NLP基础——中文分词
简介
分词是自然语言处理(NLP)中的一个基本任务,它涉及将连续的文本序列切分成多个有意义的单元,这些单元通常被称为“词”或“tokens”。在英语等使用空格作为自然分隔符的语言中,分词相对简单,因为大部分情况下只需要根据空格和标点符号来切分文本。
然而,在汉语等语言中,并没有明显的单词界限标记(如空格),因此汉语分词比较复杂。汉字序列必须被正确地切割成有意义的词组合。例如,“我爱北京天安门”,应该被正确地划分为“我/爱/北京/天安门”。
方法
中文分词技术主要可以归类为以下几种方法:
-
基于字符串匹配的方法:这种方法依赖一个预先定义好的字典来匹配和确定句子中最长能够匹配上的字符串。这包括正向最大匹配法、逆向最大匹配法以及双向最大匹配法。
-
基于理解的方法:通过模拟人类理解句子含义进行分词,考虑上下文、句法结构和其他信息。
-
基于统计学习模型:利用机器学习算法从大量已经人工标注好了分词结果的数据集里学习如何进行有效地分词。常见算法包括隐马尔可夫模型(HMM)、条件随机场(CRF)以及近年来流行起来基于深度学习框架构建神经网络模型(RNNs、CNNs、LSTMs、Transformer、BERT等)。
-
混合方法:结合以上几种不同策略以提高精确度和鲁棒性。
-
基于规则: 通过制定一系列规则手动或半自动地进行文字断开, 这通常需要专业知识并且效率不高, 但可以在特定情境下发挥作用。
Python栗子
基于字符串匹配,最大前向匹配,代码如下
def max_match_segmentation(text, dictionary):max_word_length = max(len(word) for word in dictionary)start = 0segmentation = []while start < len(text):for length in range(max_word_length, 0, -1):if length > len(text) - start:continueword = text[start:start + length]if word in dictionary:segmentation.append(word)start += lengthbreakelse: # 如果没有找到,则按单字切分segmentation.append(text[start])start += 1return segmentation# 示例字典和用法:
dictionary = {"我", "爱", "北京", "天安门"}
text_to_segment = "我爱北京天安门"segments = max_match_segmentation(text_to_segment, dictionary)print("分词结果:", "/ ".join(segments))构建思路(如何实现基于统计的分词方法)
基于统计学习的中文分词方法其核心思想是从大量已经分词的文本(语料库)中学习如何将连续的汉字序列切分成有意义的词汇。通常包括以下几个步骤:
-
语料库准备:收集并整理一定量的已经进行过人工分词处理的文本数据,作为训练集。
-
特征提取:从训练数据中提取有助于模型学习和预测的特征。在传统统计模型中,这些特征可能包括:
- 字符及其邻近字符
- 词性标注信息
- 字符组合频率
-
概率模型选择:选择合适的统计概率模型来估算不同切分方式出现的概率。常见模型包括:
- 隐马尔可夫模型(HMM)
- 条件随机场(CRF)
- 最大熵模型
- 支持向量机(SVM)
-
参数估计与训练:利用选定的统计学习算法对特征和标签进行建模,并通过算法调整参数以最大化某种性能指标或者最小化误差。
-
解码与优化:使用如Viterbi算法等解码技术找到给定字序列下最可能对应的词序列。
-
评估与调整:通过交叉验证、留出验证或引入开发集等方式,在非训练数据上评价分词效果,并据此调整特征或者优化参数。
-
迭代改进: 在实际应用过程中,根据反馈持续追踪新出现单字、新兴流行语等元素,更新语料库并重新训练以保证系统性能不断提升。
基于统计学习方法进行中文分词具有较强实用性和广泛适用性。它不依赖复杂规则体系,而是通过从数据本身“学会”如何正确地将句子划分为单个单词或短语。
分词参考链接
- tokenizer https://huggingface.co/docs/tokenizers
- 微型中文分词器 https://github.com/howl-anderson/MicroTokenizer
- 中文分词jieba https://github.com/fxsjy/jieba
- THULAC:一个高效的中文词法分析工具包https://github.com/thunlp/THULAC-Python
相关文章:

NLP基础——中文分词
简介 分词是自然语言处理(NLP)中的一个基本任务,它涉及将连续的文本序列切分成多个有意义的单元,这些单元通常被称为“词”或“tokens”。在英语等使用空格作为自然分隔符的语言中,分词相对简单,因为大部分…...

阿里云服务器Alibaba Cloud Linux 3镜像版本大全说明
Alibaba Cloud Linux阿里云打造的Linux服务器操作系统发行版,Alibaba Cloud Linux完全兼容完全兼容CentOS/RHEL生态和操作方式,目前已经推出Alibaba Cloud Linux 3,阿里云百科aliyunbaike.com分享Alibaba Cloud Linux 3版本特性说明ÿ…...

