知识库问答LangChain+LLM的二次开发:商用时的典型问题及其改进方案
前言
如之前的文章所述,我司下半年成立大模型项目团队之后,我虽兼管整个项目团队,但为让项目的推进效率更高,故分成了三大项目组
- 第一项目组由霍哥带头负责类似AIGC模特生成系统
- 第二项目组由阿荀带头负责论文审稿GPT以及AI agent项目
- 第三项目组由朝阳带头负责企业多文档的知识库问答系统,朝阳、bingo、猫药师等人贡献了本文的至少一半
对于知识库问答,现在有两种方案,一种基于llamaindex,一种基于langchain +LLM
- 对于前者,我近期会另外写一篇文章
- 对于后者,考虑到我已在此文《基于LangChain+LLM的本地知识库问答:从企业单文档问答到批量文档问答》中详细介绍了langchain、以及langchain-ChatGLM项目的源码剖析
如下图所示,整个系统流程是很清晰的,但涉及的点颇多,所以决定最终效果的关键点包括且不限于:文本分割算法、embedding、向量的存储 搜索 匹配 召回 排序、大模型本身的生成能力
本文重点则阐述“如何通过基于langchain-chatchat二次开发一个知识库问答系统”,包括其商用时的典型问题以及对应的改进方案,比如
1 如何解决检索出错:embedding算法是关键之一
2 如何解决检索到相关但不根据知识库回答而是根据模型自有的预训练知识回答
3 如何针对结构化文档采取更好的chunk分割:基于规则
4 如何解决非结构化文档分割不够准确的问题:比如最好按照语义切分
5 如何确保召回结果的全面性与准确性:多路召回与最后的去重/精排
6 如何解决基于文档中表格的问答
最后强调一下,本文及后续相关的文章(比如embedding、文本语义分割、llamaindex等)更多是入门/梳理,其中的细节/深入,以及更多问题的解决暂在我司的「大模型项目开发线上营」里见
前置部分 知识库的构建:基于langchain-chatchat的V0.2.6版本(chatglm2+m3e)
将七月近两年整理的大厂面试题PDF文件作为源文件来进行知识库的构建
默认使用RapidOCRPDFLoader作为文档加载器
RapidOCR是目前已知运行速度最快、支持最广,完全开源免费并支持离线快速部署的多平台多语言OCR。由于PaddleOCR工程化不是太好,RapidOCR为了方便大家在各种端上进行OCR推理,将PaddleOCR中的模型转换为ONNX格式,使用Python/C++/Java/Swift/C# 将它移植到各个平台
更多详情参考:https://rapidai.github.io/RapidOCRDocs/docs/overview/
另,本文里的测试及二次开发主要针对langchain-chatchat的V0.2.6版本,资源及相关默认配置如下:
- 显卡:Tesla P100,16G(显存)
- 分词器:ChineseRecursiveTextSplitter
- chunk_size:250 (顺带说一下,250是默认分块大小,但该系统也有个可选项,可以选择达摩院开源的语义分割模型:nlp_bert_document-segmentation_chinese-base )
- embedding模型:m3e-base
- LLM模型:chatglm2-6b (默认为该模型,但下文会有些结果来自chatglm3)
- 向量库:faiss
第一部分 如何解决检索的问题:比如检索出错等
1.1 如何解决检索出错:embedding算法是关键之一
1.1.1 针对「Bert的预训练过程是什么?」检索出的结果与问题不相关
使用原始的langchain-chatchat V0.2.6版本,会出现对某些问题检索不到的情况
比如问一个面试题:Bert的预训练过程是什么?
- 其在文档中的结果如下:

- 但实际检索得到的内容如下:
可以看出,是没有检索到相关内容的出处 [1] 2021Q2大厂面试题共121题(含答案及解析).pdf
成. 15.6 bert 的改进版有哪些 参考答案: RoBERTa:更强大的 BERT 加大训练数据 16GB -> 160GB,更大的batch size,训练时间加长 不需要 NSP Loss: natural inference 使用更长的训练 SequenceStatic vs. Dynamic Masking 模型训练成本在 6 万美金以上(估算) ALBERT:参数更少的 BERT一个轻量级的 BERT 模型 共享层与层之间的参数 (减少模型参数)
出处 [2] 2022Q1大厂面试题共65题(含答案及解析).pdf
可以从预训练方法角度解答。
… 20
5、RoBERTa 相比 BERT 有哪些改进?
…
20 6、BERT 的输入有哪几种 Embedding?
出处 [3] 2022Q2大厂面试题共92题(含答案及解析).pdf
保证模型的训练,pre-norm 显然更好一些。 5、GPT 与 Bert 的区别 1) GPT
是单向模型,无法利用上下文信息,只能利用上文;而 BERT 是双向模型。 2) GPT 是基于自回归模型,可以应用在 NLU 和 NLG两大任务,而原生的 BERT 采用的基于自编码模 型,只能完成 NLU 任务,无法直接应用在文本生成上面。 6、如何加速 Bert模型的训练 BERT 基线模型的训练使用 Adam with weight decay(Adam 优化器的变体)作为优化器,LAMB 是一款通用优化器,它适用于小批量和大批量,且除了学习率以外其他超参数均无需调整。LAMB 优化器支持自 -
在没检索对的情况下,接下来,大模型便只能根据自己的知识去回答(下图左侧是chatglm2-6b的回答,下图右侧是chatglm3-6b的回答)


1.1.2 可能的原因分析与优化方法
使用默认配置时,虽然上传文档可以实现基础的问答,但效果并不是最好的,通常需要考虑以下几点原因
- 文件解析及预处理:对于PDF文件,可能出现解析不准确的情况,导致检索召回率低;
- 文件切分:不同的chunk_size切分出来的粒度不一样。如果设置的粒度太小,会出现信息丢失的情况;如果设置的粒度太大,又可能会造成噪声太多,导致模型输出的结果明显错误。且单纯根据chunk_size切分比较简单粗暴,需要根据数据进行针对性优化;
- embedding 模型效果:embedding效果不好也会影响检索结果
优化方法:
- 文件解析及预处理
一方面可以尝试不同的PDF解析工具,解析更加准确
另一方面可以考虑将解析后的内容加上标题,并保存成Markdown格式,这样可以提高召回率 - 文件切分
基于策略:对于特定的文档,比如有标题的,可以优先根据标题和对应内容进行划分(就是按照题目和对应答案切分成一个块),再考虑chunk_size
基于语义分割模型:还可以考虑使用语义分割模型 - 模型效果
尝试使用更多embedding模型,获得更精确的检索结果。如:piccolo-large-zh 或 bge-large-zh-v1.5等等,下文很快阐述 - 向量库
如果知识库比较庞大(文档数量多或文件较大),推荐使用pg向量数据库
如果文件中存在较多相似的内容,可以考虑分门别类存放数据,减少文件中冲突的内容 - 多路召回
结合传统方法进行多路召回 - 精排
对多路召回得到的结果进行精排
1.2 如何根据业务场景确定最合适的embedding算法
暂见此文:一文通透Text Embedding模型:从text2vec、openai-ada-002到m3e、bge
第二部分 如何解决检索到相关但不根据相关结果回答
2.1 开源LLM并没有完全根据文档内容来回答,而是根据模型自有的预训练知识回答
LLM问题主要有以下几点:
- LLM的回答会出现遗漏信息或补充多余信息的情况
- chatglm2-6b还会出现回答明显错误的情况
2.1.1 针对「用通俗的语言介绍下强化学习?」检索到部分相关
比如问一个面试题:用通俗的语言介绍下强化学习?
- 该问题在文档中的结果如下:

- 检索得到的内容如下:
可以看出出处 [1] 2022Q2大厂面试题共92题(含答案及解析).pdf
CART 树算法的核心是在生成过程中用基尼指数来选择特征。 4、用通俗的语言介绍下强化学习(Reinforcement Learning)监督学习的特点是有一个“老师”来“监督”我们,告诉我们正确的结果是什么。在我们在小的时候,会有老师来教我们,本质上监督学习是一种知识的传递,但不能发现新的知识。对于人类整体而言,真正(甚至唯一)的知识来源是实践——也就是强化学习。比如神农尝百草,最早人类并不知道哪些草能治病,但是通 过尝试,就能学到新的知识。学习与决策者被称为智能体,与智能体交互的部分则称为环境。智能体与环境不断进行交互,具体而言,这一交互的过程可以看做是多个时刻,每一时刻,智能体根据环境的状态,依据一定的策略选择一个动作(这
出处 [2] 2021Q3大厂面试题共107题(含答案及解析).pdf
20.2 集成学习的方式,随机森林讲一下,boost 讲一下, XGBOOST 是怎么回事讲一下。 集成学习的方式主要有 bagging,boosting,stacking 等,随机森林主要是采用了 bagging 的思想,通过自助法(bootstrap)重采样技术,从原始训练样本集 N 中有放回地重复随机抽取 n 个样本生成新的训练样本集合训练决策树,然后按以上步骤生成 m 棵决策树组成随机森林,新数据的分类结果按分类树 投票多少形成的分数而定。 boosting是分步学习每个弱分类器,最终的强分类器由分步产生的分类器组合而成,根据每步学习到的分类器去改变各个样本的权重(被错分的样本权重加大,反之减小) 它是一种基于 boosting增强策略的加法模型,训练的时候采用前向分布算法进行贪婪的学习,每次迭代
出处 [3] 2022Q2大厂面试题共92题(含答案及解析).pdf
特征工程可以并行开发,大大加快开发的速度。 训练速度较快。分类的时候,计算量仅仅只和特征的数目相关。 缺点:准确率欠佳。因为形式非常的简单,而现实中的数据非常复杂,因此,很难达到很高的准确性。很难处理 数据不平衡的问题。 3、介绍下决策树算法常见的决策树算法有三种:ID3、C4.5、CART 树 ID3 算法的核心是在决策树的每个节点上应用信息增益准则选择特征,递归地构架决策树。C4.5 算法的核心是在生成过程中用信息增益比来选择特征。 CART 树算法的核心是在生成过程中用基尼指数来选择特征。4、用通俗的语言介绍下强化学习(Reinforcement Learning)
第一个检索结果和问题是相关的
第二个检索结果和问题是完全没关系的
而第三个检索结果的最后一句话是和问题相关的 - 最终,chatglm2基于知识库给的答案如下:
可以看出,LLM并没有完全根据文档内容来回答,而是基于自己的知识进行了相应回答,而对于回答的第三段话,强化学习算法主要有三种:ID3、C4.5和CART树。可以看出,这段话的表达是完全错误的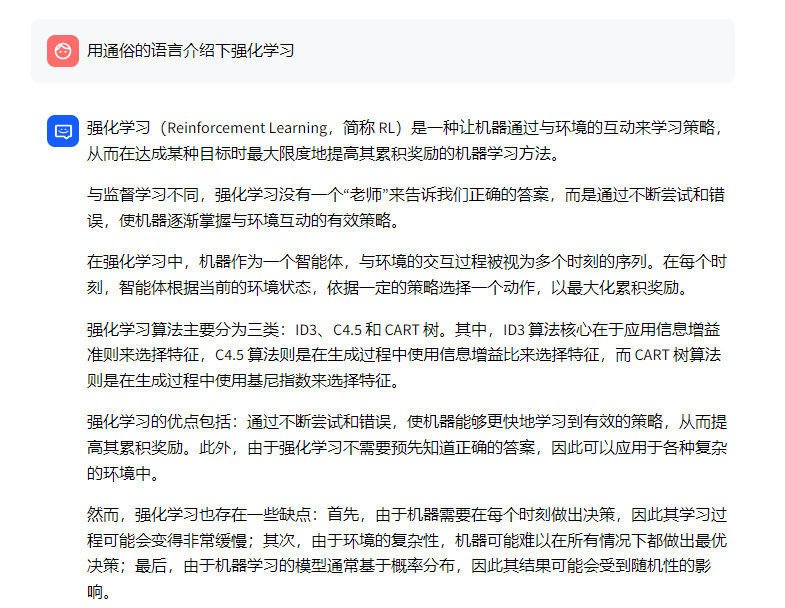
2.1.2 针对「生成式模型和判别式模型的区别并举一些例子」检索到的全是相关的
再看一个例子,即提问:生成式模型和判别式模型的区别并举一些例子
- 其在文档(知识库)中的答案如下

- 系统检索到的结果如下,很明显,三个检索结果都精准匹配到了问题

- 但,系统最终实际生成的答案如下(下图左侧是chatglm2-6b,下图右侧是chatglm3-6b)


