【Java集合类篇】HashMap的数据结构是怎样的?

HashMap的数据结构是怎样的?
- ✔️HashMap的数据结构
- ✔️ 数组
- ✔️ 链表
✔️HashMap的数据结构
在Java中,保存数据有两种比较简单的数据结构: 数组和链表(或红黑树)。
HashMap是Java中常用的数据结构,它实现了Map接口。HashMap通过键值对的形式存储数据,其中键是唯一的,而值可以是任何对象。HashMap底层使用数组和链表(或红黑树)来实现。
常用的哈希函数的冲突解决办法中有一种方法叫做链地址法,其实就是将数组和链表组合在一起,发挥了两者的优势,我们可以将其理解为链表的数组。在JDK 1.8之前,HashMap就是通过这种结构来存储数据的。

我们可以从上图看到,左边很明显是个数组,数组的每个成员是一个链表。该数据结构所容纳的所有元素均包含一个指针,用于元素间的链接。我们根据元素的自身特征把元素分配到不同的链表中去,反过来我们也正是通过这些特征找到正确的链表,再从链表中找出正确的元素。其中,根据元素特征计算元素数组下标的方法就是哈希算法,即本文的主角 hash() 函数 (当然,还包括indexOf()函数)。
✔️ 数组
数组:
HashMap使用一个数组来存储键值对。数组的每个元素都是一个桶(bucket),桶中存储着一个链表(LinkedList)或红黑树(TreeMap)。桶的数量可以根据需要动态调整。数组的索引方式采用哈希算法,通过将键的哈希值对数组长度取模来得到对应的桶。
数组的特点是:寻址容易,插入和删除困难。
看一个如何使用数组实现HashMap的代码片段:
public class MyHashMap<K, V> { // 默认初始容量 private static final int DEFAULT_INITIAL_CAPACITY = 16; // 默认加载因子 private static final float DEFAULT_LOAD_FACTOR = 0.75f; // 存储键值对的数组 private Entry<K, V>[] table; // 当前容量 private int capacity; // 实际存储的键值对数量 private int size; public MyHashMap() { this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR); } public MyHashMap(int capacity) { this(capacity, DEFAULT_LOAD_FACTOR); } public MyHashMap(int capacity, float loadFactor) { this.capacity = capacity; table = new Entry[capacity]; size = 0; } public V put(K key, V value) { int hash = hash(key); int index = indexFor(hash, table.length); Entry<K, V> oldValue = table[index]; if (oldValue == null) { table[index] = new Entry<>(key, value, null); size++; if (size > capacity * loadFactor) { rehash(); } } else { Entry<K, V> newEntry = new Entry<>(key, value, oldValue); table[index] = newEntry; } return oldValue == null ? null : oldValue.value; } public V get(K key) { int hash = hash(key); int index = indexFor(hash, table.length); Entry<K, V> entry = table[index]; if (entry != null && Objects.equals(entry.key, key)) { return entry.value; } else { return null; } } public int size() { return size; } private int hash(Object key) { return Objects.hashCode(key); } private int indexFor(int hash, int length) { return hash % length; } private void rehash() { Entry<K, V>[] oldTable = table; int oldCapacity = oldTable.length; int newCapacity = oldCapacity * 2; Entry<K, V>[] newTable = new Entry[newCapacity]; for (Entry<K, V> oldEntry : oldTable) { while (oldEntry != null) { Entry<K, V> next = oldEntry.next; int hash = hash(oldEntry.key); int index = indexFor(hash, newCapacity); oldEntry.next = newTable[index]; newTable[index] = oldEntry; oldEntry = next; } } table = newTable; capacity = newCapacity; }
}
✔️ 链表
链表:当多个键的哈希值映射到同一个桶时,它们会形成一个链表。链表中的每个节点包含一个键值对和指向下一个节点的指针。链表的作用是在插入、删除和查找操作时解决哈希冲突。
链表的特点是: 寻址困难,插入和删除容易
看一个如何使用链表实现HashMap的代码片段,是一个简单的HashMap实现,使用链表来处理哈希冲突:
public class MyHashMap<K, V> { private static class Entry<K, V> { K key; V value; Entry<K, V> next; Entry(K key, V value, Entry<K, V> next) { this.key = key; this.value = value; this.next = next; } } private Entry<K, V>[] table; private int capacity; private int size; private float loadFactor; public MyHashMap(int capacity, float loadFactor) { if (capacity < 0) throw new IllegalArgumentException("Capacity must be non-negative"); if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Load factor must be positive"); this.capacity = capacity; this.loadFactor = loadFactor; table = new Entry[capacity]; size = 0; } public V put(K key, V value) { if (key == null) return null; // HashMaps don't allow null keys // If size exceeds load factor * capacity, rehash if (size >= capacity * loadFactor) { rehash(); } int hash = hash(key); int index = indexFor(hash, capacity); Entry<K, V> entry = table[index]; if (entry == null) { // No collision, create new entry table[index] = new Entry<>(key, value, null); size++; } else { // Collision occurred, handle it using chaining while (entry != null && !entry.key.equals(key)) { if (entry.next == null) { // End of chain, insert new entry entry.next = new Entry<>(key, value, null); size++; break; } entry = entry.next; } // If key already exists, update value if (entry != null && entry.key.equals(key)) { V oldValue = entry.value; entry.value = value; return oldValue; } } return null; // If key was new or not found } public V get(K key) { if (key == null) return null; // HashMaps don't allow null keys int hash = hash(key); int index = indexFor(hash, capacity); Entry<K, V> entry = table[index]; while (entry != null && !entry.key.equals(key)) { entry = entry.next; } return entry == null ? null : entry.value; } private void rehash() { capacity *= 2; Entry<K, V>[] oldTable = table; table = new Entry[capacity]; size = 0; for (Entry<K, V> entry : oldTable) { while (entry != null) { Entry<K, V> next = entry.next; int hash = hash(entry.key); int index = indexFor(hash, capacity); entry.next = table[index]; table[index] = entry; size++; entry = next; } } } private int hash(K key) { return Math.abs(key.hashCode()) % capacity; } private int indexFor(int hash, int length) { return hash % length; } public static void main(String[] args) { MyHashMap<String, Integer> map = new MyHashMap<>(16, 0.75f); map.put("one", 1); map.put("two", 2); map.put("three", 3); System.out.println(map.get("one")); // Should print 1 System.out.println(map.get("two")); // Should print 2 System.out.println(map.get("three")); //Should print 3
在JDK 1.8中为了解决因hash冲突导致某个链表长度过长,影响 put 和 get 的效率,引入了红黑树。
关于红黑树,下一篇会作为单独的博文进行更新。
相关文章:
【Java集合类篇】HashMap的数据结构是怎样的?
HashMap的数据结构是怎样的? ✔️HashMap的数据结构✔️ 数组✔️ 链表 ✔️HashMap的数据结构 在Java中,保存数据有两种比较简单的数据结构: 数组和链表(或红黑树)。 HashMap是 Java 中常用的数据结构,它实现了 Map 接口。Has…...
:摸石头过河 | 京东云技术团队)
Spring 应用合并之路(一):摸石头过河 | 京东云技术团队
公司在推进降本增效,在尝试多种手段之后,发现应用太多,每个应用都做跨机房容灾部署,则最少需要 4 台机器(称为容器更合适)。那么,将相近应用做一个合并,减少维护项目,提高…...

