count distinct在spark中的运行机制
文章目录
- 预备 数据和执行语句
- Expand
- 第一次HashAggregate
- Shuffle and Second HashAggregate
- 最后结果
- 性能
- 原文
预备 数据和执行语句
SELECT COUNT(*), SUM(items), COUNT(DISTINCT product), COUNT(DISTINCT category)
FROM orders;
假设源数据分布在两个1核的结点上,数据就8行

Expand
spark把count distinct操作转换成count操作。
第一步是对每个要count distinct的列,生成新的行(这里是product和category列),当然原来不需要distinct聚合的列也在。
原来items列不需要distinct,product和category列要distinct,所以数据膨胀了2倍。原来8条数据,现在是8*(1+2)=24条
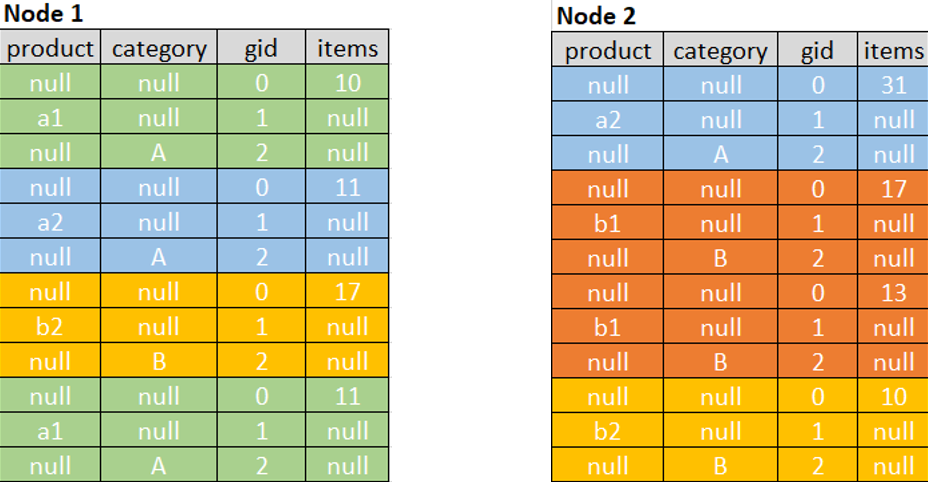
spark加了gid这一列,值为0代表所有非distinct聚合(这里是count(*)和sum(items)),值为1和2分别代表其他distinct聚合(这里1代表product,2代表category)。
NULL是怎么赋值的:对输入列来说,每行只有1个非空值。在spark的物理执行计划中,可以看到操作是这样的
ExpandInput: [product, category, items]Arguments: [[null, null, 0, items],[product, null, 1, null],[null, category, 2, null]]
第一次HashAggregate
Spark使用所有count distinct的列和gid作为关键字(product、category和gid)对行进行局部散列,并对非distinct的聚合(count(*)和SUM(items))执行局部局部聚合:
相当于执行了select product,category,gid,count(*) cnt,sum(items) items from 膨胀后的表 group by product,category,gid
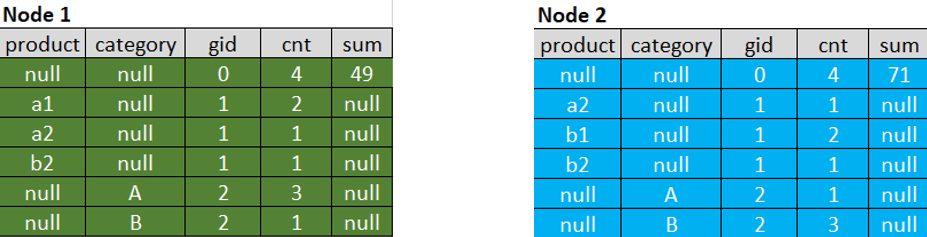
这可以使得膨胀后的数据变小。
如果不同值的数量比较少,减少的数据是相当可观的,最终结果可能比原始数据还要少。
可以看到原来每个结点上有4行,膨胀后是12行,局部聚合后变成了6行。
Shuffle and Second HashAggregate
在每个结点内部HashAggregate后,经过shuffle后变成这样

