mmdetection训练自己的数据集
mmdetection训练自己的数据集
这里写目录标题
- mmdetection训练自己的数据集
- 一: 环境搭建
- 二:数据集格式转换(yolo转coco格式)
- yolo数据集格式
- coco数据集格式
- yolo转coco数据集格式
- yolo转coco数据集格式的代码
- 三: 训练
- dataset数据文件配置
- configs
- 1.在configs/faster_rcnn/faster-rcnn_r101_fpn_1x_coco.py我们发现,索引的是'./faster-rcnn_r50_fpn_1x_coco.py'
- 2.找到'./faster-rcnn_r50_fpn_1x_coco.py',发现索引是下面代码
- 3.修改
- 4.训练
- 五: 还在继续研究的内容
一: 环境搭建
- 有很多的环境搭建过程,这里就不介绍,我自己也搭建环境了,一会就搭建好了。
二:数据集格式转换(yolo转coco格式)
yolo数据集格式
- 因为我平时训练目标检测数据集用的YOLO系列,所以数据集格式标签也是txt,在最近接触的mmdetection训练目标检测数据集是需要用到coco格式,所以在这里需要转换数据集的格式。
- 先来看看yolo数据集标签的格式,图片和标签一一对应的。有多少张图片就有多少张txt文件标签。
├── linhuo(这个是数据集名称)
│ ├── images
│ │ ├── train
│ │ │ ├── 1.jpg
│ │ │ ├── 2.jpg
│ │ │ ├── …
│ │ ├── val
│ │ │ ├── 2000.jpg
│ │ │ ├── 2001.jpg
│ │ │ ├── …
│ │ ├── test
│ │ │ ├── 3000.jpg
│ │ │ ├── 30001.jpg
│ │ │ ├── …
│ ├── labels
│ │ ├── train
│ │ │ ├── 1.xml
│ │ │ ├── 2.xml
│ │ │ ├── …
│ │ ├── val
│ │ │ ├── 2000.xml
│ │ │ ├── 2001.xml
│ │ │ ├── …
│ │ ├── test
│ │ │ ├── 3000.xml
│ │ │ ├── 3001.xml
│ │ │ ├── …
coco数据集格式
- coco数据集格式如下:
├── data
│ ├── coco
│ │ ├── annotations
│ │ │ ├── instances_train2017.json
│ │ │ ├── instances_val2017.json
│ │ ├── train2017
│ │ ├── val2017
│ │ ├── test2017
yolo转coco数据集格式
- 我们需要对yolo的数据集的训练集(train)、验证集(val)、测试集(test)标签分别进行转换生成coco数据集的标签格式(图片相对是不变的)instances_train2017.json、 instances_val2017.json(这里不需要对应的test的标签)
- 在回顾说明一下需要转换的,和保持相对不变的
- 保持相对不变的:
- linhuo/images/train的图片直接复制到train2017
- linhuo/images/val的图片直接复制到val2017
- linhuo/images/test的图片直接复制到test2017
- 需要改变的是:
- linhuo/labels/train的所有标签需要转换成 instances_train2017.json(coco格式)
- linhuo/labels/vla的所有标签需要转换成instances_val2017.json(coco格式)
yolo转coco数据集格式的代码
"""
yolo标签:
yolo数据集的标注文件是.txt文件,在label文件夹中每一个.txt文件对应数据集中的一张图片
其中每个.txt文件中的每一行代表图片中的一个目标。
coco标签:
而coco数据集的标注文件是.json文件,全部的数据标注文件由三个.json文件组成:train.json val.json test.json,
其中每个.json文件中包含全部的数据集图片中的所有目标(注意是所有目标不是数据集中的所有张图片)
准备工作:
1. 在根目录下创建coco文件格式对应的文件夹
dataset_coco:annotationsimageslabelsclasses.txt(每一行是自定义数据集中的一个类别)YOLO 格式的数据集转化为 COCO 格式的数据集
--root_dir 输入根路径
--save_path 保存文件的名字(没有random_split时使用)
--random_split 有则会随机划分数据集,然后再分别保存为3个文件。
--split_by_file 按照 ./train.txt ./val.txt ./test.txt 来对数据集进行划分运行方式:python yolo2coco.py --root_dir ./dataset_coco --random_split
