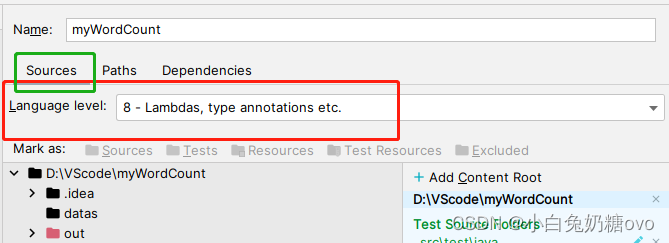
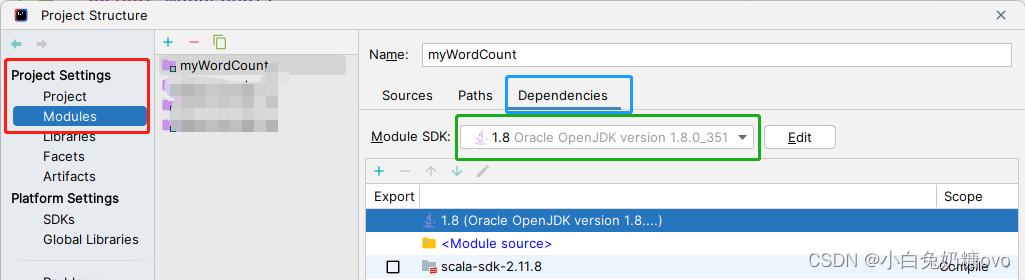
IDEA2022 配置spark开发环境
本人强烈建议在 linux环境下 学习 spark!!!
Introduction
Apache Spark是一个快速且通用的分布式计算引擎,可以在大规模数据集上进行高效的数据处理,包括数据转换、数据清洗、机器学习等。在本文中,我们将讨论如何在Windows上配置Spark开发环境,以及如何进行开发和测试等。
安装 Java 和 Spark
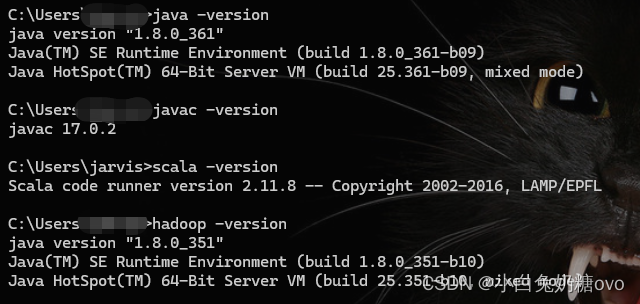
- 为了在Windows上使用Spark开发环境,你需要先安装
Java和Spark,并配置环境变量。你可以从Oracle官网下载最新版本的Java Development Kit(JDK),然后安装它。在安装完成后,你需要将Java的安装目录添加到系统环境变量中,以便Spark可以找到Java。接下来,你可以从Apache Spark官网下载适用于Windows的二进制文件,并解压到本地目录。
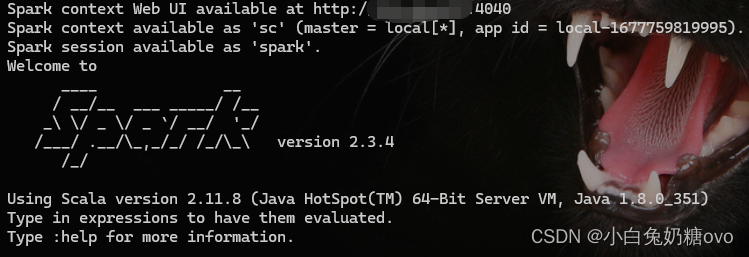
使用 Pyspark 或 Spark shell
- 在下载
Spark二进制文件后,你可以使用Pyspark或Spark shell在本地或集群上进行开发。Pyspark是一个Python API,可以使开发者用Python编写Spark应用程序。Spark shell是一个交互式环境,可以允许你使用Scala、Java或Python来调试和测试Spark代码。你可以在命令行中输入“pyspark”或“spark-shell”命令来启动相应的环境。
安装 Winutils 工具
- Winutils是一个用于在
Windows上运行Hadoop的工具,它提供了一些必要的组件和环境变量,以便Spark可以在Windows上运行。你需要从Apache官网下载Winutils二进制文件,并解压到本地目录。接下来,你需要将Winutils的安装目录添加到系统环境变量中,以便Spark可以找到它。 切记:下载与自己hadoop对应的版本,并将原本hadoop/bin替换掉!
Conclusion
- 在开发和部署
Spark应用程序时,确保你了解Spark的最佳实践和安全性措施,以避免潜在的安全漏洞和性能问题。你可以使用一些第三方的库来扩展你的Spark开发环境,例如Pyrolite和SparkR。此外,你还可以考虑使用一些数据可视化工具来帮助你更好地了解和展示你的数据,例如Tableau和PowerBI等。最后,要时刻注意更新你的环境和依赖库,以保持最新的功能和性能优化。
使用集成开发环境(IDE)
- 除了使用
Pyspark或Spark shell,你还可以考虑使用一些集成开发环境(IDE)来提高开发效率,例如PyCharm或IntelliJ IDEA等。这些IDE提供了更强大的代码编辑、自动补全和调试功能,可以帮助你更快地开发和测试Spark应用程序。此外,一些IDE还提供了一些有用的插件,可以帮助你更好地管理你的项目和依赖库。

