基于llama-index对embedding模型进行微调
QA对话目前是大语言模型的一大应用场景,在QA对话中,由于大语言模型信息的滞后性以及不包含业务知识的特点,我们经常需要外挂知识库来协助大模型解决一些问题。在外挂知识库的过程中,embedding模型的召回效果直接影响到大模型的回答效果,因此,在许多场景下,我们都需要微调我们的embedding模型来提高我们的召回效果。下面,我们就基于llama-index对BAAI/bge-base-zh-v1.5模型进行微调,关于该模型的介绍,可以参考https://huggingface.co/BAAI/bge-base-zh-v1.5。
平台介绍
对embedding模型进行微调的过程中需要使用GPU加速训练,由于家境贫寒,我这里就使用了Google colab提供的免费T4GPU进行微调测试。如果大家没办法使用这个,可以使用国内一些公司的GPU云平台,租便宜的GPU就行,微调这个模型所耗费的GPU资源不多。以下所有训练代码皆是在Jupter-notebook上编写并执行的。
依赖安装
安装一些依赖库,有些依赖需要制定版本,否则存在不兼容的问题。
!pip install langchain==0.0.300 llmx==0.0.15a0 openai==0.28.1 llama_index==0.8.23.post1 pypdf sentence-transformers
训练样本准备
我们当前的使用场景是QA问答场景,因此训练数据的格式最好也是问答的格式。我这里由于没有现成的问答样本(人工整理比较耗时),因此我就摘取了《明朝那些事儿》这个小说里面的部分章节,然后让GPT-3.5针对文章内容进行提问,从而形成问答对。代码如下
import json
import openai
import osfrom llama_index import SimpleDirectoryReader
from llama_index.node_parser import SimpleNodeParser
from llama_index.schema import MetadataMode
from llama_index import (VectorStoreIndex,SimpleDirectoryReader,ServiceContext,Response
)def load_corpus(docs, for_training=False, verbose=False):parser = SimpleNodeParser.from_defaults()if for_training:nodes = parser.get_nodes_from_documents(docs[:5], show_progress=verbose)else:nodes = parser.get_nodes_from_documents(docs[6:], show_progress=verbose)if verbose:print(f'Parsed {len(nodes)} nodes')return nodesSEC_FILE = ['embedding_test.txt'] # embedding_test.txt是我训练样本的文件名,即我摘取了部分小说章节并直接保存为了txt文件。print(f"Loading files {SEC_FILE}")reader = SimpleDirectoryReader(input_files=SEC_FILE)
docs = reader.load_data()
print(f'Loaded {len(docs)} docs')docs_nodes = load_corpus(docs, for_training=True, verbose=True)len(docs_nodes)train_nodes = docs_nodes[:75] # 人工选择3分之2作为训练集
print(f'Loaded {len(train_nodes)} train docs')
val_nodes = docs_nodes[76:] # 剩下三分之一作为验证集
print(f'Loaded {len(val_nodes)} val docs')
构造训练集和测试集
使用GPT3.5基于小说内容生成对应的问题,最后生成train_dataset.json作为训练集,val_dataset.json作为验证集。
from llama_index.finetuning import (generate_qa_embedding_pairs,EmbeddingQAFinetuneDataset,
)
from llama_index.llms import OpenAIos.environ["OPENAI_API_KEY"] = "sk-************"
openai.api_key = os.environ["OPENAI_API_KEY"]
openai.api_base = "https://************"prompt="""下方是上下文信息。---------------------
{context_str}
---------------------根据提供的上下文信息和没有先验知识的原则,仅基于以下查询生成问题。你是一名教师/教授。你的任务是为即将到来的测验/考试设置{num_questions_per_chunk}个问题。这些问题应在文档中多样化,且仅限于所提供的上下文信息。
"""train_dataset = generate_qa_embedding_pairs(train_nodes, qa_generate_prompt_tmpl=prompt)
val_dataset = generate_qa_embedding_pairs(val_nodes, qa_generate_prompt_tmpl=prompt)train_dataset.save_json("train_dataset.json")
val_dataset.save_json("val_dataset.json")
微调Embedding模型
这里的微调都是使用的默认参数,在实际微调过程中,可根据实际情况进行调整。
from llama_index.finetuning import SentenceTransformersFinetuneEngine
train_dataset = EmbeddingQAFinetuneDataset.from_json("train_dataset.json")
val_dataset = EmbeddingQAFinetuneDataset.from_json("val_dataset.json")
finetune_engine = SentenceTransformersFinetuneEngine(train_dataset,model_id="BAAI/bge-base-zh-v1.5",model_output_path="test_model",val_dataset=val_dataset,
)
finetune_engine.finetune() #由于模型较小,且训练样本较少,微调过程非常快
embed_model = finetune_engine.get_finetuned_model()
embed_model
评估微调后的模型
在评估阶段,我们对比了微调前、后的BAAI/bge-base-zh-v1.5模型以及OPENAI的ada002的Embedding模型的召回效果,代码如下:
from llama_index.embeddings import OpenAIEmbedding
from llama_index import ServiceContext, VectorStoreIndex
from llama_index.schema import TextNode
from tqdm.notebook import tqdm
import pandas as pd
def evaluate(dataset,embed_model,top_k=5,verbose=False,
):corpus = dataset.corpusqueries = dataset.queriesrelevant_docs = dataset.relevant_docsservice_context = ServiceContext.from_defaults(embed_model=embed_model)nodes = [TextNode(id_=id_, text=text) for id_, text in corpus.items()]index = VectorStoreIndex(nodes, service_context=service_context, show_progress=True)retriever = index.as_retriever(similarity_top_k=top_k)eval_results = []for query_id, query in tqdm(queries.items()):retrieved_nodes = retriever.retrieve(query)retrieved_ids = [node.node.node_id for node in retrieved_nodes]expected_id = relevant_docs[query_id][0]is_hit = expected_id in retrieved_ids # assume 1 relevant doceval_result = {"is_hit": is_hit,"retrieved": retrieved_ids,"expected": expected_id,"query": query_id,}eval_results.append(eval_result)return eval_results
注意,在执行下面的代码前,需要先在当前项目的目录下创建results文件夹,否则会导致程序执行失败。
from sentence_transformers.evaluation import InformationRetrievalEvaluator
from sentence_transformers import SentenceTransformerdef evaluate_st(dataset,model_id,name,
):corpus = dataset.corpusqueries = dataset.queriesrelevant_docs = dataset.relevant_docsevaluator = InformationRetrievalEvaluator(queries, corpus, relevant_docs, name=name)model = SentenceTransformer(model_id)return evaluator(model, output_path="results/")
OPENAI-ada002
ada = OpenAIEmbedding()
ada_val_results = evaluate(val_dataset, ada)
df_ada = pd.DataFrame(ada_val_results)
hit_rate_ada = df_ada['is_hit'].mean()
hit_rate_ada
ada002模型的最终评测结果为0.9285714285714286
原始BAAI/bge-base-zh-v1.5
bge = "local:BAAI/bge-base-zh-v1.5"
bge_val_results = evaluate(val_dataset, bge)
df_bge = pd.DataFrame(bge_val_results)
hit_rate_bge = df_bge['is_hit'].mean()
hit_rate_bge
原始的bge-base-zh-v1.5模型的评测结果为0.7663744588744589
微调后的BAAI/bge-base-zh-v1.5
finetuned = "local:test_model"
val_results_finetuned = evaluate(val_dataset, finetuned)
df_finetuned = pd.DataFrame(val_results_finetuned)
hit_rate_finetuned = df_finetuned['is_hit'].mean()
hit_rate_finetuned
微调后模型的最终评测结果为0.975。即微调后,我们的embedding模型在当前数据集的召回效果由0.766上升到0.975。注意,得分并不是越高越好,需考虑是否过拟合,可以在其他数据集上再评测下。
以上,即是一次简单的微调过程。感谢技术的发展和开源大佬们的贡献,使得人工智能的应用门槛越来越低。
参考资料:
- https://colab.research.google.com/github/wenqiglantz/nvidia-sec-finetuning/blob/main/embedding-finetuning/finetune_embedding_nvidia_sec.ipynb
相关文章:

