debug mccl 02 —— 环境搭建及初步调试
1, 搭建nccl 调试环境
下载 nccl 源代码
git clone --recursive https://github.com/NVIDIA/nccl.git
只debug host代码,故将设备代码的编译标志改成 -O3
(base) hipper@hipper-G21:~/let_debug_nccl/nccl$ git diff
diff --git a/makefiles/common.mk b/makefiles/common.mk
index a037cf3..ee2aa8e 100644
--- a/makefiles/common.mk
+++ b/makefiles/common.mk
@@ -82,7 +82,8 @@ ifeq ($(DEBUG), 0)NVCUFLAGS += -O3CXXFLAGS += -O3 -gelse
-NVCUFLAGS += -O0 -G -g
+#NVCUFLAGS += -O0 -G -g
+NVCUFLAGS += -O3CXXFLAGS += -O0 -g -ggdb3endif修改后变成如下:
nccl$ vim makefiles/common.mk
ifeq ($(DEBUG), 0)
NVCUFLAGS += -O3
CXXFLAGS += -O3 -g
else
#NVCUFLAGS += -O0 -G -g
NVCUFLAGS += -O3
CXXFLAGS += -O0 -g -ggdb3
endif
构建 nccl shared library:
机器上是几张sm_85 的卡,故:
$ cd nccl
$ make -j src.build DEBUG=1 NVCC_GENCODE="-gencode=arch=compute_80,code=sm_80"到此即可,不需要安装nccl,直接过来使用即可;
2, 创建调试APP
在nccl所在的目录中创建app文件夹:
$ mkdir app$ cd app$ vim sp_md_nccl.cpp$ vim Makefilesp_md_nccl.cpp:
#include <stdlib.h>
#include <stdio.h>
#include "cuda_runtime.h"
#include "nccl.h"
#include <time.h>
#include <sys/time.h>#define CUDACHECK(cmd) do { \cudaError_t err = cmd; \if (err != cudaSuccess) { \printf("Failed: Cuda error %s:%d '%s'\n", \__FILE__,__LINE__,cudaGetErrorString(err)); \exit(EXIT_FAILURE); \} \
} while(0)#define NCCLCHECK(cmd) do { \ncclResult_t res = cmd; \if (res != ncclSuccess) { \printf("Failed, NCCL error %s:%d '%s'\n", \__FILE__,__LINE__,ncclGetErrorString(res)); \exit(EXIT_FAILURE); \} \
} while(0)void get_seed(long long &seed)
{struct timeval tv;gettimeofday(&tv, NULL);seed = (long long)tv.tv_sec * 1000*1000 + tv.tv_usec;//only second and usecond;printf("useconds:%lld\n", seed);
}void init_vector(float* A, int n)
{long long seed = 0;get_seed(seed);srand(seed);for(int i=0; i<n; i++){A[i] = (rand()%100)/100.0f;}
}void print_vector(float* A, float size)
{for(int i=0; i<size; i++)printf("%.2f ", A[i]);printf("\n");
}void vector_add_vector(float* sum, float* A, int n)
{for(int i=0; i<n; i++){sum[i] += A[i];}
}int main(int argc, char* argv[])
