图像分割实战-系列教程4:unet医学细胞分割实战2(医学数据集、图像分割、语义分割、unet网络、代码逐行解读)
🍁🍁🍁图像分割实战-系列教程 总目录
有任何问题欢迎在下面留言
本篇文章的代码运行界面均在Pycharm中进行
本篇文章配套的代码资源已经上传
unet医学细胞分割实战1
unet医学细胞分割实战2
unet医学细胞分割实战3
unet医学细胞分割实战4
unet医学细胞分割实战5
unet医学细胞分割实战6
4、train.py主函数解析
4.1 读取配置文件
def main():config = vars(parse_args())if config['name'] is None:if config['deep_supervision']:config['name'] = '%s_%s_wDS' % (config['dataset'], config['arch'])else:config['name'] = '%s_%s_woDS' % (config['dataset'], config['arch'])os.makedirs('models/%s' % config['name'], exist_ok=True)print('-' * 20)for key in config:print('%s: %s' % (key, config[key]))print('-' * 20)with open('models/%s/config.yml' % config['name'], 'w') as f:yaml.dump(config, f)
- main函数
- 解析命令行参数为字典
- 检查 config[‘name’] 是否为 None,如果是
- 它根据 config[‘deep_supervision’] 的布尔值来设置 config[‘name’], 如果config[‘deep_supervision’] 的值为True
- config[‘dataset’] 和 config[‘arch’] 的值,并在末尾添加 ‘_wDS’(表示“with Deep Supervision”)
- 如果为False,末尾则添加 ‘_woDS’(表示“without Deep Supervision”)
- 使用 config[‘name’] 来创建一个新目录。这个目录位于 ‘models/’ 目录下,目录名是 config[‘name’] 的值,exist_ok=True 参数的意思是如果目录已经存在,则不会抛出错误
- 打印符号
- 打印所有配置参数的名字和默认值
- 打印符号
- 根据模型名称创建一个.yaml文件
- 把所有配置信息全部写入文件中
4.2 定义模型参数
if config['loss'] == 'BCEWithLogitsLoss':criterion = nn.BCEWithLogitsLoss().cuda()#WithLogits 就是先将输出结果经过sigmoid再交叉熵
else:criterion = losses.__dict__[config['loss']]().cuda()
cudnn.benchmark = True
print("=> creating model %s" % config['arch'])
model = archs.__dict__[config['arch']](config['num_classes'], config['input_channels'], config['deep_supervision'])
model = model.cuda()
params = filter(lambda p: p.requires_grad, model.parameters())
- 定义损失函数,如果损失函数的配置的默认字符参数为BCEWithLogitsLoss
- 那么使用 PyTorch 中的
nn.BCEWithLogitsLoss作为损失函数,并且将损失函数的计算移入到GPU中计算,加快速度 - 如果不是
- 则从
losses.__dict__中查找对应的损失函数,同样使用 .cuda() 方法将损失函数移动到 GPU。(losses.__dict__应该是一个包含了多种损失函数的字典,其中键是损失函数的名称,值是相应的损失函数类,这个类是我们自己写的,在后面会解析) - 启用 CUDA 深度神经网络(cuDNN)的自动调优器,当设置为 True 时,cuDNN 会自动寻找最适合当前配置的算法来优化运行效率,这在使用固定尺寸的输入数据时往往可以加快训练速度
- 打印当前创建的模型的名字
- 动态实例化一个模型,
archs是一个包含多个网络架构的模块,archs.__dict__[config['arch']]这部分代码通过查找archs对象的__dict__属性来动态地选择一个网络架构,__dict__是一个包含对象所有属性的字典。在这里,它被用来获取名为config['arch']的网络架构类,config['arch']是一个字符串,表示所选用的架构名称 - 模型放入GPU中
4.3 定义优化器、调度器等参数
if config['optimizer'] == 'Adam':optimizer = optim.Adam(params, lr=config['lr'], weight_decay=config['weight_decay'])elif config['optimizer'] == 'SGD':optimizer = optim.SGD(params, lr=config['lr'], momentum=config['momentum'],nesterov=config['nesterov'], weight_decay=config['weight_decay'])else:raise NotImplementedErrorif config['scheduler'] == 'CosineAnnealingLR':scheduler = lr_scheduler.CosineAnnealingLR( optimizer, T_max=config['epochs'], eta_min=config['min_lr'])elif config['scheduler'] == 'ReduceLROnPlateau':scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, factor=config['factor'], patience=config['patience'],verbose=1, min_lr=config['min_lr'])elif config['scheduler'] == 'MultiStepLR':scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[int(e) for e in config['milestones'].split(',')], gamma=config['gamma'])elif config['scheduler'] == 'ConstantLR':scheduler = Noneelse:raise NotImplementedError- 创建一个过滤器,它筛选出神经网络模型中所有需要梯度(即可训练的)参数,
