SQL性能优化-索引
1.性能下降sql慢执行时间长等待时间长常见原因
1)索引失效
索引分为单索、复合索引。

四种创建索引方式

create index index_name on user (name);
create index index_name_2 on user(id,name,email);
2)查询语句较烂
3)关联查询太多join,sql设计不合理
4)服务器问题。
2. explain使用
explain关键字可以模拟优化器执行 SQL 查询语句,从而知道 MySQL 是如何处理 SQL 语句的。分析查询语句或表结构的性能瓶颈。
2.1 ID 参数
select 查询的序列号,包含一组数字,表示查询中执行 select 子句或操作表的顺序。三种情况:
【1】id 相同:执行顺序由上而下;
explain select t2.* from t1,t2,t3 where t1.id = t2.id and t1.id = t3.id and t1.other_column = '';
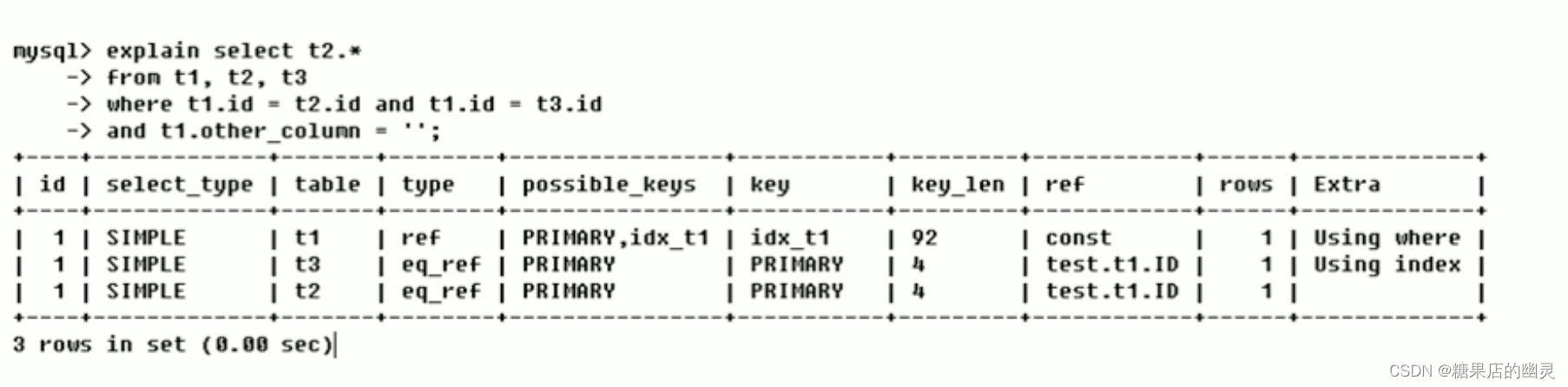
【2】id 不同:如果是子查询,id 序号会递增,id 越大优先级越高,越先被执行;
explain select t2.* from t2 where id = (select id from t1 where id = (select t3.id from t3 where t3.other_column = ''));

【3】id 相同不同同时存在:id 如果相同,可以认为是一组,由上往下执行;在所有组里 id 越大,优先级越高,越先执行;
explain select t2.* from (select t3.id from t3 where t3.other_column = '') s1,t2 where s1.id = t2.id;

2.2select_type 数据读取操作类型
【1】simple
简单的 select 查询,查询中不包含子查询或者 UNION;
【2】primary
查询中若包含任何复杂的自查询,最外层查询为 PRIMARY;
【3】subquery
在 SELECT 或 WHERE 中包含子查询;
【4】derived
在 FROM 列表中包含的子查询被标记为 DERIVED(衍生)MySQL 会递归执行这些子查询,把结果放进临时表;
【5】union
若第二个 SELECT 出现在 UNION 之后,则被标记为 UNION,若 UNION 包含在 FROM 子句的子查询,则外层SELECT 将被标记为 DERIVED;
【6】union result
从 UNION表中获取结果的 SELECT;
2.3 type 访问类型
从最好到最差:system>const>eq_ref>ref>range>index>ALL,一般达到 rang 级别,最好达到 ref 级别。
【1】system:表只有一行记录(系统表),平时不会出现;
【2】const:表示通过索引一次就能找到,const用于比较 primary和 unique索引。因为只匹配一行数据,所以很快;
【3】eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常用于主键或唯一索引扫描。eg:CEO部门;
【4】ref:非唯一性索引扫描,返回匹配某个单独值的所有行;
【5】rang:只检索给定范围的行,使用一个索引来选择行。一般where语句中出现between、<、>、in等的查询。这种范围扫描索引比全表扫描要好,因为只需开始索引的某一点,而结束另一点,不用扫描全部索引;
【6】index:Full Index Scan,index与 ALL区别为 index类型只遍历索引树,索引文件通常比数据文件小。index从索引中读取,而All是从硬盘读取;
【7】ALL:从磁盘中读取
2.4 possible_keys 与 key
possible_keys:显示可能应用到这张表中的索引,一个或多个,查询字段上若存在索引则列出来,但不一定被查询实际使用。
key:实际使用的索引,如果该值为NULL,则没有使用索引;如果查询中使用了覆盖索引,则该索引仅出现在 key列表中。
【覆盖索引】:就是 select后面的字段都具备索引,提高了查询效率,前提顺序、个数都要一致;
【理解方式一】:就是 select的数据列从索引中就能够获取到,不必读取没有必要多余的数据行,MySQL可以利用索引返回select列表中的字段,而不必根据索引再次读取数据文件,换句话说查询列要被所建索引覆盖。
