【2023】通过docker安装hadoop以及常见报错
💻目录
- 1、准备
- 2、安装镜像
- 2.1、创建centos-ssh的镜像
- 2.2、创建hadoop的镜像
- 3、配置ssh网络
- 3.1、搭建同一网段的网络
- 3.2、配置host实现互相之间可以免密登陆
- 3.3、查看是否成功
- 4、安装配置Hadoop
- 4.1、添加存储文件夹
- 4.2、添加指定配置
- 4.3、同步数据
- 5、测试启动
- 5.1、启动配置
- 5.2、启动hadoop
1、准备
准备安装的环境,最好是cenos的环境,相对问题会少一些,我因为是mac的内存比较珍贵,所以嫌麻烦就没安装虚拟机,所以问题非常多(所以还是不要嫌麻烦最好),就使用的是mac。
- 目的:通过本地docker安装hadoop,实现一主二从的分布式存储集群安装。
- 准备:
- 准备一个内存还ok,可以安装docker的系统(最好是centos7)的。
- 把相关需要的包传到该容器环境去
- 这个是我的hadoop和jdk的版本
链接: https://pan.baidu.com/s/1EN9wtLbNv7i6X2bcTh0yhw?pwd=ibum
提取码: ibum
2、安装镜像
2.1、创建centos-ssh的镜像
- 下载安装cenos7镜像
docker pull cenos:7
这里贴一下常用指令Dockerfile的常用指令,想详细学习可以了解Dockerfile文件可以看我 🍅docker安装部署容器这一篇文章。
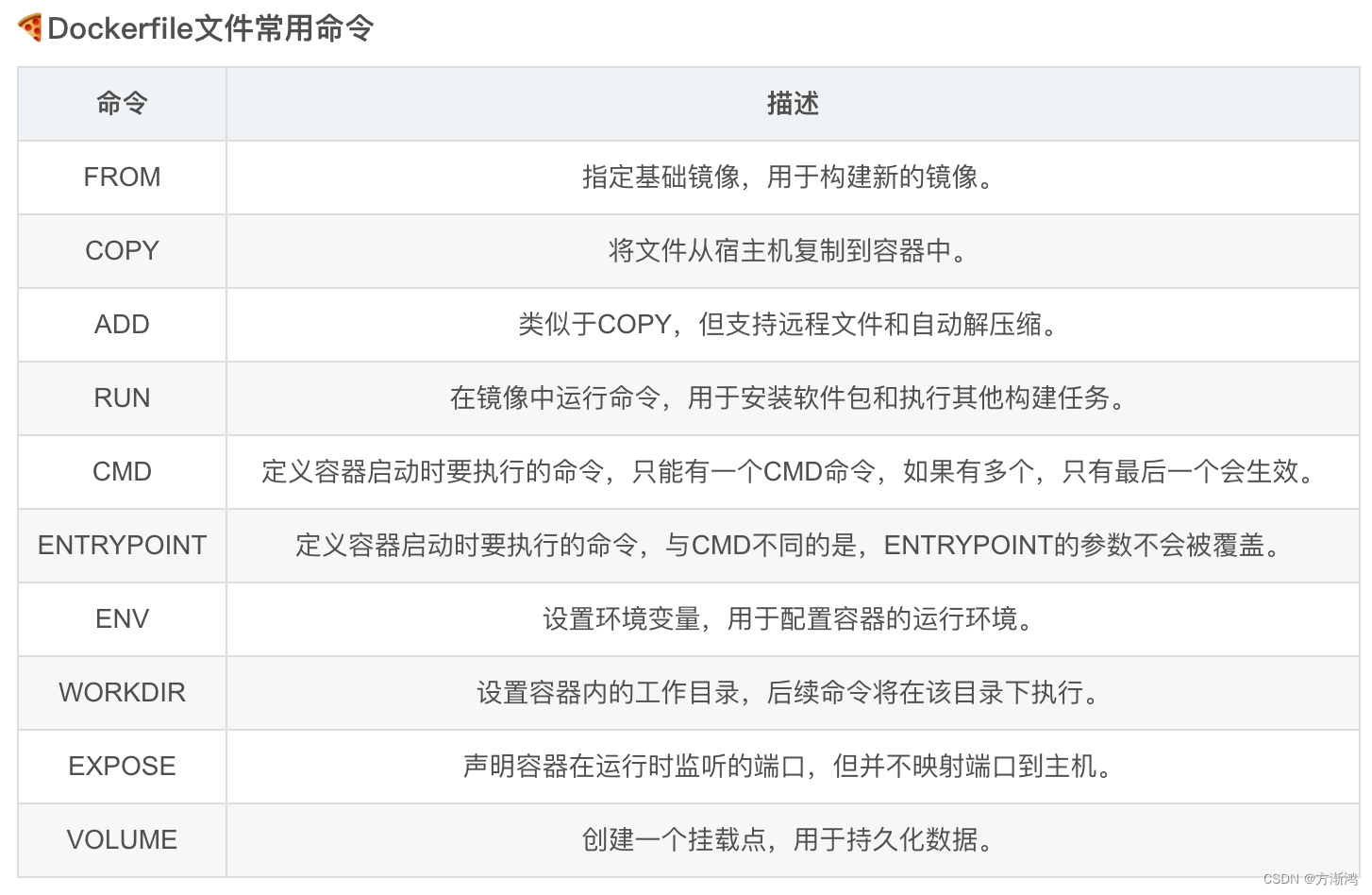
- 创建一个Dockerfile文件
通过Dockerfile文件创建镜像,通过ssh实现可以共用一个局域网
FROM centos:7
MAINTAINER zfp# 添加EPEL源(如果直接是centos的环境可以不用加)
RUN yum install -y epel-release# 安装 openssh-server 和 sudo
RUN yum install -y openssh-server sudo# 修改 SSH 配置文件,禁用 PAM 认证。
RUN sed -i 's/UsePAM yes/UsePAM no/g' /etc/ssh/sshd_config
#安装 OpenSSH 客户端
RUN yum install -y openssh-clients
#配置 SSH 服务
RUN echo "root:123456" | chpasswd
RUN echo "root ALL=(ALL) ALL" >> /etc/sudoers
RUN ssh-keygen -t dsa -f /etc/ssh/ssh_host_dsa_key
RUN ssh-keygen -t rsa -f /etc/ssh/ssh_host_rsa_key
# 创建运行 SSH 服务所需的目录
RUN mkdir /var/run/sshd# 暴露 SSH 端口
EXPOSE 22# 启动 SSH 服务
CMD ["/usr/sbin/sshd", "-D"]- 构建centos7-ssh
docker build -t="centos7-ssh" .
将生成一个名为centos7-ssh的镜像
2.2、创建hadoop的镜像
- 准备需要的包,包需要和Dockerfile在同一级目录下
hadoop的jdk和hive的,该镜像除了hadoop还需要有jdk,所以需要先把jdk的包先准备好,因为要用到hive,我把hive的包也内嵌进去了,所以需要把包先准备好。
- 继续创建一个Dockerfile文件
FROM centos7-sshADD jdk-8u361-linux-x64.tar.gz /usr/local/
#需要确认解压之后的文件名称对不对应得上
RUN mv /usr/local/jdk1.8.0_361 /usr/local/jdk1.8
ENV JAVA_HOME /usr/local/jdk1.8
ENV PATH $JAVA_HOME/bin:$PATHADD hadoop-3.3.4.tar.gz /usr/local
RUN mv /usr/local/hadoop-3.3.4 /usr/local/hadoop
ENV HADOOP_HOME /usr/local/hadoop
ENV PATH $HADOOP_HOME/bin:$PATHADD apache-hive-3.1.3-bin.tar.gz /usr/local
RUN mv /usr/local/apache-hive-3.1.3-bin /usr/local/hive
