【MYSQL】MYSQL 的学习教程(八)之 12 种慢 SQL 查询原因
日常开发中,我们经常会遇到数据库慢查询。那么导致数据慢查询都有哪些常见的原因呢?今天就跟大家聊聊导致 MySQL 慢查询的 12 个常见原因,以及对应的解决方法:
- SQL 没加索引
- SQL 索引失效
- limit 深分页问题
- 单表数据量太大
- join 或者子查询过多
- in元素过多
- 数据库在刷脏页
- order by 文件排序
- 拿不到锁
- delete + in 子查询不走索引
- group by 使用临时表
- 系统硬件或网络资源
1. SQL 没加索引
很多时候,我们的慢查询,都是因为没有加索引。如果没有加索引的话,会导致全表扫描的。因此,应考虑在 where 的条件列,建立索引,尽量避免全表扫描
2. SQL 索引失效
【MYSQL】MYSQL 的学习教程(四)之索引失效场景
有时候我们明明加了索引了,但是索引却不生效。在哪些场景,索引会不生效呢?主要有以下十大经典场景:
- 查询条件包含 or,可能导致索引失效
- 隐式的类型转换,索引失效
- like 通配符 “%” 在关键词前面导致索引失效
- 在索引列上使用 MYSQL 的内置函数,索引失效
- 对索引列运算(如,+、-、*、/),索引失效
- 索引字段上使用负向查询(NOT、!=、<>、NOT IN、NOT LIKE)时,可能会导致索引失效
- 索引字段可以为 null,使用 is null, is not null,可能导致索引失效
- 违反了索引的最左匹配原则(联合索引,查询时的条件列不是联合索引中的第一个列,索引失效)
- 左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效
- MYSQL 估计使用全表扫描要比使用索引快,则不使用索引
3. limit 深分页问题
3.1 limit 深分页为什么会变慢
limit深分页为什么会导致 SQL 变慢呢?假设我们有表结构如下:
CREATE TABLE account (id int(11) NOT NULL AUTO_INCREMENT COMMENT '主键Id',name varchar(255) DEFAULT NULL COMMENT '账户名',balance int(11) DEFAULT NULL COMMENT '余额',create_time datetime NOT NULL COMMENT '创建时间',update_time datetime NOT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',PRIMARY KEY (id),KEY idx_name (name),KEY idx_create_time (create_time) //索引
) ENGINE=InnoDB AUTO_INCREMENT=1570068 DEFAULT CHARSET=utf8 ROW_FORMAT=REDUNDANT COMMENT='账户表';
执行如下 SQL:
select id,name,balance from account where create_time> '2020-09-19' limit 100000,10;
这个SQL的执行流程:
- 通过普通二级索引树
idx_create_time,过滤create_time条件,找到满足条件的主键 id - 通过主键 id,回到 id 主键索引树,找到满足记录的行,然后取出需要展示的列(回表过程)
- 扫描满足条件的 100010 行,然后扔掉前 100000 行,返回结果
如下图:

limit 深分页,导致 SQL 变慢原因有两个:
- limit 语句会先扫描
offset+ n行,然后再丢弃掉前offset行,返回后 n 行数据。也就是说limit 100000,10,就会扫描100010行,而 limit 0,10,只扫描10行 limit 100000,10扫描更多的行数,也意味着回表更多的次数
3.2 如何优化深分页问题
我们可以通过减少回表次数来优化。一般有:标签记录法、延迟关联法
3.2.1 标签记录法
标签记录法:标记一下上次查询到哪一条了,下次再来查的时候,从该条开始往下扫描
假设上一次记录到 100000,则 SQL 可以修改为:
select id,name,balance FROM account where id > 100000 limit 10;
这样的话,后面无论翻多少页,性能都会不错的,因为命中了 id 主键索引。但是这种方式有局限性:需要一种类似连续自增的字段
3.2.2 延迟关联法
延迟关联法:把条件转移到主键索引树,然后减少回表
select acct1.id,acct1.name,acct1.balance FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.create_time > '2020-09-19' limit 100000, 10) AS acct2 on acct1.id= acct2.id;
优化思路:先通过 idx_create_time 二级索引树查询到满足条件的主键 ID,再与原表通过主键 ID 内连接,这样后面直接走了主键索引了,同时也减少了回表
4. 单表数据量太大
4.1 单表数据量太大为什么会变慢?
一个表的数据量达到好几千万或者上亿时,加索引的效果没那么明显啦。性能之所以会变差,是因为维护索引的 B+ 树结构层级变得更高了,查询一条数据时,需要经历的磁盘IO变多,因此查询性能变慢
4.2 一棵 B+ 树可以存多少数据量
【MYSQL】MYSQL 的学习教程(五)之 MySQL 索引底层:B+ 树详解
一棵高度为 3 的 B+ 树,能存放 1170 *1170 *16 =21902400,也就是说,可以存放两千万左右的记录。B+ 树高度一般为 1-3 层,已经满足千万级别的数据存储
如果 B+ 树想存储更多的数据,那树结构层级就会更高,查询一条数据时,需要经历的磁盘IO变多,因此查询性能变慢
4.3 如何解决单表数据量太大,查询变慢的问题
一般超过千万级别,我们可以考虑分库分表了
分库分表可能导致的问题:
- 事务问题
- 跨库问题
- 排序问题
- 分页问题
- 分布式ID
在评估是否分库分表前,先考虑下是否可以把部分历史数据归档,如果可以的话,先不要急着分库分表。如果真的要分库分表,综合考虑和评估方案。比如可以考虑垂直、水平分库分表。水平分库分表策略的话,range范围、hash取模、range+hash取模混合等等
5. join 或者子查询过多
一般来说,不建议使用子查询,可以把子查询改成 join 来优化
而数据库有个规范约定就是:尽量不要有超过3个以上的表连接
MySQL中,join的执行算法,分别是:Index Nested-Loop Join、Block Nested-Loop Join
Index Nested-Loop Join(索引嵌套循环连接):这个 join 算法,跟我们写程序时的嵌套查询类似,并且可以用上被驱动表的索引Block Nested-Loop Join(缓存块嵌套循环连接):被驱动表上没有可用的索引,它会先把驱动表的数据读入线程内存join_buffer 中,再扫描被驱动表,把被驱动表的每一行取出来,跟 join_buffer 中的数据做对比,满足join条件的,作为结果集的一部分返回
