首次引入大模型!Bert-vits2-Extra中文特化版40秒素材复刻巫师3叶奈法

Bert-vits2项目又更新了,更新了一个新的分支:中文特化,所谓中文特化,即针对中文音色的特殊优化版本,纯中文底模效果百尺竿头更进一步,同时首次引入了大模型,使用国产IDEA-CCNL/Erlangshen-MegatronBert-1.3B大模型作为Bert特征提取,基本上完全解决了发音的bad case,同时在情感表达方面有大幅提升,可以作为先前V1.0.1纯中文版本更好的替代。
更多情报请参见Bert-vits2项目官网:
https://github.com/fishaudio/Bert-VITS2/releases/tag/Extra
本次我们基于Bert-vits2中文特化版本通过40秒素材复刻巫师3角色叶奈法(Yennefer)的音色。
配置Bert-vits2中文特化版本
首先克隆项目:
git clone https://github.com/v3ucn/Bert-VITS2-Extra_-.git
注意这里是针对官方的Extra分支的修改版本,增加了音频切分和转写。
随后下载新的纯中文底模:
https://openi.pcl.ac.cn/Stardust_minus/Bert-VITS2/modelmanage/show_model
同时还需要下载IDEA-CCNL/Erlangshen-MegatronBert-1.3B大模型的预训练模型:

值得一提的是,这个新炼的纯中文底模非常牛逼,官方作者仅通过一个5秒的素材就可以完美复刻音色。
关于作者的中文特化底模极限测试:
https://www.bilibili.com/video/BV1Fa4y1B7HB/
随后将模型放入对应的文件夹,bert模型文件结构如下:
E:\work\Bert-VITS2-Extra\bert>tree /f
Folder PATH listing for volume myssd
Volume serial number is 7CE3-15AE
E:.
│ bert_models.json
│
├───bert-base-japanese-v3
│ .gitattributes
│ config.json
│ README.md
│ tokenizer_config.json
│ vocab.txt
│
├───bert-large-japanese-v2
│ .gitattributes
│ config.json
│ README.md
│ tokenizer_config.json
│ vocab.txt
│
├───chinese-roberta-wwm-ext-large
│ .gitattributes
│ added_tokens.json
│ config.json
│ pytorch_model.bin
│ README.md
│ special_tokens_map.json
│ tokenizer.json
│ tokenizer_config.json
│ vocab.txt
│
├───deberta-v2-large-japanese
│ .gitattributes
│ config.json
│ pytorch_model.bin
│ README.md
│ special_tokens_map.json
│ tokenizer.json
│ tokenizer_config.json
│
├───deberta-v2-large-japanese-char-wwm
│ .gitattributes
│ config.json
│ pytorch_model.bin
│ README.md
│ special_tokens_map.json
│ tokenizer_config.json
│ vocab.txt
│
├───deberta-v3-large
│ .gitattributes
│ config.json
│ generator_config.json
│ pytorch_model.bin
│ README.md
│ spm.model
│ tokenizer_config.json
│
├───Erlangshen-DeBERTa-v2-710M-Chinese
│ config.json
│ special_tokens_map.json
│ tokenizer_config.json
│ vocab.txt
│
├───Erlangshen-MegatronBert-1.3B-Chinese
│ config.json
│ pytorch_model.bin
│ vocab.txt
│
└───Erlangshen-MegatronBert-3.9B-Chinese config.json special_tokens_map.json tokenizer_config.json vocab.txt
很明显,这里关于Erlangshen-MegatronBert大模型,其实有三个参数选择,有710m和1.3b以及3.9B,作者选择了居中的1.3b大模型。
这里介绍一下国产的Erlangshen-MegatronBert大模型。
Erlangshen-MegatronBert 是一个具有 39 亿参数的中文 BERT 模型,它是目前最大的中文 BERT 模型之一。这个模型的编码器结构为主,专注于解决各种自然语言理解任务。它同时,鉴于中文语法和大规模训练的难度,使用了四种预训练策略来改进 BERT,Erlangshen-MegatronBert 模型适用于各种自然语言理解任务,包括文本生成、文本分类、问答等,这个模型的权重和代码都是开源的,可以在 Hugging Face 和 CSDN 博客等平台上找到。
Erlangshen-MegatronBert 模型可以应用于多种领域,如 AI 模拟声音、数字人虚拟主播等。
另外需要注意的是,clap模型也已经回归,结构如下:
E:\work\Bert-VITS2-Extra\emotional\clap-htsat-fused>tree /f