ENV HIVE_HOME /usr/local/hive
ENV PATH $HIVE_HOME/bin:$PATHRUN yum install -y which sudo
- 构建镜像
docker build -t="centos7-ssh" .
3、配置ssh网络
3.1、搭建同一网段的网络
-
创建网络
docker network create --driver bridge hadoop-br -
配置三台容器的网络,hadoop1因为是主节点,所以需要把web的页面端口映射出来。
docker run -itd --network hadoop-br --name hadoop1 -p 50070:50070 -p 8088:8088 hadoop
docker run -itd --network hadoop-br --name hadoop2 hadoop
docker run -itd --network hadoop-br --name hadoop3 hadoop
- 查看网络
docker network inspect hadoop-br
会看到对应的容器的ip
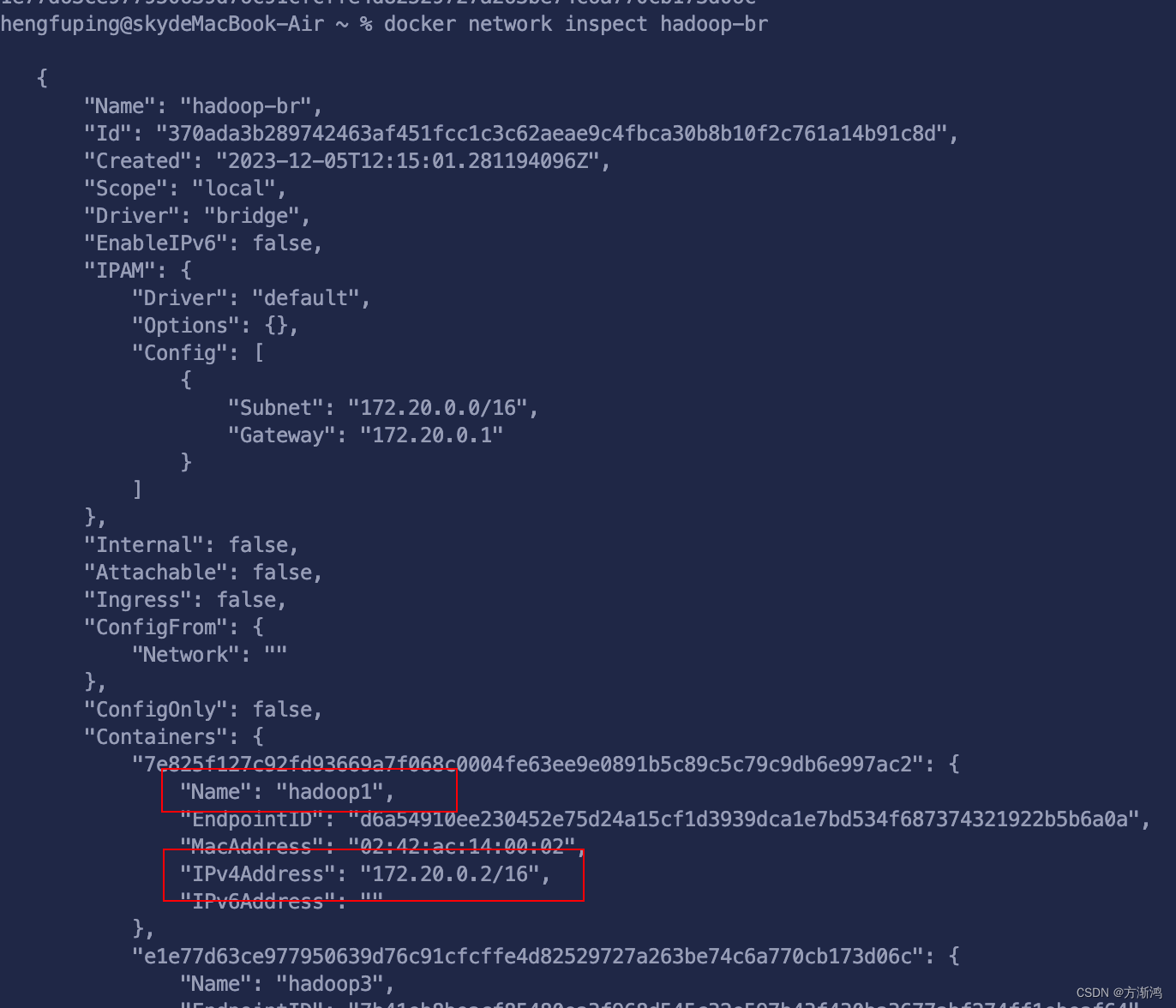
这个是我的,可以看自己的对应的,最后一位会从2开始
172.20.0.2 hadoop1
172.20.0.3 hadoop2
172.20.0.4 hadoop3
3.2、配置host实现互相之间可以免密登陆
- 分别进入不同的容器
docker exec -it hadoop1 bash
docker exec -it hadoop2 bash
docker exec -it hadoop3 bash
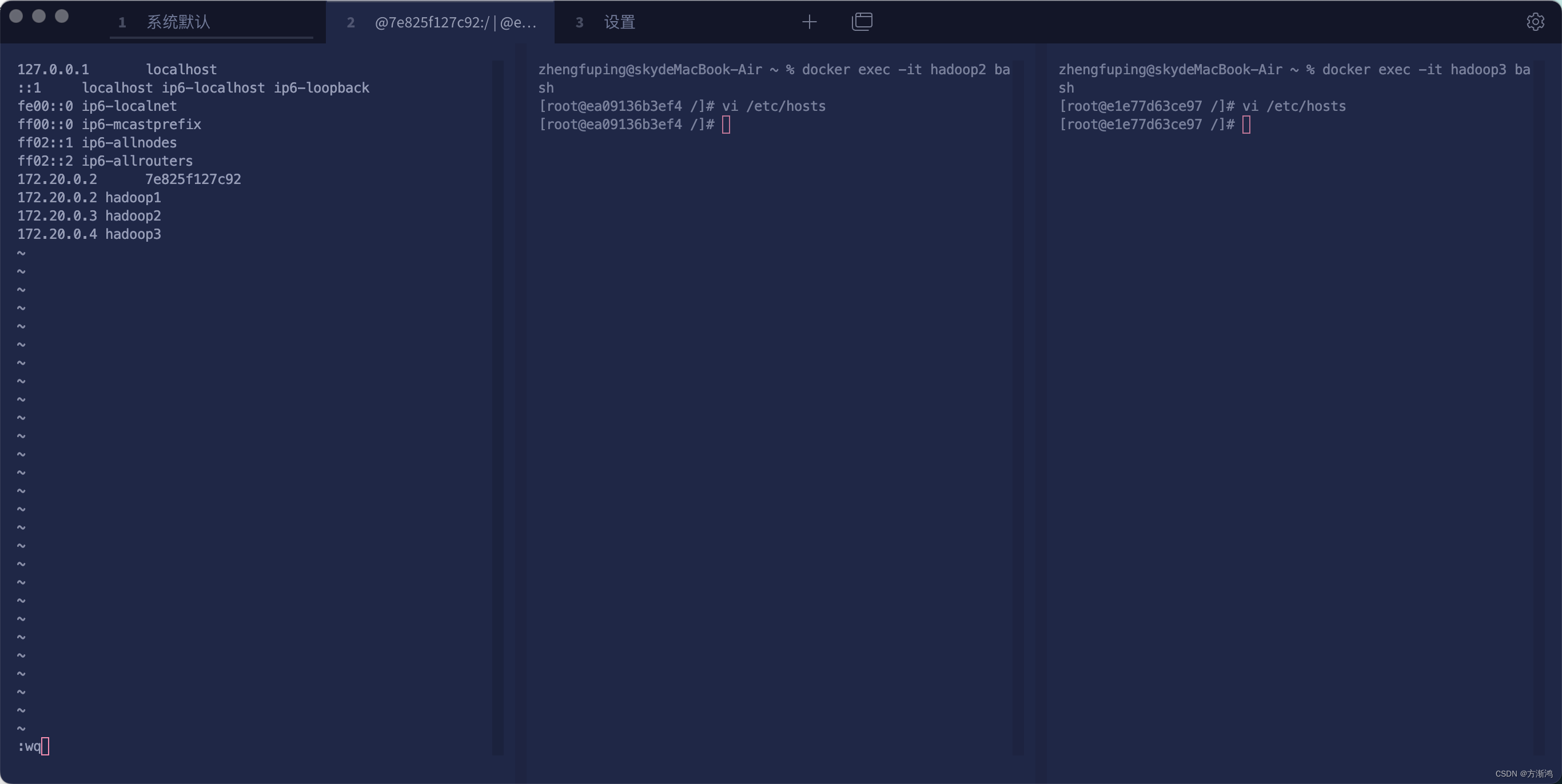
- 编辑文件
vi /etc/hosts
把端口以及名称映射放入该文件内,需要放自己生成的hadoop-br的网络
#这个是我的
172.20.0.2 hadoop1
172.20.0.3 hadoop2
172.20.0.4 hadoop3
- 配置免密登录
前面镜像中已经安装了ssh服务,所以直接分别在每台机器上执行以下命令:
ssh-keygen
一路回车
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop1
输入密码,如果按我的来得话就是123456
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop2
输入密码,如果按我的来得话就是123456
ssh-copy-id -i /root/.ssh/id_rsa -p 22 root@hadoop3
输入密码,如果按我的来得话就是1234563.3、查看是否成功
ping hadoop1
ping hadoop2
ping hadoop3
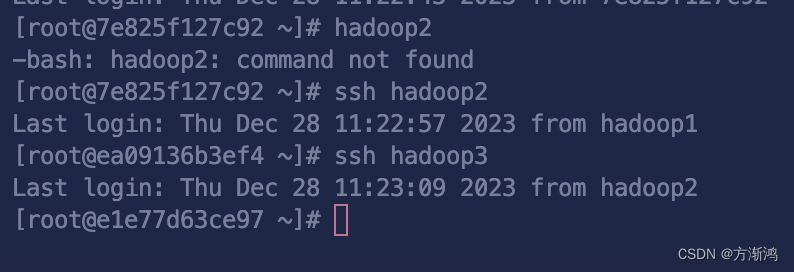
ssh hadoop1
ssh hadoop2
ssh hadoop3如果都可以正常ping通和切换则代表成功
4、安装配置Hadoop
4.1、添加存储文件夹
-
进入容器hadoop1
最好重写进入一下,要不然可能会没有hadoop文件
docker exec -it hadoop1 bash -
创建一些文件夹,用于存储hadoop运行时时产生文件的存储
mkdir /home/hadoop
mkdir /home/hadoop/tmp /home/hadoop/hdfs_name /home/hadoop/hdfs_data
4.2、添加指定配置
都添加在<configuration></configuration>标签内部,确认自己不要粘贴错误,需要先按i,否则粘贴到时候很容易去除掉一些文字
- 编辑core-site.xml:
vi core-site.xml
<!--指定namenode的地址--><property><name>fs.defaultFS</name><value>hdfs://hadoop1:9000</value></property><!--用来指定使用hadoop时产生文件的存放目录--><property><name>hadoop.tmp.dir</name><value>file:/home/hadoop/tmp</value></property><!--用来设置检查点备份日志的最长时间--><property><name>io.file.buffer.size</name><value>131702</value></property>- 编辑hdfs-site.xml:
vi hdfs-site.xml
<!--指定hdfs中namenode的存储位置--><property><name>dfs.namenode.name.dir</name><value>file:/home/hadoop/hdfs_name</value></property><!--指定hdfs中namedata的存储位置--><property><name>dfs.datanode.data.dir</name><value>file:/home/hadoop/hdfs_data</value></property><!--指定hdfs保存数据的副本数量--><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.namenode.secondary.http-address</name><value>hadoop1:9001</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property>- 编辑mapred-site.xml:
该文件部分版本没有,是因为被加了后缀先执行
cp mapred-site.xml.template mapred-site.xml
在去编辑,如果有的就直接编辑就行
vi mapred-site.xml
<!--告诉hadoop以后MR(Map/Reduce)运行在YARN上--><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>hadoop1:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop1:19888</value></property>- 编辑yarn-site.xml:
vi yarn-site.xml
<!--nomenodeManager获取数据的方式是shuffle--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!--指定Yarn的老大(ResourceManager)的地址--> <property><name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property><property><name>yarn.resourcemanager.address</name><value>hadoop1:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>hadoop1:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>hadoop1:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>hadoop1:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>hadoop1:8088</value></property>
- 编辑slaves文件
hadoop1
hadoop2
hadoop3
4.3、同步数据
同步拷贝数据到hadoop2、hadoop3
依次执行以下命令:
scp -r $HADOOP_HOME/ hadoop2:/usr/local/
scp -r $HADOOP_HOME/ hadoop3:/usr/local/scp -r /home/hadoop hadoop2:/
scp -r /home/hadoop hadoop3:/
5、测试启动
5.1、启动配置
- 分别重新连接每台机器
docker exec -it hadoop1 bash
docker exec -it hadoop2 bash
docker exec -it hadoop3 bash- 分别给每台机器配置hadoop sbin目录的环境变量,jdk的也追加一下,要不然可能报错
vi ~/.bashrc或者vi ~/.bash_profile
追加
export PATH=$PATH:$HADOOP_HOME/sbinexport JAVA_HOME=/usr/local/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
- 执行
source ~/.bashrc
5.2、启动hadoop
- 格式化hdfs
hdfs namenode -format
执行一下jps,这个时候应该是只有一个启动的(如果这个命令不行就说明jdk路径压根没配置正确)
- 一键启动
start-all.sh

