数据库定义和操作语句的重要语法
数据库📊的10种语法
数据查询语句
- select : 用于从数据库中检索数据。
select column1, column2,....
from table_name
where condition;- select distinct : 用于从数据库中检索唯一的数据值。
select DISTINCT column1, clumn2,...
from table_name;工作原理如下:
- 数据库系统会遍历指定列的所有值。
- 系统会将遇到的每个不同的值添加到结果集中。
- 最终,结果集中将包含列中的所有唯一值。
这种方法适用于任何列,但对于大型数据集可能会产生一些性能开销,因为数据库需要遍历整个列来找到唯一值。
- order by : 用于对查询结果进行排序。用在select的末尾。
select column1,column2, ...
from table_name
order by column1 [ASC|DESC], column2 [ASC|DESC],...;数据插入、更新和删除语句
- insert into : 用于将新数据插入到数据库表中。
insert into table_name (column1, column2, column3...)
values (value1, value2, value3,...);
- update : 用于更新数据库表中的现有数据。
update table_name
set column1=value1, column2=value2,...
where condition;- delete from : 用于从数据库表中删除数据。
delete from table_name
where condition;数据库结构定义和修改语句
- create table : 用于创建数据库表。
create table_name(column1 datetype,column2 datatype,...
);- alter table : 用于修改数据库表的结构。
alter table table_name
add column_name datatype;alter table table_name
modify column_name datatype;alter table table_name
drop column_name;- drop table : 用于删除数据库表。
drop table table_name;-
创建索引:用于加速查询数据库中的数据,使得系统能够快速定位,范围查询和加速排序和连接目标值。
CREAT INDEX idx_department_id ON employees (department_id);-- 查询所有部门为101的员工
SELECT * FROM employees where department_id = 101;在这个查询中,如果 department_id 列上有索引,数据库系统可能会选择使用该索引来加速查询。
数据库连接查询语句
- JOIN : 用于连接两个或多个表的行,根据指定的条件关联行。
- inner join : 返回两个表中满足条件的行。
- outer join : 返回两个表中至少有一行满足条件的行。
更复杂的语法:高级查询和数据处理
这些语法用于处理更复杂的查询需求,例如多表联合查询、汇总统计、条件过滤等。
子查询
1. 嵌套查询: 在一个查询中嵌套另一个查询,用于检索嵌套查询的结果。
select column1
from table1
where column2 in (select columns from table2 where condition);2. EXIST: 检查子查询是否返回结果,通常与WHERE子句一起使用,
select column1
from table1
where exists(select * from table2 where condition);3. IN: 指定一系列条件,如果某列的值在这个系列中,则返回结果。
select column1
from table1
where column2 in (value1, value2,...);连接查询
1. inner join: 返回两个表中满足条件的行。
select column1, column2
from table1
inner join table2 on table1.column = table2.column;其中,select column1, column2: 这部分指定了你希望从结果中集中显示的列。在这个例子中,你选择了表'table1'中的'colum1'和'column2'。
from table1: 指定主要表的部分,既要从中选择数据的表。在这里,主要表是‘table1’。
inner join table2 on table1.column = table2.column : 这里是连接表的部分。通过使用inner join,你正在执行内连接,这意味着只有在两个表中的指定列的值相匹配的情况下,相关的行才会包含在结果集中。
- 'table2':这是要与主要表'table1'进行连接的第二个表。
- 'on table1.column = table2.column': 这是指定连接条件的部分。他告诉数据库在哪两个表的列上进行匹配。在这里,它表示只有在'table1'的列与'table2'的列相等时,两个表的行才会连接。
该查询目的:这个查询的目的是从‘table1’和‘table2’中选择'table1'的'column1'和'column2',并且只选择那些在连接条件中匹配的行。
举例:假设你有两个表,employees包含员工的信息,包括ID(employee_id),姓名(employee_name),和所属部门的ID(departmet_id)。departments包含部门的信息,包括部门ID(department_id)和部门名称(department_name)。
现想要获取每个员工及其所属部门的名称:
# SQL
select employees.employee_id, employees.employee_name, departments.department_name
from employees
inner join departments on employees.department_id = departments.department_id;这个查询的含义是:
- 从
employees表中选择员工的ID (employee_id) 和姓名 (employee_name)。 - 从
departments表中选择部门的名称 (department_name)。 - 通过内连接 (
INNER JOIN) 将这两个表连接起来,连接条件是employees.department_id = departments.department_id,即员工所属部门的ID要与部门表中的ID相匹配。
内连接的好处:
- 关联数据:内连接使你能够关联两个表中相关的数据,通过共享相同值的列将他们连接起来,不必手动整合。
- 减少数据冗余:内连接仅返回满足条件的行,从而减少了结果集中的数据冗余。避免了不相关数据的混入。
- 提高查询灵活性:内连接允许你在查询中指定多个表,并且可以通过不同的连接条件创建不同的关联。
- 优化性能:仅返回满足条件的行,查询可更快,不需要处理不想干数据。
内连接的强大体现在在关系型数据库中从多个表中检索和组合数据,提供了更丰富和有关联的查询结果。
从四个表中连接表后,查询结果的例子:
select t1.column1, t2.column2, t3.column3, t4.column4
from table t1
inner join table2 t2 on t1.common_colum = t2.common_column
inner join table3 t3 on t2.another_common_column = t3.another_common_column
inner join table4 t4 on t3.yet_another_common_column = t4.yet_another_common_column;- t1, t2, t3, t4是表的别名,简化了查询语句。
- 'common_column', 'another_common_column', 'yet_another_common_column'是连接表的列,用于建立连接关系。
2. 外连接Outer join:允许检索表中未匹配的行,并在结果集中以NULL返回这些行。
外连接分为左外连接(left outer join)、右外连接(right outer join)和全外连接(full outer join)。
1. 左外连接例子
举例:假设你有两个表,employees包含员工的信息,包括ID(employee_id),姓名(employee_name),和所属部门的ID(departmet_id)。departments包含部门的信息,包括部门ID(department_id)和部门名称(department_name)。
employees表:
| employee_id | employee_name | department_id |
|-------------|---------------|---------------|
| 1 | John | 101 |
| 2 | Jane | 102 |
| 3 | Bob | 103 |
departments表:
| department_id | department_name |
|---------------|------------------|
| 101 | HR |
| 102 | IT |
| 104 | Marketing |
现打算获取所有员工及其所属部门的名称,包括那些没有匹配到部门的员工。你可以使用左外连接来实现。
