一次降低进程IO延迟的性能优化实践——基于block层bfq调度器
如果有个进程正频繁的读写文件,此时你vim查看一个新文件,将会出现明显卡顿。即便你vim查看的文件只有几十M,也可能会出现卡顿。相对的,线上经常遇到IO敏感进程偶发IO超时问题。这些进程一次读写的文件数据量很少,正常几十ms就能搞定,但是超时一次读写文件竟耗时几百ms!为什么会这样?出问题的时间点IO流量很大,磁盘IO使用率util接近100%,磁盘IO带宽占满了,IO压力太大。
原来IO敏感进程是受其他进程频繁读写文件影响导致的IO超时,怎么解决这个问题呢?磁盘选用nvme,进程的IO优先级iorenice设置实时优先级,可以一定程度缓解磁盘IO压力大场景IO敏感进程的IO超时问题,但是还是有问题!很好复现,磁盘nvme、IO调度算法bfq、启动fio压测(10个线程,128k随机写),cat读取200M大小的文件(cat进程的IO优先级设置为实时),耗时竟然会达到800ms多,而在IO空闲时只耗时200ms左右!
为什么会这样?如果你用iostat看下fio压测时的io wait(平均IO延迟)数据,发现打印的io wait 达到50ms是家常便饭。而我用systemtap抓取一下nvme盘此时DC耗时(IO请求在磁盘驱动层花费的时间)大于100ms的IO请求,竟然是会频繁打印,说明fio压测时有很多IO请求在nvme磁盘驱动的耗时都很大。调试显示,nvme磁盘驱动队列深度是1024,就是说驱动队列最多可以容纳1024个IO请求,一个128K大小的IO请求传输完成耗时50us,这1024个IO请求传输完成需耗时1024*50us=50ms。fio压测时大部分时间nvme磁盘驱动队列都是占满的,此时cat读取文件,cat进程发送的每个IO请求,大概率都排在nvme磁盘驱动队列尾,都要等队列前边fio进程的IO请求传输完成。如此,cat进程有很多IO请求在磁盘驱动层的耗时都达到50ms左右,那怪不得fio压测时cat读取文件慢了很多。
能否改善这种情况呢?磁盘nvme、IO优先级设置为实时也没用!能否在cat读取文件过程,控制nvme磁盘驱动队列的IO请求数,不要占满,比如nvme磁盘驱动队列的IO请求数控制在100。这样fio压测时,因为nvme磁盘驱动队列的IO请求数不超过100,此时cat读取文件时,cat进程的IO请求即便不幸插入到nvme磁盘驱动队列尾,这个IO请求传输完成最大耗时也只有100*50us=5ms。如果能达到这种效果,IO压力大时IO敏感进程IO超时问题就能得到明显改善了。
按照这个思路目前已经实现了预期效果,本文主要介绍设计思路。这个设计思路是在bfq算法基础上实现的,核心思想是控制派发给nvme磁盘驱动的IO请求数,不超过某个阀值。思路很简单,但是开发过程遇到的问题是个血泪史!本文基于centos 8.3,内核版本4.18.0-240.el8,探索下bfq算法,详细源码注释见 https://github.com/dongzhiyan-stack/linux-4.18.0-240.el8。
注意,本文将IO请求简称rq或者req。另外本文的测试环境是centos 8.3虚拟机。阅读本文前,希望读者先看看我写的《linux内核block层Multi queue多队列核心点分析》。这篇文章是针对block层Multi queue(简称blk-mq) 多队列基础知识点总结。
1:核心优化思路
先看一次普通的读文件触发的IO派发流程:
- [ffffb71980cbb6b8] scsi_queue_rq at ffffffffb71d1a51
- [ffffb71980cbb708] blk_mq_dispatch_rq_list at ffffffffb7009f4c
- [ffffb71980cbb7d8] blk_mq_do_dispatch_sched at ffffffffb700f4ba
- [ffffb71980cbb830] __blk_mq_sched_dispatch_requests at ffffffffb700ff99
- [ffffb71980cbb890] blk_mq_sched_dispatch_requests at ffffffffb7010020
- [ffffb71980cbb8a0] __blk_mq_run_hw_queue at ffffffffb70076a1
- [ffffb71980cbb8b8] __blk_mq_delay_run_hw_queue at ffffffffb7007f61
- [ffffb71980cbb8e0] blk_mq_sched_insert_requests at ffffffffb7010351
- [ffffb71980cbb918] blk_mq_flush_plug_list at ffffffffb700b4d6
- [ffffb71980cbb998] blk_flush_plug_list at ffffffffb6fffbe7
- [ffffb71980cbb9e8] blk_mq_make_request at ffffffffb700ad38
- [ffffb71980cbba78] generic_make_request at ffffffffb6ffe85f
- [ffffb71980cbbad0] submit_bio at ffffffffb6ffeadc
- [ffffb71980cbbb10] ext4_mpage_readpages at ffffffffc081b9a4 [ext4]
- [ffffb71980cbbbf8] read_pages at ffffffffb6e3743b
- [ffffb71980cbbc70] __do_page_cache_readahead at ffffffffb6e37721
- [ffffb71980cbbd08] ondemand_readahead at ffffffffb6e37939
- [ffffb71980cbbd50] generic_file_buffered_read at ffffffffb6e2ce5f
- [ffffb71980cbbe40] new_sync_read at ffffffffb6ed8841
- [ffffb71980cbbec8] vfs_read at ffffffffb6edb1c1
可以发现,派发IO最后的流程是__blk_mq_sched_dispatch_requests->blk_mq_do_dispatch_sched->blk_mq_dispatch_rq_list,也与本次的性能优化有关。看下blk_mq_do_dispatch_sched函数源码
- static int blk_mq_do_dispatch_sched(struct blk_mq_hw_ctx *hctx)
- {
- struct request_queue *q = hctx->queue;
- struct elevator_queue *e = q->elevator;
- LIST_HEAD(rq_list);
- int ret = 0;
- do {
- struct request *rq;
- //bfq_has_work
- if (e->type->ops.has_work && !e->type->ops.has_work(hctx))
- break;
- if (!list_empty_careful(&hctx->dispatch)) {
- ret = -EAGAIN;
- break;
- }
- if (!blk_mq_get_dispatch_budget(hctx))
- break;
- //调用bfq调度器IO派发函数bfq_dispatch_request
- rq = e->type->ops.dispatch_request(hctx);
- if (!rq) {
- blk_mq_put_dispatch_budget(hctx);
- blk_mq_delay_run_hw_queues(q, BLK_MQ_BUDGET_DELAY);
- break;
- }
- list_add(&rq->queuelist, &rq_list);
- /*取出rq_list链表上的req派发给磁盘驱动,如果因驱动队列繁忙或者nvme硬件繁忙导致派发失败,则把rq添加hctx->dispatch等稍后派发遇到rq派发失败返回false,退出while循环*/
- } while (blk_mq_dispatch_rq_list(q, &rq_list, true));
- return ret;
- }
该函数作用是:执行bfq_dispatch_request()函数循环从IO调度器队列取出IO请求存入rq_list链表,然后取出rq_list链表上的rq执行blk_mq_dispatch_rq_list()派发给磁盘驱动。blk_mq_dispatch_rq_list()函数如果因驱动队列繁忙或者磁盘硬件繁忙导致派发失败则返回false,此时blk_mq_do_dispatch_sched()函数退出while循环。当然,如果IO调度器队列没IO请求了,bfq_dispatch_request返回NULL,此时blk_mq_do_dispatch_sched()函数也会退出while循环。把blk_mq_dispatch_rq_list源码简单列下:
- bool blk_mq_dispatch_rq_list(struct request_queue *q, struct list_head *list,
- bool got_budget)
- {
- struct blk_mq_hw_ctx *hctx;
- struct request *rq, *nxt;
- bool no_tag = false;
- int errors, queued;
- blk_status_t ret = BLK_STS_OK;
- bool no_budget_avail = false;
- ................