安装下列插件:


在集群上运行 Spark 应用程序
- 在使用集群时,确保你有足够的资源来支持你的开发和测试,例如足够的内存和处理器。你可以使用一些集群管理工具,例如
Apache Hadoop、Apache Mesos或者Apache YARN等来管理和分配资源。在部署Spark应用程序时,你需要将你的应用程序打包成一个jar文件,并将其提交到集群中运行。你可以使用一些工具,例如Apache Maven或SBT等来打包和管理你的应用程序。 - 如果你已经在Windows上配置了Spark开发环境,可以考虑使用sbt来打包和管理你的应用程序,而不是使用
maven打包和管理。这可以帮助你更好地管理你的依赖库和构建过程,并提高你的开发效率。另外,你还需要时刻注意更新你的环境和依赖库,以保持最新的功能和性能优化。
附上:SBT的使用教程
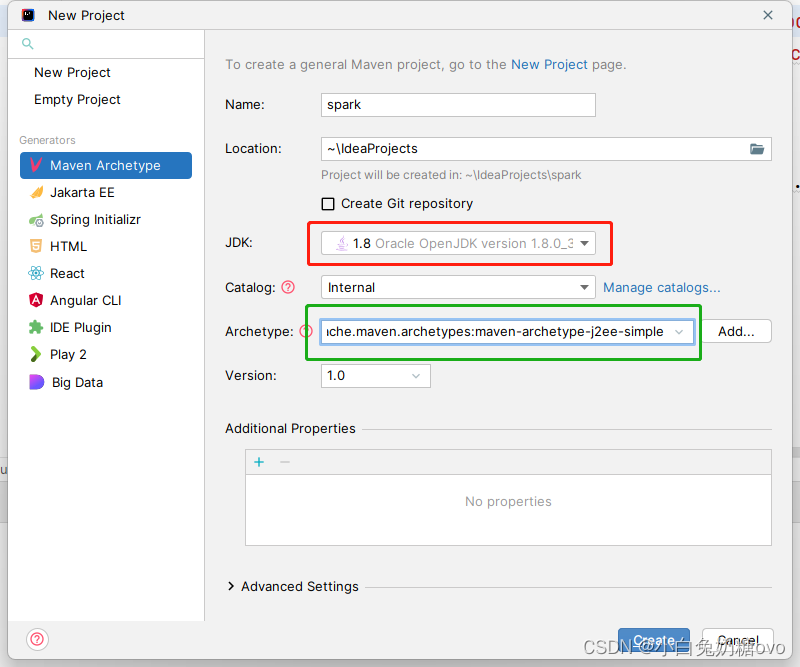
创建mvn项目:
扩展你的 Spark 开发环境
- 你可以使用一些第三方的库来扩展你的Spark开发环境,例如
Pyrolite和SparkR。Pyrolite是一个Python库,可以让你在Python中使用Java类和对象,从而方便你与Java代码进行交互。SparkR是一个R语言的API,可以让你用R语言编写Spark应用程序。此外,你还可以使用一些数据可视化工具来帮助你更好地了解和展示你的数据,例如Tableau和PowerBI等。
更新你的环境和依赖库
- 最后,在开发Spark应用程序时,你需要时刻注意更新你的环境和依赖库,以保持最新的功能和性能优化。你可以使用一些工具,例如Apache Maven或SBT等来管理你的依赖库,并定期更新它们。此外,你还需要定期更新你的Spark版本和相关组件,以获得最新的功能和修复潜在的漏洞。
Bugs 修复
scalac: Error: Error compiling the sbt component 'compiler-interface-2.11.8-61.0'
sbt.internal.inc.CompileFailed: Error compiling the sbt component 'compiler-interface-2.11.8-61.0'at sbt.internal.inc.AnalyzingCompiler$.handleCompilationError$1(AnalyzingCompiler.scala:436)at sbt.internal.inc.AnalyzingCompiler$.$anonfun$compileSources$5(AnalyzingCompiler.scala:453)at sbt.internal.inc.AnalyzingCompiler$.$anonfun$compileSources$5$adapted(AnalyzingCompiler.scala:448)at sbt.io.IO$.withTemporaryDirectory(IO.scala:490)at sbt.io.IO$.withTemporaryDirectory(IO.scala:500)at sbt.internal.inc.AnalyzingCompiler$.$anonfun$compileSources$2(AnalyzingCompiler.scala:448)at sbt.internal.inc.AnalyzingCompiler$.$anonfun$compileSources$2$adapted(AnalyzingCompiler.scala:440)at sbt.io.IO$.withTemporaryDirectory(IO.scala:490)at sbt.io.IO$.withTemporaryDirectory(IO.scala:500)at sbt.internal.inc.AnalyzingCompiler$.compileSources(AnalyzingCompiler.scala:440)at org.jetbrains.jps.incremental.scala.local.CompilerFactoryImpl$.org$jetbrains$jps$incremental$scala$local$CompilerFactoryImpl$$getOrCompileInterfaceJar(CompilerFactoryImpl.scala:162)at org.jetbrains.jps.incremental.scala.local.CompilerFactoryImpl.