分库分表之Mycat应用学习一
1 为什么要分库分表
1.1 数据库性能瓶颈的出现
对于应用来说,如果数据库性能出现问题,要么是无法获取连接,是因为在高并发的情况下连接数不够了。要么是操作数据变慢,数据库处理数据的效率除了问题。要么是存储出现问题,比如单机存储的数据量太大了,存储的问题也可能会导致性能的问题。
归根结底都是受到了硬件的限制,比如 CPU,内存,磁盘,网络等等。但是我们优化肯定不可能直接从扩展硬件入手,因为带来的收益和成本投入比例太比。
所以我们先来分析一下,当我们处理数据出现无法连接,或者变慢的问题的时候,我们可以从哪些层面入手。
1.2 数据库优化方案对比
数据库优化有很多层面
1.2.1 SQL 与索引
因为 SQL 语句是在我们的应用端编写的,所以第一步,我们可以在程序中对 SQL 语句进行优化,最终的目标是用到索引。这个是容易的也是最常用的优化手段。
1.2.2 表与存储引擎
第二步,数据是存放在表里面的,表又是以不同的格式存放在存储引擎中的,所以我们可以选用特定的存储引擎,或者对表进行分区,对表结构进行拆分或者冗余处理,或者对表结构比如字段的定义进行优化。
1.2.3 架构
第三步,对于数据库的服务,我们可以对它的架构进行优化。
如果只有一台数据库的服务器,我们可以运行多个实例,做集群的方案,做负载均衡。
或者基于主从复制实现读写分离,让写的服务都访问 master 服务器,读的请求都访问从服务器,slave 服务器自动 master 主服务器同步数据。
或者在数据库前面加一层缓存,达到减少数据库的压力,提升访问速度的目的。
为了分散数据库服务的存储压力和访问压力,我们也可以把不同的数据分布到不同的服务节点,这个就是分库分表(scale out)。
注意主从(replicate)和分片(shard)的区别:
主从通过数据冗余实现高可用,和实现读写分离。
分片通过拆分数据分散存储和访问压力。
1.2.4 配置
第四步,是数据库配置的优化,比如连接数,缓冲区大小等等,优化配置的目的都是为了更高效地利用硬件。
1.2.5 操作系统与硬件
最后一步操作系统和硬件的优化。
从上往下,成本收益比慢慢地在增加。所以肯定不是查询一慢就堆硬件,堆硬件叫做向上的扩展(scale up)。
什么时候才需要分库分表呢?我们的评判标准是什么?
如果是数据量的话,一张表存储了多少数据的时候,才需要考虑分库分表?
如果是数据增长速度的话,每天产生多少数据,才需要考虑做分库分表?
如果是应用的访问情况的话,查询超过了多少时间,有多少请求无法获取连接,才需要分库分表?这是一个值得思考的问题。
1.3 架构演进与分库分表
1.3.1 单应用单数据库
2013 年的时候,我们公司采购了一个消费金融核心系统,这个是一个典型的单体架构的应用。同学们应该也很熟悉,单体架构应用的特点就是所有的代码都在一个工程里面,打成一个 war 包部署到 tomcat,最后运行在一个进程中。
这套消费金融的核心系统,用的是 Oracle 的数据库,初始化以后有几百张表,比如客户信息表、账户表、商户表、产品表、放款表、还款表等等