基于llama-index对embedding模型进行微调
QA对话目前是大语言模型的一大应用场景,在QA对话中,由于大语言模型信息的滞后性以及不包含业务知识的特点,我们经常需要外挂知识库来协助大模型解决一些问题。在外挂知识库的过程中,embedding模型的召回效果直接影响到大模型的回答…...
如何本地搭建FastDFS文件服务器并实现远程访问【内网穿透】
文章目录 前言1. 本地搭建FastDFS文件系统1.1 环境安装1.2 安装libfastcommon1.3 安装FastDFS1.4 配置Tracker1.5 配置Storage1.6 测试上传下载1.7 与Nginx整合1.8 安装Nginx1.9 配置Nginx 2. 局域网测试访问FastDFS3. 安装cpolar内网穿透4. 配置公网访问地址5. 固定公网地址5.…...
----内部bean的引入(bean和bean之间的引入)、(3)级联方式注入)
spring基于Xml管理bean---Ioc依赖注入:对象类型属性赋值(2)----内部bean的引入(bean和bean之间的引入)、(3)级联方式注入
bean创建对象类型赋值方式 第一:外部bean的引入 第二:内部bean的引入 第三:级联属性赋值 文章目录 bean创建对象类型赋值方式对象类型内部bean赋值代码分析总结 对象类型属性级联方式的赋值扩展知识 对象类型内部bean赋值 代码分析 <b…...
Python电能质量扰动信号分类(二)基于CNN模型的一维信号分类
目录 前言 1 电能质量数据集制作与加载 1.1 导入数据 1.2 制作数据集 2 CNN-2D分类模型和训练、评估 2.1 定义CNN-2d分类模型 2.2 定义模型参数 2.3 模型结构 2.4 模型训练 2.5 模型评估 3 CNN-1D分类模型和训练、评估 3.1 定义CNN-1d分类模型 3.2 定义模型参数 …...