$anonfun$getScalac$1(CompilerFactoryImpl.scala:58)at scala.Option.map(Option.scala:242)at org.jetbrains.jps.incremental.scala.local.CompilerFactoryImpl.getScalac(CompilerFactoryImpl.scala:51)at org.jetbrains.jps.incremental.scala.local.CompilerFactoryImpl.createCompiler(CompilerFactoryImpl.scala:20)at org.jetbrains.jps.incremental.scala.local.CachingFactory.$anonfun$createCompiler$3(CachingFactory.scala:21)at org.jetbrains.jps.incremental.scala.local.Cache.$anonfun$getOrUpdate$2(Cache.scala:17)at scala.Option.getOrElse(Option.scala:201)at org.jetbrains.jps.incremental.scala.local.Cache.getOrUpdate(Cache.scala:16)at org.jetbrains.jps.incremental.scala.local.CachingFactory.createCompiler(CachingFactory.scala:21)at org.jetbrains.jps.incremental.scala.local.LocalServer.doCompile(LocalServer.scala:40)at org.jetbrains.jps.incremental.scala.local.LocalServer.compile(LocalServer.scala:27)at org.jetbrains.jps.incremental.scala.remote.Main$.compileLogic(Main.scala:206)at org.jetbrains.jps.incremental.scala.remote.Main$.$anonfun$handleCommand$1(Main.scala:193)at org.jetbrains.jps.incremental.scala.remote.Main$.decorated$1(Main.scala:183)at org.jetbrains.jps.incremental.scala.remote.Main$.handleCommand(Main.scala:190)at org.jetbrains.jps.incremental.scala.remote.Main$.serverLogic(Main.scala:166)at org.jetbrains.jps.incremental.scala.remote.Main$.nailMain(Main.scala:106)at org.jetbrains.jps.incremental.scala.remote.Main.nailMain(Main.scala)at jdk.internal.reflect.GeneratedMethodAccessor3.invoke(Unknown Source)at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.base/java.lang.reflect.Method.invoke(Method.java:568)at com.facebook.nailgun.NGSession.runImpl(NGSession.java:312)at com.facebook.nailgun.NGSession.run(NGSession.java:198)
解决办法:
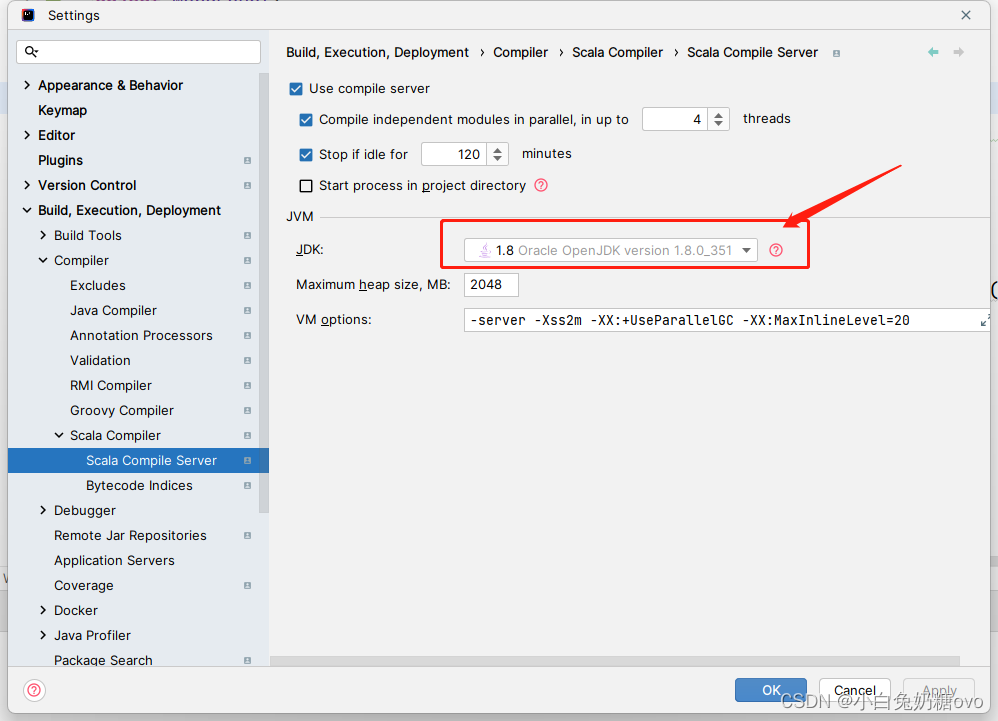
检查此处配置!
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
将SPARK_HOME/conf 目录下的 log4j.properties.template 重命名为 log4j.properties
23/03/02 18:29:33 INFO SparkContext: Created broadcast 0 from textFile at FrameDemo.scala:13