为了适应业务的发展,我们这一套系统不停地在修改,代码量越来越大,系统变得越来越臃肿。为了优化系统,我们搭集群,负载均衡,加缓存,优化数据库,优化业务代码系统,但是都应对不了系统的访问压力。
所以这个时候系统拆分就势在必行了。我们把以前这一套采购的核心系统拆分出来很多的子系统,比如提单系统、商户管理系统、信审系统、合同系统、代扣系统、催收系统,所有的系统都依旧共用一套 Oracle 数据库
1.3.2 多应用单数据库
对代码进行了解耦,职责进行了拆分,生产环境出现问题的时候,可以快速地排查和解决
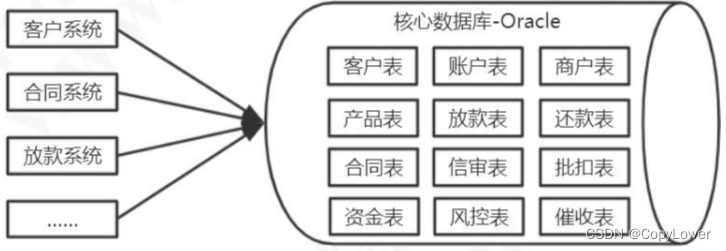
这种多个子系统共用一个 DB 的架构,会出现一些问题。
第一个就是所有的业务系统都共用一个 DB,无论是从性能还是存储的角度来说,都是满足不了需求的。随着我们的业务继续膨胀,我们又会增加更多的系统来访问核心数据库,但是一个物理数据库能够支撑的并发量是有限的,所有的业务系统之间还会产生竞争,最终会导致应用的性能下降,甚至拖垮业务系统。
1.3.3 多应用独立数据库
所以这个时候,我们必须要对各个子系统的数据库也做一个拆分。这个时候每个业务系统都有了自己的数据库,不同的业务系统就可以用不同的存储方案。
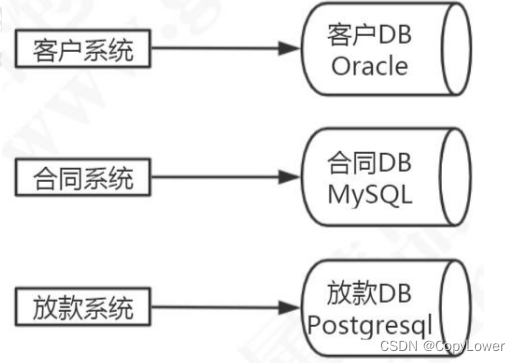
所以,分库其实是我们在解决系统性能问题的过程中,对系统进行拆分的时候带来的一个必然的结果。现在的微服务架构也是一样的,只拆应用不拆分数据库,不能解决根本的问题。
1.3.4 什么时候分表?
当我们对原来一个数据库的表做了分库以后,其中一些表的数据还在以一个非常快的速度在增长,这个时候查询也已经出现了非常明显的效率下降。
所以,在分库之后,还需要进一步进行分表。当然,我们最开始想到的可能是在一个数据库里面拆分数据,分区或者分表,到后面才是切分到多个数据库中。
分表主要是为了减少单张表的大小,解决单表数据量带来的性能问题
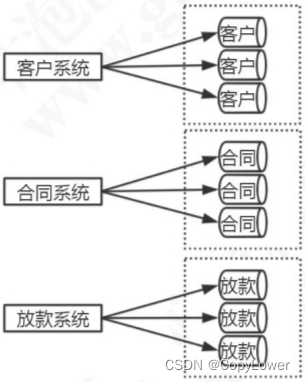
我们需要清楚的是,分库分表会提升系统的复杂度,如果在近期或者未来一段时间内必须要解决存储和性能的问题,就不要去做超前设计和过度设计。就像我们搭建项目,从快速实现的角度来说,肯定是从单体项目起步的,在业务丰富完善之前,也用不到微服务架构。
如果我们创建的表结构合理,字段不是太多,并且索引创建正确的情况下,单张表存储几千万的数据是完全没有问题的,这个还是以应用的实际情况为准。当然我们也会对未来一段时间的业务发展做一个预判。
2 分库分表的类型和特点
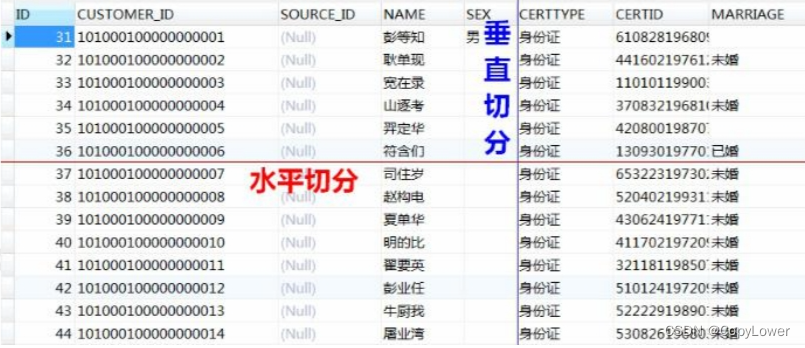
从维度来说分成两种,一种是垂直,一种是水平。
垂直切分:基于表或字段划分,表结构不同。我们有单库的分表,也有多库的分库。
水平切分:基于数据划分,表结构相同,数据不同,也有同库的水平切分和多库的切分。
2.1 垂直切分
垂直分表有两种,一种是单库的,一种是多库的。
2.1.1 单库垂直分表
单库分表,比如:商户信息表,拆分成基本信息表,联系方式表,结算信息表,附件表等等。
2.1.2 多库垂直分表
多库垂直分表就是把原来存储在一个库的不同的表,拆分到不同的数据库。
比如:消费金融核心系统数据库,有很多客户相关的表,这些客户相关的表,全部单独存放到客户的数据库里面。合同,放款,风控相关的业务表也是一样的。
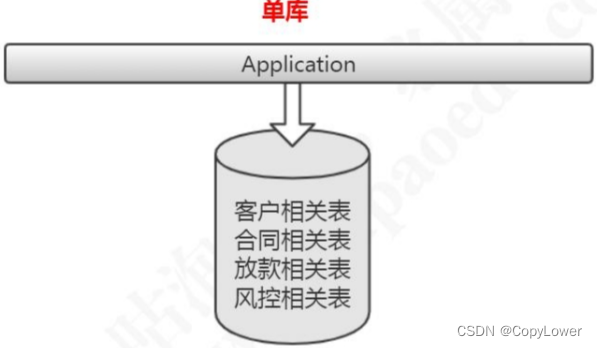
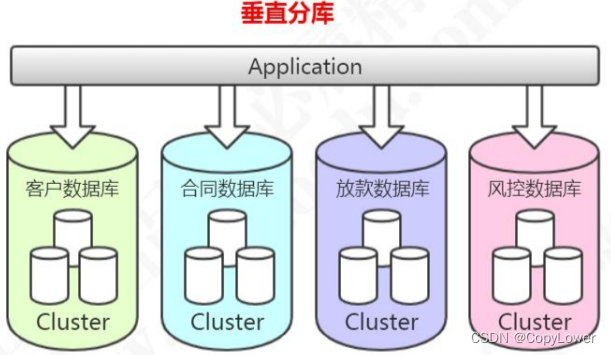
当我们对原来的一张表做了分库的处理,如果某些业务系统的数据还是有一个非常快的增长速度,比如说还款数据库的还款历史表,数据量达到了几个亿,这个时候硬件限制导致的性能问题还是会出现,所以从这个角度来说垂直切分并没有从根本上解决单库单表数据量过大的问题。在这个时候,我们还需要对我们的数据做一个水平的切分。
2.2 水平切分
当我们的客户表数量已经到达数千万甚至上亿的时候,单表的存储容量和查询效率都会出现问题,我们需要进一步对单张表的数据进行水平切分。水平切分的每个数据库的表结构都是一样的,只是存储的数据不一样,比如每个库存储 1000 万的数据。水平切分也可以分成两种,一种是单库的,一种是多库的
2.2.1 单库水平分表
银行的交易流水表,所有进出的交易都需要登记这张表,因为绝大部分时候客户都是查询当天的交易和一个月以内的交易数据,所以我们根据使用频率把这张表拆分成三张表:
当天表:只存储当天的数据。
当月表:在夜间运行一个定时任务,前一天的数据,全部迁移到当月表。用的是 insert into select,然后 delete。
历史表:同样是通过定时任务,把登记时间超过 30 天的数据,迁移到 history
历史表(历史表的数据非常大,我们按照月度,每个月建立分区)
费用表:
消费金融公司跟线下商户合作,给客户办理了贷款以后,消费金融公司要给商户返费用,或者叫提成,每天都会产生很多的费用的数据。为了方便管理,我们每个月建立一张费用表,例如 fee_detail_201901……fee_detail_201912。
但是注意,跟分区一样,这种方式虽然可以一定程度解决单表查询性能的问题,但是并不能解决单机存储瓶颈的问题
2.2.2 多库水平分表
另一种是多库的水平分表。比如客户表,我们拆分到多个库存储,表结构是完全一
样的。
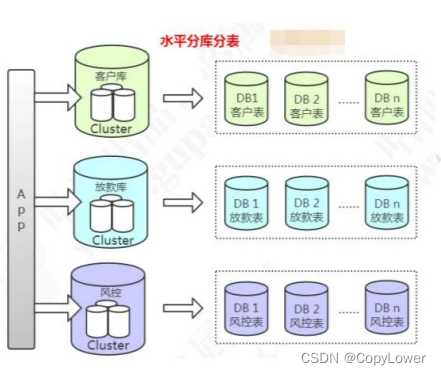
一般我们说的分库分表都是跨库的分表。
既然分库分表能够帮助我们解决性能的问题,那我们是不是马上动手去做,甚至在项目设计的时候就先给它分几个库呢?先冷静一下,我们来看一下分库分表会带来哪些问题,也就是我们前面说的分库分表之后带来的复杂性。
2.3 多案分库分表带来的问题