这个时候如果爆上面的错误,原因是 hadoop-env.sh文件,无法通过标签去读取到jdk的地址
-
修改全部主机的hadoop-env.sh文件
这个时候需要先
cd $HADOOP_HOME/etc/hadoop
去修改
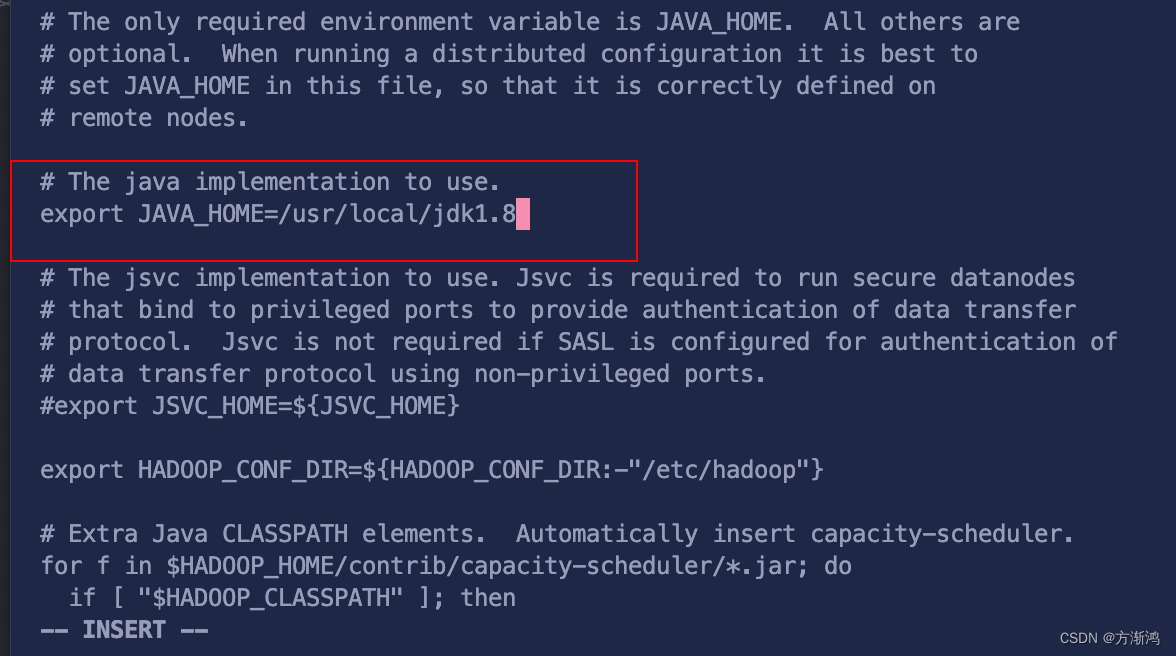
vi hadoop-env.sh文件
找到下面截图的这个位置把地址修改为jdk的实际安装路径,不要是{}的,路径是前面配置的Dockerfile文件时配置的路径
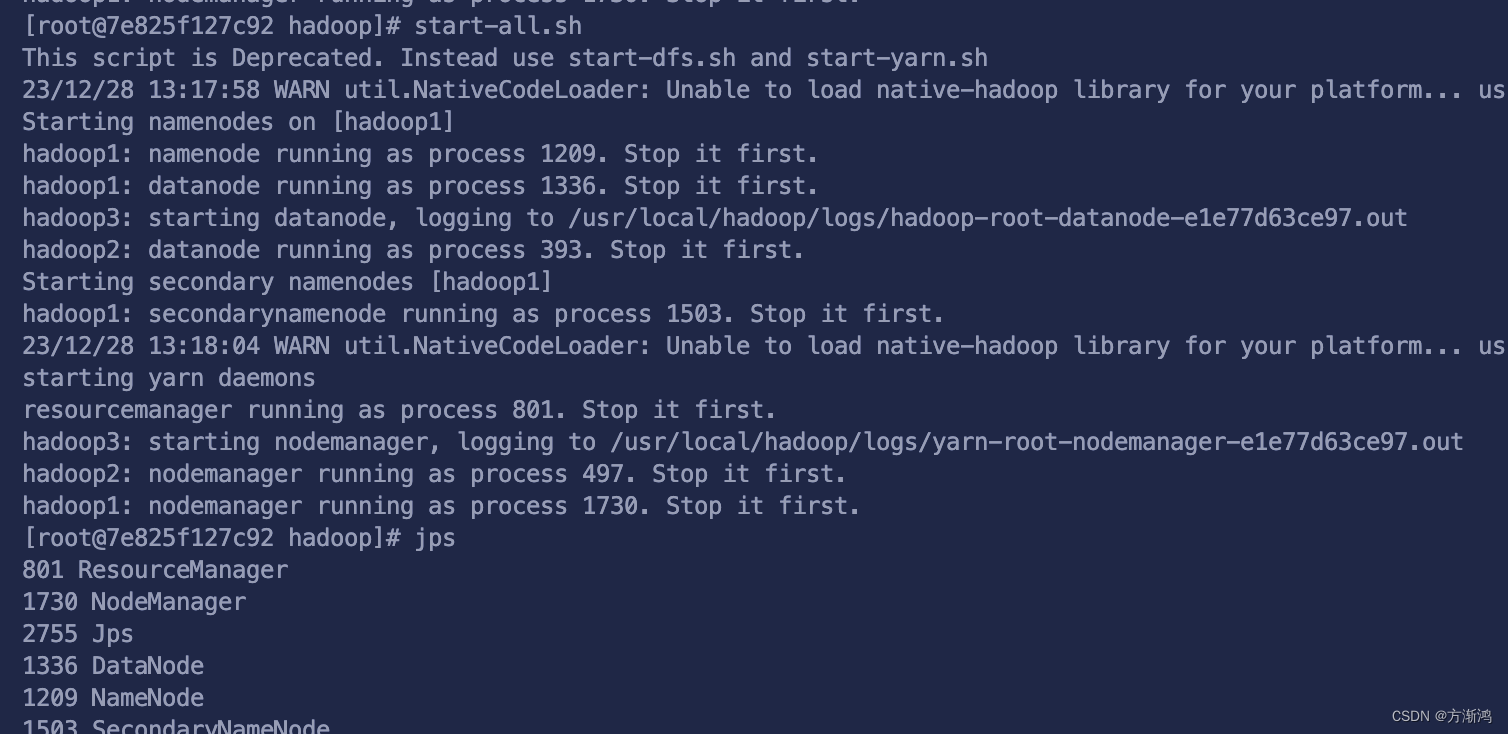