如何解决报错:Another app is currently holding yum lock?
在运行yum 相关命令的时候,不知道怎么回事无法进行下载安装,报出 Another app is currently holding the yum lock; waiting for it to exit... 的错误提示。 Another app is currently holding the yum lock. 意思是另外一个应用正在锁住进程锁。 …...
electron使用electron-builder进行MacOS的 打包、签名、公证、上架、自动更新
一、前言 由于electron在macOS下的坑太多,本文不可能把所有的问题都列出来,也不可能把所有的解决方案贴出来;本文也不太会讲解每一个配置点为什么要这么设置的原因,因为有些点我也说不清,我尽可能会说明的。所以&…...
RAD Studio 12 安装激活说明及常见问题
目录 RAD Studio 安装说明 RAD Studio 最新的修补程序更新 RAD Studio 产品相关信息 Embarcadero 产品在线注册步骤 单机版授权产品注册注意事项 Embarcadero 产品离线注册步骤 Embarcadero 产品安装次数查询 Embarcadero 序号注册次数限制 EDN账号 - 查询授权序号、下…...

JavaScript实现视频共享
1.视频共享webrtc-master index.html <!DOCTYPE html> <html> <head><script typetext/javascript srchttps://cdn.scaledrone.com/scaledrone.min.js></script><meta charset"utf-8"><meta name"viewport" cont…...

uniapp框架——vue3+uniFilePicker+fastapi实现文件上传(搭建ai项目第二步)
文章目录 ⭐前言💖 小程序系列文章 ⭐uni-file-picker 组件💖 绑定事件💖 uploadFile api💖 自定义上传 ⭐后端fastapi定义上传接口⭐uniapp开启本地请求代理devServer⭐前后端联调⭐总结⭐结束 ⭐前言 大家好,我是ym…...