2.3.1 跨库关联查询
比如查询在合同信息的时候要关联客户数据,由于是合同数据和客户数据是在不同的数据库,那么我们肯定不能直接使用 join 的这种方式去做关联查询。
我们有几种主要的解决方案:
1、字段冗余
比如我们查询合同库的合同表的时候需要关联客户库的客户表,我们可以直接把一些经常关联查询的客户字段放到合同表,通过这种方式避免跨库关联查询的问题。
2、数据同步:比如商户系统要查询产品系统的产品表,我们干脆在商户系统创建一张产品表,通过 ETL 或者其他方式定时同步产品数据。
3、全局表(广播表) 比如行名行号信息被很多业务系统用到,如果我们放在核心系统,每个系统都要去关联查询,这个时候我们可以在所有的数据库都存储相同的基础数据。
4、ER 表(绑定表)
我们有些表的数据是存在逻辑的主外键关系的,比如订单表 order_info,存的是汇总的商品数,商品金额;订单明细表 order_detail,是每个商品的价格,个数等等。或者叫做从属关系,父表和子表的关系。他们之间会经常有关联查询的操作,如果父表的数据和子表的数据分别存储在不同的数据库,跨库关联查询也比较麻烦。所以我们能不能把父表和数据和从属于父表的数据落到一个节点上呢?
比如 order_id=1001 的数据在 node1,它所有的明细数据也放到 node1;order_id=1002 的数据在 node2,它所有的明细数据都放到 node2,这样在关联查询的时候依然是在一个数据库。
上面的思路都是通过合理的数据分布避免跨库关联查询,实际上在我们的业务中,也是尽量不要用跨库关联查询,如果出现了这种情况,就要分析一下业务或者数据拆分是不是合理。如果还是出现了需要跨库关联的情况,那我们就只能用最后一种办法。
5、系统层组装
在不同的数据库节点把符合条件数据的数据查询出来,然后重新组装,返回给客户端。
2.3.2 分布式事务
比如在一个贷款的流程里面,合同系统登记了数据,放款系统也必须生成放款记录,如果两个动作不是同时成功或者同时失败,就会出现数据一致性的问题。如果在一个数据库里面,我们可以用本地事务来控制,但是在不同的数据库里面就不行了。所以分布式环境里面的事务,我们也需要通过一些方案来解决。
复习一下。分布式系统的基础是 CAP 理论。
1.C (一致性) Consistency:对某个指定的客户端来说,读操作能返回最新的写操作。对于数据分布在不同节点上的数据来说,如果在某个节点更新了数据,那么在其他节点如果都能读取到这个最新的数据,那么就称为强一致,如果有某个节点没有读取到,那就是分布式不一致。
2.A (可用性) Availability:非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。可用性的两个关键一个是合理的时间,一个是合理的响应。合理的时间指的是请求不能无限被阻塞,应该在合理的时间给出返回。合理的响应指的是系统应该明确返回结果并且结果是正确的
3.P (分区容错性) Partition tolerance:当出现网络分区后,系统能够继续工作。打个比方,这里集群有多台机器,有台机器网络出现了问题,但是这个集群仍然可以正工作。
CAP 三者是不能共有的,只能同时满足其中两点。基于 AP,我们又有了 BASE 理论。基本可用(Basically Available):分布式系统在出现故障时,允许损失部分可用功能,保证核心功能可用。
软状态(Soft state):允许系统中存在中间状态,这个状态不影响系统可用性,这里指的是 CAP 中的不一致。
最终一致(Eventually consistent):最终一致是指经过一段时间后,所有节点数据都将会达到一致。
分布式事务有几种常见的解决方案:
1、全局事务(比如 XA 两阶段提交;应用、事务管理器™、资源管理器(DB)),例如 Atomikos
2、基于可靠消息服务的分布式事务
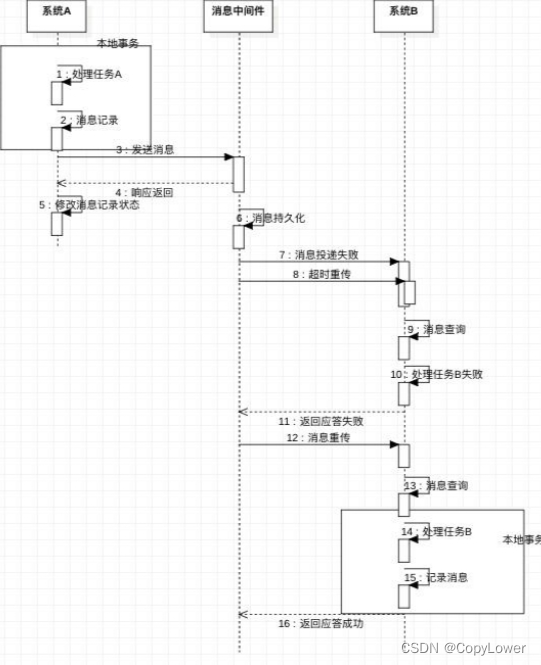
3、柔性事务 TCC(Try-Confirm-Cancel)tcc-transaction
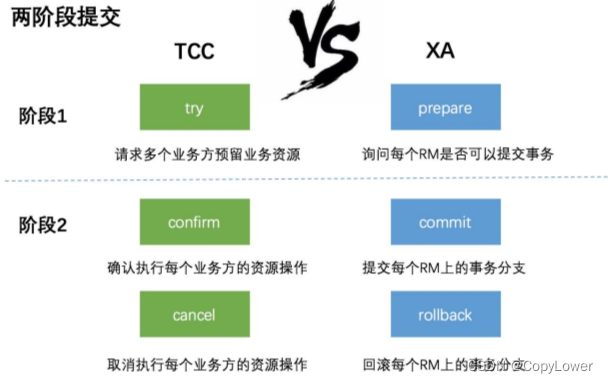
4、最大努力通知,通过消息中间件向其他系统发送消息(重复投递+定期校对)
2.3.3 排序、翻页、函数计算问题
跨节点多库进行查询时,会出现 limit 分页,order by 排序的问题。比如有两个节点,节点 1 存的是奇数 id=1,3,5,7,9……;节点 2 存的是偶数 id=2,4,6,8,10……
执行 select * from user_infoorder by id limit 0,10
需要在两个节点上各取出 10 条,然后合并数据,重新排序。
max、min、sum、count 之类的函数在进行计算的时候,也需要先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总和再次计算,最终将结果返回
2.3.4 全局主键避重问题
MySQL 的数据库里面字段有一个自增的属性,Oracle 也有 Sequence 序列。如果是一个数据库,那么可以保证 ID 是不重复的,但是水平分表以后,每个表都按照自己的规律自增,肯定会出现 ID 重复的问题,这个时候我们就不能用本地自增的方式了。
我们有几种常见的解决方案:
1)UUID(Universally Unique Identifier 通用唯一识别码)
UUID 标准形式包含 32 个 16 进制数字,分为 5 段,形式为 8-4-4-4-12 的 36 个字符,例如:c4e7956c-03e7-472c-8909-d733803e79a9。
M 表示 UUID 版本,目前只有五个版本,即只会出现 1,2,3,4,5,数字 N 的一至三个最高有效位表示 UUID 变体,目前只会出现 8,9,a,b 四种情况