然后在继续执行start-all.sh启动命令,可以通过jps命令看端口是不是变多了,如下应该就是成功啦
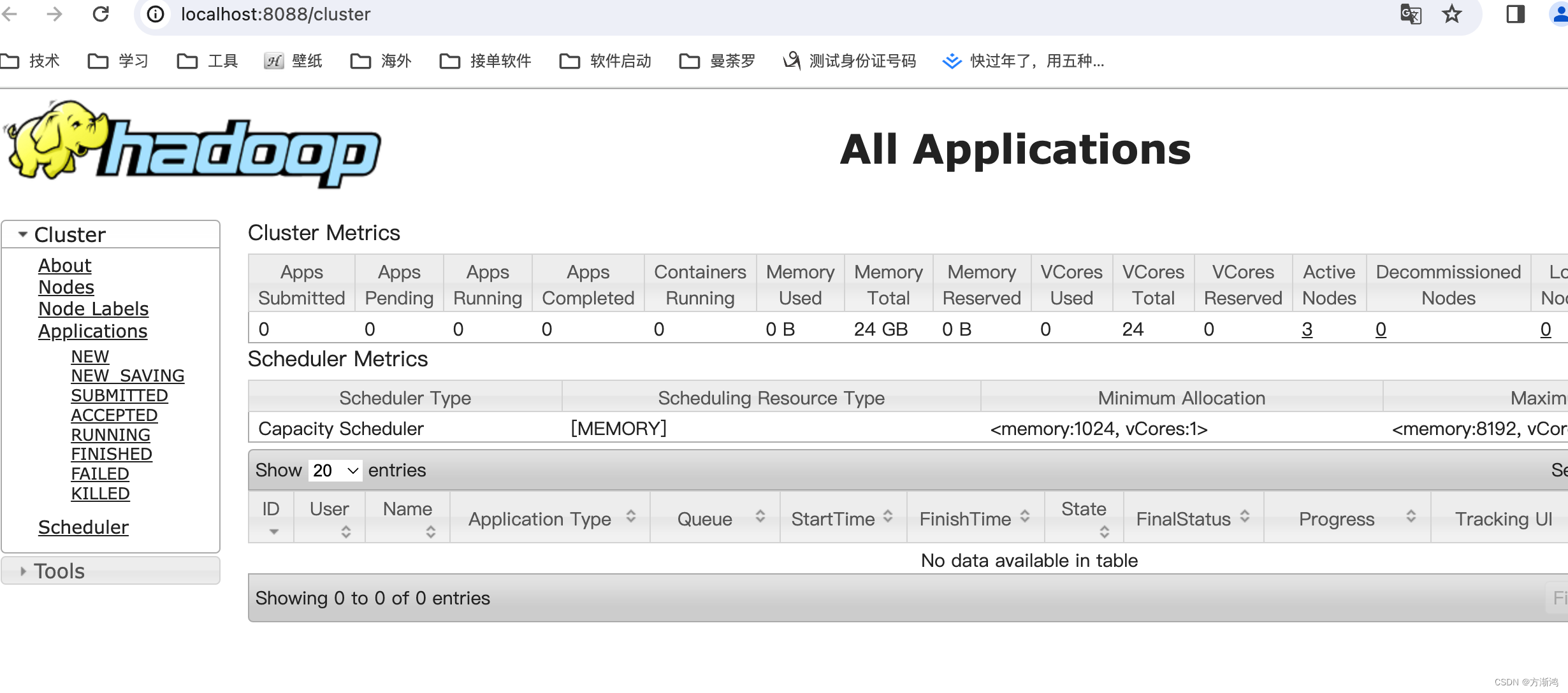
-
最后在到映射出来的web路径去查看
相关文章:
【2023】通过docker安装hadoop以及常见报错
💻目录 1、准备2、安装镜像2.1、创建centos-ssh的镜像2.2、创建hadoop的镜像 3、配置ssh网络3.1、搭建同一网段的网络3.2、配置host实现互相之间可以免密登陆3.3、查看是否成功 4、安装配置Hadoop4.1、添加存储文件夹4.2、添加指定配置4.3、同步数据 5、测试启动5.1…...