datasetcoco/images: 数据集所有图片
datasetcoco/labels: 数据集yolo标签的txt文件
classes.txt(每一行是自定义数据集中的一个类别)
"""import os
import cv2
import json
from tqdm import tqdm
from sklearn.model_selection import train_test_split
import argparseparser = argparse.ArgumentParser()
parser.add_argument('--root_dir', default='./data', type=str,help="root path of images and labels, include ./images and ./labels and classes.txt")
parser.add_argument('--save_path', type=str, default='./train.json',help="if not split the dataset, give a path to a json file")
parser.add_argument('--random_split', action='store_true', help="random split the dataset, default ratio is 8:1:1")
parser.add_argument('--split_by_file', action='store_true',help="define how to split the dataset, include ./train.txt ./val.txt ./test.txt ")arg = parser.parse_args()def train_test_val_split_random(img_paths, ratio_train=0.8, ratio_test=0.1, ratio_val=0.1):# 这里可以修改数据集划分的比例。assert int(ratio_train + ratio_test + ratio_val) == 1train_img, middle_img = train_test_split(img_paths, test_size=1 - ratio_train, random_state=233)ratio = ratio_val / (1 - ratio_train)val_img, test_img = train_test_split(middle_img, test_size=ratio, random_state=233)print("NUMS of train:val:test = {}:{}:{}".format(len(train_img), len(val_img), len(test_img)))return train_img, val_img, test_imgdef train_test_val_split_by_files(img_paths, root_dir):# 根据文件 train.txt, val.txt, test.txt(里面写的都是对应集合的图片名字) 来定义训练集、验证集和测试集phases = ['train', 'val', 'test']img_split = []for p in phases:define_path = os.path.join(root_dir, f'{p}.txt')print(f'Read {p} dataset definition from {define_path}')assert os.path.exists(define_path)with open(define_path, 'r') as f:img_paths = f.readlines()# img_paths = [os.path.split(img_path.strip())[1] for img_path in img_paths] # NOTE 取消这句备注可以读取绝对地址。img_split.append(img_paths)return img_split[0], img_split[1], img_split[2]def yolo2coco(arg):root_path = arg.root_dirprint("Loading data from ", root_path)assert os.path.exists(root_path)originLabelsDir = os.path.join(root_path, 'labels')originImagesDir = os.path.join(root_path, 'images')with open(os.path.join(root_path, 