1、基于时间和 MAC 地址的 UUID
2、基于第一版却更安全的 DCE UUID
3、基于 MD5 散列算法的 UUID
4、基于随机数的 UUID——用的最多,JDK 里面是 4
5、基于 SHA1
UUID 是主键是最简单的方案,本地生成,性能高,没有网络耗时。但缺点也很明显,由于 UUID 非常长,会占用大量的存储空间;另外,作为主键建立索引和基于索引进行查询时都会存在性能问题,在 InnoDB 中,UUID 的无序性会引起数据位置频繁变动,导致分页。
2) 数据库
把序号维护在数据库的一张表中。这张表记录了全局主键的类型、位数、起始值,当前值。当其他应用需要获得全局 ID 时,先 for update 锁行,取到值+1 后并且更新后返回。并发性比较差
3)Redis
基于 Redis 的 INT 自增的特性,使用批量的方式降低数据库的写压力,每次获取一段区间的 ID 号段,用完之后再去数据库获取,可以大大减轻数据库的压力。
4)雪花算法 Snowflake(64bit)
核心思想:
a)使用 41bit 作为毫秒数,可以使用 69 年
b)10bit 作为机器的 ID(5bit 是数据中心,5bit 的机器 ID),支持 1024 个
节点
c)12bit 作为毫秒内的流水号(每个节点在每毫秒可以产生 4096 个 ID)
d)最后还有一个符号位,永远是 0。
代码:snowflake.SnowFlakeTest
优点:毫秒数在高位,生成的 ID 整体上按时间趋势递增;不依赖第三方系统,稳定性和效率较高,理论上 QPS 约为 409.6w/s(1000*2^12),并且整个分布式系统内不会产生 ID 碰撞;可根据自身业务灵活分配 bit 位。
不足就在于:强依赖机器时钟,如果时钟回拨,则可能导致生成 ID 重复。
当我们对数据做了切分,分布在不同的节点上存储的时候,是不是意味着会产生多个数据源?既然有了多个数据源,那么在我们的项目里面就要配置多个数据源。
现在问题就来了,我们在执行一条 SQL 语句的时候,比如插入,它应该是在哪个数据节点上面执行呢?又比如查询,如果只在其中的一个节点上面,我怎么知道在哪个节点,是不是要在所有的数据库节点里面都查询一遍,才能拿到结果?
那么,从客户端到服务端,我们可以在哪些层面解决这些问题呢?
2.4 多数据源/读写数据源的解决方案
我们先要分析一下 SQL 执行经过的流程。
DAO——Mapper(ORM)——JDBC——代理——数据库服务
2.4.1 客户端 DAO 层
第一个就是在我们的客户端的代码,比如 DAO 层,在我们连接到某一个数据源之前,我们先根据配置的分片规则,判断需要连接到哪些节点,再建立连接。
Spring 中提供了一个抽象类 AbstractRoutingDataSource,可以实现数据源的动态切换。
SSM 工程:spring-boot-dynamic-data-source-master
步骤:
1)aplication.properties 定义多个数据源
2)创建@TargetDataSource 注解
3)创建 DynamicDataSource 继承 AbstractRoutingDataSource
4)多数据源配置类 DynamicDataSourceConfig
5)创建切面类 DataSourceAspect,对添加了@TargetDataSource 注解的类进行拦截设置数据源。
6)在 启 动 类 上 自 动 装 配 数 据 源 配 置@Import({DynamicDataSourceConfig.class})
7)在 实 现 类 上 加 上 注 解 , 如 @TargetDataSource(name = DataSourceNames.SECOND),调用在 DAO 层实现的优势:不需要依赖 ORM 框架,即使替换了 ORM 框架也不受影响。实现简单(不需要解析 SQL 和路由规则),可以灵活地定制。
缺点:不能复用,不能跨语言
2.4.2 ORM 框架层
第二个是在框架层,比如我们用 MyBatis 连接数据库,也可以指定数据源。我们可以基于 MyBatis 插件的拦截机制(拦截 query 和 update 方法),实现数据源的选择。
例如:https://github.com/colddew/shardbatis
https://docs.jboss.org/hibernate/stable/shards/reference/en/html_single/
2.4.3 驱动层
不管是MyBatis还是Hibernate,还是Spring的JdbcTemplate,本质上都是对JDBC的封装,所以第三层就是驱动层。比如 Sharding-JDBC,就是对 JDBC 的对象进行了封装。JDBC 的核心对象:
DataSource:数据源
Connection:数据库连接
Statement:语句对象
ResultSet:结果集
那我们只要对这几个对象进行封装或者拦截或者代理,就可以实现分片的操作。
2.4.4 代理层
前面三种都是在客户端实现的,也就是说不同的项目都要做同样的改动,不同的编程语言也有不同的实现,所以我们能不能把这种选择数据源和实现路由的逻辑提取出来,做成一个公共的服务给所有的客户端使用呢?
这个就是第四层,代理层。比如 Mycat 和 Sharding-Proxy,都是属于这一层。
2.4.5 数据库服务
最后一层就是在数据库服务上实现,也就是服务层,某些特定的数据库或者数据库的特定版本可以实现这个功能。
相关文章:
分库分表之Mycat应用学习一
1 为什么要分库分表 1.1 数据库性能瓶颈的出现 对于应用来说,如果数据库性能出现问题,要么是无法获取连接,是因为在高并发的情况下连接数不够了。要么是操作数据变慢,数据库处理数据的效率除了问题。要么是存储出现问题…...