【理解方式二】:索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此它不必读取整个数据行,毕竟索引叶子节点存储了它们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要读取行了。一个索引包含了(或覆盖了)满足查询结果的数据就叫做覆盖索引。
【使用覆盖索引注意】:如果使用覆盖索引,一定注意 select列表中只取需要的列,不可使用select *,因为如果将所有字段一起做索引会导致索引文件过大,查询性能下降。
2.5 key_len
表示索引中使用的字节数,可通过该列查找出使用索引的长度。在不损坏精准性的情况下,长度越短越好。key_len显示的值为索引字段的最大可能长度,并非实际长度,即 key_len是根据表定义实际计算出来的,不是通过表内检出来的。
2.6 ref
显示索引的那一列被使用,如果可能的话,是一个常数。那些列或常量被用于查找索引上的值。
2.7 rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录的行数。常用于优化时查看,使用该值与实际返回的行数进行比较,如果相差很大,则需要调优。
2.8 Extra
包含不适合在其他列中显示,但十分重要的信息。
【1】Using fileSort:说明 MySQL会对数据使用一个外部的索引排序,而不是按照表内索引进行读取。MySQL无法利用索引完成的排序操作称为“文件排序”。(出现表示不好)
【2】Using temporary:使用临时表保存中间结果,MySQL在查询结果排序时使用临时表。重用于排序 order by和分组查询 group by。
【3】Using index:表示相应的 select操作中使用了覆盖索引(convering index),避免访问了表的数据行,效率不错!
【4】using where,using index:查询的列被索引覆盖,并且 where筛选条件是索引列之一但是不是索引的前导列,Extra中为Using where; Using index,意味着无法直接通过索引查找来查询到符合条件的数据;
查询的列被索引覆盖,并且where筛选条件是索引列前导列的一个范围,同样意味着无法直接通过索引查询到符合条件的数据
【5】NULL(既没有Using index,也没有Using where Using index,也没有using where):查询的列未被索引覆盖,并且where筛选条件是索引的前导列,意味着用到了索引,但是部分字段未被索引覆盖,必须通过“回表”来实现,不是纯粹地用到了索引,也不是完全没用到索引,Extra中为NULL(没有信息)
【6】Using where:查询条件中使用了索引查找。查询的列未被索引覆盖,where筛选条件非索引的前导列,Extra 中为 Using where。order_id 也是索引。
查询的列未被索引覆盖,where筛选条件非索引列,Extra中为Using where。意味着通过索引或者表扫描的方式进行 where条件的过滤,反过来说,也就是没有可用的索引查找,当然这里也要考虑索引扫描+回表与表扫描的代价。这里的 type都是 all,说明MySQL认为全表扫描是一种比较低的代价。
【7】Using index condition:查询的列不全在索引中,where条件中是一个前导列的范围
查询列不完全被索引覆盖,查询条件完全可以使用到索引(进行索引查找)
【8】Using join buffer:使用了连接缓存。
【9】impossible where:where子句总是false,不能用来获取任何元素。
【10】select tables optimized away:在没有 GROUPBY 子句的情况下,基于索引优化 MIN/MAX操作。
【11】distinct:优化 distinct操作。在找到第一匹配的时候就停止找同样的动作。
相关文章:
SQL性能优化-索引
1.性能下降sql慢执行时间长等待时间长常见原因 1)索引失效 索引分为单索、复合索引。 四种创建索引方式 create index index_name on user (name); create index index_name_2 on user(id,name,email); 2)查询语句较烂 3)关联查询太多join&a…...

