【大数据进阶第三阶段之Datax学习笔记】使用阿里云开源离线同步工具DataX 实现数据同步
【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax概述
【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax快速入门
【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax类图
【大数据进阶第三阶段之Datax学习笔记】使用阿里云开源离线同步工具Datax实现数据同步
1、准备工作:
- JDK(1.8 以上,推荐 1.8)
- Python(23 版本都可以)
- Apache Maven 3.x(Compile DataX)(手动打包使用,使用
tar包方式不需要安装)
| 主机名 | 操作系统 | IP 地址 | 软件包 |
| MySQL-1 | CentOS 7.4 | 192.168.1.1 | jdk-8u181-linux-x64.tar.gz datax.tar.gz |
| MySQL-2 | CentOS 7.4 | 192.168.1.2 |
2、安装 JDK:
下载地址:Java Archive Downloads - Java SE 8(需要创建 Oracle 账号)
[root@MySQL-1 ~]# ls anaconda-ks.cfg jdk-8u181-linux-x64.tar.gz [root@MySQL-1 ~]# tar zxf jdk-8u181-linux-x64.tar.gz [root@DataX ~]# ls anaconda-ks.cfg jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz [root@MySQL-1 ~]# mv jdk1.8.0_181 /usr/local/java [root@MySQL-1 ~]# cat <<END >> /etc/profile export JAVA_HOME=/usr/local/java export PATH=$PATH:"$JAVA_HOME/bin" END [root@MySQL-1 ~]# source /etc/profile [root@MySQL-1 ~]# java -version
- 因为
CentOS 7上自带Python 2.7的软件包,所以不需要进行安装。
3、Linux 上安装 DataX 软件
[root@MySQL-1 ~]# wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz [root@MySQL-1 ~]# tar zxf datax.tar.gz -C /usr/local/ [root@MySQL-1 ~]# rm -rf /usr/local/datax/plugin/*/._*
- 当未删除时,可能会输出:
[/usr/local/datax/plugin/reader/._drdsreader/plugin.json] 不存在. 请检查您的配置文件.
验证:
[root@MySQL-1 ~]# cd /usr/local/datax/bin [root@MySQL-1 ~]# python datax.py ../job/job.json
输出:
2021-12-13 19:26:28.828 [job-0] INFO JobContainer - PerfTrace not enable! 2021-12-13 19:26:28.829 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.060s | All Task WaitReaderTime 0.068s | Percentage 100.00% 2021-12-13 19:26:28.829 [job-0] INFO JobContainer - 任务启动时刻 : 2021-12-13 19:26:18 任务结束时刻 : 2021-12-13 19:26:28 任务总计耗时 : 10s 任务平均流量 : 253.91KB/s 记录写入速度 : 10000rec/s 读出记录总数 : 100000 读写失败总数 : 0
4、DataX 基本使用
查看 streamreader \--> streamwriter 的模板:
[root@MySQL-1 ~]# python /usr/local/datax/bin/datax.py -r streamreader -w streamwriter
输出:
DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.Please refer to the streamreader document:https://github.com/alibaba/DataX/blob/master/streamreader/doc/streamreader.md Please refer to the streamwriter document:https://github.com/alibaba/DataX/blob/master/streamwriter/doc/streamwriter.md Please save the following configuration as a json file and usepython {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.{"job": {"content": [{"reader": {"name": "streamreader", "parameter": {"column": [], "sliceRecordCount": ""}}, "writer": {"name": "streamwriter", "parameter": {"encoding": "", "print": true}}}], "setting": {"speed": {"channel": ""}}}
}
根据模板编写 json 文件
[root@MySQL-1 ~]# cat <<END > test.json
{"job": {"content": [{"reader": {"name": "streamreader", "parameter": {"column": [ # 同步的列名 (* 表示所有){"type":"string","value":"Hello."},{"type":"string","value":"河北彭于晏"},], "sliceRecordCount": "3" # 打印数量}}, "writer": {"name": "streamwriter", "parameter": {"encoding": "utf-8", # 编码"print": true}}}], "setting": {"speed": {"channel": "2" # 并发 (即 sliceRecordCount * channel = 结果)}}}
}
输出:(要是复制我上面的话,需要把 # 带的内容去掉)

5、安装 MySQL 数据库
分别在两台主机上安装:
[root@MySQL-1 ~]# yum -y install mariadb mariadb-server mariadb-libs mariadb-devel
[root@MySQL-1 ~]# systemctl start mariadb # 安装 MariaDB 数据库
[root@MySQL-1 ~]# mysql_secure_installation # 初始化
NOTE: RUNNING ALL PARTS OF THIS SCRIPT IS RECOMMENDED FOR ALL MariaDBSERVERS IN PRODUCTION USE! PLEASE READ EACH STEP CAREFULLY!Enter current password for root (enter for none): # 直接回车
OK, successfully used password, moving on...