Folder PATH listing for volume myssd
Volume serial number is 7CE3-15AE
E:. .gitattributes config.json merges.txt preprocessor_config.json pytorch_model.bin README.md special_tokens_map.json tokenizer.json tokenizer_config.json vocab.json No subfolders exist
clap主要负责情感风格的引导。2.3版本去掉了,中文特化又加了回来。
至此模型就配置好了。
Bert-vits2中文特化版本训练和推理
首先把叶奈法的音频素材放入角色的raw目录。
随后需要对数据进行预处理操作:
python3 audio_slicer.py
python3 short_audio_transcribe.py
这里是切分和转写。
接着运行预处理的webui:
python3 webui_preprocess.py
这里需要注意的是,bert特征文件的生成会变慢,因为需要大模型的参与。
后续应该会有一些改进。
数据处理之后,应该包括重采样音频,bert特征文件,以及clap特征文件:
E:\work\Bert-VITS2-Extra\Data\Yennefer\wavs>tree /f
Folder PATH listing for volume myssd
Volume serial number is 7CE3-15AE
E:. Yennefer_0.bert.pt Yennefer_0.emo.pt Yennefer_0.spec.pt Yennefer_0.wav Yennefer_1.bert.pt Yennefer_1.emo.pt Yennefer_1.spec.pt Yennefer_1.wav Yennefer_10.bert.pt Yennefer_10.emo.pt Yennefer_10.spec.pt Yennefer_10.wav Yennefer_11.bert.pt Yennefer_11.emo.pt Yennefer_11.spec.pt Yennefer_11.wav Yennefer_12.bert.pt Yennefer_12.emo.pt Yennefer_12.spec.pt Yennefer_12.wav Yennefer_13.bert.pt Yennefer_13.emo.pt Yennefer_13.spec.pt Yennefer_13.wav Yennefer_14.bert.pt Yennefer_14.emo.pt Yennefer_14.spec.pt Yennefer_14.wav Yennefer_15.bert.pt Yennefer_15.emo.pt Yennefer_15.spec.pt Yennefer_15.wav Yennefer_16.bert.pt Yennefer_16.emo.pt Yennefer_16.spec.pt Yennefer_16.wav Yennefer_17.bert.pt Yennefer_17.emo.pt Yennefer_17.spec.pt Yennefer_17.wav Yennefer_18.bert.pt Yennefer_18.emo.pt Yennefer_18.spec.pt Yennefer_18.wav Yennefer_19.bert.pt Yennefer_19.emo.pt Yennefer_19.spec.pt Yennefer_19.wav Yennefer_2.bert.pt Yennefer_2.emo.pt Yennefer_2.spec.pt Yennefer_2.wav Yennefer_20.bert.pt Yennefer_20.emo.pt Yennefer_20.spec.pt Yennefer_20.wav Yennefer_3.bert.pt Yennefer_3.emo.pt Yennefer_3.spec.pt Yennefer_3.wav Yennefer_4.bert.pt Yennefer_4.emo.pt Yennefer_4.spec.pt Yennefer_4.wav Yennefer_5.bert.pt Yennefer_5.emo.pt Yennefer_5.spec.pt Yennefer_5.wav Yennefer_6.bert.pt Yennefer_6.emo.pt Yennefer_6.spec.pt Yennefer_6.wav Yennefer_7.bert.pt Yennefer_7.emo.pt Yennefer_7.spec.pt Yennefer_7.wav Yennefer_8.bert.pt Yennefer_8.emo.pt Yennefer_8.spec.pt Yennefer_8.wav Yennefer_9.bert.pt Yennefer_9.emo.pt Yennefer_9.spec.pt Yennefer_9.wav
随后训练即可:
python3 train_ms.py
结语
Bert-vits2中文特化版本引入了大模型,导致入门的门槛略微变高了一点,官方说至少需要8G显存才可以跑,实际上6G也是可以的,如果bert大模型选择参数更少的版本,相信运行的门槛会进一步的降低。
最后奉上整合包链接:
整合包链接:https://pan.quark.cn/s/754f236ef864
相关文章:
首次引入大模型!Bert-vits2-Extra中文特化版40秒素材复刻巫师3叶奈法
Bert-vits2项目又更新了,更新了一个新的分支:中文特化,所谓中文特化,即针对中文音色的特殊优化版本,纯中文底模效果百尺竿头更进一步,同时首次引入了大模型,使用国产IDEA-CCNL/Erlangshen-Megat…...