Ubuntu本地快速搭建web小游戏网站,公网用户远程访问
🔥博客主页: 小羊失眠啦. 🎥系列专栏:《C语言》 《数据结构》 《Linux》《Cpolar》 ❤️感谢大家点赞👍收藏⭐评论✍️ 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,…...
easyrecovery 2024最新免费密钥分享 实用数据恢复软件分享
在日常使用电脑时,我们经常会遇到误删文件的情况,若文件还未被彻底删除,我们还可以通过电脑中的回收站将其恢复,但若是回收站都被清空的话,想要恢复文件就变得比较困难了,而EasyRecovery可以很好的帮助我们…...

2.4信道复用技术
目录 2.4信道复用技术2.4.1频分复用、时分复用和统计时分复用频分复用FDM(Frequency Division Multiplexing)时分复用TDM(Time Division Multiplexing)统计时分复用STDM(Statistic TDM) 2.4.2波分复用2.4.3…...

JVM篇:JVM的简介
JVM简介 JVM全称为Java Virtual Machine,翻译过来就是java虚拟机,Java程序(Java二进制字节码)的运行环境 JVM的优点: Java最大的一个优点是,一次编写,到处运行。之所以能够实现这个功能就是依…...
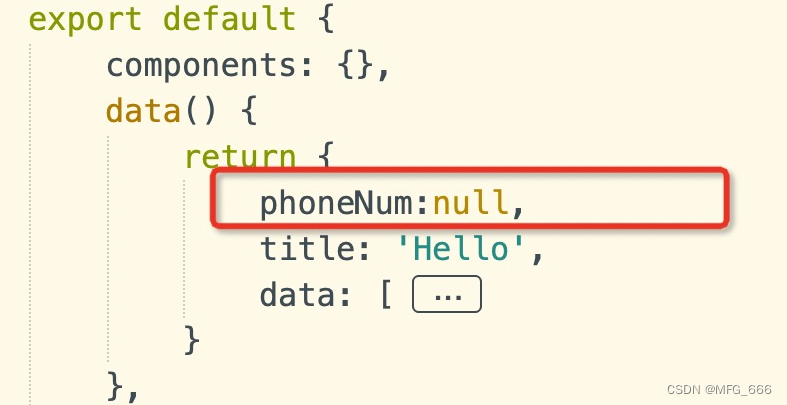
uniapp 输入手机号并且正则校验
1.<input input“onInput” :value“phoneNum” type“number” maxlength“11”/> 3. method里面写 onInput(e){ this.phoneNum e.detail.value }, 4.调用接口时候校验正则 if (!/^1[3456789]\d{9}$/.test(this.phoneNum)) {uni.showToast({title: 请输入正确的手机号…...

经典目标检测YOLO系列(一)复现YOLOV1(3)正样本的匹配及损失函数的实现
经典目标检测YOLO系列(一)复现YOLOV1(3)正样本的匹配及损失函数的实现 之前,我们依据《YOLO目标检测》(ISBN:9787115627094)一书,提出了新的YOLOV1架构,并解决前向推理过程中的两个问题,继续按照此书进行YOLOV1的复现。 经典目标…...
kbdnecat.DLL文件缺失,软件或游戏无法启动运营,快速修复方法
“kbdnecat.DLL文件是什么?为什么一起动游戏或软件,Windows就报错“kbdnecat.DLL文件缺失,软件无法启动””,应该怎么修复呢? 首先,先来了解“kbdnecat.DLL文件”是什么? kbdnecat.DLL是一个动…...
