CNN——VGG
1.VGG简介
论文下载地址:https://arxiv.org/pdf/1409.1556.pdf
VGGNet 是由牛津大学视觉几何小组(Visual Geometry Group, VGG)提出的一种深层卷积网络结构,他们以 7.32% 的错误率赢得了 2014 年 ILSVRC 分类任务的亚军(冠军由 GoogLeNet 以 6.65% 的错误率夺得)和 25.32% 的错误率夺得定位任务(Localization)的第一名(GoogLeNet 错误率为 26.44%)。
VGG通过vgg块的堆积,VGG19最高让网络达到了16 个卷积层和 3 个全连接层,共计 19 层网络(池化层不带参数,一般不算一层)。这也导致参数量非常的多,模型比较臃肿(第一个全连接层占了非常大一部分)
包括VGG11,VGG13,VGG16和VGG19,性能依次提升,最常用的是VGG16。
 核心点:
核心点:
- 全部使用3×3步长为1的小卷积核。3×3卷积核是最小的能够表示上下左右中心的尺寸。
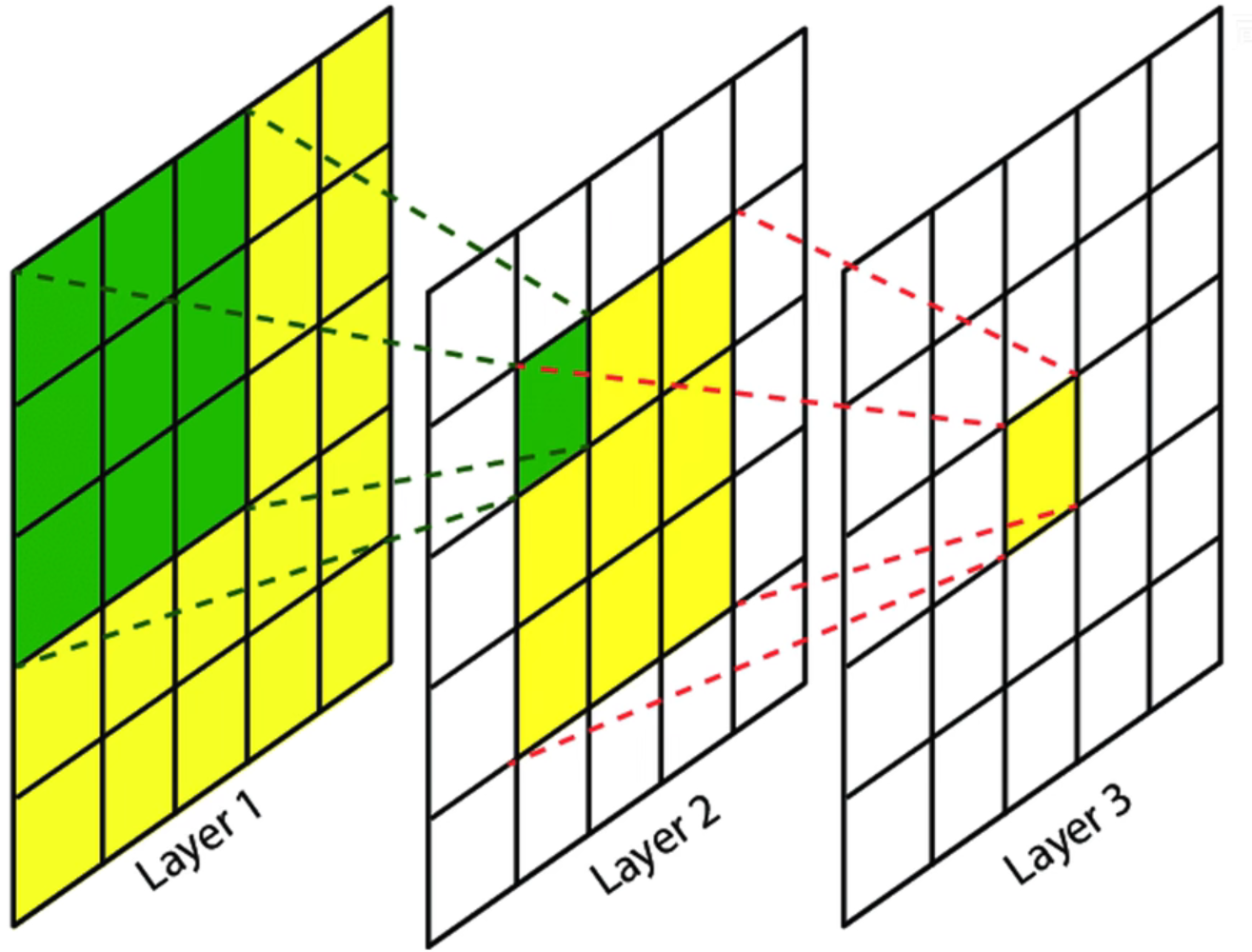
假设输入为5×5,使用2次3×3卷积后最终得到1×1的特征图,那么这个1×1的特征图的感受野为5×5。这和直接使用一个5×5卷积核得到1×1的特征图是一样的。也就是说2次3×3卷积可以代替一次5×5卷积同时,2次3×3卷积的参数更少(2×3×3=18<5×5=25)而且会经过两次激活函数进行非线性变换,学习能力会更好。同样的3次3×3卷积可以替代一次7×7的卷积。
此外步长为1可以不会丢失信息
2.相同的vgg块堆叠
3.深度深,且成功证明深度增加可以提高网络性能
2.VGG网络结构详解
这里以最常用的VGG16为例子。VGG11,VGG13,VGG19都是根据上面的表使用不同的卷积个数。

