Spark中的数据加载与保存
Apache Spark是一个强大的分布式计算框架,用于处理大规模数据。在Spark中,数据加载与保存是数据处理流程的关键步骤之一。本文将深入探讨Spark中数据加载与保存的基本概念和常见操作,包括加载不同数据源、保存数据到不同格式以及性能优化等方面的内容。
数据加载
在开始使用Spark进行数据分析和处理之前,首先需要加载数据。Spark支持多种数据源,可以根据您的需求选择合适的数据加载方法。以下是一些常见的数据加载方式以及示例代码:
1 从文本文件加载数据
加载文本文件是最常见的数据加载方式之一。可以使用textFile方法来加载文本文件,并将其转换为RDD(弹性分布式数据集)。
from pyspark import SparkContext# 创建SparkContext
sc = SparkContext("local", "DataLoadingExample")# 从文本文件加载数据
text_data = sc.textFile("data.txt")# 显示数据
text_data.take(5)
2 从CSV文件加载数据
如果数据以CSV格式存储,可以使用第三方库(如pandas)来加载CSV文件,然后将其转换为RDD或DataFrame。
import pandas as pd
from pyspark.sql import SparkSession# 创建SparkSession
spark = SparkSession.builder.appName("DataLoadingExample").getOrCreate()# 使用pandas加载CSV文件
csv_data = pd.read_csv("data.csv")# 将pandas DataFrame转换为Spark DataFrame
spark_df = spark.createDataFrame(csv_data)# 显示数据
spark_df.show()
3 从数据库加载数据
Spark支持从关系型数据库中加载数据,可以使用JDBC连接来加载数据。首先,需要提供数据库连接信息,并使用read方法加载数据。
# 配置数据库连接信息
jdbc_url = "jdbc:mysql://localhost:3306/mydb"
connection_properties = {"user": "username","password": "password","driver": "com.mysql.jdbc.Driver"
}# 从数据库加载数据
db_data = spark.read.jdbc(url=jdbc_url, table="mytable", properties=connection_properties)# 显示数据
db_data.show()
4 从Hive表加载数据
如果在Hive中存储了数据,可以直接在Spark中加载Hive表的数据。
# 从Hive表加载数据
hive_data = spark.sql("SELECT * FROM my_table")# 显示数据
hive_data.show()
数据保存
在对数据进行处理和分析后,通常需要将结果保存回不同的数据源或文件中。Spark支持多种数据保存方式,以下是一些常见的数据保存方式以及示例代码:
1 保存数据到文本文件
将数据保存到文本文件是一种常见的方式,可以使用saveAsTextFile方法将RDD的内容保存为文本文件。
# 保存数据到文本文件
text_data.saveAsTextFile("output.txt")
2 保存数据到CSV文件
如果希望将数据保存为CSV格式,可以使用DataFrame的toPandas方法将数据转换为pandas DataFrame,然后再保存为CSV文件。
# 转换为pandas DataFrame
pandas_df = spark_df.toPandas()# 保存为CSV文件
pandas_df.to_csv("output.csv", index=False)
3 保存数据到数据库
将数据保存到数据库也是一种常见的操作,可以使用write方法将数据写入数据库。
# 配置数据库连接信息
jdbc_url = "jdbc:mysql://localhost:3306/mydb"
connection_properties = {"user": "username","password": "password","driver": "com.mysql.jdbc.Driver"
}# 保存数据到数据库
db_data.write.jdbc(url=jdbc_url, table="mytable", mode="overwrite", properties=connection_properties)
4 保存数据到Parquet文件
Parquet是一种列式存储格式,适合于大规模数据的存储和分析。您可以使用Parquet格式来保存数据。
# 保存数据到Parquet文件
spark_df.write.parquet("output.parquet")
性能优化和注意事项
在加载和保存数据时,性能优化是一个重要的考虑因素。以下是一些性能优化和注意事项:
1 数据分区
在保存数据时,合理分区数据可以提高写入性能。您可以使用repartition方法来重新分区数据。
# 重新分区数据
data.repartition(4).write.parquet("output.parquet")
2 数据压缩
在保存数据时,考虑使用数据压缩可以减少存储空间和网络传输开销。可以在保存数据时指定压缩算法。
# 使用Snappy压缩算法保存数据
spark_df.write.parquet("output.parquet", compression="snappy")
3 数据合并
如果需要追加数据到已有的文件中,可以使用mode参数设置为append。
# 追加数据到已有文件中
data.write.mode("append").parquet("existing_data.parquet")
总结
Spark中的数据加载与保存是数据处理流程的重要步骤。本文深入探讨了数据加载与保存的基本概念、常见操作以及性能优化和注意事项。
希望本文能够帮助大家更好地理解和使用Spark中的数据加载与保存功能,并在数据处理和分析任务中取得更好的性能和效果。
相关文章:
Spark中的数据加载与保存
Apache Spark是一个强大的分布式计算框架,用于处理大规模数据。在Spark中,数据加载与保存是数据处理流程的关键步骤之一。本文将深入探讨Spark中数据加载与保存的基本概念和常见操作,包括加载不同数据源、保存数据到不同格式以及性能优化等方…...