- errors = queued = 0;
- do {
- struct blk_mq_queue_data bd;
- rq = list_first_entry(list, struct request, queuelist);
- hctx = rq->mq_hctx;
- ................
- list_del_init(&rq->queuelist);
- bd.rq = rq;
- if (list_empty(list))
- bd.last = true;
- else {
- nxt = list_first_entry(list, struct request, queuelist);
- bd.last = !blk_mq_get_driver_tag(nxt);
- }
- //把rq派发给驱动
- ret = q->mq_ops->queue_rq(hctx, &bd);//scsi_queue_rq 或 nvme_queue_rq
- //这个if成立应该说明是 驱动队列繁忙 或者nvme硬件繁忙,不能再向驱动派发IO,因此本次的rq派发失败
- if (ret == BLK_STS_RESOURCE || ret == BLK_STS_DEV_RESOURCE) {
- if (!list_empty(list)) {
- //把rq在list链表上的下一个req的tag释放了,搞不清楚为什么
- nxt = list_first_entry(list, struct request, queuelist);
- blk_mq_put_driver_tag(nxt);
- }
- //把派发失败的rq再添加到list链表
- list_add(&rq->queuelist, list);
- __blk_mq_requeue_request(rq);
- break;
- }
- ...........
- //派发rq失败则queued加1
- queued++;
- //一直派发list链表上的req直到list链表空
- } while (!list_empty(list));
- hctx->dispatched[queued_to_index(queued)]++;
- //如果list链表上还有rq,说明派发rq时遇到驱动队列或者硬件繁忙,rq没有派发成功
- if (!list_empty(list)) {
- ...........
- spin_lock(&hctx->lock);
- //list上没有派发成功的rq添加到hctx->dispatch链表,稍后延迟派发
- list_splice_tail_init(list, &hctx->dispatch);
- spin_unlock(&hctx->lock);
- ......................
- blk_mq_update_dispatch_busy(hctx, true);
- return false;
- } else
- blk_mq_update_dispatch_busy(hctx, false);
- //派发rq时遇到驱动队列或者硬件繁忙,返回false,否则派发正常下边返回true
- if (ret == BLK_STS_RESOURCE || ret == BLK_STS_DEV_RESOURCE)
- return false;
- return (queued + errors) != 0;
- }
该函数只是取出list链表上的rq派发给磁盘驱动,如果因驱动队列繁忙或者磁盘硬件繁忙导致派发失败,则把rq添加hctx->dispatch等稍后派发。本文的IO优化算法是在bfq算法基础上实现的,最好先对bfq算法有个了解,希望重点看下《内核block层IO调度器—bfq算法之1整体流程介绍》、《内核block层IO调度器—bfq算法之3源码要点总结》、《内核block层IO调度器—bfq算法深入探索2》这3篇文章。
bfq算法把进程传输的IO归为3类,in_large_burst型IO、交互式IO、实时性IO。fio这种短时间多个线程派发IO的属于in_large_burst型IO,进程偶尔读写一次文件且数据量不大的属于交互式IO,进程周期性的读写文件且数据量不大的属于实时性IO。这3种IO模型的对IO时延要求依次增加, bfq算法定义了bfqq->wr_coeff变量这个权重系数来表达这种特性,针对这3中IO模型依次是1、30、30* 100。bfqq->wr_coeff越大,派发IO的进程绑定的bfqq插入st->active tree(可以理解成IO运行队列)越靠左,这样可以更早被bfq调度器调度选中,进而更早得到派发该bfqq对应进程的IO,保证了低延迟。
本案例的场景是,在IO压力大时怎么降低IO敏感进程的时延。怎么模拟这种场景呢?fio压测模拟IO压力大,然后cat kern读取文件(kern文件几百M)作为IO敏感进程。在开启fio压测下cat kern读取文件,观察cat kern耗时。在磁盘空闲时,cat kern只耗时不到100ms。在开启fio压测情况,cat kern耗时500ms+。如果我的IO优化方案生效,则需要实现在开启fio压测情况下,cat kern耗时小于500ms,比如200ms、300ms。这是虚拟机里的测试数据,每次不太稳定。
ok,具体代码在何处实现呢?首先是把IO请求插入bfq IO算法队列执行的bfq_insert_request()->__bfq_insert_request()->bfq_add_request()函数,添加如下红色代码:
- /*高优先级rq*/
- #define RQF_HIGH_PRIO ((__force req_flags_t)(1 << 21))
- static void bfq_add_request(struct request *rq)
- {
- if (!bfq_bfqq_busy(bfqq)){
- bfq_bfqq_handle_idle_busy_switch(bfqd, bfqq, old_wr_coeff,rq, &interactive);
- }
- ..............
- if(bfqq->wr_coeff == 30){
- //设置rq高优先级
- rq->rq_flags |= RQF_HIGH_PRIO;
- }
- }
if(bfqq->wr_coeff == 30)成立说明当前IO传输的进程绑定的bfqq拥有高优先级rq属性,则执行rq->rq_flags |= RQF_HIGH_PRIO对rq设置高优先级rq标志。
这里插一句,本文的测试环境是,在fio压测情况观察cat kern读取文件的耗时。bfq算法中,针对fio这种频繁派发IO的进程,fio进程属于burst型IO,它的进程的bfqq对应的bfqq->wr_coeff大部分情况是1。而针对cat这种偶尔读取一次文件的进程,是交互式IO,该进程的bfqq的bfqq->wr_coeff初值是30。显然,cat kern读取文件过程,cat进程派发的IO大部分拥有高优先级rq属性,这是本文的IO性能优化方案的设计思路。
接着是从bfq IO算法队列派发IO请求执行的blk_mq_dispatch_rq_list(),源码有删减,红色是性能优化添加的代码:
- static struct request *__bfq_dispatch_request(struct blk_mq_hw_ctx *hctx)
- {
- struct bfq_data *bfqd = hctx->queue->elevator->elevator_data;
- struct request *rq = NULL;
- struct bfq_queue *bfqq = NULL;
- int direct_dispatch = 0;
- //不经IO算法队列,直接派发的rq
- if (!list_empty(&bfqd->dispatch)) {
- rq = list_first_entry(&bfqd->dispatch, struct request,queuelist);
- list_del_init(&rq->queuelist);
- bfqq = RQ_BFQQ(rq);
- direct_dispatch = 1;
- if (bfqq) {
- bfqq->dispatched++;
- goto inc_in_driver_start_rq;
- }
- goto start_rq;
- }
- .....................