Baumer工业相机堡盟工业相机如何通过NEOAPI SDK获取相机当前实时帧率(C++)
Baumer工业相机堡盟工业相机如何通过NEOAPI SDK获取相机当前实时帧率(C) Baumer工业相机Baumer工业相机的帧率的技术背景Baumer工业相机的帧率获取方式CameraExplorer如何查看相机帧率信息在NEOAPI SDK里通过函数获取相机帧率(C) …...

SpringBoot项目部署及多环境
1、多环境 2、项目部署上线 原始前端 / 后端项目宝塔Linux容器容器平台 3、前后端联调 4、项目扩展和规划 多环境 程序员鱼皮-参考文章 本地开发:localhost(127.0.0.1) 多环境:指同一套项目代码在把不同的阶段需要根据实际…...
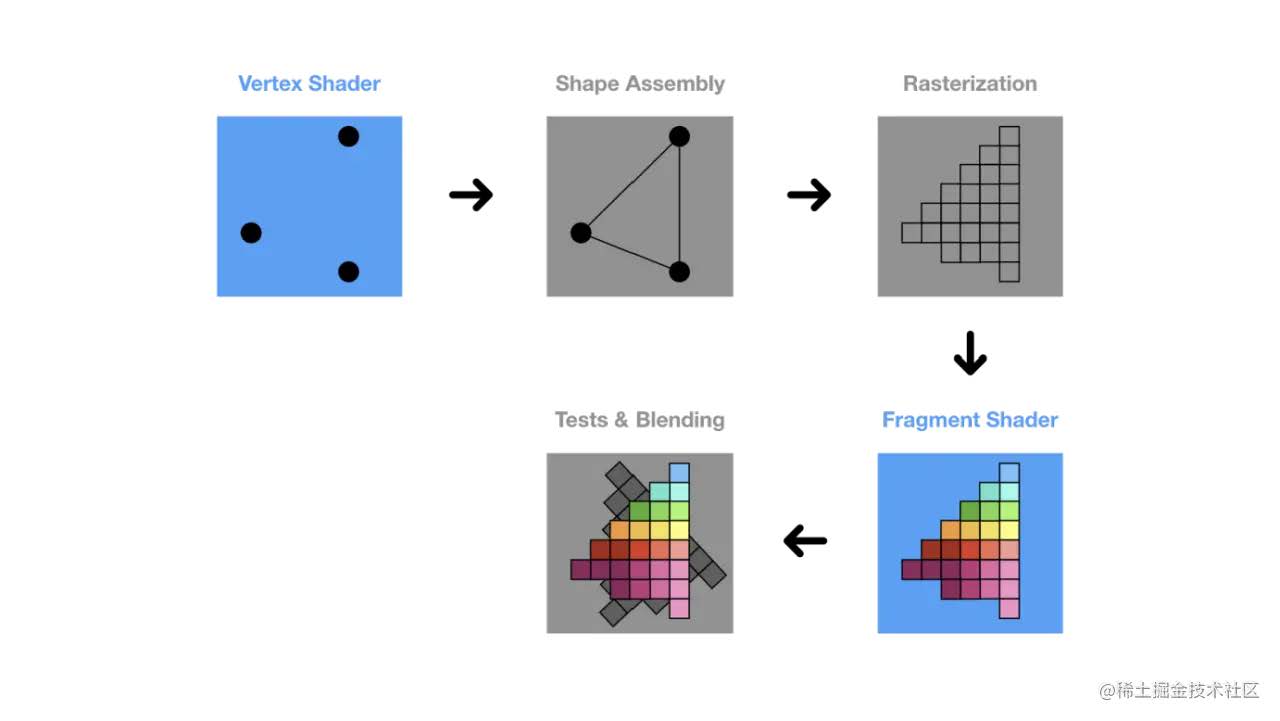
WebGL以及wasm的介绍以及简单应用
简介 下面主要介绍了WebGL和wasm,是除了html,css,js以外Web标准所支持的另外两个大件 前者实现复杂的图形处理,后者提供高效的代码迁移以及代码执行效率 WebGL 简介 首先,浏览器里的游戏是怎么做到这种交互又显示不同的画面的? 试想用我们的前端三件套实现一下.好像可以…...

