HDFS概述
HDFS背景定义
背景
先给大家介绍一下什么叫HDFS,我们生活在信息爆炸的时代,随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
HDFS 优缺点
优点
- 高容错性:HDFS通过数据冗余和自动故障恢复机制来保证数据的可靠性和容错性。它将数据划分为多个块,并在集群中的多个节点上进行复制,以防止数据丢失。
- 高扩展性:HDFS可以在廉价的硬件上构建大规模的集群,并支持PB级别的数据存储。它可以根据需求添加更多的节点来扩展存储容量和处理能力。
- 高吞吐量:HDFS的设计目标是优化大规模数据集的批量处理。它通过并行处理和数据本地性原则来实现高吞吐量的数据访问。
- 适合大数据处理:HDFS适用于存储和处理大规模数据集,特别是适用于批量处理、数据分析和机器学习等大数据应用场景。
缺点
- 不适合低延迟数据访问:由于HDFS的设计目标是优化大规模数据集的批量处理,因此它不适合需要低延迟数据访问的应用场景,如在线事务处理。
- 不支持多写多读:HDFS的设计是基于一次写入多次读取的模式,不支持多个客户端同时对同一个文件进行写操作。
- 不适合小文件存储:HDFS适合存储大文件,对于大量小文件的存储会导致存储空间的浪费和元数据管理的开销。
HDFS 组成
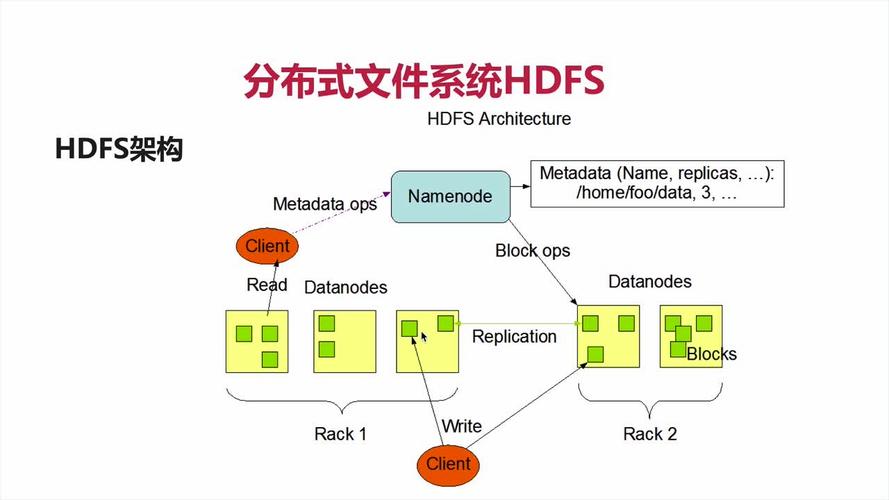
1、 NameNode(nn):就是Master,它是一个主管、管理者。
管理HDFS的名称空间;
配置副本策略;
管理数据块(Block)映射信息;
处理客户端读写请求。
2、 DataNode: 就是slave。NameNode下达命令,DataNode执行实际的操作。
储存实际的数据块;
执行数据块的读写操作。
3、 Client: 就是客户端
文件切分:文件上传HDFS的时候,Client将文件切分为一个一个的Block,然后进行上传;
与NameNode进行交互,获取文件的位置信息;
与DataNode进行交互,读取或者写入数据;
Client提供一些命令来管理HDFS,比如NameNode的格式化;
Client可以通过一些命令来访问HDFS,比如对HDFS增删改查操作。
4、 Secondary NameNode: 并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode;
在紧急情况下,可辅助恢复NameNode。
注:NameNode的HA模式下没有2NN,其功能由Standby的NameNode实现。
HDFS文件块大小
Hadoop集群中的文件存储都是以块(block)的形式存储在HDFS中的。其中从Hadoop2.7.3版本开始,文件块(block size)的默认值是128MB,之前版本默认值是64MB
在HDFS中存储是以块(block)的形式存储在DataNode中的。那么在真实存储中实际文件大小和block块大小是怎么一个关系呢?
下面举例来讲述(默认HDFS块大小为128MB,文件副本为3份)。
问题1:若从客户端上传一个大小为128MB的文件,会产生多少个block块,占用多少实际物理存储
- 根据块大小,此时应该有1个block块,但由于副本的存在,总共有3个block块;
- 实际占用物理存储为128MB,同样由于副本的存在,总共占用物理存储为128MB*3;
- 块信息位置等元数据信息是存储在NameNode中的,会存1条记录。
问题2:若从客户端上传一个大小为130MB的文件,会产生多少个block块,占用多少实际物理存储
-
根据块大小,此时应该有2个block块,其中1个块大小是128MB,1个块大小是2MB,后者占用的真实存储空间也是2MB,并不是128MB,同样由于副本的存在,总共有6个block块,其中3个块大小是128MB,3个块大小是2MB;
-
实际占用物理存储为130MB,其中1个文件大小是128MB,1个文件大小是2MB,同样由于副本的存在,总共占用物理存储为128MB * 3 + 2MB * 3;
-
块信息位置等元数据信息是存储在NameNode中的,会存2条记录。
问题3:若从客户端再上传一个大小为 24MB 的文件,那么这个block块会与问题 2 中的那个 2MB 的block块进行合并吗?
- 不会,block块不会合并,block块只是一个逻辑概念,实际占用的物理存储空间是以文件大小为准的,所以这个24MB 的文件上传后是一个独立的文件块,占用物理存储空间大小为24MB。
如何修改默认块(block)大小
从Hadoop2.7.3版本开始,文件块(block size)的默认值是128MB,之前版本默认值是64MB
block大小可以通过修改hdfs-site.xml文件中的dfs.blocksize对应的值来实现,若设置block大小为256MB如下:
<property><name>dfs.block.size</name><value>268435456</value>