- bfqq = bfq_select_queue(bfqd);
- if (!bfqq)
- goto exit;
- rq = bfq_dispatch_rq_from_bfqq(bfqd, bfqq);
- if (rq) {
- if(bfqd->queue->high_io_prio_enable)
- {
- if(rq->rq_flags & RQF_HIGH_PRIO){//高优先级IO
- //第一次遇到high prio io,置1 bfq_high_io_prio_mode,启动3s定时器,定时到了对bfq_high_io_prio_mode清0
- if(bfqd->bfq_high_io_prio_mode == 0){
- bfqd->bfq_high_io_prio_mode = 1;
- hrtimer_start(&bfqd->bfq_high_prio_timer, ms_to_ktime(3000),HRTIMER_MODE_REL);
- }
- }
- else非高优先级IO
- {
- if(bfqd->bfq_high_io_prio_mode)
- {
- //在 bfq_high_io_prio_mode 非0时间的5s内,如果遇到非high prio io,并且驱动队列IO个数大于限制,则把不派发该IO,而是临时添加到bfq_high_prio_tmp_list链表
- if((bfqd->rq_in_driver >= 20) /*&& (bfqd->bfq_high_prio_tmp_list_rq_count < 100)*/){
- list_add_tail(&rq->queuelist,&bfqd->bfq_high_prio_tmp_list);
- //bfq_high_prio_tmp_list链表上rq的个数加1
- bfqd->bfq_high_prio_tmp_list_rq_count ++;
- rq = NULL;
- goto exit1;
- }
- }
- }
- }
- /*如果 bfq_high_prio_tmp_list 链表上有rq要派发,不执行这里的rq_in_driver++,在下边的exit那里会执行。当echo 0 >/sys/block/sdb/process_high_io_prio 置1再置0后,这个if判断就起作用了。没这个判断,这里会bfqd->rq_in_driver++,下边的if里再bfqd->rq_in_driver++,导致rq_in_driver泄漏*/
- if((rq->rq_flags & RQF_HIGH_PRIO) || list_empty(&bfqd->bfq_high_prio_tmp_list)){
- inc_in_driver_start_rq:
- bfqd->rq_in_driver++;
- start_rq:
- rq->rq_flags |= RQF_STARTED;
- }
- }
- exit:
- //1:如果是高优先级IO该if不成立,直接跳过。 2:如果非高优先级IO,则把rq添加到bfq_high_prio_tmp_list尾,从链表头选一个rq派发 3:如果rq是NULL,则也从bfq_high_prio_tmp_list选一个rq派发
- if(!direct_dispatch && ((rq && !(rq->rq_flags & RQF_HIGH_PRIO)) || !rq)){
- /*如果bfq_high_prio_tmp_list有Io, 则不派发本次的io而添加到bfq_high_prio_tmp_list尾部,实际从bfq_high_prio_tmp_list链表头取出一个IO派发。放到 if(bfqd->queue->high_io_prio_enable)外边是为了保证一旦设置high_io_prio_enable为0,还能派发残留的在bfq_high_prio_tmp_list上的IO*/
- if(!list_empty(&bfqd->bfq_high_prio_tmp_list)){
- if(rq){
- list_add_tail(&rq->queuelist,&bfqd->bfq_high_prio_tmp_list);
- bfqd->bfq_high_prio_tmp_list_rq_count ++;
- }
- rq = list_first_entry(&bfqd->bfq_high_prio_tmp_list, struct request, queuelist);
- list_del_init(&rq->queuelist);
- //bfq_high_prio_tmp_list链表上rq的个数减1
- bfqd->bfq_high_prio_tmp_list_rq_count --;
- bfqd->rq_in_driver++;
- rq->rq_flags |= RQF_STARTED;
- }
- }
- exit1:
- ..................
- return rq;
- }
该函数中,首先执行bfqq = bfq_select_queue(bfqd)算法本次派发rq的bfqq,然后执行rq = bfq_dispatch_rq_from_bfqq(bfqd, bfqq)从bfqq的IO队列取出本次派发的IO请求。后边的就是针对本次性能优化添加的代码。bfqd->queue->high_io_prio_enable是一个使能开关,执行echo 1 >/sys/block/sdb/process_high_io_prio才会打开本文的性能优化功能。继续,如果派发的rq有高优先级属性(即rq->rq_flags & RQF_HIGH_PRIO返回true),则bfqd->bfq_high_io_prio_mode = 1置1,这是进入派发高优先级IO的开始标志。然后执行hrtimer_start(&bfqd->bfq_high_prio_timer, ms_to_ktime(3000),HRTIMER_MODE_REL)启动3s定时器,3s后在定时器函数里令bfqd->bfq_high_io_prio_mode = 0,这是派发高优先级IO的结束标志。
ok,在第一次遇到派发的rq有高优先级属性后,就会令bfqd->bfq_high_io_prio_mode = 1置1并进入” 派发高优先级IO”的3s时期。这段时间只有rq有高优先级属性才会会作为__bfq_dispatch_request()返回的rq,真正得到机会派发给磁盘驱动。否则,普通的rq就要执行list_add_tail(&rq->queuelist,&bfqd->bfq_high_prio_tmp_list)暂时添加到bfqd->bfq_high_prio_tmp_list链表,延迟派发,当然前提要有bfqd->rq_in_driver >= 20成立,就是说派发给磁盘驱动但还没传输完成的IO数要达到某个阀值(我在虚拟机里测试的sda机械盘磁盘队列深度是32,nvme盘队列深度达到1000多,建议这个阀值达到磁盘队列深度的60%以上)。
为什么要这么设计?其实就是要在派发给磁盘驱动但还没传输完成的IO数达到磁盘队列深度的某个阀值后(之后再派发IO可能就会把磁盘驱动IO队列占满了),此时正好有进程要派发IO敏感的IO请求(这些IO请求rq标记有RQF_HIGH_PRIO属性),优先派发IO敏感进程的IO,延迟派发普通进程的IO(就是把这些rq暂时添加到bfqd->bfq_high_prio_tmp_list链表)。等系统空闲后,IO敏感进程的IO都派发完了,再从bfqd->bfq_high_prio_tmp_list链表取出延迟派发的IO而继续派发。
简单说,在普通进程和IO敏感进程同时派发IO时,在普通进程的IO把磁盘驱动IO队列快占满前,限制普通进程向磁盘驱动IO队列派发的IO数,防止把磁盘驱动IO队列占满。此时呢,要优先派发IO敏感进程的IO到磁盘驱动队列的IO。通过这个方法,防止在IO压力很大时影响IO敏感进程派发IO的时延。
2: 实现IO性能优化效果的曲折过程
开始测试,虚拟机centos 8.3系统。先执行echo 1 >/sys/block/sdb/process_high_io_prio打开本文的IO性能优化功能。然后启动fio压测,同时time cat kern > /dev/null读取文件并打印耗时(kern文件大小300M)。没想到,竟然一点效果没有!以下是测试数据
- 1:echo 1 >/sys/block/sdb/process_high_io_prio打开IO性能优化功能,开启fio压测,cat kern耗时500ms左右,偶尔会出现耗时800ms甚至1s
- 2:echo 0 >/sys/block/sdb/process_high_io_prio关闭IO性能优化功能,开启fio压测,cat kern耗时500ms左右,偶尔会出现耗时800ms甚至1s
- 3:echo 1 >/sys/block/sdb/process_high_io_prio打开IO性能优化功能,关闭fio压测,cat kern耗时不到100ms
总结下,在磁盘IO空闲时,cat kern耗时不到100ms,而在fio压测情况下,开启和关闭IO性能优化,cat kern耗时没有区别。甚至,多次测试后,发现开启IO性能比关闭IO性能优化,cat kern更耗时。这就说明,本文的IO性能优化方案不仅没起到作用,反而拖了后腿!这就需要找下原因了!
此时,在之前”统计进程派发IO的延迟”功能的帮助下,发现开启IO性能优化功能时,启动fio压测,cat kern读取文件派发IO过程,cat进程的id耗时(IO请求在IO队列的耗时)明显偏大, id耗时(IO请求在磁盘驱动层的耗时)也没有缩短。再进一步排查,发现在fio压测时,当cat进程有IO要派发而插入bfq 的IO算法队列后,cat进程的bfqq竟然经常出现过了10ms+才得到调度机会!就是说,fio压测时,当cat进程要派发IO时,fio一直占着IO派发机会,cat进程推迟10ms+才得到派发IO机会。
怎么解决这个问题?首要目的是降低cat kern进程的延迟!就是要让cat进程的来了IO请求后,尽快得到调度派发。怎么实现,需要增大cat进程的bfqq->wr_coeff,这样cat进程绑定的bfqq插入st->active tree(可以理解成IO运行队列)后才能尽可能早的被IO调度器选中,进而派发cat进程的IO,得到调度延迟的效果。经过繁琐的调试,这样调整优化方案:
在进程bfqq派发派发IO请求过程,因为配额没了而过期失效,然后重新加入st->active tree执行的__bfq_requeue_entity()函数中:
- static void __bfq_requeue_entity(struct bfq_entity *entity)
- {
- struct bfq_sched_data *sd = entity->sched_data;
- struct bfq_service_tree *st = bfq_entity_service_tree(entity);
- //如果bfqq->wr_coeff是30说明是交互式io,执行到这里说明派发这个进程派发的IO太多了,配合消耗完了还没派发完io。此时说明该进程的bfqq需要提升权重,提高优先级,作为high prio io.
