Pytorch简介
1.1 Pytorch的历史
PyTorch是一个由Facebook的人工智能研究团队开发的开源深度学习框架。在2016年发布后,PyTorch很快就因其易用性、灵活性和强大的功能而在科研社区中广受欢迎。下面我们将详细介绍PyTorch的发展历程。
在2016年,Facebook的AI研究团队(FAIR)公开了PyTorch,其旨在提供一个快速,灵活且动态的深度学习框架。PyTorch的设计哲学与Python的设计哲学非常相似:易读性和简洁性优于隐式的复杂性。PyTorch用Python语言编写,是Python的一种扩展,这使得其更易于学习和使用。
PyTorch在设计上取了一些大胆的决定,其中最重要的一项就是选择动态计算图(Dynamic Computation Graph)作为其核心。动态计算图与其他框架(例如TensorFlow和Theano)中的静态计算图有着本质的区别,它允许我们在运行时改变计算图。这使得PyTorch在处理复杂模型时更具灵活性,并且对于研究人员来说,更易于理解和调试。
在发布后的几年里,PyTorch迅速在科研社区中取得了广泛的认可。在2019年,PyTorch发布了1.0版本,引入了一些重要的新功能,包括支持ONNX、一个新的分布式包以及对C++的前端支持等。这些功能使得PyTorch在工业界的应用更加广泛,同时也保持了其在科研领域的强劲势头。
到了近两年,PyTorch已经成为全球最流行的深度学习框架之一。其在GitHub上的星标数量超过了50k,被用在了各种各样的项目中,从最新的研究论文到大规模的工业应用。
综上,PyTorch的发展历程是一部充满创新和挑战的历史,它从一个科研项目发展成为了全球最流行的深度学习框架之一。在未来,我们有理由相信,PyTorch将会在深度学习领域继续发挥重要的作用。
1.2 Pytorch的优点
PyTorch不仅是最受欢迎的深度学习框架之一,而且也是最强大的深度学习框架之一。它有许多独特的优点,使其在学术界和工业界都受到广泛的关注和使用。接下来我们就来详细地探讨一下PyTorch的优点。
1. 动态计算图
PyTorch最突出的优点之一就是它使用了动态计算图(Dynamic Computation Graphs,DCGs),与TensorFlow和其他框架使用的静态计算图不同。动态计算图允许你在运行时更改图的行为。这使得PyTorch非常灵活,在处理不确定性或复杂性时具有优势,因此非常适合研究和原型设计。
2. 易用性
PyTorch被设计成易于理解和使用。其API设计的直观性使得学习和使用PyTorch成为一件非常愉快的事情。此外,由于PyTorch与Python的深度集成,它在Python程序员中非常流行。
3. 易于调试
由于PyTorch的动态性和Python性质,调试PyTorch程序变得相当直接。你可以使用Python的标准调试工具,如PDB或PyCharm,直接查看每个操作的结果和中间变量的状态。
4. 强大的社区支持
PyTorch的社区非常活跃和支持。官方论坛、GitHub、Stack Overflow等平台上有大量的PyTorch用户和开发者,你可以从中找到大量的资源和帮助。
5. 广泛的预训练模型
PyTorch提供了大量的预训练模型,包括但不限于ResNet,VGG,Inception,SqueezeNet,EfficientNet等等。这些预训练模型可以帮助你快速开始新的项目。
6. 高效的GPU利用
PyTorch可以非常高效地利用NVIDIA的CUDA库来进行GPU计算。同时,它还支持分布式计算,让你可以在多个GPU或服务器上训练模型。
综上所述,PyTorch因其易用性、灵活性、丰富的功能以及强大的社区支持,在深度学习领域中备受欢迎。
1.3 Pytorch的使用场景
PyTorch的强大功能和灵活性使其在许多深度学习应用场景中都能够发挥重要作用。以下是PyTorch在各种应用中的一些典型用例:
1. 计算机视觉
在计算机视觉方面,PyTorch提供了许多预训练模型(如ResNet,VGG,Inception等)和工具(如TorchVision),可以用于图像分类、物体检测、语义分割和图像生成等任务。这些预训练模型和工具大大简化了开发计算机视觉应用的过程。
2. 自然语言处理
在自然语言处理(NLP)领域,PyTorch的动态计算图特性使得其非常适合处理变长输入,这对于许多NLP任务来说是非常重要的。同时,PyTorch也提供了一系列的NLP工具和预训练模型(如Transformer,BERT等),可以帮助我们处理文本分类、情感分析、命名实体识别、机器翻译和问答系统等任务。
3. 生成对抗网络
生成对抗网络(GANs)是一种强大的深度学习模型,被广泛应用于图像生成、图像到图像的转换、样式迁移和数据增强等任务。PyTorch的灵活性使得其非常适合开发和训练GAN模型。
4. 强化学习
强化学习是一种学习方法,其中智能体通过与环境的交互来学习如何执行任务。PyTorch的动态计算图和易于使用的API使得其在实现强化学习算法时表现出极高的效率。
5. 时序数据分析
在处理时序数据的任务中,如语音识别、时间序列预测等,PyTorch的动态计算图为处理可变长度的序列数据提供了便利。同时,PyTorch提供了包括RNN、LSTM、GRU在内的各种循环神经网络模型。
总的来说,PyTorch凭借其强大的功能和极高的灵活性,在许多深度学习的应用场景中都能够发挥重要作用。无论你是在研究新的深度学习模型,还是在开发实际的深度学习应用,PyTorch都能够提供强大的支持。
2. Pytorch基础
![]()
在我们开始深入使用PyTorch之前,让我们先了解一些基础概念和操作。这一部分将涵盖PyTorch的基础,包括tensor操作、GPU加速以及自动求导机制。
2.1 Tensor操作
Tensor是PyTorch中最基本的数据结构,你可以将其视为多维数组或者矩阵。PyTorch tensor和NumPy array非常相似,但是tensor还可以在GPU上运算,而NumPy array则只能在CPU上运算。下面,我们将介绍一些基本的tensor操作。
首先,我们需要导入PyTorch库:
| 1 |
|
然后,我们可以创建一个新的tensor。以下是一些创建tensor的方法:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
我们还可以对已有的tensor进行操作。以下是一些基本操作:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
上述操作的结果如下:
| 1 2 3 4 5 6 7 |
|
在PyTorch中,我们可以使用.backward()方法来计算梯度。例如:
| 1 2 3 4 5 |
|
以上是PyTorch tensor的基本操作,我们可以看到PyTorch tensor操作非常简单和直观。在后续的学习中,我们将会使用到更多的tensor操作,例如索引、切片、数学运算、线性代数、随机数等等。
2.2 GPU加速
在深度学习训练中,GPU(图形处理器)加速是非常重要的一部分。GPU的并行计算能力使得其比CPU在大规模矩阵运算上更具优势。PyTorch提供了简单易用的API,让我们可以很容易地在CPU和GPU之间切换计算。
首先,我们需要检查系统中是否存在可用的GPU。在PyTorch中,我们可以使用torch.cuda.is_available()来检查:
| 1 2 3 4 5 6 7 |
|
如果存在可用的GPU,我们可以使用.to()方法将tensor移动到GPU上:
| 1 2 3 4 5 6 |