从零学Java - 接口
Java 接口 文章目录 Java 接口1.接口的语法1.1 与抽象类的区别 2.如何使用接口?2.1 接口的使用规范 3.什么是接口?3.1 常见关系 4.接口的多态性5.面向接口编程5.1 接口回调 6.特殊接口6.1 常量接口6.2 标记接口 7.接口的好处 补充面向对象 七大设计原则 1.接口的语法 接口&a…...

安全防御之身份鉴别技术
身份认证技术用于在计算机网络中确认操作者的身份。在计算机网络世界中,用户的身份信息是用一组特定的数据来表示的,计算机也只能识别用户的数字身份。身份认证技术能够作为系统安全的第一道防线,主要用于确认网络用户的身份,防止…...

axios post YII2无法接收post参数问题解决
axios post YII2无法接收post参数问题解决 在yii 配置文件中增加 ‘parsers’ > [“application/json” > “yii\web\JsonParser”] 如下所示: $config [id > basic,language > zh-CN,timeZone > env(TIME_ZONE, PRC),basePath > $basePath,bo…...
性能优化-OpenMP基础教程(三)
本文主要介绍OpenMP并行编程的环境变量和实战、主要对比理解嵌套并行的效果。 🎬个人简介:一个全栈工程师的升级之路! 📋个人专栏:高性能(HPC)开发基础教程 🎀CSDN主页 发狂的小花 &…...

[足式机器人]Part2 Dr. CAN学习笔记-动态系统建模与分析 Ch02-1+2课程介绍+电路系统建模、基尔霍夫定律
本文仅供学习使用 本文参考: B站:DR_CAN Dr. CAN学习笔记-动态系统建模与分析 Ch02-12课程介绍电路系统建模、基尔霍夫定律 1. 课程介绍2. 电路系统建模、基尔霍夫定律 1. 课程介绍 2. 电路系统建模、基尔霍夫定律 基本元件: 电量 库伦&…...
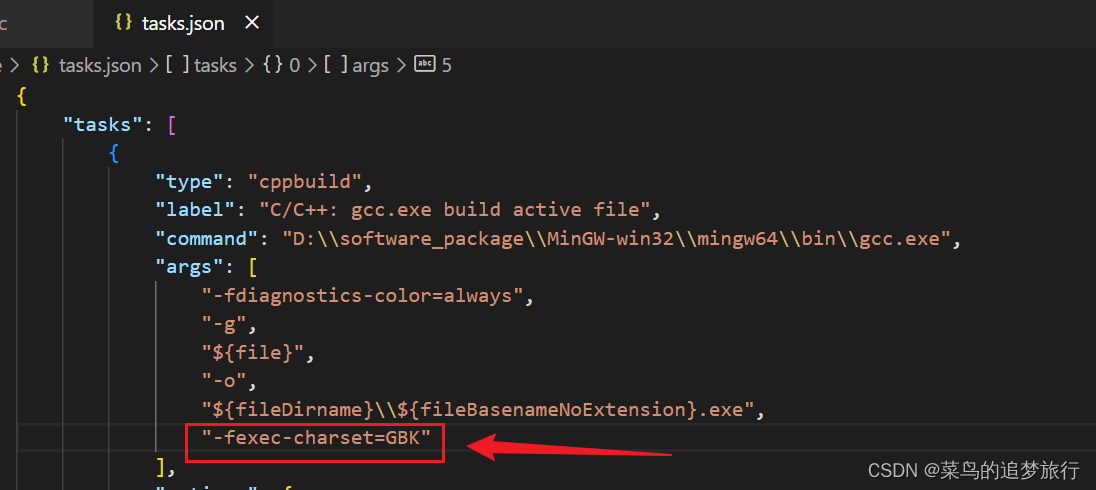
VSCode配置C/C++环境
文章目录 1. 安装配置 C 编译器1.1 下载 MinGW1.2 Mingw添加到系统变量1.3 验证 2. 安装和配置VSCode2.1 安装VSCode2.2 VSCode配置C环境2.3. 优化 3.参考文章 本文主要记录在VSCode中配置C环境,非常感谢参考文章中的博主。 1. 安装配置 C 编译器 首先需要安装 C 编…...