Set root password? [Y/n] y # 配置 root 密码
New password:
Re-enter new password:
Password updated successfully!
Reloading privilege tables..... Success!
Remove anonymous users? [Y/n] y # 移除匿名用户... skipping.
Disallow root login remotely? [Y/n] n # 允许 root 远程登录... skipping.
Remove test database and access to it? [Y/n] y # 移除测试数据库... skipping.
Reload privilege tables now? [Y/n] y # 重新加载表... Success!
1)准备同步数据(要同步的两台主机都要有这个表)
MariaDB [(none)]> create database `course-study`;
Query OK, 1 row affected (0.00 sec)MariaDB [(none)]> create table `course-study`.t_member(ID int,Name varchar(20),Email varchar(30));
Query OK, 0 rows affected (0.00 sec)
因为是使用 DataX 程序进行同步的,所以需要在双方的数据库上开放权限:
grant all privileges on *.* to root@'%' identified by '123123';
flush privileges;
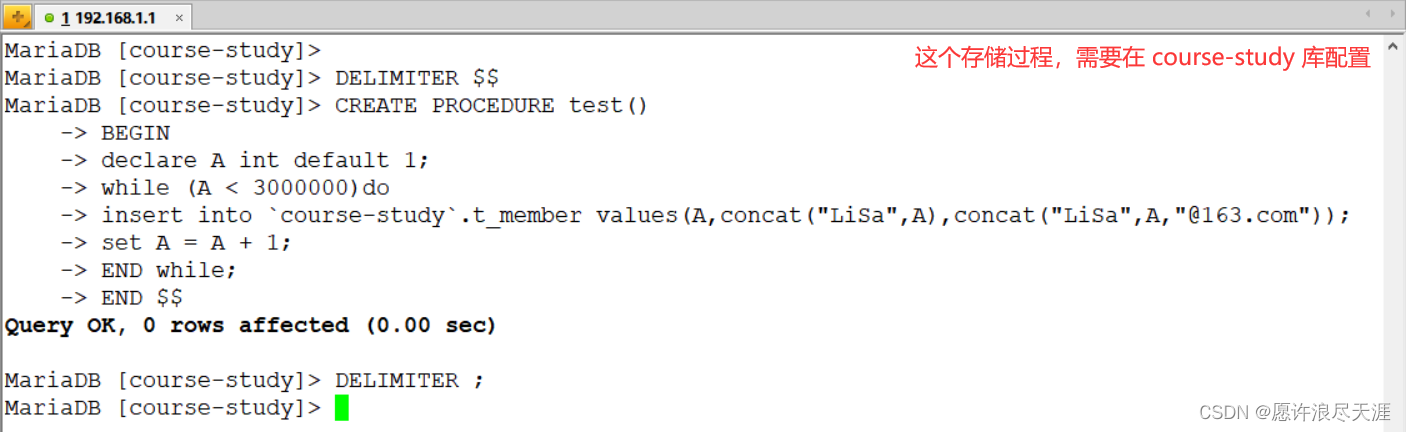
2)创建存储过程:
DELIMITER $$
CREATE PROCEDURE test()
BEGIN
declare A int default 1;
while (A < 3000000)do
insert into `course-study`.t_member values(A,concat("LiSa",A),concat("LiSa",A,"@163.com"));
set A = A + 1;
END while;
END $$
DELIMITER ;
3)调用存储过程(在数据源配置,验证同步使用):
call test();
6、通过 DataX 实 MySQL 数据同步
1)生成 MySQL 到 MySQL 同步的模板:
[root@MySQL-1 ~]# python /usr/local/datax/bin/datax.py -r mysqlreader -w mysqlwriter
{"job": {"content": [{"reader": {"name": "mysqlreader", # 读取端"parameter": {"column": [], # 需要同步的列 (* 表示所有的列)"connection": [{"jdbcUrl": [], # 连接信息"table": [] # 连接表}], "password": "", # 连接用户"username": "", # 连接密码"where": "" # 描述筛选条件}}, "writer": {"name": "mysqlwriter", # 写入端"parameter": {"column": [], # 需要同步的列"connection": [{"jdbcUrl": "", # 连接信息"table": [] # 连接表}], "password": "", # 连接密码"preSql": [], # 同步前. 要做的事"session": [], "username": "", # 连接用户 "writeMode": "" # 操作类型}}}], "setting": {"speed": {"channel": "" # 指定并发数}}}
}
2)编写 json 文件:
[root@MySQL-1 ~]# vim install.json
