爬虫基础一(持续更新)
爬虫概念:
通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程
分类:
1,通用爬虫:抓取一整张页面数据
2,聚焦爬虫:抓取页面中的局部内容
3,增量式爬虫:只会抓取网站中最新更新出来的数据
反爬协议robots.txt协议
http协议:
服务器与客户端进行数据交互的一种形式
User-Agent:请求载体的身份标识
Connection:请求完毕是断开还是保持连接
Content-Type: 服务器响应回客户端的数据类型
https协议:证书认证加密,安全的超文本传输协议
1,requests模块:
作用:模拟浏览器发请求
流程:1,指定url 2,发起请求 3,获取响应数据 4,持久化存储
1.1爬取搜狗首页:
import requests
if __name__ == '__main__':url='https://www.sogou.com/'response=requests.get(url=url)page_text=response.text#返回字符串形式的响应数据print(page_text)with open('./sougou.html','w',encoding='utf-8') as fp:fp.write(page_text)print('爬取数据结束!')
1.2网页采集器
User-Agent:请求载体的身份标识
UA伪装:让爬虫对应的请求载体身份标识伪装成某一款浏览器
import requests
if __name__ == '__main__':#UA伪装:将对应的UA封装到一个字典里headers={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2669.400 QQBrowser/9.6.10990.400'}url='https://www.sogou.com/sie?hdq=AQxRG-0000&'#处理URL参数分装到字典里kw=input('enter a word:')param={'query':kw}
#对指定URL发起的请求对应的url是携带参数的请求过程中处理了参数response=requests.get(url=url,params=param,headers=headers)page_text=response.text#返回字符串形式的响应数据fileName=kw+'.html'with open(fileName,'w',encoding='utf-8') as fp:fp.write(page_text)print(fileName,'保存成功!!')