model.parameters(),返回模型的权重和偏置,lambda p: p.requires_grad: 这是一个匿名函数(lambda 函数),用于检查每个参数p是否需要梯度 - 如果优化器是 Adam
- 则指定参数、学习率、学习率衰减的参数给Adam
- 如果是SGD
- 则指定参数、学习率、学习率衰减的参数给SGD,此外还有momentum动量加速,此外还使用了一个自定义的类型转换函数 str2bool 来处理输入值
- 如果两者都不是
- 返回错误
- 如果学习率调度器为CosineAnnealingLR
- 给该调度器,指定优化器、epochs、最小学习率
- 如果是ReduceLROnPlateau
- 给该调度器,指定优化器、指定调整学习率时的乘法因子、指定在性能不再提升时减少学习率要等待多少周期、verbose=1: 这个设置意味着调度器会在每次更新学习率时打印一条信息、最小学习率
- 如果是MultiStepLR
- 给该调度器,指定优化器、何时降低学习率的周期数、gamma值
- 如果是ConstantLR
- 调度器为None
- 如果都不是
- 返回错误
4.4 数据增强
img_ids = glob(os.path.join('inputs', config['dataset'], 'images', '*' + config['img_ext']))img_ids = [os.path.splitext(os.path.basename(p))[0] for p in img_ids]train_img_ids, val_img_ids = train_test_split(img_ids, test_size=0.2, random_state=41)train_transform = Compose([transforms.RandomRotate90(),transforms.Flip(),OneOf([ transforms.HueSaturationValue(), transforms.RandomBrightness(), transforms.RandomContrast(), ], p=1),transforms.Resize(config['input_h'], config['input_w']),transforms.Normalize(),])val_transform = Compose([transforms.Resize(config['input_h'], config['input_w']),transforms.Normalize(),])
-
从本地文件夹inputs,根据config[‘dataset’]的值选择一个数据集,然后images文件,*代表后面所有的文件名称,加上config[‘img_ext’]对应的后缀,返回一个列表,列表的每个元素都是每条数据的路径加文件名和后缀名组成的字符串,类似这种形式:[‘inputs/dataset_name/images/image1.png’, ‘inputs/dataset_name/images/image2.png’, ‘inputs/dataset_name/images/image3.png’]
-
for p in img_ids按照每个字符串包含的信息,进行遍历,os.path.basename(p)从每个路径 p 中提取文件名,os.path.splitext(...)[0]则从文件名中去除扩展名,留下文件的基本名称(即 ID),最后是一个只包含文件名的list,即:[‘image1’, ‘image2’, ‘image3’] -
使用sklearn包的train_test_split函数,按照80%和20%的比例分为训练集和验证集,并且打乱数据集,41是随机种子
-
训练集数据增强
-
随机以 90 度的倍数旋转图像进行数据增强
-
水平或垂直翻转图像进行数据增强
-
从调整色调和饱和度和值(HSV)、随机调整图像的亮度、随机调整图像的对比度这个方式中随机选择一个进行数据增强
-
将图像调整到指定的高度和宽度
-
对图像进行标准化(比如减去均值,除以标准差)
-
验证集同样进行调整,是为了和训练集的尺寸、标准化等保存一致
-
调整和训练集一样的长宽
-
调整和训练一样的 标准化处理
4.5 数据集制作
train_dataset = Dataset(img_ids=train_img_ids,img_dir=os.path.join('inputs', config['dataset'], 'images'),mask_dir=os.path.join('inputs', config['dataset'], 'masks'),img_ext=config['img_ext'],mask_ext=config['mask_ext'],num_classes=config['num_classes'],transform=train_transform)
val_dataset = Dataset(img_ids=val_img_ids,img_dir=os.path.join('inputs', config['dataset'], 'images'),mask_dir=os.path.join('inputs', config['dataset'], 'masks'),img_ext=config['img_ext'],mask_ext=config['mask_ext'],num_classes=config['num_classes'],transform=val_transform)
- 使用自己写的数据集类制作训练数据集
- 返回图像数据id
- 返回图像数据路径