23/03/02 18:29:34 ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:278)at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:300)at org.apache.hadoop.util.Shell.<clinit>(Shell.java:293)at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:76)at org.apache.hadoop.mapred.FileInputFormat.setInputPaths(FileInputFormat.java:362)at <br>org.apache.spark.SparkContext$$anonfun$hadoopFile$1$$anonfun$33.apply(SparkContext.scala:1015)at org.apache.spark.SparkContext$$anonfun$hadoopFile$1$$anonfun$33.apply(SparkContext.scala:1015)at <br>org.apache.spark.rdd.HadoopRDD$$anonfun$getJobConf$6.apply(HadoopRDD.scala:176)at <br>org.apache.spark.rdd.HadoopRDD$$anonfun$getJobConf$6.apply(HadoopRDD.scala:176)<br>at scala.Option.map(Option.scala:145)<br>at org.apache.spark.rdd.HadoopRDD.getJobConf(HadoopRDD.scala:176)<br>at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:195)<br>at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)<br>at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)<br>at scala.Option.getOrElse(Option.scala:120)<br>at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)<br>at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)<br>at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)<br>at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)<br>at scala.Option.getOrElse(Option.scala:120)<br>at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)<br>at org.apache.spark.SparkContext.runJob(SparkContext.scala:1929)<br>at org.apache.spark.rdd.RDD.count(RDD.scala:1143)<br>at com.org.SparkDF.FrameDemo$.main(FrameDemo.scala:14)<br>at com.org.SparkDF.FrameDemo.main(FrameDemo.scala)<br>
以编程方式设置 HADOOP_HOME 环境变量:
System.setProperty(“hadoop.home.dir”, “full path to the folder with winutils”);
总结
- 在本文中,我们讨论了如何在
Windows上配置Spark开发环境,并介绍了如何使用Pyspark或Spark shell进行开发和测试。此外,我们还讨论了如何使用集成开发环境(IDE)和扩展你的Spark开发环境。最后,我们提醒你时刻注意更新你的环境和依赖库,以保持最新的功能和性能优化。如果你正在学习Spark开发,希望这篇文章能够帮助你更好地开始你的Spark开发之旅。
相关文章:
IDEA2022 配置spark开发环境
本人强烈建议在 linux环境下 学习 spark!!! Introduction Apache Spark是一个快速且通用的分布式计算引擎,可以在大规模数据集上进行高效的数据处理,包括数据转换、数据清洗、机器学习等。在本文中,我们将…...