Android13配置selinux让system应用可读sys,proc,SN号
system权限应用读sys,proc目录及SN号 Android13预置的system应用,需要读/sys, /proc目录,读(SN)serial number号, 需要修改selinux配置,否则会报avc错. 其修改方法会比Android11复杂一些. 实现 system_app.te中添加…...

防勒索病毒攻击的关键措施
【作者】朱向东 中原银行 高级工程师 在当今数字化时代,勒索病毒成为了企业和个人面临的一项严峻威胁。勒索病毒攻击可以导致数据丢失、系统瘫痪以及经济损失。为了保护自己和组织的利益,采取一系列的防范措施是至关重要的。下面是一些关键的措施&#…...

代表团坐车 - 华为OD统一考试
OD统一考试(B卷) 分值: 100分 题解: Java / Python / C++ 题目描述 某组织举行会议,来了多个代表团同时到达,接待处只有一辆汽车可以同时接待多个代表团,为了提高车辆利用率,请帮接待员计算可以坐满车的接待方案输出方案数量。 约束: 一个团只能上一辆车,并且代表团…...
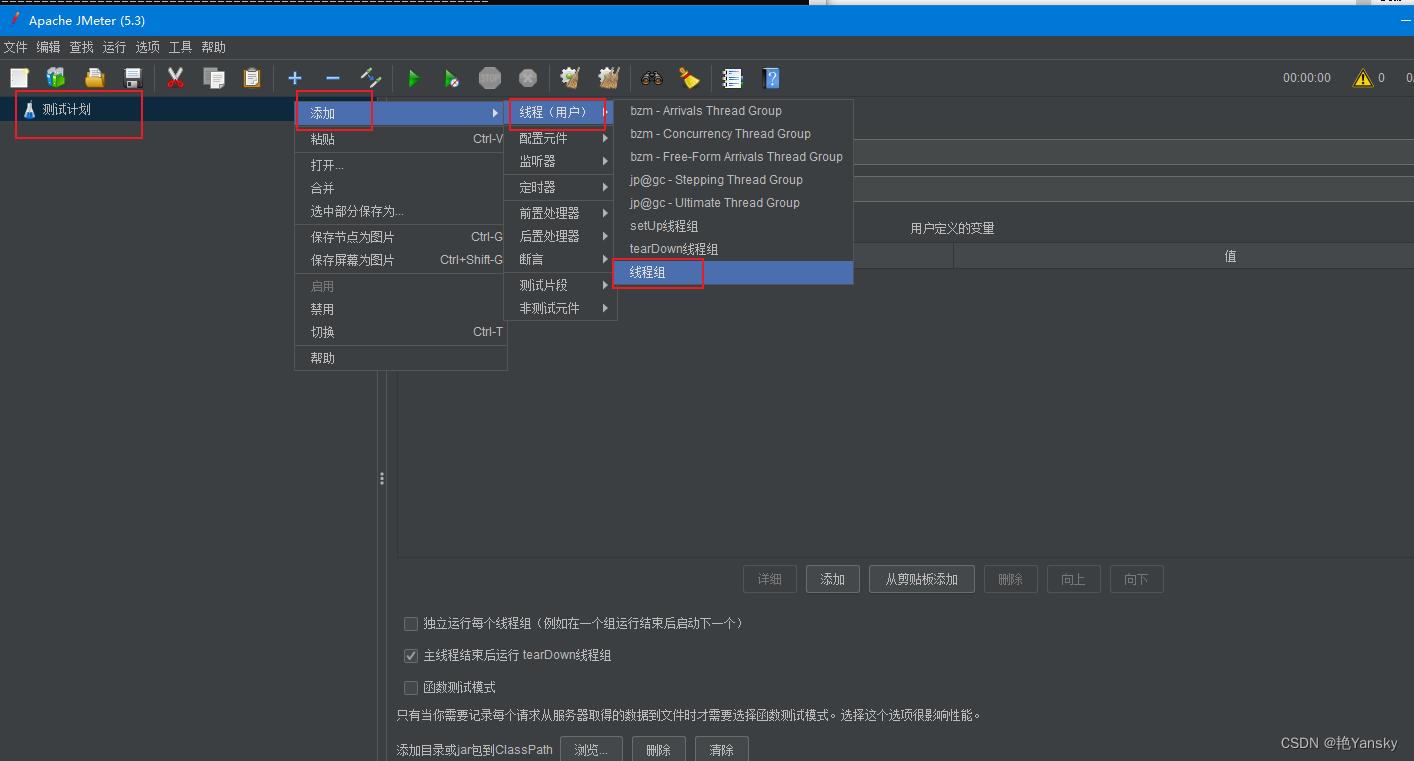
运用Jmeter进行登录测试
开始了解Jmeter,写篇关于Jmeter的博客做备忘,这里以苏宁易购网站的登录请求为例实战来说明测试计划元件,创建一个 Web 测试计划。 今天简单介绍Jemeter的入门,Jmeter 的安装这边就跳过,直接讲述如何使用JMETER,如何运用Jmeter进行测试。 a.下载jmeter软件 b.安装…...
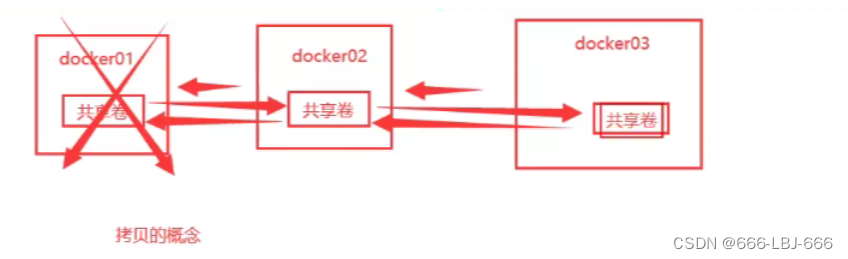
Docker学习与应用(四)-容器数据卷
1、容器数据卷 1)什么是容器数据卷 docker的理念回顾 将应用和环境打包成一个镜像! 数据?如果数据都在容器中,那么我们容器删除,数据就会丢失!需求:数据可以持久化 MySQL,容器删…...

