pandas处理双周数据
处理文件题头格式
部门名称 年度名称 季节名称 商品名称 商品代码 品牌名称 品类名称 颜色名称 商店名称 0M 1L 1XL 27 28 29 2XL 30 31 32 33 3XL 4XL 5XL 6XL S 均
1.导入包
导入源
pip install openpyxl -i https://pypi.doubanio.com/simple
pip install pandas -i https://pypi.doubanio.com/simple
from openpyxl import load_workbook
from openpyxl import Workbook
from openpyxl import styles
from openpyxl.styles import *
import pandas as pd
import string
import re
import os
2读入数据
filePath1 = './src/本周销售明细.xlsx'filePath2 = './src/上周销售明细.xlsx'# 加载工作簿wb = load_workbook(filePath1)# 获取sheet页,修改第一个sheet页面为name1 = wb.sheetnames[0]ws1 = wb[name1]ws1.title = "销售明细"wb.save(filePath1)# 销售明细df0 = pd.read_excel(filePath1, sheet_name='销售明细')
合并两列数据
pd.merge(df1, #要合并的左表df2, #要合并的右表how = 'outer',#合并的方式:inner-内连接,outer--全外连接,left--左外连接,right--右外连接,外连接的时候,没有数据的地方会填充为NaN,默认为inner。on=None,
#默认为None,合并的根据,要写出两个DataFrame共有的列,注意一定要是列名相同的,否则会报错,为list类型(多个列)或str(一列)
#如:['name']或者'name',默认None的时候,merge会自动寻找相同列名的列。left_on=None,right_on=None,
#当两表连接的根据列名字不一样的时候,用left on和right on列出两表连接的根据列,数值类型和on一样,默认None,比如df1和df3合并就需要用到left_on = 'name',right_on = '名字'。left_index = False,right_index = False,
#当进行连接的两表没有共同的根据列的时候,可以使用行索引进行合并,将left_index和right_index都设置为True即可,默认为Falsesort = True) #根据连接用的列进行排序,默认为False
数据预处理
file_path1 = './src/本周销售明细.xlsx'file_path2 = './src/上周销售明细.xlsx'#修改工作簿表名为销售明细sheet_name_deal(file_path1)sheet_name_deal(file_path2)file_path3 = './src/本周销售明细精修.xlsx'file_path4 = './src/上周销售明细精修.xlsx'creat_excel(file_path3)creat_excel(file_path4)#计算合计index_list = ['部门名称', '年度名称', '季节名称', '商品代码', '商品名称', '品牌名称', '品类名称', '颜色名称', '商店名称']value_list = ['0M', '1L', '1XL', '27', '28', '29', '2XL', '30', '3XL', '4XL', '5XL', '6XL', 'S', '均', '合计']#读入数据df1 = pd.read_excel(file_path1, sheet_name='销售明细')df2 = pd.read_excel(file_path2, sheet_name='销售明细')# 求和,需将文本的列指定为索引df1 = df1.set_index(index_list)# df1.loc["按列求和"] = df1.apply(lambda x: x.sum())df1['合计'] = df1.apply(lambda x: x.sum(), axis=1)# 求和,需将文本的列指定为索引df2 = df2.set_index(index_list)# df1.loc["按列求和"] = df1.apply(lambda x: x.sum())df2['合计'] = df2.apply(lambda x: x.sum(), axis=1)# 重置索引,防止导出excel列索引时单元格合并df1 = df1.reset_index()df2 = df2.reset_index()# 将生成的工作表导入到程序中result_sheet = pd.ExcelWriter(file_path3, engine='openpyxl') # 先定义要存入的文件名xxx,然后分别存入xxx下不同的sheet# df1将0转变为空df1 = df1.replace(0, '')df1.to_excel(result_sheet, "销售明细", index=False, na_rep=0, inf_rep=0)# 这步不能省,否则不生成文件result_sheet._save()# 将生成的工作表导入到程序中result_sheet = pd.ExcelWriter(file_path4, engine='openpyxl') # 先定义要存入的文件名xxx,然后分别存入xxx下不同的sheet# df1将0转变为空df2.to_excel(result_sheet, "销售明细", index=False, na_rep=0, inf_rep=0)# 这步不能省,否则不生成文件result_sheet._save()
完整代码
from openpyxl import load_workbook
from openpyxl import Workbook
from openpyxl import styles
from openpyxl.styles import *
import pandas as pd