{"job": {"content": [{"reader": {"name": "mysqlreader", "parameter": {"username": "root","password": "123123","column": ["*"],"splitPk": "ID","connection": [{"jdbcUrl": ["jdbc:mysql://192.168.1.1:3306/course-study?useUnicode=true&characterEncoding=utf8"], "table": ["t_member"]}]}}, "writer": {"name": "mysqlwriter", "parameter": {"column": ["*"], "connection": [{"jdbcUrl": "jdbc:mysql://192.168.1.2:3306/course-study?useUnicode=true&characterEncoding=utf8","table": ["t_member"]}], "password": "123123","preSql": ["truncate t_member"], "session": ["set session sql_mode='ANSI'"], "username": "root", "writeMode": "insert"}}}], "setting": {"speed": {"channel": "5"}}}
}
3)验证
[root@MySQL-1 ~]# python /usr/local/datax/bin/datax.py install.json
输出:
2021-12-15 16:45:15.120 [job-0] INFO JobContainer - PerfTrace not enable!
2021-12-15 16:45:15.120 [job-0] INFO StandAloneJobContainerCommunicator - Total 2999999 records, 107666651 bytes | Speed 2.57MB/s, 74999 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 82.173s | All Task WaitReaderTime 75.722s | Percentage 100.00%
2021-12-15 16:45:15.124 [job-0] INFO JobContainer -
任务启动时刻 : 2021-12-15 16:44:32
任务结束时刻 : 2021-12-15 16:45:15
任务总计耗时 : 42s
任务平均流量 : 2.57MB/s
记录写入速度 : 74999rec/s
读出记录总数 : 2999999
读写失败总数 : 0
你们可以在目的数据库进行查看,是否同步完成。
- 上面的方式相当于是完全同步,但是当数据量较大时,同步的时候被中断,是件很痛苦的事情;
- 所以在有些情况下,增量同步还是蛮重要的。
7、使用 DataX 进行增量同步
使用 DataX 进行全量同步和增量同步的唯一区别就是:增量同步需要使用 where 进行条件筛选。(即,同步筛选后的 SQL)
1)编写 json 文件:
[root@MySQL-1 ~]# vim where.json
{"job": {"content": [{"reader": {"name": "mysqlreader", "parameter": {"username": "root","password": "123123","column": ["*"],"splitPk": "ID","where": "ID <= 1888","connection": [{"jdbcUrl": ["jdbc:mysql://192.168.1.1:3306/course-study?useUnicode=true&characterEncoding=utf8"], "table": ["t_member"]}]}}, "writer": {"name": "mysqlwriter", "parameter": {"column": ["*"], "connection": [{"jdbcUrl": "jdbc:mysql://192.168.1.2:3306/course-study?useUnicode=true&characterEncoding=utf8","table": ["t_member"]}], "password": "123123","preSql": ["truncate t_member"], "session": ["set session sql_mode='ANSI'"], "username": "root", "writeMode": "insert"}}}], "setting": {"speed": {"channel": "5"}}}
}
- 需要注意的部分就是:
where(条件筛选) 和preSql(同步前,要做的事) 参数。
2)验证:
[root@MySQL-1 ~]# python /usr/local/data/bin/data.py where.json
输出:
2021-12-16 17:34:38.534 [job-0] INFO JobContainer - PerfTrace not enable!
