python爬取招聘网站数据
这段代码是使用Selenium自动化测试模块进行网页爬取的示例代码。它通过模拟人的行为在浏览器中操作网页来实现爬取。具体的流程如下:
- 导入所需的模块,包括Selenium、时间、随机、csv等模块。
- 打开浏览器,创建一个Chrome浏览器实例。
- 设置要爬取的页数范围。
- 循环遍历每一页的URL。
- 访问每一页的URL,获取网页数据。
- 创建一个CSV文件,设置字段名。
- 获取每个职位的详情页URL。
- 遍历每个详情页URL,发送请求获取响应数据。
- 使用css选择器解析响应数据,提取所需的数据内容。
- 将提取到的数据写入CSV文件。
- 打印出职位的相关信息。
该代码的主要功能是爬取招聘网上的职位信息,包括职位名、薪资、城市、经验、学历、福利、岗位标签、公司名、详情页等信息。使用了Selenium模拟人的行为,通过使用开发者工具获取到的CSS选择器来定位和提取数据。
# 导入自动化测试模块
from selenium import webdriver
# 导入时间模块
import time
# 导入随机模块
import random
# 导入csv模块 内置模块 不需要安装
import csv
import requests
import parsel
"""
selenium: 模拟人的行为去操作浏览器
"""
# 1. 打开浏览器
driver = webdriver.Chrome()# 设置页数范围
start_page = 0
end_page = 10 # 假设要爬取前5页的数据
for page in range(start_page, end_page):# 2. 访问网站url = f'https://www.liepin.com/zhaopin/?city=070020&dq=070020&pubTime=¤tPage={page}&pageSize=40&key=%E8%B4%A2%E5%8A%A1bp&suggestTag=&workYearCode=0&compId=&compName=&compTag=&industry=&salary=&jobKind=&compScale=&compKind=&compStage=&eduLevel=&otherCity=&sfrom=search_job_pc&ckId=vda04kszzsgxhhl7nc4fc21r5hthguv9&scene=condition&skId=vda04kszzsgxhhl7nc4fc21r5hthguv9&fkId=vda04kszzsgxhhl7nc4fc21r5hthguv9&suggestId='driver.get(url)# 隐式等待 ---> 让网页数据加载完成driver.implicitly_wait(10)time.sleep(3)# 创建文件f = open('data.csv', mode='a', encoding='utf-8', newline='')csv_writer = csv.DictWriter(f, fieldnames=['职位名','薪资','城市','经验','学历','福利','岗位标签','公司名','详情页',])# 写入表头csv_writer.writeheader()# 3. 获取岗位详情页url地址url_list = driver.find_elements('css selector', '.job-detail-box a')for index in url_list:url = index.get_attribute('href')print(url)time.sleep(random.randint(1, 2))"""1. 发送请求, 模拟浏览器对 url地址 发送请求- 把python代码伪装成浏览器发送请求目的: 为了防止被反爬"""# 请求url地址# url = 'https://www.liepin.com/job/1948917627.shtml?d_sfrom=search_prime&d_ckId=null&d_curPage=2&d_pageSize=40&d_headId=null&d_posi=1&skId=s5h3mfxh8n1c3ec3dr7nnc6d4lycb9db&fkId=s5h3mfxh8n1c3ec3dr7nnc6d4lycb9db&ckId=s5h3mfxh8n1c3ec3dr7nnc6d4lycb9db&sfrom=search_job_pc&curPage=2&pageSize=40&index=1'# 模拟伪装 ---> 开发者工具里面进行复制粘贴headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36',}# 发送请求 -> <Response [200]> 表示请求成功response = requests.get(url=url, headers=headers)"""2. 获取数据, 获取服务器返回响应数据开发者工具: responseresponse.text 获取响应文本数据, 返回字符串数据类型 html字符串数据内容3. 解析数据, 提取我们想要的数据内容css选择器 根据标签属性提取数据内容:"""# 把获取下来 html字符串数据内容 <response.text> 转成可解析对象selector = parsel.Selector(response.text)""".job-apply-content .name-box .name 定位标签- get() 获取第一个标签 就获取一个内容 返回字符串- getall 获取所有标签内容, 返回列表css选择器, 在系统课程 都是从头到尾讲2.5个小时才能讲完知识点内容a::text 表示 提取a标签里面文本呀"""title = selector.css('.job-apply-content .name-box .name::text').get() # 职位名salary = selector.css('.job-apply-content .name-box .salary::text').get() # 薪资city = selector.css('.job-apply-content .job-properties span:nth-child(1)::text').get() # 城市exp = selector.css('.job-apply-content .job-properties span:nth-child(3)::text').get() # 经验edu = selector.css('.job-apply-content .job-properties span:nth-child(5)::text').get() # 学历# 把列表合并成字符串labels = ','.join(selector.css('.job-apply-container-desc .labels span::text').getall()) # 福利job_labels = ','.join(selector.css('.tag-box ul li::text').getall()) # 职位标签company = selector.css('.company-info-container .company-card .content .name::text').get() # 公司名job_info = '\n'.join(selector.css('.job-intro-container .paragraph dd::text').getall()) # 岗位职业"""4. 保存数据, 把数据保存本地文件- 基本数据 保存csv表格里面- 岗位职责 保存文本里面"""# 把数据写入到字典里面dit = {'职位名': title,'薪资': salary,'城市': city,'经验': exp,'学历': edu,'福利': labels,'岗位标签': job_labels,'公司名': company,'详情页': url,}# 写入数据csv_writer.writerow(dit)print(title, salary, city, exp, edu, labels, job_labels, company, job_info)
相关文章:

python爬取招聘网站数据
这段代码是使用Selenium自动化测试模块进行网页爬取的示例代码。它通过模拟人的行为在浏览器中操作网页来实现爬取。具体的流程如下: 导入所需的模块,包括Selenium、时间、随机、csv等模块。打开浏览器,创建一个Chrome浏览器实例。设置要爬取…...
灌区信息化方案(什么是现代化灌区,如何一步到位)
一、系统概述 详情:https://www.key-iot.com.cn/ 本灌区信息化方案以星创易联公司的各类智能设备为基础,通过其产品完成水文、雨情、土壤等多源异构数据的采集,以无线自组网的方式实现数据传输,并在后台管理中心建立信息化软件平台,对数据进行融合处理。系统实现对…...
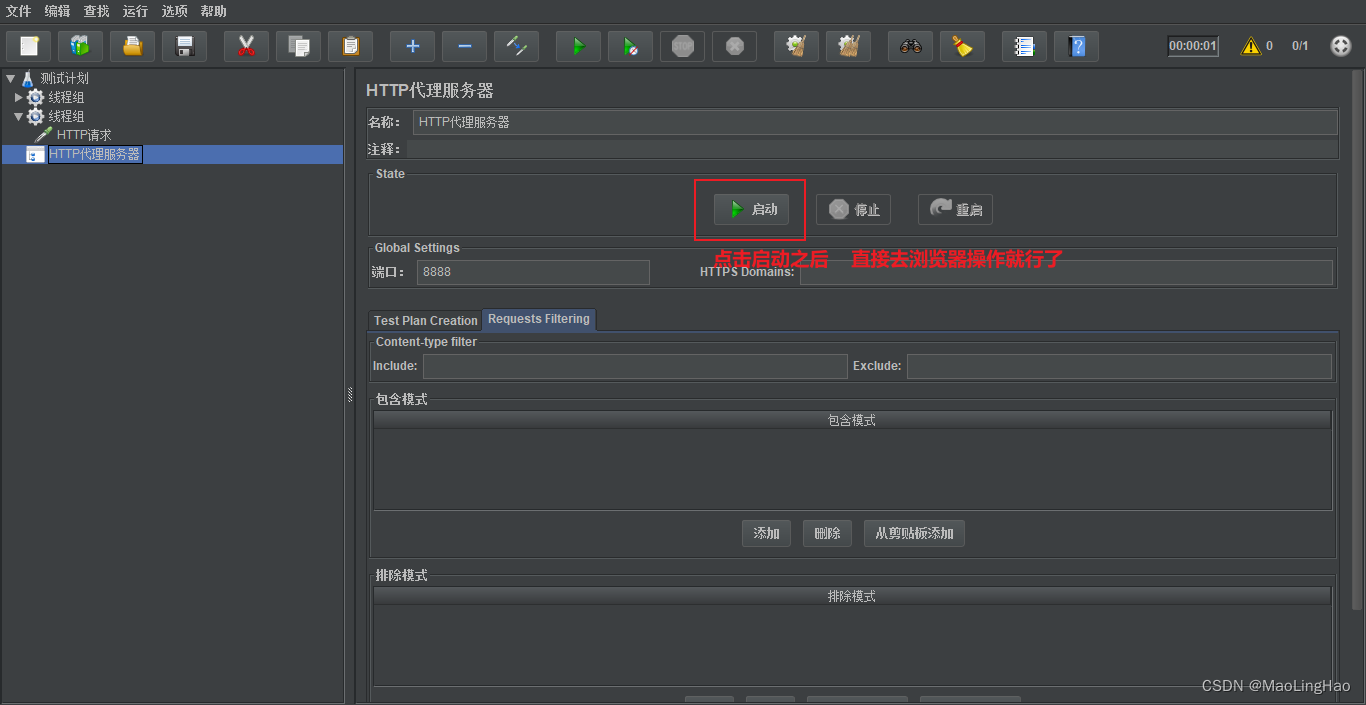
jmeter自动录制脚本功能
问题排查: 建议用 google浏览器; 重启一下jmeter; 过滤规则重新检查下; 看下代理设置是否正常; 注意:下面的的过滤设置中 用的都是正则表达式的规则。...