import string
import re
import os
# Press the green button in the gutter to run the script.def sheet_name_deal(file_path):wb = load_workbook(file_path)# 获取sheet页,修改第一个sheet页面名为销售明细name1 = wb.sheetnames[0]ws1 = wb[name1]ws1.title = "销售明细"wb.save(file_path)def creat_excel(file_path):# 没有就创建if os.path.exists(file_path):print("文件已存在")print(file_path)else:# 创建一个新的 Excel 文件wb = Workbook()wb.save(file_path)def pretreatment():file_path1 = './src/本周销售明细.xlsx'file_path2 = './src/上周销售明细.xlsx'# 修改工作簿表名为销售明细sheet_name_deal(file_path1)sheet_name_deal(file_path2)file_path3 = './src/本周销售明细精修.xlsx'file_path4 = './src/上周销售明细精修.xlsx'creat_excel(file_path3)creat_excel(file_path4)# 计算合计index_list = ['部门名称', '年度名称', '季节名称', '商品代码', '商品名称', '品牌名称', '品类名称', '颜色名称', '商店名称']value_list = ['0M', '1L', '1XL', '27', '28', '29', '2XL', '30', '3XL', '4XL', '5XL', '6XL', 'S', '均', '合计']# 读入数据df1 = pd.read_excel(file_path1, sheet_name='销售明细')df2 = pd.read_excel(file_path2, sheet_name='销售明细')# 求和,需将文本的列指定为索引df1 = df1.set_index(index_list)# df1.loc["按列求和"] = df1.apply(lambda x: x.sum())df1['合计'] = df1.apply(lambda x: x.sum(), axis=1)# 求和,需将文本的列指定为索引df2 = df2.set_index(index_list)# df1.loc["按列求和"] = df1.apply(lambda x: x.sum())df2['合计'] = df2.apply(lambda x: x.sum(), axis=1)# 重置索引,防止导出excel列索引时单元格合并df1 = df1.reset_index()df2 = df2.reset_index()# 将生成的工作表导入到程序中result_sheet = pd.ExcelWriter(file_path3, engine='openpyxl') # 先定义要存入的文件名xxx,然后分别存入xxx下不同的sheet# df1将0转变为空df1 = df1.replace(0, '')df1.to_excel(result_sheet, "销售明细", index=False, na_rep=0, inf_rep=0)# 这步不能省,否则不生成文件result_sheet._save()# 将生成的工作表导入到程序中result_sheet = pd.ExcelWriter(file_path4, engine='openpyxl') # 先定义要存入的文件名xxx,然后分别存入xxx下不同的sheet# df1将0转变为空df2.to_excel(result_sheet, "销售明细", index=False, na_rep=0, inf_rep=0)# 这步不能省,否则不生成文件result_sheet._save()if __name__ == '__main__':# pretreatment()file_path3 = './src/本周销售明细精修.xlsx'file_path4 = './src/上周销售明细精修.xlsx'# 销售明细df3 = pd.read_excel(file_path3, sheet_name='销售明细')df4 = pd.read_excel(file_path4, sheet_name='销售明细')# 部门周销df01 = df3.pivot_table(index="部门名称", values="合计", aggfunc='sum').copy()df01 = df01.reset_index()df01.sort_values(by="合计", axis=0, ascending=False, inplace=True)# 客户周销环比index_list = ['部门名称', '商店名称']# 本周客户周销df021 = df3.pivot_table(index=index_list, values="合计", aggfunc='sum').copy()# 上周客户周销df022 = df4.pivot_table(index=index_list, values="合计", aggfunc='sum').copy()# 全连接# 重命名列df021["本周销量"] = df021.pop('合计')df022['上周销量'] = df022.pop('合计')df023 = pd.merge(df021, df022, how='outer', left_index=True, right_index=True)df023['销比'] = (df023['本周销量']-df023['上周销量'])/df023['上周销量']df023 = df023.reset_index()df023.sort_values(by="销比", axis=0, ascending=False, inplace=True)#品类周销环比#本周销量df031 = df3.pivot_table(index="品类名称", values="合计", aggfunc='sum').copy()#上周销量df032 = df4.pivot_table(index="品类名称", values="合计", aggfunc='sum').copy()# 全连接# 重命名列df031["本周销量"] = df031.pop('合计')df032['上周销量'] = df032.pop('合计')df033 = pd.merge(df031, df032, how='outer', left_index=True, right_index=True)df033['销比'] = (df033['本周销量'] - df033['上周销量']) / df033['上周销量']df033 = df033.reset_index()df033.sort_values(by="销比", axis=0, ascending=False, inplace=True)#季节周销df04 = df3.pivot_table(index="季节名称", values="合计", aggfunc='sum').copy()df04 = df04.reset_index()df04.sort_values(by="合计", axis=0, ascending=False, inplace=True)#品类周销df05 = df3.pivot_table(index="品类名称", values="合计", aggfunc='sum').copy()df05 = df05.reset_index()df05.sort_values(by="合计", axis=0, ascending=False, inplace=True)# 各部门品类销量前五index_list = ['部门名称', '商店名称']df060 = df3.pivot_table(index=index_list, values="合计", aggfunc='sum').copy()df060 = df060.reset_index()df061 = df060[df060['部门名称'] == '商品1部'].nlargest(5, '合计')df062 = df060[df060['部门名称'] == '商品3部'].nlargest(5, '合计')df063 = df060[df060['部门名称'] == '商品6部'].nlargest(5, '合计')df064 = df060[df060['部门名称'] == '直营4部'].nlargest(5, '合计')df065 = pd.concat([df061, df062, df063, df064])#删除第一列数字索引#df065 = df065.drop(df065.columns[0], axis=1)df065 = df065.pivot_table(index=index_list, values="合计", aggfunc='sum').copy()print(df065)#将行索引转化为列索引#df065.stack(level=1)# 将生成的工作表导入到程序中file_path5 = './src/双周数据图表.xlsx'creat_excel(file_path5)result_sheet = pd.ExcelWriter(file_path5, engine='openpyxl') # 先定义要存入的文件名xxx,然后分别存入xxx下不同的sheet# df1将0转变为空#部门周销df01 = df01.replace(0, '')df01.to_excel(result_sheet, "部门周销", index=False, na_rep=0, inf_rep=0)# 客户周销环比#将NaN替换为空白df023 = df023.fillna('')df023.to_excel(result_sheet, "客户周销环比", index=False, na_rep=0, inf_rep=0)#品类周销环比# 将NaN替换为空白df033 = df033.fillna('')df033.to_excel(result_sheet, "品类周销环比", index=False, na_rep=0, inf_rep=0)# 季节周销df04 = df04.replace(0, '')df04.to_excel(result_sheet, "季节周销", index=False, na_rep=0, inf_rep=0)# 品类周销df05 = df05.replace(0, '')df05.to_excel(result_sheet, "品类周销", index=False, na_rep=0, inf_rep=0)# 品类部门周销排名df065 = df05.replace(0, '')df065.to_excel(result_sheet, "品类部门周销排名", index=True, na_rep=0, inf_rep=0)# 这步不能省,否则不生成文件result_sheet._save()
# See PyCharm help at https://www.jetbrains.com/help/pycharm/相关文章:

pandas处理双周数据
处理文件题头格式 部门名称 年度名称 季节名称 商品名称 商品代码 品牌名称 品类名称 颜色名称 商店名称 0M 1L 1XL 27 28 29 2XL 30 31 32 33 3XL 4XL 5XL 6XL S 均1.导入包 导入源 pip install openpyxl -i https://pypi.doubanio.com/simple pip install pandas -i https…...
2023结婚成家,2024借势起飞
您好,我是码农飞哥(wei158556),感谢您阅读本文,欢迎一键三连哦。 💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精…...
linux SHELL语句
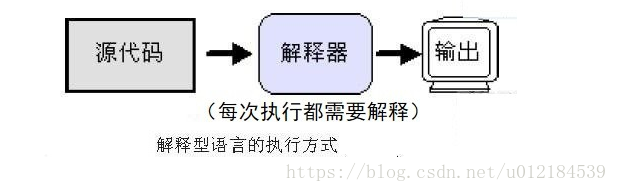
shell编程 shell编程 一、初识shell 程序 语言 编程语言 自然语言 汉语 英语 计算机语言 c语言cjava php python go shell 编译型语言 c c java解释型语言 php python bash (不能闭源,开发难度低) 编译型语言:运行编译型语言是相对于解释型语言存在的ÿ…...