- struct bfq_queue *bfqq = bfq_entity_to_bfqq(entity);
- if(bfqq && bfqq->bfqd->queue->high_io_prio_enable && bfqq->wr_coeff == 30){
- bfqq->wr_coeff = 30 * BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR;
- //置1表示权重变了,然后才会在bfq_update_fin_time_enqueue->__bfq_entity_update_weight_prio 里真正提升权重
- entity->prio_changed = 1;
- //增大权重提升时间为1.5s
- bfqq->wr_cur_max_time = msecs_to_jiffies(1500);
- //权重提升时间开始时间为当前时间
- bfqq->last_wr_start_finish = jiffies;
- bfqq->entity.completed_size = 0;
- }
- .............
- if (entity->tree)
- bfq_active_extract(st, entity);
- bfq_update_fin_time_enqueue(entity, st, false);
- }
cat进程最初派发IO时被判定为交互式IO,bfqq->wr_coeff是30。实际测试表明,cat进程因为派发IO很多导致的bfqq第一次过期失效,是配额耗尽而过期失效。此时cat进程的bfqq是要重新插入st->active tree而等待bfq调度器再次被选中派发IO,执行的正是__bfq_requeue_entity()函数!在__bfq_requeue_entity()函数中,发现cat进程bfqq的bfqq->wr_coeff是30,就增大bfqq->wr_coeff为bfqq->wr_coeff = 30 * BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR,BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR是50。
还有一个重点是bfqq->wr_cur_max_time = msecs_to_jiffies(1500),这是cat进程的bfqq权重系数增大为30 * BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR的时间期限,bfqq->last_wr_start_finish = jiffies是cat进程的bfqq权重系数增大为30 * BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR的起始时间。这样设置过后,从当前时间起的1.5s内,cat进程的bfqq->wr_coeff的都是30 * BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR!这样的效果就是,这段时间cat进程的bfqq插入st->active tree后能尽可能被bfq调度器选中派发IO,大大降低延迟!
在插入IO请求函数bfq_add_request()中,遇到bfqq->wr_coeff是30 * BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR的进程bfqq,才会把该bfqq的IO设置高优先级标志RQF_HIGH_PRIO。这样是为了过滤bfqq->wr_coeff是30的进程的IO,不让这种IO被判定为高优先级IO。
- #define BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR 50
- static void bfq_add_request(struct request *rq)
- {
- if (!bfq_bfqq_busy(bfqq)){
- bfq_bfqq_handle_idle_busy_switch(bfqd, bfqq, old_wr_coeff,rq, &interactive);
- }
- .............
- if(bfqq->wr_coeff == 30*BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR){
- //设置rq高优先级
- rq->rq_flags |= RQF_HIGH_PRIO;
- }
- }
在cat进程因没有IO请求派发而过期失效,加入st->idle tree。然后过了一段时间又来了新的IO请求,此时需要执行bfq_add_request()->bfq_bfqq_handle_idle_busy_switch()激活cat进程的bfqq,把bfqq插入st->active tree。在这个函数中强制cat进程的bfqq->wr_coeff保持30*BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR,不受bfq_bfqq_handle_idle_busy_switch()原生代码的影响,具体实现看如下红色代码。
- static void bfq_bfqq_handle_idle_busy_switch(struct bfq_data *bfqd,
- struct bfq_queue *bfqq,
- int old_wr_coeff,
- struct request *rq,
- bool *interactive)
- {
- //禁止high prio io进程被判定为rt、interactive 、burst 型io,这样下边的bfq_update_bfqq_wr_on_rq_arrival()函数不会修改它的 bfqq->wr_coeff
- if(bfqq->wr_coeff == 30*BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR){
- *interactive = 0;
- wr_or_deserves_wr = 0;
- in_burst = 0;
- soft_rt = 0;
- }
- ................
- bfq_update_bfqq_wr_on_rq_arrival(bfqd, bfqq,
- old_wr_coeff,
- wr_or_deserves_wr,
- *interactive,
- in_burst,
- soft_rt);
- ................
- }
在cat进程的bfqq被bfq调度器选中派发IO后,每次执行派发IO执行__bfq_dispatch_request()->bfq_dispatch_rq_from_bfqq()->bfq_update_wr_data()过程,都会检查cat进程的bfqq权重提升时间是否到了,到了的话就要令bfqq的权重提升时间结束,令bfqq->wr_coeff重置为1,之后cat进程的bfqq就不再享有低延时派发特性了。在结束进程权重提升bfq_update_wr_data()函数需要添加如下红色代码,否则会导致cat进程的bfqq的bfqq->wr_coeff被设置为30*BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR后,很短时间就会执行里边的bfq_bfqq_end_wr()令bfqq->wr_coeff重置为1。
- static void bfq_update_wr_data(struct bfq_data *bfqd, struct bfq_queue *bfqq)
- {
- struct bfq_entity *entity = &bfqq->entity;
- if (bfqq->wr_coeff > 1) {
- ...............
- if (bfq_bfqq_in_large_burst(bfqq)){
- bfq_bfqq_end_wr(bfqq);
- }
- else if (time_is_before_jiffies(bfqq->last_wr_start_finish +
- bfqq->wr_cur_max_time)) {
- if (bfqq->wr_cur_max_time != bfqd->bfq_wr_rt_max_time ||
- time_is_before_jiffies(bfqq->wr_start_at_switch_to_srt +
- bfq_wr_duration(bfqd)))
- {
- bfq_bfqq_end_wr(bfqq);
- }
- else {
- switch_back_to_interactive_wr(bfqq, bfqd);
- bfqq->entity.prio_changed = 1;
- }
- }
- if (bfqq->wr_coeff > 1 &&
- bfqq->wr_cur_max_time != bfqd->bfq_wr_rt_max_time &&
- bfqq->service_from_wr > max_service_from_wr &&
- bfqq->wr_coeff != 30 * BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR)//high prio io进程禁止在这里结束权重提升
- {
- bfq_bfqq_end_wr(bfqq);
- }
- }
- if ((entity->weight > entity->orig_weight) != (bfqq->wr_coeff > 1)){
- __bfq_entity_update_weight_prio(bfq_entity_service_tree(entity),
- entity, false);
- }
- }
在派发IO请求的bfq_dispatch_rq_from_bfqq()函数添加如下代码:
- static struct request *bfq_dispatch_rq_from_bfqq(struct bfq_data *bfqd,
- struct bfq_queue *bfqq)
- {
- struct request *rq = bfqq->next_rq;
- unsigned long service_to_charge;
- service_to_charge = bfq_serv_to_charge(rq, bfqq);
- bfq_bfqq_served(bfqq, service_to_charge);
- bfq_dispatch_remove(bfqd->queue, rq);
- if (bfqq != bfqd->in_service_queue)
- goto return_rq;
- if(bfqd->queue->high_io_prio_enable){
- if(bfqq->wr_coeff == 30 * BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR){
- //累加bfqq传输完成的rq的数据量,如果bfqq传输数据量太多而超过限制,强制令进程bfqq不再有high prio io属性
- bfqq->entity.completed_size += blk_rq_bytes(rq);
- if(bfqq->entity.completed_size > bfqd->high_prio_io_all_size_limit){
- bfq_bfqq_end_wr(bfqq);
- }
- }
- }
- bfq_update_wr_data(bfqd, bfqq);
- ...................