</property>原则:最小化寻址开销,减少网络传输
寻址时间:HDFS中找到目标文件块(block)所需要的时间。
原理:
文件块越大,寻址时间越短,但磁盘传输时间越长;
文件块越小,寻址时间越长,但磁盘传输时间越短
减少磁盘寻道时间(disk seek time):HDFS的设计是为了支持大数据操作,合适的block大小有助于减少硬盘寻道时间(平衡了硬盘寻道时间、IO时间),提高系统吞吐量。
减少NameNode内存消耗:NameNode需要在内存FSImage文件中记录DataNode中数据块信息,若block size太小,那么需要维护的数据块信息会更多。而HDFS只有一个NameNode节点,内存是极其有限的。
影响map端失败时重启时间:若map端任务出现崩溃,那么在重新启动拉起任务时会重新加载数据,而数据块的大小直接影响了加載数据的时间,例如数据块(block)越大,数据加载时间就会越长,进而该map任务的恢复时间越长。
考虑网络传输问题:在数据读写过程中,需要进行网络传输。如果block块过大,会导致网络传输的时间边长,也会因网络不稳定等因素造成程序卡顿、超时、无响应等。如果block块过小,会频繁的进行文件传输,初始化的map端对象会变多,资源占用变高、jvm增高、网络占用变多。
考虑监管时间问题:主节点监管其他节点的情况,每个节点会周期性的把完成的工作和状态的更新报告回来。若某个节点保存沉默超过预设的时间间隔,主节点“宣告”该节点状态为死亡,并把分配给这个节点的数据发到别的节点。预设的时间间隔是根据数据块 size角度估算的,若size设置不合理,容易误判节点死亡。
HDFS中块(block)为什么不能设置太大,也不能设置太小
主要取决于磁盘/网络的传输速率。[其实就是CPU、磁盘、网卡之间的协同效率,即跨物理机/机架之间文件传输速率]
如果块设置过大,
从磁盘传输数据的时间会明显大于寻址时间,导致程序在处理这块数据时,变得非常慢;
mapreduce中的map任务通常一次只处理一个块中的数据,如果块过大运行速度也会很慢;
在数据读写计算的时候,需要进行网络传输。如果block过大会导致网络传输时间增长,程序卡顿/超时/无响应。任务执行的过程中拉取其他节点的block或者失败重试的成本会过高;
namenode监管容易判断数据节点死亡。导致集群频繁产生/移除副本,占用cpu、网络、内存资源。
如果块设置过小,
存放大量小文件会占用NameNode中大量内存来存储元数据,而NameNode的物理内存是有限的;
文件块过小,寻址时间增大,导致程序一直在找block的开始位置;
操作系统对目录中的小文件处理存在性能问题,比如同一个目录下文件数量操作100万,执行"fs -l "之类的命令会卡死;
会频繁的进行文件传输,严重占用网络/CPU资源。
为什么block块大小设置为128MB
实际中,磁盘传输速率为200MB/s时,一般设定block大小为256MB
首先HDFS中平均寻址时间大概为10ms;
经过前任的大量测试发现,寻址时间为传输时间的1%时,为最佳状态,所以最佳传输时间为:
10ms/0.01=1000s=1s
目前磁盘的传输速度普遍为100MB/s,最佳block大小计算:
100MB/s*1s=100MB
所以我们设置block大小为128MB
而在实际中,
磁盘传输速率为200MB/s时,一般设定block大小为256MB;
磁盘传输速率为400MB/s时,一般设定block大小为512MB。
前磁盘的传输速度普遍为100MB/s,最佳block大小计算:
100MB/s*1s=100MB
所以我们设置block大小为128MB
而在实际中,
磁盘传输速率为200MB/s时,一般设定block大小为256MB;
磁盘传输速率为400MB/s时,一般设定block大小为512MB。
相关文章:
HDFS概述
文章目录 HDFS背景定义HDFS 优缺点HDFS 组成HDFS文件块大小 HDFS背景定义 背景 先给大家介绍一下什么叫HDFS,我们生活在信息爆炸的时代,随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁…...
Hive 的 安装与部署
目录 1 安装 MySql2 安装 Hive3 Hive 元数据配置到 MySql4 启动 Hive Hive 官网 1 安装 MySql 为什么需要安装 MySql? 原因在于Hive 默认使用的元数据库为 derby,开启 Hive 之后就会占用元数据库,且不与其他客户端共享数据,如果想多窗口操作…...
【HBase】——优化
1 RowKey设计 重要:一条数据的唯一标识就是 rowkey,那么这条数据存储于哪个分区,取决于 rowkey 处于 哪个一个预分区的区间内,设计 rowkey的主要目的 ,就是让数据均匀的分布于所有的 region 中,在一定程度…...