音频修复和增强软件:iZotope RX 10 (Win/Mac)中文汉化版
iZotope RX 是一款专业的音频修复和增强软件,一直是电影和电视节目中使用的行业标准音频修复工具,iZotope能够帮助用户对音频进行制作、后期合成处理、混音以及对损坏的音频进行修复,再解锁更多功能之后还能够对电影、游戏、电视之中的音频进…...
算法篇)
复试 || 就业day03(2023.12.29)算法篇
文章目录 前言同构字符串存在重复元素有效的字母异位词丢失的数字单词规律 前言 💫你好,我是辰chen,本文旨在准备考研复试或就业 💫文章题目大多来自于 leetcode,当然也可能来自洛谷或其他刷题平台 💫欢迎大…...
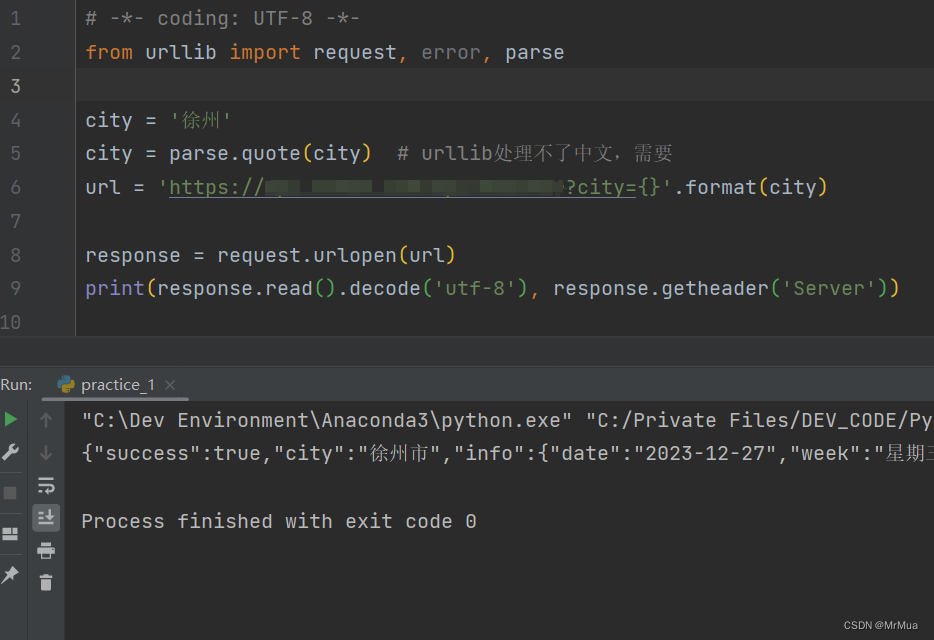
处理urllib.request.urlopen报错UnicodeEncodeError:‘ascii‘
参考:[Python3填坑之旅]一urllib模块网页爬虫访问中文网址出错 目录 一、报错内容 二、报错截图 三、解决方法 四、实例代码 五、运行截图 六、其他UnicodeEncodeError: ascii codec 问题 一、报错内容 UnicodeEncodeError: ascii codec cant encode charac…...