vgg_block包括若干个3×3卷积(padding=1,stride=1)+激活+2×2池化(padding=0,stride=2),第一个卷积将通道数翻倍
- 3×3卷积,padding=1,stride=1,output=(input-3+2×1)/1+1=input,特征图尺寸不变
- 2×2池化,padding=0,stride=2,output=(input-2)/2+1=1/2input,特征图尺寸减半
1.输入层。224×224×3,RGB图
2.vgg_block1
| 操作 | 填充 | 步长 | 输入通道数 | 输出通道数 | 输出特征图尺寸 |
| 3×3卷积 | 1 | 1 | 3 | 64 | 224×224 |
| Relu激活 | / | / | 64 | 64 | 224×224 |
| 3×3卷积 | 1 | 1 | 64 | 64 | 224×224 |
| Relu激活 | / | / | 64 | 64 | 224×224 |
| 2×2最大池化 | 0 | 2 | 64 | 64 | 112×112 |
2.vgg_block2
| 操作 | 填充 | 步长 | 输入通道数 | 输出通道数 | 输出特征图尺寸 |
| 3×3卷积 | 1 | 1 | 64 | 128 | 112×112 |
| Relu激活 | / | / | 128 | 128 | 112×112 |
| 3×3卷积 | 1 | 1 | 128 | 128 | 112×112 |
| Relu激活 | / | / | 128 | 128 | 112×112 |
| 2×2最大池化 | 0 | 2 | 128 | 128 | 56×56 |
3.vgg_block3
从这个块开始卷积变成3次
| 操作 | 填充 | 步长 | 输入通道数 | 输出通道数 | 输出特征图尺寸 |
| 3×3卷积 | 1 | 1 | 128 | 256 | 56×56 |
| Relu激活 | / | / | 256 | 256 | 56×56 |
| 3×3卷积 | 1 | 1 | 256 | 256 | 56×56 |
| Relu激活 | / | / | 256 | 256 | 56×56 |
| 3×3卷积 | 1 | 1 | 256 | 256 | 56×56 |
| Relu激活 | / | / | 256 | 256 | 56×56 |
| 2×2最大池化 | 0 | 2 | 256 | 256 | 28×28 |
4.vgg_block4
| 操作 | 填充 | 步长 | 输入通道数 | 输出通道数 | 输出特征图尺寸 |
| 3×3卷积 | 1 | 1 | 256 | 512 | 28×28 |
| Relu激活 | / | / | 512 | 512 | 28×28 |
| 3×3卷积 | 1 | 1 | 512 | 512 | 28×28 |
| Relu激活 | / | / | 512 | 512 | 28×28 |
| 3×3卷积 | 1 | 1 | 512 | 512 | 28×28 |
| Relu激活 | / | / | 512 | 512 | 28×28 |
| 2×2最大池化 | 0 | 2 | 512 | 512 | 14×14 |
4.vgg_block5
| 操作 | 填充 | 步长 | 输入通道数 | 输出通道数 | 输出特征图尺寸 |
| 3×3卷积 | 1 | 1 | 512 | 512 | 14×14 |
| Relu激活 | / | / | 512 | 512 | 14×14 |
| 3×3卷积 | 1 | 1 | 512 | 512 | 14×14 |
| Relu激活 | / | / | 512 | 512 | 14×14 |
| 3×3卷积 | 1 | 1 | 512 | 512 | 14×14 |
| Relu激活 | / | / | 512 | 512 | 14×14 |
| 2×2最大池化 | 0 | 2 | 512 | 512 | 7×7 |
6.向量化
flatten,7×7×512(25,088) ->> 1×1×25,088
7.全连接FC1
1×1×25,088 ->>1×1×4096
8.全连接FC2
1×1×4096 ->> 1×1×4096
9.全连接FC3(Softmax)
1×1×4096 ->> 1×1×1000
3.VGGPytorch实现
3.1 手动实现VGG
# 定义VGG块
def vgg_block(num_convs, in_channels, out_channels):layers = [] # 初始化一个空列表用于存放层(卷积层和ReLU激活函数)for _ in range(num_convs): # 循环创建指定数量的卷积层和ReLU激活函数layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)) # 添加一个卷积层layers.append(nn.ReLU(inplace=True)) # 添加一个ReLU激活函数,并在原地执行节省内存in_channels = out_channels # 更新输入通道数为输出通道数,以便下一层使用layers.append(nn.MaxPool2d(kernel_size=2, stride=2)) # 添加一个最大池化层return nn.Sequential(*layers) # 返回一个由这些层组成的Sequential模型# 定义VGG网络
class VGG(nn.Module):def __init__(self, cfg, num_classes=1000):super(VGG, self).__init__()self.conv_layers = self._make_layers(cfg) # 创建VGG的卷积层部分self.fc_layers = nn.Sequential( # 创建VGG的全连接层部分nn.Linear(512 * 7 * 7, 4096), # 全连接层1nn.ReLU(inplace=True), # ReLU激活函数nn.Dropout(), # Dropout层用于防止过拟合nn.Linear(4096, 4096), # 全连接层2nn.ReLU(inplace=True), # ReLU激活函数nn.Dropout(), # Dropout层用于防止过拟合nn.Linear(4096, num_classes) # 全连接层3,输出类别数)self.flatten = nn.Flatten()def forward(self, x):x = self.conv_layers(x) # 卷积层部分x = self.flatten(x) # 将特征张量展平以输入全连接层x = self.fc_layers(x) # 全连接层部分return xdef _make_layers(self, cfg):layers = [] # 初始化一个空列表用于存放VGG的层in_channels = 3 # 输入通道数为RGB图像的3通道for num_convs, out_channels in cfg:layers.append(vgg_block(num_convs, in_channels, out_channels)) # 添加VGG块in_channels = out_channels # 更新输入通道数为输出通道数,以便下一层使用return nn.Sequential(*layers) # 返回一个由VGG块组成的Sequential模型# 不同版本的VGG配置
cfgs = {'VGG11': [(1, 64), (1, 128), (2, 256), (2, 512), (2, 512)], # VGG11的卷积层配置'VGG13': [(2, 64), (2, 128), (2, 256), (2, 512), (2, 512)], # VGG13的卷积层配置'VGG16': [(2, 64), (2, 128), (3, 256), (3, 512), (3, 512)], # VGG16的卷积层配置'VGG19': [(2, 64), (2, 128), (4, 256), (4, 512), (4, 512)] # VGG19的卷积层配置
}# 实例化不同版本的VGG
def get_vgg(model_name, num_classes=1000):cfg = cfgs[model_name] # 获取指定版本的VGG配置model = VGG(cfg, num_classes) # 根据配置创建相应版本的VGG模型return model # 返回指定版本的VGG模型# 实例化不同版本的VGG示例
# vgg11 = get_vgg('VGG11')
# vgg13 = get_vgg('VGG13')
vgg16 = get_vgg('VGG16') # 修改分类数目,vgg16 = get_vgg('VGG16',num_classes=10)
# vgg19 = get_vgg('VGG19')summary(vgg16.to(device), (3, 224, 224))
3.2 手动实现VGG16简易版
还有一个简单易懂的实现方式,如VGG16实现如下。但这种方式如果网络比较深代码就比较冗长了,而且一次只能实现一种模型
# 定义VGG16模型结构
class VGG16(nn.Module):def __init__(self, num_classes=1000):super(VGG16, self).__init__()# 特征层self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),)self.flatten = nn.Flatten()# 分类层 self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, num_classes),)def forward(self, x):x = self.features(x)x = self.flatten(x)x = self.classifier(x)return x3.2 使用Pytorch自带的VGG
官方文档:VGG — Torchvision 0.16 documentation (pytorch.org)。Pytorch官方实现了VGG,并且还附带有在ImageNet上预训练权重