|
我们也可以直接在创建tensor的时候就指定其设备:
| 1 2 3 |
|
在进行模型训练时,我们通常会将模型和数据都移动到GPU上:
| 1 2 3 4 5 6 7 8 9 10 |
|
以上就是在PyTorch中进行GPU加速的基本操作。使用GPU加速可以显著提高深度学习模型的训练速度。但需要注意的是,数据在CPU和GPU之间的传输会消耗一定的时间,因此我们应该尽量减少数据的传输次数。
2.3 自动求导
在深度学习中,我们经常需要进行梯度下降优化。这就需要我们计算梯度,也就是函数的导数。在PyTorch中,我们可以使用自动求导机制(autograd)来自动计算梯度。
在PyTorch中,我们可以设置tensor.requires_grad=True来追踪其上的所有操作。完成计算后,我们可以调用.backward()方法,PyTorch会自动计算和存储梯度。这个梯度可以通过.grad属性进行访问。
下面是一个简单的示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
以上示例中,out.backward()等同于out.backward(torch.tensor(1.))。如果out不是一个标量,因为tensor是矩阵,那么在调用.backward()时需要传入一个与out同形的权重向量进行相乘。
例如:
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
以上就是PyTorch中自动求导的基本使用方法。自动求导是PyTorch的重要特性之一,它为深度学习模型的训练提供了极大的便利。
3. PyTorch 神经网络
![]()
在掌握了PyTorch的基本使用方法之后,我们将探索一些更为高级的特性和用法。这些高级特性包括神经网络构建、数据加载以及模型保存和加载等等。
3.1 构建神经网络
PyTorch提供了torch.nn库,它是用于构建神经网络的工具库。torch.nn库依赖于autograd库来定义和计算梯度。nn.Module包含了神经网络的层以及返回输出的forward(input)方法。
以下是一个简单的神经网络的构建示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
|
以上就是一个简单的神经网络的构建方法。我们首先定义了一个Net类,这个类继承自nn.Module。然后在__init__方法中定义了网络的结构,在forward方法中定义了数据的流向。在网络的构建过程中,我们可以使用任何tensor操作。
需要注意的是,backward函数(用于计算梯度)会被autograd自动创建和实现。你只需要在nn.Module的子类中定义forward函数。
在创建好神经网络后,我们可以使用net.parameters()方法来返回网络的可学习参数。
3.2 数据加载和处理
在深度学习项目中,除了模型设计之外,数据的加载和处理也是非常重要的一部分。PyTorch提供了torch.utils.data.DataLoader类,可以帮助我们方便地进行数据的加载和处理。
3.2.1 DataLoader介绍
DataLoader类提供了对数据集的并行加载,可以有效地加载大量数据,并提供了多种数据采样方式。常用的参数有:
- dataset:加载的数据集(Dataset对象)
- batch_size:batch大小
- shuffle:是否每个epoch时都打乱数据
- num_workers:使用多进程加载的进程数,0表示不使用多进程
以下是一个简单的使用示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
3.2.2 自定义数据集
除了使用内置的数据集,我们也可以自定义数据集。自定义数据集需要继承Dataset类,并实现__len__和__getitem__两个方法。
以下是一个自定义数据集的简单示例:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
这个例子中,我们创建了一个简单的数据集,包含10个数据。然后我们使用DataLoader加载数据,并设置了batch大小和shuffle参数。
以上就是PyTorch中数据加载和处理的主要方法,通过这些方法,我们可以方便地对数据进行加载和处理。
3.3 模型的保存和加载
在深度学习模型的训练过程中,我们经常需要保存模型的参数以便于将来重新加载。这对于中断的训练过程的恢复,或者用于模型的分享和部署都是非常有用的。
PyTorch提供了简单的API来保存和加载模型。最常见的方法是使用torch.save来保存模型的参数,然后通过torch.load来加载模型的参数。
3.3.1 保存和加载模型参数
以下是一个简单的示例:
| 1 2 3 4 5 6 7 |
|
在保存模型参数时,我们通常使用.state_dict()方法来获取模型的参数。.state_dict()是一个从参数名字映射到参数值的字典对象。
在加载模型参数时,我们首先需要实例化一个和原模型结构相同的模型,然后使用.load_state_dict()方法加载参数。
请注意,load_state_dict()函数接受一个字典对象,而不是保存对象的路径。这意味着在你传入load_state_dict()函数之前,你必须反序列化你的保存的state_dict。
在加载模型后,我们通常调用.eval()方法将dropout和batch normalization层设置为评估模式。否则,它们会在评估模式下保持训练模式。
3.3.2 保存和加载整个模型
除了保存模型的参数,我们也可以保存整个模型。
| 1 2 3 4 5 6 |
|
保存整个模型会将模型的结构和参数一起保存。这意味着在加载模型时,我们不再需要手动创建模型实例。但是,这种方式需要更多的磁盘空间,并且可能在某些情况下导致代码的混乱,所以并不总是推荐的。
以上就是PyTorch中模型的保存和加载的基本方法。适当的保存和加载模型可以帮助我们更好地进行模型的训练和评估。
4. PyTorch GPT加速
![]()
掌握了PyTorch的基础和高级用法之后,我们现在要探讨一些PyTorch的进阶技巧,帮助我们更好地理解和使用这个强大的深度学习框架。
4.1 使用GPU加速
PyTorch支持使用GPU进行计算,这可以大大提高训练和推理的速度。使用GPU进行计算的核心就是将Tensor和模型转移到GPU上。
4.1.1 判断是否支持GPU
首先,我们需要判断当前的环境是否支持GPU。这可以通过torch.cuda.is_available()来实现:
| 1 |
|
4.1.2 Tensor在CPU和GPU之间转移
如果支持GPU,我们可以使用.to(device)或.cuda()方法将Tensor转移到GPU上。同样,我们也可以使用.cpu()方法将Tensor转移到CPU上:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
4.1.3 将模型转移到GPU上
类似的,我们也可以将模型转移到GPU上:
| 1 2 |
|
当模型在GPU上时,我们需要确保输入的Tensor也在GPU上,否则会报错。
注意,将模型转移到GPU上后,模型的所有参数和缓冲区都会转移到GPU上。
以上就是使用GPU进行计算的基本方法。通过合理的使用GPU,我们可以大大提高模型的训练和推理速度。
4.2 使用torchvision进行图像操作
torchvision是一个独立于PyTorch的包,提供了大量的图像数据集,图像处理工具和预训练模型等。