'classes.txt')) as f:classes = f.read().strip().split()# images dir nameindexes = os.listdir(originImagesDir)if arg.random_split or arg.split_by_file:# 用于保存所有数据的图片信息和标注信息train_dataset = {'categories': [], 'annotations': [], 'images': []}val_dataset = {'categories': [], 'annotations': [], 'images': []}test_dataset = {'categories': [], 'annotations': [], 'images': []}# 建立类别标签和数字id的对应关系, 类别id从0开始。for i, cls in enumerate(classes, 0):train_dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'mark'})val_dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'mark'})test_dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'mark'})if arg.random_split:print("spliting mode: random split")train_img, val_img, test_img = train_test_val_split_random(indexes, 0.8, 0.1, 0.1)elif arg.split_by_file:print("spliting mode: split by files")train_img, val_img, test_img = train_test_val_split_by_files(indexes, root_path)else:dataset = {'categories': [], 'annotations': [], 'images': []}for i, cls in enumerate(classes, 0):dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'mark'})# 标注的idann_id_cnt = 0for k, index in enumerate(tqdm(indexes)):# 支持 png jpg 格式的图片。txtFile = index.replace('images', 'txt').replace('.jpg', '.txt').replace('.png', '.txt')# 读取图像的宽和高im = cv2.imread(os.path.join(root_path, 'images/') + index)height, width, _ = im.shapeif arg.random_split or arg.split_by_file:# 切换dataset的引用对象,从而划分数据集if index in train_img:dataset = train_datasetelif index in val_img:dataset = val_datasetelif index in test_img:dataset = test_dataset# 添加图像的信息dataset['images'].append({'file_name': index,'id': k,'width': width,'height': height})if not os.path.exists(os.path.join(originLabelsDir, txtFile)):# 如没标签,跳过,只保留图片信息。continuewith open(os.path.join(originLabelsDir, txtFile), 'r') as fr:labelList = fr.readlines()for label in labelList:label = label.strip().split()x = float(label[1])y = float(label[2])w = float(label[3])h = float(label[4])# convert x,y,w,h to x1,y1,x2,y2H, W, _ = im.shapex1 = (x - w / 2) * Wy1 = (y - h / 2) * Hx2 = (x + w / 2) * Wy2 = (y + h / 2) * H# 标签序号从0开始计算, coco2017数据集标号混乱,不管它了。