"avg": {"field": "taskTime"}}}}
返回结果:

咱们看下如何去重,根据接口地址去重查询:
{"size": 0,"aggs": {"cardinality": {"cardinality": {"field": "routePath"}}}}

只是这个cardinality有误差,它底层采用的是HyperLogLog的算法,通过计算数据的hash值来去重所以有误差,百万数据误差在5%以内,我们可以通过precision_threshold参数去调整最大支持4万,该值越大耗费内存也就越大如果数据总量在4万以内那么调整到最大值可以保证100%正确。
接下来咱们看Percentile ranks这个也是比较常用的聚合分析函数他的结果也是有误差的但是不影响我们分析整体情况,比如我们需要计算整体系统的性能可以这样搞:查询接口再响应这些耗时上的百分比就可以通过如下语句
{"size": 0,"aggs": {"rate": {"percentile_ranks": {"field": "taskTime","values": [20,40,50,60]}}}}
结果:

bucket聚合
桶聚合中我们常用的有分组、直方图、范围、根据日期分桶聚合这几类,咱们先看下分组查询(terms)举例我们想统计下各个接口调用量情况:
{"size": 0,"aggs": {"term": {"terms": {"field": "routePath"}}}
返回结果:
"aggregations": {"term": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "/user/getUserInfo","doc_count": 5},{"key": "/user/addUser","doc_count": 1},{"key": "/user/updateMobile","doc_count": 1},{"key": "/user/updateUser","doc_count": 1}]}}
咱们再看直方图的查询统计接口耗时、间隔为1:
{"size": 0,"aggs": {"histogram": {"histogram": {"field": "taskTime","interval": 1}}}}
结果
"aggregations": {"histogram": {"buckets": [{"key": 20.0,"doc_count": 2},{"key": 21.0,"doc_count": 0},{"key": 22.0,"doc_count": 0}]}}
根据日期统计各接口调用情况,用直方图实行展现:
{"size": 0,"aggs": {"date_histogram": {"date_histogram": {"field": "requestTime","interval": "day"}}}}
查询结果:
"aggregations": {"histogram": {"buckets": [{"key_as_string": "2023-02-01T00:00:00.000Z","key": 1675209600000,"doc_count": 1},{"key_as_string": "2023-02-02T00:00:00.000Z","key": 1675296000000,"doc_count": 1},{"key_as_string": "2023-02-03T00:00:00.000Z","key": 1675382400000,"doc_count": 1}]}}
pipeline聚合
它其实是对bucket聚合的结果再次进行聚合分期,数据准备:
{ "create" : { "_index" : "employees" } }
{ "name" : "Emma","age":32,"job":"Product Manager","gender":"female","salary":35000 }
{ "create" : { "_index" : "employees" } }
{ "name" : "Underwood","age":41,"job":"Dev Manager","gender":"male","salary": 50000}
{ "create" : { "_index" : "employees" } }
{ "name" : "Tran","age":25,"job":"Web Designer","gender":"male","salary":18000 }
{ "create" : { "_index" : "employees" } }
{ "name" : "Rivera","age":26,"job":"Web Designer","gender":"female","salary": 22000}
{ "create" : { "_index" : "employees" } }
{ "name" : "Rose","age":25,"job":"QA","gender":"female","salary":18000 }
{ "create" : { "_index" : "employees" } }
{ "name" : "Lucy","age":31,"job":"QA","gender":"female","salary": 25000}
{ "create" : { "_index" : "employees" } }
{ "name" : "Byrd","age":27,"job":"QA","gender":"male","salary":20000 }
{ "create" : { "_index" : "employees" } }
{ "name" : "Foster","age":27,"job":"Java Programmer","gender":"male","salary": 20000}
{ "create" : { "_index" : "employees" } }
{ "name" : "Gregory","age":32,"job":"Java Programmer","gender":"male","salary":22000 }
{ "create" : { "_index" : "employees" } }
{ "name" : "Bryant","age":20,"job":"Java Programmer","gender":"male","salary": 9000}
{ "create" : { "_index" : "employees" } }
{ "name" : "Jenny","age":36,"job":"Java Programmer","gender":"female","salary":38000 }
{ "create" : { "_index" : "employees" } }
{ "name" : "Mcdonald","age":31,"job":"Java Programmer","gender":"male","salary": 32000}
{ "create" : { "_index" : "employees" } }
{ "name" : "Jonthna","age":30,"job":"Java Programmer","gender":"female","salary":30000 }
{ "create" : { "_index" : "employees" } }
{ "name" : "Marshall","age":32,"job":"Javascript Programmer","gender":"male","salary": 25000}
{ "create" : { "_index" : "employees" } }
{ "name" : "King","age":33,"job":"Java Programmer","gender":"male","salary":28000 }
{ "create" : { "_index" : "employees" } }
{ "name" : "Mccarthy","age":21,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "create" : { "_index" : "employees" } }
{ "name" : "Goodwin","age":25,"job":"Javascript Programmer","gender":"male","salary": 16000}
{ "create" : { "_index" : "employees" } }
{ "name" : "Catherine","age":29,"job":"Javascript Programmer","gender":"female","salary": 20000}
{ "create" : { "_index" : "employees" } }
{ "name" : "Boone","age":30,"job":"DBA","gender":"male","salary": 30000}
{ "create" : { "_index" : "employees" } }
{ "name" : "Kathy","age":29,"job":"DBA","gender":"female","salary": 20000}我们根据以上数据想要查询平均薪资最低的行业:
{"size": 0,"aggs": {"jobs": {"terms": {"field": "job.keyword","size": 10},"aggs": {"avg_salary": {"avg": {"field": "salary"}}}},"min_salary_by_job":{"min_bucket": { #再次进行聚合查询 将jobs桶下的avg_salary求出最小值"buckets_path": "jobs>avg_salary"}}}}
结果如下:
"aggregations": {"jobs": {"doc_count_error_upper_bound": 0,"sum_other_doc_count": 0,"buckets": [{"key": "Java Programmer","doc_count": 7,"avg_salary": {"value": 25571.428571428572}},{"key": "Javascript Programmer","doc_count": 4,"avg_salary": {"value": 19250.0}},{"key": "DBA","doc_count": 2,"avg_salary": {"value": 25000.0}},{"key": "Product Manager","doc_count": 1,"avg_salary": {"value": 35000.0}}]},"min_salary_by_job": {"value": 19250.0,"keys": ["Javascript Programmer"]}}
还有将bucket结果再次进行平均 avg_bucket,bucket结果再次求最大的max_bucket,bucket结果再次求百分比的 percentiles_bucket等等。
总结
基本上咱们把常用的一些聚合查询都给大家演示了一遍,当然es本身支持的聚合查询远远不止这些,有兴趣的同学可以参考es官网的学习手册:https://www.elastic.co/guide/en/elasticsearch/reference/7.10/index.html 来探索更多的语法糖。
Elasticsearch系列经典文章
-
elasticsearch列一:索引模板的使用
-
elasticsearch系列二:引入索引模板后发现数据达到一定量还是慢怎么办?
-
elasticsearch系列三:常用查询语法
-
elasticsearch系列四:集群常规运维
-
elasticsearch系列五:集群的备份与恢复
-
elasticsearch系列六:索引重建