Windows下Qt使用MSVC编译出现需要转为unicode的提示
参考 Qt5中文编码问题解决办法_qt5设置编码-CSDN博客 致敬 提示:warning: C4819: 该文件包含不能在当前代码页(936)中表示的字符。请将该文件保存为 Unicode 格式以防止数据丢失。 出现此问题,应该是Unix格式下代码的编码格式是UTF-8,注意不…...

【数值分析】乘幂法,matlab实现
乘幂法 一种求实矩阵 A {A} A 的按模最大的特征值,及其对应的特征向量 x i {x_i} xi 的方法,只能求一个。特别适合于大型稀疏矩阵。 一个矩阵的特征值和特征向量可以通过矩阵不断乘以一个初始向量得到。 每次乘完之后要规范化,防止上溢或…...

视频监控EasyCVR如何通过设置sei接口,实现在webrtc视频流中添加画框和文字?
安防视频监控系统基于视频综合管理平台EasyCVR视频系统,采用了开放式的网络结构,可以提供实时远程视频监控、视频录像、录像回放与存储、告警、语音对讲、云台控制、平台级联、磁盘阵列存储、视频集中存储、云存储等丰富的视频能力,具备权限管…...

智能三维数据虚拟现实电子沙盘
一、概述 易图讯科技(www.3dgis.top)以大数据、云计算、虚拟现实、物联网、AI等先进技术为支撑,支持高清卫星影像、DEM高程数据、矢量数据、无人机倾斜摄像、BIM模型、点云、城市白模、等高线、标高点等数据融合和切换,智能三维数…...