WebGIS开发的常见框架及优缺点
WebGIS开发引擎的发展历程: 内容来自公众号:Spatial Data 地图API分类 WebGIS系统通常都围绕地图进行内容表达,但并不是有地图就一定是WebGIS,所以下面要讨论下基于Web的地图API分类及应用场景。Web上的Map API主要分类ÿ…...
ansible 配置jspgou商城上线(MySQL版)
准备环境 准备两台纯净的服务器进行,在实验之前我们关闭防火墙和selinux systemctl stop firewalld #关闭防火墙 setenforce 0 #临时关闭selinux hosts解析(两台服务器都要去做) [rootansible-server ~]# vim /etc/hosts 10.31.162.24 ansible-ser…...
算法导论复习——CHP22 分支限界法
LIFO和FIFO分枝-限界法 采用宽度优先策略,在生成当前E-结点全部儿子之后再生成其它活结点的儿子,且用限界函数帮助避免生成不包含答案结点子树的状态空间的检索方法。两种基本设计策略: FIFO检索:活结点表采用队列&#x…...

鸿蒙系列--装饰器
一、基础UI组件结构 每个UI组件需要定义为Component struct对象,其内部必须包含一个且只能包含一个build(){}函数,用于绘制UI;struct之内、build()函数之外的地方用于存放数据。 二、基本UI装饰器 Entry 装饰struct,页面的入口…...

FairGuard游戏加固产品常见问题解答
针对日常对接中,各位用户对FairGuard游戏加固方案在安全性、稳定性、易用性、接入流程等方面的关注,我们梳理了相关问题与解答,希望可以让您对产品有一个初步的认知与认可。 Q1:FairGuard游戏加固产品都有哪些功能? A:FairGuar…...

Redis(二)数据类型
文章目录 官网备注十大数据类型StringListHashSetZSetBitmapHyperLogLog:GEOStreamBitfield 官网 英文:https://redis.io/commands/ 中文:http://www.redis.cn/commands.html 备注 命令不区分大小写,key区分大小写帮助命令help…...
)
2023年广东省网络安全B模块(笔记详解)
模块B 网络安全事件响应、数字取证调查和应用安全 一、项目和任务描述: 假定你是某网络安全技术支持团队成员,某企业的服务器系统被黑客攻击,你的团队前来帮助企业进行调查并追踪本次网络攻击的源头,分析黑客的攻击方式,发现系统漏洞,提交网络安全事件响应报告,修复系统…...
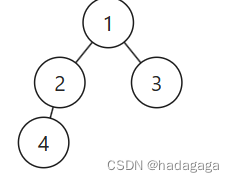
每日力扣算法题(简单篇)
543.二叉树的直径 原题: 给你一棵二叉树的根节点,返回该树的 直径 。 二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根节点 root 。 两节点之间路径的 长度 由它们之间边数表示。 解题思路: …...
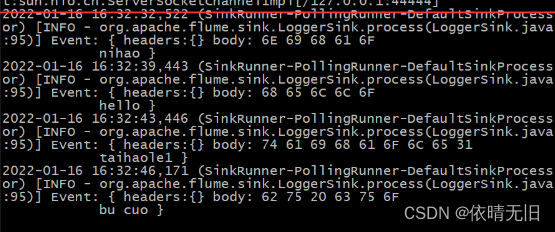
Flume基础知识(三):Flume 实战监控端口数据官方案例
1. 监控端口数据官方案例 1)案例需求: 使用 Flume 监听一个端口,收集该端口数据,并打印到控制台。 2)需求分析: 3)实现步骤: (1)安装 netcat 工具 sudo yum …...

通过IP地址如何进行网络安全防护
IP地址在网络安全防护中起着至关重要的作用,可以用于监控、过滤和控制网络流量,识别潜在威胁并加强网络安全。以下是通过IP地址进行网络安全防护的一些建议: 1. 建立IP地址白名单和黑名单: 白名单:确保只有授权的IP地…...

Vue.js 中使用 Watch 选项实现动态问题判断与展示答案
组件结构 以下是组件的基本结构: <template><div><!-- 输入框,用于输入问题 --><p>提出一个是/否问题:<input v-model"question" :disabled"loading" /></p><!-- 显示答案 --&…...

python笔记-自用
2024/1/3# python用号实现字符串的拼接,非字符串不能拼接 from pymysql import Connection# 连接mysql数据库salary 100 name "wang"ans "%s" % salary name print(ans)x 1 y 2 sum "%s %s" % (x, y) print(sum)# %s字符串占…...

安克创新与火山引擎数智平台开展合作:数据分析降门槛 数据协同破边界
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群 近日,消费电子品牌安克创新与火山引擎数智平台(VeDI)达成合作,双方将聚焦安克创新大数据平台的海量数据分析场景&…...
LDD学习笔记 -- Linux内核模块
LDD学习笔记 -- 内核模块 简介LKM类型Static Linux Kernel ModuleDynamic Linux Kernel ModuleLKM编写语法 syntax详细描述内核头文件用户空间头文件Module Initialization FunctionModule Cleanup FunctionKeyword & Tag宏 __init __exitLKM入口注册Module Metadate&#…...
springboot整合springbatch批处理
springboot整合springbatch实现批处理 简介项目搭建步骤 简介 项目搭建 参考博客【场景实战】Spring Boot Spring Batch 实现批处理任务,保姆级教程 步骤 1.建表 建表sql CREATE TABLE student (id int NOT NULL AUTO_INCREMENT,name varchar(100) NOT NULL C…...