什么是跨域以及怎么处理跨域问题
文章目录 什么是跨域?跨域问题常见场景怎么处理跨域1、配置代理2、CORS(跨域资源共享)3、JSONP(仅限 GET 请求)4、使用 WebSocket 注意事项: 什么是跨域? 跨域(Cross-Origin&#x…...

【Linux Shell】11. 输入/输出 重定向
文章目录 【 1. 重定向简介 】【 2. 输出重定向 】【 3. 输入重定向 】【 4. Here Document 】【 5. /dev/null 文件 】 【 1. 重定向简介 】 大多数 UNIX 系统命令从终端接受输入并将所产生的输出发送回到原来输入的终端。一个命令通常从标准输入的地方读取输入ÿ…...

数据库-简单表的操作And查看表的结构
查看表的结构 desc 表名;mysql> use study; Database changed mysql> create table Class(class_id int ,class_name varchar(128),class_teachar varchar(64)) ; Query OK, 0 rows affected (0.06 sec) mysql> show tables; ----------------- | Tables_in_study…...

<设计模式修炼>模板方法模式的使用场景和注意事项学习
介绍 模板方法模式(Template Method Pattern),又叫模板模式(Template Pattern),在一个抽象类公开定义了执行它的方法的模板。它的子类可以按需要重写方法实现,但调用将以抽象类中定义的方式进行。 2) 简单说ÿ…...
android 分享文件
1.在AndroidManifest.xml 中配置 FileProvider <providerandroid:name"android.support.v4.content.FileProvider"android:authorities"com.example.caliv.ffyy.fileProvider"android:exported"false"android:grantUriPermissions"true…...
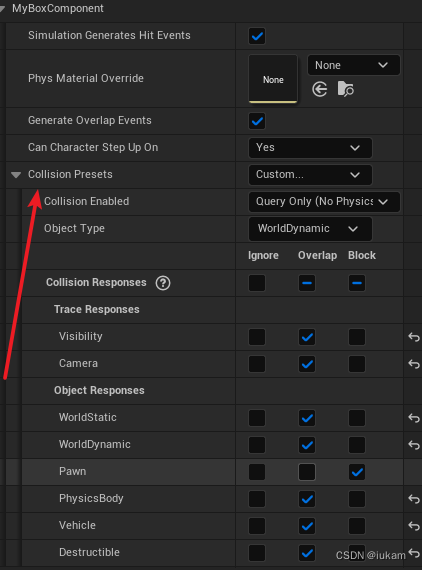
UE5 C++(十一)— 碰撞检测
文章目录 代理绑定BeginOverlap和EndOverlapHit事件的代理绑定碰撞设置 代理绑定BeginOverlap和EndOverlap 首先,创建自定义ActorC类 MyCustomActor 添加碰撞组件 #include "Components/BoxComponent.h"public:UPROPERTY(VisibleAnywhere, BlueprintRea…...