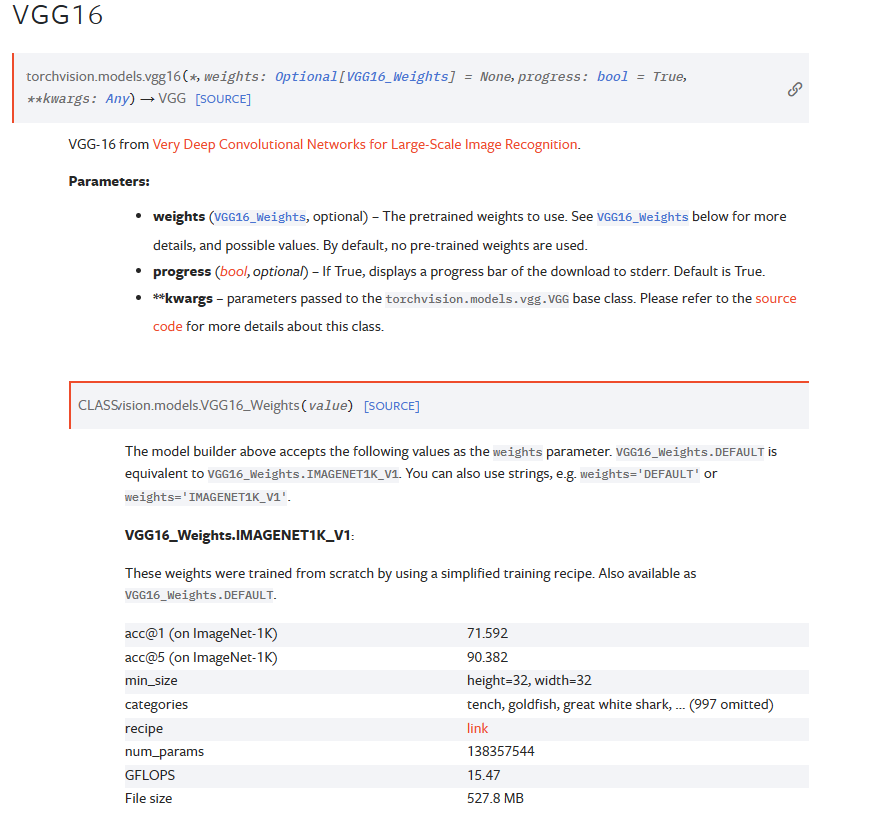
可以看到还有bn版本可选,即在卷积后增加使用了batch-normalization批量归一化。下面是使用的示例:
# 初始化预训练的vgg16模型
modelPre = models.vgg16(weights='DEFAULT')
summary(modelPre.to(device), (3, 224, 224))![]()
weights='DEFAULT'会默认使用最新最好的权重,或者直接指明weights='IMAGENET1K_V1',什么模型有什么权重可以直接去官方文档中查看就好。