相当于即便在上步骤中,系统检索到的三个结果的内容都是和问题相关的,但大模型还是根据自己的知识进行了回答
2.2 LLM不按照知识库回答的优化方法
- 优先使用最新的6B/7B模型:ChatGLM3-6B、Baichuan2-7B、Qwen-7B
当然,即便有的模型换成到了能力更强的最新版,也不一定听话(依然不严格按照知识库中的回答),例如“2.1.1 针对「用通俗的语言介绍下强化学习?」”中,把chatglm2替换成最新的chatglm3,也未完全严格按照文档中的答案来回答(但GLM3这个结果相比GLM2的结果 至少是进步了,没有出现毫不相干的决策树之类的内容)
所以,如果资源可以支持48G以上的显卡,可以考虑使用Qwen-14B-Chat 或 Baichuan-13B-Chat,13B的模型通常好于6B/7B模型
- 优化prompt,可能会有一定效果的。但由于随机性,结果并不能得到保证
- PDF文档解析优化方案,下文详述
第三部分 结构化文档与非结构化文档的典型问题:如何更好分割
3.1 如何针对结构化文档采取更好的chunk分割:基于规则
3.1.1 先解析PDF,然后分别获取文本内容和图片内容,最后拼接文本内容和图片内容
Langchian-Chatchat中对于不同类型的文件提供了不同的处理方式,从项目server/knoledge_base/utils.py文件中可以看到对于不同类型文件的加载方式,大体有HTML,Markdown,json,PDF,图片及其他类型等
LOADER_DICT = {"UnstructuredHTMLLoader": ['.html'],"UnstructuredMarkdownLoader": ['.md'],"CustomJSONLoader": [".json"],"CSVLoader": [".csv"],# "FilteredCSVLoader": [".csv"], # 需要自己指定,目前还没有支持"RapidOCRPDFLoader": [".pdf"],"RapidOCRLoader": ['.png', '.jpg', '.jpeg', '.bmp'],"UnstructuredFileLoader": ['.eml', '.msg', '.rst','.rtf', '.txt', '.xml','.docx', '.epub', '.odt','.ppt', '.pptx', '.tsv'],}这里,我们重点关注PDF文件的解析方式,并探究其可能的优化方案
从上面的文件加载字典中可以看出,PDF文件使用的加载器为RapidOCRPDFLoader,该文件的方法在项目document_loaders/mypdfloader.py中
处理方法:
- 首先使用fitz(即pyMuPDF)的open方法解析PDF文件;
- 对于每一页的文本内容,通过get_text方法进行获取,而对于图片内容通过get_images方法进行获取,获取后通过RapidOCR对图片中的文本内容进行提取;
- 最后将从图片中提取的文本和原始的文本内容进行拼接,得到最终的所有文本内容。然后进行下一步的分词和文本切割。
这种方式的优点简单粗暴,基本上对于任何排版的PDF文件都能够提取到有效信息。但缺点也很明显,就是无差别,比如我们的文档本身就有较好结构,提取出来的内容也无法将结构反映出来。所以,通常情况下需要根据文档的具体情况对解析后的文档做进一步定制化处理
3.1.2 针对结构化文档本身的特点:针对性分割
3.1.2.1 七月在线大厂面试题PDF文档特点
以七月在线大厂面试题PDF文档为例,有以下特点:
- 文档具有书签,可以直接根据书签对应到具体的页码
- 文档结构不复杂,共有两级标题,一级标题表示一个大的章节,二级标题表示面试题的问题,文本内容为每道面试题对应的答案;
- 每道面试题是独立的,和其前后的面试题并没有明显的相关性。
- 面试题题目的长度长短不一,短的有几个词组成,长的基本一句话
- 文档中除中文外,还有大量模型或算法英文词,且文档中包含部分公式和代码
因此,可以考虑根据文档的标题进行分割,即将文档中的标题和标题对应的内容分为一块,在放入向量库的时候可以尝试两种方式
- 一种是只将题目进行向量化表示存入向量库
- 另一种是将题目和答案一起进行向量化表示存入向量库
3.1.2.2 PDF文档解析可选方案
对此,尝试了几种PDF解析工具包:pdfplumber、PyPDF2、fitz(PyMuPDF)
- 通过fitz获取书签信息,得到面试题题目与其所在的页码,保存为一个字典;
- 尝试用pdfplumber、PyPDF2、fitz抽取每一页的文本信息,与字典中的标题进行匹配(使用find方法)
- 通过面试题当前位置和下一个面试题位置(这里的位置指的是索引),对面试题进行分块;
- 最后,输出面试题与其对应的答案
3.1.2.3 PDF文档解析存在问题
文档解析过程中存在的问题:
- 书签中的标题内容和文档中的标题内容并不完全一致,这种情况可能是解析后出现多余的空格导致的
- 需要考虑一道面试题可能存在跨页的情况,一般是会出现一道面试题出现在两页的情况,但也需要考虑一道面试跨三页或多页的情况
- 由于一级标题是有分页符的,每个一级标题会另起一页,因此在处理时也需要考虑此种情况。
- 解析的文本中带有页脚,如:第 4 页 共 46 页,由于页脚的内容对面试题是没有意义的,因此也需要考虑去掉
3.1.2.4 PDF文档解析解决方案
解决方案:
- 对于书签中的标题内容和文档中的标题内容并不完全一致的问题
一种方式有考虑去除文档中标题的空格,实现困难在于无法精确定位,如果全去掉就会出现一些英文单词拼接在一块的情况,可能对语义或后续的检索产生影响
- 对于一道面试题可能存在跨页的情况,可以通过设置起始页和终止页,对相邻标题(主要是下一个标题)所在页进行判断的方式来处理;
- 对于每个一级标题会另起一页的情况,可以通过添加对特殊字符“1、”判断的方式来处理;
- 对于页脚,可以使用正则表达式进行匹配去除
3.1.2.5 结果分析
测试效果:
以2022Q2大厂面试题共92题(含答案及解析).pdf文件为例,共92道面试题,匹配不到的数量
- pdfplumber:30
- PyPDF2:20(解析过程中,英文词之间的空格会消失,如selfattention)
- fitz:35
这个结果说明,即便根据文档的标题进行分割(将文档中的标题和标题对应的内容分为一块),最终匹配率也不算高,因为92个问题,各个解析器下来,依然都20 30多个匹配不到,但如果不按照标题分割的话,就会出现那种比如一段文本中只有部分内容而不完整的情况
接下来,咱们来看下语义分割的方案
3.2 如何解决非结构化文档分割不够准确的问题:比如最好按照语义切分
// 待更
第四部分 让召回结果更全面、准确,及基于表格的问答
4.1 如何确保召回结果的全面性与准确性:多路召回与最后的去重/精排
// 待更
4.2 如何解决基于文档中表格的问答
// 待更
参考文献与推荐阅读
- 基于Langchain-Chatchat的知识库问答系统
- ..
相关文章:
知识库问答LangChain+LLM的二次开发:商用时的典型问题及其改进方案
前言 如之前的文章所述,我司下半年成立大模型项目团队之后,我虽兼管整个项目团队,但为让项目的推进效率更高,故分成了三大项目组 第一项目组由霍哥带头负责类似AIGC模特生成系统第二项目组由阿荀带头负责论文审稿GPT以及AI agen…...

