论文复现-2:代码部分
以CONLL03数据集为例
文章目录
- 1 整体框架
- 2 数据结构
- 2.1 原始数据集
- 2.2 处理之后的数据集
- 3 代码部分
- 3.0 模型参数
- 3.1 数据预处理
- 3.2 模型方法
- 3.1.1 定义
- 表示的学习
- 权重项的学习
- 双塔模型
- 3.2.2 forward
- 3.3 损失函数
- 3.4 训练与推理
- Ablation study
- 训练实例
1 整体框架
任务是实体识别任务;
语义表示:双塔模型;
模型方法:1、span表示学习(span的hi , hj 和j-i这个span width)
2、span position表示学习 (start end position) 每个position位置的embedding是由当前token的表示作为的,然后每个类型的embedding是cls token的语义表示。
损失函数:对应于上边的模型方法。
可能涉及的细节:阈值确定、语义表示选择什么方式——CLS还是pooling。
2 数据结构
2.1 原始数据集
原始数据集中是以一整篇文档作为存储单位的。
关键词有doc_key表示文档序号。
ner表示句子中的实体列表,每个实体由start 和 end 和type三部分,是一个句子作为初始计数单位。
sentence表示文档中的所有句子,构成的二维列表。
{"doc_key": "train_01", "ners": [[[0, 0, "ORG"], [2, 2, "MISC"], [6, 6, "MISC"]], [[0, 1, "PER"]], [[0, 0, "LOC"]], [[1, 2, "ORG"], [9, 9, "MISC"], [15, 15, "MISC"]], [[0, 0, "LOC"], [5, 6, "ORG"], [10, 11, "PER"], [23, 23, "LOC"]], [[20, 20, "ORG"], [24, 27, "PER"]], [[22, 23, "ORG"]], [[7, 7, "ORG"], [10, 11, "PER"]], [[0, 0, "PER"], [2, 2, "MISC"], [7, 7, "LOC"], [9, 9, "LOC"], [17, 19, "MISC"], [21, 21, "MISC"]], [[1, 1, "PER"], [9, 9, "ORG"]], [[0, 0, "MISC"], [3, 5, "PER"], [9, 9, "PER"], [12, 12, "ORG"]], [], [[1, 1, "LOC"], [3, 3, "LOC"], [5, 5, "PER"]], [[1, 1, "ORG"]], [[14, 14, "MISC"]], [[0, 0, "MISC"], [20, 20, "MISC"], [27, 27, "MISC"], [33, 33, "LOC"]], [[17, 17, "LOC"], [22, 26, "ORG"], [28, 28, "ORG"], [31, 33, "PER"], [36, 37, "ORG"]], [[0, 0, "LOC"], [16, 16, "MISC"]], [[0, 0, "LOC"], [5, 5, "LOC"]], [[6, 6, "MISC"]]], "sentences": [["EU", "rejects", "German", "call", "to", "boycott", "British", "lamb", "."], ["Peter", "Blackburn"], ["BRUSSELS", "1996-08-22"], ["The", "European", "Commission", "said", "on", "Thursday", "it", "disagreed", "with", "German", "advice", "to", "consumers", "to", "shun", "British", "lamb", "until", "scientists", "determine", "whether", "mad", "cow", "disease", "can", "be", "transmitted", "to", "sheep", "."], ["Germany", "'s", "representative", "to", "the", "European", "Union", "'s", "veterinary", "committee", "Werner", "Zwingmann", "said", "on", "Wednesday", "consumers", "should", "buy", "sheepmeat", "from", "countries", "other", "than", "Britain", "until", "the", "scientific", "advice", "was", "clearer", "."], ["\"", "We", "do", "n't", "support", "any", "such", "recommendation", "because", "we", "do", "n't", "see", "any", "grounds", "for", "it", ",", "\"", "the", "Commission", "'s", "chief", "spokesman", "Nikolaus", "van", "der", "Pas", "told", "a", "news", "briefing", "."], ["He", "said", "further", "scientific", "study", "was", "required", "and", "if", "it", "was", "found", "that", "action", "was", "needed", "it", "should", "be", "taken", "by", "the", "European", "Union", "."], ["He", "said", "a", "proposal", "last", "month", "by", "EU", "Farm", "Commissioner", "Franz", "Fischler", "to", "ban", "sheep", "brains", ",", "spleens", "and", "spinal", "cords", "from", "the", "human", "and", "animal", "food", "chains", "was", "a", "highly", "specific", "and", "precautionary", "move", "to", "protect", "human", "health", "."], ["Fischler", "proposed", "EU-wide", "measures", "after", "reports", "from", "Britain", "and", "France", "that", "under", "laboratory", "conditions", "sheep", "could", "contract", "Bovine", "Spongiform", "Encephalopathy", "(", "BSE", ")", "--", "mad", "cow", "disease", "."], ["But", "Fischler", "agreed", "to", "review", "his", "proposal", "after", "the", "EU", "'s", "standing", "veterinary", "committee", ",", "mational", "animal", "health", "officials", ",", "questioned", "if", "such", "action", "was", "justified", "as", "there", "was", "only", "a", "slight", "risk", "to", "human", "health", "."], ["Spanish", "Farm", "Minister", "Loyola", "de", "Palacio", "had", "earlier", "accused", "Fischler", "at", "an", "EU", "farm", "ministers", "'", "meeting", "of", "causing", "unjustified", "alarm", "through", "\"", "dangerous", "generalisation", ".", "\""], ["."], ["Only", "France", "and", "Britain", "backed", "Fischler", "'s", "proposal", "."], ["The", "EU", "'s", "scientific", "veterinary", "and", "multidisciplinary", "committees", "are", "due", "to", "re-examine", "the", "issue", "early", "next", "month", "and", "make", "recommendations", "to", "the", "senior", "veterinary", "officials", "."], ["Sheep", "have", "long", "been", "known", "to", "contract", "scrapie", ",", "a", "brain-wasting", "disease", "similar", "to", "BSE", "which", "is", "believed", "to", "have", "been", "transferred", "to", "cattle", "through", "feed", "containing", "animal", "waste", "."], ["British", "farmers", "denied", "on", "Thursday", "there", "was", "any", "danger", "to", "human", "health", "from", "their", "sheep", ",", "but", "expressed", "concern", "that", "German", "government", "advice", "to", "consumers", "to", "avoid", "British", "lamb", "might", "influence", "consumers", "across", "Europe", "."], ["\"", "What", "we", "have", "to", "be", "extremely", "careful", "of", "is", "how", "other", "countries", "are", "going", "to", "take", "Germany", "'s", "lead", ",", "\"", "Welsh", "National", "Farmers", "'", "Union", "(", "NFU", ")", "chairman", "John", "Lloyd", "Jones", "said", "on", "BBC", "radio", "."], ["Bonn", "has", "led", "efforts", "to", "protect", "public", "health", "after", "consumer", "confidence", "collapsed", "in", "March", "after", "a", "British", "report", "suggested", "humans", "could", "contract", "an", "illness", "similar", "to", "mad", "cow", "disease", "by", "eating", "contaminated", "beef", "."], ["Germany", "imported", "47,600", "sheep", "from", "Britain", "last", "year", ",", "nearly", "half", "of", "total", "imports", "."], ["It", "brought", "in", "4,275", "tonnes", "of", "British", "mutton", ",", "some", "10", "percent", "of", "overall", "imports", "."]]}2.2 处理之后的数据集
将原始数据集转为文中数据集格式。
数据集的key如下《text是一个文档的所有句子构成的text文本》
entity type是文档中所有的实体构成的列表。
entity start chars是实体开始的char的起始位置
end chars 也是以每个字母作为一个计量单位的,指的实体的结束位置的char的位置索引
‘text’: text,
‘entity_types’: entity_types,
‘entity_start_chars’: entity_start_chars,
‘entity_end_chars’: entity_end_chars,
‘id’: example[‘doc_key’],
‘word_start_chars’: start_words,
‘word_end_chars’: end_words