1.3破解百度翻译
打开百度翻译官网,右键检查
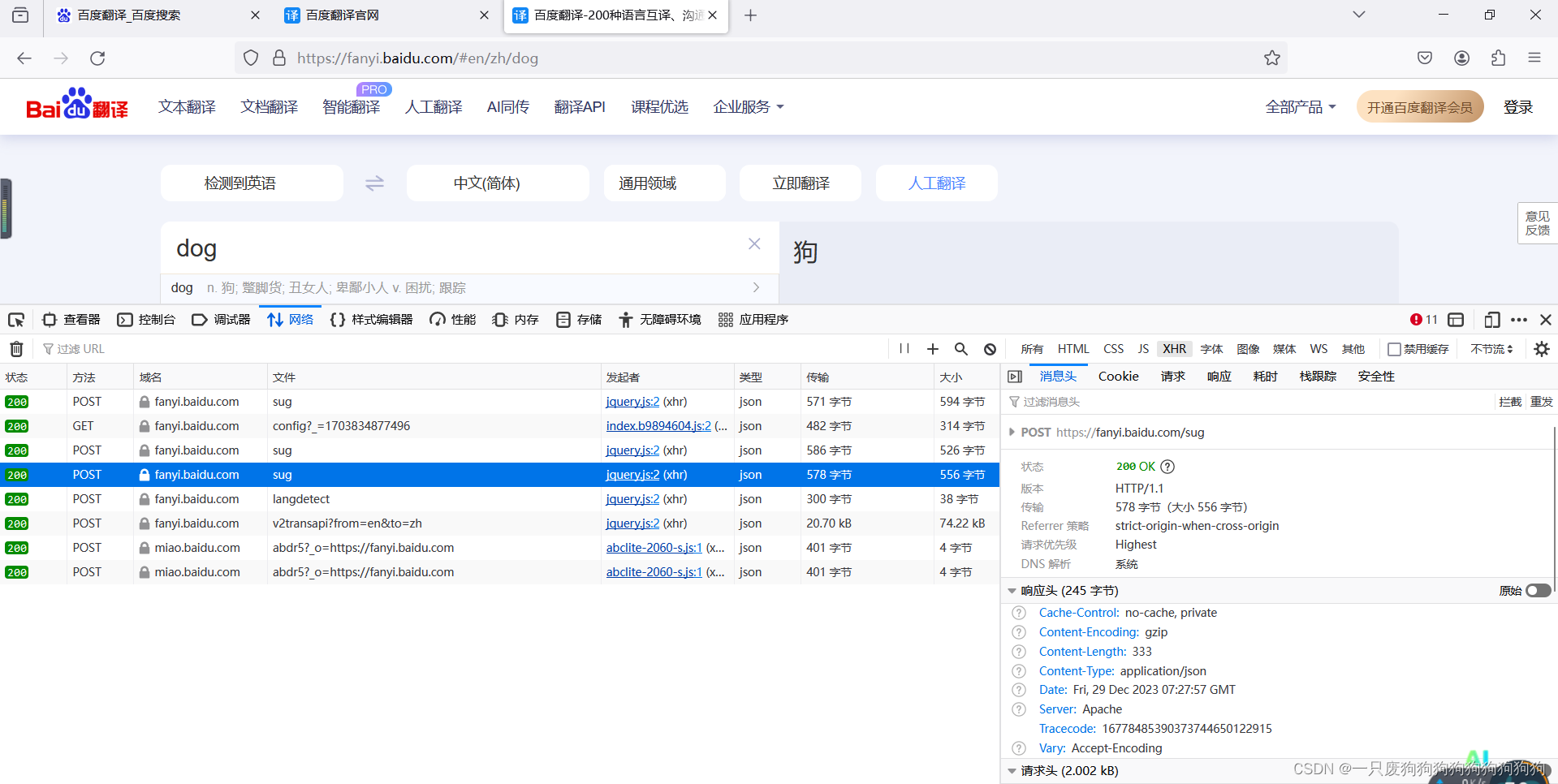
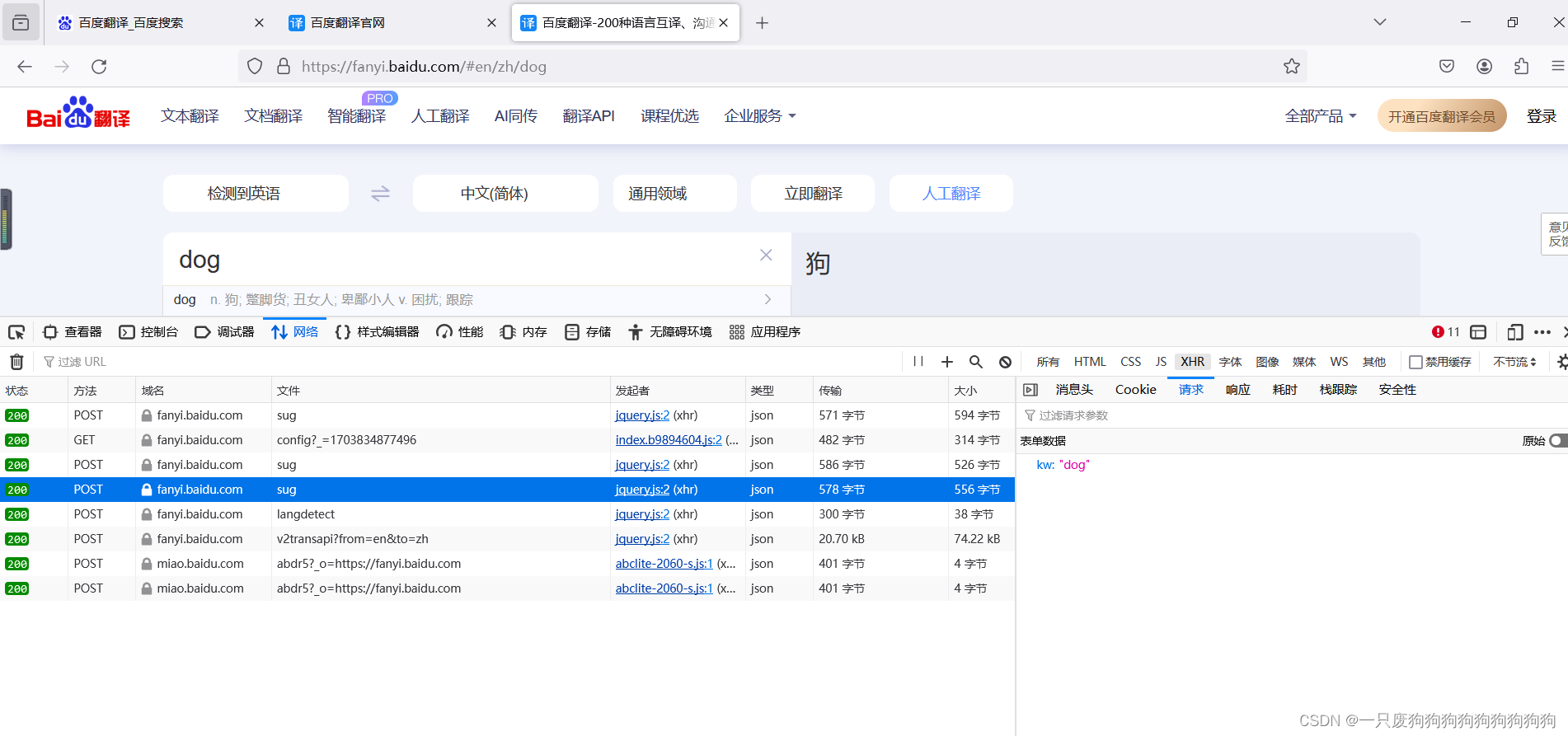
发出的是一个post请求(携带参数),响应数据是一组json数据
import requests
import json#导入模块
if __name__ == '__main__':post_url='https://fanyi.baidu.com/sug'#1,指定urlheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2669.400 QQBrowser/9.6.10990.400'}#经行UA伪装#3,post请求参数处理(与get类似)word=input('enter a word:')data={'kw':word}#4,发送请求response=requests.post(url=post_url,data=data,headers=headers)#5,获取响应数据:json()方法返回的是obj(提前确定是json类型)dic_obj=response.json()#持久化存储fileName=word+'.json'fp=open(fileName,'w',encoding='utf-8')json.dump(dic_obj,fp=fp,ensure_ascii=False)#中文不可以用ASCII码print('over!!')效果:

1.4,豆瓣电影爬取

文件类型为json,地址中有参数,获取方式为get
import requests
import json#导入模块
if __name__ == '__main__':url='https://movie.douban.com/j/chart/top_list'param={'type':'24','interval_id':'100:90','action':'','start':'3',#第一个电影'limit':'20'#数量}headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2669.400 QQBrowser/9.6.10990.400'}response=requests.get(url=url,params=param,headers=headers)#请求list_data=response.json()#json类型fp=open('./douban.json','w',encoding='utf-8')#生成文件json.dump(list_data,fp=fp,ensure_ascii=False)print('over!!!')1.5爬取肯德基餐厅
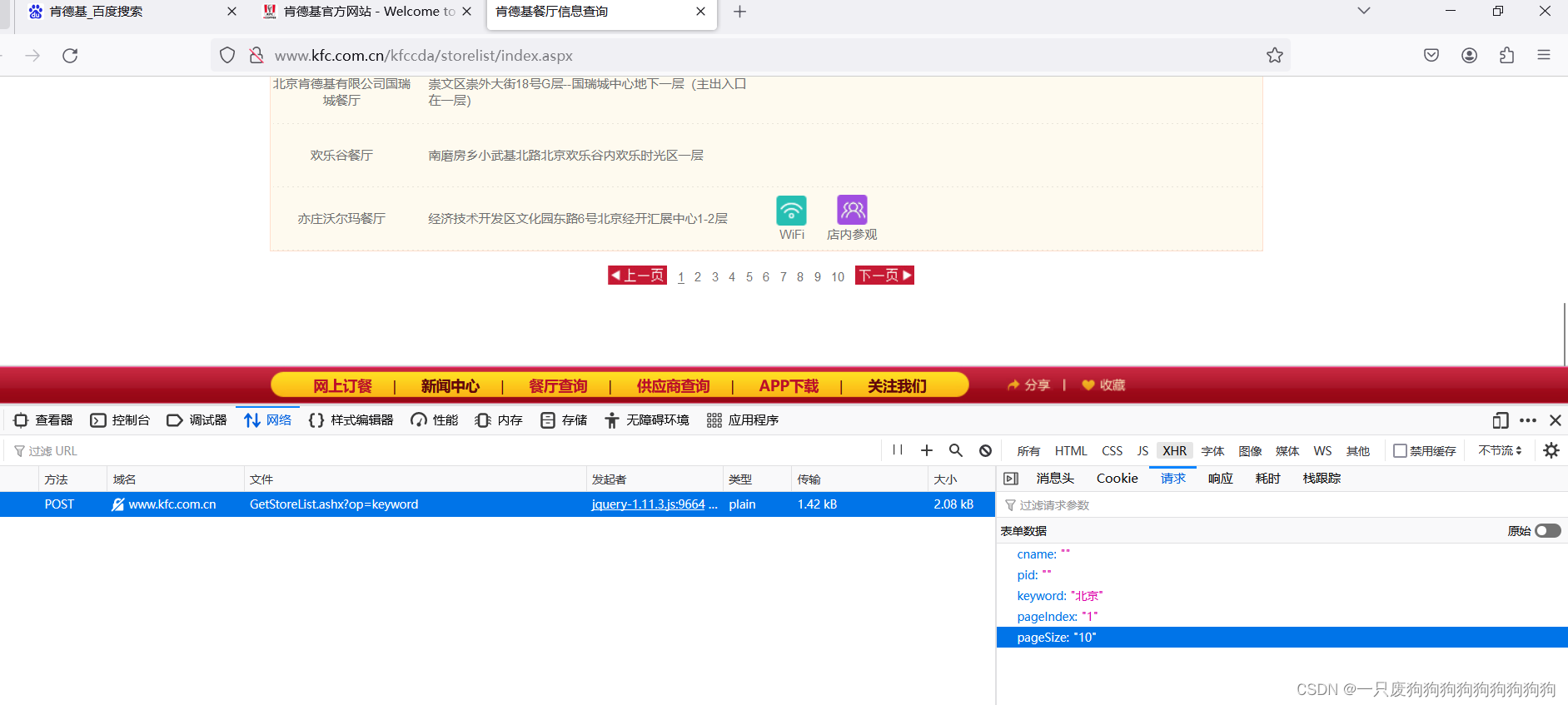
要求:统计各个城市共有多少家肯德基餐厅,并打印门店信息
请求方式为post,文本类型(content-Type):text