select employees.employee_id, employees.employee_name, departments.department_name
from employees
left outer join departments on employees.department_id = departments.departments_id语句含义:最终会返回employees 表中的所有行,不论它们在 departments 表中是否有匹配的部门信息。如果某个员工没有匹配到部门,departments 表的相关列将会包含 NULL 值。
left outer join结果:
| employee_id | employee_name | department_name |
|-------------|---------------|------------------|
| 1 | John | HR |
| 2 | Jane | IT |
| 3 | Bob | NULL |
2. 右外连接right outer join例子:
右外连接,以返回departments表中所有数据为基准,employees中缺失值补NULL:
SELECT employees.employee_id, employees.employee_name, departments.department_name
FROM employees
RIGHT OUTER JOIN departments ON employees.department_id = departments.department_id;
在这个查询中,RIGHT OUTER JOIN 表示右外连接。这意味着将返回 departments 表中的所有行,不论它们在 employees 表中是否有匹配的员工信息。如果某个部门没有匹配到员工,employees 表的相关列将会包含 NULL 值。
结果如下:
| employee_id | employee_name | department_name |
|-------------|---------------|------------------|
| 1 | John | HR |
| 2 | Jane | IT |
| NULL | NULL | Marketing |
3. 全外连接full outer join例子
右外连接,以返回employees表和departments表中所有数据为基准,employees和departments中缺失值补NULL:
SELECT employees.employee_id, employees.employee_name, departments.department_name
FROM employees
FULL OUTER JOIN departments ON employees.department_id = departments.department_id;
运行结果:
| employee_id | employee_name | department_name |
|-------------|---------------|------------------|
| 1 | John | HR |
| 2 | Jane | IT |
| 3 | Bob | NULL |
| NULL | NULL | Marketing |
这个结果集包含了 employees 和 departments 表中的所有记录,不论它们在另一个表中是否有匹配。如果某个记录在其中一个表中没有匹配,相应的列将包含 NULL 值。
连接查询进阶
1. UNION:合并两个或多个SELECT语句的结果集,并去除重复的行。
SELECT column1 FROM table1
UNION
SELECT column1 FROM table2;
2. INTERSECT: 返回两个SELECT语句的交集,并去除重复的行。
SELECT column1 FROM table1
INTERSECT
SELECT column1 FROM table2;
3. EXCEPT(或MINUS):
返回第一个 SELECT 语句的结果集,去除与第二个 SELECT 语句的结果集相交的部分。
SELECT column1 FROM table1
EXCEPT
SELECT column1 FROM table2;
窗口函数
1. OVER:用于在执行聚合函数时,定义窗口,使得聚合函数可以对指定窗口的行进行计算。
SELECT column1, AVG(column2) OVER (PARTITION BY column3 ORDER BY column4) As avg_column2
FROM table;示例数据:
+---------+---------+---------+---------+
| column1 | column2 | column3 | column4 |
+---------+---------+---------+---------+
| A | 10 | X | 3 |
| B | 15 | X | 1 |
| C | 20 | X | 2 |
| D | 8 | Y | 1 |
| E | 12 | Y | 3 |
| F | 18 | Y | 2 |
+---------+---------+---------+---------+
1. 对于分区 X,按照 column4 的顺序排序后的数据是:
+---------+---------+---------+---------+
| column1 | column2 | column3 | column4 |
+---------+---------+---------+---------+
| B | 15 | X | 1 |
| C | 20 | X | 2 |
| A | 10 | X | 3 |
+---------+---------+---------+---------+
计算 AVG(column2) 时,按照 column4 的升序顺序计算:
- 对于第一行(B),平均值是15(自身)。
- 对于第二行(C),平均值是 (15 + 20) / 2 = 17.5。
- 对于第三行(A),平均值是 (15 + 20 + 10) / 3 = 15。
2. 对于分区 Y,按照 column4 的顺序排序后的数据是:
+---------+---------+---------+---------+
| column1 | column2 | column3 | column4 |
+---------+---------+---------+---------+
| D | 8 | Y | 1 |
| F | 18 | Y | 2 |
| E | 12 | Y | 3 |
+---------+---------+---------+---------+
计算 AVG(column2) 时,按照 column4 的升序顺序计算:
- 对于第一行(D),平均值是8(自身)。
- 对于第二行(F),平均值是 (8 + 18) / 2 = 13。
- 对于第三行(E),平均值是 (8 + 18 + 12) / 3 = 15。
最终结果:
+---------+------------+
| column1 | avg_column2|
+---------+------------+
| B | 15 | -- 在分区X中,第一行的平均值是15
| C | 17.5 | -- 在分区X中,前两行的平均值是 (15 + 20) / 2 = 17.5
| A | 15 | -- 在分区X中,前三行的平均值是 (15 + 20 + 10) / 3 = 15
| D | 8 | -- 在分区Y中,第一行的平均值是8
| F | 13 | -- 在分区Y中,前两行的平均值是 (8 + 18) / 2 = 13
| E | 15 | -- 在分区Y中,前三行的平均值是 (8 + 18 + 12) / 3 = 15
+---------+------------+
解释:
在 SQL 中,`AVG()` 是一个聚合函数,它计算指定列的平均值。当你在窗口函数中使用 `AVG()` 时,它通常是以当前行及其之前的行为基础进行计算的,具体取决于 `OVER` 子句中的 `ORDER BY` 子句和 `PARTITION BY` 子句。
在你的查询中:
SELECT column1, AVG(column2) OVER (PARTITION BY column3 ORDER BY column4) AS avg_column2
FROM table;- PARTITION BY column3: 指定了窗口函数将按照 `column3` 的不同值进行分区,每个分区内的计算是独立的。
- ORDER BY column4:指定了窗口函数计算平均值时要按照 `column4` 列的值进行排序,以确定计算的顺序和范围。
具体来说,对于每个分区,`AVG(column2)` 将按照 `column4` 列的顺序计算当前行及其之前的行的平均值。这不是规定每行的平均值是前几行的平均值,而是根据 `column4` 的排序顺序计算当前行及其之前的行的平均值。
因此,虽然在通常的情况下,`AVG()` 确实是从第一行到当前行的平均值,但具体计算的范围还受到 `ORDER BY` 子句的影响,确切的计算方式还取决于你的数据和排序列的值。希望这次的解释更加清楚。
全文搜索
1. MATCH AGAINST: 用于在全文搜索中匹配文本。
SELECT column1
FROM table1
WHERE MATCH(column2) AGAINST ('search_keyword');含义:语句表示在表table1的column2列中执行全文搜索,寻找包含指定搜索关键字的匹配相,并返回对应的column1列的数据。