重新再每个结点做局部shuffle,得到
(相当于执行了select product,category,gid,count(*) cnt,sum(items) items from 膨胀后的表 group by product,category,gid)

这一步使得所有键都变成了唯一的。
最后结果
现在所有行可以合并成一个partition,再次HashAggregation,但这次不用group by product, category和gid
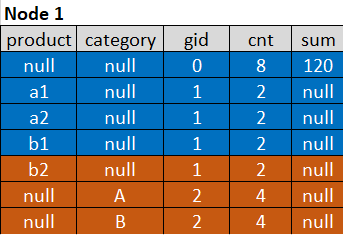
现在再也没有重复值了,简单的count和根据gid筛选就可以得到想要的count distinct结果
cnt FILTER (WHERE gid = 0),sum FILTER (WHERE gid = 0),COUNT(product) FILTER (WHERE gid = 1),COUNT(category) FILTER (WHERE gid = 2)Result:
COUNT(*): 8SUM(items): 120COUNT(DISTINCT product): 4COUNT(DISTINCT category): 2
性能
- 如果不同值的数量比较少,那么即使膨胀后,最后要shuffle的行也很少,这样因为spark局部聚合的原因,count distinct是相对比较快的
- 如果不同值的数量很多,并且你在一个语句中使用多个count distinct对不同的列。那么要shuffle行因为膨胀会很多,局部聚合也不能有效遏制数据的膨胀,那么要让查询语句成功执行需要消耗更多的executor内存。
原文
Distributed COUNT DISTINCT – How it Works in Spark, Multiple COUNT DISTINCT, Transform to COUNT with Expand, Exploded Shuffle, Partial Aggregations – Large-Scale Data Engineering in Cloud (cloudsqale.com)
相关文章:
count distinct在spark中的运行机制
文章目录 预备 数据和执行语句Expand第一次HashAggregateShuffle and Second HashAggregate最后结果性能原文 预备 数据和执行语句 SELECT COUNT(*), SUM(items), COUNT(DISTINCT product), COUNT(DISTINCT category) FROM orders;假设源数据分布在两个1核的结点上࿰…...

创建加密分区或者文件
文章目录 [GParted 中已清除的分区与未格式化的分区](https://superuser.com/questions/706624/cleared-vs-unformatted-partition-in-gparted)创建加密分区解密创建的加密分区以便挂载格式化设备未具体的格式(这里为ext4格式)创建挂载点目录挂载加密的文…...

STL——遍历算法
1.for_each 函数原型: for_each(iterator beg, iterator end, _func);——// 遍历算法 遍历容器元素; beg 开始迭代器;end 结束迭代器; _func 函数或者函数对象 #include<iostream> using namespace std; #include<ve…...

C语言经典算法【每日一练】20
题目:有一个已经排好序的数组。现输入一个数,要求按原来的规律将它插入数组中。 1、先排序 2、插入 #include <stdio.h>// 主函数 void main() {int i,j,p,q,s,n,a[11]{127,3,6,28,54,68,87,105,162,18};//排序(选择排序)…...
Linux磁盘阵列
一.RAID磁盘阵列介绍 RAID(Redundatnt Array of lndependent Disks),全称为:独立冗余磁盘阵列 解释: RAID是一种把多块独立的硬盘(物理硬盘)按不同的方式组合起来形成一个硬盘组(逻…...

本地网络禁用了在哪里开启?
在当今数字化时代,网络已经成为人们生活中不可或缺的一部分。然而,有时我们可能需要禁用本地网络,无论是出于安全考虑、提高专注力还是其他原因。本文将探讨禁用本地网络的方法以及如何在需要时重新开启网络连接。 第一部分:禁用…...

[mysql 基于C++实现数据库连接池 连接池的使用] 持续更新中
目背景 常见的MySQL、Oracle、SQLServer等数据库都是基于C/S架构设计的,即(客户端/服务器)架构,也就是说我们对数据库的操作相当于一个客户端,这个客户端使用既定的API把SQL语句通过网络发送给服务器端,MyS…...