参数:
import requestsurl = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
# UA伪装
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'
}
word = input("请输入地址: ")
numbers = 1
# 页数
number_pages = 0
# 第一次检测页数
state = True
while numbers != 0:number_pages += 1data = {'cname': '','pid': '','keyword': word,'pageIndex': number_pages,'pageSize': '10',}# 请求发送response = requests.post(url=url, data=data, headers=header)text = response.textnumbers -= 1# 计算页数,因为只需要一次即可if state:# 将列表text转化为字典dictionary = eval(text)# 获取第一段Table的页数rowcount = dictionary['Table']# 将这个列表中的字典赋给dictsdicts = rowcount[0]# 查询rowcount所指的页数numbers = dicts['rowcount']if numbers == 0:print("抱歉,您所输入的地址没有肯德基餐厅")else:print(f"{word}一共有{numbers}家肯德基餐厅")if numbers % 10 == 0:numbers = numbers // 10#整除else:numbers = numbers // 10 # 不加一是因为已经检查过一次了state = Falseprint(text)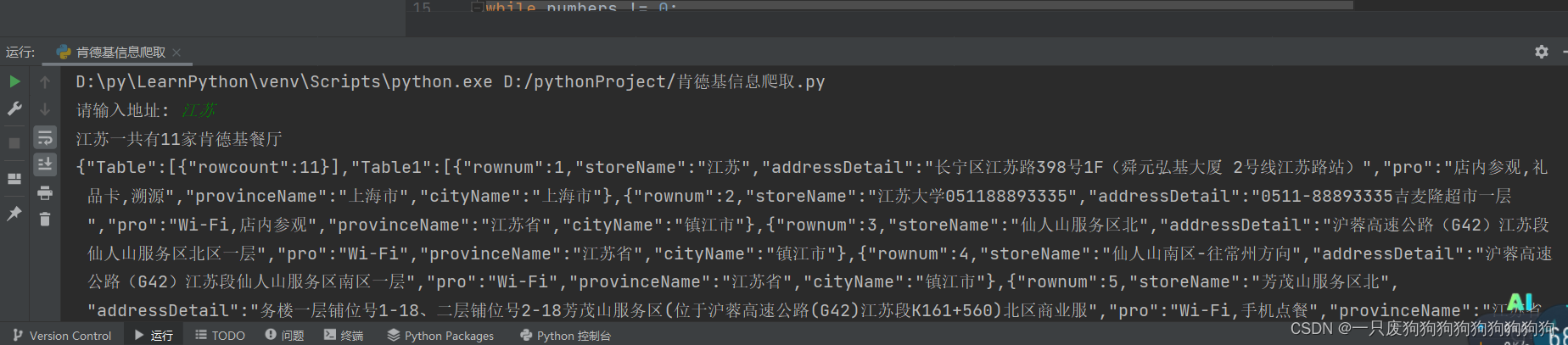
相关文章:
爬虫基础一(持续更新)
爬虫概念: 通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程 分类: 1,通用爬虫:抓取一整张页面数据 2,聚焦爬虫:抓取页面中的局部内容 3,增量式爬虫&…...
右键菜单“以notepad++打开”,在windows文件管理器中
notepad 添加到文件管理器的右键菜单中 找到安装包,重新安装一般即可。 这里有最新版:地址 密码:f0f1 方法 在安装的时候勾选 “Context Menu Entry” 即可 Notepad的右击打开文件功能 默认已勾选 其作用是添加右键快捷键。即,对于任何…...