{ncclComm_t comms[4];printf("ncclComm_t is a pointer type, sizeof(ncclComm_t)=%lu\n", sizeof(ncclComm_t));//managing 4 devices//int nDev = 4;int nDev = 2;//int size = 32*1024*1024;int size = 16*16;int devs[4] = { 0, 1, 2, 3 };float** sendbuff_host = (float**)malloc(nDev * sizeof(float*));float** recvbuff_host = (float**)malloc(nDev * sizeof(float*));for(int dev=0; dev<nDev; dev++){sendbuff_host[dev] = (float*)malloc(size*sizeof(float));recvbuff_host[dev] = (float*)malloc(size*sizeof(float));init_vector(sendbuff_host[dev], size);init_vector(recvbuff_host[dev], size);}//sigma(sendbuff_host[i]); i = 0, 1, ..., nDev-1float* result = (float*)malloc(size*sizeof(float));memset(result, 0, size*sizeof(float));for(int dev=0; dev<nDev; dev++){vector_add_vector(result, sendbuff_host[dev], size);printf("sendbuff_host[%d]=\n", dev);print_vector(sendbuff_host[dev], size);}printf("result=\n");print_vector(result, size);//allocating and initializing device buffersfloat** sendbuff = (float**)malloc(nDev * sizeof(float*));float** recvbuff = (float**)malloc(nDev * sizeof(float*));cudaStream_t* s = (cudaStream_t*)malloc(sizeof(cudaStream_t)*nDev);for (int i = 0; i < nDev; ++i) {CUDACHECK(cudaSetDevice(i));CUDACHECK(cudaMalloc(sendbuff + i, size * sizeof(float)));CUDACHECK(cudaMalloc(recvbuff + i, size * sizeof(float)));CUDACHECK(cudaMemcpy(sendbuff[i], sendbuff_host[i], size*sizeof(float), cudaMemcpyHostToDevice));CUDACHECK(cudaMemcpy(recvbuff[i], recvbuff_host[i], size*sizeof(float), cudaMemcpyHostToDevice));CUDACHECK(cudaStreamCreate(s+i));}//initializing NCCLNCCLCHECK(ncclCommInitAll(comms, nDev, devs));//calling NCCL communication API. Group API is required when using//multiple devices per threadNCCLCHECK(ncclGroupStart());printf("blocked ncclAllReduce will be calleded\n");fflush(stdout);for (int i = 0; i < nDev; ++i)NCCLCHECK(ncclAllReduce((const void*)sendbuff[i], (void*)recvbuff[i], size, ncclFloat, ncclSum, comms[i], s[i]));printf("blocked ncclAllReduce is calleded nDev =%d\n", nDev);fflush(stdout);NCCLCHECK(ncclGroupEnd());//synchronizing on CUDA