趣味答题竞赛小程序开发功能的详细介绍
随着人们对知识学习的要求越来越高,答题已经成为了一项重要的学习和考核方式。而为了让答题变得更加有趣和富有挑战性,我们推出了趣味答题竞赛小程序。下面,我们将详细介绍这个小程序的开发功能。 1.个人淘汰赛 在个人淘汰赛中,…...

【独家】华为OD机试提供C语言题解 - 获取最大软件版本号
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试人员的实战技巧文章目录 最近更新的博客使用说明获取…...

k8s编程operator实战之云编码平台——⑤项目完成、部署
文章目录1、效果展示2、保存用户状态和访问用户服务实现方案2.1 如何保存用户的状态2.1.1 解决保留安装的插件问题2.2 如何访问到用户在工作空间中启动的http服务2.2.1 code-server如何帮我们实现了用户程序的代理3、Operator功能实现3.1 使用KubeBuilder创建项目3.1.1 完善kin…...

C语言杂记(指针篇)
指针篇 指针就是地址,地址就是指针 指针变量就是存放地址的变量 *号只有定义的时候表示定义指针变量,其他表示从地址里面取内容 通过指针的方法使main函数中的data1和data2发生数据交换。 #include <stdio.h> void chang_data(int *data1,int *da…...
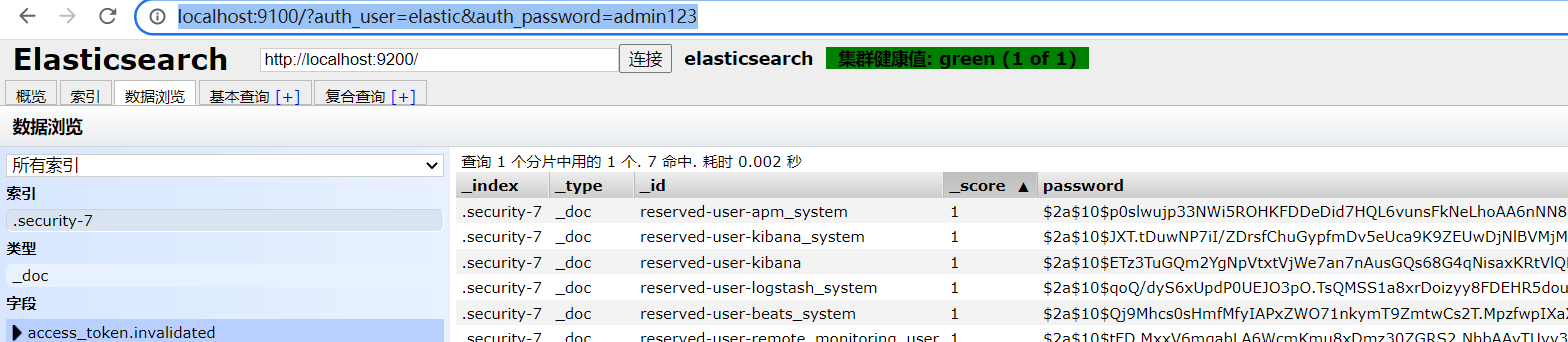
ES window 系统环境下连接问题
环境问题:(我采用的版本是 elasticsearch-7.9.3)注意 开始修正之前的配置:前提:elasticsearch.yml增加或者修正一下配置:xpack.security.enabled: truexpack.license.self_generated.type: basicxpack.secu…...

hexo部署github搭建个人博客 完整详细带图版(更新中)
文章目录0. 前置内容1. hexo创建个人博客2. GitHub创建仓库3. hexo部署到GitHub4. 常用命令newcleangenerateserverdeploy5. 添加插件5.1 主题5.2 博客基本信息5.3 创建新的菜单5.4 添加搜索功能5.5 添加阅读时间字数提示5.6 打赏功能5.7 切换主题5.8 添加不蒜子统计5.9 添加百…...