2023-12-20 LeetCode每日一题(判别首字母缩略词)
2023-12-20每日一题 一、题目编号 2828. 判别首字母缩略词二、题目链接 点击跳转到题目位置 三、题目描述 给你一个字符串数组 words 和一个字符串 s ,请你判断 s 是不是 words 的 首字母缩略词 。 如果可以按顺序串联 words 中每个字符串的第一个字符形成字符…...
)
C# 事件(Event)
C# 事件(Event) C# 事件(Event)通过事件使用委托声明事件(Event)实例 C# 事件(Event) 事件(Event) 基本上说是一个用户操作,如按键、点击、鼠标移…...

2312d,d的sql构建器
原文 项目 该项目在我工作项目中广泛使用,它允许自动处理联接方式动态构建SQL语句. 还会自动直接按表示数据库行结构序化.它在dconf2022在线演讲中介绍了:建模一切. 刚刚添加了对sqlite的支持.该API还不稳定,但仍非常有用.这是按需构建,所以虽然有个计划外表,但满足了我的需要…...

以太网二层交换机实验
实验目的: (1)理解二层交换机的原理及工作方式; (2)利用交换机组建小型交换式局域网。 实验器材: Cisco packet 实验内容: 本实验可用一台主机去ping另一台主机,并…...

启封涂料行业ERP需求分析和方案分享
涂料制造业是一个庞大而繁荣的行业 它广泛用于建筑、汽车、电子、基础设施和消费品。涂料行业生产不同的涂料,如装饰涂料、工业涂料、汽车涂料和防护涂料。除此之外,对涂料出口的需求不断增长,这增加了增长和扩张的机会。近年来,…...
华为ensp网络设计期末测试题-复盘
网络拓扑图 地址分配表 vlan端口分配表 需求 The device is running!<Huawei>sys Enter system view, return user view with CtrlZ. [Huawei]un in en Info: Information center is disabled. [Huawei]sys S1 [S1]vlan 99 [S1-vlan99]vlan 100 [S1-vlan100]des IT [S1-…...

Dockerfile: WORKDIR vs VOLUME
WORKDIR WORKDIR指令为Dockerfile中的任何RUN、CMD、ENTRYPOINT、COPY和ADD指令设置工作目录。 如果WORKDIR不存在,它将被创建,即使它没有在任何后续Dockerfile指令中使用。 语法 : WORKDIR dirpath WORKDIR指令可以在Dockerfile中多次使用。如果提供了…...
;)
spring ioc源码-refresh();
主要作用是刷新应用上下文 Override public void refresh() throws BeansException, IllegalStateException {synchronized (this.startupShutdownMonitor) {// 启动刷新的性能跟踪步骤StartupStep contextRefresh this.applicationStartup.start("spring.context.refre…...

使用递归实现深拷贝
文章目录 为什么要使用递归什么深拷贝具体实现基础实现处理 函数处理 Symbol处理 Set处理 Map处理 循环引用 结语-源码 为什么要使用递归什么深拷贝 我们知道在 JavaScript 中可以通过使用JSON序列化来完成深拷贝,但是这种方法存在一些缺陷,比如对于函数…...