Mac内心os:在下只是个工具,指望我干人事?
呜呜呜,今天去医院看病了,乌央央的好多人。最近在研究苹果开发者工具中的HealthKit,等我研究透给大家安利。今天还是继续闲聊吧😂😂提前感谢大家体谅我这个病号,发射小红心,biubiubiu~ 据说&am…...

2024年最新远程控制软件
远程控制软件是一种技术工具,允许用户通过互联网远程控制他人的计算机。该软件通常用于公司或个人远程管理其他计算机的功能。它们允许用户远程操作他人电脑上的程序、文件或网页,或查看目标计算机的屏幕图片和其他信息。因此,该软件也广泛应…...
-ArkTs)
华为鸿蒙应用--文件管理工具(鸿蒙工具)-ArkTs
0、代码 import fs from ohos.file.fs; import { Logger } from ./Logger; import { Constants } from ../constants/Constants; import { toast } from ./ToastUtils;export class FileUtils {/*** 获取目录下所有文件* param filesDir* returns*/static getFiles(filesDir: …...

Python基础语法笔记 tkinter的简单使用
语法 物质 动态类型语言,不需要声明类型 数字 类型int float bool 操作 //整除 **幂 字符串 str1 "Hello python" str2 "world" print(str1 * 3) # 重复输出 print(str1[1]) # 索引访问 print(str1 " " str2) # 拼接 print(str1[2…...