SpringBoot集成DruidDataSource实现监控 SQL 性能
一、快速入门 1.1 基本概念 我们都使用过连接池,比如C3P0、DBCP、hikari、Druid,虽然 HikariCP 的速度稍快,但 Druid 能够提供强大的监控和扩展功能。Druid DataSource 是阿里巴巴开发的号称为监控而生的数据库连接池,它不仅可以…...
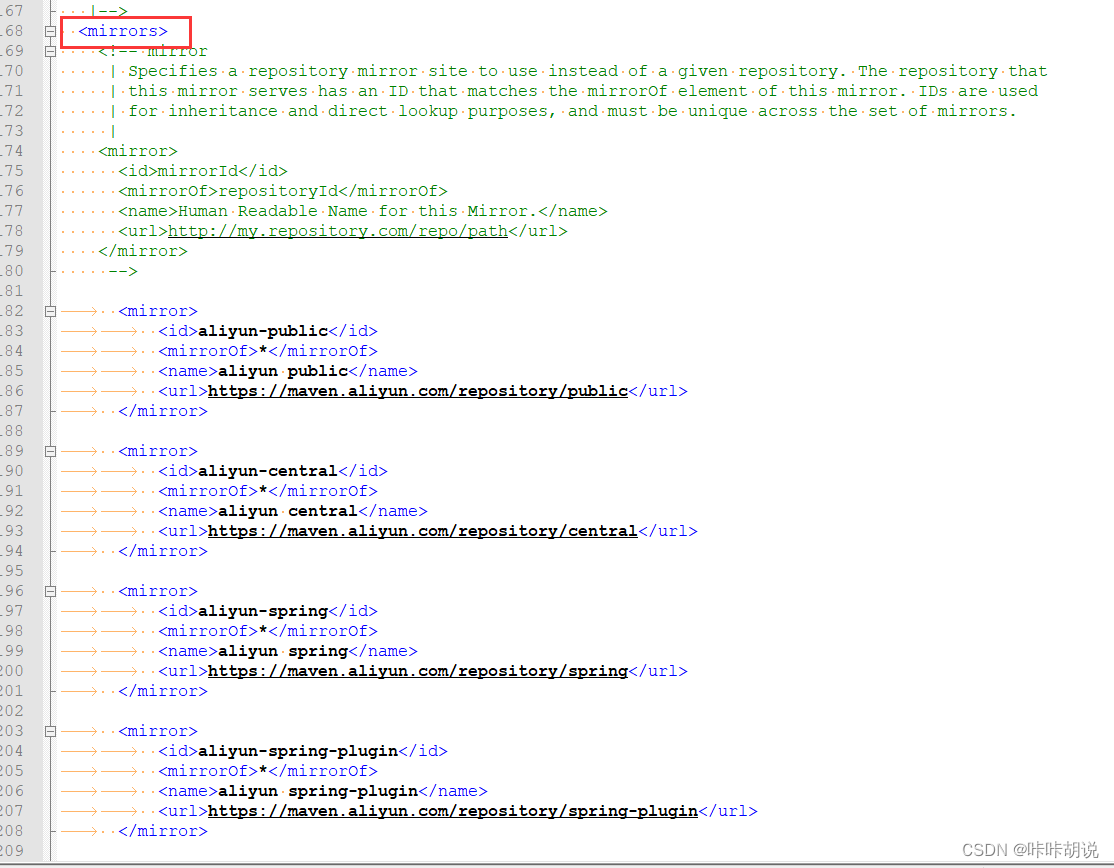
maven镜像源及代理配置
在公司使用网络一般需要设置代理, 我在idea中创建springboot工程时,发现依赖下载不了,原以为只要浏览器设置代理,其他的网络访问都会走代理,经过查资料设置了以下几个地方后工程创建正常,在此记录给大家参考…...
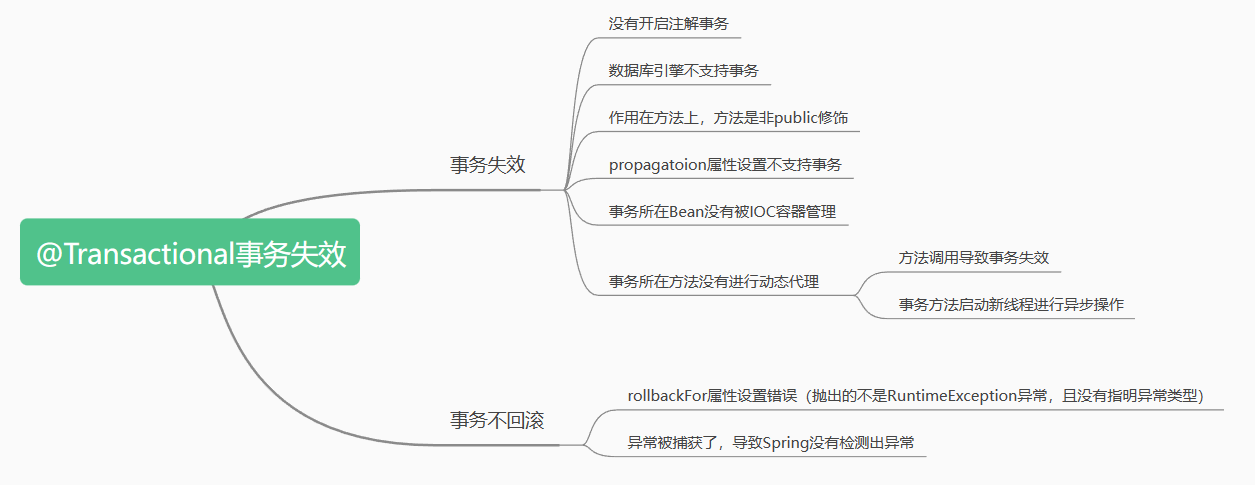
【Java面试篇】Spring中@Transactional注解事务失效的常见场景
文章目录Transactional注解的失效场景☁️前言🍀前置知识🍁场景一:Transactional应用在非 public 修饰的方法上🍁场景二: propagation 属性设置错误🍁场景三:rollbackFor属性设置错误dz…...

