Python之自然语言处理库snowNLP
一、介绍
SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob不同的是,这里没有用NLTK,所有的算法都是自己实现的,并且自带了一些训练好的字典。注意本程序都是处理的unicode编码,所以使用时请自行decode成unicode。
GitHub - isnowfy/snownlp: Python library for processing Chinese text
二、snowNLP操作详解
2.1 安装
pip install snownlp 2.2 功能详解
1)中文分词(Character-Based Generative Model)
# -*- coding:utf-8 -*-
import sys
from snownlp import SnowNLPtxt = u'''在文学的海洋中,有一部名为《薄雾》的小说,它犹如一颗闪耀的明珠,让人过目难忘。这部作品讲述了一段发生在上世纪初的跨越阶级的爱情故事。在这篇文学短评中,我们将探讨这部小说所展现的情感与人性,以及它在文学史上的地位。'''s = SnowNLP(txt)
print(s.words)

2)词性标注(TnT 3-gram 隐马)
# -*- coding:utf-8 -*-
import sys
from snownlp import SnowNLPtxt = u'''在文学的海洋中,有一部名为《薄雾》的小说,它犹如一颗闪耀的明珠,让人过目难忘。这部作品讲述了一段发生在上世纪初的跨越阶级的爱情故事。在这篇文学短评中,我们将探讨这部小说所展现的情感与人性,以及它在文学史上的地位。'''s = SnowNLP(txt)
for i in s.tags: print(i)

3)情感分析(朴素贝叶斯算法)
现在训练数据主要是买卖东西时的评价,所以对其他的一些可能效果不是很好。
情感分析的结果是一个0~1之间的数字,数字越大表示这句话越偏向于肯定的态度,数字越小表示越偏向于否定的态度。
# -*- coding:utf-8 -*-
import sys
from snownlp import SnowNLPtxt = u'''在文学的海洋中,有一部名为《薄雾》的小说,它犹如一颗闪耀的明珠,让人过目难忘。这部作品讲述了一段发生在上世纪初的跨越阶级的爱情故事。在这篇文学短评中,我们将探讨这部小说所展现的情感与人性,以及它在文学史上的地位。'''s = SnowNLP(txt)
print(s.sentiments)
4)文本分类(Naiv eBayes)
模型训练(若是想要利用新训练的模型进行情感分析,可修改 snownlp/seg/__init__.py 里的data_path指向刚训练好的文件)
#coding:UTF-8from snownlp import sentimentif __name__ == "__main__":# 重新训练模型sentiment.train('./neg.txt', './pos.txt')# 保存好新训练的模型sentiment.save('sentiment.marshal')5)转换成拼音(Trie树实现的最大匹配)
# -*- coding:utf-8 -*-
import sys
from snownlp import SnowNLPtxt = u'''在文学的海洋中,有一部名为《薄雾》的小说,它犹如一颗闪耀的明珠,让人过目难忘。这部作品讲述了一段发生在上世纪初的跨越阶级的爱情故事。在这篇文学短评中,我们将探讨这部小说所展现的情感与人性,以及它在文学史上的地位。'''s = SnowNLP(txt)
print(s.pinyin)

6)繁体转简体(Trie树实现的最大匹配)
# -*- coding:utf-8 -*-
import sys
from snownlp import SnowNLPtxt = u'''在文學的海洋中,有一部名為《薄霧》的小說,它猶如一顆閃耀的明珠,讓人過目難忘。 這部作品講述了一段發生在上世紀初的跨越階級的愛情故事。 在這篇文學短評中,我們將探討這部小說所展現的情感與人性,以及它在文學史上的地位。'''s = SnowNLP(txt)
print(s.han)