【Flink SQL API体验数据湖格式之paimon】
前言 随着大数据技术的普及,数据仓库的部署方式也在发生着改变,之前在部署数据仓库项目时,首先想到的是选择国外哪家公司的产品,比如:数据存储会从Oracle、SqlServer中或者Mysql中选择,ETL工具会从Informa…...
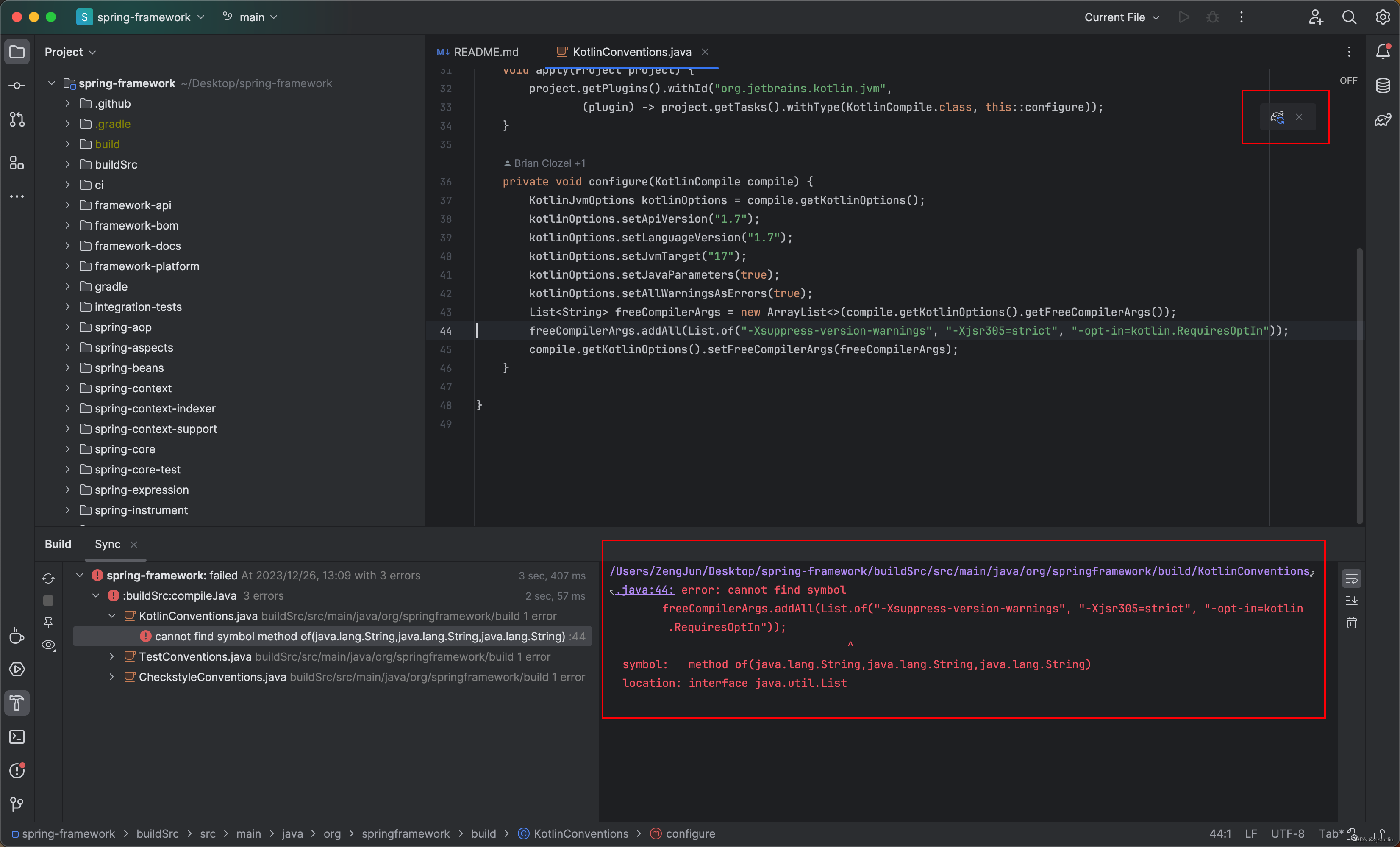
idea导入spring-framework异常:error: cannot find symbol
从github上clone代码spring-framework到本地后导入idea,点击gradle构建后控制台提示异常: 具体异常信息: /Users/ZengJun/Desktop/spring-framework/buildSrc/src/main/java/org/springframework/build/KotlinConventions.java:44: error:…...
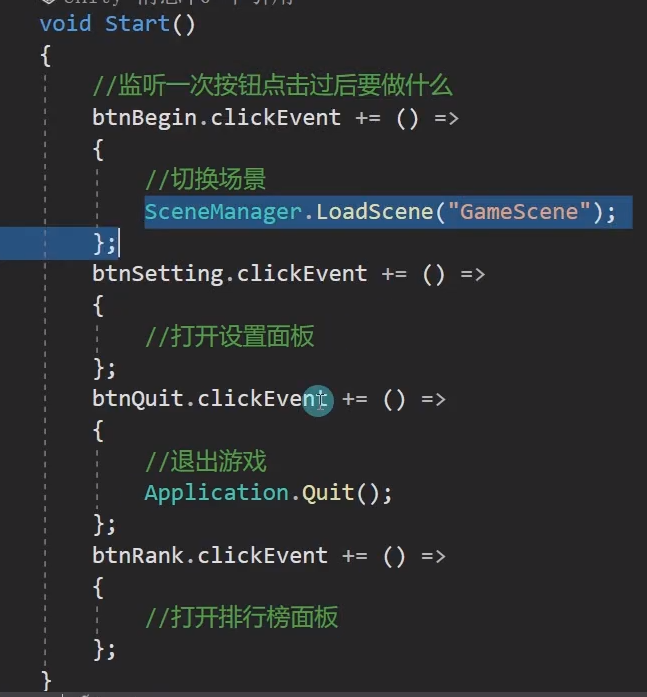
Unity坦克大战开发全流程——开始场景——开始界面
开始场景——开始界面 step1:设置UI 反正按照这张图拼就行了 step2:写脚本 前面的拼UI都是些比较机械化的工作,直到这里写代码的时候才真正开始有点意思了,从这里开始,我们就要利用面向对象的思路来进行分析࿱…...