- }
这是令被判定为高优先级IO的进程派发的数据量超过bfqd->high_prio_io_all_size_limit阀值(200M或者300M)后,就结束该进程的高优先级IO属性,具体是执行bfq_bfqq_end_wr(bfqq)令bfqq->wr_coeff由30 * BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR降低为1,这就是普通IO了。这样做是为了防止fio这种频繁数据传输IO的进程被长时间判定为高优先级IO,因为fio进程最初派发IO时,被判定为交互式IO,fqq->wr_coeff = 30。然后因配额耗尽而执行__bfq_requeue_entity()重新加入st->active tree时,因为bfqq->wr_coeff 是30,则fqq->wr_coeff = 30* BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR。这样fio进程就被判定为高优先级IO了!这个是没办法避免的,但是等fio派发IO的数据量超过bfqd->high_prio_io_all_size_limit,就强制令fio结束高优先级IO属性。
这样终于实现了IO性能优化效果, echo 1 >/sys/block/sdb/process_high_io_prio打开IO性能优化功能,开启fio压测,cat kern耗时只有200ms左右:
- 1:echo 1 >/sys/block/sdb/process_high_io_prio打开IO性能优化功能,开启fio压测,cat kern耗时200ms左右,偶尔会出现耗时800m,但出现概率低
- 2:echo 1 >/sys/block/sdb/process_high_io_prio关闭IO性能优化功能,开启fio压测,cat kern耗时200ms左右,但设置cat进程的IO调度算法为RT,偶尔会出现耗时800ms,但出现概率更高
可以发现,本文的性能优化效果比设置IO调度算法为RT更优。这说明本文的IO性能优化算法——降低磁盘驱动队列深度而降低IO敏感进程的IO在磁盘驱动的耗时,终于起到了作用!因为这是在虚拟机里做的测试,性能不太稳定。如果在PC本地测试,性能稳定很多,但是测试规律跟上边一致。
3:其他优化方案
如上方案终于实现了预期效果,但是还有还有其他性能优化点。主要是在IO请求插入IO队列的bfq_add_request()函数:
- #define BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR 50
- static void bfq_add_request(struct request *rq)
- {
- if (!bfq_bfqq_busy(bfqq)){
- bfq_bfqq_handle_idle_busy_switch(bfqd, bfqq, old_wr_coeff,rq, &interactive);
- }
- ..............
- //如果同一个线程组的进程近期有in_large_burst属性,禁止它新创建的线程被判定为交互式io
- if(bfq_bfqq_in_large_burst(bfqq)){
- if(current->tgid != bfqd->large_burst_process_tgid){
- bfqd->large_burst_process_tgid = current->tgid;
- strncpy(bfqd->large_burst_process_name,current->comm,COMM_LEN-1);
- bfqd->large_burst_process_count = 0;
- }else{
- bfqd->large_burst_process_count ++;
- }
- }
- if(bfqq->wr_coeff == 30*BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR){
- //设置rq高优先级
- rq->rq_flags |= RQF_HIGH_PRIO;
- }
- }
把IO请求插入IO队列,把进程bfqq激活插入st->active tree执行的bfq_bfqq_handle_idle_busy_switch()函数中,添加如下代码:
- static void bfq_bfqq_handle_idle_busy_switch(struct bfq_data *bfqd,
- struct bfq_queue *bfqq,
- int old_wr_coeff,
- struct request *rq,
- bool *interactive)
- {
- bool soft_rt, in_burst, wr_or_deserves_wr,
- bfqq_wants_to_preempt,
- idle_for_long_time = bfq_bfqq_idle_for_long_time(bfqd, bfqq),
- ...................
- in_burst = bfq_bfqq_in_large_burst(bfqq);
- soft_rt = bfqd->bfq_wr_max_softrt_rate > 0 &&
- !BFQQ_TOTALLY_SEEKY(bfqq) &&
- !in_burst &&
- time_is_before_jiffies(bfqq->soft_rt_next_start) &&
- bfqq->dispatched == 0;
- *interactive = !in_burst && idle_for_long_time;
- //如果同一个线程组的进程近期有in_large_burst属性,禁止它新创建的线程被判定为交互式io
- if((bfqd->large_burst_process_count > 1) &&(bfqd->large_burst_process_tgid == current->tgid) && (strncmp(bfqd->large_burst_process_name,current->comm,COMM_LEN-1) == 0)){
- *interactive = 0;
- soft_rt = 0;
- in_burst = 1;
- bfq_prevent_high_prio_count++;
- }
- /*该if成立,说明当前进程最近被判定为high prio io。这样等该进程再进程新的IO传输时,强制令该进程被判定为 high prio io。否则,只能被判断为交互式 io。bfqq->bfqq_list 是NULL说明该进程是新创建的。否则可能该bfqq过期失效而处于st->idle tree,现在又派发rq,此时该if不成立。*/
- if((bfqq->wr_coeff == 1) && list_empty(&bfqq->bfqq_list) && (strncmp(bfqd->last_high_prio_io_process,current->comm,COMM_LEN-1)) == 0){
- bfqq->wr_coeff = 30*BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR;
- }
- wr_or_deserves_wr = bfqd->low_latency &&
- (bfqq->wr_coeff > 1 ||
- (bfq_bfqq_sync(bfqq) &&
- bfqq->bic && (*interactive || soft_rt)));
- //禁止high prio io进程被判定为rt、interactive 、burst 型io,这样下边的bfq_update_bfqq_wr_on_rq_arrival()函数不会修改它的 bfqq->wr_coeff
- if(bfqq->wr_coeff == 30*BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR){
- *interactive = 0;
- wr_or_deserves_wr = 0;
- in_burst = 0;
- soft_rt = 0;
- //保存最近high prio io进程的名字
- strncpy(bfqd->last_high_prio_io_process,current->comm,COMM_LEN-1);
- }
- ................
- bfq_update_bfqq_wr_on_rq_arrival(bfqd, bfqq,
- old_wr_coeff,
- wr_or_deserves_wr,
- *interactive,
- in_burst,
- soft_rt);
- ................