join 过多的问题:
- 过多的表连接,会大大增加 SQL 复杂度
- 如果可以使用被驱动表的索引那还好,并且使用小表来做驱动表,查询效率更佳。如果被驱动表没有可用的索引,join是在 join_buffer 内存做的,如果匹配的数据量比较小或者 join_buffer 设置的比较大,速度也不会太慢。但是,如果join的数据量比较大时,mysql 会采用在硬盘上创建临时表的方式进行多张表的关联匹配,这种显然效率就极低,本来磁盘的 IO 就不快,还要关联
一般情况下,如果业务需要的话,关联 2~3 个表是可以接受的,但是关联的字段需要加索引哈。如果需要关联更多的表,建议从代码层面进行拆分,在业务层先查询一张表的数据,然后以关联字段作为条件查询关联表形成 map,然后在业务层进行数据的拼装
6. in元素过多
如果使用了 in,即使后面的条件加了索引,还是要注意in后面的元素不要过多哈。in 元素一般建议不要超过500个,如果超过了,建议分组,每次500一组进行哈
如果我们对in的条件不做任何限制的话,该查询语句一次性可能会查询出非常多的数据,很容易导致接口超时。尤其有时候,我们是用的子查询,in后面的子查询,你都不知道数量有多少那种,更容易采坑。如下这种子查询:
select * from user where user_id in (select author_id from artilce where type = 1);
正例是,分批进行,每批500个:
select user_id,name from user where user_id in (1,2,3...500);
7. 数据库在刷脏页
7.1 什么是脏页
当内存数据页跟磁盘数据页内容不一致的时候,我们称这个内存页为**“脏页”。内存数据写入到磁盘后,内存和磁盘上的数据页的内容就一致了,称为“干净页”**。一般有更新 SQL 才可能会导致脏页
7.2 一条更新语句是如何执行的?
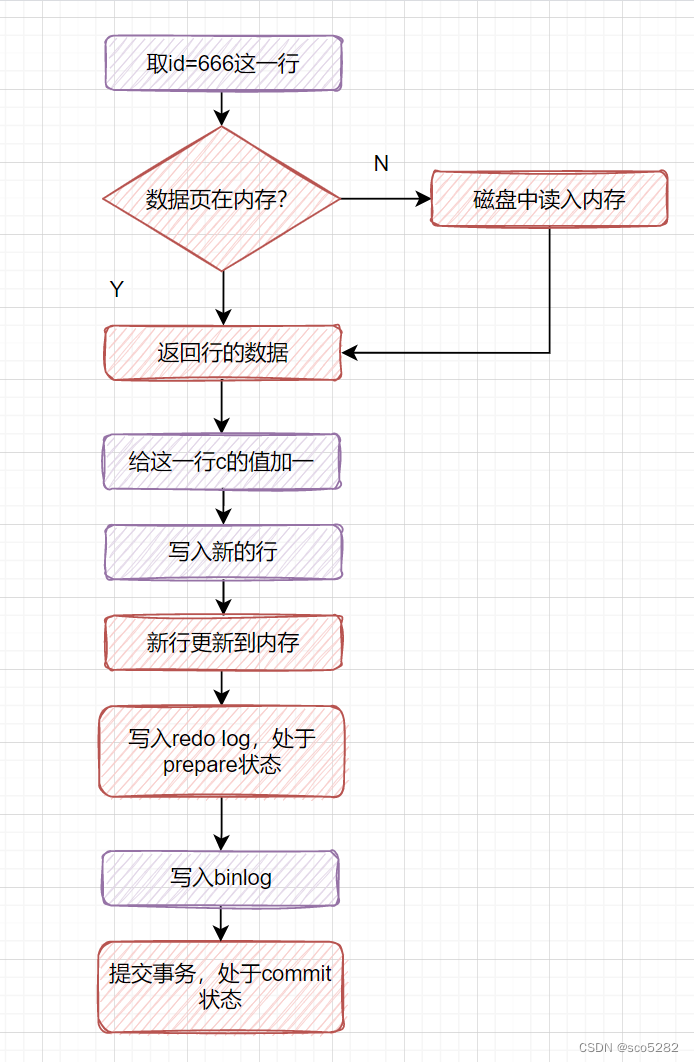
以下的这个更新SQL,如何执行的呢?
update t set c=c+1 where id=666;
- 对于这条更新SQL,执行器会先找引擎取 id = 666 这一行。如果这行所在的数据页本来就在内存中的话,就直接返回给执行器。如果不在内存,就去磁盘读入内存,再返回
- 执行器拿到引擎给的行数据后,给这一行 C 的值加一,得到新的一行数据,再调用引擎接口写入这行新数据
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,但是此时 redo log 是处于 prepare 状态的哈
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成
如下图:
InnoDB 在处理更新语句的时候,只做了写日志这一个磁盘操作。这个日志叫作 redo log(重做日志)。平时更新 SQL 执行得很快,其实是因为它只是在写内存和 redo log 日志,等到空闲的时候,才把 redo log 日志里的数据同步到磁盘中
redo log 日志不是在磁盘嘛?那为什么不慢?其实是因为写 redo log 的过程是顺序写磁盘的。磁盘顺序写会减少寻道等待时间,速度比随机写要快很多的。
7.3 为什么会出现脏页呢?
更新 SQL 只是在写内存和 redo log 日志,等到空闲的时候,才把 redo log 日志里的数据同步到磁盘中。这时内存数据页跟磁盘数据页内容不一致,就出现脏页
7.4 什么时候会刷脏页(flush)?
InnoDB 存储引擎的 redo log 大小是固定,且是环型写入的,如下图:
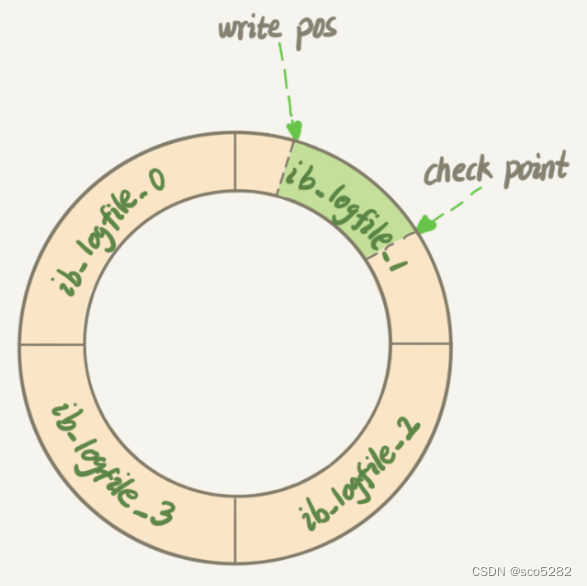
那什么时候会刷脏页?有几种场景:
- redo log 写满了,要刷脏页。这种情况要尽量避免的。因为出现这种情况时,整个系统就不能再接受更新啦,即所有的更新都必须堵住
- 内存不够了,需要新的内存页,就要淘汰一些数据页,这时候会刷脏页
InnoDB 用缓冲池(buffer pool)管理内存,而当要读入的数据页没有在内存的时候,就必须到缓冲池中申请一个数据页。这时候只能把最久不使用的数据页从内存中淘汰掉:如果要淘汰的是一个干净页,就直接释放出来复用;但如果是脏页呢,就必须将脏页先刷到磁盘,变成干净页后才能复用
- MySQL 认为系统空闲的时候,也会刷一些脏页
- MySQL 正常关闭时,会把内存的脏页都 flush 到磁盘上
7.5 为什么刷脏页会导致 SQL 变慢呢?
- redo log 写满了,要刷脏页,这时候会导致系统所有的更新堵住,写性能都跌为0了,肯定慢呀。一般要杜绝出现这个情况。
- 一个查询要淘汰的脏页个数太多,一样会导致查询的响应时间明显变长
8. order by 文件排序
order by 就一定会导致慢查询吗?不是这样的哈,因为 order by 平时用得多,并且数据量一上来,还是走文件排序的话,很容易有慢SQL的
8.1 order by 的 Using filesort 文件排序
平时经常需要用到 order by ,主要就是用来给某些字段排序的。比如以下 SQL:
select name,age,city from staff where city = '深圳' order by age limit 10;
查看 explain 执行计划的时候,可以看到 Extra 这一列,有一个 Using filesort,它表示用到文件排序
8.2 order by文件排序效率为什么较低
order by 用到文件排序时,为什么查询效率会相对低呢?
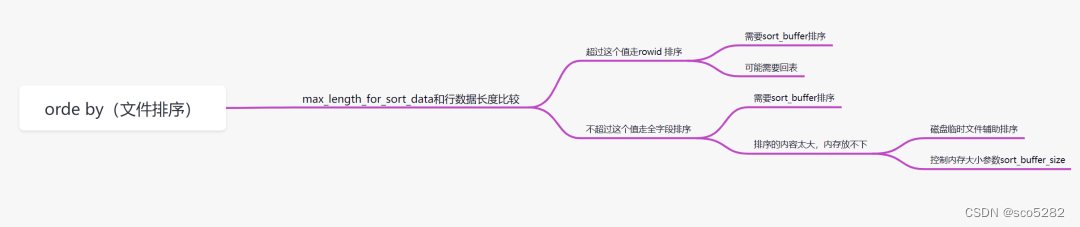
order by 排序,分为全字段排序、rowid排序。它是拿 max_length_for_sort_data 和结果行数据长度对比,如果结果行数据长度超过 max_length_for_sort_data 这个值,就会走 rowid 排序,相反,则走全字段排序
8.2.1 rowid 排序
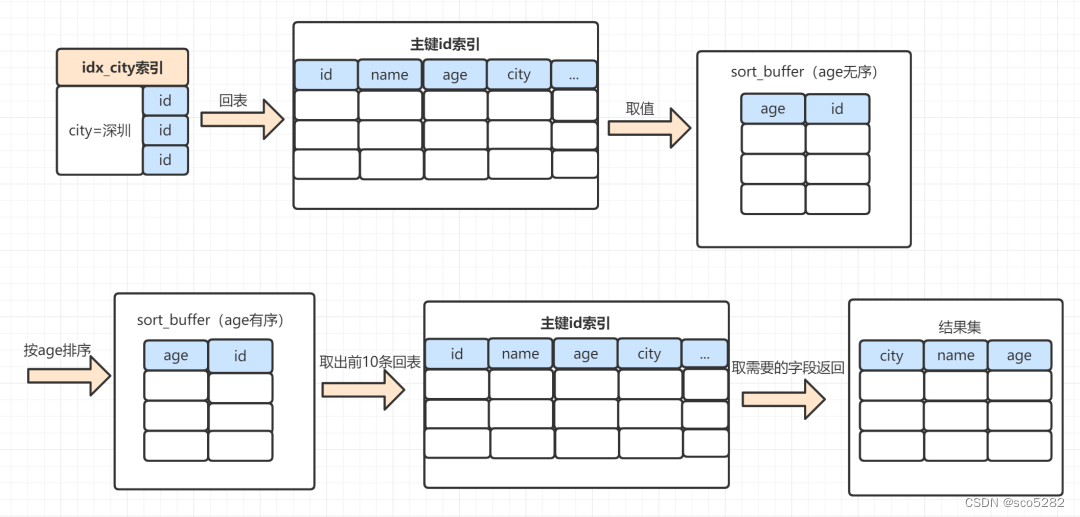
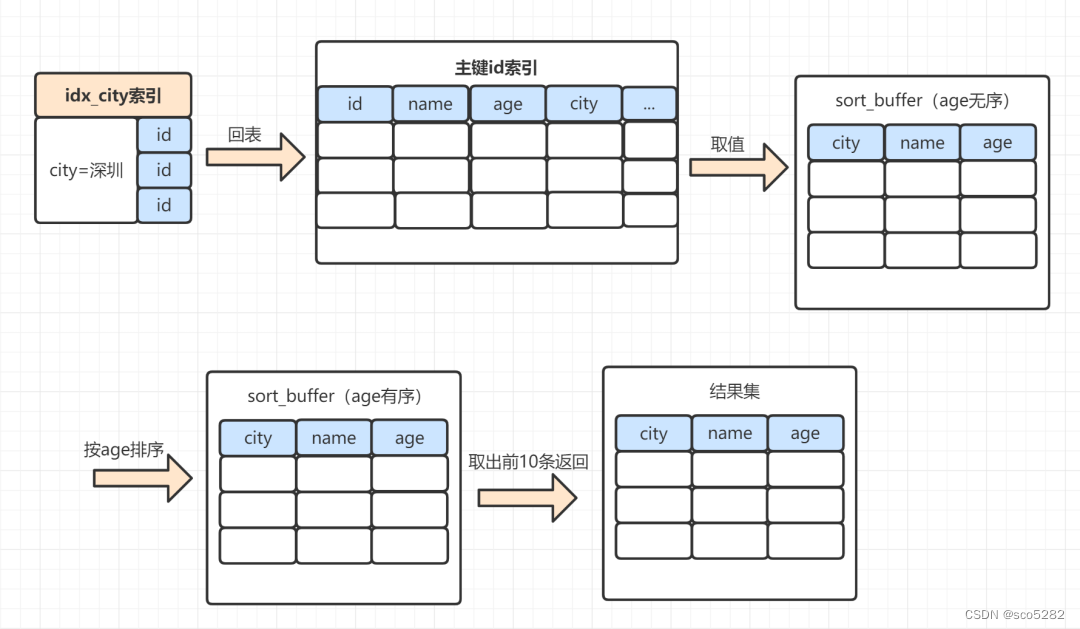
rowid 排序,一般需要回表去找满足条件的数据,所以效率会慢一点。以下这个 SQL,使用 rowid 排序,执行过程是这样:
select name,age,city from staff where city = '深圳' order by age limit 10;
- MySQL 为对应的线程初始化
sort_buffer,放入需要排序的 age 字段,以及主键 id - 从索引树 idx_city, 找到第一个满足 city='深圳’ 条件的主键 id,也就是图中的 id=9
- 到
主键 id索引树拿到 id=9 的这一行数据, 取 age 和主键 id 的值,存到 sort_buffer - 从
索引树 idx_city拿到下一个记录的主键 id,即图中的 id=13 - 重复步骤 3、4 直到 city 的值不等于深圳为止
- 前面 5 步已经查找到了所有 city 为深圳的数据,在 sort_buffer 中,将所有数据根据 age 进行排序
- 遍历排序结果,取前 10 行,并按照 id 的值回到原表中,取出 city、name 和 age 三个字段返回给客户端
8.2.2 全字段排序