SSL/TLS 握手过程详解
SSL握手过程详解 1、SSL/TLS 历史发展2、SSL/TLS握手过程概览2.1、协商交换密码套件和参数2.2、验证一方或双方的身份2.3、创建/交换对称会话密钥 3、TLS 1.2 握手过程详解4、TLS 1.3 握手过程详解5、The TLS 1.2 handshake – Diffie-Hellman Edition 1、SSL/TLS 历史发展 可…...
B端产品经理学习-对用户进行需求挖掘
目录: 用户需求挖掘的方法 举例:汽车销售系统的用户访谈-前期准备 用户调研提纲 预约用户做访谈 用户访谈注意点 我们对于干系人做完调研之后需要对用户进行调研;在C端产品常见的用户调研方式外,对B端产品仍然适用的 用户需…...
高清网络视频监控平台的应用-城市大交通系统视联网
目 录 一、应用需求 二、系统架构设计 三、功能介绍 1.实时视频监控 2.云台控制 3.语音功能 4. 录像管理与回放 5.告警联动 6.多种显示终端呈现 (1)CS客户端 (2)web客户端 (3…...

java设计小分队01
1.开发流程: 编辑:生成.java文件编译:javac命令,生成.class文件运行:java命令 2.标识符下列那个(不)合法: 除了第一个词小写,其他词首字母大写;java标识符为…...

instant ngp win11 安装笔记
目录 训练保姆级教程: instant ngp安装参考: 编译步骤1 编译步骤2 我把编译成功的库分享到百度网盘了 训练保姆级教程: 英伟达NeRF项目Instant-ngp在Windows下的部署,以及数据集的制作(适合小白的保姆级教学)_colmap2nerf.p…...

Microsoft Word去除页面多余的换行符
大家写论文的时候或者排版的时候可能遇到换行符多出来了导致页面的不美观。像下面这张图一样,虽然latex不会出现这种问题。 处理方式 点击插入然后点击分页 结果展示...

[Javaweb/LayUI/上机考试作业/开源]学生/图书/课程/仓库等管理系统六合一基础功能通用模板
展示 考试要求 给定用户表和六张图书/教师/顾客/仓库....的表(随机给每人抽选),要求实现用户登录注册,异步更新,对物品增删改查,精确/模糊查询等。 环境 tomcat 9 mysql 8 java 17 项目结构 项目类图 写前…...
完善 Golang Gin 框架的静态中间件:Gin-Static
Gin 是 Golang 生态中目前最受用户欢迎和关注的 Web 框架,但是生态中的 Static 中间件使用起来却一直很不顺手。 所以,我顺手改了它,然后把这个改良版开源了。 写在前面 Gin-static 的改良版,我开源在了 soulteary/gin-static&a…...

html websocket的基本使用
html websocket的基本使用 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta http-equiv"X-UA-Compatible" content"IEedge" /><meta name"viewport" content"w…...
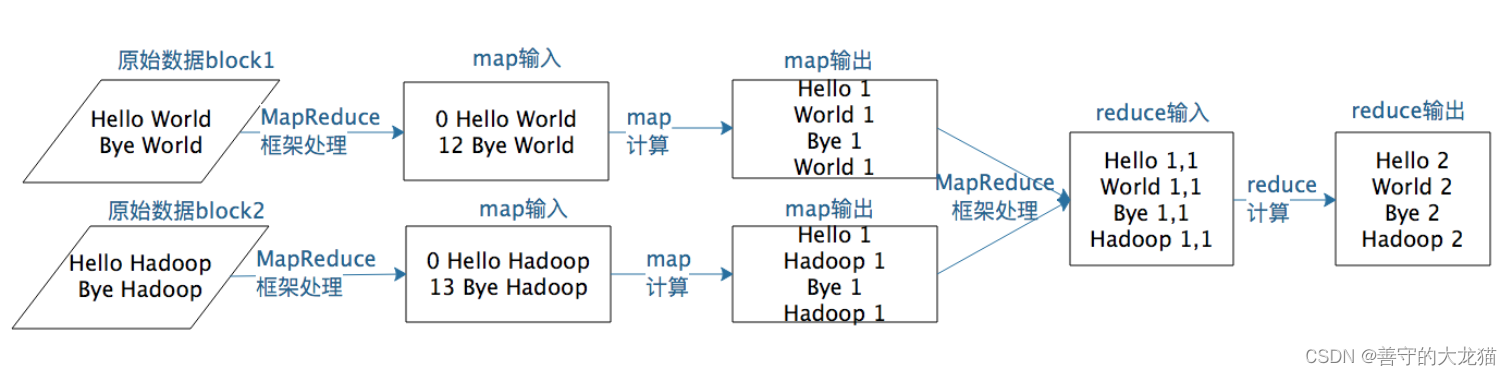
大数据 MapReduce是什么?
在Hadoop问世之前,其实已经有了分布式计算,只是那个时候的分布式计算都是专用的系统,只能专门处理某一类计算,比如进行大规模数据的排序。 很显然,这样的系统无法复用到其他的大数据计算场景,每一种应用都…...

ubuntu 如何放开防火墙端口,ubuntu 防火墙操作命令,ubuntu 防火墙全面操作说明
本文介绍了Ubuntu操作系统有关防火墙操作的命令。为了便于说明,请使用 root 用户或具有超级管理员权限的用户登录到 Ubuntu 系统,这样操作命令前就不需要加 sudo了。 一、安装防火墙 如果没有安装防火墙,请用如下命令安装: apt …...