2021-12-16 17:34:38.534 [job-0] INFO StandAloneJobContainerCommunicator - Total 1888 records, 49543 bytes | Speed 1.61KB/s, 62 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.002s | All Task WaitReaderTime 100.570s | Percentage 100.00%
2021-12-16 17:34:38.537 [job-0] INFO JobContainer -
任务启动时刻 : 2021-12-16 17:34:06
任务结束时刻 : 2021-12-16 17:34:38
任务总计耗时 : 32s
任务平均流量 : 1.61KB/s
记录写入速度 : 62rec/s
读出记录总数 : 1888
读写失败总数 : 0
目标数据库上查看: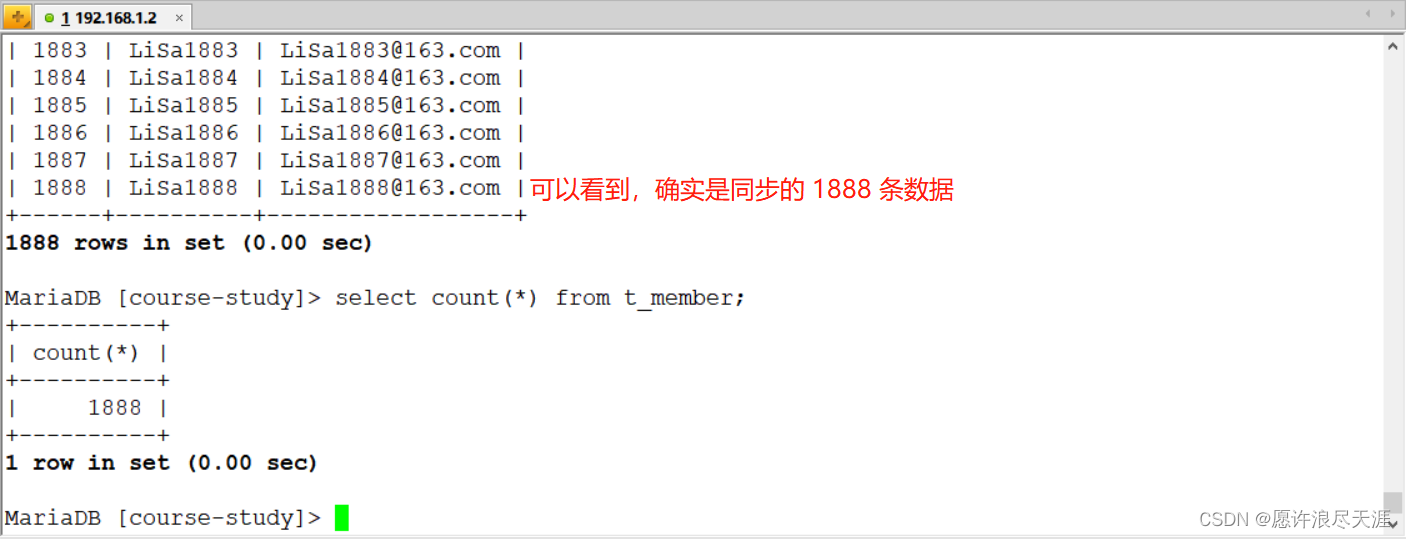
3)基于上面数据,再次进行增量同步:
主要是 where 配置:"where": "ID > 1888 AND ID <= 2888" # 通过条件筛选来进行增量同步
同时需要将我上面的 preSql 删除(因为我上面做的操作时 truncate 表)

相关文章:
【大数据进阶第三阶段之Datax学习笔记】使用阿里云开源离线同步工具DataX 实现数据同步
【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax概述 【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax快速入门 【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax类图 【大数据进阶第三阶段之Datax学习笔记】使用…...