十一、工具盒类(MyQQ)(Qt5 GUI系列)
目录 编辑 一、设计需求 二、实现代码 三、代码解析 四、总结 一、设计需求 抽屉效果是软件界面设计中的一种常用形式,可以以一种动态直观的方式在有限大小的界面上扩展出更多的功能。本例要求实现类似 QQ 抽屉效果。 二、实现代码 #include "dialog.…...

postgresql 查询字段 信息
SELECT base.“column_name”, col_description ( t1.oid, t2.attnum ), base.udt_name, COALESCE(character_maximum_length, numeric_precision, datetime_precision), (CASE WHEN ( SELECT t2.attnum ANY ( conkey ) FROM pg_constraint WHERE conrelid t1.oid AND contyp…...

antv/x6_2.0学习使用(四、边)
一、添加边 节点和边都有共同的基类 Cell,除了从 Cell 继承属性外,还支持以下选项。 属性名类型默认值描述sourceTerminalData-源节点或起始点targetTerminalData-目标节点或目标点verticesPoint.PointLike[]-路径点routerRouterData-路由connectorCon…...

C++ stack用法总结
std::stack 是 C 标准模板库(STL)中的容器适配器,它提供了栈(stack)的功能,基于其他序列容器实现。以下是 std::stack 的用法总结: 包含头文件: #include <stack>创建 std::…...
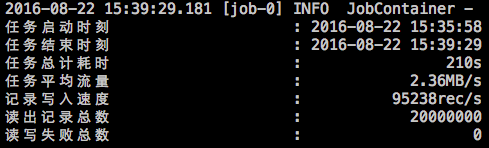
【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax概述
【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax概述 【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax快速入门 【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax类图 【大数据进阶第三阶段之Datax学习笔记】使用…...
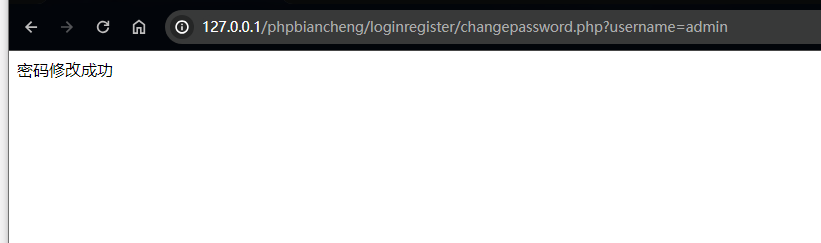
PHP 基础编程 2
文章目录 时间函数dategetdatetime 使用数组实现登录注册和修改密码简单数组增加元素方法修改元素方法删除元素方法 具体实现方法数组序列化数组写入文件判断元素是否在关联数组中(登录功能实现)实现注册功能实现修改admin用户密码功能 时间函数 时区&am…...

git merge origin master 和 git merge origin/master 的区别
git merge origin master和git merge origin/master的区别 1. git checkout dev 2. git fetch origin master 3. git merge origin release 把 origin/master,heads/release merge到 heads/dev1. git checkout dev 2. git fetch origin master 3. git me…...