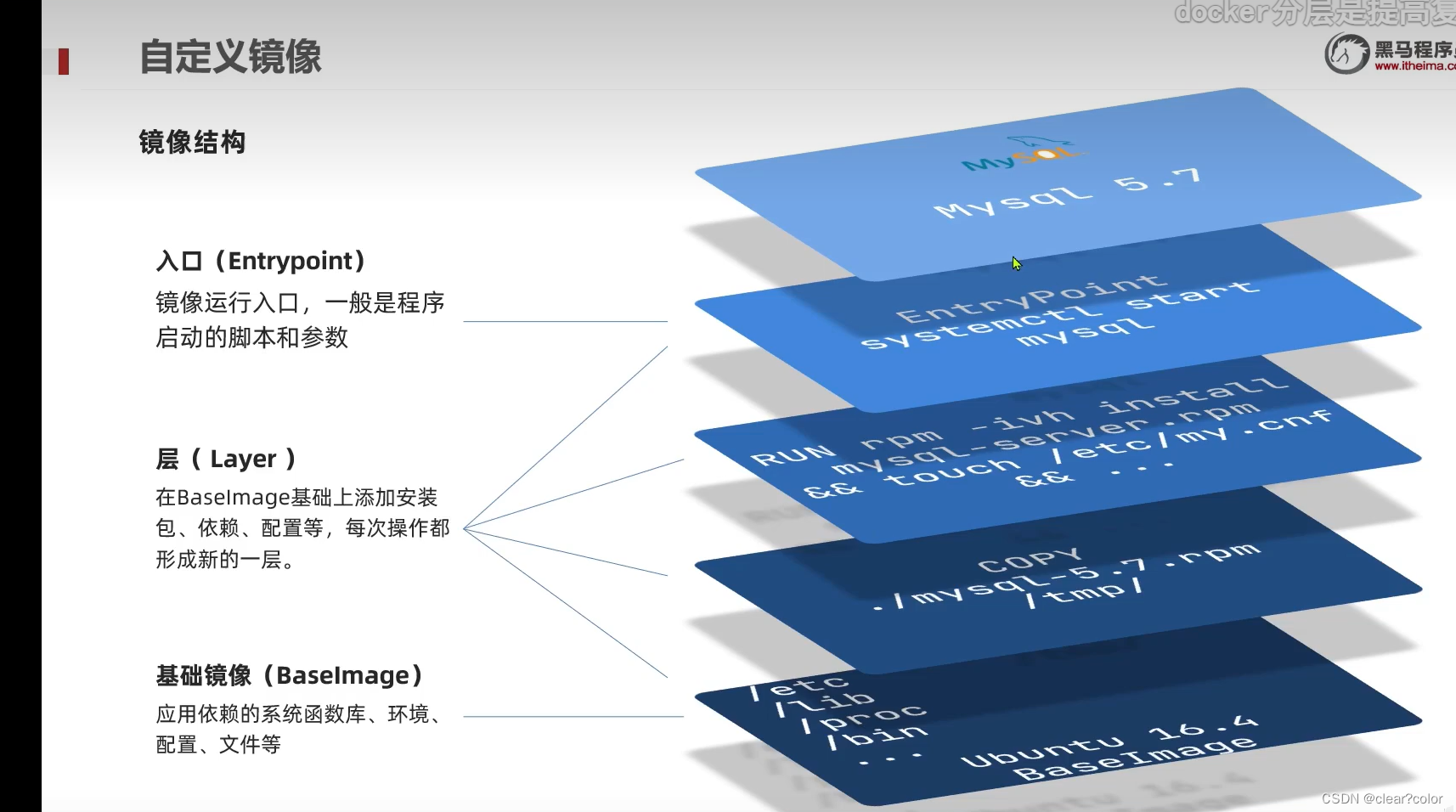
Dockerfile与DockerCompose
Docker的Image结构是怎样的? 镜像是将应用程序 及其需要的 系统函数库、环境、配置、依赖 打包而成。 镜像结构 入口( Entrypoint ) 镜像运行入口,一般是程序启动的脚本和参数 层( Layer ) 在BaseImage基…...