同样的 SQL,如果是走全字段排序是这样的:
- MySQL 为对应的线程初始化 sort_buffer,放入需要查询的 name、age、city 字段
- 从
索引树 idx_city, 找到第一个满足 city='深圳’ 条件的主键 id,也就是图中的 id=9 - 到
主键id索引树拿到 id=9 的这一行数据, 取 name、age、city 三个字段的值,存到 sort_buffer - 从
索引树idx_city拿到下一个记录的主键 id,即图中的 id=13 - 重复步骤 3、4 直到 city 的值不等于深圳为止
- 前面 5 步已经查找到了所有 city 为深圳的数据,在 sort_buffer 中,将所有数据根据 age 进行排序
- 按照排序结果取前 10 行返回给客户端
sort_buffer 的大小是由一个参数控制的:sort_buffer_size
- 如果要排序的数据小于 sort_buffer_size,排序在 sort_buffer 内存中完成
- 如果要排序的数据大于 sort_buffer_size,则借助磁盘文件来进行排序
借助磁盘文件排序的话,效率就更慢一点。因为先把数据放入 sort_buffer,当快要满时。会排一下序,然后把 sort_buffer 中的数据,放到临时磁盘文件,等到所有满足条件数据都查完排完,再用归并算法把磁盘的临时排好序的小文件,合并成一个有序的大文件
8.3 如何优化 order by 的文件排序
order by 使用文件排序,效率会低一点。我们怎么优化呢
- 因为数据是无序的,所以就需要排序。如果数据本身是有序的,那就不会再用到文件排序啦。而索引数据本身是有序的,我们通过建立索引来优化 order by 语句
- 可以通过调整
max_length_for_sort_data、sort_buffer_size等参数优化
9. 拿不到锁
有时候,我们查询一条很简单的 SQL,但是却等待很长的时间,不见结果返回。一般这种时候就是表被锁住了,或者要查询的某一行或者几行被锁住了。我们只能慢慢等待锁被释放
这时候,我们可以用 show processlist 命令,看看当前语句处于什么状态哈
10. delete + in 子查询不走索引
当 delete 遇到 in 子查询时,即使有索引,也是不走索引的。而对应的 select + in 子查询,却可以走索引
实际执行的时候,MySQL 对 select in 子查询做了优化,把子查询改成 join 的方式,所以可以走索引。但是很遗憾,对于 delete in 子查询,MySQL 却没有对它做这个优化
11. group by 使用临时表
group by 一般用于分组统计,它表达的逻辑就是根据一定的规则,进行分组
假设有表结构:
CREATE TABLE `staff` (`id` bigint(11) NOT NULL AUTO_INCREMENT COMMENT '主键id',`id_card` varchar(20) NOT NULL COMMENT '身份证号码',`name` varchar(64) NOT NULL COMMENT '姓名',`age` int(4) NOT NULL COMMENT '年龄',`city` varchar(64) NOT NULL COMMENT '城市',PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=15 DEFAULT CHARSET=utf8 COMMENT='员工表';
我们查看一下这个SQL的执行计划:
explain select city ,count(*) as num from staff group by city;