JS和TS的基础语法学习以及babel的基本使用
简介 本文主要介绍了一下js和ts的基础语法,为前端开发zuo JavaScript 更详细的 JavaScript 学习资料:https://developer.mozilla.org/zh-CN/docs/Web/JavaScript 简介 定位 : JavaScript 是一种动态语言,它包含类型、运算符、标准内置( bu…...

Centos安装Composer
今天分享下如何在centos系统里安装composer 一、下载composer curl -sS https://getcomposer.org/installer | php二、移动或复制composer到环境下可执行 cp composer.phar /usr/local/bin/composer三、测试看是否安装成功 composer -V四、全局安装 curl -sS https://getc…...

面试题:从 MySQL 读取 100w 数据进行处理,应该怎么做?
文章目录 背景常规查询流式查询MyBatis 流式查询接口为什么要用流式查询? 游标查询OptionsResultType注意:原因: 非流式查询和流式查询区别: 背景 大数据量操作的场景大致如下: 数据迁移数据导出批量处理数据 在实际…...
销售转行上位机编程:我的学习与职业经历分享
同学们好,我是杨工,原先是一名销售。 通过在华山编程培训中心学习,成功转行上位机编程,对此我想分享学习和职业经历。 在职业生涯的早期,我并没有考虑将技术融入到我的工作中。然而,在几次创业的失败后&a…...
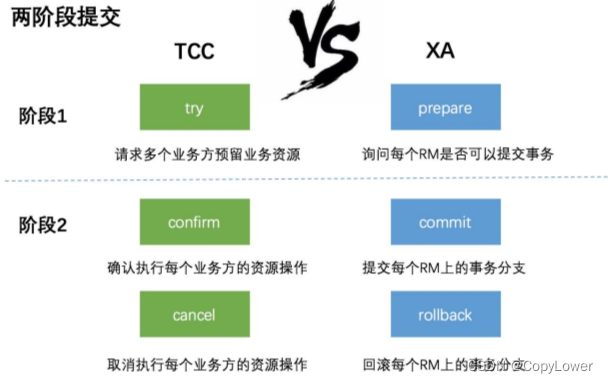
分库分表之Mycat应用学习一
1 为什么要分库分表 1.1 数据库性能瓶颈的出现 对于应用来说,如果数据库性能出现问题,要么是无法获取连接,是因为在高并发的情况下连接数不够了。要么是操作数据变慢,数据库处理数据的效率除了问题。要么是存储出现问题…...

Windows下Qt使用MSVC编译出现需要转为unicode的提示
参考 Qt5中文编码问题解决办法_qt5设置编码-CSDN博客 致敬 提示:warning: C4819: 该文件包含不能在当前代码页(936)中表示的字符。请将该文件保存为 Unicode 格式以防止数据丢失。 出现此问题,应该是Unix格式下代码的编码格式是UTF-8,注意不…...

【数值分析】乘幂法,matlab实现
乘幂法 一种求实矩阵 A {A} A 的按模最大的特征值,及其对应的特征向量 x i {x_i} xi 的方法,只能求一个。特别适合于大型稀疏矩阵。 一个矩阵的特征值和特征向量可以通过矩阵不断乘以一个初始向量得到。 每次乘完之后要规范化,防止上溢或…...

视频监控EasyCVR如何通过设置sei接口,实现在webrtc视频流中添加画框和文字?
安防视频监控系统基于视频综合管理平台EasyCVR视频系统,采用了开放式的网络结构,可以提供实时远程视频监控、视频录像、录像回放与存储、告警、语音对讲、云台控制、平台级联、磁盘阵列存储、视频集中存储、云存储等丰富的视频能力,具备权限管…...

智能三维数据虚拟现实电子沙盘
一、概述 易图讯科技(www.3dgis.top)以大数据、云计算、虚拟现实、物联网、AI等先进技术为支撑,支持高清卫星影像、DEM高程数据、矢量数据、无人机倾斜摄像、BIM模型、点云、城市白模、等高线、标高点等数据融合和切换,智能三维数…...

【SpringCloud】-GateWay源码解析
GateWay系列 【SpringCloud】-GateWay网关 一、背景介绍 当一个请求来到 Spring Cloud Gateway 之后,会经过一系列的处理流程,其中涉及到路由的匹配、过滤器链的执行等步骤。今天我们来说说请求经过 Gateway 的主要执行流程和原理是什么吧 二、正文 …...
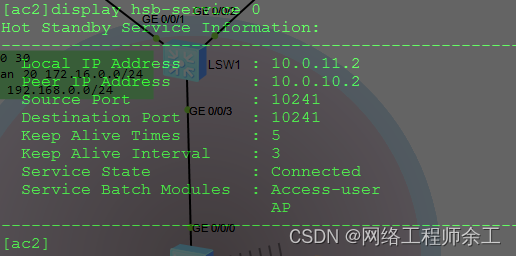
华为无线ac双链路冷备和热备配置案例
所谓的冷备和热备,冷备就是不用vrrp和hsb协议同步ap和用户信息,主的断了等七十五秒后,备的capwap和ap连接上去。 双链路冷备不用vrrp和hsb 双链路热备份只用hsb同步ap和用户信息,不用vrrp,两个ac可以不用在同一个二层…...
VSCode Python开发环境配置
目录 1 插件安装2 Debug和测试配置常见问题 1 插件安装 1.1 基础编译插件,Python、Pylance 1.2 修改语言服务器类型,进入用户配置页面搜索Python: Language Server,选择Pylance(一定要修改可以提供很多语法提示) 1…...

浅谈【GPU和CPU】
GPU和显卡的区别 GPU(Graphics Processing Unit,图形处理器)通常指的就是显卡。显卡是一种安装在计算机中的扩展卡,主要用于图形和图像处理任务。 GPU作为显卡的核心组件,负责处理图形渲染、图像处理、视频解码和其他…...
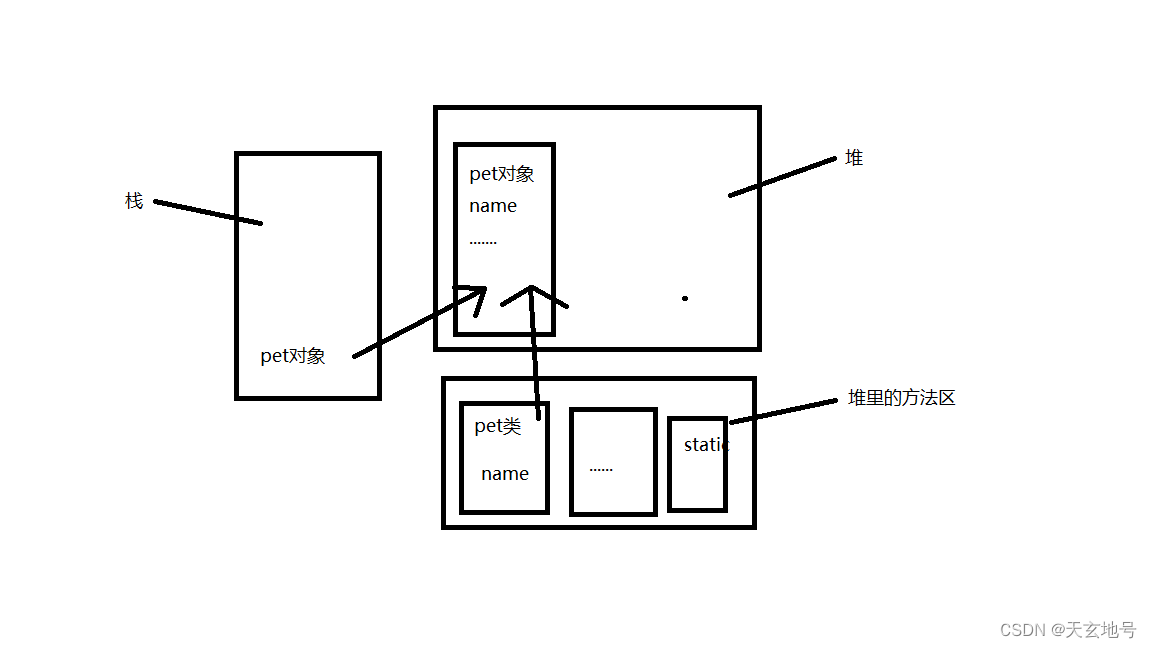
啥是构造器?
当我们new一个对象时就是在引用构造器 构造器又叫做构造函数 构造函数一般分为无参构造函数与有参构造函数 假设我们创建一个pet类,这个类里面就会有一个看不见的自动生成的无参构造函数 如果pet类里没有这个隐形的无参构造,我们new一个对象时就会报错…...