4.2.1 torchvision.datasets
torchvision.datasets模块提供了各种公共数据集,如CIFAR10、MNIST、ImageNet等,我们可以非常方便地下载和使用这些数据集。例如,下面的代码展示了如何下载和加载CIFAR10数据集:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
4.2.2 torchvision.transforms
torchvision.transforms模块提供了各种图像转换的工具,我们可以使用这些工具进行图像预处理和数据增强。例如,上面的代码中,我们使用了Compose函数来组合了两个图像处理操作:ToTensor(将图像转换为Tensor)和Normalize(标准化图像)。
4.2.3 torchvision.models
torchvision.models模块提供了预训练的模型,如ResNet、VGG、AlexNet等。我们可以非常方便地加载这些模型,并使用这些模型进行迁移学习。
| 1 2 3 4 |
|
以上就是torchvision的基本使用,它为我们提供了非常丰富的工具,可以大大提升我们处理图像数据的效率。
4.3 使用TensorBoard进行可视化
TensorBoard 是一个可视化工具,它可以帮助我们更好地理解,优化,和调试深度学习模型。PyTorch 提供了对 TensorBoard 的支持,我们可以非常方便地使用 TensorBoard 来监控模型的训练过程,比较不同模型的性能,可视化模型结构,等等。
4.3.1 启动 TensorBoard
要启动 TensorBoard,我们需要在命令行中运行 tensorboard --logdir=runs 命令,其中 runs 是保存 TensorBoard 数据的目录。
4.3.2 记录数据
我们可以使用 torch.utils.tensorboard 模块来记录数据。首先,我们需要创建一个 SummaryWriter 对象,然后通过这个对象的方法来记录数据。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
4.3.3 可视化模型结构
我们也可以使用 TensorBoard 来可视化模型结构。
| 1 2 |
|
4.3.4 可视化高维数据
我们还可以使用 TensorBoard 的嵌入功能来可视化高维数据,如图像特征、词嵌入等。
| 1 2 |
|
以上就是 TensorBoard 的基本使用方法。通过使用 TensorBoard,我们可以更好地理解和优化我们的模型。
5. PyTorch实战案例
![]()
在这一部分中,我们将通过一个实战案例来详细介绍如何使用PyTorch进行深度学习模型的开发。我们将使用CIFAR10数据集来训练一个卷积神经网络(Convolutional Neural Network,CNN)。
5.1 数据加载和预处理
首先,我们需要加载数据并进行预处理。我们将使用torchvision包来下载CIFAR10数据集,并使用transforms模块来对数据进行预处理。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
在这段代码中,我们首先定义了一系列的数据预处理操作,然后使用datasets.CIFAR10来下载CIFAR10数据集并进行预处理,最后使用torch.utils.data.DataLoader来创建数据加载器,它可以帮助我们在训练过程中按照批次获取数据。
5.2 定义网络模型
接下来,我们定义我们的卷积神经网络模型。在这个案例中,我们将使用两个卷积层和两个全连接层。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
在这个网络模型中,我们使用nn.Module来定义我们的网络模型,然后在__init__方法中定义网络的层,最后在forward方法中定义网络的前向传播过程。
5.3 定义损失函数和优化器
现在我们已经有了数据和模型,下一步我们需要定义损失函数和优化器。损失函数用于衡量模型的预测与真实标签的差距,优化器则用于优化模型的参数以减少损失。
在这个案例中,我们将使用交叉熵损失函数(Cross Entropy Loss)和随机梯度下降优化器(Stochastic Gradient Descent,SGD)。
| 1 2 3 4 5 6 7 |
|
在这段代码中,我们首先使用nn.CrossEntropyLoss来定义损失函数,然后使用optim.SGD来定义优化器。我们需要将网络的参数传递给优化器,然后设置学习率和动量。
5.4 训练网络
一切准备就绪后,我们开始训练网络。在训练过程中,我们首先通过网络进行前向传播得到输出,然后计算输出与真实标签的损失,接着通过后向传播计算梯度,最后使用优化器更新模型参数。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
在这段代码中,我们首先对数据集进行两轮训练。在每轮训练中,我们遍历数据加载器,获取一批数据,然后通过网络进行前向传播得到输出,计算损失,进行反向传播,最后更新参数。我们还在每2000个批次后打印一次损失信息,以便我们了解训练过程。
5.5 测试网络
训练完成后,我们需要在测试集上测试网络的性能。这可以让我们了解模型在未见过的数据上的表现如何,以评估其泛化能力。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
|
在这段代码中,我们首先加载一些测试图片,并打印出真实的标签。然后我们让网络对这些图片做出预测,并打印出预测的标签。最后,我们在整个测试集上测试网络,并打印出网络在测试集上的准确率。
5.6 保存和加载模型
在训练完网络并且对其进行了测试后,我们可能希望保存训练好的模型,以便于将来使用,或者继续训练。
| 1 2 |
|
在这段代码中,我们使用torch.save函数,将训练好的模型参数(通过net.state_dict()获得)保存到文件中。
当我们需要加载模型时,首先需要创建一个新的模型实例,然后使用load_state_dict方法将参数加载到模型中。
| 1 2 3 |
|
需要注意的是,load_state_dict方法加载的是模型的参数,而不是模型本身。因此,在加载模型参数之前,你需要先创建一个模型实例,这个模型需要与保存的模型具有相同的结构。
6. 总结
这篇文章通过详细且实践性的方式介绍了 PyTorch 的使用,包括环境安装、基础知识、张量操作、自动求导机制、神经网络创建、数据处理、模型训练、测试以及模型的保存和加载。
我们利用 PyTorch 从头到尾完成了一个完整的神经网络训练流程,并在 CIFAR10 数据集上测试了网络的性能。在这个过程中,我们深入了解了 PyTorch 提供的各种功能和工具。
希望这篇文章能对你学习 PyTorch 提供帮助,对于想要更深入了解 PyTorch 的读者,我建议参考 PyTorch 的官方文档以及各种开源教程。实践是最好的学习方法,只有通过大量的练习和实践,才能真正掌握 PyTorch 和深度学习。
谢谢你的阅读,希望你在深度学习的道路上越走越远!
相关文章:

Pytorch简介
1.1 Pytorch的历史 PyTorch是一个由Facebook的人工智能研究团队开发的开源深度学习框架。在2016年发布后,PyTorch很快就因其易用性、灵活性和强大的功能而在科研社区中广受欢迎。下面我们将详细介绍PyTorch的发展历程。 在2016年,Facebook的AI研究团队…...