一篇文章带你入门PHP魔术方法
PHP魔术方法 PHP 中的"魔术方法"是一组特殊的方法,它们在特定情况下自动被调用。这些方法的名称都是以两个下划线(__)开头。魔术方法提供了一种方式来执行各种高级编程技巧,使得对象的行为可以更加灵活和强大。以下是一…...

【数据库系统概论】第6章-关系数据库理论
真别看吧,抄ppt而已啊 文章目录 6.1 引言6.2 规范化6.2.1 函数依赖6.2.2 码6.2.3 范式(Normal Form)6.2.4 BC范式6.2.5 规范化小结 6.1 引言 我们有这样一张表: but 为啥这样设计呢?由此引出怎样设计一个关系数据库…...
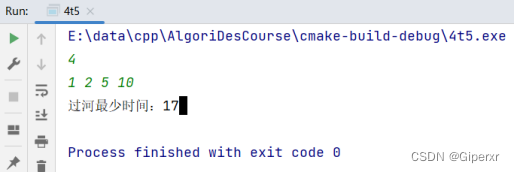
算法设计与分析实验报告-贪心算法
校课程的简单实验报告。 算法设计与分析实验报告-递归与分治策略 算法设计与分析实验报告-动态规划算法 算法设计与分析实验报告-贪心算法 dijkstra迪杰斯特拉算法(邻接表法) 算法设计与分析实验报告-回溯法 算法设计与分析实验报告-分支限界法 …...

Unity读取服务器声音文件
Unity读取服务器声音文件 功能1.在网站的根目录放置一个声音文件Alarm01.wav(这个是window系统自带的找不到这个格式的可以直接在C盘搜索)2.在WebManager.cs脚本中添加clipPath、audio、m_downloadClip属性和DownloadSound()函数&…...

掌握ElasticSearch(一):Elasticsearch安装与配置、Kibana安装
文章目录 〇、简介1.Elasticsearch简介2.典型业务场景3.数据采集工具4.名词解释 一、安装1.使用docker(1)创建虚拟网络(2)Elasticsearch安装步骤 2.使用压缩包 二、配置1.目录介绍2.配置文件介绍3.elasticsearch.yml节点配置4.jvm.options堆配置 二、可视化工具Kibana1.介绍2.安…...
)
《剑指offer》Java版--13.机器人的运动范围(BFS)
剑指offer原题13:机器人的运动范围 地上有一个m行n列的方格。一个机器人从坐标(0,0)的格子开始移动,它每次可以向左、右、上、下移动一格,但不能进入行坐标和列坐标的数位之和大于k的格子。例如,当k为18时,机器人能够进入方格(35,37),因为353…...
基于流程挖掘的保险理赔优化策略实践
引言 在当今日益竞争的商业环境中,保险公司面临着日益增长的业务量和客户期望的挑战。特别是在理赔领域,理赔是保险行业的重要环节,也是保险公司和客户之间最直接的联系点。然而,长周期和繁琐的理赔流程常常给保险公司和投保人带来困扰。因此,如何提供准确且高效的理赔处…...

Docker五 | DockerFile
目录 DockerFile 常用保留字 FROM MAINTAINER RUN EXPOSE WORKDIR USER ENV VOLUME ADD COPY CMD ENTRYPOINT DockerFile案例 前期准备 编写DockerFile文件 运行DockerFile 运行镜像 DockerFile是用来构建Docker镜像的文本文件,是由一条条构建…...