【C】分配内存的函数
#include <stdlib.h>//分配所需的内存空间,并返回一个指向它的指针。 void *malloc(size_t size);//分配所需的内存空间,并返回一个指向它的指针。并且calloc负责把这块内存空间用字节0填//充,而malloc并不负责把分配的内存空间清零 vo…...
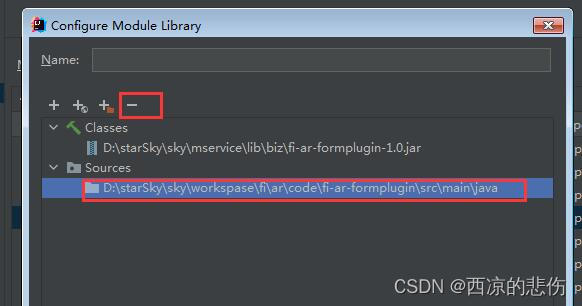
IDEA 断点总是进入class文件没有进入源文件解决
前言 idea 断点总是进入class文件没有进入源文件解决 问题 在源文件里打了断点,断点模式启动时却进入了class文件里的断点,而没有进入到java源文件里的断点。 比如:我在 A.java 里打了断点,调试时却进入到了 jar 包里的 A.clas…...
【flink】 flink入门教程demo 初识flink
文章目录通俗解释什么是flink及其应用场景flink处理流程及核心APIflink代码快速入门flink重要概念什么是flink? 刚接触这个词的同学 可能会觉得比较难懂,网上搜教程 也是一套一套的官话, 如果大家熟悉stream流,那或许会比较好理解…...

LeetCode 1487. 保证文件名唯一
【LetMeFly】1487.保证文件名唯一 力扣题目链接:https://leetcode.cn/problems/making-file-names-unique/ 给你一个长度为 n 的字符串数组 names 。你将会在文件系统中创建 n 个文件夹:在第 i 分钟,新建名为 names[i] 的文件夹。 由于两个…...

详细剖析|袋鼠云数栈前端框架Antd 3.x 升级 4.x 的踩坑之路
袋鼠云数栈从2016年发布第⼀个版本开始,就始终坚持着以技术为核⼼、安全为底线、提效为⽬标、中台为战略的思想,坚定不移地⾛国产化信创路线,不断推进产品功能迭代、技术创新、服务细化和性能升级。 在数栈过去的产品迭代中受限于当前组件的…...

【C++PrimerPlus】第三章 处理数据
文章目录前言内容目录3.1 简单变量3.1.2 变量名3.1.2 整形3.1.3 整形short,int,long,long long3.1.4 无符号类型3.1.5 选择整形类型3.1.6 整形字面值3.1.7 C如何确定常量的类型3.1.8 char类型:字符和小整数3.1.9 bool类型3.2 const修饰符3.3浮点数3.3.1 书写浮点数3…...

【基础算法】单链表的OJ练习(1) # 反转链表 # 合并两个有序链表 #
文章目录前言反转链表合并两个有序链表写在最后前言 上一章讲解了单链表 -> 传送门 <- ,后面几章就对单链表进行一些简单的题目练习,目的是为了更好的理解单链表的实现以及加深对某些函数接口的熟练度。 本章带来了两个题目。一是反转链表&#x…...
命题逻辑)
离散数学笔记(1)命题逻辑
文章目录1.命题符号化及联结词基本概念本节题型2.命题公式及分类基本概念本节题型1.命题符号化及联结词 基本概念 命题的定义:能够判断真假的陈述句称为命题。 备注:感叹句、疑问句、祈使句和类似于xy>5之类真值不唯一的句子都不是命题。 真值的真假…...
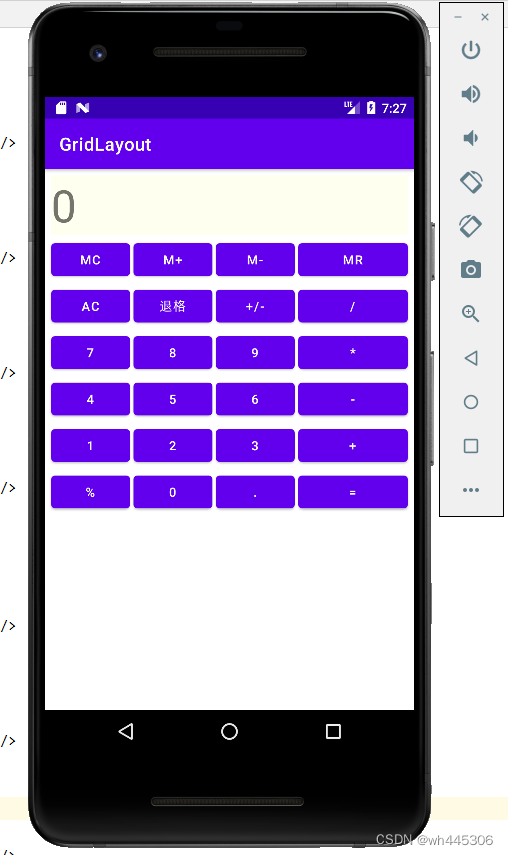
IDEA Android 网格布局(GridLayout)示例(计算器界面布局)
网格布局(GridLayout) 示例程序效果(实现类似vivo手机自带计算器UI) 真机和模拟器运行效果: 简述: GridLayout(网格布局)和TableLayout(表格布局)有类似的地方,通俗来讲可以理解为…...