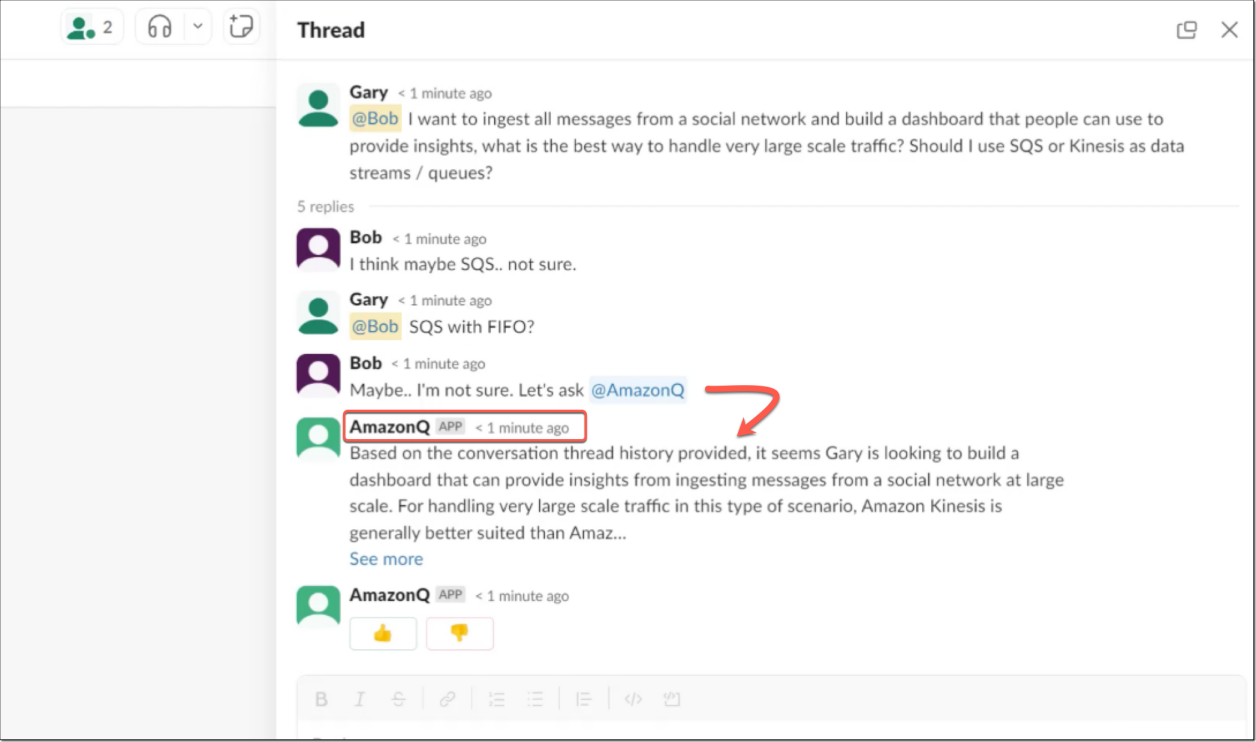
亚马逊云科技Amazon Q,一款基于生成式人工智能的新型助手
近日,亚马逊云科技宣布推出Amazon Q,这是一款基于生成式人工智能(AI)的新型助手,专为辅助工作而设计,可以根据您的业务量身定制。通过连接到公司的信息存储库、代码、数据和企业系统,可以使用Am…...
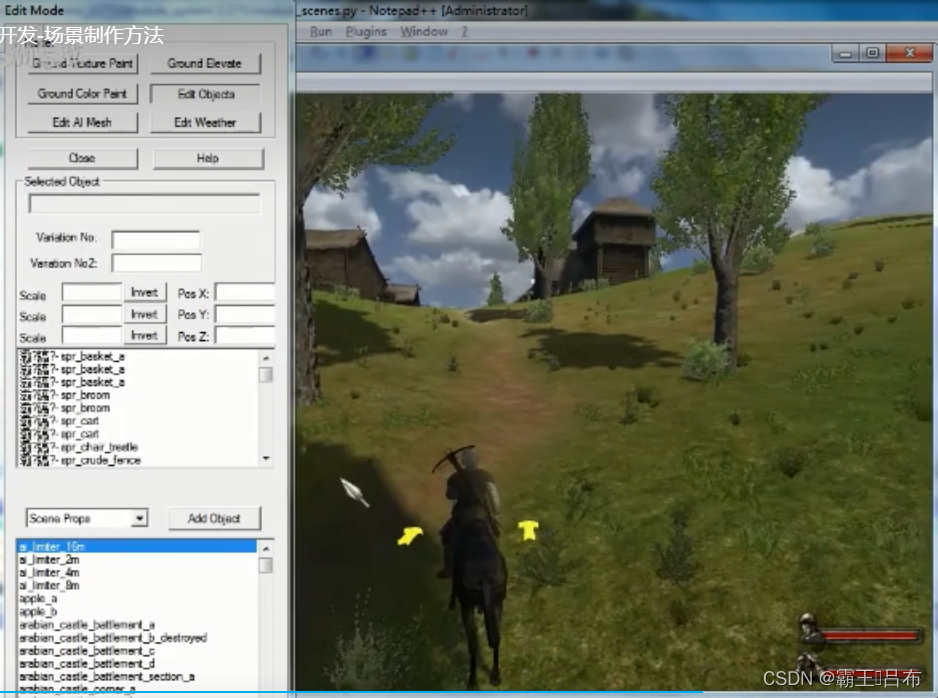
骑砍战团MOD开发(29)-module_scenes.py游戏场景
骑砍1战团mod开发-场景制作方法_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1Cw411N7G4/ 一.骑砍游戏场景 骑砍战团中进入城堡,乡村,战斗地图都被定义为场景,由module_scenes.py进行管理。 scene(游戏场景) 天空盒(Skyboxes.py) 地形(terrain code) 场景物(scene_…...
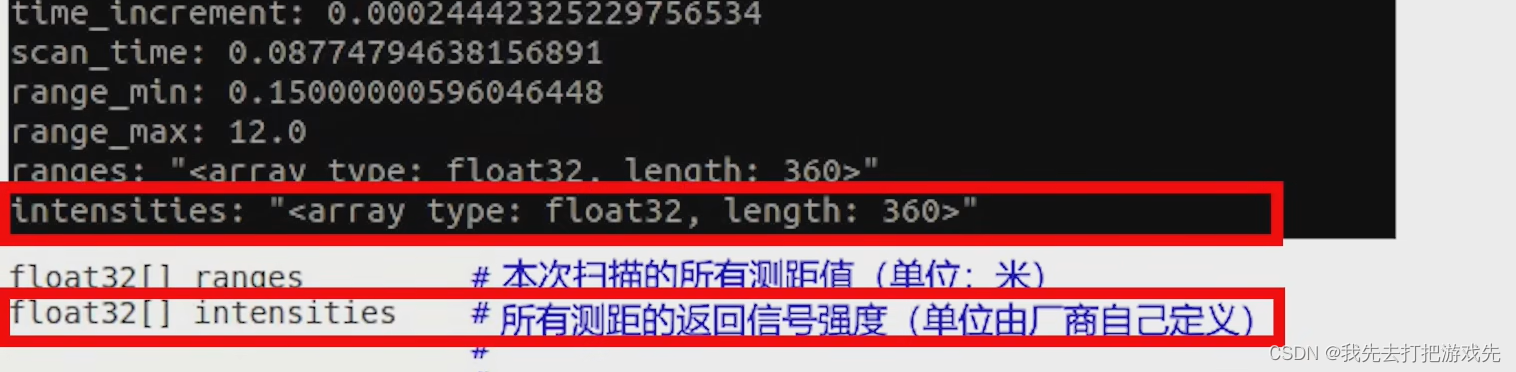
ROS学习记录:ROS系统中的激光雷达消息包的数据格式
一、在工作空间中输入source ./devel/setup.bash 二、输入roslaunch wpr_simulation wpb_simple.launch打开机器人仿真环境 三、机器人仿真环境打开成功 四、给机器人围上一圈障碍物 五、再打开一个工作空间终端 六、输入roslaunch wpr_simulation wpb_rviz.launch打开RViz 七、…...