ChatGPT绘制全球植被类型分布图、生物量图、土壤概念图、处理遥感数据并绘图、病毒、植物、动物细胞结构图
以ChatGPT、LLaMA、Gemini、DALLE、Midjourney、Stable Diffusion、星火大模型、文心一言、千问为代表AI大语言模型带来了新一波人工智能浪潮,可以面向科研选题、思维导图、数据清洗、统计分析、高级编程、代码调试、算法学习、论文检索、写作、翻译、润色、文献辅助…...
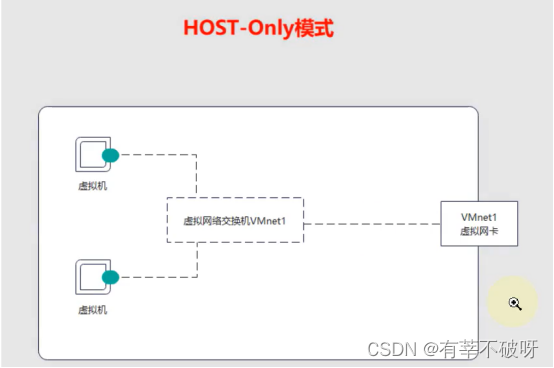
vmware workstation的三种网络模式通俗理解
一、前言 workstations想必很多童鞋都在用,经常会用来在本机创建不同的虚拟机来做各种测试,那么对于它支持的网络模式,在不同的测试场景下应该用哪种网络模式,你需要做下了解,以便可以愉快的继续测(搬&…...
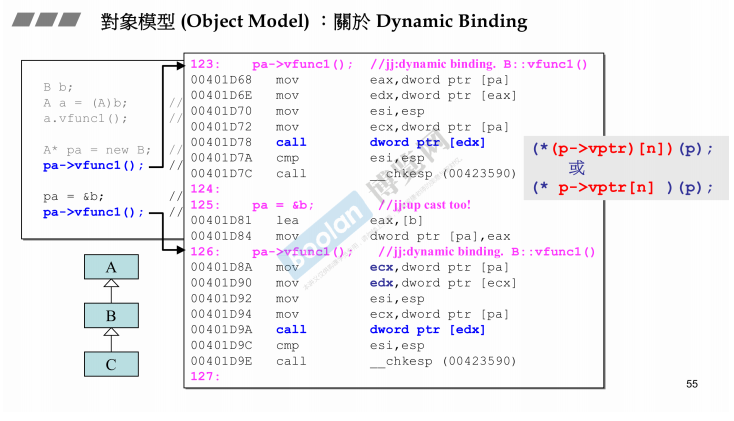
C++程序设计兼谈对象模型(侯捷)笔记
C程序设计兼谈对象模型(侯捷) 这是C面向对象程序设计的续集笔记,仅供个人学习使用。如有侵权,请联系删除。 主要内容:涉及到模板中的类模板、函数模板、成员模板以及模板模板参数,后面包含对象模型中虚函数调用&…...

selenium实现UI自动化
1.selenium简介 selenium是支持web浏览器自动化的一系列工具和库的综合项目。具有支持linux、windows等多个平台,支持Firefox、chrome等多种主流浏览器;支持Java、Python等多种语言。 主要包括的三大工具有: WebDriver(rc 1.0)、…...