cls_id = int(label[0])width = max(0, x2 - x1)height = max(0, y2 - y1)dataset['annotations'].append({'area': width * height,'bbox': [x1, y1, width, height],'category_id': cls_id,'id': ann_id_cnt,'image_id': k,'iscrowd': 0,# mask, 矩形是从左上角点按顺时针的四个顶点'segmentation': [[x1, y1, x2, y1, x2, y2, x1, y2]]})ann_id_cnt += 1# 保存结果folder = os.path.join(root_path, 'annotations')if not os.path.exists(folder):os.makedirs(folder)if arg.random_split or arg.split_by_file:for phase in ['train', 'val', 'test']:json_name = os.path.join(root_path, 'annotations/{}.json'.format(phase))with open(json_name, 'w') as f:if phase == 'train':json.dump(train_dataset, f)elif phase == 'val':json.dump(val_dataset, f)elif phase == 'test':json.dump(test_dataset, f)print('Save annotation to {}'.format(json_name))else:json_name = os.path.join(root_path, 'annotations/{}'.format(arg.save_path))with open(json_name, 'w') as f:json.dump(dataset, f)print('Save annotation to {}'.format(json_name))if __name__ == "__main__":yolo2coco(arg)三: 训练
以configs/faster_rcnn/faster-rcnn_r101_fpn_1x_coco.py为例
- mmdetection-mian创建文件夹data,在将上面转换后的格式进行简单整理如下,放到mmdetection-mian文件下
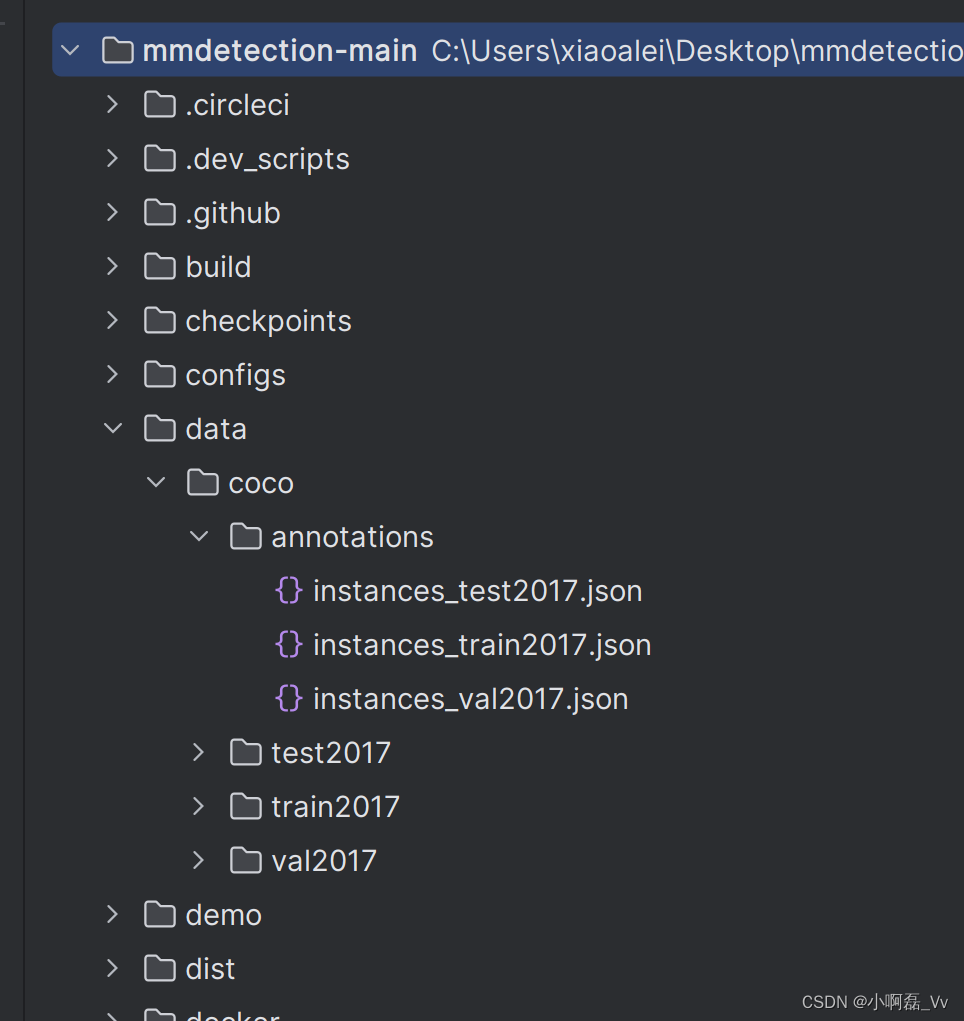
dataset数据文件配置
在路径下面路径中,修改数据集种类为自己数据集的种类。
mmdet/datasets/coco.py
configs
1.在configs/faster_rcnn/faster-rcnn_r101_fpn_1x_coco.py我们发现,索引的是’./faster-rcnn_r50_fpn_1x_coco.py’
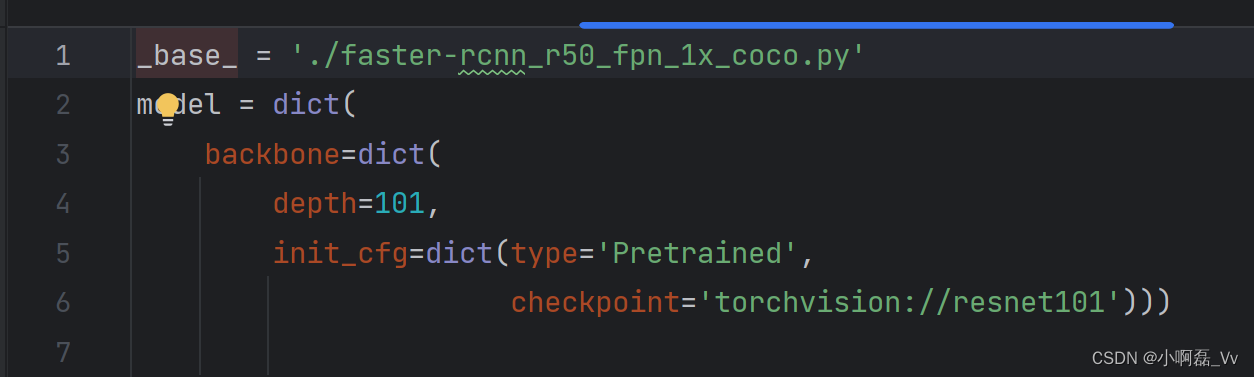
2.找到’./faster-rcnn_r50_fpn_1x_coco.py’,发现索引是下面代码
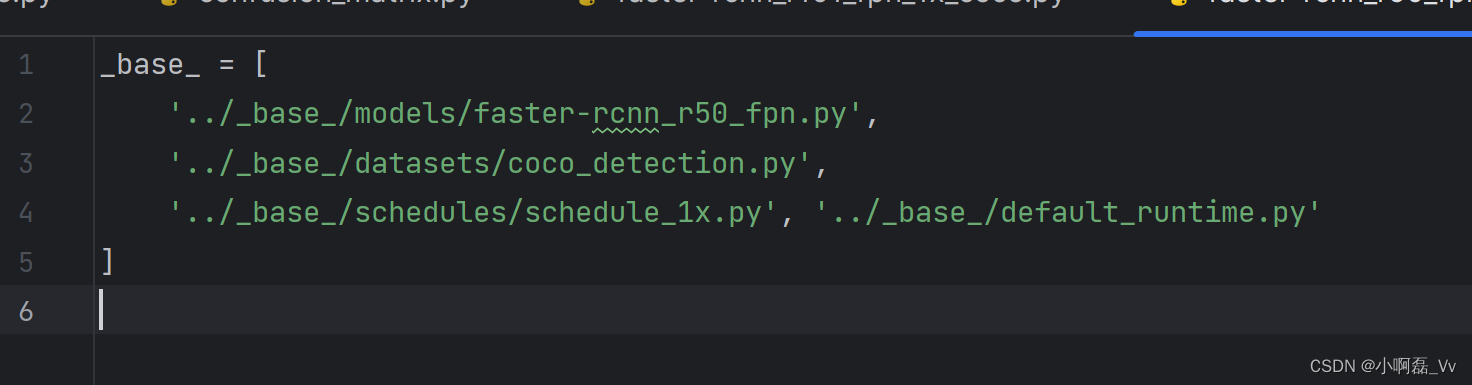
3.修改
_base_ = ['../_base_/models/faster-rcnn_r50_fpn.py',#指向的是model dict,修改其中的num_classes类别为自己的类别。'../_base_/datasets/coco_detection.py',# 修改train_dataloader的ann_file为自己数据集json路径,我这里ann_file='annotations/instances_val2017.json',val_dataloader,val_evaluator也要修改ann_file'../_base_/schedules/schedule_1x.py', # 优化器,超参数,自己实际情况来'../_base_/default_runtime.py'# 可以不修改
]
4.训练
- 若改动框架源代码后,一定要注意重新编译后再使用。类似这里修改了几个源代码文件后再使用train命令之前,先要编译,执行下面命令。
pip install -v -e . # or "python setup.py develop"
- 训练语句
python tools/train.py configs/faster_rcnn/faster-rcnn_r101_fpn_1x_coco.py --work-dir work_dirs_2
五: 还在继续研究的内容
相关文章:
mmdetection训练自己的数据集
mmdetection训练自己的数据集 这里写目录标题 mmdetection训练自己的数据集一: 环境搭建二:数据集格式转换(yolo转coco格式)yolo数据集格式coco数据集格式yolo转coco数据集格式yolo转coco数据集格式的代码 三: 训练dataset数据文件配置config…...