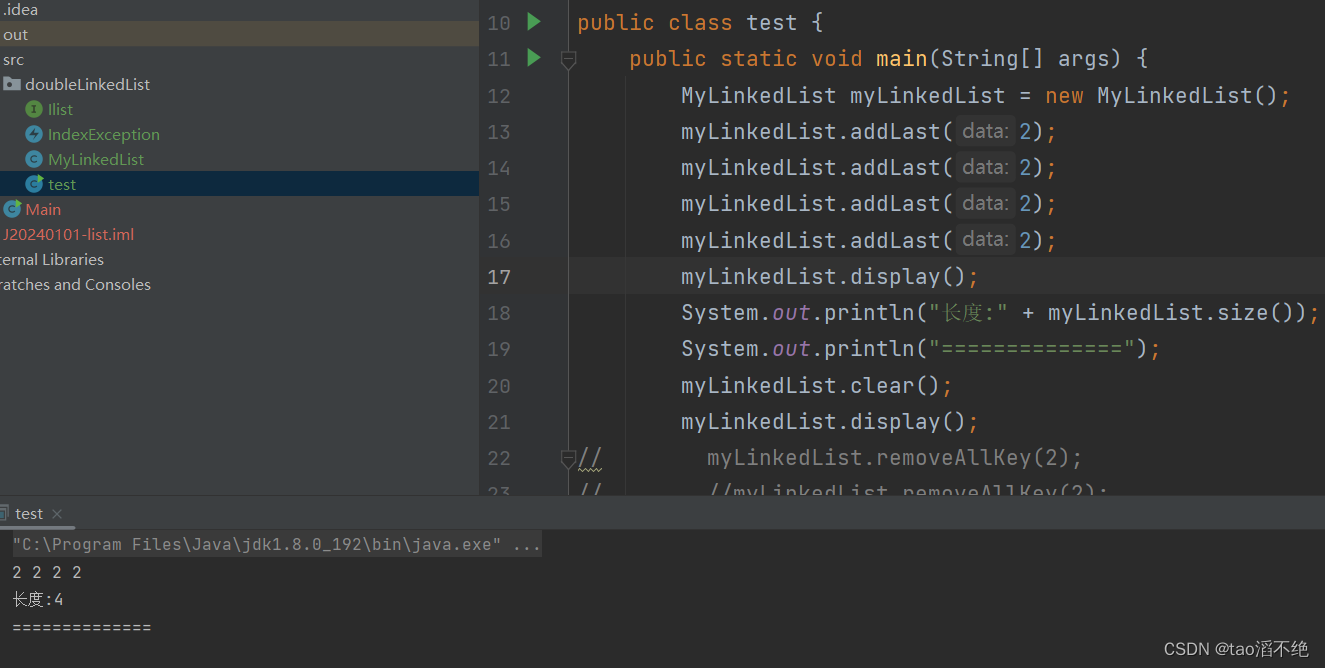
数据结构模拟实现LinkedList双向不循环链表
目录 一、双向不循环链表的概念 二、链表的接口 三、链表的方法实现 (1)display方法 (2)size方法 (3)contains方法 (4)addFirst方法 (5)addLast方法 …...
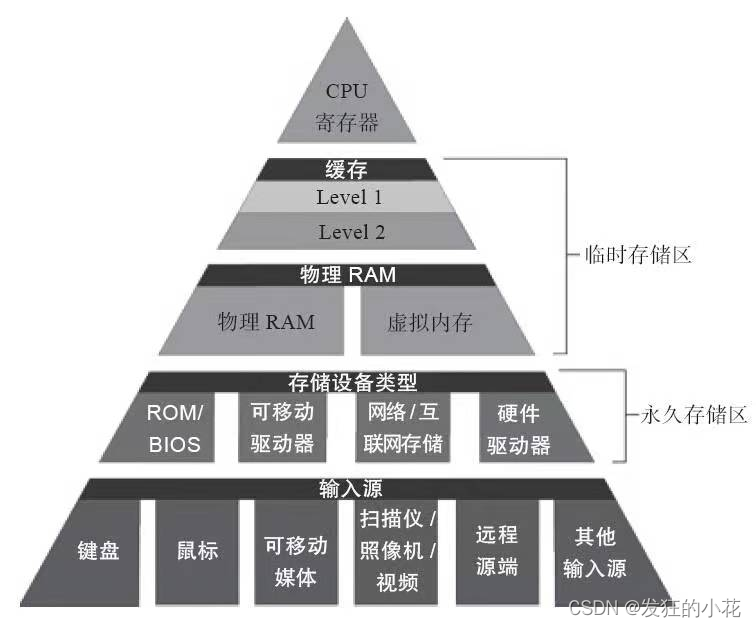
性能优化-如何提高cache命中率
本文主要介绍性能优化领域常见的cache的命中率问题,旨在全面的介绍提高cache命中率的方法,以供大家编写出性能友好的代码,并且可以应对性能优化领域的面试问题。 🎬个人简介:一个全栈工程师的升级之路! &am…...