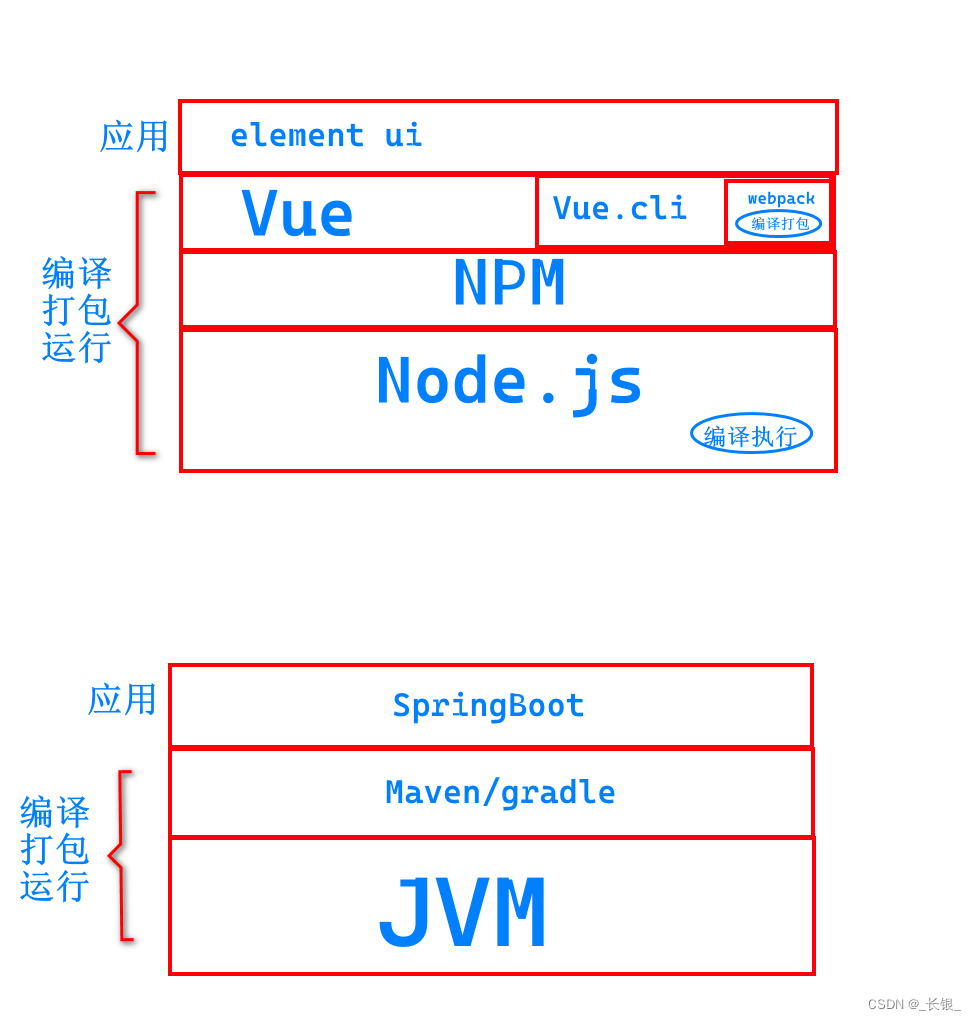
Vue.js和Node.js的关系--类比Java系列
首先我们看一张图 这里我们类比了Java的jvm和JavaScript的node.js。 可以看到,node.js是基础,提供了基础的编译执行的能力。vue,js是实际上定义了一种他自己的代码格式,以加速开发。...

我的笔记本电脑死机问题折腾记录
两年前,买了一台笔记本电脑。直到今年4月份,不到两年的时间,便出现了花屏的情况,然后就到官方售后去维修,换屏。然后在6月份,屏幕问题再次出现,又去售后维修。 经过两次维修,笔记本…...

uniApp中uView组件库的丰富布局方法
目录 基本使用 #分栏间隔 #混合布局 #分栏偏移 #对齐方式 API #Row Props #Col Props #Row Events #Col Events UniApp的uView组件库是一个丰富的UI组件库,提供了各种常用的UI组件和布局方法,帮助开发者快速构建美观、灵活的界面。下面给你写一…...
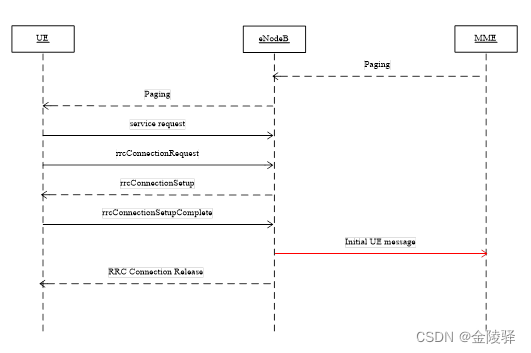
TDD-LTE 寻呼流程
目录 1. 寻呼成功流程 1.1 空闲态寻呼 1.2 连接态寻呼 2. 寻呼失败流程 2.1 Paging消息不可达 2.2 RRC建立失败 2.3 eNodeB未上发Initial UE message或达到超时 1. 寻呼成功流程 1.1 空闲态寻呼 寻呼成功:MME发起寻呼(S1 接口发送Paing 消息&…...