MySQL取出N列里最大or最小的一个数据
如题,现在有3列,都是数字类型,要取出这3列里最大或最小的的一个数字 -- N列取最小 SELECT LEAST(temperature_a,temperature_b,temperature_c) min FROM infrared_heat-- N列取最大 SELECT GREATEST(temperature_a,temperature_b,temperat…...
编写.NET的Dockerfile文件构建镜像
创建一个WebApi项目,并且创建一个Dockerfile空文件,添加以下代码,7.0代表的你项目使用的SDK的版本,构建的时候也需要选择好指定的镜像tag FROM mcr.microsoft.com/dotnet/aspnet:7.0 AS base WORKDIR /app EXPOSE 80 EXPOSE 443F…...
 练习7-4 找出不是两个数组共有的元素)
【C语言】浙大版C语言程序设计(第三版) 练习7-4 找出不是两个数组共有的元素
前言 最近在学习浙大版的《C语言程序设计》(第三版)教材,同步在PTA平台上做对应的练习题。这道练习题花了比较长的时间,于是就写篇博文记录一下我的算法和代码。 2024.01.03 题目 练习7-4 找出不是两个数组共有的元素 作者 张彤…...

7.27 SpringBoot项目实战 之 整合Swagger
文章目录 前言一、Maven依赖二、编写Swagger配置类三、编写接口配置3.1 控制器Controller 配置描述3.2 接口API 配置描述3.3 参数配置描述3.4 忽略API四、全局参数配置五、启用增强功能六、调试前言 在我们实现了那么多API以后,进入前后端联调阶段,需要给前端同学提供接口文…...
创建第一个SpringMVC项目,入手必看!
文章目录 创建第一个SpringMVC项目,入手必看!1、新建一个maven空项目,在pom.xml中设置打包为war之前,右击项目添加web框架2、如果点击右键没有添加框架或者右击进去后没有web框架,点击左上角file然后进入项目结构在模块…...