相关文章:
elasticsearch系列七:聚合查询
概述 今天咱们来看下es中的聚合查询,在es中聚合查询分为三大类bucket、metrics、pipeline,每一大类下又有十几种小类,咱们各举例集中,有兴许的同学可以参考官网:https://www.elastic.co/guide/en/elasticsearch/refere…...

SQL面试题挑战11:访问会话切割
目录 问题:SQL解答: 问题: 如下为某电商公司用户访问网站的数据,包括用户id和访问时间两个字段。现有如下规则:如果某个用户的连续的访问记录时间间隔小于60秒,则属于同一个会话,现在需要计算每…...
)
2023“楚怡杯”湖南省赛“信息安全管理与评估“--应急响应(高职组)
2023“楚怡杯”湖南省“信息安全管理与评估”(高职组)任务书 2023“楚怡杯”湖南省“信息安全管理与评估”(高职组)任务书第一阶段竞赛项目试题第二阶段竞赛项目试题网络安全事件响应:需要环境私聊博主:2023“楚怡杯”湖南省“信息安全管理与评估”(高职组)任务书 第一…...

【Python百宝箱】Python引领制造变革:CAM技术全景解析与实战指南
Python 驭技术潮流:探索计算机辅助制造的全方位工具库 前言 在当今制造业的快速发展中,计算机辅助制造(Computer-Aided Manufacturing,CAM)技术扮演着至关重要的角色。为了提高制造效率、优化工艺流程以及实现数字化…...