具体来说:
-
SELECT column1: 查询结果将包括column1列的数据,即返回与搜索条件匹配的相关信息。 -
FROM table1: 数据将从名为table1的表中检索。 -
WHERE MATCH(column2) AGAINST ('search_keyword'): 这是实际的搜索条件。它要求在column2列中执行全文搜索,寻找包含给定搜索关键字('search_keyword')的匹配项。匹配度高的结果将排在前面。
需要注意的是,为了使用这种全文搜索,表中的 column2 列通常需要进行全文索引的配置。此外,MySQL 的全文搜索还涉及到一些配置参数和算法,以满足特定的搜索需求。
存储过程和触发器
它们是在数据库中用于执行特定任务的两种对象。它们通常与关系型数据库系统(如MySQL、SQL Server、Oracle等)一起使用。
1. CREATE PROCEDURE: 用于创建存储过程。
- 定义: 存储过程是一组预编译的SQL语句,可以被存储在数据库中,并通过一个单独的调用来执行。
- 创建过程: 创建存储过程通常涉及使用数据库管理系统提供的特定语法,其中包括过程的名称、输入参数、输出参数和过程体(包含SQL语句的代码块)。
- 用途: 存储过程可以用于封装、重用和简化数据库操作。它们可以被调用,以执行一系列的SQL语句,并且还能接收参数,使其更加灵活。
CREATE PROCEDURE sp_GetCustomerInfo(IN customerID INT)
BEGINSELECT * FROM Customers WHERE CustomerID = customerID;
END;
2. CREATE TRIGGER: 用于创建触发器。
- 定义:触发器是与表相关联的一种特殊类型的存储过程,它会在表上的特定时间(如插入、更新、删除)发生时自动执行。
- 创建过程:创建触发器需要指定触发的时间、触发的表、触发时机(BEFORE或AFTER)以及触发时执行的SQL语句。
- 用途:触发器常用语实现数据的完整性、自动化任务、日志记录等。它们可以用来强制执行特定的业务规则,以确保数据库中的数据始终保持一致性。
CREATE TRIGGER trigger_name
BEFORE/AFTER INSERT/UPDATE/DELETE ON table_name
FOR EACH ROW
-- trigger body示例:
CREATE TRIGGER before_insert_example
BEFORE INSERT ON Orders
FOR EACH ROW
BEGINSET NEW.OrderDate() = NOW();
END;这是一个MySQL语法下的触发器创建语句,它的作用是在往Orders表中插入新记录之前(BEFORE INSERT)执行一些特定的操作。让我们逐步解释这个触发器的定义:
-
CREATE TRIGGER before_insert_example: 这部分指定了创建触发器的语法,
before_insert_example是触发器的名称,你可以根据需要自定义触发器的名字。 -
BEFORE INSERT ON Orders: 这部分说明了触发器是在
Orders表上执行的,而且是在插入操作之前触发。 -
FOR EACH ROW: 这表示这是一个行级触发器,也就是说,它会在每次插入一行记录时执行一次。
-
BEGIN...END: 这是触发器的主体,包含了触发器要执行的代码块。在这个例子中,使用了
SET NEW.OrderDate = NOW();,它的作用是将即将插入的新记录的OrderDate字段设置为当前的系统时间(使用NOW()函数)。
总体而言,这个触发器的目的是在每次往Orders表插入新记录之前,自动将该记录的OrderDate字段设置为当前时间。这可以用于确保在插入新订单时,OrderDate字段总是包含当前的时间戳,而不是由插入语句提供的值。触发器提供了一种在数据库中自动执行特定逻辑的方式,以确保数据的一致性和完整性。
聚合函数
聚合函数是用于对一组值进行计算并返回单个结果的SQL函数。这些函数通常用于对数据库中的数据进行汇总和统计,提供了对数据集合进行分析的强大工具。
1. SUM:计算某列的总和。
select SUM(column1) from table1;2. AVG: 计算某列的平均值。
select AVG(column1) from table1;
3. COUNT: 计算某列的行数。
select COUNT(column1) from table1;4. MAX: 获取某列的最大值。
select max(column1) from table1;5. MIN: 获取某列的最小值。
select min(column1) from table1;GROUP BY 和 HAVING
1. GROUP BY: 对查询结果按例进行分组:
select column1, COUNT(*)
from table1
group by column1;解释:
- select column1, count(*): 选择查询结果中的列,其中包括column1列和一个计算每个分组中行的数量的计数值。count(*)表示对每个分组中的行数进行计数。
- from table: 指定查询的数据来源,即要统计的表是table。
- group by column1: 根据column1列的值对结果进行分组。这意味着查询将返回每个不同的column1值以及该值出现的次数。
举例1:
| column1 |
|---------|
| A |
| B |
| A |
| A |
| B |
| C |
运行上述查询后,结果可能是:
| column1 | COUNT(*) |
|---------|----------|
| A | 3 |
| B | 2 |
| C | 1 |
解释结果:
- "A" 出现了 3 次。
- "B" 出现了 2 次。
- "C" 出现了 1 次。
这种查询对于了解数据分布、查找出现频率最高的项等情况非常有用。
举例2:
table1包含以下数据:
| column1 | column2 |
|---------|---------|
| A | X |
| B | Y |
| A | X |
| A | Z |
| B | Z |
| C | Y |
运行以下查询:
SELECT column1, column2, COUNT(*)
FROM table1
GROUP BY column1, column2;
可能的结果是:
| column1 | column2 | COUNT(*) |
|---------|---------|----------|
| A | X | 2 |
| B | Y | 1 |
| A | Z | 1 |
| B | Z | 1 |
| C | Y | 1 |
这表示按照 column1 和 column2 的组合进行分组,然后计算每个组合的行数。例如,"A" 和 "X" 的组合出现了 2 次,"B" 和 "Y" 的组合出现了 1 次,以此类推。
2. HAVING: 在GROUP BY的基础上进行条件过滤。
select column1, COUNT(*)
from table1
group by coumn1
having count(*) > 1;解释:
这是一个带有having子句的sql查询语句,用于从表table1中选择出现次数大于1的不同column1值以及它们的出现次数。
- select column1, count(*): 选择查询结果中的列,包括column1列和一个计算每个分组中行的数量的计数值。count(*)表示对每个分组中的行数进行计数。
- from table1: 指定查询的数据来源,即要统计的表是table1。
- group by column1: 根据
column1列的值对结果进行分组。这意味着查询将返回每个不同的column1值以及该值出现的次数。 -
HAVING COUNT(*) > 1: 通过HAVING子句筛选出现次数大于 1 的分组。这样,结果将只包含那些在column1列中出现次数大于 1 的值。
举例:
table1如下:
| column1 |
|---------|
| A |
| B |
| A |
| A |
| B |
| C |
运行上面查询语句的结果可能是:
| column1 | COUNT(*) |
|---------|----------|
| A | 3 |
| B | 2 |
这表示在 column1 列中,只有 "A" 和 "B" 出现的次数大于 1。这种查询常用于查找具有重复出现的特定值的情况。
3. group by 和聚合函数sum的组合使用
假如有table1:
| column1 | column2 | some_numeric_column |
|---------|---------|---------------------|
| A | X | 10 |
| B | Y | 5 |
| A | X | 7 |
| A | Z | 3 |
| B | Z | 8 |
| C | Y | 12 |
运行:
SELECT column1, column2, SUM(some_numeric_column)
FROM table1
GROUP BY column1, column2;
可能的结果:
| column1 | column2 | SUM(some_numeric_column) |
|---------|---------|---------------------------|
| A | X | 17 |
| B | Y | 5 |
| A | Z | 3 |
| B | Z | 8 |
| C | Y | 12 |
这表示按照 column1 和 column2 的组合进行分组,并计算每个组合中 some_numeric_column 列的总和。
相关文章:

数据库定义和操作语句的重要语法
数据库📊的10种语法 数据查询语句 select : 用于从数据库中检索数据。 select column1, column2,.... from table_name where condition; select distinct : 用于从数据库中检索唯一的数据值。 select DISTINCT column1, clumn2,... from table_name; 工作原理…...
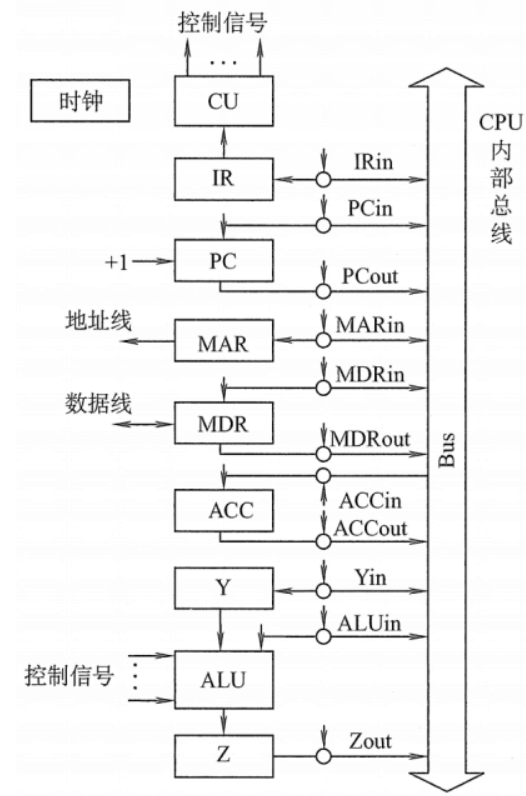
计算机组成原理 CPU的功能和基本结构和指令执行过程
文章目录 CPU的功能和基本结构CPU的功能CPU的基本结构 指令执行过程指令周期概念指令执行方案指令数据流取周期数据流析指周期数据流执行周期数据流中断周期数据流 数据通路的功能和基本结构数据通路的功能数据通路的结构单总线 CPU的功能和基本结构 #mermaid-svg-0uHwjZOZh4kS…...
批量归一化:彻底改变深度学习架构
一、介绍 在深度学习的动态领域,批量归一化的引入标志着神经网络训练方法的关键转变。这项创新技术由 Sergey Ioffe 和 Christian Szegedy 在 2015 年提出,已成为现代神经网络架构的基石。它解决了训练深度网络的关键挑战,特别是处理臭名昭著…...
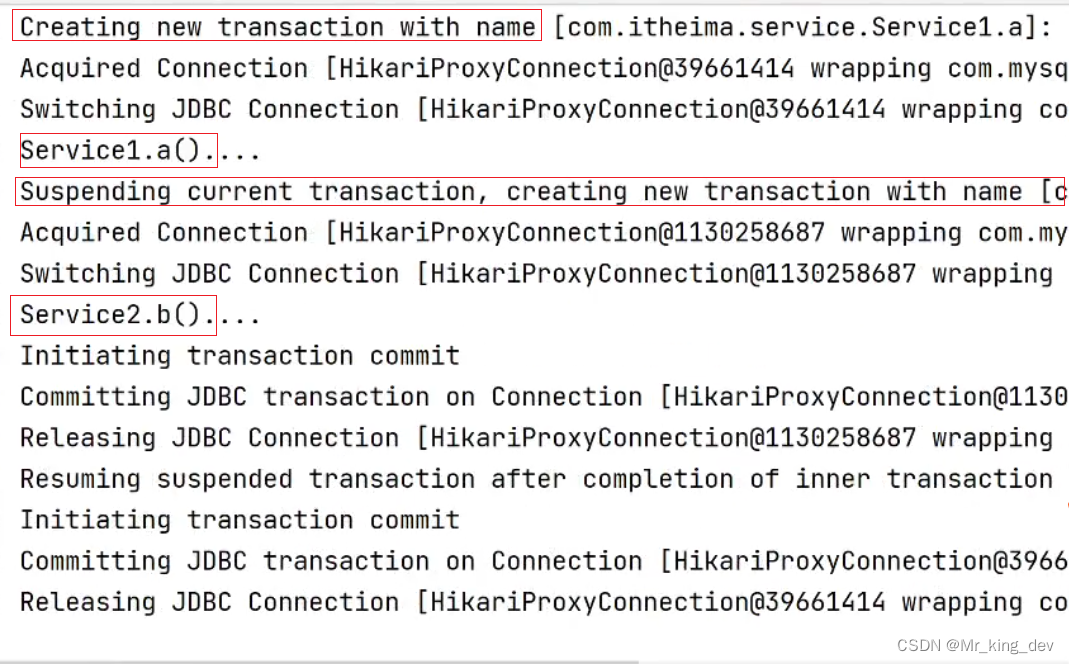
Spring05
一、Spring事务管理入门 1.1、创建数据库和表 创建一个Spring数据库,在Spring数据库中创建tb_account(账户表),并初始化数据。 1.2、编写Service层、Mapper层以及调用层 1.2.1、AccountServiceImpl实现了AccountService接口 1.2.2、Mapper层中的代码 1…...
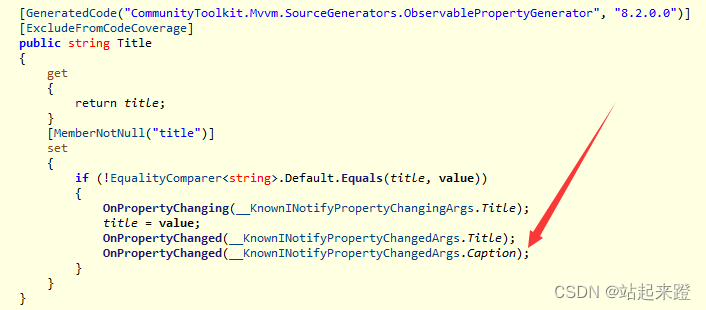
MvvmToolkit的使用
背景:MvvmLight不更新了,用Toolkit代替 1、首先下载好社区版本的NuGet包 2、ViewModel中需要继承ObservableObject,查看ObservableObject可以看到里面有实现好InotifyPropertyChanged。 3、对于属性的set,可以简写成一行ÿ…...
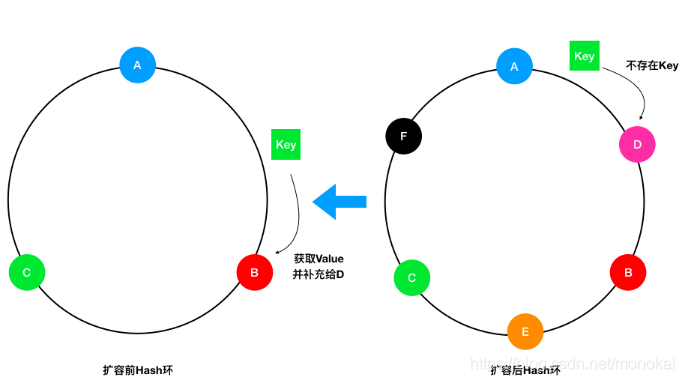
分布式【一致性Hash算法简介】
一致性Hash是一种特殊的Hash算法,由于其均衡性、持久性的映射特点,被广泛的应用于负载均衡领域,如nginx和memcached都采用了一致性Hash来作为集群负载均衡的方案。 一致性Hash算法简介 在了解一致性Hash算法之前,先来讨论一下Ha…...