streams to wait for completion of NCCL operationfor (int i = 0; i < nDev; ++i) {CUDACHECK(cudaSetDevice(i));CUDACHECK(cudaStreamSynchronize(s[i]));}for (int i = 0; i < nDev; ++i) {CUDACHECK(cudaSetDevice(i));CUDACHECK(cudaMemcpy(recvbuff_host[i], recvbuff[i], size*sizeof(float), cudaMemcpyDeviceToHost));}for (int i = 0; i < nDev; ++i) {CUDACHECK(cudaSetDevice(i));CUDACHECK(cudaStreamSynchronize(s[i]));}for(int i=0; i<nDev; i++) {printf("recvbuff_dev2host[%d]=\n", i);print_vector(recvbuff_host[i], size);}//free device buffersfor (int i = 0; i < nDev; ++i) {CUDACHECK(cudaSetDevice(i));CUDACHECK(cudaFree(sendbuff[i]));CUDACHECK(cudaFree(recvbuff[i]));}//finalizing NCCLfor(int i = 0; i < nDev; ++i)ncclCommDestroy(comms[i]);printf("Success \n");return 0;
}Makefile:
INC := -I /usr/local/cuda/include -I ../nccl/build/include
LD_FLAGS := -L ../nccl/build/lib -lnccl -L /usr/local/cuda/lib64 -lcudartEXE := singleProc_multiDev_ncclall: $(EXE)%: %.cppg++ -g -ggdb3 $< -o $@ $(INC) $(LD_FLAGS).PHONY: clean
clean: -rm -rf $(EXE)export LD_LIBRARY_PATH=../nccl/build/lib
3, 开始调试
$ cuda-gdb sp_md_nccl(cuda-gdb) start (cuda-gdb) rbreak doLauches(cuda-gdb) c(cuda-gdb) p ncclGroupCommHead->tasks.collQueue.head->op 初步实现了可debug的效果:
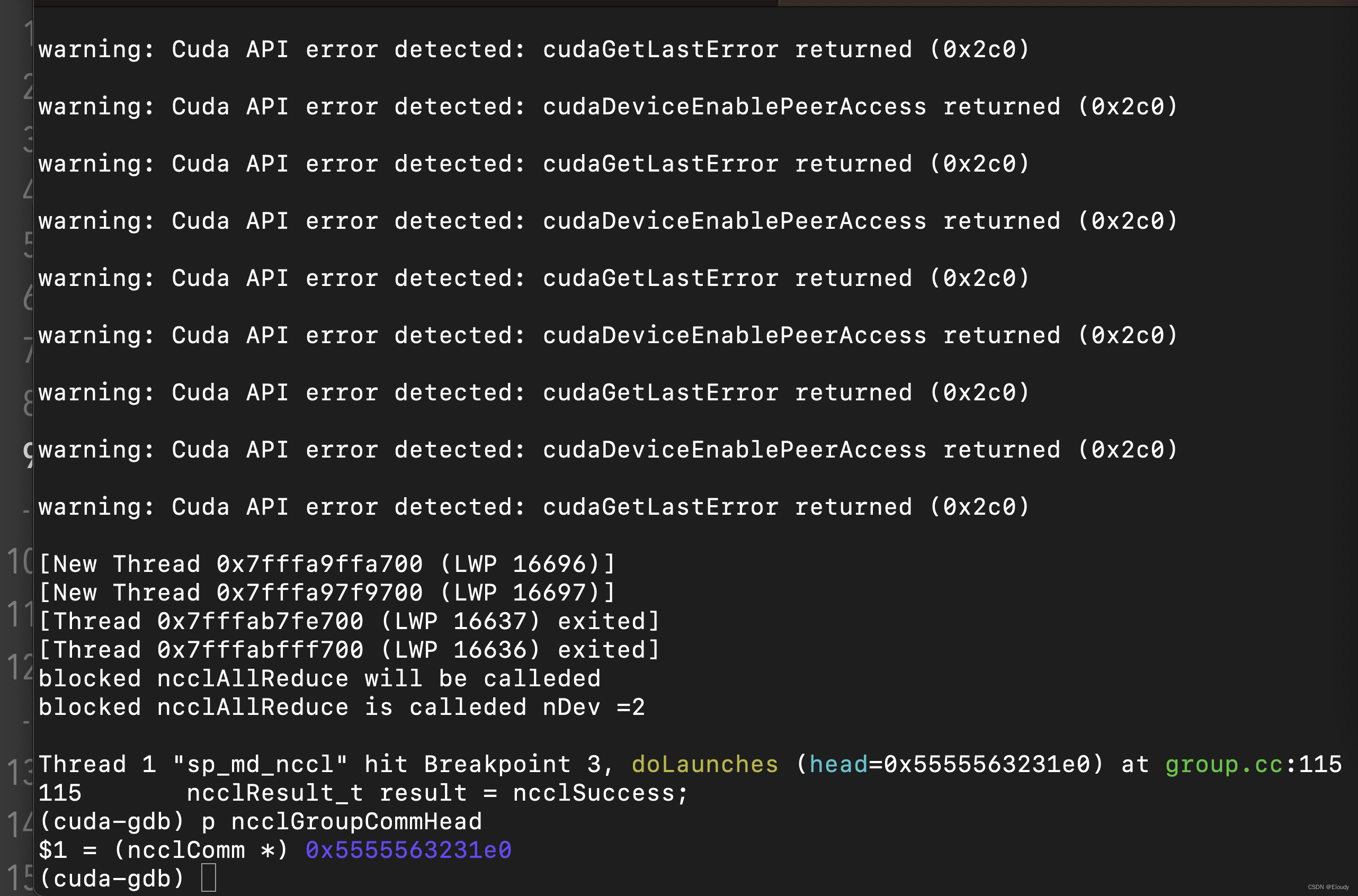
现在想要搞清楚在程序调用 ncclAllReduce(..., ncclSum, ... ) 后,是如何映射到 cudaLaunchKernel调用到了正确的 cuda kernel 函数的。
在doLaunches函数中,作如下debug动作:
查看 doLaunches(ncclComm*) 的函数参数,即,gropu.cc中的变量:ncclGroupCommHead的某个成员的成员的值:op
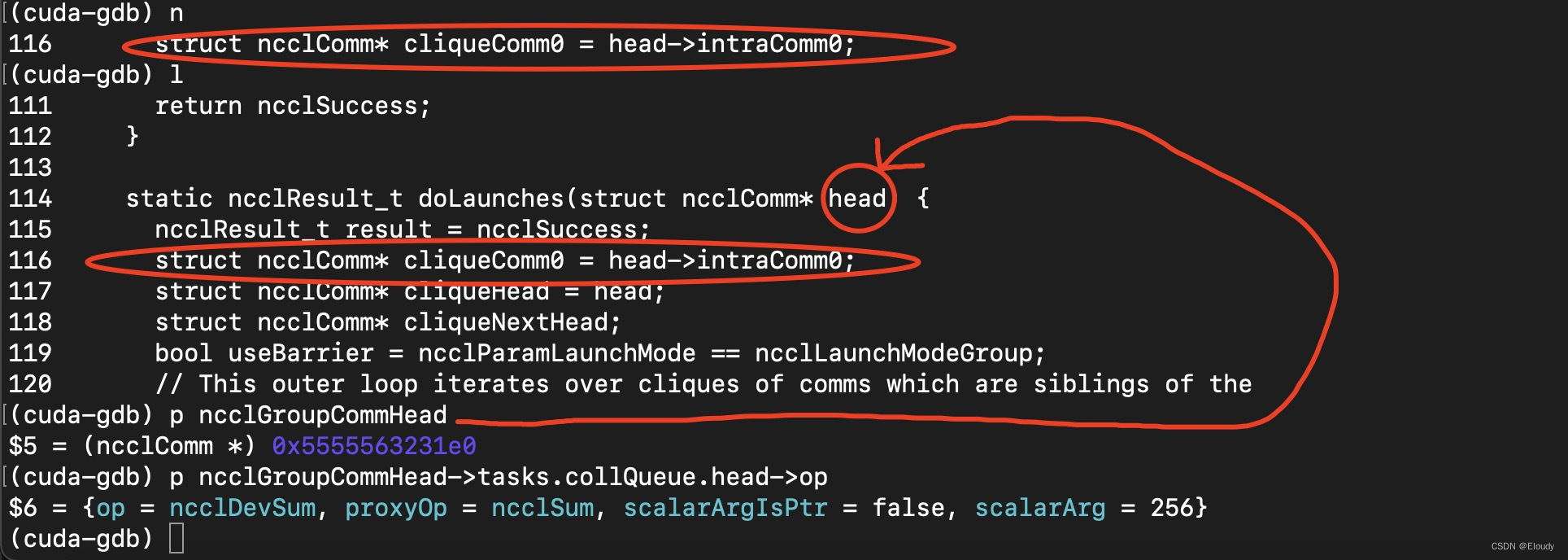
其结果如下:
(cuda-gdb) p ncclGroupCommHead
$5 = (ncclComm *) 0x5555563231e0
(cuda-gdb) p ncclGroupCommHead->tasks.collQueue.head->op
$6 = {op = ncclDevSum, proxyOp = ncclSum, scalarArgIsPtr = false, scalarArg = 256}
(cuda-gdb) 不过这依然只停留在了 ncclSum的这个枚举类型上,还没锁定对应的cudaKernel。
接下来继续努力 ...
相关文章:
debug mccl 02 —— 环境搭建及初步调试
1, 搭建nccl 调试环境 下载 nccl 源代码 git clone --recursive https://github.com/NVIDIA/nccl.git 只debug host代码,故将设备代码的编译标志改成 -O3 (base) hipperhipper-G21:~/let_debug_nccl/nccl$ git diff diff --git a/makefiles/common.mk b/makefiles/…...