答案解析——C语言—第2次作业:转义字符
本次作业的链接如下:C语言—第2次作业:转义字符 1.下面哪个不是C语言内置的数据类型: C char //字符数据类型short //短整型int //整形long //长整型long long //更长的整形float //单精度浮点数double //双精度浮点数 …...

HTML5-新增表单input属性
新增表单属性 form控件主要新增的属性: autocomplete 是否启用表单的自动完成功能,取值:on(默认)、off novalidate 提交表单时不进行校验,默认会进行表单校验 autocomplete属性 概念:autocomplete属性…...

css-、串联选择器和后代选择器的用法
& &表示嵌套的上一级,这是sass的语法,代表上一级选择器 .btn {&.primary {background-color: #007bff;color: #fff;} } 编译出来的结果是同一个元素,有两个类名,两个类名之间没有空格: .btn.primary {…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

如何为服务器生成TLS证书
TLS(Transport Layer Security)证书是确保网络通信安全的重要手段,它通过加密技术保护传输的数据不被窃听和篡改。在服务器上配置TLS证书,可以使用户通过HTTPS协议安全地访问您的网站。本文将详细介绍如何在服务器上生成一个TLS证…...

零基础在实践中学习网络安全-皮卡丘靶场(第九期-Unsafe Fileupload模块)(yakit方式)
本期内容并不是很难,相信大家会学的很愉快,当然对于有后端基础的朋友来说,本期内容更加容易了解,当然没有基础的也别担心,本期内容会详细解释有关内容 本期用到的软件:yakit(因为经过之前好多期…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...
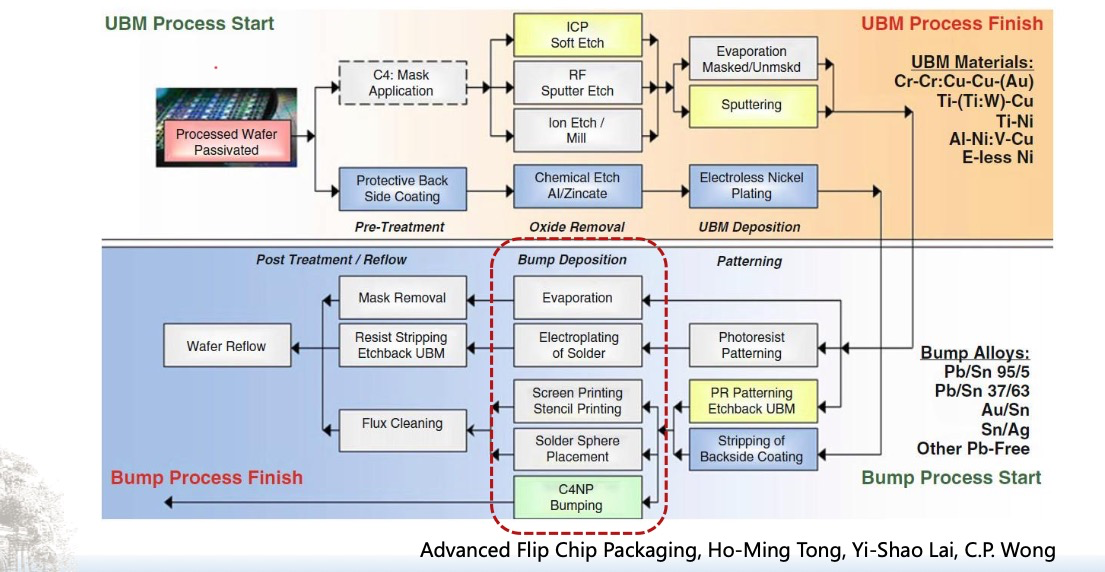
倒装芯片凸点成型工艺
UBM(Under Bump Metallization)与Bump(焊球)形成工艺流程。我们可以将整张流程图分为三大阶段来理解: 🔧 一、UBM(Under Bump Metallization)工艺流程(黄色区域ÿ…...

C++--string的模拟实现
一,引言 string的模拟实现是只对string对象中给的主要功能经行模拟实现,其目的是加强对string的底层了解,以便于在以后的学习或者工作中更加熟练的使用string。本文中的代码仅供参考并不唯一。 二,默认成员函数 string主要有三个成员变量,…...

安宝特方案丨从依赖经验到数据驱动:AR套件重构特种装备装配与质检全流程
在高压电气装备、军工装备、石油测井仪器装备、计算存储服务器和机柜、核磁医疗装备、大型发动机组等特种装备生产型企业,其产品具有“小批量、多品种、人工装配、价值高”的特点。 生产管理中存在传统SOP文件内容缺失、SOP更新不及、装配严重依赖个人经验、产品装…...