除了加入了全局平均池化层之外,其他和我们自己实现的是一样的。全局平均池化层可以支持任意输入尺寸,无论31输出什么尺寸,全部变成7×7
4.VGG在CIFAR-10简单实践
所需库
import torch
import torch.nn as nn
from torchsummary import summary
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from tqdm import tqdm
from torchvision import models
import matplotlib.pyplot as plt1.修改网络结构
CIFAR-10输入尺寸为32×32,为了适应该数据集,需要简单修改一下第一层全连接层的输入参数。根据网络结构,尺寸会减半5次,对于224×224来说会降到7,则会降低到1。
将nn.Linear(512 * 7 * 7, 4096)修改为nn.Linear(512 * 1 * 1, 4096)
# 定义VGG16模型结构
class VGG16(nn.Module):def __init__(self, num_classes=1000):super(VGG16, self).__init__()# 特征层self.features = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),)self.flatten = nn.Flatten()# 分类层 self.classifier = nn.Sequential(#nn.Linear(512 * 7 * 7, 4096),nn.Linear(512 * 1 * 1, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, num_classes),)def forward(self, x):x = self.features(x)x = self.flatten(x)x = self.classifier(x)return x# 打印模型结构
model = VGG16(num_classes=10).to(device)
summary(model, (3, 32, 32))
2.读取数据集
# 数据预处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])# 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./dataset', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./dataset', train=False, download=True, transform=transform)# 数据加载器
train_dataloader = DataLoader(train_dataset, batch_size=128, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=128, shuffle=False)3.使用GPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'4.模型训练
def train(model, lr, epochs, train_dataloader, device, save_path):# 将模型放入GPUmodel = model.to(device)# 使用交叉熵损失函数loss_fn = nn.CrossEntropyLoss().to(device)# SGDoptimizer = torch.optim.SGD(model.parameters(), lr=lr, weight_decay=5e-4, momentum=0.9)# 记录训练与验证数据train_losses = []train_accuracies = []# 开始迭代 for epoch in range(epochs): # 切换训练模式model.train() # 记录变量train_loss = 0.0correct_train = 0total_train = 0# 读取训练数据并使用 tqdm 显示进度条for i, (inputs, targets) in tqdm(enumerate(train_dataloader), total=len(train_dataloader), desc=f"Epoch {epoch+1}/{epochs}", unit='batch'):# 训练数据移入GPUinputs = inputs.to(device)targets = targets.to(device)# 模型预测outputs = model(inputs)# 计算损失loss = loss_fn(outputs, targets)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 使用优化器优化参数optimizer.step()# 记录损失train_loss += loss.item()# 计算训练正确个数_, predicted = torch.max(outputs, 1)total_train += targets.size(0)correct_train += (predicted == targets).sum().item()# 计算训练正确率并记录train_loss /= len(train_dataloader)train_accuracy = correct_train / total_traintrain_losses.append(train_loss)train_accuracies.append(train_accuracy)# 输出训练信息print(f"Epoch [{epoch + 1}/{epochs}] - Train Loss: {train_loss:.4f}, Train Acc: {train_accuracy:.4f}")# 绘制损失和正确率曲线plt.figure(figsize=(10, 5))plt.subplot(1, 2, 1)plt.plot(range(epochs), train_losses, label='Training Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.subplot(1, 2, 2)plt.plot(range(epochs), train_accuracies, label='Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.tight_layout()plt.show()torch.save(model.state_dict(), save_path)model = VGG16(num_classes=10)
lr = 0.0001
epochs = 10
save_path = './modelWeight/VGG16_CIFAR10'
train(model,lr,epochs,train_dataloader,device,save_path)相关文章:
CNN——VGG
1.VGG简介 论文下载地址:https://arxiv.org/pdf/1409.1556.pdf VGGNet 是由牛津大学视觉几何小组(Visual Geometry Group, VGG)提出的一种深层卷积网络结构,他们以 7.32% 的错误率赢得了 2014 年 ILSVRC 分类任务的亚军ÿ…...