ros python 接收GPS RTK 串口消息再转发 ros 主题消息
代码是一个ROS(Robot Operating System)节点,用于从GPS设备读取RTK(实时动态)数据并通过ROS主题发布。 步骤: 导入必要的模块: rospy 是ROS的Python库,用于ROS的节点、发布者和订阅者。serial 用于串行通信。NavSatFix 和 NavSatStatus 是从GPS接收的NMEA 0183标准消息…...

2024年网络安全竞赛-页面信息发现任务解析
页面信息发现任务说明: 服务器场景:win20230305(关闭链接)在渗透机中对服务器信息收集,将获取到的服务器网站端口作为Flag值提交;访问服务器网站页面,找到主页面中的Flag值信息,将Flag值提交;访问服务器网站页面,找到主页面中的脚本信息,并将Flag值提交;访问服务器…...

ARM DMA使用整理
Direct Memory Access, 直接存储访问。同SPI,IIC,USART等一样,属于MCU的一个外设,用于在不需要MCU介入的情况下进行数据传输。可以将数据从外设传输到flash,也可以将数据从flash传输到外设,或者flash内部数据移动。 它…...
移动通信原理与关键技术学习(第四代蜂窝移动通信系统)
前言:LTE 标准于2008 年底完成了第一个版本3GPP Release 8的制定工作。另一方面,ITU 于2007 年召开了世界无线电会议WRC07,开始了B3G 频谱的分配,并于2008 年完成了IMT-2000(即3G)系统的演进——IMT-Advanc…...

