MR实战:统计总分与平均分
文章目录
- 一、实战概述
- 二、提出任务
- 三、完成任务
- (一)准备数据
- 1、在虚拟机上创建文本文件
- 2、上传文件到HDFS指定目录
- (二)实现步骤
- 1、创建Maven项目
- 2、添加相关依赖
- 3、创建日志属性文件
- 4、创建成绩映射器类
- 5、创建成绩驱动器类
- 6、启动应用,查看结果
- 7、创建成绩归并器类
- 8、修改成绩驱动器类
- 9、启动应用,查看结果
一、实战概述
- 在本次实战中,我们将利用Apache Hadoop的MapReduce框架来计算一个包含五名学生五门科目成绩的数据集的总分和平均分。我们将通过以下步骤实现这一目标:首先,在虚拟机上创建并准备数据,将成绩表以文本文件形式存储并在HDFS上设定输入目录;然后,使用IntelliJ IDEA创建Maven项目,并添加必要的Hadoop和JUnit依赖;接着,我们将实现ScoreMapper和ScoreReducer类,分别负责处理输入数据和计算总分与平均分;在ScoreDriver类中,我们将配置作业并运行MapReduce任务。最后,我们将通过HDFS Shell命令查看结果文件内容。此实战旨在深入理解并掌握MapReduce在处理和分析学生成绩数据中的应用,展现其强大的分布式计算能力。
二、提出任务
- 成绩表,包含六个字段(姓名、语文、数学、英语、物理、化学),有五条记录
| 姓名 | 语文 | 数学 | 英语 | 物理 | 化学 |
|---|---|---|---|---|---|
| 李小双 | 89 | 78 | 94 | 96 | 87 |
| 王丽霞 | 94 | 80 | 86 | 78 | 80 |
| 吴雨涵 | 90 | 67 | 95 | 92 | 60 |
| 张晓红 | 87 | 76 | 90 | 79 | 59 |
| 陈燕文 | 97 | 95 | 92 | 88 | 86 |
- 利用MR框架,计算每个同学的总分与平均分

三、完成任务
(一)准备数据
1、在虚拟机上创建文本文件
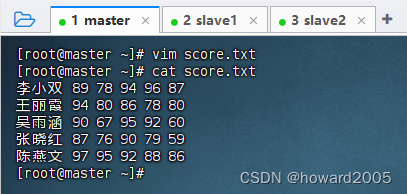
- 在master虚拟机上创建
score.txt文件
2、上传文件到HDFS指定目录
-
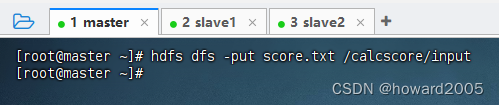
创建
/calcscore/input目录,执行命令:hdfs dfs -mkdir -p /calcscore/input

-
将文本文件
score.txt上传到HDFS的/calcscore/input目录
(二)实现步骤
- 说明:集成开发环境IntelliJ IDEA版本 -
2022.3
1、创建Maven项目
- Maven项目 -
MRCalcScore,设置了JDK版本 -1.8,组标识 -net.huawei.mr

- 单击【Create】按钮,得到初始化项目
2、添加相关依赖
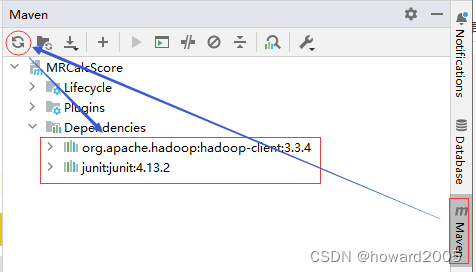
- 在
pom.xml文件里添加hadoop和junit依赖