深入理解Java中的多线程编程与并发控制
当谈论到 Java 编程语言时,多线程编程和并发控制是其中最重要的话题之一。Java 在多线程领域有着强大的支持和丰富的工具集,允许开发人员利用并发性来提高程序性能和效率。本文将深入探讨 Java 中的多线程编程和并发控制,包括线程的创建、同步…...

提供10个mysql的实例和思路
学生信息管理系统 学生表(id, name, gender, age, class_id)班级表(id, name)思路:通过学生表和班级表进行关联,可以实现学生信息的查询、添加、修改、删除等操作。 订单管理系统 订单表(id, us…...
FPGA项目(14)——基于FPGA的数字秒表设计
1.功能设计 设计内容及要求: 1.秒表最大计时范围为99分59. 99秒 2.6位数码管显示,分辨率为0.01秒 3.具有清零、启动计时、暂停及继续计时等功能 4.控制操作按键不超过二个。 2.设计思路 所采用的时钟为50M,先对时钟进行分频,得到100HZ频率…...
)
浅谈指数移动平均(ema)
经常在各种代码中看到指数移动平均(比如我专注的网络传输领域),但却不曾想到它就是诠释世界的方法,我们每个人都在被这种方式 “平均”… 今天说说指数移动平均(或移动指数平均,Exponential Moving Average)。 能查到的资料都侧重于其数学形…...