【CFP-专栏2】计算机类SCI优质期刊汇总(含IEEE/Top)
一、计算机区块链类SCI-IEEE 【期刊概况】IF:4.0-5.0, JCR2区,中科院2区; 【大类学科】计算机科学; 【检索情况】SCI在检; 【录用周期】3-5个月左右录用; 【截稿时间】12.31截稿; 【接收领域】区块链…...

Stable Diffusion 本地部署详细教程
目录 一、前言二、系统和硬件要求三、安装前说明四、安装步骤5、升级pip(这是管理python环境软件工具),并把资源库换成国内地址为清华镜像。一、前言 虽然MJ和SD都可以生成图像,但是为什么我们要考虑使用本地SD部署呢?原因其实很简单:首先,本地部署的使用成本更低,且更加…...
【超图】SuperMap iClient3D for WebGL/WebGPU —— 坐标系位置 —— Cartesian2
作者:taco 说到关于地理必然逃不开位置的关系。借用百度百科的内容来说地理学(geography),是研究地球表层空间地理要素或者地理综合体空间分布规律、时间演变过程和区域特征的一门学科。所以位置&坐标系必然逃不掉了。那么在S…...
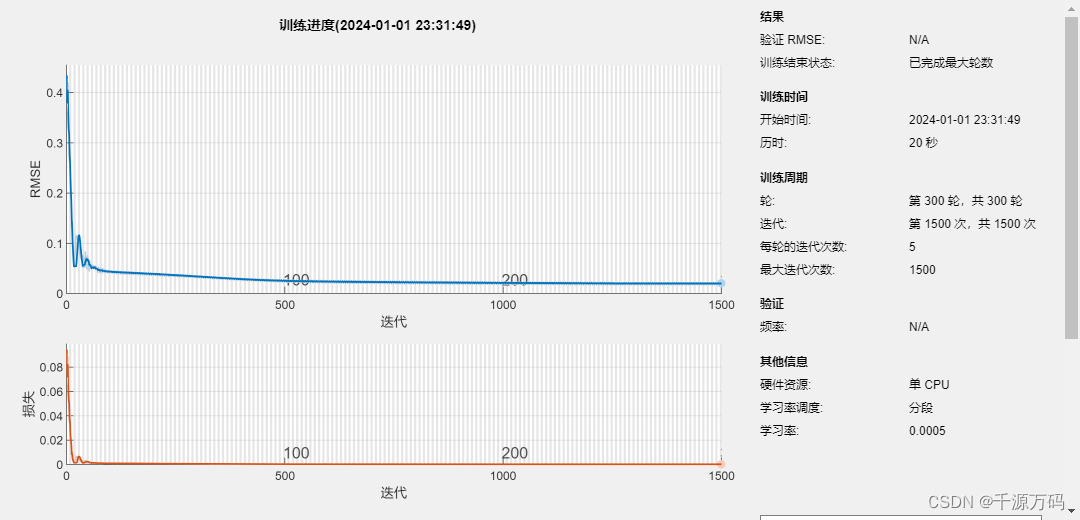
【Matlab】LSTM长短期记忆神经网络时序预测算法(附代码)
资源下载: https://download.csdn.net/download/vvoennvv/88688439 一,概述 LSTM(Long Short-Term Memory)是一种常用的循环神经网络(Recurrent Neural Network,RNN)结构,由于其对于…...

2.2 设计FMEA步骤二:结构分析
2.2.1 目的 设计结构分析的目的是将设计识别和分解为系统、子系统、组件和零件,以便进行技术风险分析。其主要目标包括: 可视化分析范围结构化表示:方块图、边界图、数字模型、实体零件识别设计接口、交互作用和间隙促进顾客和供应商工程团队之间的协作(接口责任)为功能分…...

红队攻防实战之DC2
吾愿效法古圣先贤,使成千上万的巧儿都能在21世纪的中华盛世里,丰衣足食,怡然自得 0x01 信息收集: 1.1 端口探测 使用nmap工具 可以发现开放了80端口,网页服务器但是可以看出做了域名解析,所以需要在本地完成本地域名…...
【28】Kotlin语法进阶——使用协程编写高效的并发程序
提示:此文章仅作为本人记录日常学习使用,若有存在错误或者不严谨得地方欢迎指正。 文章目录 一、Kotlin中的协程1.1 协程的基本用法1.1.1协程与协程作用域1.1.2 使用launch函数创建子协程1.1.3 通过suspend关键声明挂起函数1.1.4 coroutineScope函数 1.2…...