时序数据库InfluxDB、TimeScaleDB简介
一、时序数据库作用、优点 1、作用: 时序数据库通常被用在监控场景,比如运维和 IOT(物联网)领域。这类数据库旨在存储时序数据并实时处理它们。 比如。我们可以写一个程序将服务器上 CPU 的使用情况每隔 10 秒钟向 InfluxDB 中…...

复试 || 就业day05(2024.01.08)项目一
文章目录 前言代码模拟梯度下降构建函数与导函数函数的可视化求这个方程的最小值(直接求导)求方程最小值(不令方程导为0)【梯度下降】eta0.1eta 0.2eta 50eta 0.01画出eta0.1时的梯度下降x的变化过程 总结 前言 💫你…...

基于商品列表的拖拽排序后端实现
目录 一:实现思路 二:实现步骤 二:实现代码 三:注意点 一:实现思路 后台实现拖拽排序通常需要与前端进行配合,对商品的列表拖拽排序,前端需要告诉后端拖拽的元素和拖动的位置。 这里我们假…...
小游戏实战丨基于PyGame的贪吃蛇小游戏
文章目录 写在前面PyGame贪吃蛇注意事项系列文章写在后面 写在前面 本期内容:基于pygame的贪吃蛇小游戏 下载地址:https://download.csdn.net/download/m0_68111267/88700188 实验环境 python3.11及以上pycharmpygame 安装pygame的命令:…...
AOP(面向切面编程)基于XML方式配置
概念解释:(理解基本概念方可快速入手) 连接点(joinpoint) 被拦截到的点,因为Spring只支持方法类型的连接点,所以在Spring中连接点指的就是被拦截到的方法。 切入点(pointcut&#x…...
多线程的概念
多线程 同时执行多个任务,例如一个人一边听歌,一边跳舞 继承Thread类实现多线程的方式 定义一个MyThread类继承Thread类,重写里面的run方法 package com.itxs.demo01;/*** Classname : MyThread* Description : TODO 自定义线程继承Thread类*…...
DeepPurpose 生物化学深度学习库;蛋白靶点小分子药物对接亲和力预测虚拟筛选
参考: https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/107649770 https://github.com/kexinhuang12345/DeepPurpose ##安装 pip install DeepPurpose rdkitDeepPurpose包括: 数据: 关联TDC库下载,是同一作者开发的 https://blog.csdn.net/weixin_42357472/artic…...

Java实现责任链模式
责任链模式是一种设计模式,用于处理请求的解耦。在责任链模式中,多个对象都有机会处理请求,从而避免了请求发送者和接收者之间的直接依赖关系。每个处理者都可以决定是否处理请求以及将请求传递给下一个处理者。 简介 责任链模式由一条链组…...
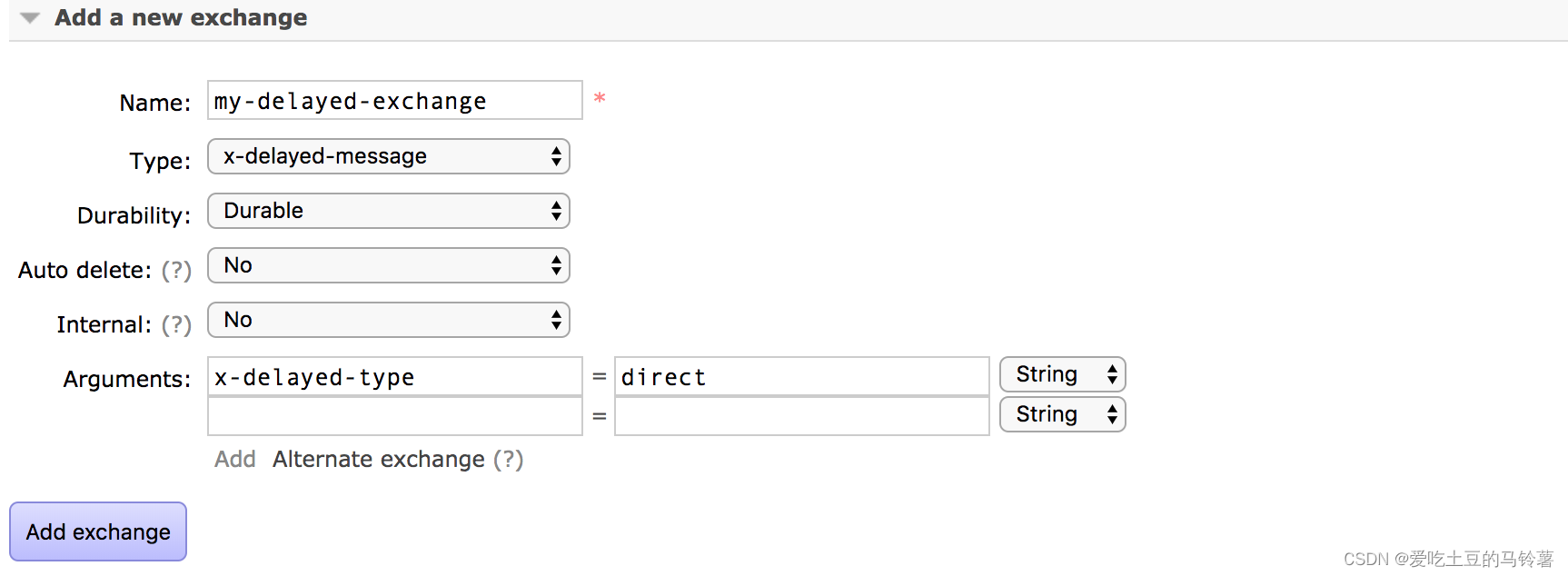
rabbitmq延时队列相关配置
确保 RabbitMQ 的延时消息插件已经安装和启用。你可以通过执行以下命令来安装该插件: rabbitmq-plugins enable rabbitmq_delayed_message_exchange 如果提示未安装,以下是安装流程: 查看mq版本: 查看自己使用的 MQ(…...