- Extra 这个字段的
Using temporary表示在执行分组的时候使用了临时表 - Extra 这个字段的
Using filesort表示使用了文件排序
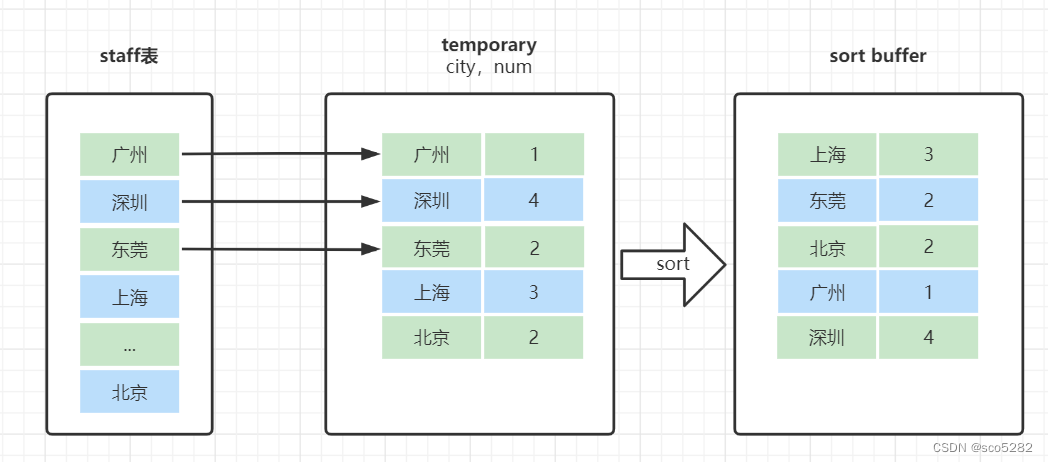
group by 是怎么使用到临时表和排序了呢?我们来看下这个SQL的执行流程:
- 创建内存临时表,表里有两个字段 city 和 num;
- 全表扫描 staff 的记录,依次取出 city = ‘X’ 的记录
- 判断临时表中是否有为 city='X '的行,没有就插入一个记录 (X,1);
- 如果临时表中有 city=‘X’ 的行,就将X这一行的 num 值加 1;
- 遍历完成后,再根据字段 city 做排序,得到结果集返回给客户端
这个流程的执行图如下:
临时表的排序是怎样的呢?
就是把需要排序的字段,放到 sort buffer,排完就返回。在这里注意一点哈,排序分全字段排序和 rowid 排序
- 如果是全字段排序,需要查询返回的字段,都放入sort buffer,根据排序字段排完,直接返回
- 如果是 rowid 排序,只是需要排序的字段放入sort buffer,然后多一次回表操作,再返回
11.2 group by 可能会慢在哪里?
因为它既用到临时表,又默认用到排序。有时候还可能用到磁盘临时表
- 如果执行过程中,会发现内存临时表大小到达了上限(控制这个上限的参数就是
tmp_table_size),会把内存临时表转成磁盘临时表。 - 如果数据量很大,很可能这个查询需要的磁盘临时表,就会占用大量的磁盘空间
11.3 如何优化 group by 呢?
从哪些方向去优化呢?
- 方向1:既然它默认会排序,我们不给它排是不是就行啦。
- 方向2:既然临时表是影响 group by 性能的因素,我们是不是可以不用临时表?
执行 group by 语句为什么需要临时表呢?group by 的语义逻辑,就是统计不同的值出现的个数。如果这个这些值一开始就是有序的,我们是不是直接往下扫描统计就好了,就不用临时表来记录并统计结果啦?
可以有这些优化方案:
- group by 后面的字段加索引
- order by null 不用排序
- 尽量只使用内存临时表
- 使用
SQL_BIG_RESULT(直接用磁盘临时表。不需要从内存临时表转到磁盘临时表,这个过程很耗时)
12. 系统硬件或网络资源
- 如果数据库服务器内存、硬件资源,或者网络资源配置不是很好,就会慢一些哈。这时候可以升级配置。这就好比你的计算机有时候很卡,你可以加个内存条什么的一个道理
- 如果数据库压力本身很大,比如高并发场景下,大量请求到数据库来,数据库服务器CPU占用很高或者IO利用率很高,这种情况下所有语句的执行都有可能变慢的哈
相关文章:
【MYSQL】MYSQL 的学习教程(八)之 12 种慢 SQL 查询原因
日常开发中,我们经常会遇到数据库慢查询。那么导致数据慢查询都有哪些常见的原因呢?今天就跟大家聊聊导致 MySQL 慢查询的 12 个常见原因,以及对应的解决方法: SQL 没加索引SQL 索引失效limit 深分页问题单表数据量太大join 或者…...