- 返回掩码数据路径,经过数据增强的时候,albumentations工具包能够自动的把数据做变换的同时标签也相应的变换
- 返回后缀
- 返回掩码后缀
- 分类的种类
- 数据增强(这里制定为None)
- 同样的给验证集也来一遍
train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=config['batch_size'],shuffle=True,num_workers=config['num_workers'],drop_last=True)
val_loader = torch.utils.data.DataLoader(val_dataset,batch_size=config['batch_size'],shuffle=False,num_workers=config['num_workers'],drop_last=False)log = OrderedDict([ ('epoch', []), ('lr', []), ('loss', []), ('iou', []), ('val_loss', []), ('val_iou', []), ])
- 制作训练集Dataloader
- 指定训练数据集
- batch_size
- 洗牌操作
- 进程数
- 不能整除的batch是否就不要了
- 同样的给验证集也来一遍
- 最后一行日志记录:创建
OrderedDict对象 log,将’epoch’、‘lr’、‘loss’、‘iou’、‘val_loss’、'val_iou’按照类似字典的形式进行存储(与字典不同的是它会记住插入元素的顺序)
4.6 迭代训练
best_iou = 0trigger = 0for epoch in range(config['epochs']):print('Epoch [%d/%d]' % (epoch, config['epochs']))train_log = train(config, train_loader, model, criterion, optimizer)val_log = validate(config, val_loader, model, criterion)if config['scheduler'] == 'CosineAnnealingLR':scheduler.step()elif config['scheduler'] == 'ReduceLROnPlateau':scheduler.step(val_log['loss'])print('loss %.4f - iou %.4f - val_loss %.4f - val_iou %.4f'% (train_log['loss'], train_log['iou'], val_log['loss'], val_log['iou']))log['epoch'].append(epoch)log['lr'].append(config['lr'])log['loss'].append(train_log['loss'])log['iou'].append(train_log['iou'])log['val_loss'].append(val_log['loss'])log['val_iou'].append(val_log['iou'])pd.DataFrame(log).to_csv('models/%s/log.csv' % config['name'], index=False)trigger += 1if val_log['iou'] > best_iou:torch.save(model.state_dict(), 'models/%s/model.pth' % config['name'])best_iou = val_log['iou']print("=> saved best model")trigger = 0if config['early_stopping'] >= 0 and trigger >= config['early_stopping']:print("=> early stopping")breaktorch.cuda.empty_cache()
- 记录最好的IOU的值
- trigger 是一个计数器,用于追踪自从模型上次改进(即达到更好的验证 IoU)以来经过了多少个训练周期(epochs),这种技术通常用于实现早停(early stopping)机制,以避免过度拟合
- 按照epochs进行迭代训练
- 打印当前epochs数,即训练进度
- 使用训练函数进行单个epoch的训练
- 使用验证函数进行单个epoch的验证
- 当使用
CosineAnnealingLR调度器时 scheduler.step()被直接调用,无需任何参数- 当使用
ReduceLROnPlateau调度器时 scheduler.step(val_log['loss'])调用时传入了验证集的损失 val_log[‘loss’] 作为参数- 打印当前epoch训练损失、训练iou
- 打印当前epoch验证损失、验证iou
- 当前epoch索引加入日志字典中
- 当前学习率值加入日志字典中
- 当前训练损失加入日志字典中
- 当前训练iou加入日志字典中
- 当前验证损失加入日志字典中
- 当前验证iou加入日志字典中
- 当前日志信息保存为csv文件
- trigger +1
- 如果当前验证iou的值比当前记录最佳iou的值要好
- 保存当前模型文件
- 更新最佳iou的值
- 打印保存了当前的最好模型
- 把trigger 置0
- 如果当前记录的trigger的值大于提前设置的trigger阈值
- 打印提前停止
- 停止训练
- 清除GPU缓存
自此,train.py的main函数部分全部解读完毕,其中有多个子函数或者类,在下一篇文章中继续解读
unet医学细胞分割实战1
unet医学细胞分割实战2
unet医学细胞分割实战3
unet医学细胞分割实战4
unet医学细胞分割实战5
unet医学细胞分割实战6
相关文章:
)
图像分割实战-系列教程4:unet医学细胞分割实战2(医学数据集、图像分割、语义分割、unet网络、代码逐行解读)
🍁🍁🍁图像分割实战-系列教程 总目录 有任何问题欢迎在下面留言 本篇文章的代码运行界面均在Pycharm中进行 本篇文章配套的代码资源已经上传 unet医学细胞分割实战1 unet医学细胞分割实战2 unet医学细胞分割实战3 unet医学细胞分割实战4 unet…...