CentOS 7.6下HTTP隧道代理的安全性考虑
在CentOS 7.6上配置HTTP隧道代理时,安全性是一个不可忽视的重要因素。以下是对HTTP隧道代理安全性的一些关键考虑因素: 1. 加密和数据安全 使用强加密算法:确保您使用的是经过广泛认可和强化的加密算法,如AES-256-GCM。数据完整…...

Mockito+junit5搞定单元测试
目录 一、简介1.1 单元测试的特点1.2 Mock类框架的使用场景1.3 常见的Mock框架1.3.1 Mockito1.3.2 EasyMock1.3.3 PowerMock1.3.4 Testable1.3.5 比较 二、Mockito的使用2.1 导入pom文件2.2 mock对象和spy对象2.3 初始化mock/spy对象的方式2.4 参数匹配2.5 方法插桩2.6 InjectM…...

PostgreSQL获取当天、昨天、本月、上个月、本年、去年的数据
gps_time为timestamp类型日期字段 获取当天的数据 WHERE DATE_TRUNC(day, gps_time) CURRENT_DATE --或 WHERE DATE(gps_time) CURRENT_DATE获取昨天的数据 WHERE DATE_TRUNC(day, gps_time) CURRENT_DATE - INTERVAL 1 day获取本月的数据 WHERE DATE_TRUNC(month, gps_…...
XCTF:stage1[WriteUP]
从题目中下载到图片: 考虑图片是png,隐写方式有可能是高宽修改,也可能是色相隐藏,色彩通道位隐藏等等 使用stegsolve对图片进行一下伽马、颜色转换 在图片的左上角就显示出了一个二维码 使用QR_Rresearch工具对二维码扫描 获得一…...

STM32CubeMX教程13 ADC - 单通道转换
目录 1、准备材料 2、实验目标 3、ADC概述 4、实验流程 4.0、前提知识 4.1、CubeMX相关配置 4.1.1、时钟树配置 4.1.2、外设参数配置 4.1.3、外设中断配置 4.2、生成代码 4.2.1、外设初始化调用流程 4.2.2、外设中断调用流程 4.2.3、添加其他必要代码 5、常用函数…...

矩阵的乘法
首先矩阵的乘法定义如下: #include <stdio.h> int main() { int i 0; int j 0; int arr[20][20] { 0 }; int str[20][20] { 0 }; int s[20][20] { 0 }; int n1 0; int n2 0; int m2 0; int z 0; int m1 0;…...