Linux基础知识学习2
tree命令的使用 可以看到dir2目录下的这些文件,要想显示dir2的具体结构,可用tree命令 mv命令 它可以实现两个功能 1.将文件移动到另一个目录中 2.对某一个文件进行重命名 1.将文件移动到另一个目录中 这里将dir1中的2.txt移动到他的子目录dir3中 执行…...

Grafana二进制部署并配置prometheus数据源
1、获取grafna二进制安装包 https://grafana.com/grafana/download?pggraf&plcmtdeploy-box-1 grafana官网下载地址 [rootambari-hadoop1 ~]# cd /opt/module/grafana/ [rootambari-hadoop1 grafana]# pwd /opt/module/grafana2、在安装自己的安装目录执行 wget https:…...

Span<T>不是语法糖!透过CoreCLR源码看JIT如何为ref struct生成特殊栈帧——稀缺的底层机制白皮书
第一章:Span<T>不是语法糖!透过CoreCLR源码看JIT如何为ref struct生成特殊栈帧——稀缺的底层机制白皮书Span 是 C# 7.2 引入的 ref struct 类型,它**无法被装箱、不能作为字段存储在托管堆类中、也不允许跨 await 边界捕获**——这些限…...

性价比高的南昌实体店线上获客哪个靠谱
在南昌,实体店想要在竞争激烈的市场中脱颖而出,线上获客是关键。然而,面对众多的线上获客途径,哪个才靠谱且性价比高呢?今天,我们就来详细探讨一下,同时为大家推荐南昌琨瑜象限本地生活运营服务…...

MySQL 主从延迟根因诊断法
📌 解决思路:从网络、IO、SQL 到参数,系统化定位高并发下的同步瓶颈 📌 适用版本:MySQL 5.7 / 8.0 📌 适用场景:高并发写入、主从延迟告警、从库追不上主库 目录 一、先量化延迟:别…...
)
PaddlePaddle-GPU环境配置:为什么你的显卡总是被识别成CPU?(附解决方案)
PaddlePaddle-GPU环境配置:为什么你的显卡总是被识别成CPU?(附解决方案) 刚拿到新显卡准备大展拳脚,却发现PaddlePaddle死活不认GPU,这种挫败感我太懂了。明明花大价钱买的显卡,结果深度学习训…...

高压输电线路智能监测系统设计与实现
1. 项目背景与需求分析高压输电线路作为电力系统的"大动脉",其稳定运行直接关系到整个电网的安全。我在电力行业工作多年,亲眼见过多次因间隔棒故障导致的线路跳闸事故。传统的人工巡检方式存在明显短板:巡检周期长(通常…...

大模型之Linux服务器部署大模型斜
一、各自优势和对比 这是检索出来的数据,据说是根据第三方评测与企业数据,三款产品在代码生成质量上各有侧重: 产品 语言优势 场景亮点 核心差异 百度 Comate C核心代码质量第一;Python首生成率达92.3% SQL生成准确率提升35%&…...

从原理到实战:LRU缓存算法的核心机制与工程实践
1. LRU缓存算法的基础原理 最近最少使用(LRU)算法是每个后端工程师都应该掌握的缓存淘汰策略。我第一次在线上系统使用LRU时,发现它完美解决了我们的缓存击穿问题。简单来说,LRU就像图书馆里整理书籍的管理员——总是把最近被借阅…...

紧急预警:.NET 9 RC2已移除旧版LowCodeProvider——所有基于.NET 8低代码框架的项目须在2024年11月30日前完成迁移,否则将触发运行时降级熔断
第一章:.NET 9 低代码开发范式演进与熔断机制全景概览.NET 9 将低代码能力深度融入平台原生架构,不再依赖第三方可视化设计器,而是通过源生成器(Source Generators)、属性驱动的组件注册、以及声明式 UI 模型ÿ…...

【C# 13高性能内存编程终极指南】:Span<T> 7大生产级扩展模式首次公开,微软内部文档未披露的3个关键约束条件
第一章:Span<T>在C# 13中的核心演进与内存语义重构C# 13 对 Span<T> 的底层实现与语言集成进行了深度优化,不再仅将其视为高性能切片工具,而是重构为具备显式内存生命周期契约的一等公民。编译器现在能对 Span<T> 变量执行…...

从DINO Score到LLaVA:拆解SPAA论文如何用“双考官”机制筛选高质量AI修图
从DINO Score到LLaVA:构建AI图像编辑的"双考官"质量评估体系 在AI图像编辑技术快速发展的今天,如何系统评估生成结果的质量已成为产品落地的关键瓶颈。传统方法往往依赖人工审核或单一指标,既难以规模化又无法全面捕捉图像修改的语…...