防火墙未开端口导致zookeeper集群异常,kafka起不来
转载说明:如果您喜欢这篇文章并打算转载它,请私信作者取得授权。感谢您喜爱本文,请文明转载,谢谢。 问题描述: 主机信息: IPhostname10.0.0.10host1010.0.0.12host1210.0.0.13host13 在这三台主机上部署…...
:表单数据处理)
React-hook-form-mui(二):表单数据处理
前言 在上一篇文章中,我们介绍了react-hook-form-mui的基础用法。本文将着表单数据处理。 react-hook-form-mui提供了丰富的表单数据处理功能,可以通过watch属性来获取表单数据。 Demo 下面是一个使用watch属性的例子: import React from…...

java网络文件地址url的转换为MultipartFile文件流
废话不多说,直接上代码 一、异常捕捉类 public class BusinessException extends RuntimeException {public BusinessException(String msg){super(msg);} }二、转换类 package com.example.answer_system.utils;import org.springframework.mock.web.MockMultipa…...

JS实现/封装节流函数
封装节流函数 节流原理:在一定时间内,只能触发一次 let timer, flag; /*** 节流原理:在一定时间内,只能触发一次* * param {Function} func 要执行的回调函数 * param {Number} wait 延时的时间* param {Boolean} immediate 是否立…...

ENVI 各版本安装指南
ENVI下载链接 https://pan.baidu.com/s/1APpjHHSsrXMaCcJUQGmFBA?pwd0531 1.鼠标右击【ENVI 5.6(64bit)】压缩包(win11及以上系统需先点击“显示更多选项”)选择【解压到 ENVI 5.6(64bit)】。 2.打开解压后的文件夹,…...

60天零基础干翻C++————初识C++
初识c 命名空间命名空间的定义命名空间的使用 输入输出流缺省参数引用引用定义常量的引用引用的使用场景做函数参数引用做返回值 命名空间 命名空间的定义 在c语言中会有下面问题 上述代码中,全局变量rand 可能会命名冲突,如下图 此时编译失败&…...

考研复试英语口语问答举例第二弹
考研复试英语口语问答举例第二弹 文章目录 考研复试英语口语问答举例第二弹Question :介绍你的读研兴趣与动机Answer11:(自动化控制方向)Answer12:(集成电路方向)Answer13:ÿ…...

MyBatis-Plus实现自定义SQL语句的分页查询
正常开发的时候,有时候要写一个多表查询,然后多表查询之后还需要分页,MyBatis-Plus的分页插件功能挺不错的,可以很简单实现自定义SQL的分页查询。 分页插件配置 import com.baomidou.mybatisplus.annotation.DbType; import com…...

vue3 里的 ts 类型工具函数
目录 前言一、PropType\<T>二、MaybeRef\<T>三、MaybeRefOrGetter\<T>四、ExtractPropTypes\<T>五、ExtractPublicPropTypes\<T>六、ComponentCustomProperties七、ComponentCustomOptions八、ComponentCustomProps九、CSSProperties 前言 相关 …...