PHP命令行脚本接收传入参数的三种方式
1.使用$argv or $argc参数接收,会把文件本身计算在内 $argv: 以数组形式接收保存参数 $argc:保存参数个数 <?php echo "接收到{$argc}个参数"; print_r($argv); //执行 //php /usr/local/php/bin/php test.php 接收到1个…...

【STM32】STM32学习笔记-ADC单通道 ADC多通道(22)
00. 目录 文章目录 00. 目录01. ADC简介02. ADC相关API2.1 RCC_ADCCLKConfig2.2 ADC_RegularChannelConfig2.3 ADC_Init2.4 ADC_InitTypeDef2.5 ADC_Cmd2.6 ADC_ResetCalibration2.7 ADC_GetResetCalibrationStatus2.8 ADC_StartCalibration2.9 ADC_GetCalibrationStatus2.10 A…...
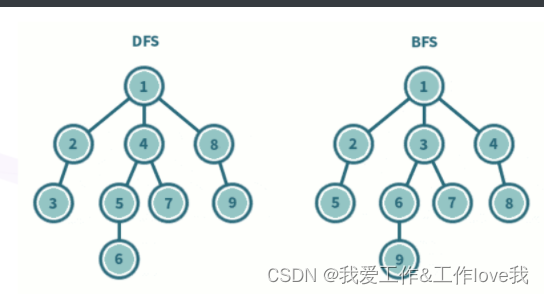
1329:【例8.2】细胞 广度优先搜索
1329:【例8.2】细胞 时间限制: 1000 ms 内存限制: 65536 KB 【题目描述】 一矩形阵列由数字0 到9组成,数字1到9 代表细胞,细胞的定义为沿细胞数字上下左右还是细胞数字则为同一细胞,求给定矩形阵列的细胞个数。如: 4 10 0234500067 1034560500 2045600671 00000000…...