python爬取招聘网站数据
这段代码是使用Selenium自动化测试模块进行网页爬取的示例代码。它通过模拟人的行为在浏览器中操作网页来实现爬取。具体的流程如下: 导入所需的模块,包括Selenium、时间、随机、csv等模块。打开浏览器,创建一个Chrome浏览器实例。设置要爬取…...
灌区信息化方案(什么是现代化灌区,如何一步到位)
一、系统概述 详情:https://www.key-iot.com.cn/ 本灌区信息化方案以星创易联公司的各类智能设备为基础,通过其产品完成水文、雨情、土壤等多源异构数据的采集,以无线自组网的方式实现数据传输,并在后台管理中心建立信息化软件平台,对数据进行融合处理。系统实现对…...
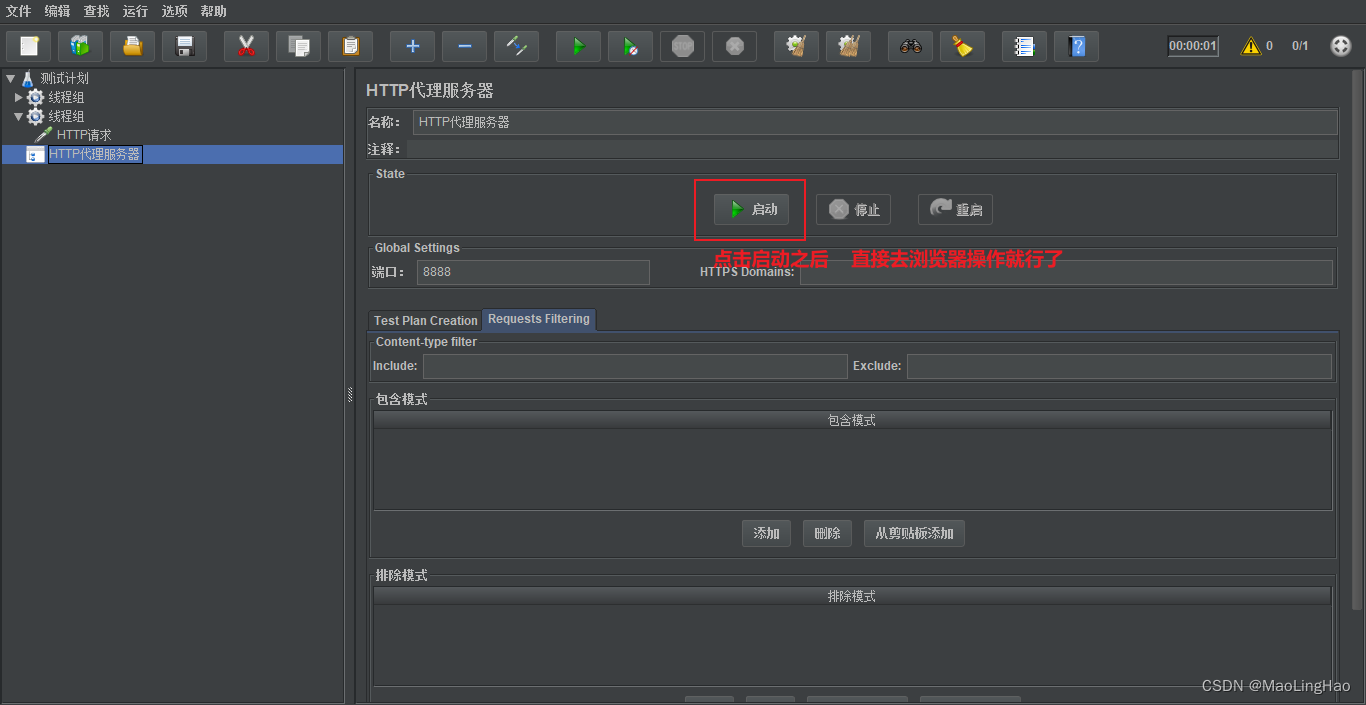
jmeter自动录制脚本功能
问题排查: 建议用 google浏览器; 重启一下jmeter; 过滤规则重新检查下; 看下代理设置是否正常; 注意:下面的的过滤设置中 用的都是正则表达式的规则。...