分布式【4. 什么是 CAP?】
什么是 CAP? C 代表 Consistency,一致性,是指所有节点在同一时刻的数据是相同的,即更新操作执行结束并响应用户完成后,所有节点存储的数据会保持相同。 A 代表 Availability,可用性,是指系统提…...
 》)
<软考高项备考>《论文专题 - 39采购管理(3) 》
3 过程2-实施采购 3.1 问题 4W1H过程做什么获取卖方应答、选择卖方并授予合同的过程作用:选定合格卖方并签署关于货物或服务交付的法律协议。本过程的最后成果是签订的协议,包括正式合同。为什么做实际进行采购谁来做组织中的职能部门或项目经理什么时…...

Java在SpringCloud中自定义Gateway负载均衡策略
Java在SpringCloud中自定义Gateway负载均衡策略 一、前言 spring-cloud-starter-netflix-ribbon已经不再更新了,最新版本是2.2.10.RELEASE,最后更新时间是2021年11月18日,详细信息可以看maven官方仓库:org.springframework.clou…...
前端 js 基础(1)
js 结果输出 (点击按钮修改文字 ) <!DOCTYPE html> <html> <head></head><body><h2>Head 中的 JavaScript</h2><p id"demo">一个段落。</p><button type"button" onclic…...

Android : 使用GestureOverlayView进行手势识别—简单应用
示例图: GestureOverlayView介绍: GestureOverlayView 是 Android 开发中用于识别和显示手势的视图组件。它允许用户在屏幕上绘制手势,并且应用程序可以检测和响应这些手势。以下是关于 GestureOverlayView 的主要特点: 手势识别…...
C卷 (JavaPythonNode.jsC语言C++))
API集群负载统计 (100%用例)C卷 (JavaPythonNode.jsC语言C++)
某个产品的RESTful API集合部署在服务器集群的多个节点上, 近期对客户端访问日志进行了采集,需要统计各个API的访问频次, 根据热点信息在服务器节点之间做负载均衡,现在需要实现热点信息统计查询功能。 RESTful API的由多个层级构成,层级之间使用/连接,如/A/B/C/D这个地址…...

小梅哥Xilinx FPGA学习笔记18——专用时钟电路 PLL与时钟向导 IP
目录 一:IP核简介(具体可参考野火FPGA文档) 二: 章节导读 三:PLL电路原理 3.1 PLL基本实现框图 3.2 PLL倍频实现 3.3 PLL分频实现 四: 基于 PLL 的多时钟 LED 驱动设计 4.1 配置 Clocking Wizard 核 4.2 led …...

低代码平台在金融银行中的应用场景
随着数字化转型的推进,商业银行越来越重视技术在业务发展中的作用。在这个背景下,白码低代码平台作为一种新型的开发方式,正逐渐受到广大商业银行的关注和应用。白码低代码平台能够快速构建各类应用程序,提高开发效率,…...

Css基础内容
<!DOCTYPE html> <html> <head> <meta charset"UTF-8" /> <title>CSS</title> <!-- <link rel"stylesheet" href"Html5与Css3\CSS\my.css"> --> <!-- link引入外部样式表:rel&…...

微服务(11)
目录 51.pod的重启策略是什么? 52.描述一下pod的生命周期有哪些状态? 53.创建一个pod的流程是什么? 54.删除一个Pod会发生什么事情? 55.k8s的Service是什么? 51.pod的重启策略是什么? 可以通过命令kub…...