【SpringCloud】之远程消费(进阶使用)
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是君易--鑨,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的博客专栏《SpringCloud开发之远程消费》。🎯&a…...
自然语言处理24-T5模型的介绍与训练过程,利用简单构造数据训练微调该模型,体验整个过程
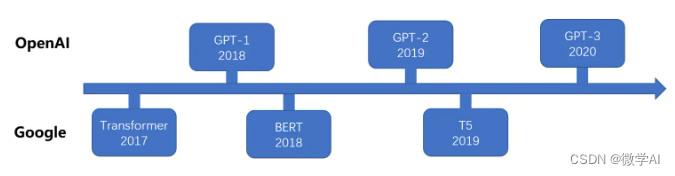
大家好,我是微学AI,今天给大家介绍一下自然语言处理24-T5模型的介绍与训练过程,利用简单构造数据训练微调该模型,体验整个过程。在大模型ChatGPT发布之前,NLP领域是BERT,T5模型为主导,T5(Text-to-Text Transfer Transformer)是一种由Google Brain团队在2019年提出的自然…...

CISSP 第5章 保护资产的安全
1、资产识别和分类 1.1 敏感数据 1.1.1 定义 敏感数据是任何非公开或非机密的信息,包括机密的、专有的、受保护的或因其对组织的价值或按照现有的法律和法规而需要组织保护的任何其他类型的数据。 1.1.2 个人身份信息PII 个人身份信息(PII)…...

docker安装-在linux下的安装步骤
#切换到root用户 su yum安装jcc相关 yum -y install gcc yum -y install gcc-c 安装yum-utils sudo yum install -y yum-utils 设置stable镜像仓库 sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo 更新yum软件包索…...
在Uniapp中使用Echarts创建可视化图表
在uniapp中可以引入echarts创建数据可视化图表。 1. 安装Echarts 使用npm安装echarts插件,命令如下: npm install echarts --save2. 引入Eharts 在需要使用Echarts的页面引入: import *as echarts from echarts3. 创建实例 创建画布元素…...
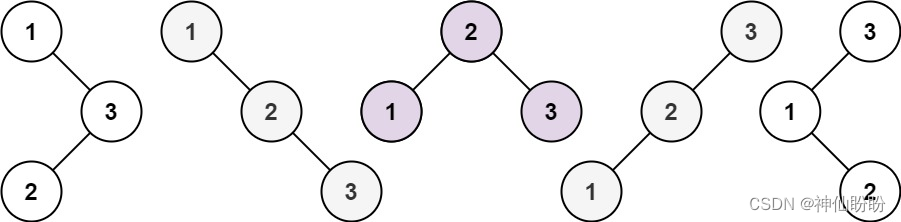
基于python的leetcode算法介绍之动态规划
文章目录 零 算法介绍一 例题介绍 使用最小花费爬楼梯问题分析 Leetcode例题与思路[118. 杨辉三角](https://leetcode.cn/problems/pascals-triangle/)解题思路题解 [53. 最大子数组和](https://leetcode.cn/problems/maximum-subarray/)解题思路题解 [96. 不同的二叉搜索树](h…...