9款免费网络钓鱼模拟器详解
根据《2023年网络钓鱼状况报告》显示,自2022年第四季度至2023年第三季度,网络钓鱼电子邮件数量激增了1265%。其中,利用ChatGPT等生成式人工智能工具和聊天机器人的形式尤为突出。 除了数量上的激增外,网络钓鱼攻击模式也在不断进…...

linux cpu、memory 、io、网络、文件系统多种类型负荷模拟调测方法工具
目录 一、概述 二、stress介绍和使用 2.1 介绍 2.2 使用 三、stress-ng介绍和使用 3.1 介绍 3.2 使用 3.3 实例 四、sysbench 4.1 介绍 4.2 使用 五、lmbench 5.1 介绍 5.2 使用 一、概述 今天介绍两款cpu负荷调试工具,用来模拟多种类型的负载。主要用来模拟CPU…...
1018:奇数偶数和1028:I love 闰年!和1029:三角形判定
1018:奇数偶数 要求:输入一个整数,判断该数是奇数还是偶数。如果该数是奇数就输出“odd”,偶数就输出“even”(输出不含双引号)。 输入样例:8 输出样例:even 程序流程图:…...

数据密集型应用系统设计--第2章 数据模型与查询语言
一、引言 数据模型可能是开发软件最重要的部分,而且还对如何思考待解决的问题都有深远的影响。 大多数应用程序是通过一层一层叠加数据模型来构建的。每一层都面临的关键问题是:如何将其用下一层来表示? 1.作为一名应用程序开发人员,观测现实…...
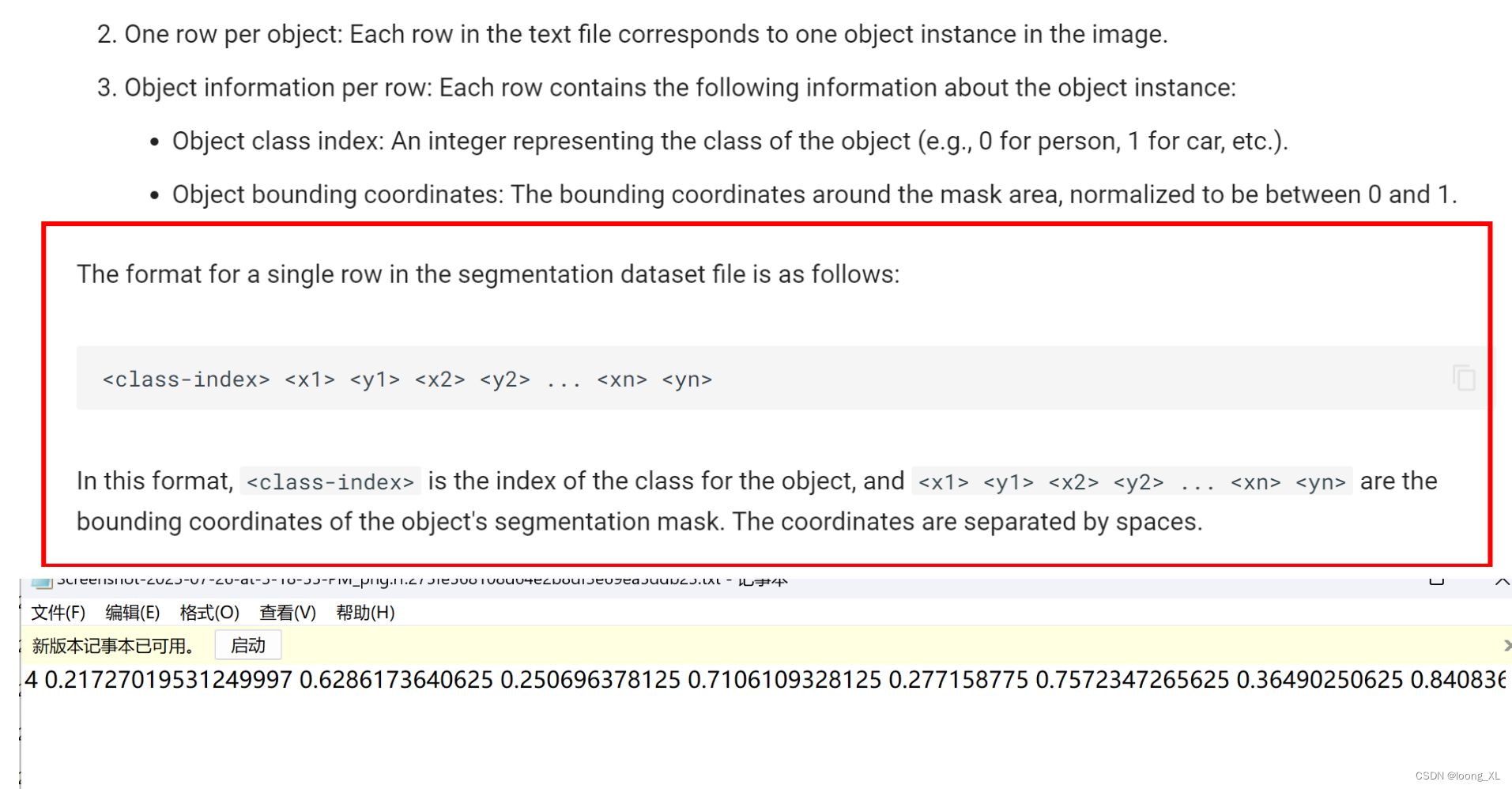
yolo 分割label格式标注信息图片显示可视化查看