【SpringCloud】从实际业务问题出发去分析Eureka-Server端源码
文章目录 前言1.EnableEurekaServer2.初始化缓存3.jersey应用程序构建3.1注册jeseryFilter3.2构建JerseyApplication 4.处理注册请求5.registry() 前言 前段时间遇到了一个业务问题就是k8s滚动发布Eureka微服务的过程中接口会有很多告警,当时…...
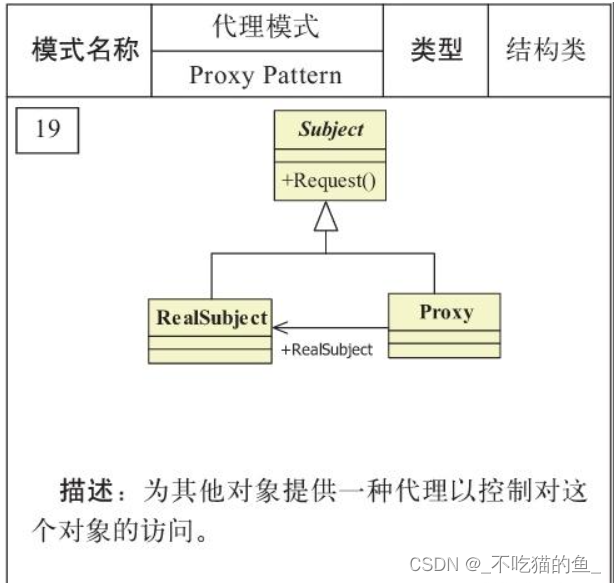
Java 代理模式
一、代理模式概述 代理模式是一种比较好理解的设计模式。简单来说就是 我们使用代理对象来代替对真实对象(real object)的访问,这样就可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能。 代理模式的主要作用是扩展目标…...
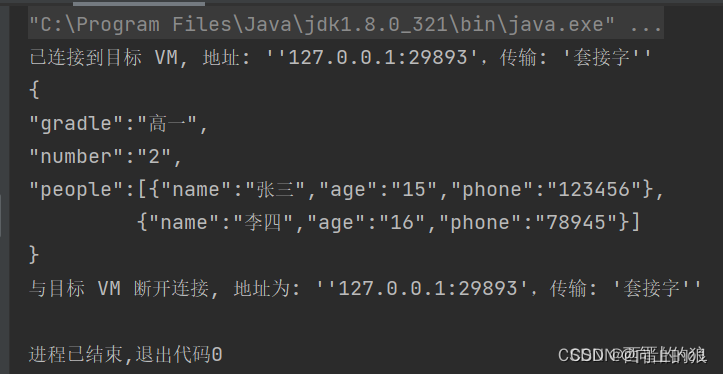
【Java干货教程】JSON,JSONObject,JSONArray类详解
一、定义 JSON:就是一种轻量级的数据交换格式,被广泛应用于WEB应用程序开发。JSON的简洁和清晰的层次结构,易于阅读和编写;同时也易于机器解析和生成,有效的提升网络传输效率;支持多种语言,很多…...
2023年高级软考系统架构师考题参考
对于一些有实践经验的同学来说,感觉不难,但是落笔到纸面上,就差强人意了,平时这方面要多练习,所想所思要落到纸面上,或者表达清晰让别人听懂,不仅是工作中的一个基本素质,也是个非常…...