【新版Hi3559AV100 旗舰8K30 AI摄像机芯片】
新版Hi3559AV100 旗舰8K30 AI摄像机芯片 一、总体介绍 Hi3559AV100是专业的8K Ultra-HD Camera SOC,它提供了8K30/4K120广播级图像质量的数字视频录制,支持8路Sensor输入,支持H.265编码输出或影视级的RAW数据输出,并集成高性能ISP…...
)
小样本学习idea(不断更新)
在此整理并记录自己的思考过程,其中不乏有一些尚未成熟或者尚未实现的idea,也有一些idea实现之后没有效果或者正在实现,当然也有部分idea已写成论文正在投稿,都是自己的一些碎碎念念的思考,欢迎交流。 研一上学期 9.…...
表情包搜索网站
一个非常不错的表情包搜索网站,输入关键词即可得到所有相关的表情,还可以选择套图下载,自制表情,非常给力666 可以点击下载,会新建窗口打开图片,鼠标右键“图片另存为”,下载文件名手动补充“…...
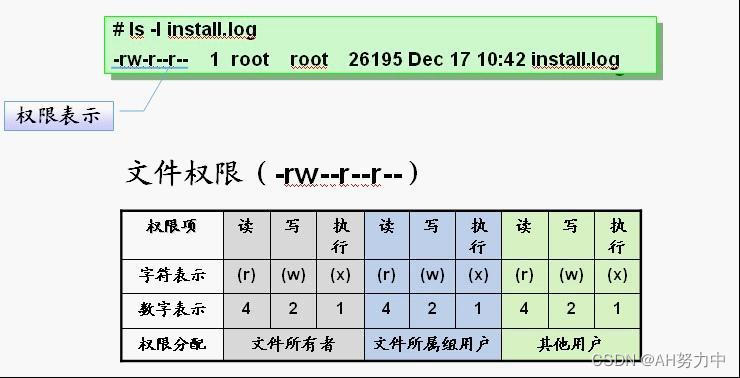
Linux账号和权限管理
目录 一、用户账号和组账号概述 1、用户账号类型 2、组账号 1.基本组(私有组) 2.附加组(公共组) 3、ID 1.UID 2.GID 4、用户和账号管理 1.文件位置 2.useradd-----创建用户 3.userdel——删除用户账号 4.usermod---修…...
)
Qt/QML编程学习之心得:QML和C++的相互调用(十五)
Qt下的QML说到底是类似于JavaScript的一种解释性语言,习惯了VC的MVC(Veiw+Control)的模式,那种界面视图任何事件都是和C++的cpp中处理函数一一对应,在类中也有明确的说明的。一下子玩Qt会觉得哪里对不上,比如使用QML这种节脚本语言贴了图做了layout布局,那么一个按钮的o…...
月入10.5K,专科小伙转行网优:据说每个领域都有一个“显眼包”
网络热词流行的今天,显眼包一词又上热搜。除了熟知的内娱显眼包外,其实各行业也都有自己的“显眼包”。 显眼包又叫“现眼包”看似丢人现眼,实则是个“褒义词”,他们勇敢自信,积极乐观,敢于展示自己&#x…...

Python自动化测试:选择最佳的自动化测试框架
在开始学习python自动化测试之前,先了解目前市场上的自动化测试框架有哪些? 随着技术的不断迭代更新,优胜劣汰也同样发展下来。从一开始工具型自动化,到现在的框架型;从一开始的能用,到现在的不仅能用&…...
Ubuntu16.04 安装Anaconda
步骤 1: 去官网下载安装包,链接如下: https://repo.anaconda.com/archive/ 找到对应版本下载至本地电脑,并上传至服务器。 步骤2: 通过命令解压 sh Anaconda3-2023.03-0-Linux-x86_64.sh 一路选择yes或则回车,直到安装成功出现下面画面&…...
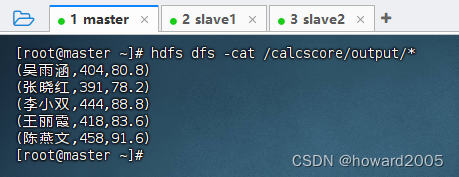
MR实战:统计总分与平均分
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据1、在虚拟机上创建文本文件2、上传文件到HDFS指定目录 (二)实现步骤1、创建Maven项目2、添加相关依赖3、创建日志属性文件4、创建成绩映射器类5、创建成绩驱动器类6、启…...
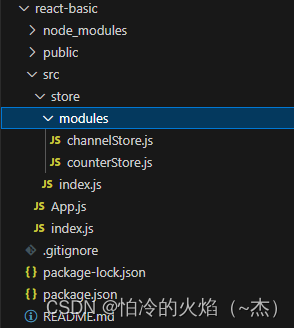
Redux与React环境准备、实现counter(及传参)、异步获取数据
环境说明: 一:说明 在React中使用redux,官方要求安装两个其他插件:Redux Toolkit和react-redux 1. Redux ToolKit(RTK) - 官方推荐编写Redux逻辑的方式,是一套工具的集合集,简化书写方式 (简化…...
网站服务器被入侵,如何排查,该如何预防入侵呢?
在我们日常使用服务器的过程中,当公司的网站服务器被黑客入侵时,导致整个网站以及业务系统瘫痪,将会给企业带来无法估量的损失。作为服务器的维护人员应当在第一时间做好安全响应,对入侵问题做到及时处理,以最快的时间…...