JSON.parseObject强制将自动转化的Intage型设置为Long型
通过Redis或Caffeine存储入json型String,通过JSON.parseObject自动类型转化之后,数值会优先转为Intage,如果存入的字符值大于Intage最大值,会自动转为Long型; 需求是:实要取出时数值类型值为Long࿱…...

Redis的集群模式:主从 哨兵 分片集群
基于Redis集群解决单机Redis存在的问题,在之前学Redis一直都是单节点部署 单机或单节点Redis存在的四大问题: 数据丢失问题:Redis是内存存储,服务重启可能会丢失数据 > 利用Redis数据持久化的功能将数据写入磁盘并发能力问题…...
Note: An Interesting Festival
An Interesting Festival 一个有趣的节日。 festival The Agricultural Feast takes place after the independence Day. 农业盛会在独立日后举行 takes place independence feast agricultural It is not a worldwide celebration. 它不是一个全球的庆典。 worldwide ce…...
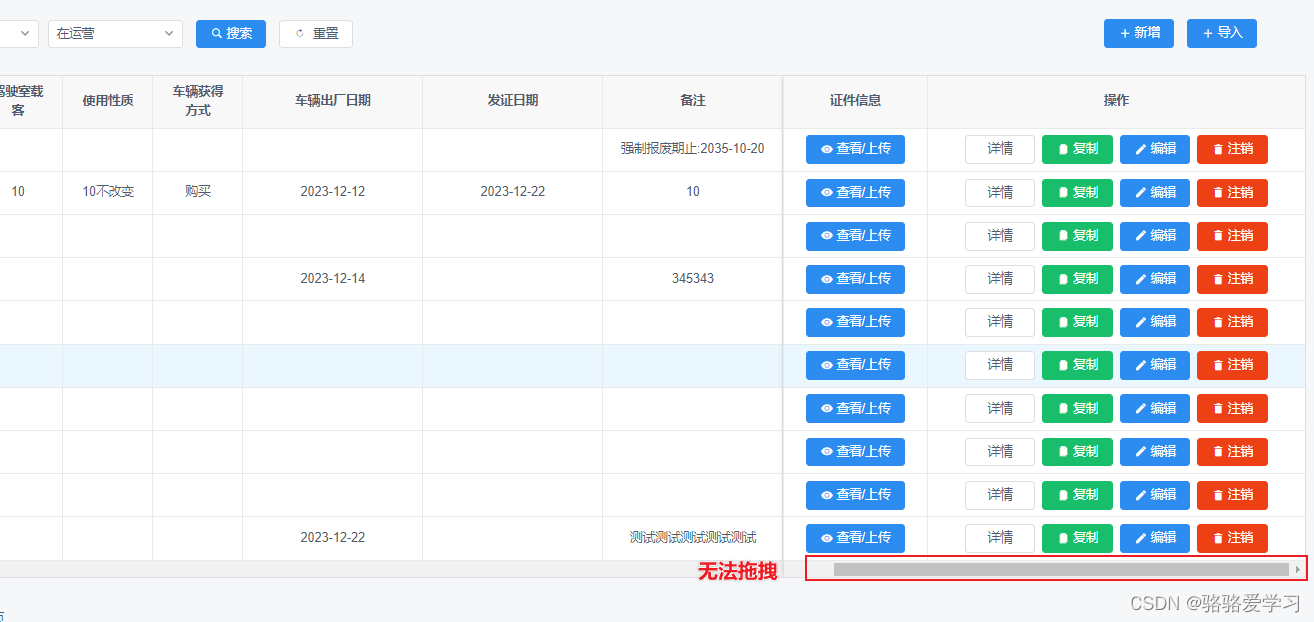
iview表格固定列横向滚动条无法拖动问题
文章目录 问题解决办法 问题 在使用iview的表格组件时,遇到了设置固定列表格后滚动条无法拖动的问题,当对表格列进行固定后,底部的横向滚动条就无法拖动了,主要的问题就是固定区域盖住了横向滚动条。 解决办法 在组件内直接加下…...