7)提取文本关键词(TextRank算法)
# -*- coding:utf-8 -*-
import sys
from snownlp import SnowNLPtxt = u'''在文学的海洋中,有一部名为《薄雾》的小说,它犹如一颗闪耀的明珠,让人过目难忘。这部作品讲述了一段发生在上世纪初的跨越阶级的爱情故事。在这篇文学短评中,我们将探讨这部小说所展现的情感与人性,以及它在文学史上的地位。'''s = SnowNLP(txt)
print(s.keywords(5))

8)提取文本摘要(TextRank算法)
# -*- coding:utf-8 -*-
import sys
from snownlp import SnowNLPtxt = u'''在文学的海洋中,有一部名为《薄雾》的小说,它犹如一颗闪耀的明珠,让人过目难忘。这部作品讲述了一段发生在上世纪初的跨越阶级的爱情故事。在这篇文学短评中,我们将探讨这部小说所展现的情感与人性,以及它在文学史上的地位。'''s = SnowNLP(txt)
print(s.summary(5))

10)Tokenization(分割成句子)
# -*- coding:utf-8 -*-
import sys
from snownlp import SnowNLPtxt = u'''在文学的海洋中,有一部名为《薄雾》的小说,它犹如一颗闪耀的明珠,让人过目难忘。这部作品讲述了一段发生在上世纪初的跨越阶级的爱情故事。在这篇文学短评中,我们将探讨这部小说所展现的情感与人性,以及它在文学史上的地位。'''s = SnowNLP(txt)
print(s.sentences)

9)tf(词频),idf(逆文档频率:可以用于tf-idf关键词提取)
# -*- coding:utf-8 -*-
import sys
from snownlp import SnowNLPs = SnowNLP([[u'这篇', u'文章'],[u'那篇', u'论文'],[u'这个']])print("tf:")
print(s.tf)
print("\n")print("idf:")
print(s.idf)

11)文本相似(BM25)
1. 文本的相似度是通过上面的tf和idf来计算的,这里给出的也是词的相似度分析。
# -*- coding:utf-8 -*-
import sys
from snownlp import SnowNLPs = SnowNLP([[u'这篇', u'文章'],[u'那篇', u'论文'],[u'这个']])print(s.sim([u'文章']))
2. 用 sklearn库的句子相似度的计算方法,计算 TF 矩阵中两个向量的相似度,实际上就是求解两个向量夹角的余弦值:点乘积除以二者的模长,公式如下
cosθ=a·b/|a|*|b|
from sklearn.feature_extraction.text import CountVectorizer
import numpy as np
from scipy.linalg import normdef tf_similarity(s1, s2):def add_space(s):return ' '.join(s)# 将字中间加入空格s1, s2 = add_space(s1), add_space(s2)# 转化为TF矩阵cv = CountVectorizer(tokenizer=lambda s: s.split())corpus = [s1, s2]vectors = cv.fit_transform(corpus).toarray()# 计算TF系数return np.dot(vectors[0], vectors[1]) / (norm(vectors[0]) * norm(vectors[1]))s1 = '我出生在中国'
s2 = '我生于中国'
print(tf_similarity(s1, s2)) # 结果:0.73029674334022142.3 情感分析源码解析
class Sentiment(object):def __init__(self):self.classifier = Bayes() # 使用的是Bayes的模型def save(self, fname, iszip=True):self.classifier.save(fname, iszip) # 保存最终的模型def load(self, fname=data_path, iszip=True):self.classifier.load(fname, iszip) # 加载贝叶斯模型# 分词以及去停用词的操作 def handle(self, doc):words = seg.seg(doc) # 分词words = normal.filter_stop(words) # 去停用词return words # 返回分词后的结果def train(self, neg_docs, pos_docs):data = []# 读入负样本for sent in neg_docs:data.append([self.handle(sent), 'neg'])# 读入正样本for sent in pos_docs:data.append([self.handle(sent), 'pos'])# 调用的是Bayes模型的训练方法self.classifier.train(data)def classify(self, sent):# 1、调用sentiment类中的handle方法# 2、调用Bayes类中的classify方法ret, prob = self.classifier.classify(self.handle(sent)) # 调用贝叶斯中的classify方法if ret == 'pos':return probreturn 1-probclass Sentiment(object):def __init__(self):self.classifier = Bayes() # 使用的是Bayes的模型def save(self, fname, iszip=True):self.classifier.save(fname, iszip) # 保存最终的模型def load(self, fname=data_path, iszip=True):self.classifier.load(fname, iszip) # 加载贝叶斯模型# 分词以及去停用词的操作 def handle(self, doc):words = seg.seg(doc) # 分词words = normal.filter_stop(words) # 去停用词return words # 返回分词后的结果def train(self, neg_docs, pos_docs):data = []# 读入负样本for sent in neg_docs:data.append([self.handle(sent), 'neg'])# 读入正样本for sent in pos_docs:data.append([self.handle(sent), 'pos'])# 调用的是Bayes模型的训练方法self.classifier.train(data)def classify(self, sent):# 1、调用sentiment类中的handle方法# 2、调用Bayes类中的classify方法ret, prob = self.classifier.classify(self.handle(sent)) # 调用贝叶斯中的classify方法if ret == 'pos':return probreturn 1-prob从上述的代码中,classify函数和train函数是两个核心的函数,其中,train函数用于训练一个情感分类器,classify函数用于预测。在这两个函数中,都同时使用到的handle函数,handle函数的主要工作为对输入文本分词和去停用词。
情感分类的基本模型是贝叶斯模型 Bayes,对于贝叶斯模型,这里就先介绍一下机器学习算法—朴素贝叶斯的公式,详细说明可查看 python版 朴素贝叶斯-基础 - 简书。对于有两个类别c1和c2的分类问题来说,其特征为w1,⋯,wn,特征之间是相互独立的,属于类别c1的贝叶斯模型的基本过程为:

其中:

相关文章:
Python之自然语言处理库snowNLP
一、介绍 SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库,并且和TextBlob不同的是&…...
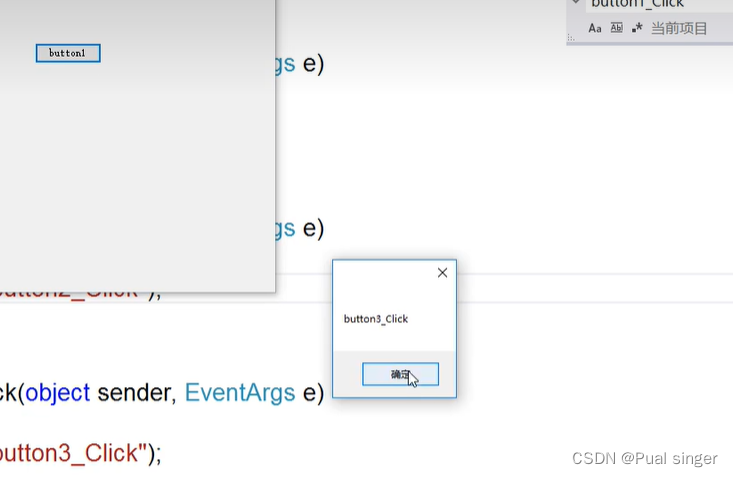
C# 语法进阶 委托
1.委托 委托是一个引用类型,其实他是一个类,保存方法的指针 (指针:保存一个变量的地址)他指向一个方法,当我们调用委托的时候这个方法就立即被执行 关键字:delegate 运行结果: 思…...
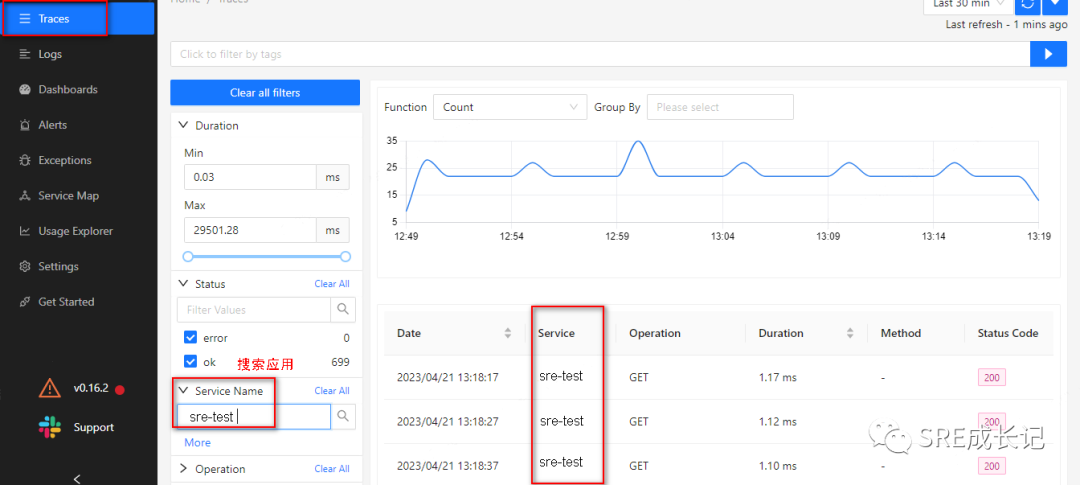
开源可观测性平台Signoz(四)【链路监控及数据库中间件监控篇】
转载说明:如果您喜欢这篇文章并打算转载它,请私信作者取得授权。感谢您喜爱本文,请文明转载,谢谢。 前文链接: 开源可观测性平台Signoz系列(一)【开篇】 开源可观测性平台Signoz&…...