go 切片长度与容量的区别
切片的声明 切片可以看成是数组的引用(实际上切片的底层数据结构确实是数组)。在 Go 中,每个数组的大小是固定的,不能随意改变大小,切片可以为数组提供动态增长和缩小的需求,但其本身并不存储任何数据。 …...

回归和分类区别
回归任务(Regression): 特点: 输出是连续值,通常是实数。任务目标是预测或估计一个数值。典型应用包括房价预测、销售额预测、温度预测等。 目标: 最小化预测值与真实值之间的差异,通常使用…...

docker nginx滚动日志配置
将所有日志打印到控制台 nginx.conf user nginx; worker_processes auto; # 日志打印控制台 error_log /dev/stdout; #error_log /var/log/nginx/error.log notice; pid /var/run/nginx.pid;events {worker_connections 1024; }http {include /etc/nginx/m…...
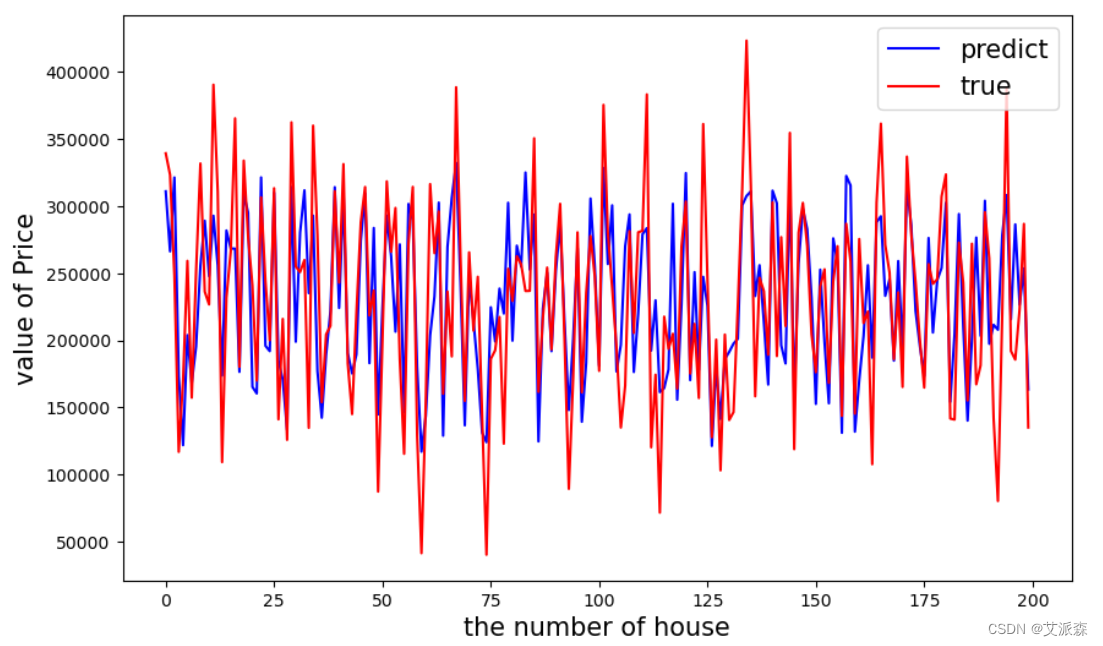
大数据分析案例-基于LinearRegression回归算法构建房屋价格预测模型
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...
:基本使用)
React-hook-form-mui(一):基本使用
前言 在项目开发中,我们选择了ReactMUI作为技术栈。在使用MUI构建form表单时,我们发现并没有与antd类似的表单验证功能,于是我们选择了MUI推荐使用的react-hook-form-mui库去进行验证。但是发现网上关于这个库的使用方法和demo比较少且比较简…...