光明源@智慧厕所技术:优化生活,提升卫生舒适度
在当今数字科技飞速发展的时代,我们的日常生活正在经历一场革命,而这场革命的其中一个前沿领域就是智慧厕所技术。这项技术不仅仅是对传统卫生间的一次升级,更是对我们生活品质的全方位提升。从智能感应到数据分析,从环保设计到舒…...

【Bootstrap学习 day13】
Bootstrap5 下拉菜单 下拉菜单通常用于导航标题内,在用户鼠标悬停或单击触发元素时显示相关链接列表。 基础的下拉列表 <div class"dropdown"><button type"button" class"btn btn-primary dropdown-toggle" data-bs-toggl…...

Shell:常用命令之dirname与basename
一、介绍 1、dirname命令用于去除文件名中的非目录部分,删除最后一个“\”后面的路径,显示父目录。 语法:dirname [选项] 参数 2、basename命令用于打印目录或者文件的基本名称,显示最后的目录名或文件名。 语法:basen…...
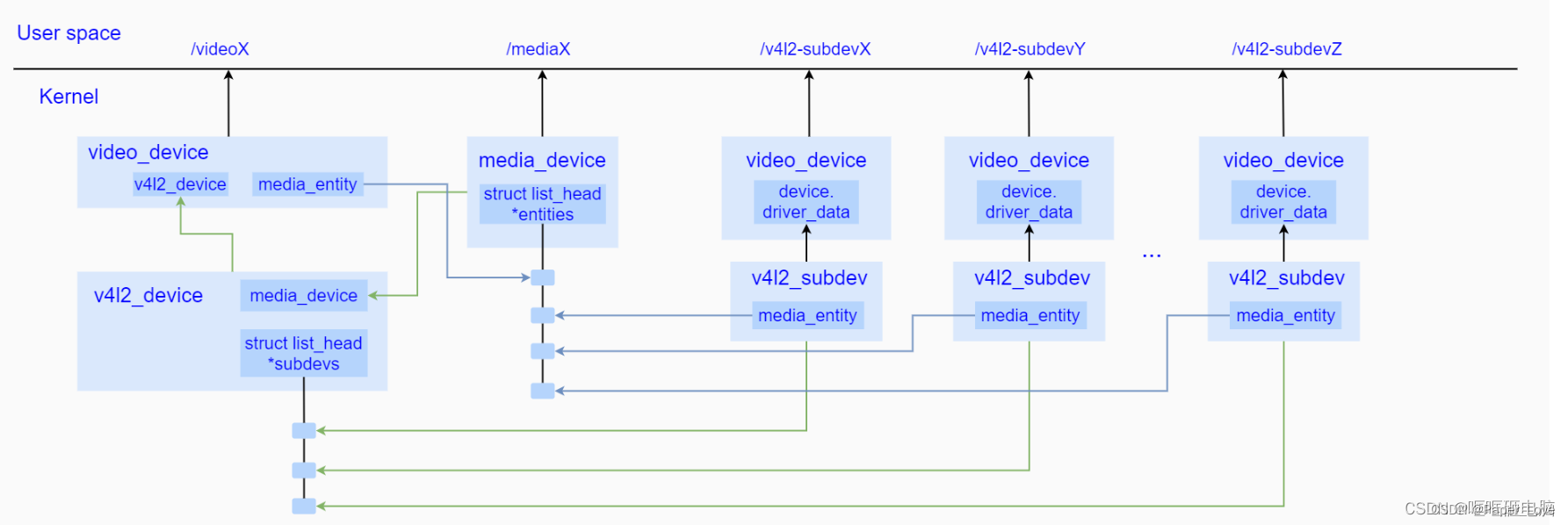
Linux-v4l2框架
框架图 从上图不难看出,v4l2_device作为顶层管理者,一方面通过嵌入到一个video_device中,暴露video设备节点给用户空间进行控制;另一方面,video_device内部会创建一个media_entity作为在media controller中的抽象体&a…...

VPC网络架构下的网络上数据采集
介绍 想象这样一个场景,一开始在公司里,所有的部门的物理机、POD都在一个经典网络内,它们可以通过 IP 访问彼此,没有任何限制。因此有很多系统基于此设计了很多点对点 IP 直连的访问,比如中心控制服务器 S 会主动访问物…...