【嵌入式开发 Linux 常用命令系列 4.2 -- git .gitignore 使用详细介绍】
文章目录 .gitignore 使用详细介绍.gitignore 文件的位置.gitignore 语法规则使用示例注意事项 .gitignore 使用详细介绍 .gitignore 文件是一个特殊的文本文件,它告诉 Git 哪些文件或目录是可以被忽略的,即不应该被纳入版本控制系统。这主要用于避免一…...

【熔断限流组件resilience4j和hystrix】
文章目录 🔊博主介绍🥤本文内容起因resilience4j落地实现pom.xml依赖application.yml配置接口使用 hystrix 落地实现pom.xml依赖启动类上添加注解接口上使用 📢文章总结📥博主目标 🔊博主介绍 🌟我是廖志伟…...
微服务雪崩问题及解决方案
雪崩问题 微服务中,服务间调用关系错综复杂,一个微服务往往依赖于多个其它微服务。 微服务之间相互调用,因为调用链中的一个服务故障,引起整个链路都无法访问的情况。 如果服务提供者A发生了故障,当前的应用的部分业务…...

008、所有权
所有权可以说是Rust中最为独特的一个功能了。正是所有权概念和相关工具的引入,Rust才能够在没有垃圾回收机制的前提下保障内存安全。 因此,正确地了解所有权概念及其在Rust中的实现方式,对于所有Rust开发者来讲都是十分重要的。在本文中&…...

千里马2023年终总结-android framework实战
背景: hi粉丝朋友们: 2023年马上就过去了,很多学员朋友也都希望马哥这边写个年终总结,因为这几个月时间都忙于新课程halsystracesurfaceflinger专题的开发,差点都忘记了这个事情了,今天特别花时间来写个bl…...

vue3中pinia的使用及持久化(详细解释)
解释一下pinia: Pinia是一个基于Vue3的状态管理库,它提供了类似Vuex的功能,但是更加轻量化和简单易用。Pinia的核心思想是将所有状态存储在单个store中,并且将store的行为和数据暴露为可响应的API,从而实现数据&#…...

安装 yarn、pnpm、功能比较
安装 yarn 官网:https://classic.yarnpkg.com/ 快速、可靠和安全的依赖性管理。 Yarn是您代码的软件包管理器。它允许您使用和共享(例如JavaScript)与来自世界各地的其他开发人员一起编写代码。Yarn是一个新的快速安全可信赖的可以替代 NP…...