<dependencies> <!--hadoop客户端--> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.4</version> </dependency> <!--单元测试框架--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.13.2</version> </dependency>
</dependencies>
- 刷新项目依赖
3、创建日志属性文件
- 在
resources目录里创建log4j.properties文件

log4j.rootLogger=ERROR, stdout, logfile
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/calcscore.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
4、创建成绩映射器类
- 创建
net.huawei.mr包,在包里创建ScoreMapper类
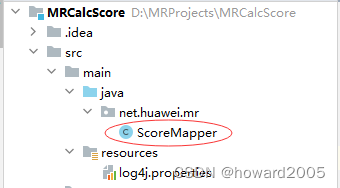
package net.huawei.mr;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** 功能:成绩映射器* 作者:华卫* 日期:2023年12月29日*/
public class ScoreMapper extends Mapper<LongWritable, Text, Text, IntWritable> {@Overrideprotected void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {// 获取行数据String line = value.toString();// 按空格拆分,得到字段数组String[] fields = line.split(" ");// 获取姓名String name = fields[0];// 遍历各科成绩for (int i = 1; i < fields.length; i++) {// 获取成绩int score = Integer.parseInt(fields[i]);// 将<姓名,成绩>键值对写入中间结果context.write(new Text(name), new IntWritable(score)); }}
}
- 说明:该Java类ScoreMapper继承自Hadoop MapReduce的Mapper,用于处理文本格式学生成绩数据。在map方法中,它首先读取一行输入数据并按空格拆分成字段数组,其中姓名为第一个字段。然后遍历剩余字段(各科成绩),将每门课程的成绩与姓名组合成<姓名, 成绩>键值对,并通过context.write写入到中间结果中。
5、创建成绩驱动器类
- 在
net.huawei.mr包里创建ScoreDriver类
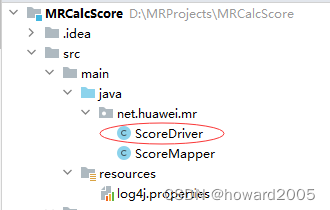
package net.huawei.mr;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.net.URI;/*** 功能:成绩驱动器类* 作者:华卫* 日期:2023年12月29日*/
public class ScoreDriver {public static void main(String[] args) throws Exception {// 创建配置对象Configuration conf = new Configuration();// 设置客户端使用数据节点主机名属性conf.set("dfs.client.use.datanode.hostname", "true");// 获取作业实例Job job = Job.getInstance(conf);// 设置作业启动类job.setJarByClass(ScoreDriver.class);// 设置Mapper类job.setMapperClass(ScoreMapper.class);// 设置map任务输出键类型job.setMapOutputKeyClass(Text.class);// 设置map任务输出值类型job.setMapOutputValueClass(IntWritable.class); // 定义uri字符串String uri = "hdfs://master:9000";// 创建输入目录Path inputPath = new Path(uri + "/calcscore/input");// 创建输出目录Path outputPath = new Path(uri + "/calcscore/output");// 获取文件系统FileSystem fs = FileSystem.get(new URI(uri), conf);// 删除输出目录(第二个参数设置是否递归)fs.delete(outputPath, true);// 给作业添加输入目录(允许多个)FileInputFormat.addInputPath(job, inputPath);// 给作业设置输出目录(只能一个)FileOutputFormat.setOutputPath(job, outputPath);// 等待作业完成job.waitForCompletion(true);// 输出统计结果System.out.println("======统计结果======");FileStatus[] fileStatuses = fs.listStatus(outputPath);for (int i = 1; i < fileStatuses.length; i++) {// 输出结果文件路径System.out.println(fileStatuses[i].getPath());// 获取文件系统数据字节输入流FSDataInputStream in = fs.open(fileStatuses[i].getPath());// 将结果文件显示在控制台IOUtils.copyBytes(in, System.out, 4096, false);}}
}
- 说明:该Java类ScoreDriver是Hadoop MapReduce作业的主驱动类,用于启动和监控整个计算流程。首先,它配置作业属性、设置Mapper类、输入输出格式及路径,并从HDFS读取数据。作业完成后,它遍历输出目录下的结果文件,逐个打开并打印至控制台,实现成绩统计任务的执行与结果显示。
6、启动应用,查看结果
- 运行
ScoreDriver类,会看到两列,一列姓名,一列成绩