【SpringCloud】-GateWay源码解析
GateWay系列 【SpringCloud】-GateWay网关 一、背景介绍 当一个请求来到 Spring Cloud Gateway 之后,会经过一系列的处理流程,其中涉及到路由的匹配、过滤器链的执行等步骤。今天我们来说说请求经过 Gateway 的主要执行流程和原理是什么吧 二、正文 …...
华为无线ac双链路冷备和热备配置案例
所谓的冷备和热备,冷备就是不用vrrp和hsb协议同步ap和用户信息,主的断了等七十五秒后,备的capwap和ap连接上去。 双链路冷备不用vrrp和hsb 双链路热备份只用hsb同步ap和用户信息,不用vrrp,两个ac可以不用在同一个二层…...
VSCode Python开发环境配置
目录 1 插件安装2 Debug和测试配置常见问题 1 插件安装 1.1 基础编译插件,Python、Pylance 1.2 修改语言服务器类型,进入用户配置页面搜索Python: Language Server,选择Pylance(一定要修改可以提供很多语法提示) 1…...

浅谈【GPU和CPU】
GPU和显卡的区别 GPU(Graphics Processing Unit,图形处理器)通常指的就是显卡。显卡是一种安装在计算机中的扩展卡,主要用于图形和图像处理任务。 GPU作为显卡的核心组件,负责处理图形渲染、图像处理、视频解码和其他…...
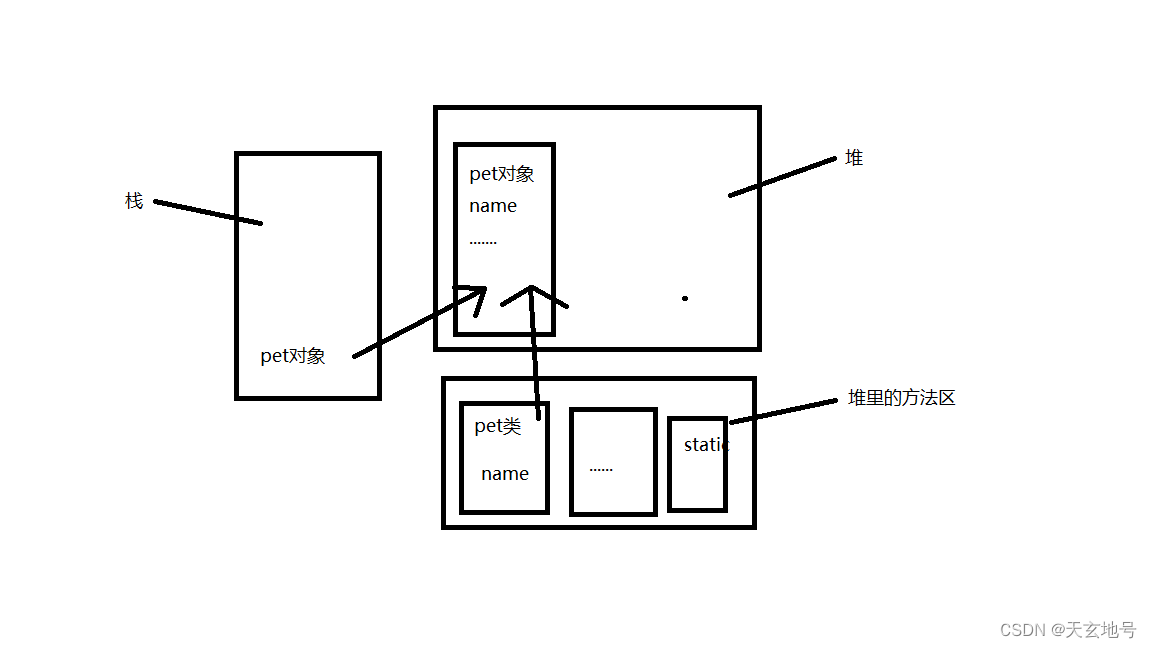
啥是构造器?
当我们new一个对象时就是在引用构造器 构造器又叫做构造函数 构造函数一般分为无参构造函数与有参构造函数 假设我们创建一个pet类,这个类里面就会有一个看不见的自动生成的无参构造函数 如果pet类里没有这个隐形的无参构造,我们new一个对象时就会报错…...

Linux基础知识学习2
tree命令的使用 可以看到dir2目录下的这些文件,要想显示dir2的具体结构,可用tree命令 mv命令 它可以实现两个功能 1.将文件移动到另一个目录中 2.对某一个文件进行重命名 1.将文件移动到另一个目录中 这里将dir1中的2.txt移动到他的子目录dir3中 执行…...

Grafana二进制部署并配置prometheus数据源
1、获取grafna二进制安装包 https://grafana.com/grafana/download?pggraf&plcmtdeploy-box-1 grafana官网下载地址 [rootambari-hadoop1 ~]# cd /opt/module/grafana/ [rootambari-hadoop1 grafana]# pwd /opt/module/grafana2、在安装自己的安装目录执行 wget https:…...

时序预测 | Matlab实现SSA-CNN-BiLSTM麻雀算法优化卷积双向长短期记忆神经网络时间序列预测
时序预测 | Matlab实现SSA-CNN-BiLSTM麻雀算法优化卷积双向长短期记忆神经网络时间序列预测 目录 时序预测 | Matlab实现SSA-CNN-BiLSTM麻雀算法优化卷积双向长短期记忆神经网络时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 MATLAB实现SSA-CNN-BiLSTM麻雀算…...