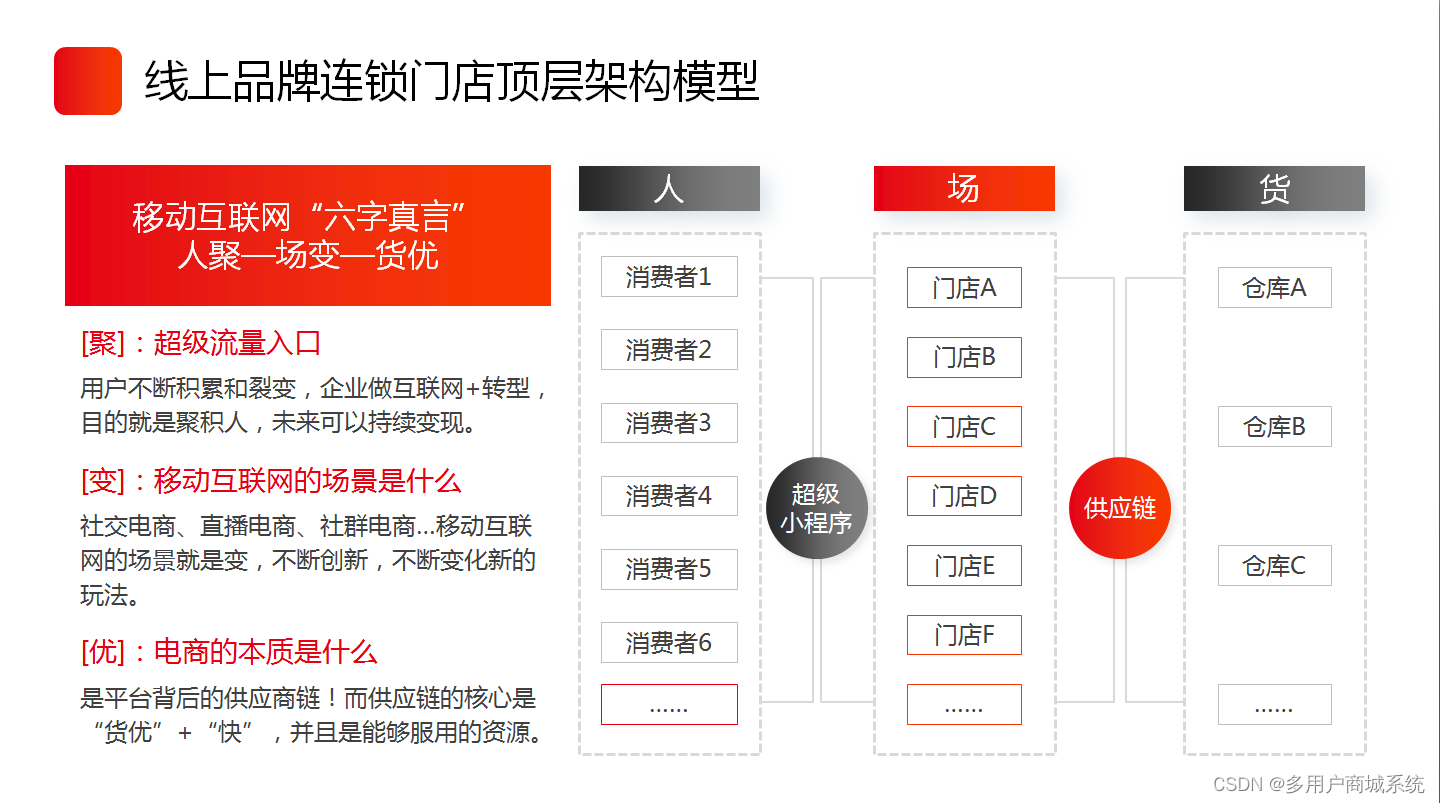
连锁门店管理需要信息化系统
连锁门店管理的信息化系统可以提供以下功能,以满足连锁企业日常管理的需求: 1. 连锁线下收银:信息化系统可以提供线下收银功能,包括商品扫码、价格结算、支付方式选择等。通过系统记录每笔交易数据,方便对销售情况进行…...

UTF-8编码:打破字符编码的国界
UTF-8编码:打破字符编码的国界 大家好,我是免费搭建查券返利机器人赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天,让我们一同探讨编程世界中一项至关重要的技术——“UTF-…...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...
详细解析)
Caliper 负载(Workload)详细解析
Caliper 负载(Workload)详细解析 负载(Workload)是 Caliper 性能测试的核心部分,它定义了测试期间要执行的具体合约调用行为和交易模式。下面我将全面深入地讲解负载的各个方面。 一、负载模块基本结构 一个典型的负载模块(如 workload.js)包含以下基本结构: use strict;/…...