参考: https://github.com/ultralytics/ultralytics/issues/3137 https://blog.csdn.net/weixin_42357472/article/details/135218349?spm=1001.2014.3001.5501 需要把坐标信息在图片上显示 代码 1)只画出了坐标边缘 import cv2 import numpy as np from random impor…...
霍兰德职业兴趣测试 60题(免费版)
霍兰德职业兴趣理论从兴趣的角度出发探索职业指导的问题,明确了职业兴趣的人格观念,使得人们对于职业兴趣的认识有了质的变化。在霍兰德职业兴趣理论提出来之前,职业兴趣和职业环境二者分别独立存在,正是霍兰德的总结,…...

MySQL之视图内连接、外连接、子查询
目录 一、视图 1.1 含义 2.1 视图的基本语法 二、案例 三、思维导图 一、视图 1.1 含义 虚拟表,和普通表一样使用 视图(view)是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据…...
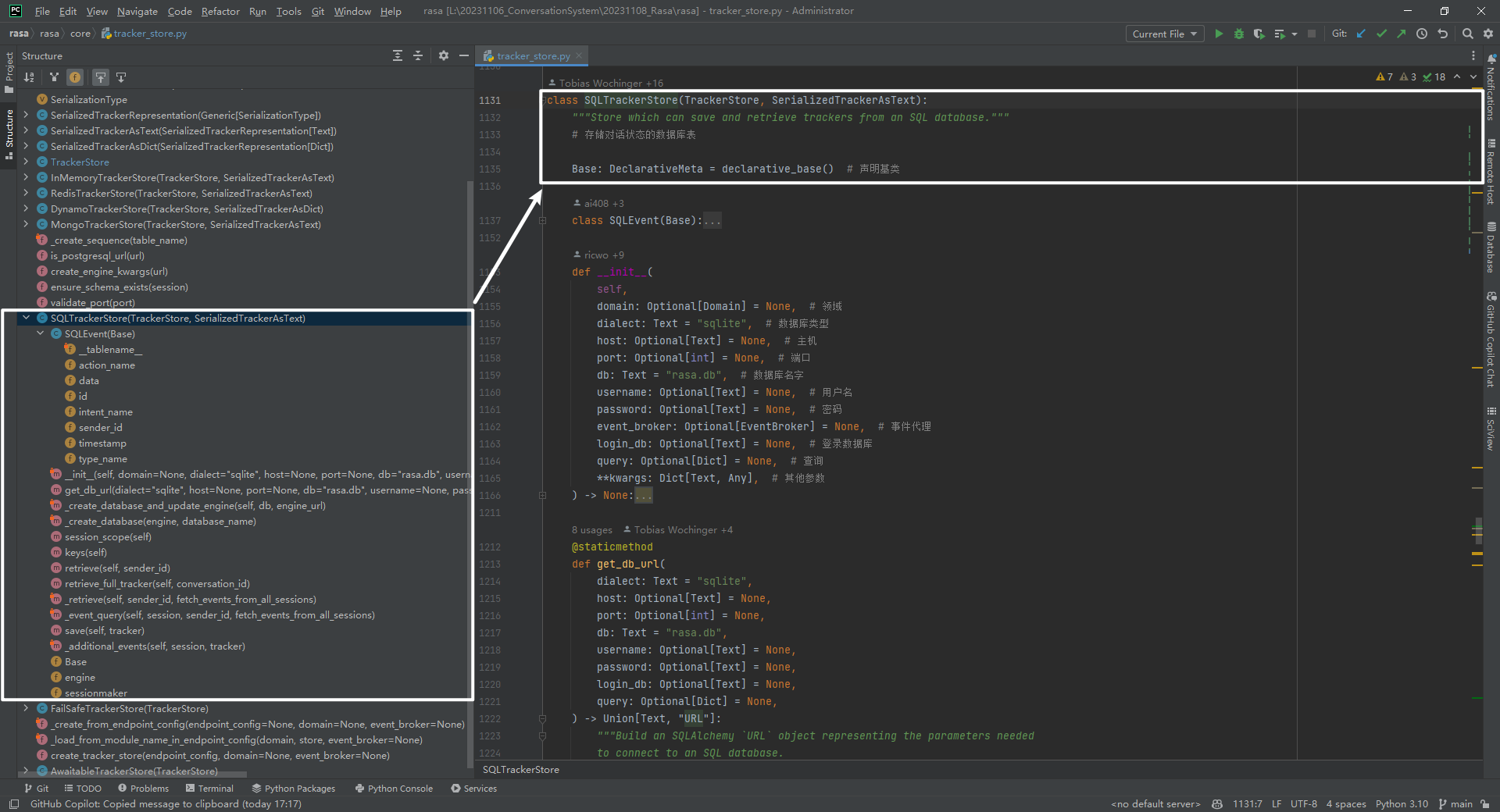
以报时机器人为例详细介绍tracker_store和event_broker
报时机器人源码参考[1][2],本文重点介绍当 tracker_store 类型为 SQL 时,events 表的表结构以及数据是如何生成的。以及当 event_broker 类型为 SQL 时,events 表的表结构以及数据是如何生成的。 一.报时机器人启动 [3] Rasa 对话系统启动方…...