【c语言】飞机大战(1)
提前准备好游戏要的素材,可以到爱给网去找,飞机大战我们需要的是一个我方战机图片,一个背景图,三个敌方战机的图,我方战机的图片,敌方战机的图片,并且将图片和.cpp放在同一文件夹下. 这里创建.…...
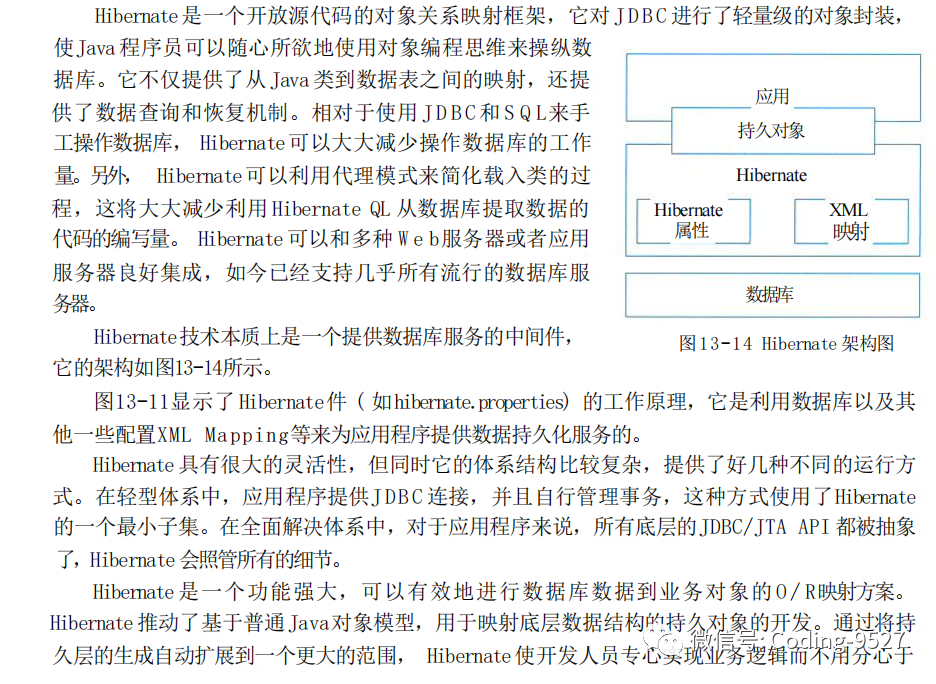
关于 K8s 的一些基础概念整理
〇、前言 Kubernetes,将中间八个字母用数字 8 替换掉简称 k8s,是一个开源的容器集群管理系统,由谷歌开发并维护。它为跨主机的容器化应用提供资源调度、服务发现、高可用管理和弹性伸缩等功能。 下面简单列一下 k8s 的几个特性: 自…...
Node.js-fs、path、http模块
1.初识Node.js 1.1 什么是Node.js 1.2 Node.js中的JavaScript运行环境 1.3 Node.js可以做什么 Node.js 作为一个JavaScript 的运行环境,仅仅提供了基础的功能和 AP1。然而,基于 ode.s 提供的这些基础能,很多强大的工具和框架如雨后春笋&…...