通信原理期末复习——计算大题(一)
个人名片: 🦁作者简介:一名喜欢分享和记录学习的在校大学生 🐯个人主页:妄北y 🐧个人QQ:2061314755 🐻个人邮箱:2061314755qq.com 🦉个人WeChat:V…...
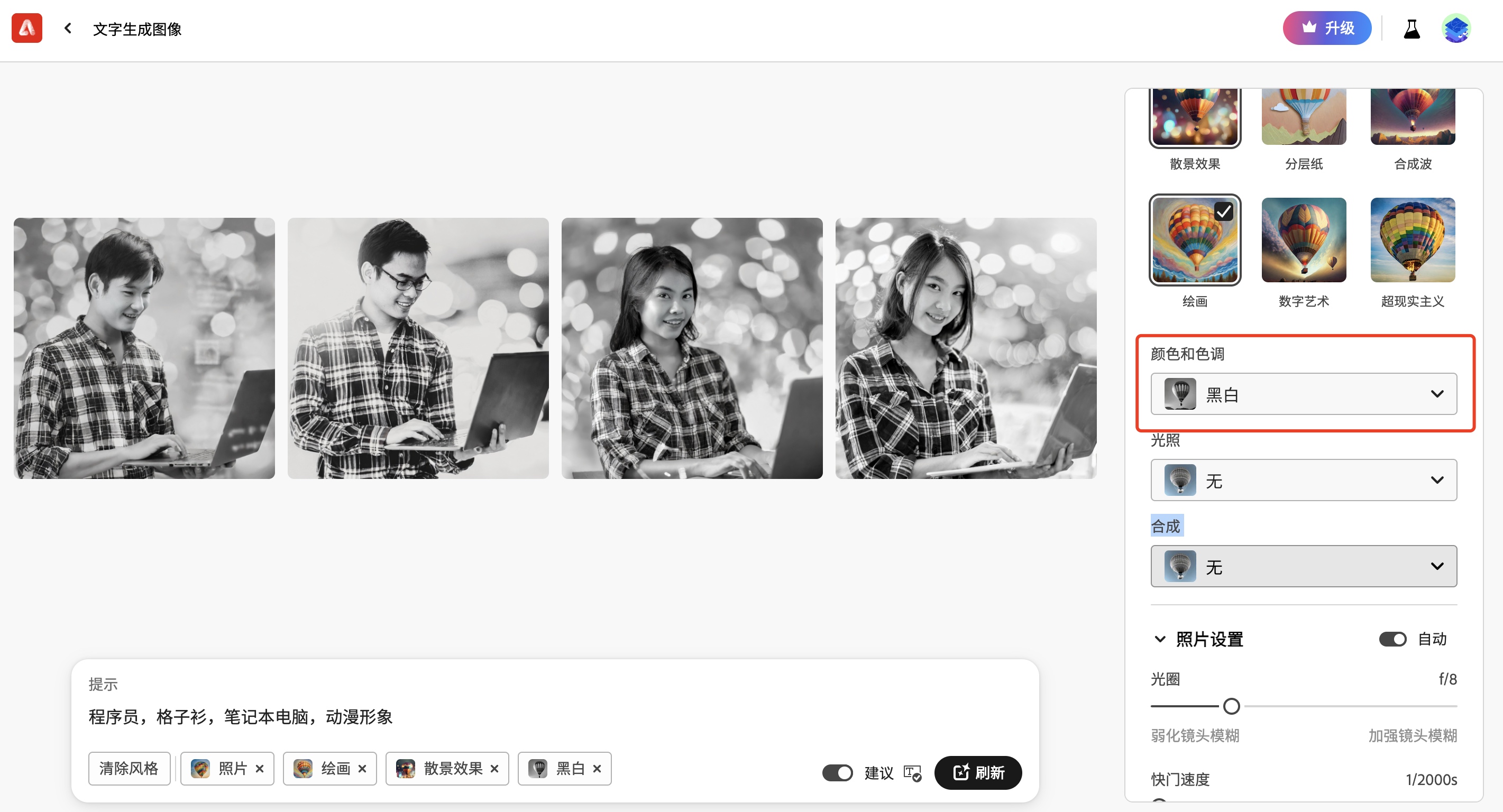
【萤火虫系列教程】2/5-Adobe Firefly 文字生成图像
文字生成图像 登录账号后,在主页点击文字生成图像的【生成】按钮,进入到文字生成图像 查看图像 在文字生成图像页面,可以看到别人生成的图像。 点击某个图像,就可以进入图像详情,可以看到文字描述。 生成图像 我…...

JDK 11:崭新特性解析
JDK 11:崭新特性解析 JDK 11:崭新特性解析1. HTTP Client(标准化)示例代码 2. 局部变量类型推断的扩展示例代码 3. 新的字符串方法示例代码 4. 动态类文件常量示例代码 5. Epsilon 垃圾收集器使用方式 结语 JDK 11:崭新…...

leetcode.在链表中插入最大公约数
文章目录 题目解题方法复杂度Code Problem: 2807. 在链表中插入最大公约数 题目 给你一个链表的头 head ,每个结点包含一个整数值。 在相邻结点之间,请你插入一个新的结点,结点值为这两个相邻结点值的 最大公约数 。 请你返回插入之后的链表。…...