数据挖掘 模糊聚类
格式化之前的代码: import matplotlib.pyplot as plt#绘图 import pandas as pd#读取数据集 from sklearn.preprocessing import scale from sklearn.cluster import DBSCAN#聚类 from sklearn import preprocessing#数据预处理的功能,包括缩放、标准化…...

Vue2和Vue3各自的优缺点以及区别对比
Vue2和Vue3各自的优缺点以及区别对比 Vue2的优点: 成熟稳定:Vue2是一个经过长时间发展和测试的成熟版本,广泛应用于各种项目中。 生态系统丰富:由于Vue2的流行程度,它的生态系统相对较为完善,有大量的插件…...

手写一个加盐加密算法(java实现)
目录 前言 什么是MD5?? 加盐算法 那别的人会不会跟你得到相同的UUID? 如何使用盐加密? 代码实现 前言 对于我们常见的登录的时候需要用到的组件,加密是一个必不可少的东西,如果我们往数据库存放用户…...
基于Springboot的在线考试系统
点击以下链接获取源码: https://download.csdn.net/download/qq_64505944/88499371 mysql5、mysql8都可使用 内含配置教程文档,一步一步配置 Springboot所写 管理员页面 学生页面...

【React系列】JSX核心语法和原理
本文来自#React系列教程:https://mp.weixin.qq.com/mp/appmsgalbum?__bizMzg5MDAzNzkwNA&actiongetalbum&album_id1566025152667107329) 一. ES6 的 class 虽然目前React开发模式中更加流行hooks,但是依然有很多的项目依然是使用类组件&#x…...

【C++初阶(九)】C++模版(初阶)----函数模版与类模版
本专栏内容为:C学习专栏,分为初阶和进阶两部分。 通过本专栏的深入学习,你可以了解并掌握C。 💓博主csdn个人主页:小小unicorn ⏩专栏分类:C 🚚代码仓库:小小unicorn的代码仓库&…...

Permission denied
Permission denied:权限被拒绝,没有访问文件的权限。 查询对文件的权限: ls -l 文件名称 r为可读权限,w为可写权限,x为可执行权限。 授权文件rwx,可读可写可执行权限: chmod 777 文件名称 如…...

轻松学会电脑如何录制音频
随手录音,保留证据以便后续出现问题进行判定,或者保存会议音频记录方便后续根据录音内容整理自己会议记录不足之处等等;越来越多的地方需要用到录音,那么在电脑上该如何进行音频录制呢?特别是使用比较广泛的Windows电脑…...

react antd,echarts全景视图
1.公告滚动,40s更新一次 2.echarts图标 左右轮播 60s更新一次 3.table 表格 import { useState, useEffect } from react;import Slider from react-slick; import slick-carousel/slick/slick-theme.css; import slick-carousel/slick/slick.css;import Layout fro…...
GD32 支持IAP的bootloader开发,使用串口通过Ymodem协议传输固件(附代码)
资料下载: https://download.csdn.net/download/wouderw/88714985 一、概述 关于IAP的原理和Ymodem协议,本文不做任何论述,本文只论述bootloader如何使用串口通过Ymodem协议接收升级程序并进行IAP升级,以及bootloader和主程序两个工程的配置…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

Java毕业设计:WML信息查询与后端信息发布系统开发
JAVAWML信息查询与后端信息发布系统实现 一、系统概述 本系统基于Java和WML(无线标记语言)技术开发,实现了移动设备上的信息查询与后端信息发布功能。系统采用B/S架构,服务器端使用Java Servlet处理请求,数据库采用MySQL存储信息࿰…...