CentOS 安装WebLogic
1.JDK 安装 cd /home/ mkdir java cd java/ tar -zxvf jdk-8u321-linux-x64.tar.gzvim /etc/profile添加以下内容到 /etc/profile JAVA_HOME/home/java/jdk1.8.0_321 CLASSPATH.:$JAVA_HOME/lib.tools.jar PATH$JAVA_HOME/bin:$PATH export JAVA_HOME CLASSPATH PATH刷新配置…...

Linux命令的操作练习
1.创建ss别名,查看长格式详细信息 alias ssls -l 2.创建ss别名,复制boot文件夹下的内容到data文件夹下 alias sscp -r /boot /data 3.删除别名ss unalias ss 4. 复制test文件夹下的passwd文件到qq文件夹下,并改名为ww cp test/pas…...
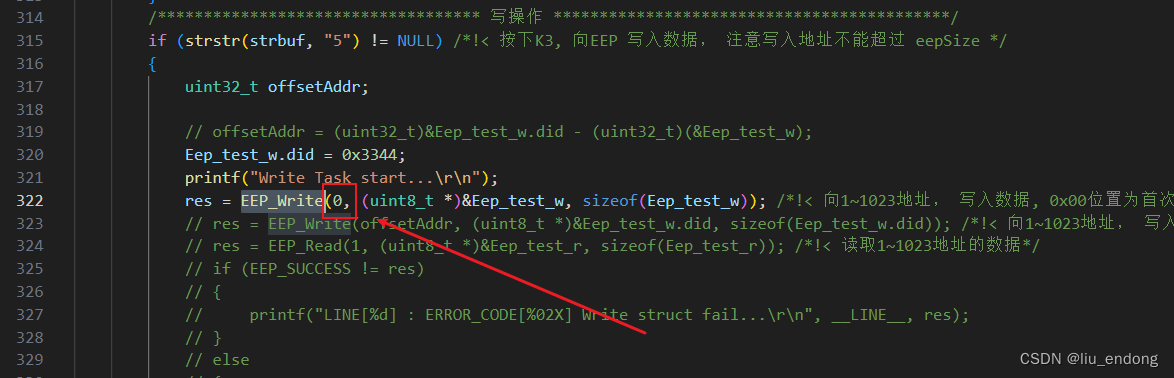
杰发科技AC7840——EEPROM初探
0.序 7840和7801的模拟EEPROM使用不太一样 1.现象 按照官方Demo,在这样的配置下,我们看到存储是这样的(连续三个数字1 2 3)。 使用串口工具的多帧发送功能 看不出多少规律 修改代码后 发现如下规律: 前四个字节是…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

虚拟电厂发展三大趋势:市场化、技术主导、车网互联
市场化:从政策驱动到多元盈利 政策全面赋能 2025年4月,国家发改委、能源局发布《关于加快推进虚拟电厂发展的指导意见》,首次明确虚拟电厂为“独立市场主体”,提出硬性目标:2027年全国调节能力≥2000万千瓦࿰…...

三分算法与DeepSeek辅助证明是单峰函数
前置 单峰函数有唯一的最大值,最大值左侧的数值严格单调递增,最大值右侧的数值严格单调递减。 单谷函数有唯一的最小值,最小值左侧的数值严格单调递减,最小值右侧的数值严格单调递增。 三分的本质 三分和二分一样都是通过不断缩…...

DAY 26 函数专题1
函数定义与参数知识点回顾:1. 函数的定义2. 变量作用域:局部变量和全局变量3. 函数的参数类型:位置参数、默认参数、不定参数4. 传递参数的手段:关键词参数5 题目1:计算圆的面积 任务: 编写一…...

负载均衡器》》LVS、Nginx、HAproxy 区别
虚拟主机 先4,后7...