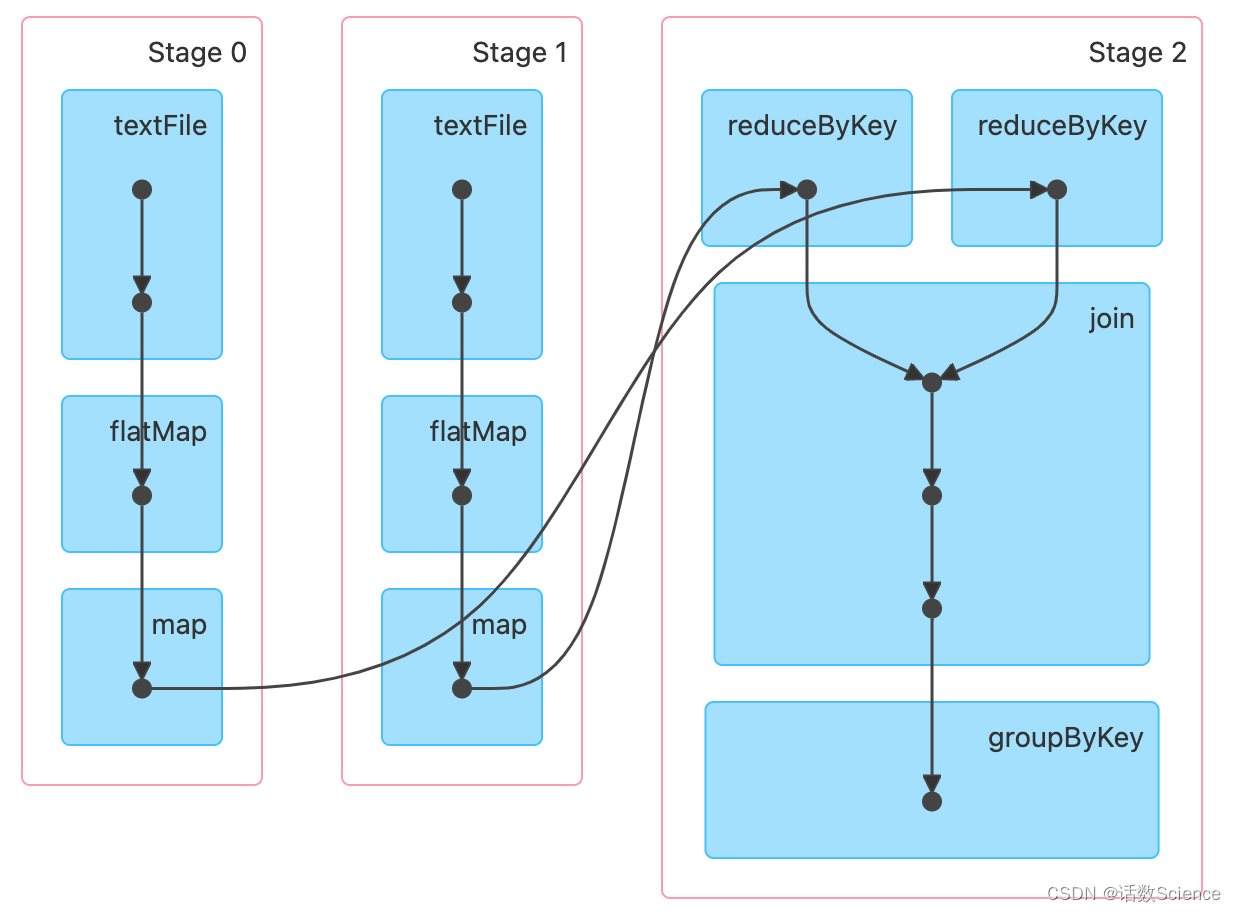
【大数据面试知识点】Spark的DAGScheduler
Spark数据本地化是在哪个阶段计算首选位置的? 先看一下DAGScheduler的注释,可以看到DAGScheduler除了Stage和Task的划分外,还做了缓存的跟踪和首选运行位置的计算。 DAGScheduler注释: The high-level scheduling layer that i…...