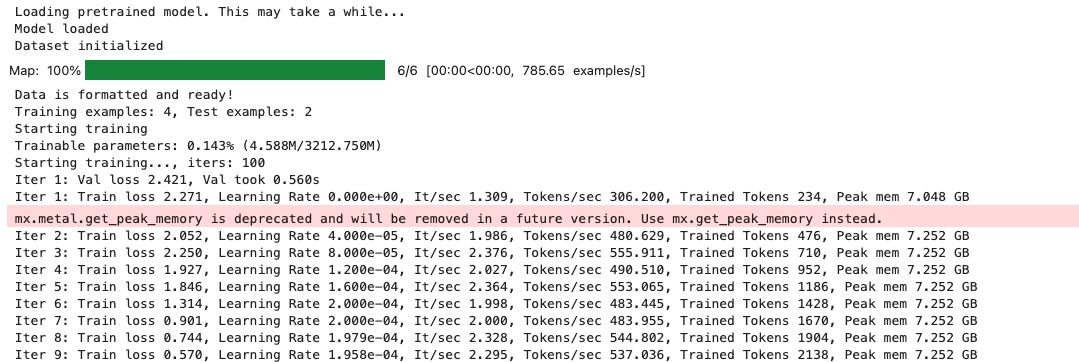
mac:大模型系列测试
0 MAC 前几天经过学生优惠以及国补17K入手了mac studio,然后这两天亲自测试其模型行运用能力如何,是否支持微调、推理速度等能力。下面进入正文。 1 mac 与 unsloth 按照下面的进行安装以及测试,是可以跑通文章里面的代码。训练速度也是很快的。 注意…...
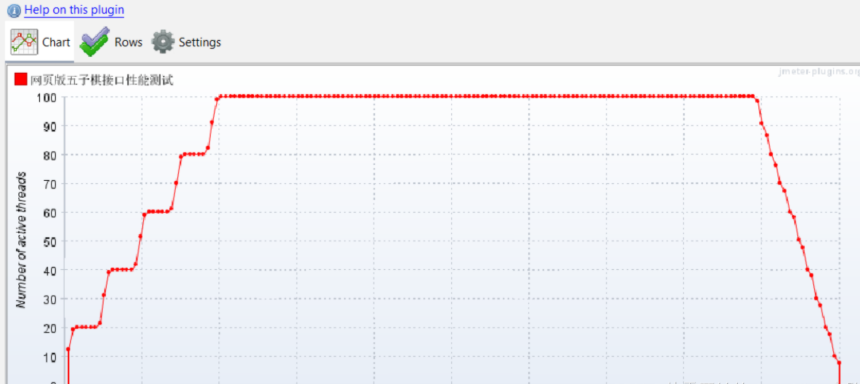
五子棋测试用例
一.项目背景 1.1 项目简介 传统棋类文化的推广 五子棋是一种古老的棋类游戏,有着深厚的文化底蕴。通过将五子棋制作成网页游戏,可以让更多的人了解和接触到这一传统棋类文化。无论是国内还是国外的玩家,都可以通过网页五子棋感受到东方棋类…...
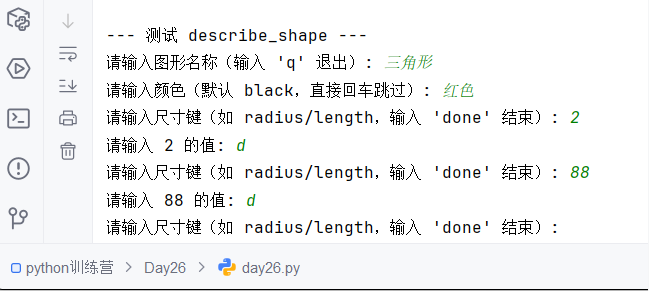
Python训练营-Day26-函数专题1:函数定义与参数
题目1:计算圆的面积 任务: 编写一个名为 calculate_circle_area 的函数,该函数接收圆的半径 radius 作为参数,并返回圆的面积。圆的面积 π * radius (可以使用 math.pi 作为 π 的值)要求:函数接收一个位置参数 radi…...

数据结构第5章:树和二叉树完全指南(自整理详细图文笔记)
名人说:莫道桑榆晚,为霞尚满天。——刘禹锡(刘梦得,诗豪) 原创笔记:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 上一篇:《数据结构第4章 数组和广义表》…...