工程(十七)——自己数据集跑R2live
博主创建了一个科研互助群Q:772356582,欢迎大家加入讨论。 r2live是比较早的算法,编译过程有很多问题,通过以下两个博客可以解决 编译R2LIVE问题&解决方法-CSDN博客 r2live process has died 问题解决了_required process …...
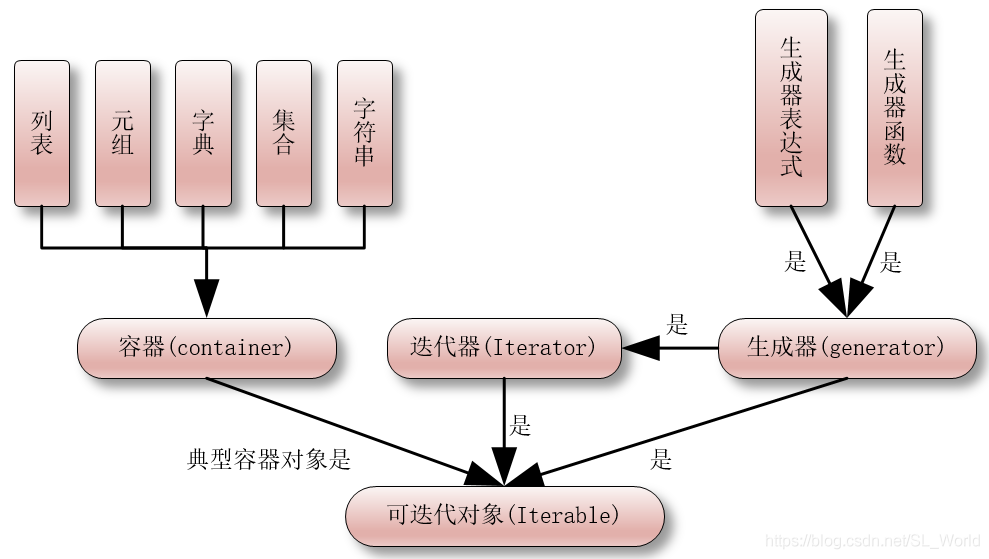
【python高级用法】迭代器、生成器、装饰器、闭包
迭代器 可迭代对象:可以使用for循环来遍历的,可以使用isinstance()来测试。 迭代器:同时实现了__iter__()方法和__next__()方法,可以使用isinstance()方法来测试是否是迭代器对象 from collections.abc import Iterable, Iterat…...

Nx市工业数据洞察:Flask、MySQL、Echarts的可视化之旅
Nx市工业数据洞察:Flask、MySQL、Echarts的可视化之旅 背景数据集来源技术选型功能介绍创新点总结 背景 随着工业化的不断发展,Nx市工业数据的收集和分析变得愈发重要。本博客将介绍如何利用Flask、MySQL和Echarts等技术,从统计局获取的数据…...

关于正态分布
目录 1.正态分布是什么2.正态分布有什么用途3.如何确定数据服从正态分布 本文简单介绍正态分布的基本概念和用途。 1.正态分布是什么 正态分布,也称为高斯分布,是由德国数学家卡尔弗里德里希高斯在研究测量误差时提出的。他发现许多自然现象和统计数据…...

每日一练(编程题-C/C++)
目录 CSDN每日一练1. 2023/2/27- 一维数组的最大子数组和(类型:数组 难度:中等)2. 2023/4/7 - 小艺照镜子(类型:字符串 难度:困难)3. 2023/4/14 - 最近的回文数(难度:中等)4. 2023/2/1-蛇形矩阵(难度:困难)…...

Unity UnityWebRequest 在Mac上使用报CommectionError
今天是想把前两天写的Demo拿到Mac上打个IPA的完事我发现 在运行时释放游戏资源的时候UnityWebRequest返回的结果不是Success 查看Log发现是 req.result 是CommectionError error是 Cannot connect to destination host 代码如下: UnityWebRequest req UnityWebRequ…...

WorkPlus为企业打造私有化部署IM解决方案
在移动数字化时代,企业面临着如何全面掌控业务和生态的挑战。企业微信、钉钉、飞书、Teams等应用虽然提供了部分解决方案,但无法满足企业的私有化部署需求。此时,WorkPlus作为安全专属的移动数字化平台,被誉为移动应用的“航空母舰…...
QT上位机开发(抽奖软件)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing 163.com】 用抽奖软件抽奖,是一种很常见的抽奖方式。特别是写这篇文章的时候,正好处于2023年12月31日,也是一年中最后一天…...

雨课堂作业整理
第一次作业 1.下列序列是图序列的是( ) A.1,2,2,3,4,4,5 B.1,1,2,2,4,6,6 C.0,0,2&am…...

C#/WPF 只允许一个实例程序运行并将已运行程序置顶
使用用互斥量(System.Threading.Mutex): 同步基元,它只向一个线程授予对共享资源的独占访问权。在程序启动时候,请求一个互斥体,如果能获取对指定互斥的访问权,就职运行一个实例。 实例代码: /// <…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

CMake控制VS2022项目文件分组
我们可以通过 CMake 控制源文件的组织结构,使它们在 VS 解决方案资源管理器中以“组”(Filter)的形式进行分类展示。 🎯 目标 通过 CMake 脚本将 .cpp、.h 等源文件分组显示在 Visual Studio 2022 的解决方案资源管理器中。 ✅ 支持的方法汇总(共4种) 方法描述是否推荐…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...