- }
在进程绑定的bfqq初始化函数 bfq_init_bfqq()中,对bfqq->bfqq_list初始化,表示bfqq是新创建的。
static void bfq_init_bfqq(struct bfq_data *bfqd, struct bfq_queue *bfqq,
struct bfq_io_cq *bic, pid_t pid, int is_sync)
{
//bfqq创建时对bfqq->bfqq_list初始化
INIT_LIST_HEAD (&bfqq->bfqq_list);
}
在bfq_add_request()、bfq_bfqq_handle_idle_busy_switch()中添加的代码的代码,主要是两个作用。
1:保存最近被判定被高优先级IO的进程名字(比如cat)到bfqd->last_high_prio_io_process。后续如果再有同样进程名字的进程派发IO,则立即令进程被判定为高优先级IO。这段代码是bfq_bfqq_handle_idle_busy_switch()函数if((bfqq->wr_coeff == 1) && list_empty(&bfqq->bfqq_list) && (strncmp(bfqd->last_high_prio_io_process,current->comm,COMM_LEN-1)) == 0) bfqq->wr_coeff = 30*BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR这段代码。
注意,正常情况,一个进程最早开始派发IO时,只是被判定为交互式IO,bfqq->wr_coeff只有30。然后该进程被bfq调度器选中派发IO,接着因为配额消耗完而过期失效,执行__bfq_requeue_entity()重新加入st->active tree,等待被bfq调度器重新调度。此时在__bfq_requeue_entity()函数中,因为bfqq->wr_coeff是30,才会判定这个进程被高优先级IO。总之,这优化点是保证进程一开始派发IO就能被判定为高优先级IO,一开始就保证降低IO调度延迟。
2:保存最近被判定为in_large_burst型IO的进程名字到bfqd->large_burst_process_name。这样后续再有同样进程名字的新进程派发IO 或者 原本在st->idle tree但来了新的IO而激活加入st->active tree,这两种情况进程都会被判定为交互式IO,bfqq->wr_coeff 赋值30。然后等bfq调度器选中该进程派发IO后,该进程因为配额消耗光而过期失效,此时是要执行__bfq_requeue_entity()重新加入st->active tree。而在__bfq_requeue_entity()函数中,因为bfqq->wr_coeff是30,则该进程也会被判定高优先级IO。这样fio压测的进程有可能被判定为高优先级IO,进而影响cat 进程派发IO。
解决方案正是bfqd->large_burst_process_name!因为fio压测进程会被判定为in_large_burst型IO,bfqd->large_burst_process_name记录该进程名字fio,等后续再有fio压测,或者fio进程从原本在st->idle tree但来了新的IO而激活加入st->active tree,执行到bfq_bfqq_handle_idle_busy_switch()函数的if((bfqd->large_burst_process_count > 1) &&(bfqd->large_burst_process_tgid == current->tgid) && (strncmp(bfqd->large_burst_process_name,current->comm,COMM_LEN-1) == 0)),强制赋值bfqq->wr_coeff为1,就是强制作为普通IO,没有高优先级属性。这个性能优化点就是避免fio这种IO流量的但时延不敏感的进程影响IO时延敏感进程派发IO。
接着,还有一个性能优化点:在fio压测时,cat 进程读取文件而加入st->active tree,即便cat进程被判定为高优先级IO,但是也有可能因fio频繁派发IO导致cat进程延迟被bfq调度器选中派发IO。于是加入了高优先级IO进程bfqq在加入st->active tree后超时强制派发机制。代码实现如下:
- static void __bfq_activate_entity(struct bfq_entity *entity,
- bool non_blocking_wait_rq)
- {
- struct bfq_service_tree *st = bfq_entity_service_tree(entity);
- bool backshifted = false;
- unsigned long long min_vstart;
- struct bfq_queue *bfqq = bfq_entity_to_bfqq(entity);
- //high prio io的bfqq,记录激活加入st->active tree的时间点。在 high_prio_io_schedule_deadline 时间点到期后,该bfqq必须被调度到派发rq。bfqq->deadline_list->prev 和 next 必须是LIST_POISON2/LIST_POISON1 ,说明没有添加到链表上
- if((bfqq->deadline_list.prev == LIST_POISON2) && (bfqq->deadline_list.next == LIST_POISON1) && (bfqq->wr_coeff == 30 * BFQ_HIGH_PRIO_IO_WEIGHT_FACTOR)){
- bfqq->high_prio_io_active_time = jiffies;
- list_add_tail(&bfqq->deadline_list, &bfqq->bfqd->deadline_head);
- }
- /* See comments on bfq_fqq_update_budg_for_activation */
- if (non_blocking_wait_rq && bfq_gt(st->vtime, entity->finish)) {
- backshifted = true;
- min_vstart = entity->finish;
- } else
- min_vstart = st->vtime;
- ...............
- }
如红色代码,在cat这种被判定为高优先级IO进程bfqq插入st->active tree时,还把bfqq加入bfqd->deadline_head链表。
在bfq调度器选择下一个派发IO的bfqq而执行的bfq_lookup_next_entity()函数中,如果bfqd->deadline_head链表上有超时派发IO的bfqq,则强制选择这个bfqq作为下次派发IO的bfqq,此时不再执行__bfq_lookup_next_entity()从st->active tree选择。代码如下:
- static struct bfq_entity *bfq_lookup_next_entity(struct bfq_sched_data *sd,
- bool expiration)
- {
- struct bfq_service_tree *st = sd->service_tree;
- struct bfq_service_tree *idle_class_st = st + (BFQ_IOPRIO_CLASSES - 1);
- struct bfq_entity *entity = NULL;
- int class_idx = 0;
- struct bfq_queue *bfqq = bfq_entity_to_bfqq(sd->next_in_service);
- struct bfq_data *bfqd = bfqq->bfqd;
- //high prio io的bfqq在加入st->active tree后。high_prio_io_schedule_deadline时间到了,必须立即得到调度派发rq。不用遍历链表,只有看链表头第一个成员是否超时,第一个没超时,后边的更不会超时。
- if(!list_empty(&bfqd->deadline_head)){
- bfqq = list_first_entry(&bfqd->deadline_head, struct bfq_queue,deadline_list);
- if(time_is_before_jiffies(bfqq->high_prio_io_active_time + bfqd->high_prio_io_schedule_deadline)){
- entity = &bfqq->entity;
- list_del(&bfqq->deadline_list);
- return entity;
- }
- }
- ................
- entity = __bfq_lookup_next_entity(st + class_idx,sd->in_service_entity &&!expiration);
- return entity;
- }
bfq算法是很复杂的,本文的优化算法也需要持续打磨。本文如有错误请指出!
相关文章:

一次降低进程IO延迟的性能优化实践——基于block层bfq调度器
如果有个进程正频繁的读写文件,此时你vim查看一个新文件,将会出现明显卡顿。即便你vim查看的文件只有几十M,也可能会出现卡顿。相对的,线上经常遇到IO敏感进程偶发IO超时问题。这些进程一次读写的文件数据量很少,正常几…...

C语言易错知识点十(指针(the final))
❀❀❀ 文章由不准备秃的大伟原创 ❀❀❀ ♪♪♪ 若有转载,请联系博主哦~ ♪♪♪ ❤❤❤ 致力学好编程的宝藏博主,代码兴国!❤❤❤ 许久不见,甚是想念,真的是时间时间,你慢些吧,不能再让头发变秃…...

React 18 新增的钩子函数
React 18 引入了一些新的钩子函数,用于处理一些常见的场景和问题。以下是 React 18 中引入的一些新钩子函数以及它们的代码示例和使用场景: useTransition: 代码示例:import { useTransition } from react;function MyComponent()…...
安装与部署Hadoop
一、前置安装准备1、机器2、java3、创建hadoop用户 二、安装Hadoop三、环境配置1、workers2、hadoop-env.sh3、core-site.xml4、hdfs-site.xml5、linux中Hadoop环境变量 四、启动hadoop五、验证 一、前置安装准备 1、机器 主机名ip服务node1192.168.233.100NameNode、DataNod…...
MySQL 8.0 InnoDB Tablespaces之General Tablespaces(通用表空间/一般表空间)
文章目录 MySQL 8.0 InnoDB Tablespaces之General Tablespaces(通用表空间/一般表空间)General tablespaces(通用表空间/一般表空间)通用表空间的功能通用表空间的限制 创建通用表空间(一般表空间)创建语法…...

循环生成对抗网络(CycleGAN)
一、说明 循环生成对抗网络(CycleGAN)是一种训练深度卷积神经网络以执行图像到图像翻译任务的方法。网络使用不成对的数据集学习输入和输出图像之间的映射。 二、基本介绍 CycleGAN 是图像到图像的翻译模型,就像Pix2Pix一样。Pix2Pix模型面临…...

数组--53.最大子数组和/medium
53.最大子数组和 1、题目2、题目分析3、解题步骤4、复杂度最优解代码示例5、抽象与扩展 1、题目 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 子数组 是数组中的一个连…...

centos 编译安装 python 和 openssl
安装环境: centos 7.9 : python 3.10.5 和 openssl 3.0.12 centos 6.10 : python 3.10.5 和 openssl 1.1.1 两个环境都能安装成功,可以正常使用。 安装 openssl 下载地址 下载后解压,进入到解压目录 执行…...
【nodejs】前后端身份认证
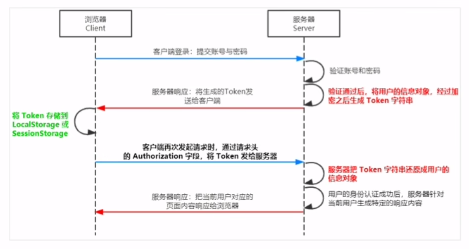
前后端身份认证 一、web开发模式 服务器渲染,前后端分离。 不同开发模式下的身份认证: 服务端渲染推荐使用Session认证机制前后端分离推荐使用JWT认证机制 二、session认证机制 1.HTTP协议的无状态性 了解HTTP协议的无状态性是进一步学习Session认…...

数据结构【线性表篇】(三)
数据结构【线性表篇】(三) 文章目录 数据结构【线性表篇】(三)前言为什么突然想学算法了?为什么选择码蹄集作为刷题软件? 目录一、双链表二、循环链表三、静态链表 结语 前言 为什么突然想学算法了? > 用较为“官方…...