【蓝桥杯嵌入式】拓展板之数码管显示
文章目录硬件电路连接方式函数实现文章福利硬件电路 通过上述原理图,可知拓展板上的数码管是一个共阴数码管,也就是说某段数码管接上高电平时,就会点亮。 上述原理图还给出一个提示,即:三个数码管分别与三个74HC59…...
)
Dify + Weaviate/Qdrant混合重排架构实践(支持动态权重调度、Fallback降级与A/B测试埋点)
第一章:Dify重排序架构的核心设计哲学Dify 的重排序(Reranking)模块并非简单叠加于检索之后的后处理步骤,而是在整个 LLM 应用生命周期中承担语义对齐、意图强化与可信度校准三重使命的设计原语。其核心哲学可凝练为:*…...

OpenClaw Graph Memory 知识图谱深度解析:告别 AI 记忆困境,实现去中心化自我改进!
当 AI 助手频繁出错、反复试错消耗大量 token;当跨对话的宝贵经验第二天就消失无踪;当某个 Skills 学到的孤岛知识点无法迁移——这些问题是否困扰着你?OpenClaw 开源项目 Graph Memory 登场,用知识图谱颠覆传统记忆方案ÿ…...

PDF补丁丁实战指南:从文档难题到高效解决方案的全流程掌握
PDF补丁丁实战指南:从文档难题到高效解决方案的全流程掌握 【免费下载链接】PDFPatcher PDF补丁丁——PDF工具箱,可以编辑书签、剪裁旋转页面、解除限制、提取或合并文档,探查文档结构,提取图片、转成图片等等 项目地址: https:…...
Pixel Fashion Atelier应用场景:高校数字媒体专业像素艺术教学辅助工具
Pixel Fashion Atelier应用场景:高校数字媒体专业像素艺术教学辅助工具 1. 教学痛点与解决方案 在高校数字媒体专业的像素艺术教学中,传统教学方式面临几个核心挑战: 创作效率低:学生需要从零开始绘制像素画,耗时耗…...

算法艺术创作与Canvas视觉开发:技术驱动的创意编程实践指南
算法艺术创作与Canvas视觉开发:技术驱动的创意编程实践指南 【免费下载链接】skills 本仓库包含的技能展示了Claude技能系统的潜力。这些技能涵盖从创意应用到技术任务、再到企业工作流。 项目地址: https://gitcode.com/GitHub_Trending/skills3/skills Git…...
)
告别手动复制!用Apifox Helper插件实现IDEA代码注释自动同步API文档(2024最新版)
2024终极指南:用Apifox Helper打造无缝API文档同步工作流 在当今快节奏的开发环境中,API文档与代码的同步问题一直是困扰开发团队的痛点。传统的手动维护方式不仅耗时耗力,还容易因人为疏忽导致文档与实现不一致。想象一下,当你在…...

基于天棚控制原理的半主动悬架模型探索
基于天棚控制原理的半主动悬架模型 详细介绍:采用天棚阻尼控制的1/4主动悬架模型,以车身垂向加速度为控制目标,输入为B级随机路面,输出为车身垂向加速度、轮胎动载荷、悬架动挠度等平顺性评价指标,并计算了各个参数的均…...

WebSocket避坑指南:用ws库时你可能会遇到的5个典型问题
WebSocket实战避坑指南:5个高频问题与深度解决方案 1. 连接稳定性:从握手失败到心跳检测 WebSocket连接建立阶段最常见的错误是HTTP 101 Switching Protocols响应失败。某电商平台的监控数据显示,约23%的连接异常发生在握手阶段。以下是典型错…...

清华大学提出统一多模态模型新突破:让AI同时学会“看“和“画“
这项由清华大学、西安交通大学和中科院大学联合开展的研究发表于2026年的arXiv预印本(论文编号:arXiv:2603.12793v1),研究团队开发了一个名为CHEERS的全新AI模型,能够同时具备图像理解和图像生成两种截然不同的能力。对…...

终极iOS越狱指南:使用palera1n突破iOS 15.0+设备限制的完整方案
终极iOS越狱指南:使用palera1n突破iOS 15.0设备限制的完整方案 【免费下载链接】palera1n Jailbreak for arm64 devices on iOS 15.0 项目地址: https://gitcode.com/GitHub_Trending/pa/palera1n 你是否在为iOS 15.0以上设备找不到稳定的越狱工具而困扰&…...