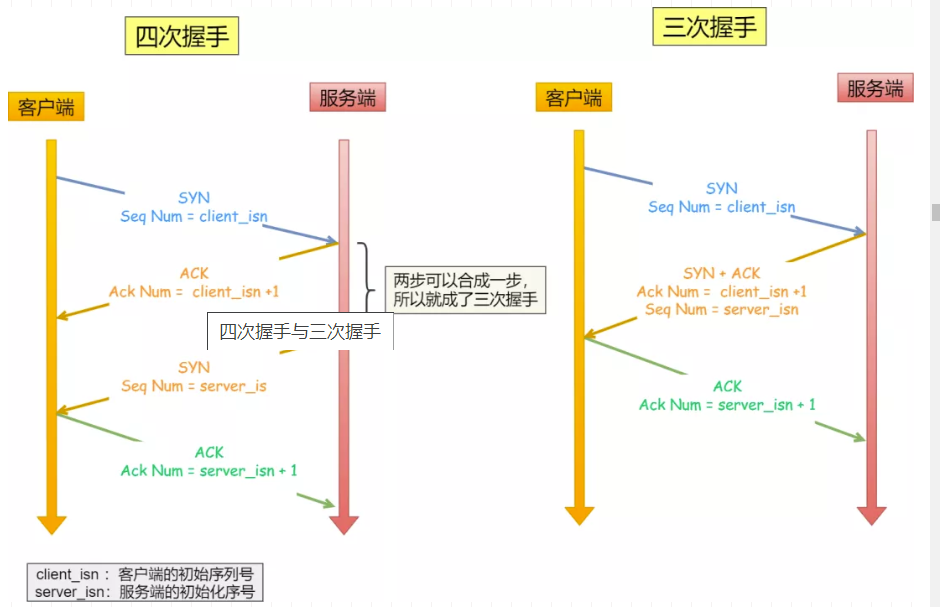
TCP中的三次握手和四次挥手
TCP中的连接和断开可以说是在面试中经常被问到的问题之一,正好有空就总结一下,首先回顾一下TCP的相关知识点 1. TCP的基础知识 1.1 TCP的基本概念 我们知道TCP是运输层的面向连接的可靠的传输协议。面向连接的,指的就是在两个进程发送数据…...
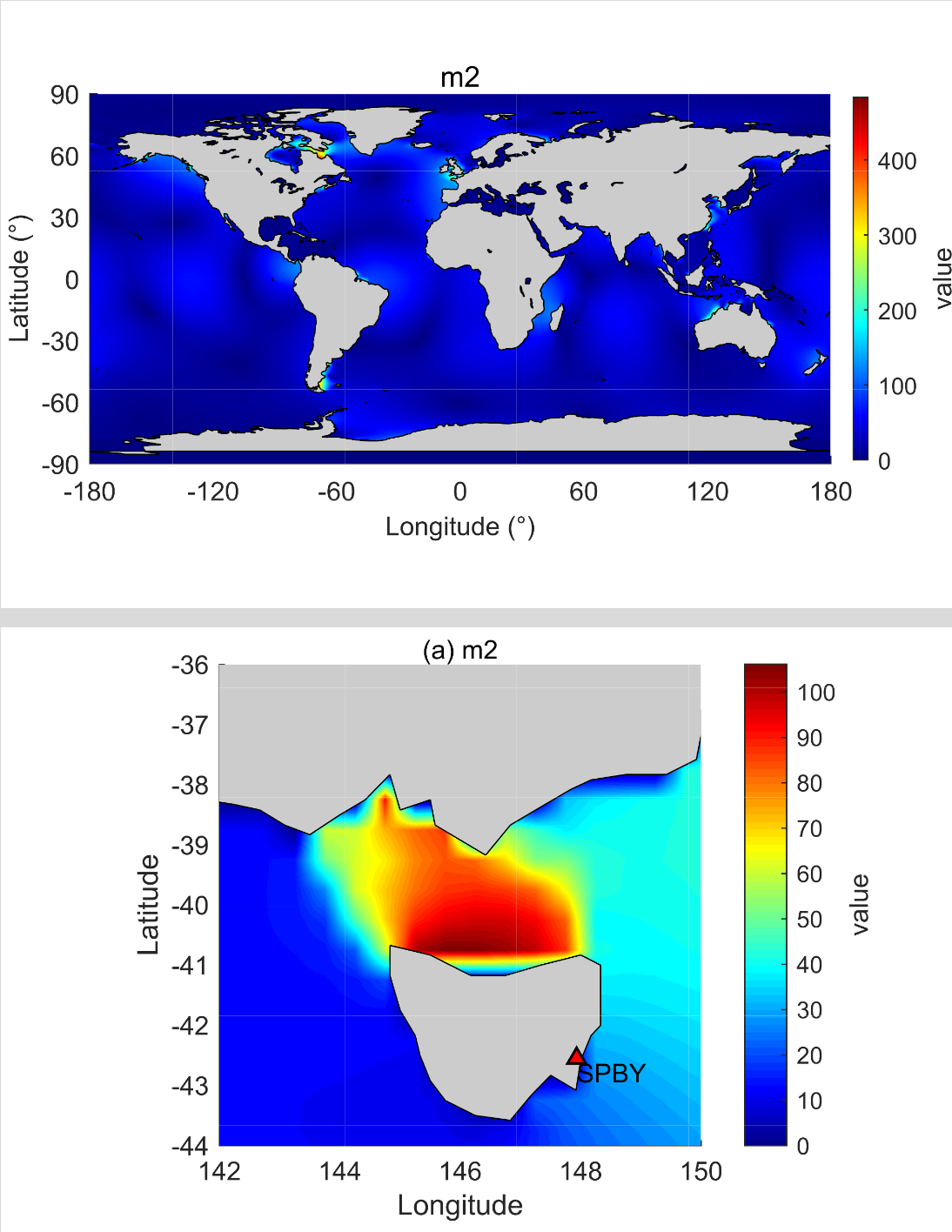
NAO.99b海潮模型的详解教程
NAO.99b模型是由日本国家天文台开发的全球潮汐模式,基于二维非线性浅水方程。该模型具有较高的分辨率,网格间距为0.50.5,网格数为720360,覆盖的经度范围为0.25~359.75E,纬度范围为89.75S~89.75N…...
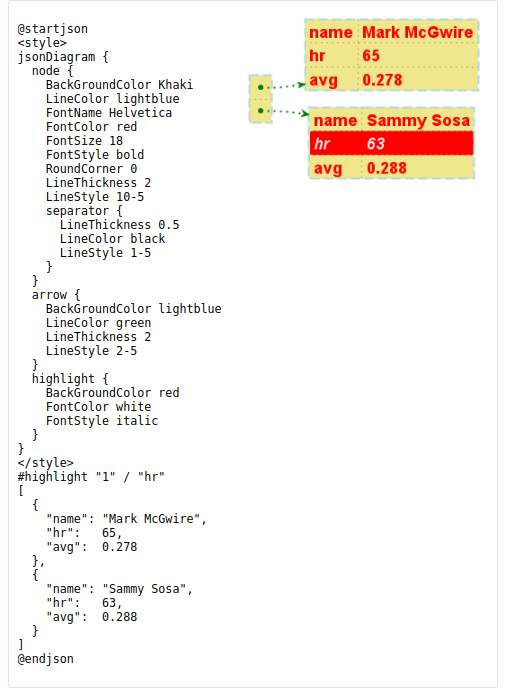
Plantuml之JSON数据语法介绍(二十五)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...