Python装饰器的专业解释
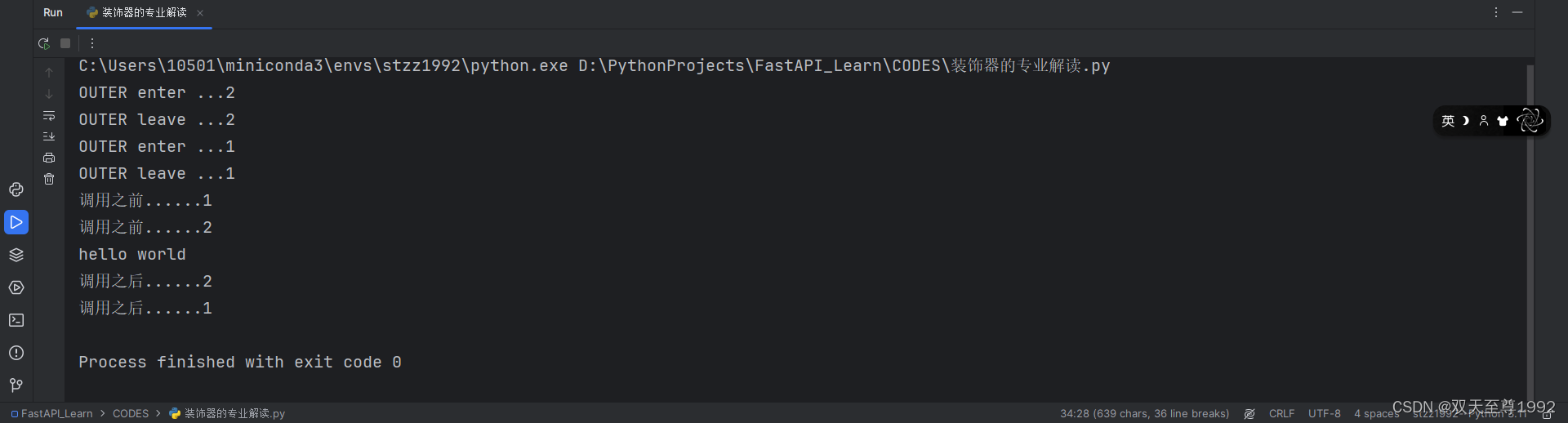
装饰器,其实是用到了闭包的原理来进行操作的。 单个装饰器: 以下是一个简单的例子: def outer(func):print("OUTER enter ...")def wrapper(*args, **kwargs):print("调用之前......")result func(*args, **kwargs)p…...
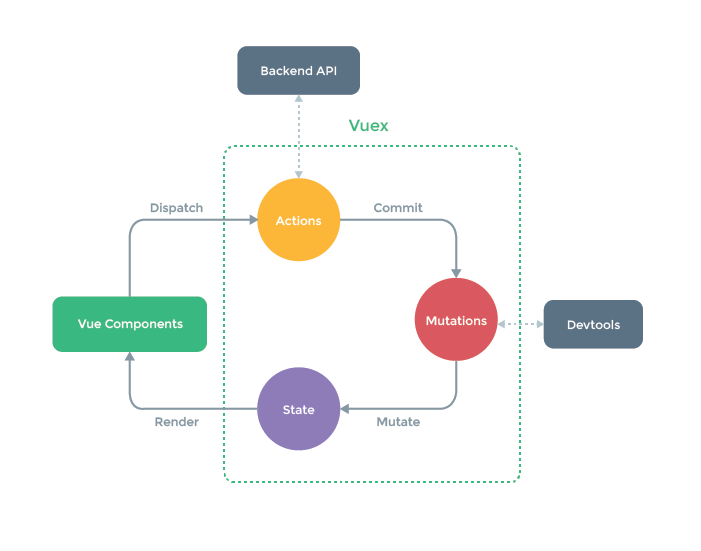
vue3框架笔记
Vue Vue 是一个渐进式的前端开发框架,很容易上手。Vue 目前的版本是 3.x,但是公司中也有很多使用的是 Vue2。Vue3 的 API 可以向下兼容 2,Vue3 中新增了很多新的写法。我们课程主要以 Vue3 为主 官网 我们学习 Vue 需要转变思想࿰…...
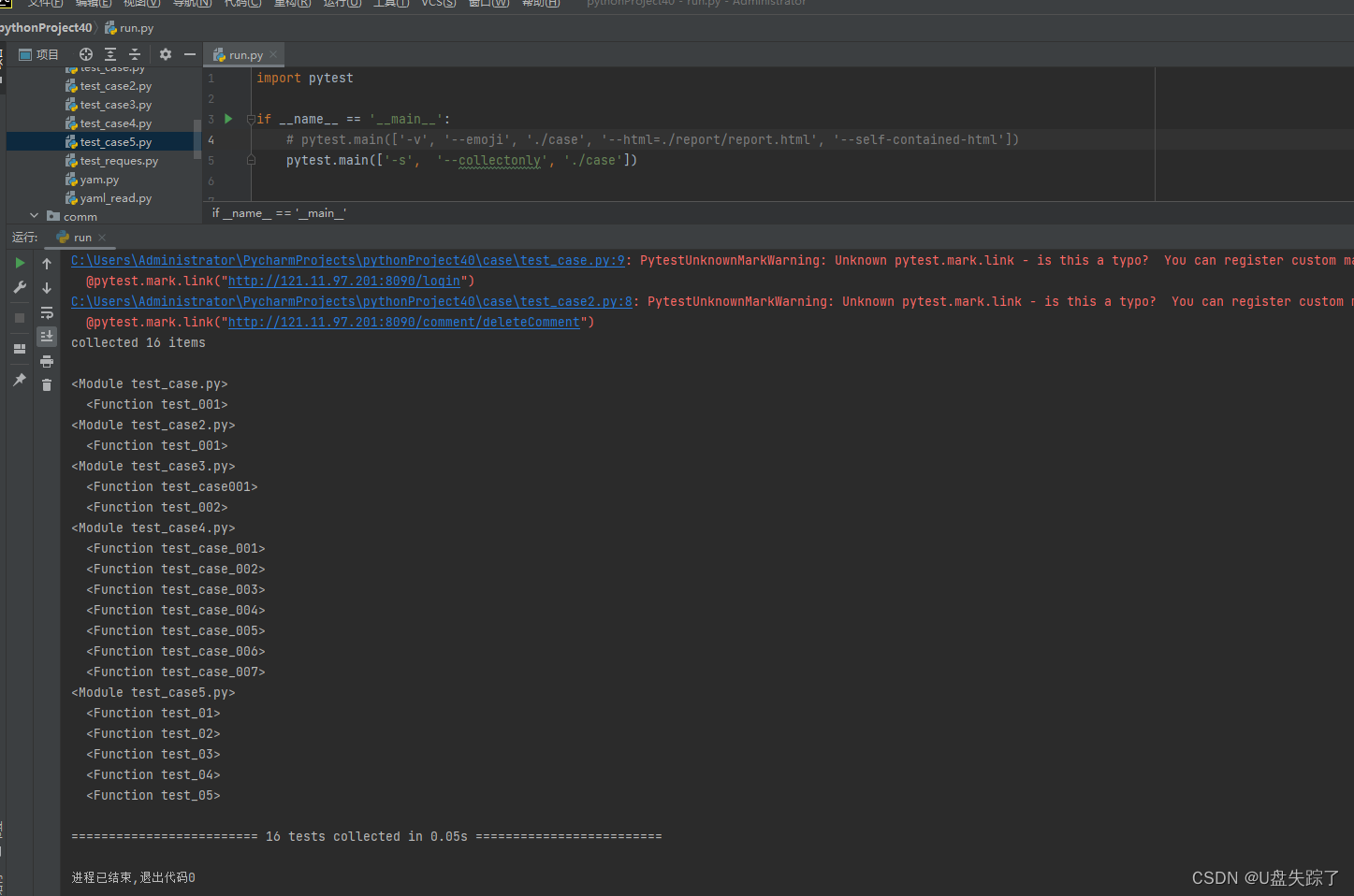
pytest --collectonly 收集测试案例
pytest --collectonly 是一条命令行指令,用于在运行 pytest 测试时仅收集测试项而不执行它们。它会显示出所有可用的测试项列表,包括测试模块、测试类和测试函数,但不会执行任何实际的测试代码。 这个命令对于查看项目中的测试结构和确保所有…...
dev express 15.2图表绘制性能问题(dotnet绘图表)
dev express 15.2 绘制曲线 前端代码 <dxc:ChartControl Grid.Row"1"><dxc:XYDiagram2D EnableAxisXNavigation"True"><dxc:LineSeries2D x:Name"series" CrosshairLabelPattern"{}{A} : {V:F2}"/></dxc:XYDi…...