1-并发编程线程基础
什么是线程 在讨论什么是线程前有必要先说下什么是进程,因为线程是进程中的一个实体,线程本身是不会独立存在的。 进程是代码在数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,线程则是进程的一个执行路径&#…...
vue中动态出来返回的时间秒数,在多少范围显示多少秒,多少范围显示分,小时等等
在Vue中,你可以使用计算属性(computed property)或过滤器(filter)来根据动态返回的时间秒数来显示不同的时间单位,比如秒、分、小时等等。 下面是一个使用计算属性的示例: <template>&l…...

English: go through customs
文章目录 常见单词机场指示登机和中转降落以及公共服务签证篇出/入境卡篇入境英语会话篇 常见单词 customs: 海关 (kʌstəmz)cash: 现金 (kʃ)passport: 护照 (pspɔːt)luggage/baggage: 行李 (lʌɡɪdʒ/ˈbɡɪdʒ)Exchange: 换钱 (ɪks’tʃeɪndʒ)airport: 飞机场 (ɛ…...
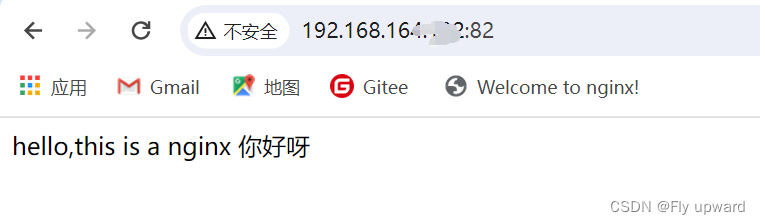
Nginx 多端口部署多站点
目录 1.进行nginx.conf 2.复制粘贴 3.修改端口及站点根目录 4. 网站上传 1.进行nginx.conf 在 nginx 主要配置文件 nginx.conf 中,server 是负责一个网站配置的,我们想要多个端口访问的话,可以复制多个 server 先进入到 nginx.conf 中 …...
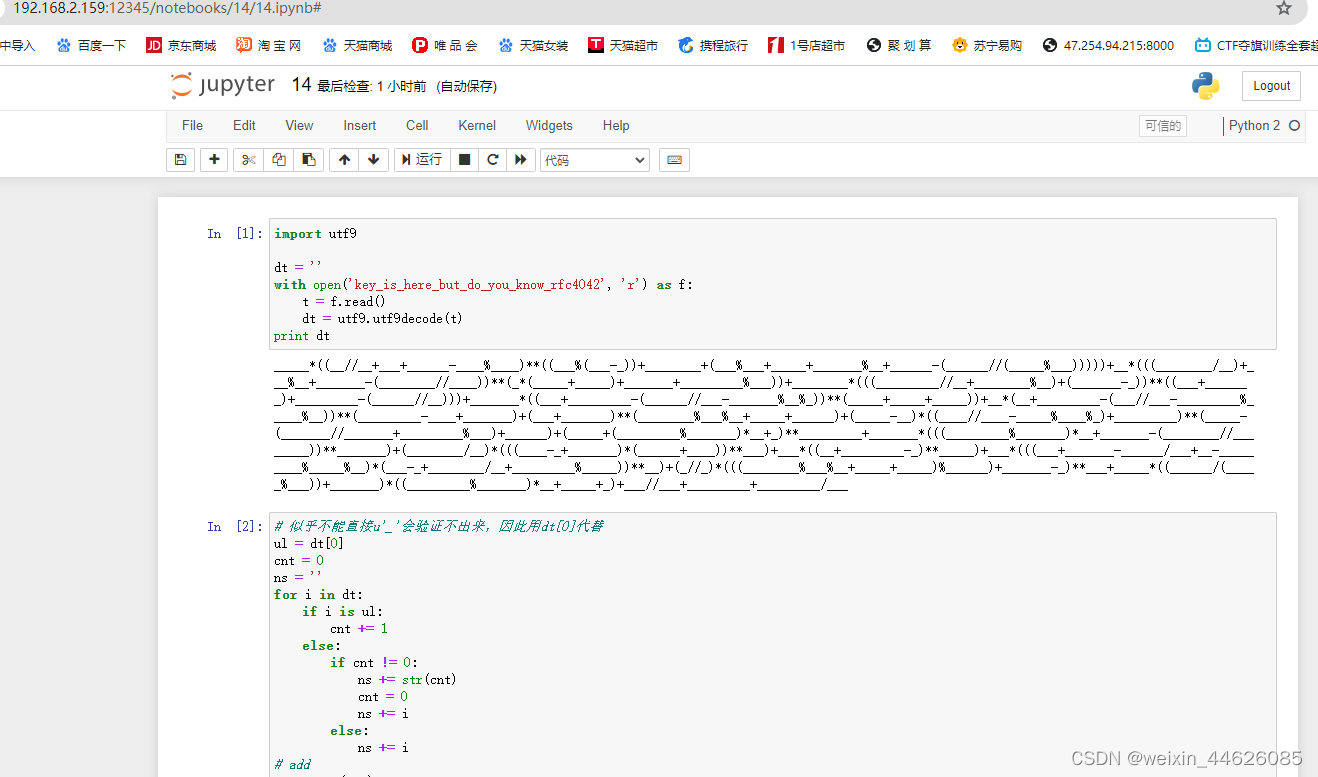
从零开始配置kali2023环境:配置jupyter的多内核环境
在kali2023上面尝试用anaconda3,anaconda2安装实现配置jupyter的多内核环境时出现各种问题,现在可以通过镜像方式解决 1. 搜索镜像 ┌──(holyeyes㉿kali2023)-[~] └─$ sudo docker search anaconda ┌──(holyeyes㉿kali2023)-[~] └─$ sudo …...