kotlin chunked 和 windowed
kotlin chunked的作用 将集合按照指定的数量分割成多个结合 val numbers listOf(0,1,2,3,4,5,6,7,8,9) //把集合按照一个结合3个元素分割 Log.d("chunked", numbers.chunked(3).toString()) // 打印结果 [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]] kotlin windowed…...
C语言光速入门笔记
C语言是一门面向过程的编译型语言,它的运行速度极快,仅次于汇编语言。C语言是计算机产业的核心语言,操作系统、硬件驱动、关键组件、数据库等都离不开C语言;不学习C语言,就不能了解计算机底层。 目录 C语言介绍C语言特…...

Flutter+Go_Router+Fluent_Ui仿阿里网盘桌面软件开发跨平台实战-买就送仿小米app开发
Flutter是谷歌公司开发的一款开源、免费的UI框架,可以让我们快速的在Android和iOS上构建高质量App。它最大的特点就是跨平台、以及高性能。 目前 Flutter 已经支持 iOS、Android、Web、Windows、macOS、Linux 的跨平台开发。 Flutter官方介绍,目前Flutte…...
内联函数的作用
目的 主要为了提升程序运行速度。 分析 当程序调用一个函数时,程序暂停执行当前指令,跳到函数体处执行,在函数执行完后,返回原来的位置继续执行。如果该函数为内联函数,则不需跳,是因为该内联函数直接插…...
Simpy简介:python仿真模拟库-02/5
一、说明 关于python下的仿真库,本篇为第二部分,是更进一步的物理模型讲解,由于这部分内容强依赖于第一部分的符号介绍,因此,有以下建议: 此文为第二部分,若看第一部分。建议查看本系列的第一部…...

Kafka高级应用:如何配置处理MQ百万级消息队列?
在大数据时代,Apache Kafka作为一款高性能的分布式消息队列系统,广泛应用于处理大规模数据流。本文将深入探讨在Kafka环境中处理百万级消息队列的高级应用技巧。 本文,已收录于,我的技术网站 ddkk.com,有大厂完整面经…...

LIN总线学习笔记(1)-总线传输规范
关注菲益科公众号—>对话窗口发送 “CANoe ”或“INCA”,即可获得canoe入门到精通电子书和INCA软件安装包(不带授权码)下载地址。 接触LIN是从最近负责项目中开始的。项目已经快要量产了,因为中间遇到的大大小小的问题…...

Qt界面篇:Qt停靠控件QDockWidget、树控件QTreeWidget及属性控件QtTreePropertyBrowser的使用
1、功能介绍 本篇主要使用Qt停靠控件QDockWidget、树控件QTreeWidget及Qt属性控件QtTreePropertyBrowser来搭建一个简单实用的主界面布局。效果如下所示。 2、控件使用详解 2.1 停靠控件QDockWidget QDockWidget可以停靠在 QMainWindow 内或作为桌面上的顶级窗口浮动。默认值…...
H266/VVC网络适配层概述
视频编码标准的分层结构 视频数据分层的必要性:网络类型的多样性、不同的应用场景对视频有不同的需求。 编码标准的分层结构:为了适应不同网络和应用需求,视频编码数据根据其内容特性被分成若干NAL单元(NAL Unit,NALU…...