C语言例题3
1.设x、y、z和k都是int型变量,则执行表达式:x(y4,z16,k32)后,x的值为(32); x(y4,z16,k32),x的值为32 理解逗号运算符在c语言中的工作方式:逗号运算…...

很实用的ChatGPT网站——httpchat-zh.com
很实用的ChatGPT网站——http://chat-zh.com/ 今天介绍一个好兄弟开发的ChatGPT网站,网址[http://chat-zh.com/]。这个网站功能模块很多,包含生活、美食、学习、医疗、法律、经济等很多方面。下面简单介绍一些部分功能与大家一起分享。 登录和注册页面…...

Python函数中的*args,**kwargs作用与用法
前言 最近在使用Python函数的时候,经常碰见函数中使用*args、**kwargs,而且参数的传递也是非常奇特,就特意对Python函数中*args、**kwargs进行了查询,下面就以实例进行说明。 1 Python中的*args、**kwargs 在 Python 中&#x…...

python可视化界面自动生成,python如何做可视化界面
大家好,小编来为大家解答以下问题,python gui可视化操作界面制作,python做出的炫酷的可视化,现在让我们一起来看看吧! 目录 前言 一.环境配置 插件: 1.python 2.Chinese 3.Open In Default Browser 安装pyt…...

力扣热题100道-双指针篇
文章目录 双指针283.移动零11.盛最多水的容器15.三数之和42.接雨水 双指针 283.移动零 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。 …...

数据库一般会采取什么样的优化方法?
数据库一般会采取什么样的优化方法? 1、选取适合的字段属性 为了获取更好的性能,可以将表中的字段宽度设得尽可能小。 尽量把字段设置成not null 执行查询的时候,数据库不用去比较null值。 对某些省份或者性别字段,将他们定义为e…...

编程笔记 html5cssjs 015 HTML列表
编程笔记 html5&css&js 015 HTML列表 一、有序列表例1:例2: 二、无序列表例1:例2: 列表是一种特定文字格式,很常用。 HTML 列表。HTML 支持有序、无序和定义列表。 一、有序列表 例1: <!DOCTY…...

【力扣题解】P404-左叶子之和-Java题解
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【力扣题解】 文章目录 【力扣题解】P404-左叶子之和-Java题解🌏题目描述💡题解🌏总结…...

elasticsearch 索引数据多了怎么办,如何调优,部署
当Elasticsearch索引的数据量增加时,可能会遇到性能瓶颈,需要进行调优。以下是一些建议和步骤,可帮助你处理数据量增加的情况: 1. 硬件升级: 增加节点数或升级硬件,包括更快的CPU、更大的内存和更快的存储…...

Spring Cloud Gateway之Predicate断言详解
目录 Predicate(断言)内置Predicate请求参数匹配请求路径匹配Header 属性匹配Cookie 匹配请求方式匹配请求 ip 地址匹配时间匹配组合匹配 Predicate(断言) 在 Spring Cloud Gateway 中,Predicate(断言&…...

JavaScript中的prototype和_proto_的关系是什么
JavaScript中的prototype和_proto_的关系是什么 __proto__ 是 JavaScript 中对象的一个内部属性,它指向该对象的原型。JavaScript 中每个对象都有一个 __proto__ 属性,通过它可以访问对象的原型。prototype 是函数对象特有的属性,每个函数都…...
 -- 数据预处理(3))
机器学习(二) -- 数据预处理(3)
系列文章目录 未完待续…… 目录 前言 tips:这里只是总结,不是教程哈。本章开始会用到numpy,pandas以及matplotlib,这些就不在这讲了哈。 “***”开头的是给好奇心重的宝宝看的,其实不太重要可以跳过。 此处以下所有…...
【数学建模美赛M奖速成系列】Matplotlib绘图技巧(三)
Matplotlib绘图技巧(三) 写在前面7. 雷达图7.1 圆形雷达图7.2 多边形雷达图 8. 极坐标图 subplot9. 折线图 plot10. 灰度图 meshgrid11. 热力图11.1 自定义colormap 12. 箱线图 boxplot 写在前面 终于更新完Matplotlib绘图技巧的全部内容,有…...

手写Spring与基本原理--简易版
文章目录 手写Spring与基本原理解析简介写一个简单的Bean加载容器定义一个抽象所有类的BeanDefinition定义一个工厂存储所有的类测试 实现Bean的注册定义和获取基于Cglib实现含构造函数的类实例化策略Bean对象注入属性和依赖Bean的功能Spring.xml解析和注册Bean对象实现应用上下…...
EasyNTS端口穿透服务新版本发布 0.8.7 增加隧道流量总数记录,可以知晓设备哪个端口耗费流量了
EasyNTS上云平台可通过远程访问内网应用,包含网络桥接、云端运维、视频直播等功能,极大地解决了现场无固定IP、端口不开放、系统权限不开放等问题。平台可提供一站式上云服务,提供直播上云、设备上云、业务上云、运维上云服务,承上…...

python自动合计各部周销
下载依赖 pip install openpyxl -i https://pypi.doubanio.com/simplepip install pandas -i https://pypi.doubanio.com/simple引入依赖 from openpyxl import load_workbook from openpyxl import styles from openpyxl.styles import * import pandas as pd import string…...