2023年度总结:技术旅程的杨帆远航⛵
文章目录 职业规划与心灵成长 ❤️🔥我的最大收获与成长 💪新年Flag 🚩我的技术发展规划 ⌛对技术行业的深度思考 🤔祝愿 🌇 2023 年对我来说是一个充实而令人难以忘怀的一年。这一年,我在CSDN上发表了 1…...
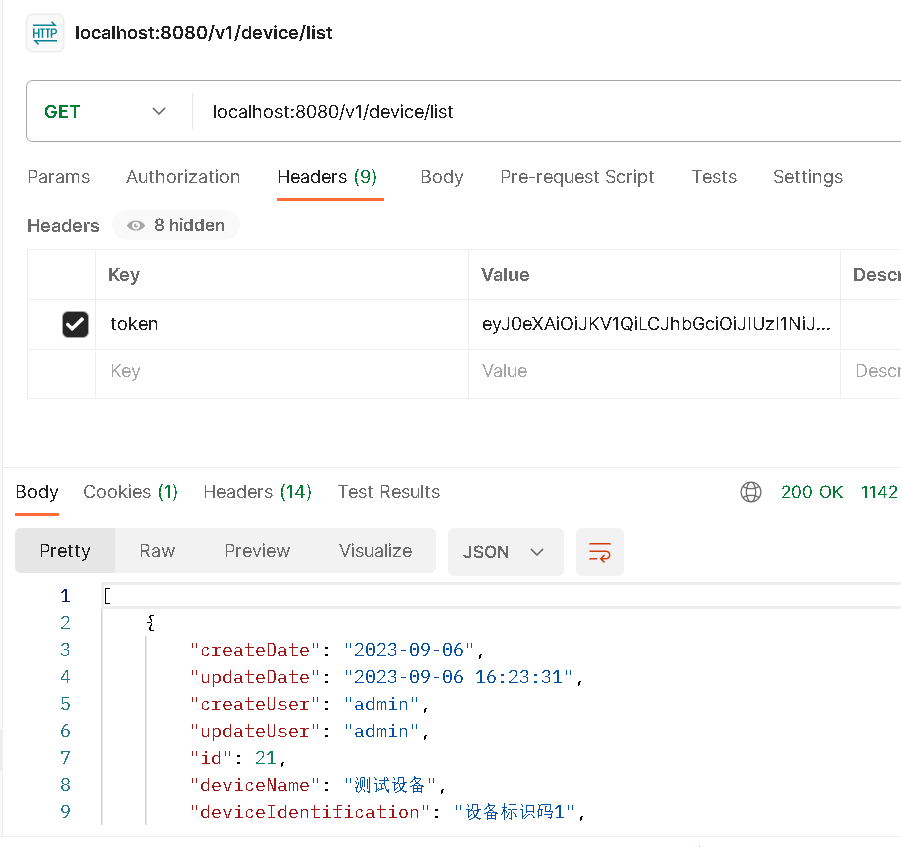
SpringBoot+AOP+Redis 防止重复请求提交
本文项目基于以下教程的代码版本: https://javaxbfs.blog.csdn.net/article/details/135224261 代码仓库: springboot一些案例的整合_1: springboot一些案例的整合 1、实现步骤 2.引入依赖 我们需要redis、aop的依赖。 <dependency><groupId>org.spr…...

偷流量、端口占用、网络负载高、socket创建释放异常等Android高阶TCP/IP网络问题定位思路
一,背景 通常一些偷流量、端口占用、网络负载高、socket创建释放异常等Android网络相关问题,可以通过使用tcpdump抓tcp/ip报文,来定位。但是tcpdump无进程信息,也没有APK包名信息,无法确认异常的报文来自哪些Apk或者n…...

观成科技:隐蔽隧道工具Ligolo-ng加密流量分析
1.工具介绍 Ligolo-ng是一款由go编写的高效隧道工具,该工具基于TUN接口实现其功能,利用反向TCP/TLS连接建立一条隐蔽的通信信道,支持使用Let’s Encrypt自动生成证书。Ligolo-ng的通信隐蔽性体现在其支持多种连接方式,适应复杂网…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

让回归模型不再被异常值“带跑偏“,MSE和Cauchy损失函数在噪声数据环境下的实战对比
在机器学习的回归分析中,损失函数的选择对模型性能具有决定性影响。均方误差(MSE)作为经典的损失函数,在处理干净数据时表现优异,但在面对包含异常值的噪声数据时,其对大误差的二次惩罚机制往往导致模型参数…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...