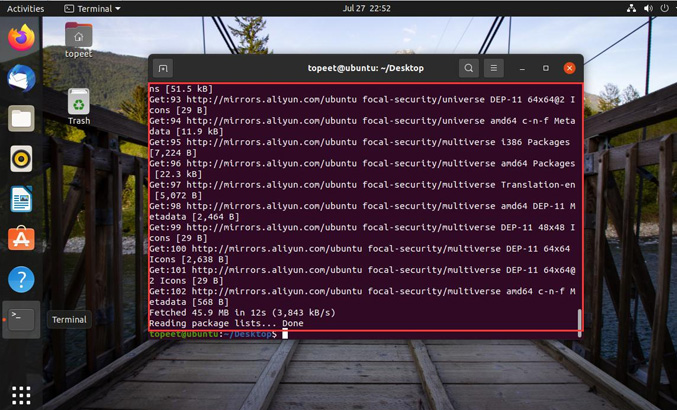
迅为龙芯2K1000开发板虚拟机 ubuntu 更换下载源
Ubuntu 系统软件的下载安装我们通常使用命令“apt-get” , 该命令可以实现软件自动下载, 安装, 配置。 该命令采用客户端/服务器的模式, 我们的 Ubuntu 系统作为客户端, 当需要下载软件的时候就向服务器发起请求&#…...

你好!Apache Seata
北京时间 2023 年 10 月 29 日,分布式事务开源项目 Seata 正式通过 Apache 基金会的投票决议,以全票通过的优秀表现正式成为 Apache 孵化器项目! 根据 Apache 基金会邮件列表显示,在包含 13 个约束性投票 (binding votes) 和 6 个…...
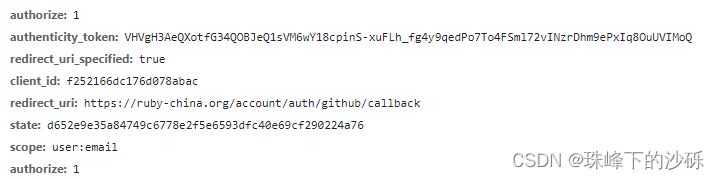
RFC6749-OAuth2.0
前言 最近在项目中需要实现SSO(单点登录)功能,以实现一处注册,即可在任何平台之间登录的功能。我们项目中并没有直接对接第三方认证系统而是通过集成keycloak 完成一系类安全协议的对接工作。如果我们在代码级别自己完成各种安全协议的对接是一项十分大的工程。不仅要走统一的…...
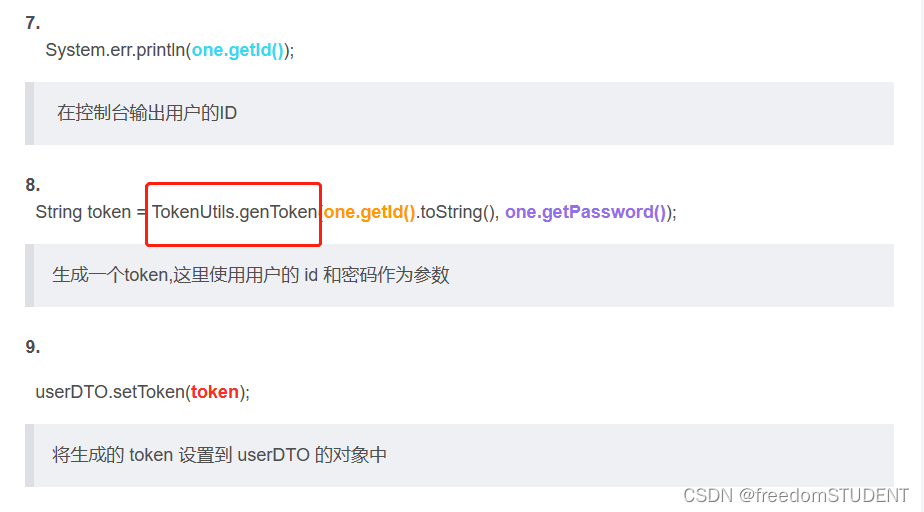
【代码解析】代码解析之生成token(1)
本篇文章主要解析上一篇:代码解析之登录(1)里的第8行代码调用 TokenUtils 类里的genToken 方法 https://blog.csdn.net/m0_67930426/article/details/135327553?spm1001.2014.3001.5501 genToken方法代码如下: public static S…...
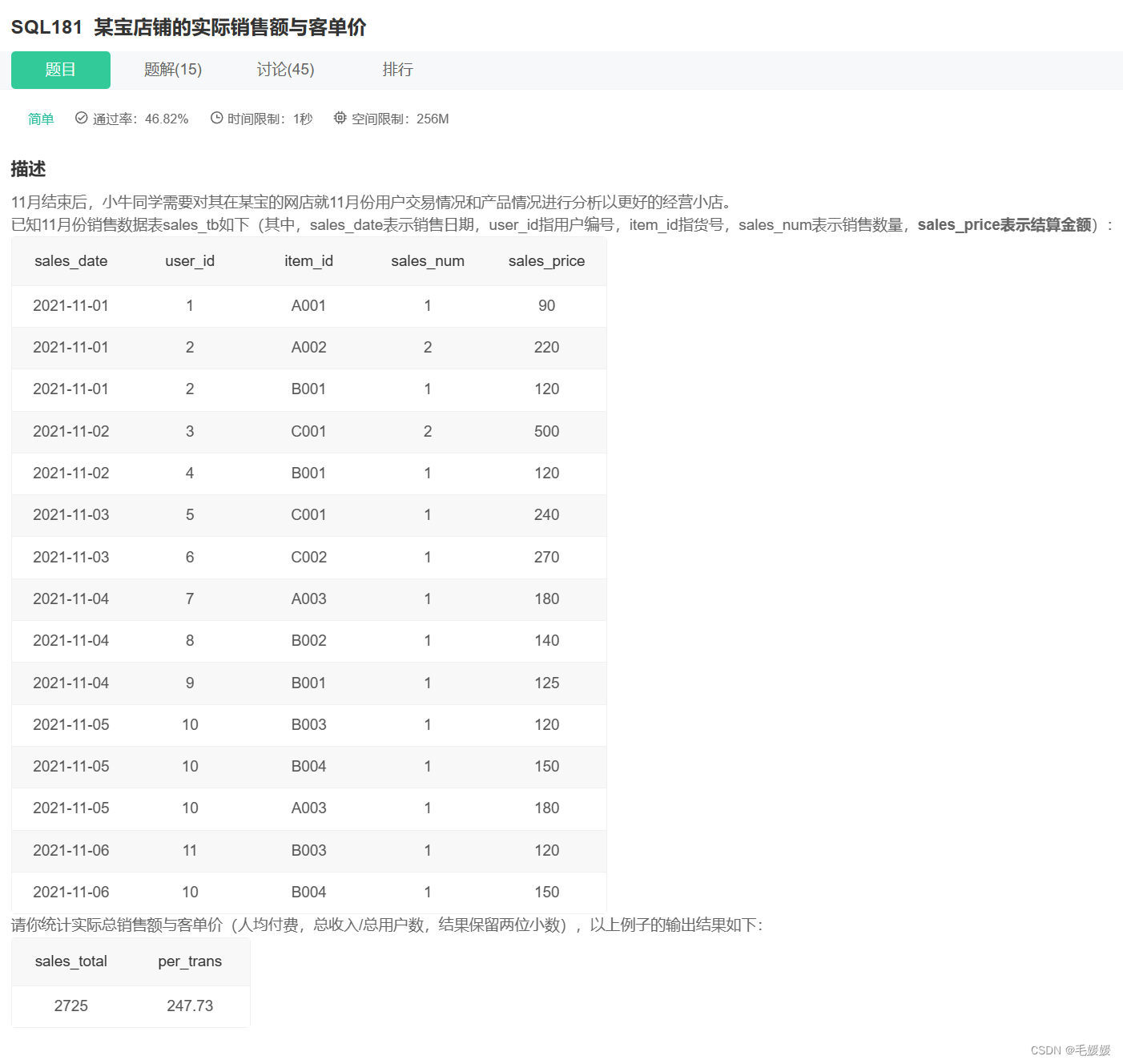
牛客网SQL训练5—SQL大厂面试真题
文章目录 一、某音短视频1.各个视频的平均完播率2.平均播放进度大于60%的视频类别3.每类视频近一个月的转发量/率4.每个创作者每月的涨粉率及截止当前的总粉丝量5.国庆期间每类视频点赞量和转发量6.近一个月发布的视频中热度最高的top3视频 二、用户增长场景(某度信…...