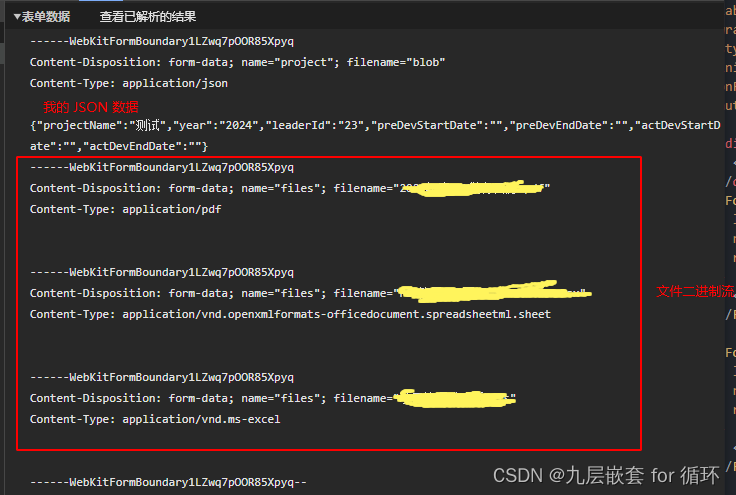
new FormData 同时发送表单 json 以及文件二进制流
需要新增时同时发送表单 json 以及对应的文件即可使用以下方法传参 let formDataParams new FormData(); 首先通过 new FormData() 创建你需要最后发送的表单 接着将你的对象 json 存储,注意使用 new Blob 创建大表单转换成 json 格式。以…...
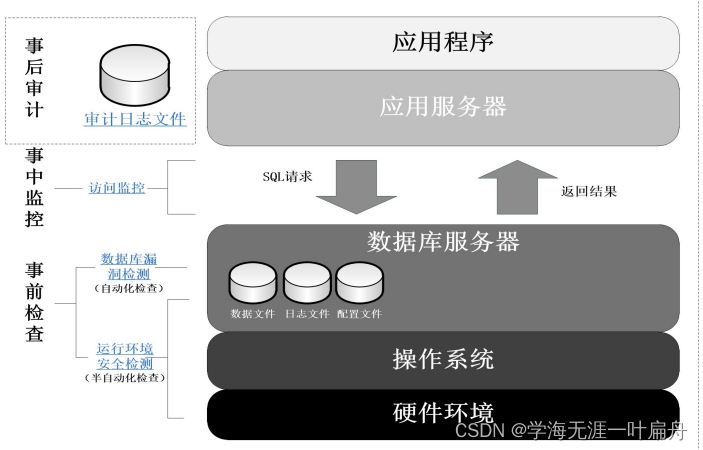
计算机环境安全
操作系统安全----比如windows,linux 安全标识--实体唯一性 windows---主体:账户,计算机,服务 安全标识符SID-Security Identifier 普通用户SID是1000,管理用SID是500 linux---主体:用户,用户组…...

Activiti7工作流引擎:多租户
一:多租户 表示每个租户之间数据隔离互不影响,互不可见。通常一个租户表示一个系统应用(类似于appid的作用)或者一家公司。 通过数据库级别进行隔离,每个租户对应一个数据库;通过表记录级别进行隔离&…...