python总结-生成器与迭代器
生成器与迭代器 生成器生成器定义为什么要有生成器创建生成器的方式一(生成器表达式) 创建生成器的方式二(生成器函数)生成器函数的工作原理总结 迭代器概念可迭代对象和迭代器区别for循环的本质创建一个迭代器 动态添加属性和方法运行过程中给对象、类添加属性和方法types.Met…...

MySQL如何从数据中截取所需要的字符串
MySQL如何从数据中截取所需要的字符串 背景 有这样的一个场景,我想从我的表里面进行数据截取,我的数据内容大致如下: 张三-建外SOHO-2-16 POA 20210518.pdf 我想获取数据中的:20210518这一日期部分,需要如何实现? 解…...

动态加载和动态链接的区别
动态加载(Dynamic Loading)和动态链接(Dynamic Linking)是两个与程序运行时加载和使用代码相关的概念,它们有一些区别: 动态加载(Dynamic Loading): 定义: 动…...

js数组循环,当前循环完成后执行下次循环
前言 上图中,点击播放icon,图中左边地球视角会按照视角列表依次执行。u3D提供了api,但是我们如何保证在循环中依次执行。即第一次执行完成后,再走第二次循环。很多人的第一思路就是promise。对,不错,出发的思路是正确的…...
)
决策树(Decision Trees)
决策树(Decision Trees)是一种基于树形结构进行决策的模型,广泛应用于分类和回归任务。它通过对数据集进行递归划分,构建一棵树,每个节点代表一个特征,每个分支代表一个决策规则,叶节点存储一个…...

湖南大学-计算机网路-2023期末考试【部分原题回忆】
前言 计算机网络第一门考,而且没考好,回忆起来的原题不多。 这门学科学的最认真,复习的最久,考的最差。 教材使用这本书: 简答题(6*530分) MTU和MSS分别是什么,联系是什么&#x…...

LCD—液晶显示
本节主要介绍以下内容 显示器简介 液晶控制原理 秉火3.2寸液晶屏简介 使用FSMC模拟8080时序 NOR FLASH时序结构体 FSMC初始化结构体 一、显示器简介 显示器属于计算机的I/O设备,即输入输出设备。它是一种将特定电子信息输出到屏幕上再反射到人眼的显示工具。…...

论正确初始化深度学习模型参数的重要性
遇到的问题:在一般的深度学习训练过程中,我们建立好模型以后,程序就有自动的初始化一些模型的参数,比如全连接层中每一个节点的权重等等,在之前的网络训练过程中,我总是事先设下随机种子以后,让…...
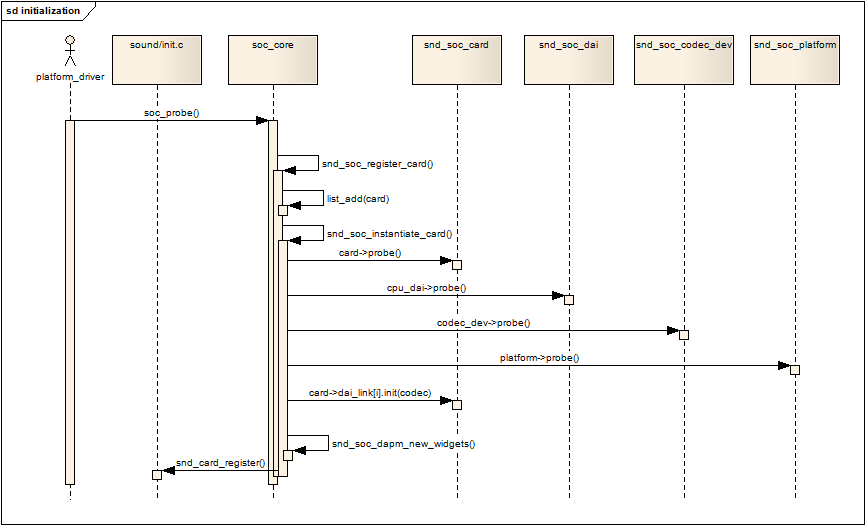
ALSA学习(5)——ASoC架构中的Machine
参考博客:https://blog.csdn.net/DroidPhone/article/details/7231605 (以下内容皆为原博客转载) 文章目录 一、注册Platform Device二、注册Platform Driver三、初始化入口soc_probe() 一、注册Platform Device ASoC把声卡注册为Platform …...