Java中的单元测试
单元测试 单元测试概述: 单元测试是指在软件开发中对软件的最小可测试单元进行测试和验证的过程。最小可测试单元通常是指函数、方法或者类,单元测试可以保证开发人员的代码正确性,同时也方便后期维护和修改。单元测试的主要目的是检测代码的正确性&am…...
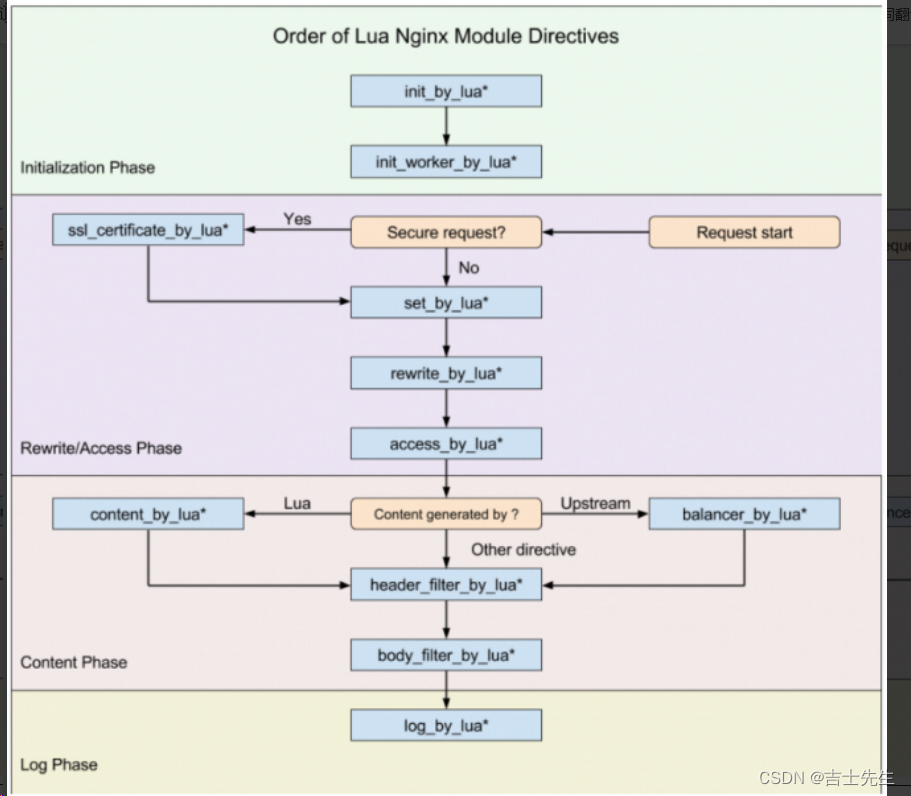
143.【Nginx-02】
Nginx-02 (五)、Nginx负载均衡1.负载均衡概述2.负载均衡的原理及处理流程(1).负载均衡的作用 3.负载均衡常用的处理方式(1).用户手动选择(2).DNS轮询方式(3).四/七层负载均衡(4).Nginx七层负载均衡指令 ⭐(5).Nginx七层负载均衡的实现流程 ⭐ 4.负载均衡状态(1).down (停用)(2)…...

代码随想录刷题 | Day2
今日学习目标 一、基础 链表 接下来说一说链表的定义。 链表节点的定义,很多同学在面试的时候都写不好。 这是因为平时在刷leetcode的时候,链表的节点都默认定义好了,直接用就行了,所以同学们都没有注意到链表的节点是如何定…...

C++ enum class 如何使用
enum class 是 C11 引入的一种新的枚举类型,它是对传统 C 风格的枚举的一种改进。enum class 提供了更强大的类型安全性和作用域限定。以下是关于 enum class 的详细介绍和用法说明: 1. 基本语法 enum class EnumName {Enumerator1,Enumerator2,// ...…...
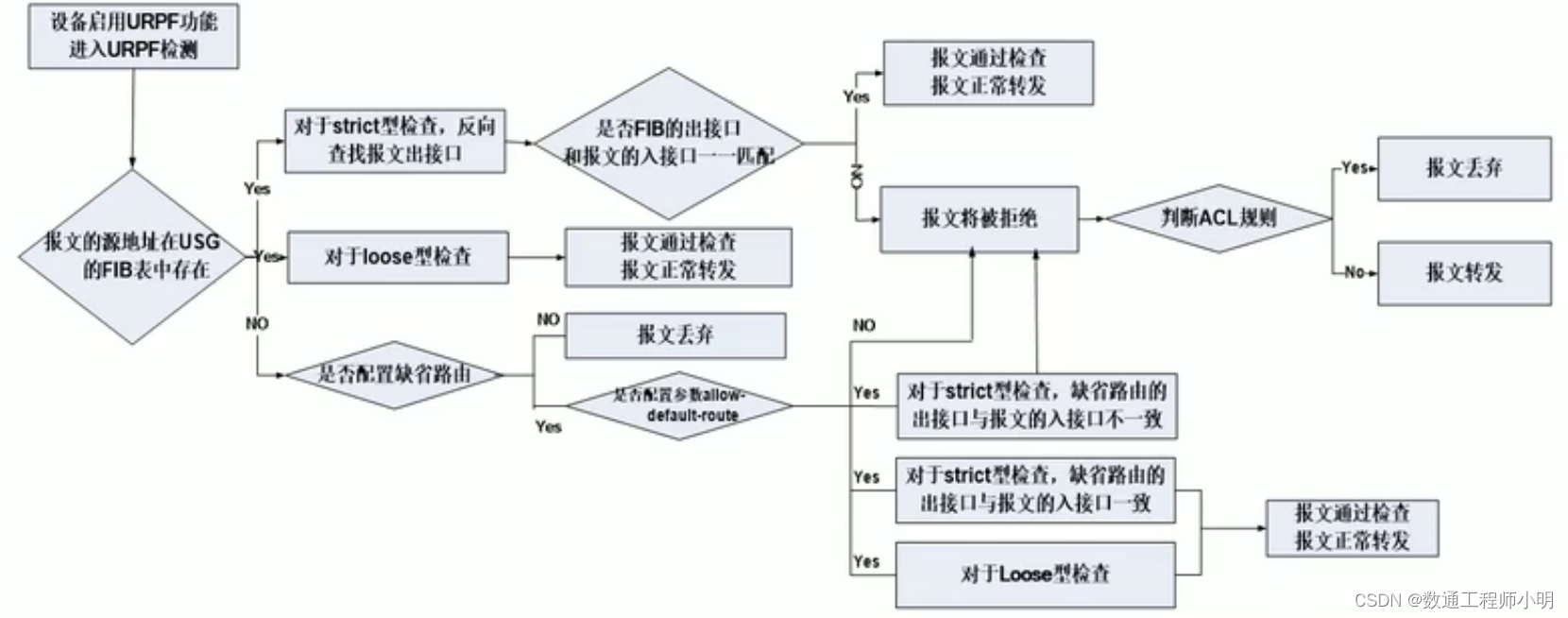
攻防技术-单包攻击防范:扫描、畸形、特殊(HCIP)
单包攻击类型介绍 一、扫描窥探攻击 1、地址扫描攻击防范 攻击介绍 运用ping程序探测目标地址,确定目标系统是否存活。也可使用TCP/UDP报文对目标系统发起探测(如TCP ping)。 防御方法 检测进入防火墙的ICMP、TCP和UDP报文,根…...
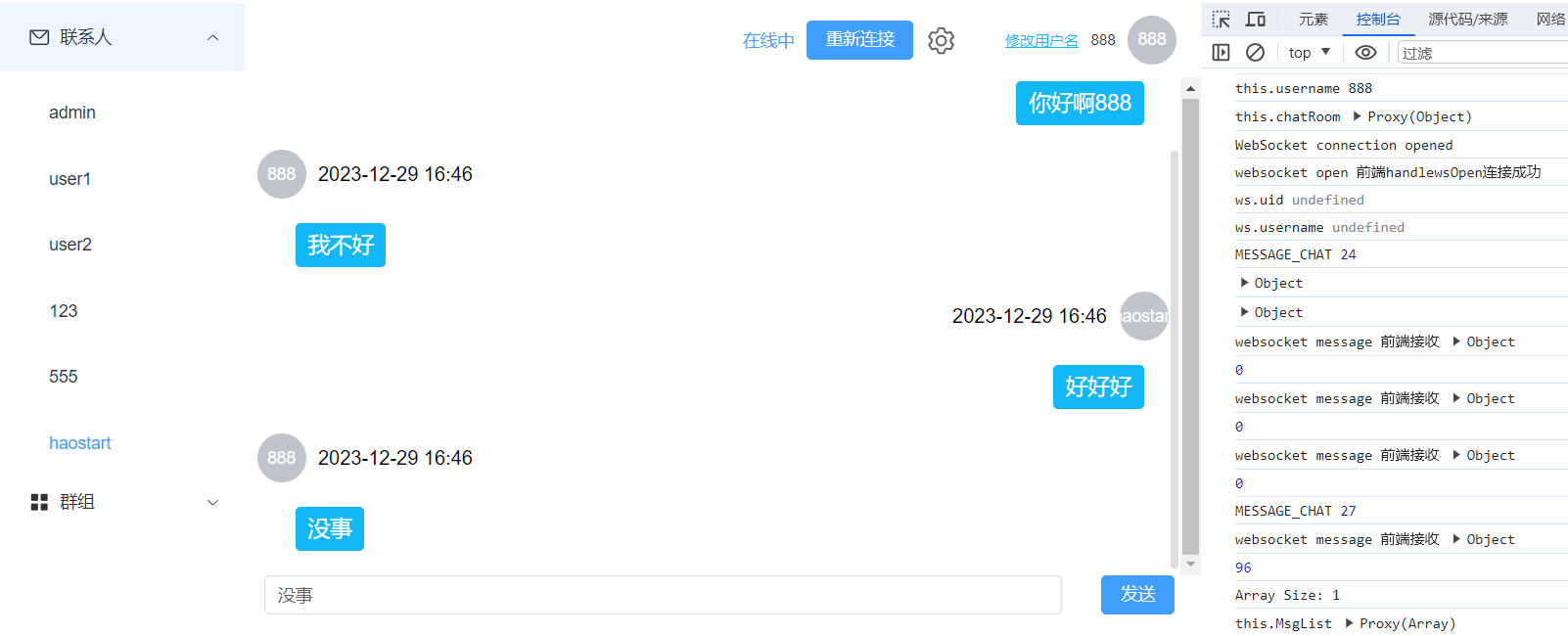
基于 Vue3 和 WebSocket 实现的简单网页聊天应用
首先附上项目介绍,后面详细解释技术细节 1. chat-websocket 一个基于Vue3和WebSocket的简易网络聊天室项目,包括服务端和客户端部分。 项目地址 websocket-chat 下面是项目的主要组成部分和功能: 项目结构 chat-websocket/ |-- server/ # WebSocket 服…...
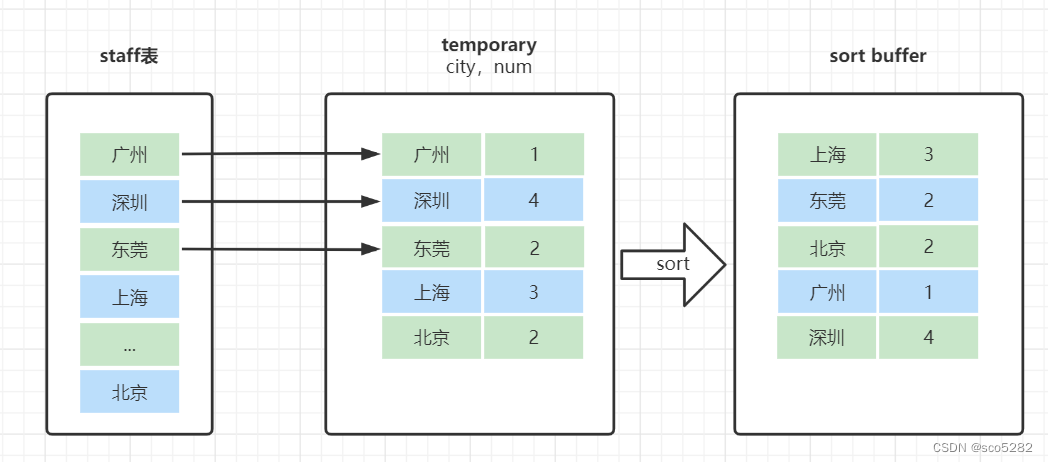
【MYSQL】MYSQL 的学习教程(八)之 12 种慢 SQL 查询原因
日常开发中,我们经常会遇到数据库慢查询。那么导致数据慢查询都有哪些常见的原因呢?今天就跟大家聊聊导致 MySQL 慢查询的 12 个常见原因,以及对应的解决方法: SQL 没加索引SQL 索引失效limit 深分页问题单表数据量太大join 或者…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