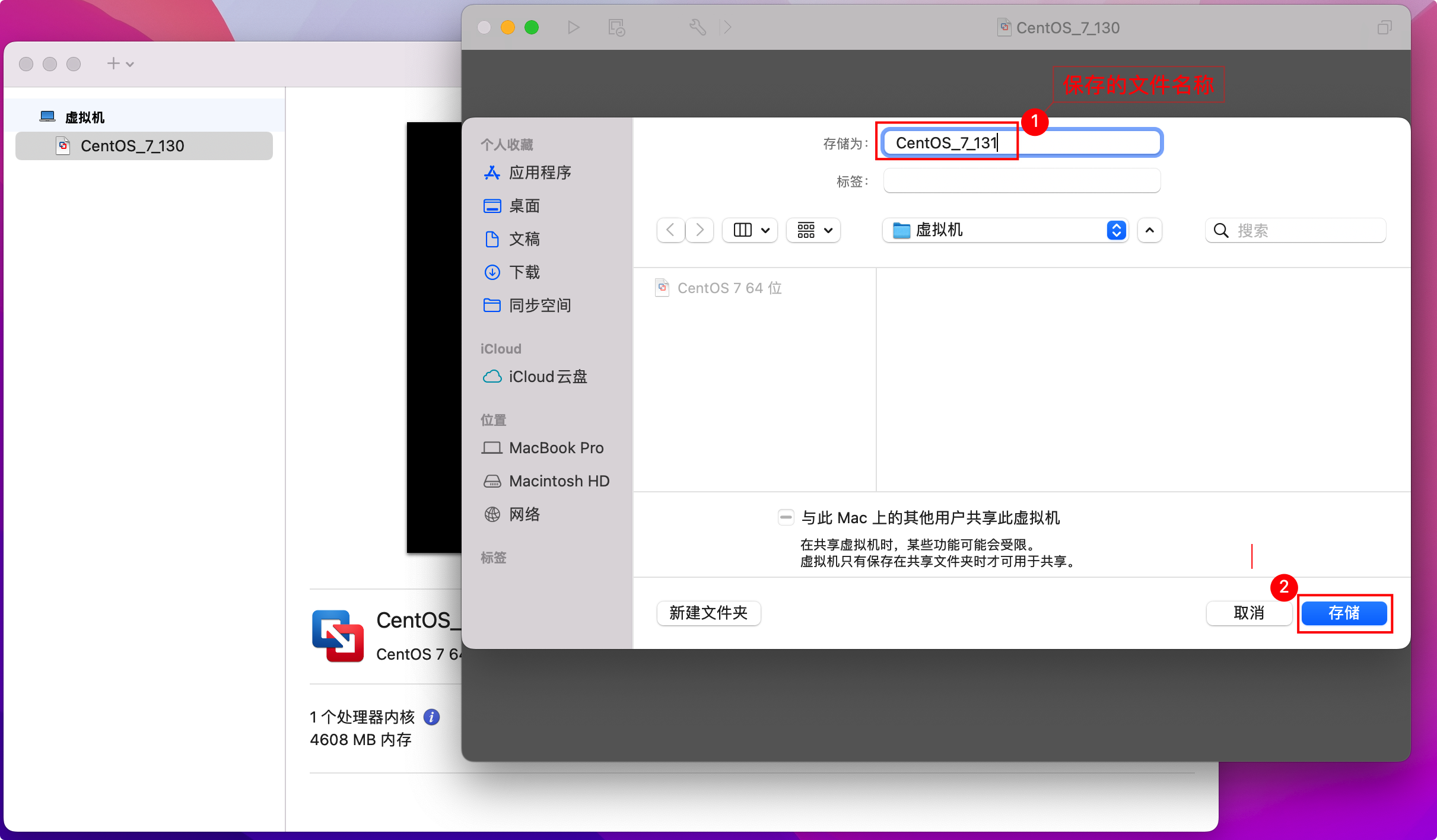
【DevOps-03】Build阶段-Maven安装配置
一、简要说明 下载安装JDK8下载安装Maven二、复制准备一台虚拟机 1、VM虚拟复制克隆一台机器 2、启动刚克隆的虚拟机,修改IP地址 刚刚克隆的虚拟机 ,IP地址和原虚拟的IP地址是一样的,需要修改克隆后的虚拟机IP地址,以免IP地址冲突。 # 编辑修改IP地址 $ vi /etc/sysconfig…...