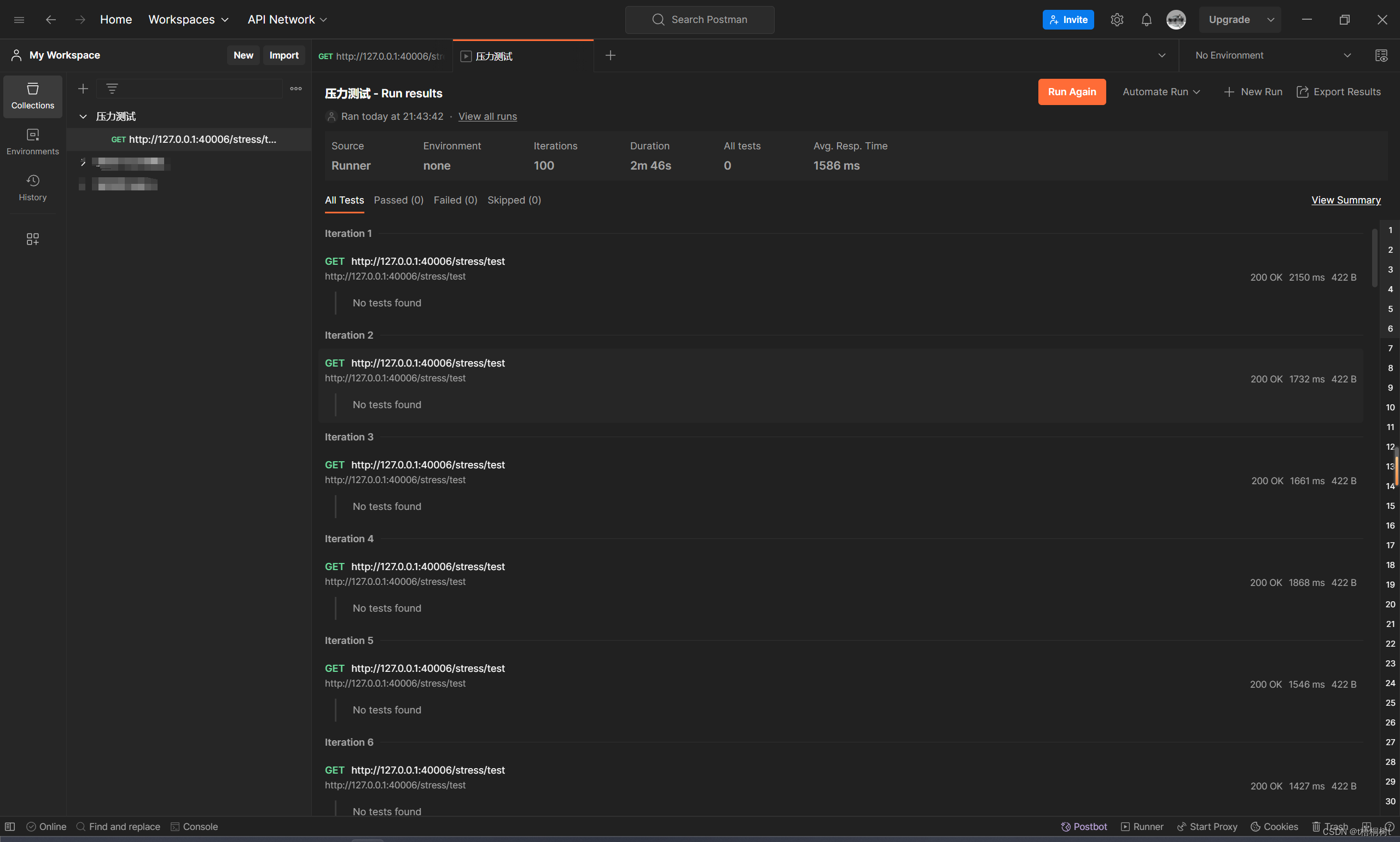
Postman实现压力测试
从事软件开发对于压力测试并不陌生,常见的一些压测软件有Apache JMeter LoadRunner Gatling Tsung 等,这些都是一些比较专业的测试软件,对于我的工作来说一般情况下用不到这么专业的测试,有时候需要对一些接口进行压力测试又不想再安装新软件,那么可以使用Postman来实现对…...