7、创建成绩归并器类
- 在
net.huawei.mr包里创建ScoreReducer类

package net.huawei.mr;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;
import java.text.DecimalFormat;/*** 功能:成绩归并器类* 作者:华卫* 日期:2023年12月29日*/
public class ScoreReducer extends Reducer<Text, IntWritable, Text, NullWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context)throws IOException, InterruptedException {// 声明科目数、总分和平均分变量int count = 0;int sum = 0;double avg = 0;// 遍历迭代器计算总分for (IntWritable value : values) {count++; // 科目数累加sum = sum + value.get(); // 累加每科成绩}// 计算平均分avg = sum * 1.0 / count;// 创建小数点格式对象(保留一位小数)DecimalFormat df = new DecimalFormat("#.#");// 拼接每个学生总分与平均分成绩信息String scoreInfo = "(" + key + "," + new IntWritable(sum) + "," + df.format(avg) + ")";// 写入键值对<scoreInfo,null>context.write(new Text(scoreInfo), NullWritable.get());}
}
- 说明:该Java类ScoreReducer继承自Hadoop MapReduce的Reducer,用于计算每个学生各科成绩总分与平均分。在reduce方法中,遍历输入的<姓名, 成绩>对,累加科目数和总分,计算平均分,并格式化输出结果(保留一位小数)。最后将拼接好的成绩信息作为键,写入null值的键值对到输出文件。
8、修改成绩驱动器类
- 设置Reducer类及其输出键值类型
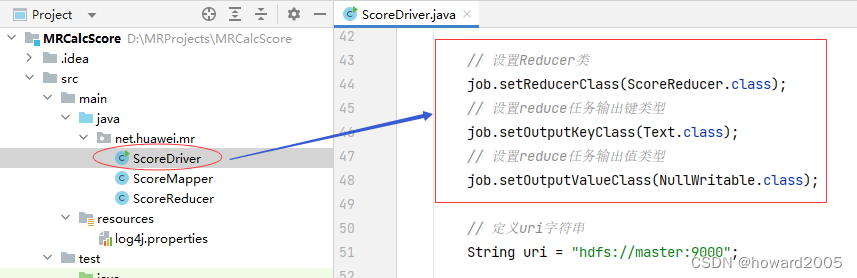
9、启动应用,查看结果
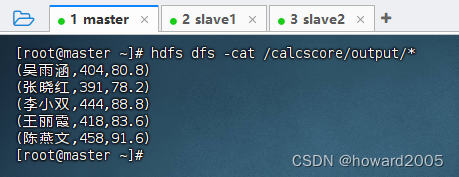
-
运行
ScoreDriver类,看到指定格式的成绩统计
-
利用HDFS Shell命令查看结果文件内容
相关文章:
MR实战:统计总分与平均分
文章目录 一、实战概述二、提出任务三、完成任务(一)准备数据1、在虚拟机上创建文本文件2、上传文件到HDFS指定目录 (二)实现步骤1、创建Maven项目2、添加相关依赖3、创建日志属性文件4、创建成绩映射器类5、创建成绩驱动器类6、启…...
Redux与React环境准备、实现counter(及传参)、异步获取数据
环境说明: 一:说明 在React中使用redux,官方要求安装两个其他插件:Redux Toolkit和react-redux 1. Redux ToolKit(RTK) - 官方推荐编写Redux逻辑的方式,是一套工具的集合集,简化书写方式 (简化…...
网站服务器被入侵,如何排查,该如何预防入侵呢?
在我们日常使用服务器的过程中,当公司的网站服务器被黑客入侵时,导致整个网站以及业务系统瘫痪,将会给企业带来无法估量的损失。作为服务器的维护人员应当在第一时间做好安全响应,对入侵问题做到及时处理,以最快的时间…...

应用在网络摄像机领域中的国产音频ADC芯片
IPC:其实叫“网络摄像机”,是IP Camera的简称。它是在前一代模拟摄像机的基础上,集成了编码模块后的摄像机。它和模拟摄像机的区别,就是在新增的“编码模块”上。模拟摄像机,顾名思义,输出的是模拟视频信号…...
Unity3D 安装和下载指南及汉化
Unity3D是一款强大的游戏开发引擎,为开发者提供了丰富的工具和资源,使得游戏制作变得更加简单和高效。本文将介绍Unity3D的安装和下载步骤,以帮助初学者迅速入门。 步骤一:访问Unity官网 首先,打开浏览器,…...

【SpringCache】SpringCache详解及其使用,Redis控制失效时间
一、使用 在 Spring 中,使用缓存通常涉及以下步骤: 1、添加缓存依赖: 确保项目中添加了缓存相关的依赖。如果使用 Maven,可以在项目的 pom.xml 文件中添加 Spring Cache 的依赖。 <dependency><groupId>org.spring…...