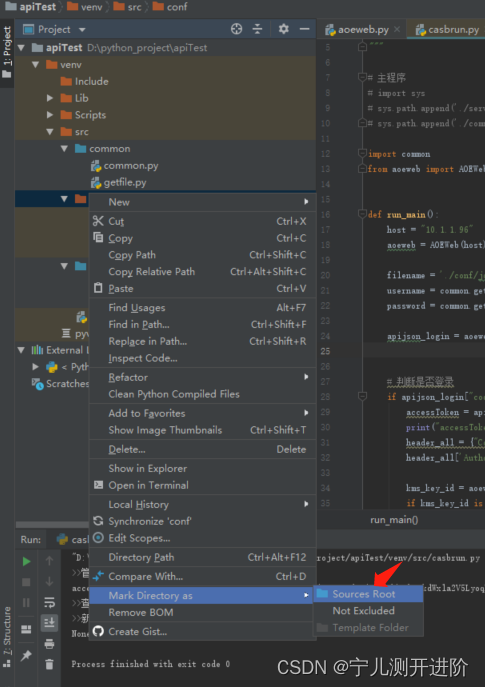
Pycharm引用其他文件夹的py
Pycharm引用其他文件夹的py 方式1:包名设置为Sources ROOT 起包名的时候,需要在该文件夹上:右键 --> Mark Directory as --> Sources ROOT 标记目录为源码目录,就可以了。 再引用就可以了 import common from aoeweb impo…...
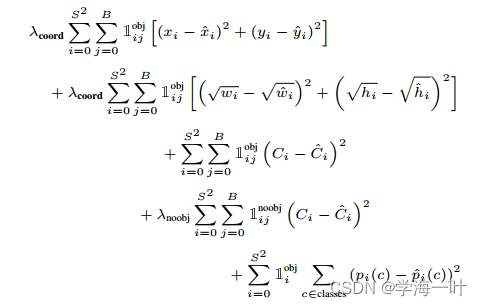
目标检测-One Stage-YOLOv1
文章目录 前言一、YOLOv1的网络结构和流程二、YOLOv1的损失函数三、YOLOv1的创新点总结 前言 前文目标检测-Two Stage-Mask RCNN提到了Two Stage算法的局限性: 速度上并不能满足实时的要求 因此出现了新的One Stage算法簇,YOLOv1是目标检测中One Stag…...
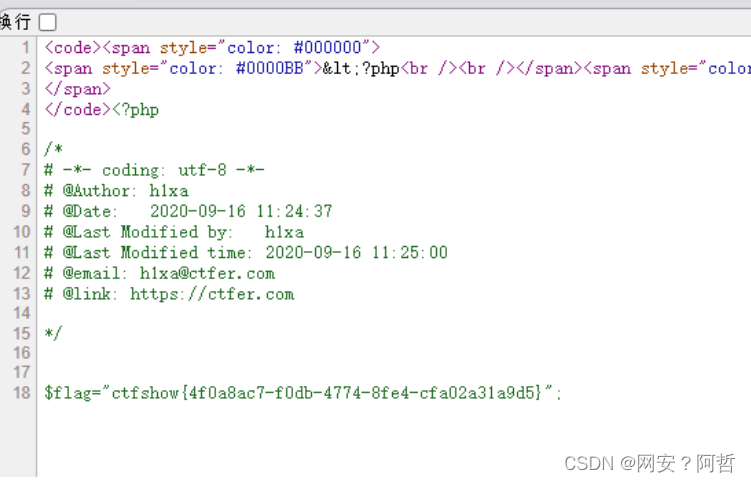
PHP序列化总结3--反序列化的简单利用及案例分析
反序列化中生成对象里面的值,是由反序列化里面的值决定,与原类中预定义的值的值无关,穷反序列化的对象可以使用类中的变量和方法 案例分析 反序列化中的值可以覆盖原类中的值 我们创建一个对象,对象创建的时候触发了construct方…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

JAVA后端开发——多租户
数据隔离是多租户系统中的核心概念,确保一个租户(在这个系统中可能是一个公司或一个独立的客户)的数据对其他租户是不可见的。在 RuoYi 框架(您当前项目所使用的基础框架)中,这通常是通过在数据表中增加一个…...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...