Python序列之集合
系列文章目录 Python序列之列表Python序列之元组Python序列之字典Python序列之集合(本篇文章) Python序列之集合 系列文章目录前言一、集合是什么?二、集合的操作1.集合的创建(1)使用{}创建(2)…...

智慧园区物联综合管理平台之架构简述
总体架构 系统总体划分为物联感知系统层、 核心平台层、 综合运营服务平台和展示层四部分。 物联感知系统层 物联感知系统主要是支撑园区智能化运行的各子系统, 包括门禁系统、 视频监控系统、 车辆管理系统等。 核心平台层 核心平台层包括: 园区物联综合管理平台和园区…...

国科大图像处理2023速通期末——汇总2017-2019
国科大2023.12.28图像处理0854期末重点 图像处理 王伟强 作业 课件 资料 一、填空 一个阴极射线管它的输入与输出满足 s r 2 sr^{2} sr2,这将使得显示系统产生比希望的效果更暗的图像,此时伽马校正通常在信号进入显示器前被进行预处理,令p…...
oracle 9i10g编程艺术-读书笔记2
配置Statspack 安装Statspack需要用internal身份登陆,或者拥有SYSDBA(connect / as sysdba)权限的用户登陆。需要在本地安装或者通过telnet登陆到服务器。 select instance_name,host_name,version,startup_time from v$instance;检查数据文件路径及磁盘空间&…...

PACC:数据中心网络的主动 CNP 生成方案
PACC:数据中心网络的主动 CNP 生成方案 文章目录 PACC:数据中心网络的主动 CNP 生成方案PACC算法CNP数据结构PACC参数仿真结果参考文献 PACC算法 CNP数据结构 PACC参数 仿真结果 PACC Hadoop Load0.2 的情况: PACC Hadoop Load0.4 的情况&a…...

我最喜欢的趣味几何书-读书笔记
我最喜欢的趣味几何书-读书笔记 1、利用阴影的长度来测量 公元前6世纪,古希腊哲学家泰勒思为了测量金字塔,想到了这样的方法:选择了一个特殊的时间,在那个时间,他自身的影子长度刚好跟他的身高相等。此时,…...
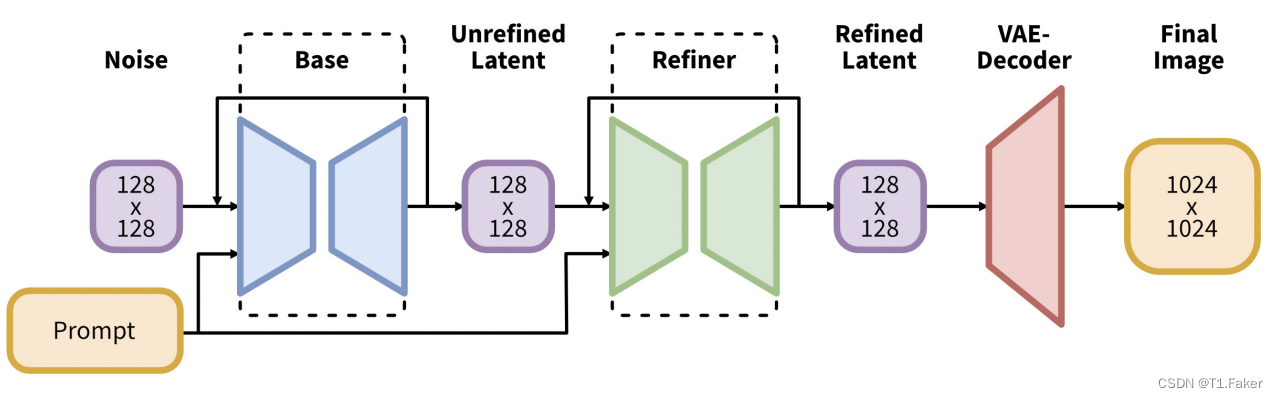
Stable Diffusion模型概述
Stable Diffusion 1. Stable Diffusion能做什么?2. 扩散模型2.1 正向扩散2.2 反向扩散 3. 训练如何进行3.1 反向扩散3.2 Stable Diffusion模型3.3 潜在扩散模型3.4 变分自动编码器3.5 图像分辨率3.6 图像放大 4. 为什么潜在空间是可能的?4.1 在潜在空间中…...