Ollama快速上手:EmbeddingGemma-300m助力专利工程师效率翻倍
Ollama快速上手:EmbeddingGemma-300m助力专利工程师效率翻倍 1. 为什么专利工程师需要EmbeddingGemma-300m? 专利工程师每天都要处理大量技术文档,从专利申请到专利检索,再到技术分析,工作量巨大且重复性高。传统的人…...

HMS Core推送token获取失败?6003错误码的5种常见原因及解决方案
HMS Core推送token获取失败?6003错误码深度解析与实战解决方案 当你正在开发一款集成华为推送服务的应用时,突然遇到客户端调用getToken方法失败并返回6003错误码,屏幕上赫然显示com.huawei.hms.common.ApiException: 6003: certificate fing…...

《WebPages PHP:深入理解PHP在网页开发中的应用》
《WebPages PHP:深入理解PHP在网页开发中的应用》 引言 随着互联网技术的飞速发展,PHP作为一门成熟的编程语言,在网页开发领域发挥着举足轻重的作用。本文将从PHP的基本概念、开发环境搭建、常用函数、面向对象编程以及安全防护等方面,全面介绍PHP在网页开发中的应用。 …...

GTE文本向量中文大模型保姆级教程:从部署到旅游评论分析全流程
GTE文本向量中文大模型保姆级教程:从部署到旅游评论分析全流程 1. 引言:为什么需要文本向量模型? 想象一下,你正在经营一家旅游平台,每天新增数万条用户评论。如何从这些海量文字中快速了解游客对景点的真实评价&…...

算力基建分类-基础算力、智能算力与超算的区别
算力基建分类:基础算力、智能算力与超算的区别📚 本章学习目标:深入理解基础算力、智能算力与超算的区别的核心概念与实践方法,掌握关键技术要点,了解实际应用场景与最佳实践。本文属于《云原生、云边端一体化与算力基…...

EasyDMX:ESP32平台DMX512全双工通信实现方案
1. EasyDMX库深度解析:面向ESP32的DMX512全双工通信实现方案1.1 库定位与工程价值EasyDMX是一个专为ESP32平台设计的轻量级DMX512协议栈,其核心目标并非替代专业级舞台控制设备,而是解决嵌入式开发者在中小型灯光控制系统、互动装置、教育实验…...

CH582/CH592/CH584硬件SPI驱动OLED屏实战:从引脚配置到显示优化全流程
CH582/CH592/CH584硬件SPI驱动OLED屏全流程实战指南 在嵌入式开发中,SPI接口因其高速、全双工的特性,成为驱动OLED显示屏的首选方案。WCH的CH582、CH592和CH584三款芯片在物联网和嵌入式领域应用广泛,但开发者在使用其SPI接口驱动OLED时&…...

解决UniApp Camera拍照区域裁剪难题:我的Canvas绘制与上传优化方案
UniApp Camera精准裁剪与性能优化实战:从VIN码识别到文档扫描 在移动应用开发中,相机功能的高效实现往往决定着核心用户体验。特别是在需要精确识别特定区域内容的场景下——无论是汽车VIN码扫描、证件识别还是文档数字化处理——开发者都会面临三个关键…...

Nuclei Studio工程编译与调试实战:如何高效配置GD-Link和OpenOCD
Nuclei Studio工程编译与调试实战:GD-Link与OpenOCD高效配置指南 引言 在嵌入式开发领域,高效的编译与调试流程往往能决定项目的成败。对于使用RISC-V架构GD32VF103系列MCU的开发者而言,Nuclei Studio作为官方推荐的集成开发环境,…...

C语言基础:AnythingtoRealCharacters2511模型底层优化入门
C语言基础:AnythingtoRealCharacters2511模型底层优化入门 1. 从动漫到真实的魔法背后 你可能已经用过一些AI工具,把动漫头像变成真人照片,感觉很神奇对吧?但你知道吗,这些看似简单的转换背后,其实是一大…...