Java内存区域与内存溢出异常
Java与C++之间有一堵由内存分配和垃圾收集技术所围成的高墙,墙外面的人想进去,墙里面的人却想出来。 2.1 概述 对于从事C、C++程序开发的开发人员来说,在内存管理领域,他们即是拥有最高权力的“皇帝”,又是从事最基础工作的劳动人民——即拥有每一个对象的“所有权”,又…...
远程网络唤醒家庭主机(openwrt设置)
远程网络唤醒家庭主机(openwrt设置) 前提: 1.配置好主板bios的网络唤醒功能(网络教程自己百度一下找) 2.电脑开启网络唤醒功能(网络教程自己百度一下找) 3.路由器通过ddns实现域名和动态IP绑定内网穿透方法汇总_不修改光猫进行内网穿透-C…...
Spring知识02
1、这边是做单元测试的 2、项目部署上线的时候需要把Test那里注解掉 3、pom.xml的坐标系,用来导出包给别人用 4、项目名称,artifactId,name属性名保持一致 5、maven中央仓库那里可以看到导包之后会随着附加的内容 6、class.getSingleName获取…...
)
Ubuntu显示优化全攻略:从分辨率调整到界面缩放(2024最新版)
1. Ubuntu显示问题全解析:从模糊到清晰的蜕变 刚装好Ubuntu系统时,最让我头疼的就是显示问题。要么文字小得要用放大镜看,要么图标大得像老年机,更别提外接显示器时各种错位的界面。经过无数次折腾,我发现这些问题其实…...
在深度神经网络中的关键作用与实现细节)
残差块(Residual Block)在深度神经网络中的关键作用与实现细节
1. 残差块的定义与核心思想 第一次听说残差块这个概念时,我也是一头雾水。直到在项目中实际使用ResNet模型后,才真正理解它的精妙之处。简单来说,残差块就像是给神经网络装上了"记忆芯片",让信息可以跳过某些层直接传递…...

车载C语言安全合规进入“熔断期”:2026年Q1起新车型申报将拒收未覆盖Annex G.5.2.3的静态分析报告
第一章:车载C语言安全合规“熔断期”的本质与影响车载嵌入式系统在ISO 26262 ASIL-B及以上等级开发中,“熔断期”并非标准术语,而是工程实践中对**安全机制响应窗口超限所触发的强制降级或停机行为**的通俗表述。其本质是功能安全监控模块&am…...

DeepSeek-Coder-V2本地AI部署指南:突破开发效率瓶颈的技术实践
DeepSeek-Coder-V2本地AI部署指南:突破开发效率瓶颈的技术实践 【免费下载链接】DeepSeek-Coder-V2 项目地址: https://gitcode.com/GitHub_Trending/de/DeepSeek-Coder-V2 在当今软件开发领域,开发者面临着代码编写效率低、依赖网络服务导致数据…...
)
Qt实战:用QTreeView打造高颜值导航菜单(附完整QSS代码)
Qt实战:用QTreeView打造高颜值导航菜单(附完整QSS代码) 在Qt开发中,原生控件的美观度常常成为用户体验的短板。QTreeView作为常用的树形结构控件,其默认样式往往显得过于朴素。本文将带你从零开始,通过QSS样…...

零基础玩转vLLM-v0.11.0:一键部署,体验5-10倍推理加速
零基础玩转vLLM-v0.11.0:一键部署,体验5-10倍推理加速 你是不是觉得大模型推理又慢又占显存?每次想跑个模型,都得等半天,显存还动不动就爆掉。作为开发者或者研究者,我们最头疼的就是:怎么让模…...

华为Datacom认证中的5个常见配置错误及解决方法
华为Datacom认证中的5个常见配置错误及解决方法 在网络工程师的日常工作中,配置错误是导致网络故障的常见原因之一。特别是在华为Datacom认证的学习和实际应用场景中,一些看似简单的配置细节往往成为阻碍网络正常运行的"绊脚石"。本文将深入分…...

大规模驱动企业 AI:Elastic 与 NVIDIA cuVS 集成
作者:来自 Elastic Brian BergholmRachael WadeHubert GrzesiekAleta Hubbell 无缝向量化高容量数据,并通过 GPU 加速向量搜索的新黄金标准加快生产上线时间。 总结 Elastic 与 NVIDIA 合作推出了由 NVIDIA cuVS 提供支持的 GPU 加速向量索引。集成到 NV…...

网络安全岗位薪水多少?
网络安全行业薪资一直备受关注,也是很多人入行的重要原因。其薪酬受城市、经验、岗位影响较大,整体高于普通IT岗位,那么网络安全薪水一般多少?以下是具体内容介绍。网络安全岗位的薪水跨度较大,具体区间如下:初级职位…...

用MCGS6.2玩转交通灯自动控制
交通信号灯自动控制mcgs6.2仿真程序11,带西门子S7-200PLCio表,接线图CAD最近在工控圈子里,用MCGS组态软件做交通灯仿真算是个经典项目了。这次结合西门子S7-200 PLC搞了一套带IO表和CAD接线图的方案,实测效果挺有意思,…...