WorkPlus:领先的IM即时通讯软件,打造高效沟通协作新时代
在当今快节奏的商业环境中,高效沟通和协作是企业成功的关键。而IM即时通讯软件作为实现高效沟通的利器,成为了现代企业不可或缺的一部分。作为一款领先的IM即时通讯软件,WorkPlus以其卓越的性能和独特的功能,助力企业打造高效沟通…...
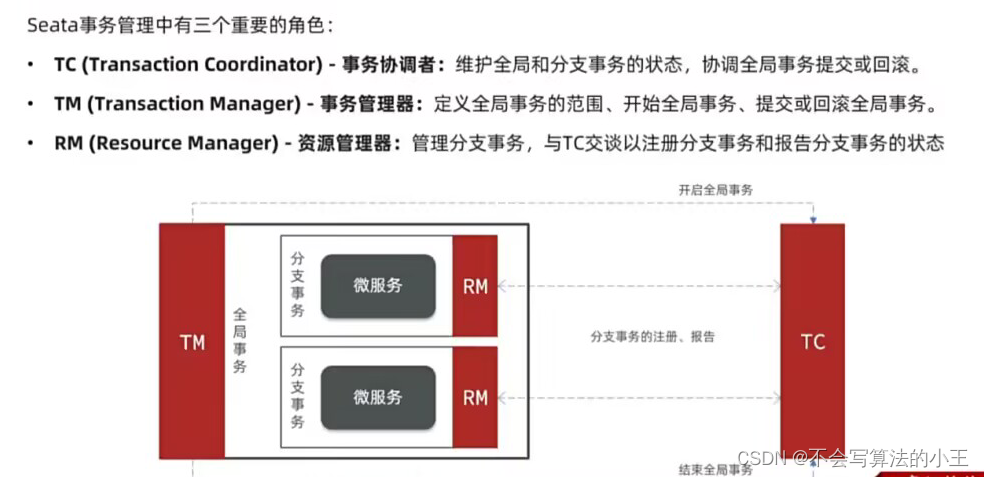
学习SpringCloud微服务
SpringCloud 微服务单体框架微服务框架SpringCloud微服务拆分微服务差分原则拆分商品服务拆分购物车服务拆分用户服务拆分交易服务拆分支付服务服务调用RestTemplate远程调用 微服务拆分总结 服务治理注册中心Nacos注册中心服务注册服务发现 OpenFeign实现远程调用快速入门引入…...
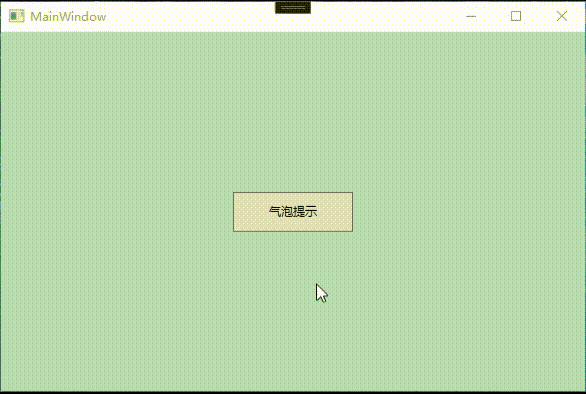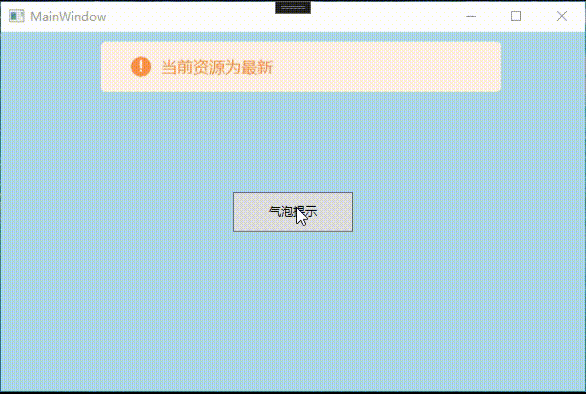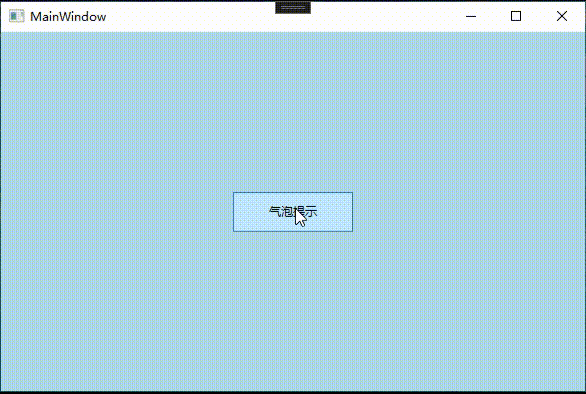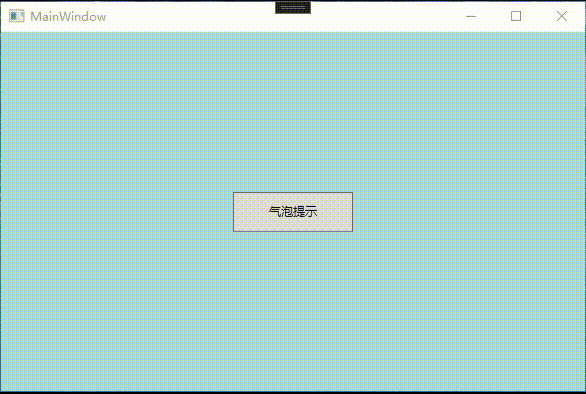
WPF 显示气泡提示框
气泡提示框应用举例 有时候在我们开发的软件经常会遇到需要提示用户的地方,为了让用户更直观,快速了解提示信息,使用简洁、好看又方便的气泡提示框显得更加方便,更具人性化。如下面例子:(当用户未输入账号时࿰…...
L1-062:幸运彩票
题目描述 彩票的号码有 6 位数字,若一张彩票的前 3 位上的数之和等于后 3 位上的数之和,则称这张彩票是幸运的。本题就请你判断给定的彩票是不是幸运的。 输入格式: 输入在第一行中给出一个正整数 N(≤ 100)。随后 N 行…...

python+vue高校体育器材管理信息系统5us4g
优秀的高校体育馆场地预订系统能够更有效管理体育馆场地预订业务规范,帮助管理者更加有效管理场地的使用,有效提高场地使用效率,可以帮助提高克服人工管理带来的错误等不利因素,所以一个优秀的高校体育馆场地预订系统能够带来很大…...
10 款顶级的免费U盘数据恢复软件(2024 年 更新)
你曾经遇到过U盘无法访问的情况吗?现在我们教你如何恢复数据。 在信息时代,数据丢失往往会造成巨大的困扰。而USB闪存驱动器作为我们常用的数据存储设备,其重要性不言而喻。但是,U盘也可能会出现各种问题,如无法访问、…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...