计算机视觉入门与调优
大家好啊,我是董董灿。 在 CSDN 上写文章写了有一段时间了,期间不少小伙伴私信我,咨询如何自学入门AI,或者咨询一些AI算法。 90%的问题我都回复了,但有时确实因为太忙,没顾得过来。 在这个过程中&#x…...

Ndk编译hevc静态库
源码下载: https://hg.videolan.org/x265 然后执行以下脚本: #!/bin/bash# 设置NDK路径,根据你的实际安装路径修改 NDK_PATH/mnt/c/Users/Administrator/ubuntu_dev/ndk/android-ndk-r21e# 设置目标平台和ABI版本,可以根据实际情况修改 aarch64-linux-…...
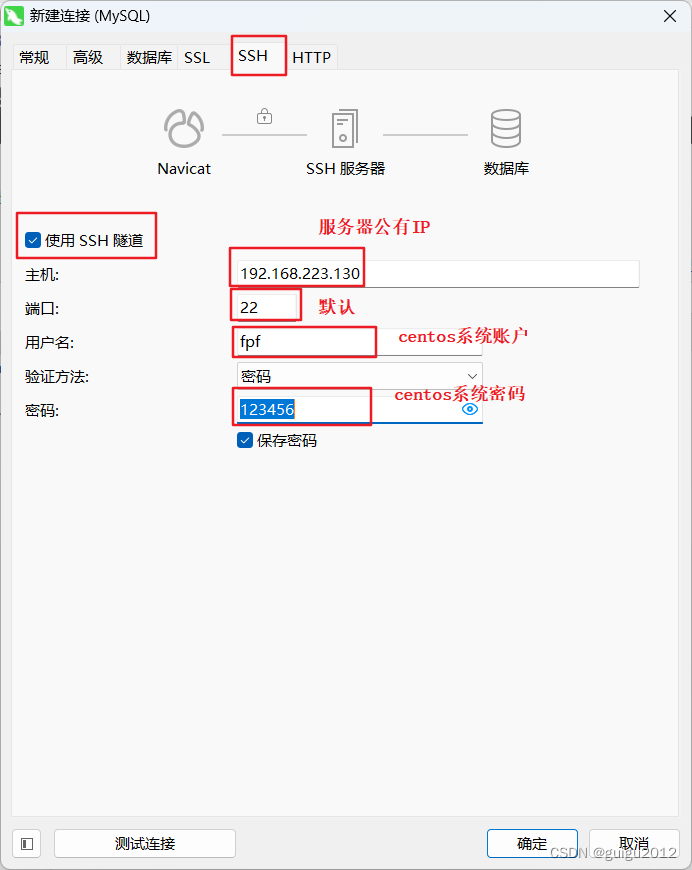
Linux系统安装MySQL
Linux系统安装MySQL 第一步:下载YUM wget http://dev.mysql.com/get/mysql57-community-release-el7-11.noarch.rpm第二步:安装MySQL的YUM 仓库 rpm -ivh mysql57-community-release-el7-11.noarch.rpm第三步:查看MySQL版本 yum repolist …...
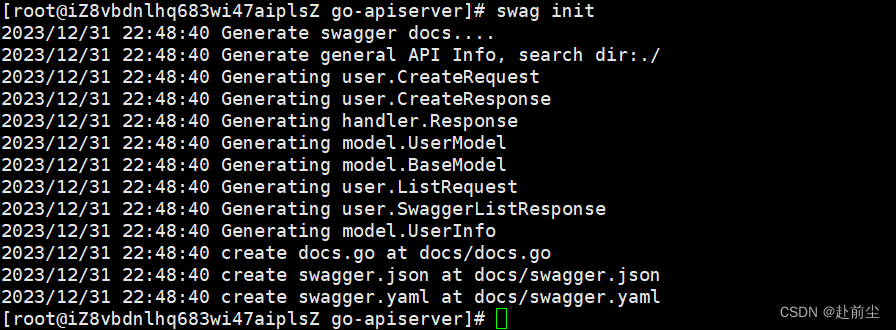
linux go环境安装 swag
下载依赖包 go get -u github.com/swaggo/swag编译 移动到下载的swag包目录,一般在$GOPATH/pkg/mod下 查看 GOPATH echo $GOPATHcd /root/GolangProjects/pkg/mod/github.com/swaggo/swagv1.16.2go install ./cmd/swag/不出意外,$GOPATH/bin下 已经有了swag 初…...