JDK17安装避坑指南:Windows环境变量配置常见错误及解决方法
JDK17安装避坑指南:Windows环境变量配置常见错误及解决方法 刚接触Java开发的朋友们,安装JDK17时最头疼的往往不是下载和安装过程本身,而是后续的环境变量配置环节。很多初学者在这一步反复踩坑,明明按照教程一步步操作࿰…...

基于Rust架构的番茄小说下载器技术实现与应用实践
基于Rust架构的番茄小说下载器技术实现与应用实践 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader Tomato-Novel-Downloader是一款采用Rust语言重构的跨平台小说下载解决方案&a…...

导引头 公式4.1到4.16
目标运动假设模型目标坐标表示与跟踪多目标多导弹通道控制脱靶量与命中精度指令制导系统算法...
Transformer推理加速实战:KV Cache与GQA在自回归生成中的优化技巧
Transformer推理加速实战:KV Cache与GQA在自回归生成中的优化技巧 当我们需要处理长文本生成任务时,Transformer模型的推理效率往往成为瓶颈。每次生成新token时重复计算所有历史token的注意力权重,这种计算方式在长序列场景下会带来显著的性…...

CEO必会之创建公司文化
CEO必会之创建公司文化 CEO必会之建立公司文化:把墙上标语,变成员工骨子里的信仰 课程导语 话术升级: 各位好,今天我们来聊一个CEO最容易忽视、但也最决定企业高度的课题:建立公司文化。 很多人觉得文化是虚的——墙上…...

为什么93%的MCP项目在上线3个月后成本翻倍?揭秘本地数据库连接器的3层“幽灵开销”与零代码修复方案
第一章:MCP服务器本地数据库连接器成本失控的真相MCP(Microservice Coordination Platform)服务器在部署本地数据库连接器时,常因连接池配置失当、连接泄漏与无感知重连机制导致资源持续占用,最终引发云资源账单异常飙…...

呼吸纪元:城市觉醒的肺叶
呼吸纪元:当整座城市成为单个肺叶2061年立春,零点零分零秒,上海所有电动汽车同时完成一次深呼吸——不是比喻,是物理意义上的空气吞吐。一万七千个车载空气净化系统同时反向运转,将储存了整整一个冬季的、来自世界各地…...

利用VisualFreeBASIC与BASS音频库打造轻量级MP3播放器
1. 为什么选择VisualFreeBASIC和BASS音频库 很多朋友可能第一次听说VisualFreeBASIC(简称VFB),它其实是一个基于BASIC语言的现代化开发环境。相比其他编程语言,VFB最大的优势就是语法简单直观,特别适合初学者快速上手…...

DLSS Swapper:智能优化NVIDIA显卡游戏性能的DLSS管理工具
DLSS Swapper:智能优化NVIDIA显卡游戏性能的DLSS管理工具 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 价值定位:为何选择DLSS Swapper优化游戏体验 在PC游戏领域,DLSS࿰…...

Scroll Reverser:macOS滚动方向终极解决方案免费快速配置指南
Scroll Reverser:macOS滚动方向终极解决方案免费快速配置指南 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 还在为macOS系统触控板和鼠标滚动方向无法独立设置而烦…...