十一、工具盒类(MyQQ)(Qt5 GUI系列)
目录 编辑 一、设计需求 二、实现代码 三、代码解析 四、总结 一、设计需求 抽屉效果是软件界面设计中的一种常用形式,可以以一种动态直观的方式在有限大小的界面上扩展出更多的功能。本例要求实现类似 QQ 抽屉效果。 二、实现代码 #include "dialog.…...

postgresql 查询字段 信息
SELECT base.“column_name”, col_description ( t1.oid, t2.attnum ), base.udt_name, COALESCE(character_maximum_length, numeric_precision, datetime_precision), (CASE WHEN ( SELECT t2.attnum ANY ( conkey ) FROM pg_constraint WHERE conrelid t1.oid AND contyp…...

antv/x6_2.0学习使用(四、边)
一、添加边 节点和边都有共同的基类 Cell,除了从 Cell 继承属性外,还支持以下选项。 属性名类型默认值描述sourceTerminalData-源节点或起始点targetTerminalData-目标节点或目标点verticesPoint.PointLike[]-路径点routerRouterData-路由connectorCon…...

C++ stack用法总结
std::stack 是 C 标准模板库(STL)中的容器适配器,它提供了栈(stack)的功能,基于其他序列容器实现。以下是 std::stack 的用法总结: 包含头文件: #include <stack>创建 std::…...

C++中显示与隐式加载dll的使用与区别
一、什么是 DLL?DLL(Dynamic Link Library) 是 Windows 下的动态链接库,包含可被多个程序共享的函数、资源或类。使用 DLL 可以实现代码复用、模块化设计和插件机制。在 C 中,调用 DLL 中的函数有两种主要方式…...

机器学习模型评估中的构念效度:超越基准测试分数的科学推断
1. 项目概述与核心问题在机器学习的日常研究和工程实践中,我们每天都在和各种各样的基准测试(Benchmark)打交道。无论是为了比较新提出的ResNet变体在ImageNet上的Top-1准确率,还是评估一个大型语言模型在MMLU上的常识推理能力&am…...

AI智能体到底强在哪?为什么大家开始从“养龙虾”转向“养马”
那么AI智能体的核心能力是什么? 1、理解需求 它能分析你的真实意图,而不是只看表面的文字,比如让它整理这个月的消费情况,它明白之后,会读取账单,做分类统计,生成总结,最后输出图表。…...

BurpSuite 2025插件开发JDK版本兼容性实战指南
1. 为什么BurpSuite插件开发环境总在JDK版本上翻车?你是不是也经历过:下载好BurpSuite最新版2025.4,兴冲冲打开插件开发文档,照着官方示例写完第一个HelloWorld插件,一编译——java.lang.UnsupportedClassVersionError…...

量子软件测试的挑战与优化策略
1. 量子软件测试的挑战与机遇量子计算正在从实验室走向实际应用,随之而来的是对可靠量子软件的需求激增。与传统软件不同,量子程序面临三大独特挑战:首先,量子态的叠加性和纠缠性使得测试变得异常复杂。一个n量子比特系统可以同时…...

广州因特智能:AI视觉软硬结合,打破半导体检测装备“卡脖子”困境
【导语:广州因特智能科技孵化于西安电子科技大学广州研究院,专注用AI视觉技术解决工业场景的“卡脖子”检测难题,为半导体、光通信、新能源三大领域提供高端检测装备。】校地合作孵化,构建完整能力体系广州因特智能科技由西安电子…...

终极Node.js Mock工具:Mockery入门到精通实战教程
终极Node.js Mock工具:Mockery入门到精通实战教程 【免费下载链接】mockery Simplifying the use of mocks with Node.js 项目地址: https://gitcode.com/gh_mirrors/mock/mockery Mockery是Node.js生态中简化Mock使用的终极工具,它为开发者提供了…...
:3类高危使用场景+2个监管红线预警)
Claude SWOT分析(内部风控文档流出版):3类高危使用场景+2个监管红线预警
更多请点击: https://intelliparadigm.com 第一章:Claude SWOT分析(内部风控文档流出版):3类高危使用场景2个监管红线预警 高危使用场景识别 在企业级AI应用中,Claude模型若未经严格风控适配,…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词
终极歌词同步神器LRCGET:5分钟为你的音乐库添加完美歌词 【免费下载链接】lrcget Utility for mass-downloading LRC synced lyrics for your offline music library. 项目地址: https://gitcode.com/gh_mirrors/lr/lrcget 你是否厌倦了在听歌时手动搜索歌词…...