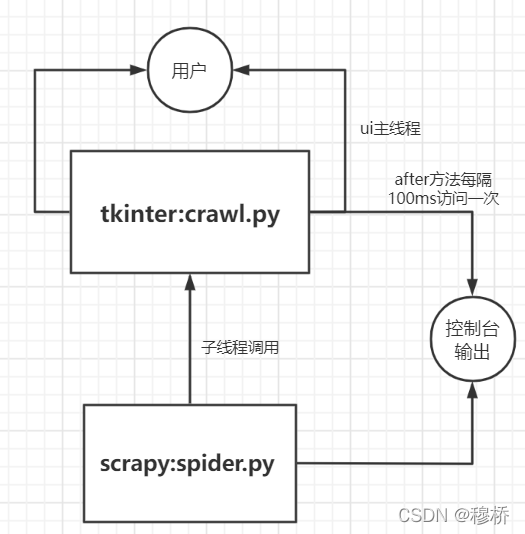
爬虫工具(tkinter+scrapy+pyinstaller)
需求介绍输入:关键字文件,每一行数据为一爬取单元。若一行存在多个and关系的关键字 ,则用|隔开处理:爬取访问6个网站的推送,获取推送内容的标题,发布时间,来源,正文第一段࿰…...

MySQL常用sql语句记录
1,创建用户及赋权 -- 创建用户 CREATE USER usernamelocalhost IDENTIFIED BY password;-- 赋予所有权限 GRANT ALL PRIVILEGES ON database_name.* TO usernamelocalhost;-- 赋予特定表的某些权限 GRANT SELECT, INSERT ON table_name TO usernamelocalhost;-- 更…...

2024.1.4力扣每日一题——被列覆盖的最多行数
2024.1.4 题目来源我的题解方法一 回溯位运算优化 题目来源 力扣每日一题;题序:2397 我的题解 方法一 回溯位运算优化 这道题一看就会想到使用回溯法,但是采用回溯法后如何判断有多少行被覆盖,直接计算矩阵时间复杂度较高&…...
Elasticsearch:Serarch tutorial - 使用 Python 进行搜索 (一)
本实践教程将教你如何使用 Elasticsearch 构建完整的搜索解决方案。 在本教程中你将学习: 如何对数据集执行全文关键字搜索(可选使用过滤器)如何使用机器学习模型生成、存储和搜索密集向量嵌入如何使用 ELSER 模型生成和搜索稀疏向量如何使用…...

第五讲_css元素显示模式
css元素显示模式 1. 元素的显示模式1.1 块元素1.2 行内元素1.3 行内块元素 2. 元素根据显示模式分类3. 修改元素的显示模式 1. 元素的显示模式 1.1 块元素 块元素的特性: 在页面中独占一行,从上到下排列。默认宽度,撑满父元素。默认高度&a…...

Shell脚本入门实战:探索自动化任务与实用场景
引言 Shell脚本作为一种强大的自动化工具,在现代操作系统中具有广泛的应用。无论是简单的文件操作,还是复杂的系统管理,Shell脚本都能提供高效、快速的解决方案。在本文中,我们将探索Shell脚本的基础知识,并通过实战场…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...

TDengine 快速体验(Docker 镜像方式)
简介 TDengine 可以通过安装包、Docker 镜像 及云服务快速体验 TDengine 的功能,本节首先介绍如何通过 Docker 快速体验 TDengine,然后介绍如何在 Docker 环境下体验 TDengine 的写入和查询功能。如果你不熟悉 Docker,请使用 安装包的方式快…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...
)
是否存在路径(FIFOBB算法)
题目描述 一个具有 n 个顶点e条边的无向图,该图顶点的编号依次为0到n-1且不存在顶点与自身相连的边。请使用FIFOBB算法编写程序,确定是否存在从顶点 source到顶点 destination的路径。 输入 第一行两个整数,分别表示n 和 e 的值(1…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

算法岗面试经验分享-大模型篇
文章目录 A 基础语言模型A.1 TransformerA.2 Bert B 大语言模型结构B.1 GPTB.2 LLamaB.3 ChatGLMB.4 Qwen C 大语言模型微调C.1 Fine-tuningC.2 Adapter-tuningC.3 Prefix-tuningC.4 P-tuningC.5 LoRA A 基础语言模型 A.1 Transformer (1)资源 论文&a…...