二叉树详解(深度优先遍历、前序,中序,后序、广度优先遍历、二叉树所有节点的个数、叶节点的个数)
目录 一、树概念及结构(了解) 1.1树的概念 1.2树的表示 二、二叉树概念及结构 2.1概念 2.2现实中的二叉树: 2.3数据结构中的二叉树: 2.4特殊的二叉树: 2.5 二叉树的存储结构 2.51 顺序存储: 2.5.2 链式存储&…...
C++日期类的实现
前言:在类和对象比较熟悉的情况下,我们我们就可以开始制作日期表了,实现日期类所包含的知识点有构造函数,析构函数,函数重载,拷贝构造函数,运算符重载,const成员函数 1.日期类的加减…...

B+树的插入删除
操作 插入 case2的原理,非叶子节点永远和最右边的最左边的节点的值相等。 case3:的基本原理 非叶子节点都是索引节点 底层的数据分裂之后 相当于向上方插入一个新的索引(你可以认为非叶子节点都是索引),反正第二层插入160 都要分裂,然后也需要再插入(因为索引部分不需要重…...

c# Avalonia 绘图
在Avalonia UI框架中,绘图主要通过使用DrawingContext类来实现。DrawingContext提供了一系列的绘图API,可以用来绘制线条、形状、图像以及文本等内容。以下是一个简单的示例,说明如何在Avalonia中进行基础的图形绘制 <!-- MainWindow.axa…...