CSS设置元素的宽度根据其内容自动调整
width: fit-content 是 CSS 中的一个属性值,用于设置元素的宽度根据其内容自动调整,确保宽度刚好容纳内容而不会超出。 效果对比 默认情况(width: auto): 块级元素(如 <div>)会占满父容器…...

WPF八大法则:告别模态窗口卡顿
⚙️ 核心问题:阻塞式模态窗口的缺陷 原始代码中ShowDialog()会阻塞UI线程,导致后续逻辑无法执行: var result modalWindow.ShowDialog(); // 线程阻塞 ProcessResult(result); // 必须等待窗口关闭根本问题:…...

redis和redission的区别
Redis 和 Redisson 是两个密切相关但又本质不同的技术,它们扮演着完全不同的角色: Redis: 内存数据库/数据结构存储 本质: 它是一个开源的、高性能的、基于内存的 键值存储数据库。它也可以将数据持久化到磁盘。 核心功能: 提供丰…...

规则与人性的天平——由高考迟到事件引发的思考
当那位身着校服的考生在考场关闭1分钟后狂奔而至,他涨红的脸上写满绝望。铁门内秒针划过的弧度,成为改变人生的残酷抛物线。家长声嘶力竭的哀求与考务人员机械的"这是规定",构成当代中国教育最尖锐的隐喻。 一、刚性规则的必要性 …...
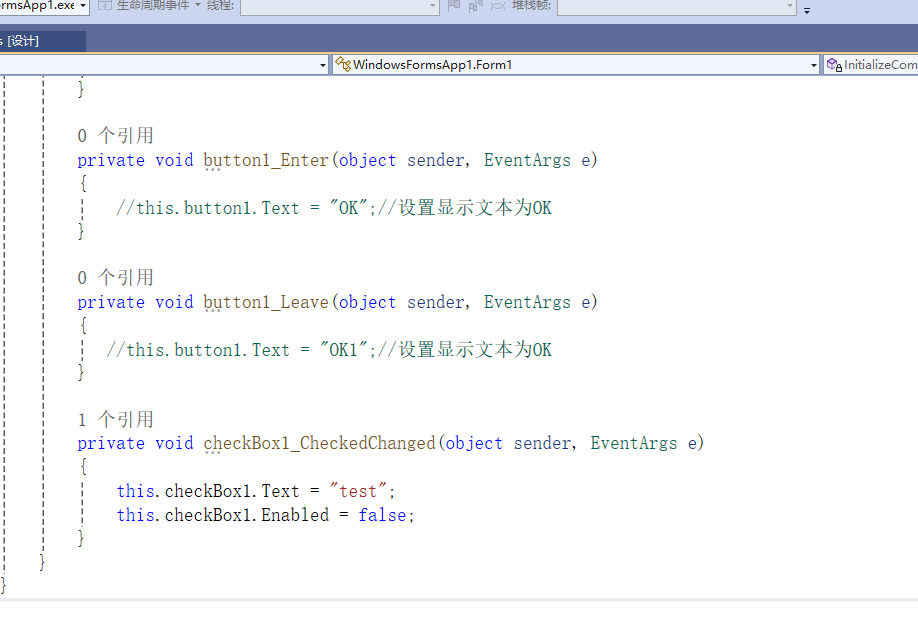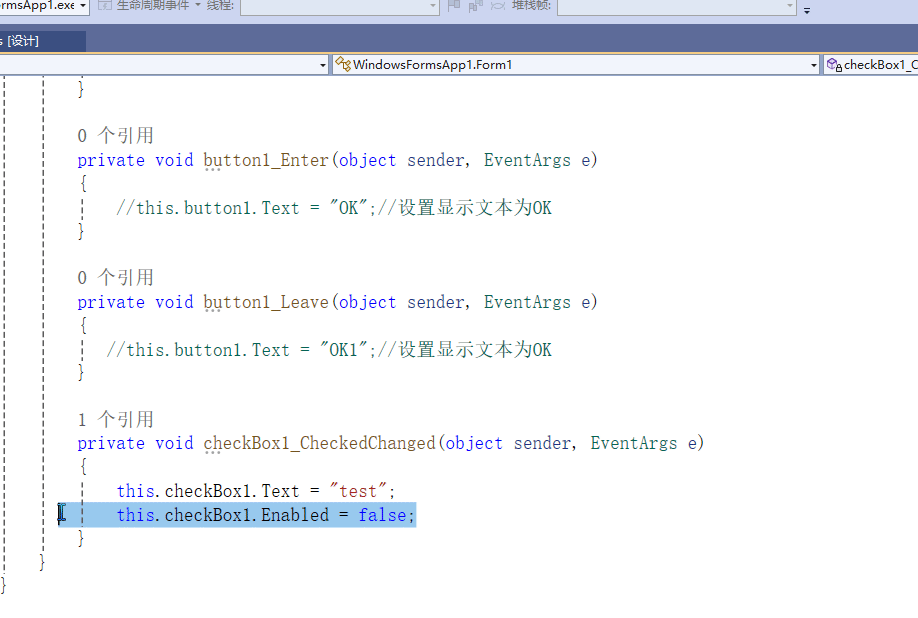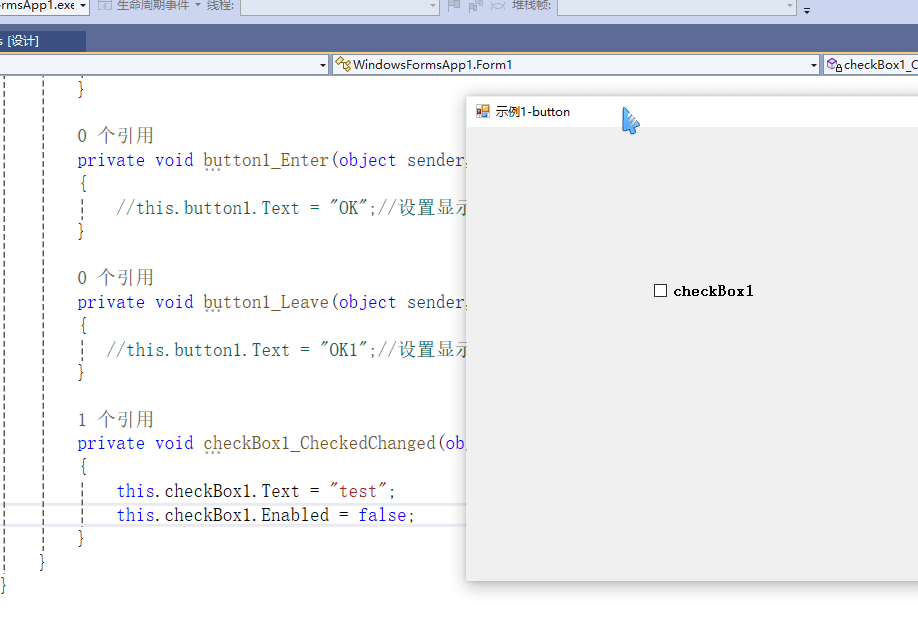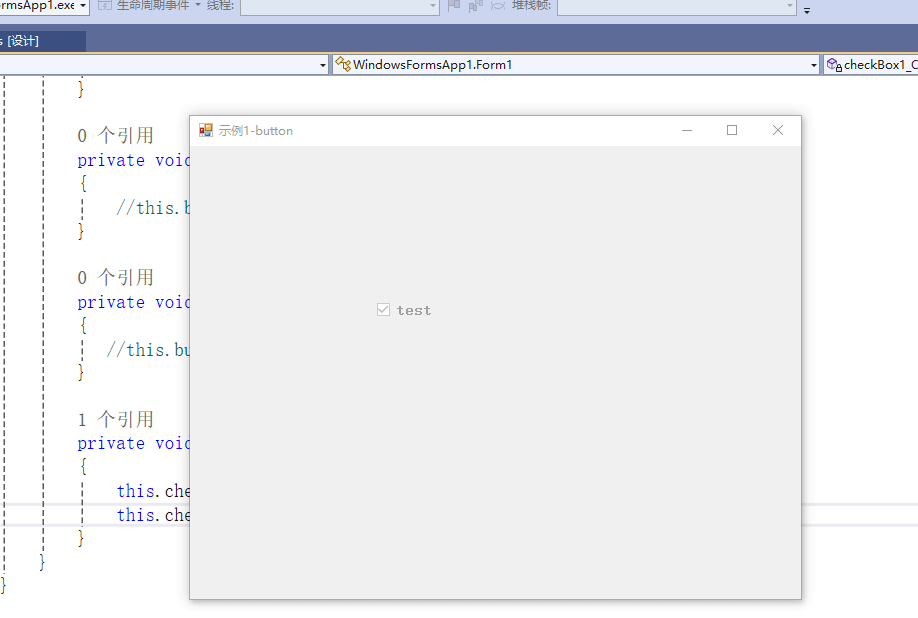
C# winform教程(二)----checkbox
一、作用 提供一个用户选择或者不选的状态,这是一个可以多选的控件。 二、属性 其实功能大差不差,除了特殊的几个外,与button基本相同,所有说几个独有的 checkbox属性 名称内容含义appearance控件外观可以变成按钮形状checkali…...