kubeadm来搭建k8s集群。
我们采用了二进制包搭建出的k8s集群,本次我们采用更为简单的kubeadm的方式来搭建k8s集群。 二进制的搭建更适合50台主机以上的大集群,kubeadm更适合中小型企业的集群搭建 主机配置建议:2c 4G 主机节点 IP …...
【java爬虫】使用element-plus进行个股详细数据分页展示
前言 前面的文章我们讲述了获取详细个股数据的方法,并且使用echarts对个股的价格走势图进行了展示,本文将编写一个页面,对个股详细数据进行展示。别问涉及到了element-plus中分页的写法,对于这部分知识将会做重点讲解。 首先看一…...

Python使用余弦相似度比较两个图片
为了使用余弦相似度来找到与样例图片相似的图片,我们需要先进行一些预处理,然后计算每两张图片之间的余弦相似度。以下是一个简单的实现: 读取样例图片和目标文件夹中的所有图片。对每张图片进行预处理,例如灰度化、降噪等。计算…...
树莓派4B-Python使用PyCharm的SSH协议在电脑上远程编辑程序
目录 前言一、pycharm的选择二、添加SSH的解释器使用总结 前言 树莓派的性能始终有限,不好安装与使用高级一点的程序编辑器,如果只用thonny的话,本人用得不习惯,还不如PyCharm,所以想着能不能用电脑中的pycharm来编写…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

SpringAI实战:ChatModel智能对话全解
一、引言:Spring AI 与 Chat Model 的核心价值 🚀 在 Java 生态中集成大模型能力,Spring AI 提供了高效的解决方案 🤖。其中 Chat Model 作为核心交互组件,通过标准化接口简化了与大语言模型(LLM࿰…...
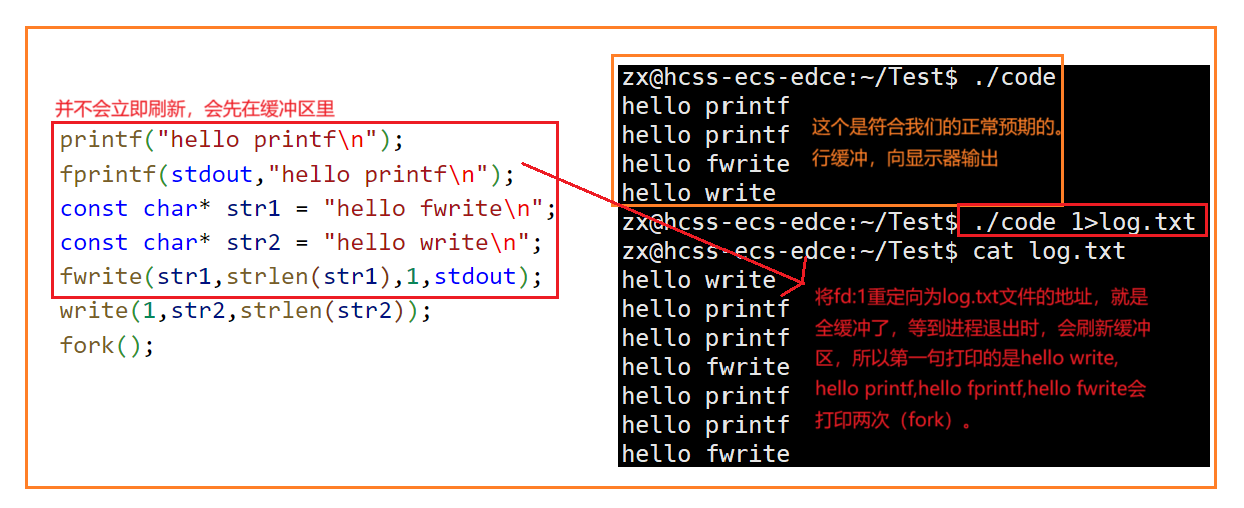
Linux中《基础IO》详细介绍
目录 理解"文件"狭义理解广义理解文件操作的归类认知系统角度文件类别 回顾C文件接口打开文件写文件读文件稍作修改,实现简单cat命令 输出信息到显示器,你有哪些方法stdin & stdout & stderr打开文件的方式 系统⽂件I/O⼀种传递标志位…...
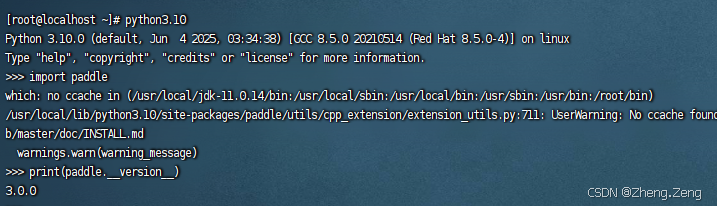
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10+pip3.10)
第一篇:Liunx环境下搭建PaddlePaddle 3.0基础环境(Liunx Centos8.5安装Python3.10pip3.10) 一:前言二:安装编译依赖二:安装Python3.10三:安装PIP3.10四:安装Paddlepaddle基础框架4.1…...

算法250609 高精度
加法 #include<stdio.h> #include<iostream> #include<string.h> #include<math.h> #include<algorithm> using namespace std; char input1[205]; char input2[205]; int main(){while(scanf("%s%s",input1,input2)!EOF){int a[205]…...