springboot 双数据源配置
1:pom <!--SpringBoot启动依赖--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</group…...
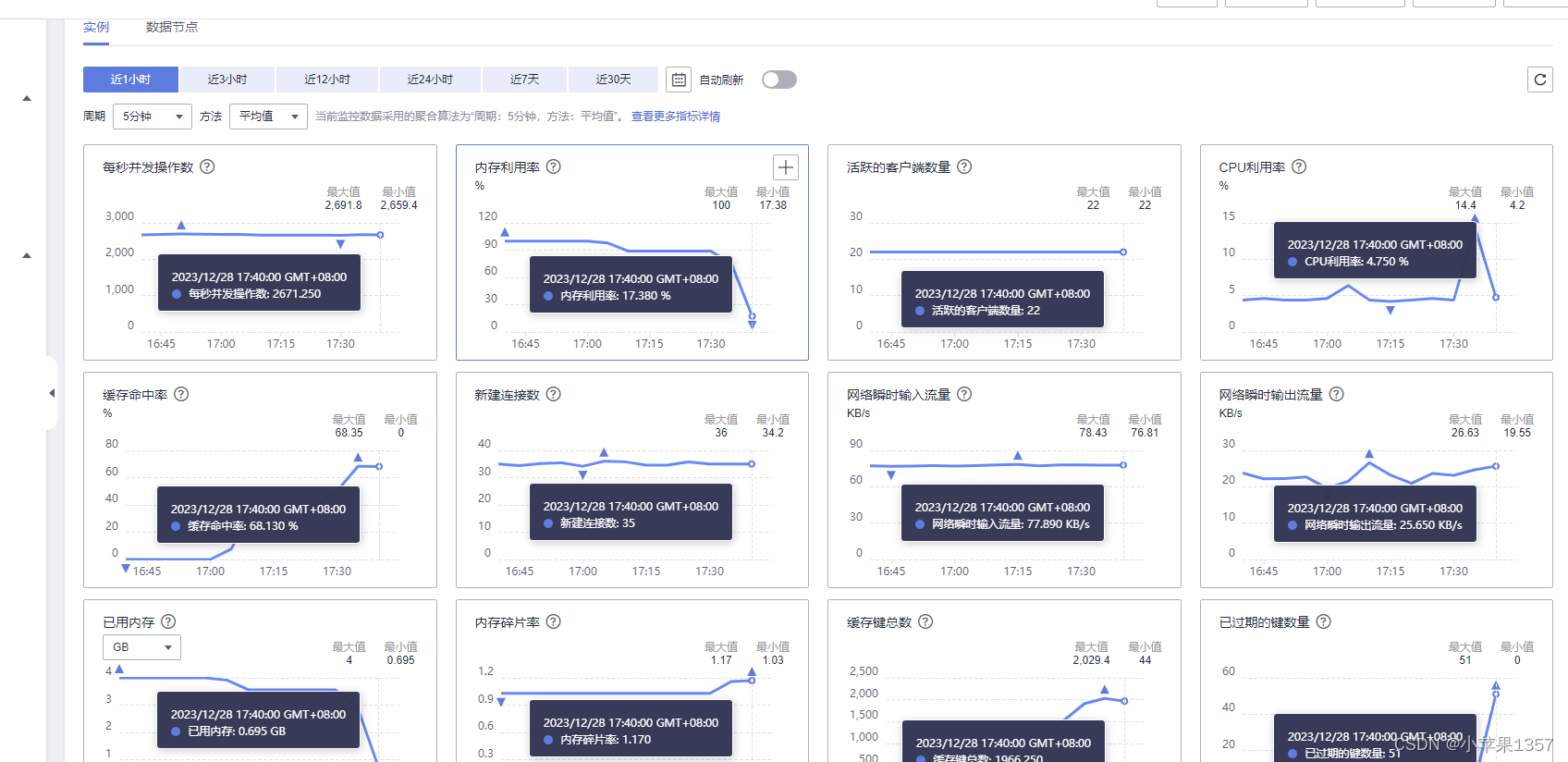
Redis内存使用率高,内存不足问题排查和解决
问题现象 表面现象是系统登录突然失效,排查原因发现,使用redis查询用户信息异常,从而定位到redis问题 if (PassWord.equals(dbPassWord)) {map.put("rtn", 1);map.put("value", validUser);session.setAttribute("…...
bootstrap5开发房地产代理公司Hamilton前端页面
一、需求分析 房地产代理网站是指专门为房地产行业提供服务的在线平台。这些网站的主要功能是连接房地产中介机构、房产开发商和潜在的买家或租户,以促成买卖或租赁房产的交易。以下是一些常见的房地产代理网站的功能: 房源发布:房地产代理网…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

【磁盘】每天掌握一个Linux命令 - iostat
目录 【磁盘】每天掌握一个Linux命令 - iostat工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景 注意事项 【磁盘】每天掌握一个Linux命令 - iostat 工具概述 iostat(I/O Statistics)是Linux系统下用于监视系统输入输出设备和CPU使…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

算法岗面试经验分享-大模型篇
文章目录 A 基础语言模型A.1 TransformerA.2 Bert B 大语言模型结构B.1 GPTB.2 LLamaB.3 ChatGLMB.4 Qwen C 大语言模型微调C.1 Fine-tuningC.2 Adapter-tuningC.3 Prefix-tuningC.4 P-tuningC.5 LoRA A 基础语言模型 A.1 Transformer (1)资源 论文&a…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

【 java 虚拟机知识 第一篇 】
目录 1.内存模型 1.1.JVM内存模型的介绍 1.2.堆和栈的区别 1.3.栈的存储细节 1.4.堆的部分 1.5.程序计数器的作用 1.6.方法区的内容 1.7.字符串池 1.8.引用类型 1.9.内存泄漏与内存溢出 1.10.会出现内存溢出的结构 1.内存模型 1.1.JVM内存模型的介绍 内存模型主要分…...