理解JavaScript事件循环机制
JavaScript作为前端开发的核心语言之一,其事件循环机制是实现异步编程的关键。本文将深入探讨JavaScript事件循环机制,帮助您更好地理解它是如何工作的,以及如何在前端开发中充分利用这一机制。 1. 什么是事件循环? JavaScript是…...

自定义View之重写onMeasure
一、重写onMeasure()来修改已有的View的尺寸 步骤: 重写 onMeasure(),并调用 super.onMeasure() 触发原先的测量用 getMeasuredWidth() 和 getMeasuredHeight() 取到之前测得的尺寸,利用这两个尺寸来计算出最终尺寸使用 setMeasuredDimensio…...

专为Mac用户设计的思维导图软件MindNode 2023 for Mac助您激发创意!
在现代快节奏的生活中,我们经常需要整理思绪、规划项目、记录灵感。而思维导图作为一种高效的思维工具,能够帮助我们更好地整理和展现思维。现在,我们介绍一款强大而直观的思维导图软件——MindNode 2023 for Mac,助您拓展思维边界…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

Python如何给视频添加音频和字幕
在Python中,给视频添加音频和字幕可以使用电影文件处理库MoviePy和字幕处理库Subtitles。下面将详细介绍如何使用这些库来实现视频的音频和字幕添加,包括必要的代码示例和详细解释。 环境准备 在开始之前,需要安装以下Python库:…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

WebRTC从入门到实践 - 零基础教程
WebRTC从入门到实践 - 零基础教程 目录 WebRTC简介 基础概念 工作原理 开发环境搭建 基础实践 三个实战案例 常见问题解答 1. WebRTC简介 1.1 什么是WebRTC? WebRTC(Web Real-Time Communication)是一个支持网页浏览器进行实时语音…...

WPF八大法则:告别模态窗口卡顿
⚙️ 核心问题:阻塞式模态窗口的缺陷 原始代码中ShowDialog()会阻塞UI线程,导致后续逻辑无法执行: var result modalWindow.ShowDialog(); // 线程阻塞 ProcessResult(result); // 必须等待窗口关闭根本问题:…...

【把数组变成一棵树】有序数组秒变平衡BST,原来可以这么优雅!
【把数组变成一棵树】有序数组秒变平衡BST,原来可以这么优雅! 🌱 前言:一棵树的浪漫,从数组开始说起 程序员的世界里,数组是最常见的基本结构之一,几乎每种语言、每种算法都少不了它。可你有没有想过,一组看似“线性排列”的有序数组,竟然可以**“长”成一棵平衡的二…...

32位寻址与64位寻址
32位寻址与64位寻址 32位寻址是什么? 32位寻址是指计算机的CPU、内存或总线系统使用32位二进制数来标识和访问内存中的存储单元(地址),其核心含义与能力如下: 1. 核心定义 地址位宽:CPU或内存控制器用32位…...

6.计算机网络核心知识点精要手册
计算机网络核心知识点精要手册 1.协议基础篇 网络协议三要素 语法:数据与控制信息的结构或格式,如同语言中的语法规则语义:控制信息的具体含义和响应方式,规定通信双方"说什么"同步:事件执行的顺序与时序…...

接口 RESTful 中的超媒体:REST 架构的灵魂驱动
在 RESTful 架构中,** 超媒体(Hypermedia)** 是一个核心概念,它体现了 REST 的 “表述性状态转移(Representational State Transfer)” 的本质,也是区分 “真 RESTful API” 与 “伪 RESTful AP…...