别再只当开关用了!手把手教你用p-GaN HEMT在GaN芯片上实现高性能电容
解锁p-GaN HEMT的隐藏技能:片上高性能电容设计实战指南 在GaN功率集成电路设计中,工程师们常常面临一个棘手的问题:如何在有限的芯片面积内集成更多功能模块?传统解决方案是增加MIM(金属-绝缘体-金属)电容&…...

Claude插件管理工具fake-claude-plugins:架构解析与实战指南
1. 项目概述:一个为Claude生态打造的插件管理工具 最近在折腾Claude相关的开发,发现一个挺有意思的项目—— fake-claude-plugins 。这名字乍一看有点“山寨”味儿,但实际用下来,它解决的是一个非常实际的问题:如何在…...

手把手教你用Livox Mid-360跑通LIO-SAM:从CustomMsg数据转换到完整配置流程
手把手教你用Livox Mid-360跑通LIO-SAM:从CustomMsg数据转换到完整配置流程 当固态激光雷达遇上传统SLAM框架,数据兼容性问题往往成为开发者的第一道门槛。Livox Mid-360作为一款非重复扫描式雷达,其点云分布特性与机械旋转雷达存在本质差异…...
)
从‘123456’到强密码策略:一次完整的弱口令攻防演练与自动化加固方案(Python脚本实战)
从‘123456’到强密码策略:一次完整的弱口令攻防演练与自动化加固方案(Python脚本实战) 在数字化转型加速的今天,弱口令问题依然是企业安全防线的"阿喀琉斯之踵"。2023年Verizon数据泄露调查报告显示,80%的网…...

基于MCP协议构建可审计AI工作空间:多角色协作与文件权限治理
1. 项目概述:一个为Claude Code设计的可审计AI工作空间如果你和我一样,经常需要同时打开多个Claude Code会话来处理一个项目——比如一个前端在改组件,另一个后端在写API,还有一个在调整共享类型——那你肯定遇到过文件冲突的麻烦…...

网络安全情报MCP服务器:AI驱动的自动化威胁分析工作流
1. 项目概述与核心价值最近在整理自己的安全情报工作流时,发现了一个非常有意思的MCP(模型上下文协议)服务器项目:apifyforge/cybersecurity-intelligence-mcp。这个项目本质上是一个桥梁,它把那些我们日常在终端里敲命…...

【深度解析】从 Chatbot 到 AI 数字队友:Claude 高阶能力、模型选型与 API 实战
摘要 本文基于 Claude 高阶使用方法,系统拆解 Memory、Projects、Artifacts、Code Execution、Computer Use 等能力,并结合 OpenAI 兼容 API 给出 Python 实战示例,帮助开发者构建更稳定、可复用的 AI 工作流。背景介绍:为什么很多…...

代码还原点工具设计:为开发者打造本地代码时光机
1. 项目概述:代码的“时光机”与“后悔药”在软件开发这个行当里干了十几年,我敢说,每个程序员都至少经历过一次“手滑”的噩梦。可能是误删了一个还没提交的关键文件,可能是执行了一个破坏性的数据库迁移脚本,或者更常…...

新手吉他弦距与按弦力度分析:法雅特梵高日记测评
零基础学吉他?先别急着买,听我说完 学吉他这件事,90%的人会在前三个月放弃。 不是因为不够热爱,而是因为第一把琴没选对。 我见过太多人兴致勃勃买了把吉他,结果弦距高到按不下去、手指磨出血泡、每次练琴像上刑——然…...

游戏模组加载器终极指南:3步搞定ASI插件安装与管理
游戏模组加载器终极指南:3步搞定ASI插件安装与管理 【免费下载链接】Ultimate-ASI-Loader The Ultimate ASI Loader is a proxy DLL that loads custom .asi libraries into any game process. 项目地址: https://gitcode.com/gh_mirrors/ul/Ultimate-ASI-Loader …...