已解决java.lang.ArrayIndexOutOfBoundsException异常的正确解决方法,亲测有效!!!
已解决java.lang.ArrayIndexOutOfBoundsException异常的正确解决方法,亲测有效!!! 目录 报错问题 解决思路 解决方法 总结 Q1 - 报错问题 java.long.ArrayIndexOutOfBoundsException 是Java中的一个运行时异常,…...
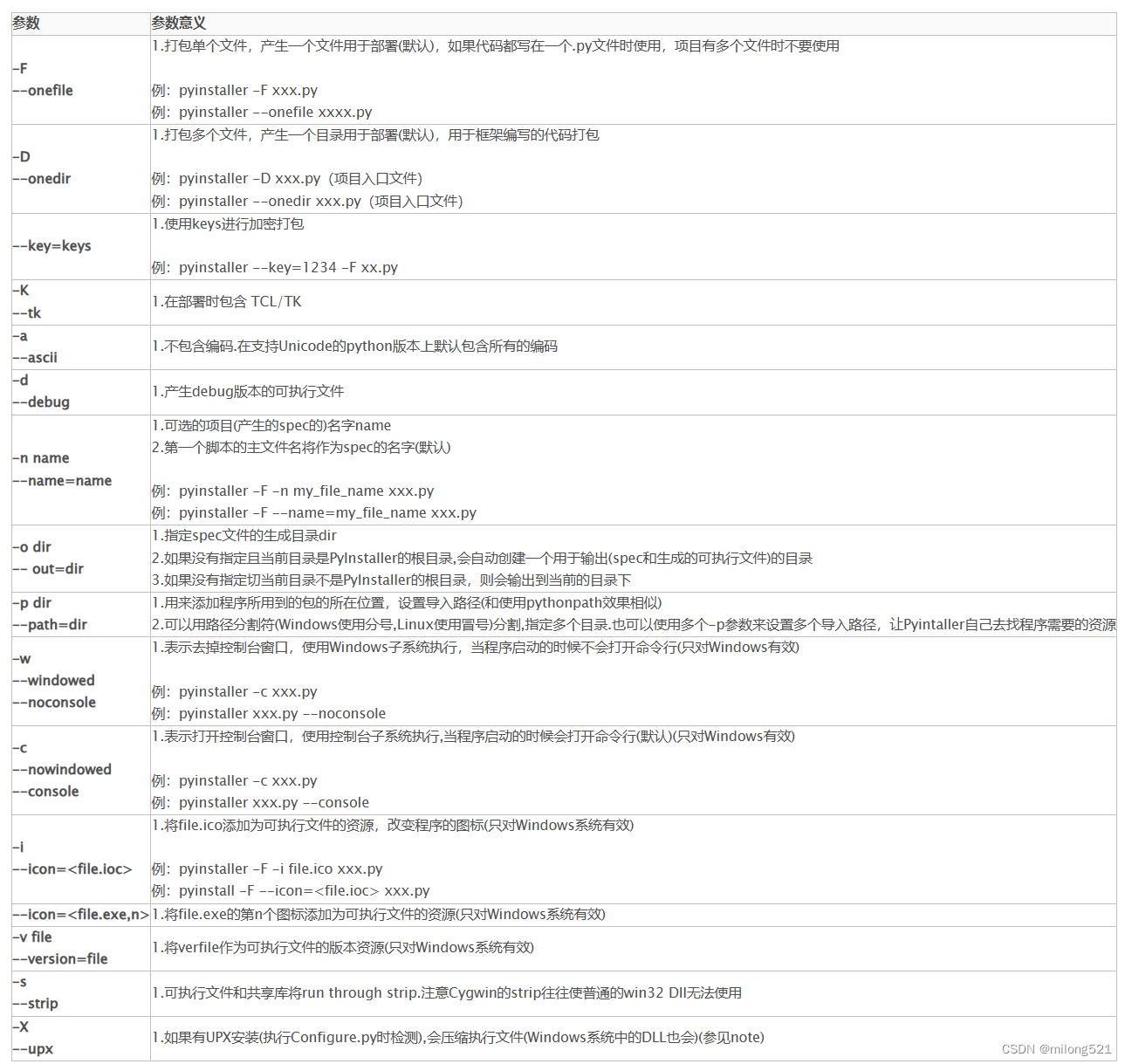
Pycharm打包程序为exe文件
Pycharm打包程序为exe文件 【一】导入模块pyinstaller 【1】图片说明 【2】文字说明 根据图片顺序执行 首先点击file进入settings界面,在setting界面找到Project下面的Python Interpretor,点击号进行模块的添加在搜索框中输入pyinstaller,…...