MyBatis的基本使用及常见问题
MyBatis 前言MyBatis简介MyBatis快速上手Mapper代理开发增删改查环境准备配置文件完成增删改查查询添加修改删除 参数传递注解完成增删改查 前言 JavaWeb JavaWeb是用Java技术来解决相关Web互联网领域的技术栈。 MySQL数据库与SQL语言 MySQL:开源的中小型数据库。…...

[RoarCTF2019] TankGame
不多说,用dnspy反编译data文件夹中的Assembly-CSharp文件 使用分析器分析一下可疑的FlagText 发现其在WinGame中被调用,跟进WinGame函数 public static void WinGame(){if (!MapManager.winGame && (MapManager.nDestroyNum 4 || MapManager.n…...

相比于其他流处理技术,Flink的优点在哪?
Apache Flink 是一个开源的流处理框架,用于在高吞吐量和低延迟的情况下进行大规模数据流的处理。Flink 以其在流处理领域的性能而闻名,相比于其他流处理技术,Flink 提供了一些独特的特性和优化,使其在某些情况下更快。以下是 Flin…...

react中使用ref属性获取元素,并判断该元素内是否含有子元素
在react中,可以使用ref属性来获取到一个元素的引用,然后再使用ref.current来访问该元素的DOM节点,使用DOM API来判断这个元素是否含有子元素,要判断一个元素是否含有子元素,可以使用hasChildNodes(),其返回…...
idea 如何快速拉取新分支
方式1 (快捷键:CtrlShift~) 方式2:(快捷键:Alt9)...

【经验分享】日常开发中的故障排查经验分享(一)
目录 简介CPU飙高问题1、使用JVM命令排查CPU飙升100%问题2、使用Arthas的方式定位CPU飙升问题3、Java项目导致CPU飙升的原因有哪些?如何解决? OOM问题(内存溢出)1、如何定位OOM问题?2、OOM问题产生原因 死锁问题的定位…...
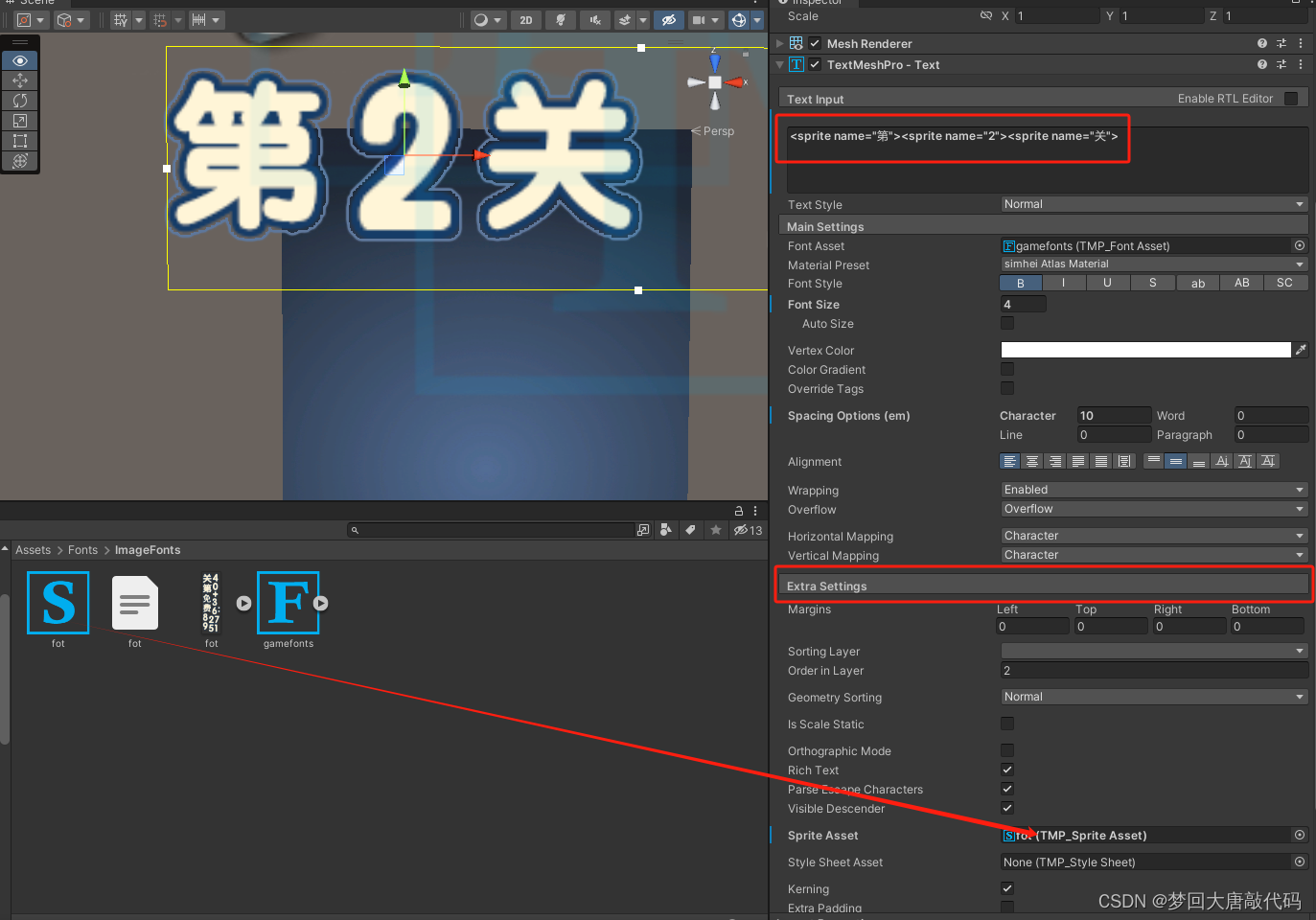
关于Unity使用图片字体示例
1.使用TexturePacker打包图集 下载地址 TexturePacker - Create Sprite Sheets for your game! 2.准备好数字图 3. 导入图片 4. 打包图集需要的设置 将重心点设置为左下方 点击回车 > 后点击回 >到精灵列表 选择导出的格式 导出后的内容 >导入unity 导入 >…...