Dart调用JS对10000条定位数据滤波
使用Dart调用JS,还是为了练习跨语言调用; 一、编写对应的JS代码 平时在开发时不推荐将算法放在JS里,我这里是简单的做一下数据过滤; 首先生成一些随机定位数据,在实际开发中可以使用真实数据; // 随机定…...

大模型应用实践:AIGC探索之旅
随着OpenAI推出ChatGPT,AIGC迎来了前所未有的发展机遇。大模型技术已经不仅仅是技术趋势,而是深刻地塑造着我们交流、工作和思考的方式。 本文介绍了笔者理解的大模型和AIGC的密切联系,从历史沿革到实际应用案例,再到面临的技术挑…...

【.NET Core】异步编程模式
【.NET Core】异步编程模式 文章目录 【.NET Core】异步编程模式一、概述二、基于任务的异步模式(TAP)2.1 TAP模式命名、参数和返回类型2.2 TAP初始化异步操2.3 TAP如何编译2.4 手动生成TAP方法2.5 混合方法实现TAP2.6 TAP中Await挂起执行2.7 TAP中使用Y…...

macOS通过外置驱动器备份数据
通过外置驱动器备份数据(谨慎操作) 1.将外置驱动器连接到您的 Mac。驱动器容量应等于或大于您当前的启动磁盘。驱动器还应该是您可以抹掉的。 2.使用 macOS 恢复功能 抹掉外置驱动器,然后将 macOS 安装 到外置驱动器上。确保您选择的外置驱动…...
rtsp解析视频流
这里先说一下 播放rtsp 视频流,尽量让后端转换一下其他格式的流进行播放。因为rtsp的流需要flash支持,现在很多浏览器不支持flash。 先说一下这里我没有用video-player插件,因为它需要用flash ,在一个是我下载flash后,还是无法播放…...