地理空间分析3——数据可视化与地理空间
写在开头 数据可视化是将数据以图形形式呈现,使其更易于理解和分析的过程。在地理空间分析中,数据可视化不仅能够展示地理位置信息,还能够有效地传达地理空间数据的模式、趋势和关联。本文将探讨数据可视化在地理空间分析中的作用,介绍Python中常用的数据可视化工具,并深…...
答案(4.3))
python开发案例教程-清华大学出版社(张基温)答案(4.3)
练习 4.1 1. 判断题 判断下列描述的对错。 (1)子类是父类的子集。 ( ✖ ) (2)父类中非私密的方法能够被子类覆盖。 ( ✔ ) (3)子类…...
Qt 5.9.4 转 Qt 6.6.1 遇到的问题总结(一)
最近公司对大家的开发的硬件环境进行了升级,电脑主机的配置、显示器(两台大屏显示器)变得的逼格高多了。既然电脑上的开发环境都需要重装,就打算把开发环境也升级到最新版本,要用就用最新版本。下面对升级后的开发环境…...

探索生成式AI:自动化、问题解决与创新力
目录 自动化和效率:生成式AI的颠覆力量 解谜大师生成式AI:如何理解和解决问题 创新与创造力的启迪:生成式AI的无限潜能 自动化和效率:生成式AI的颠覆力量 1. 神奇的代码生成器:生成式AI可以帮助开发人员像魔术一样快…...
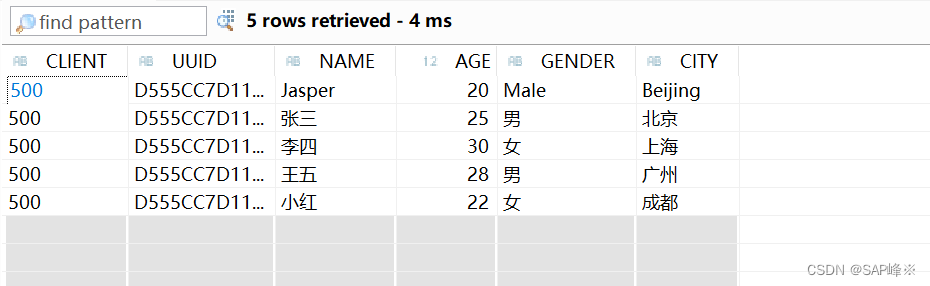
UI5与后端的文件交互(一)
文章目录 前言一、RAP的开发1. 创建表格2. 创建CDS Entity3. 创建BDEF4. 创建implementation class5. 创建Service Definition和Binding6. 测试API 二、创建UI5 Project1. 使用Basic模板创建2. 创建View3. 测试页面及绑定的oData数据是否正确4. 创建Controller5. 导入外部包&am…...

[HCTF 2018]Warmup
[HCTF 2018]Warmup wp 进入页面: 查看源码: 发现提示:source.php ,直接访问,得到源代码: <?phphighlight_file(__FILE__);class emmm{public static function checkFile(&$page){$whitelist [&qu…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...