开源大语言模型简记
文章目录 开源大模型LlamaChinese-LLaMA-AlpacaLlama2-ChineseLinlyYaYiChatGLMtransformersGPT-3(未完全开源)BERTT5QwenBELLEMossBaichuan其他...

python高级代码
目录 列表推导式和生成器表达式:使用简洁的语法来生成列表和生成器。 装饰器:用于修改函数行为的函数。 上下文管理器:用于管理资源的对象,可以使用with语句来自动管理资源的分配和释放。 多线程和多进程编程:使用…...
透彻掌握GIT基础使用
网址 https://learngitbranching.js.org/?localezh_CN 清屏 clear重新开始reset...

二、类与对象(三)
17 初始化列表 17.1 初始化列表的引入 之前我们给成员进行初始化时,采用的是下面的这种方式: class Date { public:Date(int year, int month, int day)//构造函数{_year year;_month month;_day day;} private:int _year;int _month;int _day; };…...
CentOS 7 Tomcat服务的安装
前提 安装java https://blog.csdn.net/qq_36940806/article/details/134945175?spm1001.2014.3001.5501 1. 下载 wget https://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-9/v9.0.84/bin/apache-tomcat-9.0.84.tar.gzps: 可选择自己需要的版本下载安装https://mir…...
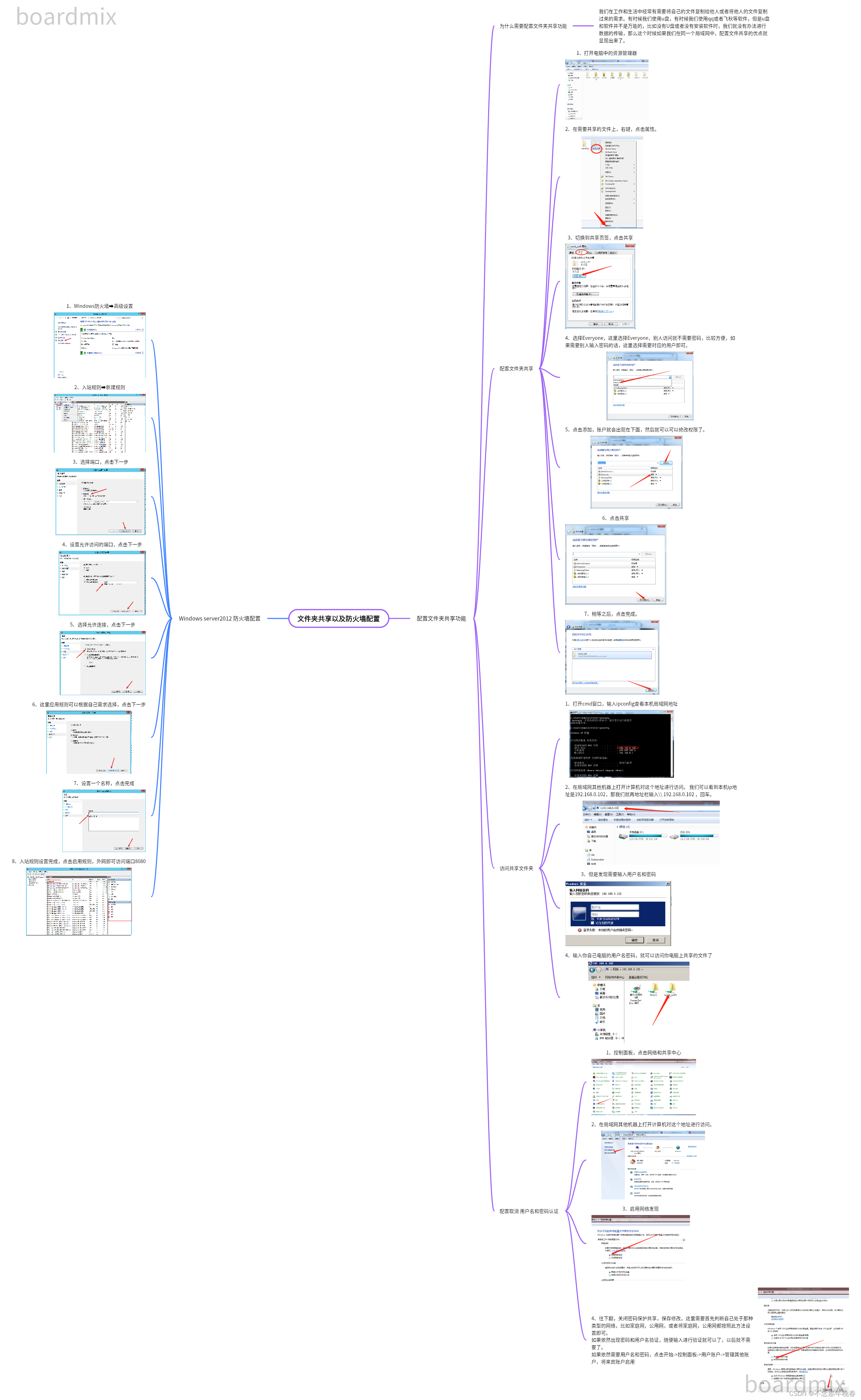
文件夹共享功能的配置 以及Windows server2012防火墙的配置
目录 一. 配置文件夹共享功能 1.1 为什么需要配置文件夹共享功能 1.2 配置文件夹共享 1.3 访问共享文件夹 1.4 配置取消 用户名和密码认证 二. windows server 2012防火墙配置 思维导图 一. 配置文件夹共享功能 1.1 为什么需要配置文件夹共享功能 我们在工作和生活中经…...

前端使用高德api的AMap.Autocomplete无效,使用AMap.Autocomplete报错
今天需要一个坐标拾取器,需要一个输入框输入模糊地址能筛选的功能 查看官方文档,有一个api可以直接满足我们的需求 AMap.Autocomplete 上代码 AMapLoader.load({"key": "你的key", // 申请好的Web端开发者Key,首次调…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...
)
Typeerror: cannot read properties of undefined (reading ‘XXX‘)
最近需要在离线机器上运行软件,所以得把软件用docker打包起来,大部分功能都没问题,出了一个奇怪的事情。同样的代码,在本机上用vscode可以运行起来,但是打包之后在docker里出现了问题。使用的是dialog组件,…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...