模拟算法(模拟算法 == 依葫芦画瓢)万字
模拟算法 基本思想引入算法题替换所有的问号提莫攻击Z字形变换外观数列数青蛙 基本思想 模拟算法 依葫芦画瓢解题思维要么通俗易懂,要么就是找规律,主要难度在于将思路转换为代码。 特点:相对于其他算法思维,思路比较简单&#x…...

QtApplets-SystemInfo
QtApplets-SystemInfo 今天是2024年1月3日09:18:44,这也是2024年的第一篇博客,今天我们主要两件事,第一件,获取系统CPU使用率,第二件,获取系统内存使用情况。 这里因为写博客的这个本本的环境配置不…...

vue3防抖函数封装与使用,以指令的形式使用
utils/debounce.js /*** 防抖函数* param {*} fn 函数* param {*} delay 暂停时间* returns */ export function debounce(fn, delay 500) {let timer nullreturn function (...args) {// console.log(arguments);// const args Array.from(arguments)if (timer) {clearTim…...
Hive学习(13)lag和lead函数取偏移量
hive里面lag函数 在数据处理和分析中,窗口函数是一种重要的技术,用于在数据集中执行聚合和分析操作。Hive作为一种大数据处理框架,也提供了窗口函数的支持。在Hive中,Lag函数是一种常用的窗口函数,可以用于计算前一行…...

Centos Unable to verify the graphical display setup
ERROR: Unable to verify the graphical display setup. 在Linux下安装Oracle时 运行 ./runInstaller 报错 ERROR: Unable to verify the graphical display setup. This application requires X display. Make sure that xdpyinfo exist under PATH variable. No X11 DISPL…...

Java 说一下 synchronized 底层实现原理?
Java 说一下 synchronized 底层实现原理? synchronized 是 Java 中用于实现同步的关键字,它保证了多个线程对共享资源的互斥访问。底层实现涉及到对象头的 Mark Word 和锁升级过程。 synchronized 可以用于方法上或代码块上,分别对应于方法…...

nginx访问路径匹配方法
目录 一:匹配方法 二:location使用: 三:rewrite使用 一:匹配方法 location和rewrite是两个用于处理请求的重要模块,它们都可以根据请求的路径进行匹配和处理。 二:location使用: 1:简单匹配…...

偌依 项目部署及上线步骤
准备实验环境,准备3台机器 1.作为前端服务器,mysql,redis服务器--同时临时作为代码打包服务器 192.168.2.65 nginx-server 2.作为后端服务器 192.168.2.66 java-server-1 192.168.2.67 java-server-2 安装nginx/mysql #安装nginx [rootweb-nginx ~]…...

PHP特性知识点扫盲 - 上篇
概述 之前在分析thinkphp源码的时候,对依赖注入等等php高级的特性一直想做一个梳理和总结,一直没有时间,好不容易抽一点时间对技术的盲点做一个扫盲和总结。 特性 1.命名空间 命名空间是在PHP5.3中引入,是一个很重要的工具&am…...
Docker一键极速安装Nacos,并配置数据库!
1 部署方式 1.1 DockerHub javaedgeJavaEdgedeMac-mini ~ % docker run --name nacos \ -e MODEstandalone \ -e JVM_XMS128m \ -e JVM_XMX128m \ -e JVM_XMN64m \ -e JVM_MS64m \ -e JVM_MMS64m \ -p 8848:8848 \ -d nacos/nacos-server:v2.2.3 a624c64a1a25ad2d15908a67316d…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

如何在看板中有效管理突发紧急任务
在看板中有效管理突发紧急任务需要:设立专门的紧急任务通道、重新调整任务优先级、保持适度的WIP(Work-in-Progress)弹性、优化任务处理流程、提高团队应对突发情况的敏捷性。其中,设立专门的紧急任务通道尤为重要,这能…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...

2025年低延迟业务DDoS防护全攻略:高可用架构与实战方案
一、延迟敏感行业面临的DDoS攻击新挑战 2025年,金融交易、实时竞技游戏、工业物联网等低延迟业务成为DDoS攻击的首要目标。攻击呈现三大特征: AI驱动的自适应攻击:攻击流量模拟真实用户行为,差异率低至0.5%,传统规则引…...