应用在网络摄像机领域中的国产音频ADC芯片
IPC:其实叫“网络摄像机”,是IP Camera的简称。它是在前一代模拟摄像机的基础上,集成了编码模块后的摄像机。它和模拟摄像机的区别,就是在新增的“编码模块”上。模拟摄像机,顾名思义,输出的是模拟视频信号…...
Unity3D 安装和下载指南及汉化
Unity3D是一款强大的游戏开发引擎,为开发者提供了丰富的工具和资源,使得游戏制作变得更加简单和高效。本文将介绍Unity3D的安装和下载步骤,以帮助初学者迅速入门。 步骤一:访问Unity官网 首先,打开浏览器,…...

【SpringCache】SpringCache详解及其使用,Redis控制失效时间
一、使用 在 Spring 中,使用缓存通常涉及以下步骤: 1、添加缓存依赖: 确保项目中添加了缓存相关的依赖。如果使用 Maven,可以在项目的 pom.xml 文件中添加 Spring Cache 的依赖。 <dependency><groupId>org.spring…...

MyBatis的基本使用及常见问题
MyBatis 前言MyBatis简介MyBatis快速上手Mapper代理开发增删改查环境准备配置文件完成增删改查查询添加修改删除 参数传递注解完成增删改查 前言 JavaWeb JavaWeb是用Java技术来解决相关Web互联网领域的技术栈。 MySQL数据库与SQL语言 MySQL:开源的中小型数据库。…...

[RoarCTF2019] TankGame
不多说,用dnspy反编译data文件夹中的Assembly-CSharp文件 使用分析器分析一下可疑的FlagText 发现其在WinGame中被调用,跟进WinGame函数 public static void WinGame(){if (!MapManager.winGame && (MapManager.nDestroyNum 4 || MapManager.n…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

P3 QT项目----记事本(3.8)
3.8 记事本项目总结 项目源码 1.main.cpp #include "widget.h" #include <QApplication> int main(int argc, char *argv[]) {QApplication a(argc, argv);Widget w;w.show();return a.exec(); } 2.widget.cpp #include "widget.h" #include &q…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

QT: `long long` 类型转换为 `QString` 2025.6.5
在 Qt 中,将 long long 类型转换为 QString 可以通过以下两种常用方法实现: 方法 1:使用 QString::number() 直接调用 QString 的静态方法 number(),将数值转换为字符串: long long value 1234567890123456789LL; …...

Python Ovito统计金刚石结构数量
大家好,我是小马老师。 本文介绍python ovito方法统计金刚石结构的方法。 Ovito Identify diamond structure命令可以识别和统计金刚石结构,但是无法直接输出结构的变化情况。 本文使用python调用ovito包的方法,可以持续统计各步的金刚石结构,具体代码如下: from ovito…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...
免费数学几何作图web平台
光锐软件免费数学工具,maths,数学制图,数学作图,几何作图,几何,AR开发,AR教育,增强现实,软件公司,XR,MR,VR,虚拟仿真,虚拟现实,混合现实,教育科技产品,职业模拟培训,高保真VR场景,结构互动课件,元宇宙http://xaglare.c…...

Vue ③-生命周期 || 脚手架
生命周期 思考:什么时候可以发送初始化渲染请求?(越早越好) 什么时候可以开始操作dom?(至少dom得渲染出来) Vue生命周期: 一个Vue实例从 创建 到 销毁 的整个过程。 生命周期四个…...