【工具】推荐一个好用的代码画图工具
PlantUML 官网地址:https://plantuml.com/zh/ 跳转 支持各种结构化数据画图支持代码调用jar包生成图片 提供在线画图能力 https://www.plantuml.com/plantuml/uml/SyfFKj2rKt3CoKnELR1Io4ZDoSa70000 有兴趣可以尝试下 over~~...
)
Leetcode14-判断句子是否为全字母句(1832)
1、题目 全字母句 指包含英语字母表中每个字母至少一次的句子。 给你一个仅由小写英文字母组成的字符串 sentence ,请你判断 sentence 是否为 全字母句 。 如果是,返回 true ;否则,返回 false 。 示例 1: 输入&am…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

掌握 HTTP 请求:理解 cURL GET 语法
cURL 是一个强大的命令行工具,用于发送 HTTP 请求和与 Web 服务器交互。在 Web 开发和测试中,cURL 经常用于发送 GET 请求来获取服务器资源。本文将详细介绍 cURL GET 请求的语法和使用方法。 一、cURL 基本概念 cURL 是 "Client URL" 的缩写…...
QT开发技术【ffmpeg + QAudioOutput】音乐播放器
一、 介绍 使用ffmpeg 4.2.2 在数字化浪潮席卷全球的当下,音视频内容犹如璀璨繁星,点亮了人们的生活与工作。从短视频平台上令人捧腹的搞笑视频,到在线课堂中知识渊博的专家授课,再到影视平台上扣人心弦的高清大片,音…...
AxureRP-Pro-Beta-Setup_114413.exe (6.0.0.2887)
Name:3ddown Serial:FiCGEezgdGoYILo8U/2MFyCWj0jZoJc/sziRRj2/ENvtEq7w1RH97k5MWctqVHA 注册用户名:Axure 序列号:8t3Yk/zu4cX601/seX6wBZgYRVj/lkC2PICCdO4sFKCCLx8mcCnccoylVb40lP...

《Offer来了:Java面试核心知识点精讲》大纲
文章目录 一、《Offer来了:Java面试核心知识点精讲》的典型大纲框架Java基础并发编程JVM原理数据库与缓存分布式架构系统设计二、《Offer来了:Java面试核心知识点精讲(原理篇)》技术文章大纲核心主题:Java基础原理与面试高频考点Java虚拟机(JVM)原理Java并发编程原理Jav…...
goreplay
1.github地址 https://github.com/buger/goreplay 2.简单介绍 GoReplay 是一个开源的网络监控工具,可以记录用户的实时流量并将其用于镜像、负载测试、监控和详细分析。 3.出现背景 随着应用程序的增长,测试它所需的工作量也会呈指数级增长。GoRepl…...
GraphRAG优化新思路-开源的ROGRAG框架
目前的如微软开源的GraphRAG的工作流程都较为复杂,难以孤立地评估各个组件的贡献,传统的检索方法在处理复杂推理任务时可能不够有效,特别是在需要理解实体间关系或多跳知识的情况下。先说结论,看完后感觉这个框架性能上不会比Grap…...