计算机专业个人简历范文(8篇)
HR浏览一份简历也就25秒左右,如果你连「好简历」都没有,怎么能找到好工作呢? 如果你不懂得如何在简历上展示自己,或者觉得怎么改简历都不出彩,那请你一定仔细读完。 互联网运营个人简历范文> 男 22 本科 AI简历…...

几个实用网站
论文短语:https://www.phrasebank.manchester.ac.uk/ 翻译:https://www.deepl.com/en/translator 润色:https://quillbot.com/ 榜单:www.paperwithcode.com ****NLP民工的乐园: 几乎最全的中文NLP资源库:****https…...

Pycharm 切换interpreter---python的环境和第三方库问题
这篇回答两个问题: 1.为什么在 pycharm中打开新的project,切换interpreter 之后发现自己之前装的库消失了? 2.为什么 interpreter 切换到python3.8了, terminal 还是在 3.9?? 问题的关键:搞懂什…...

TP-LINK 路由器忘记密码 - 恢复出厂设置
TP-LINK 路由器忘记密码 - 恢复出厂设置 1. 恢复出厂设置2. 创建管理员密码3. 上网设置4. 无线设置5. TP-LINK ID6. 网络状态References 1. 恢复出厂设置 在设备通电的情况下,按住路由器背面的 Reset 按钮直到所有指示灯同时亮起后松开。 2. 创建管理员密码 3. 上网…...

关闭 Elasticsearch 集群的安全性设置
关闭 Elasticsearch 集群的安全性设置,特别是如果您正在使用 X-Pack,涉及到修改 Elasticsearch 的配置。以下是一般步骤,但请注意,这可能会使您的 Elasticsearch 集群面临安全风险,因此建议仅在开发或测试环境中执行此…...
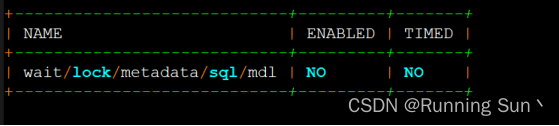
[技术分享]一招解决 MySQL 中 DDL 被阻塞的问题
爱可生开源社区. 爱可生开源社区,提供稳定的MySQL企业级开源工具及服务,每年1024开源一款优良组件,并持续运营维护。 背景 之前碰到客户咨询定位DDL阻塞的相关问题,整理了一下方法,如何解决DDL被阻塞的问题。下面,就这个问题,整理了一下思路: 怎么判断一个 DDL 是…...
Windows搭建Emby媒体库服务器,无公网IP远程访问本地影音文件
文章目录 1.前言2. Emby网站搭建2.1. Emby下载和安装2.2 Emby网页测试 3. 本地网页发布3.1 注册并安装cpolar内网穿透3.2 Cpolar云端设置3.3 Cpolar内网穿透本地设置 4.公网访问测试5.结语 1.前言 在现代五花八门的网络应用场景中,观看视频绝对是主力应用场景之一&…...
自动化测试系列 之 Python单元测试框架unittest
一、概述 什么是单元测试 单元测试是一种软件测试方法,是测试最小的可测试单元,通常是一个函数或一个方法。 在软件开发过程中,单元测试作为一项重要的测试方法被广泛应用。 为什么需要单元测试 单元测试是软件开发中重要的一环…...

C语言朴素算法
#include <stdio.h> #include <string.h>// 朴素算法,用于字符串匹配 void naiveMatch(char* text, char* pattern) {int textLength strlen(text); // 计算文本串长度int patternLength strlen(pattern); // 计算模式串长度for …...

【力扣题解】P501-二叉搜索树中的众数-Java题解
👨💻博客主页:花无缺 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 本文由 花无缺 原创 收录于专栏 【力扣题解】 文章目录 【力扣题解】P501-二叉搜索树中的众数-Java题解🌏题目描述💡题解…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...