【物联网】手把手完整实现STM32+ESP8266+MQTT+阿里云+APP应用——第3节-云产品流转配置
🌟博主领域:嵌入式领域&人工智能&软件开发 本节目标:本节目标是进行云产品流转配置为后面实际的手机APP的接入做铺垫。云产品流转配置的目的是为了后面能够让后面实际做出来的手机APP可以控制STM32/MCU,STM32/MCU可以将数…...
)
Spring Cloud Config相关问题及答案(2024)
1、什么是 Spring Cloud Config,它解决了哪些问题? Spring Cloud Config 是一个为微服务架构提供集中化外部配置支持的项目。它是构建在 Spring Cloud 生态系统之上,利用 Spring Boot 的开发便利性,简化了分布式系统中的配置管理…...
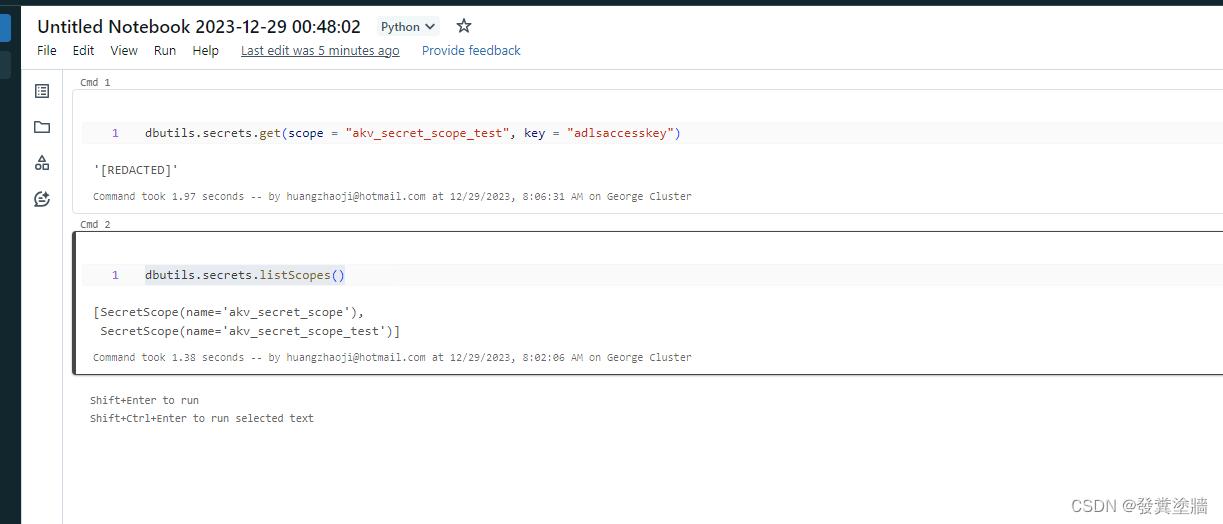
【Azure 架构师学习笔记】- Azure Databricks (4) - 使用Azure Key Vault 管理ADB Secret
本文属于【Azure 架构师学习笔记】系列。 本文属于【Azure Databricks】系列。 接上文 【Azure 架构师学习笔记】- Azure Databricks (3) - 再次认识DataBricks 前言 Azure Databricks有access token,是具有ADB内部最高权限的token。在云环境中这些高级别权限的sec…...

[每周一更]-(第50期):Go的垃圾回收GC
参考文章: https://juejin.cn/post/7111515970669117447https://draveness.me/golang/docs/part3-runtime/ch07-memory/golang-garbage-collector/https://colobu.com/2022/07/16/A-Guide-to-the-Go-Garbage-Collector/https://liangyaopei.github.io/2021/01/02/g…...
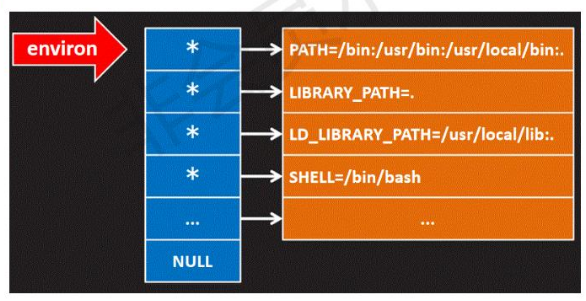
【嵌入式学习笔记-01】什么是UC,操作系统历史介绍,计算机系统分层,环境变量(PATH),错误
【嵌入式学习笔记】什么是UC,操作系统历史介绍,计算机系统分层,环境变量(PATH),错误 文章目录 什么是UC?计算机系统分层什么是操作系统? 环境变量什么是环境变量?环境变量的添加&am…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

腾讯云V3签名
想要接入腾讯云的Api,必然先按其文档计算出所要求的签名。 之前也调用过腾讯云的接口,但总是卡在签名这一步,最后放弃选择SDK,这次终于自己代码实现。 可能腾讯云翻新了接口文档,现在阅读起来,清晰了很多&…...

Python 高效图像帧提取与视频编码:实战指南
Python 高效图像帧提取与视频编码:实战指南 在音视频处理领域,图像帧提取与视频编码是基础但极具挑战性的任务。Python 结合强大的第三方库(如 OpenCV、FFmpeg、PyAV),可以高效处理视频流,实现快速帧提取、压缩编码等关键功能。本文将深入介绍如何优化这些流程,提高处理…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...

高防服务器价格高原因分析
高防服务器的价格较高,主要是由于其特殊的防御机制、硬件配置、运营维护等多方面的综合成本。以下从技术、资源和服务三个维度详细解析高防服务器昂贵的原因: 一、硬件与技术投入 大带宽需求 DDoS攻击通过占用大量带宽资源瘫痪目标服务器,因此…...