{"text": "EU rejects German call to boycott British lamb . Peter Blackburn BRUSSELS 1996-08-22 The European Commission said on Thursday it disagreed with German advice to consumers to shun British lamb until scientists determine whether mad cow disease can be transmitted to sheep . Germany 's representative to the European Union 's veterinary committee Werner Zwingmann said on Wednesday consumers should buy sheepmeat from countries other than Britain until the scientific advice was clearer . \" We do n't support any such recommendation because we do n't see any grounds for it , \" the Commission 's chief spokesman Nikolaus van der Pas told a news briefing . He said further scientific study was required and if it was found that action was needed it should be taken by the European Union . He said a proposal last month by EU Farm Commissioner Franz Fischler to ban sheep brains , spleens and spinal cords from the human and animal food chains was a highly specific and precautionary move to protect human health . Fischler proposed EU-wide measures after reports from Britain and France that under laboratory conditions sheep could contract Bovine Spongiform Encephalopathy ( BSE ) -- mad cow disease . But Fischler agreed to review his proposal after the EU 's standing veterinary committee , mational animal health officials , questioned if such action was justified as there was only a slight risk to human health . Spanish Farm Minister Loyola de Palacio had earlier accused Fischler at an EU farm ministers ' meeting of causing unjustified alarm through \" dangerous generalisation . \" . Only France and Britain backed Fischler 's proposal . The EU 's scientific veterinary and multidisciplinary committees are due to re-examine the issue early next month and make recommendations to the senior veterinary officials . Sheep have long been known to contract scrapie , a brain-wasting disease similar to BSE which is believed to have been transferred to cattle through feed containing animal waste . British farmers denied on Thursday there was any danger to human health from their sheep , but expressed concern that German government advice to consumers to avoid British lamb might influence consumers across Europe . \" What we have to be extremely careful of is how other countries are going to take Germany 's lead , \" Welsh National Farmers ' Union ( NFU ) chairman John Lloyd Jones said on BBC radio . Bonn has led efforts to protect public health after consumer confidence collapsed in March after a British report suggested humans could contract an illness similar to mad cow disease by eating contaminated beef . Germany imported 47,600 sheep from Britain last year , nearly half of total imports . It brought in 4,275 tonnes of British mutton , some 10 percent of overall imports .", "entity_types": ["ORG", "MISC", "MISC", "PER", "LOC", "ORG", "MISC", "MISC", "LOC", "ORG", "PER", "LOC", "ORG", "PER", "ORG", "ORG", "PER", "PER", "MISC", "LOC", "LOC", "MISC", "MISC", "PER", "ORG", "MISC", "PER", "PER", "ORG", "LOC", "LOC", "PER", "ORG", "MISC", "MISC", "MISC", "MISC", "LOC", "LOC", "ORG", "ORG", "PER", "ORG", "LOC", "MISC", "LOC", "LOC", "MISC"], "entity_start_chars": [0, 11, 34, 49, 65, 89, 144, 179, 273, 306, 345, 437, 580, 610, 769, 819, 840, 1011, 1029, 1065, 1077, 1138, 1173, 1204, 1253, 1416, 1438, 1476, 1491, 1594, 1605, 1620, 1647, 1903, 1999, 2117, 2164, 2210, 2302, 2322, 2355, 2370, 2395, 2407, 2506, 2621, 2656, 2737], "entity_end_chars": [2, 17, 41, 64, 73, 108, 150, 186, 280, 320, 361, 444, 590, 630, 783, 821, 854, 1019, 1036, 1072, 1083, 1170, 1176, 1212, 1255, 1423, 1455, 1484, 1493, 1600, 1612, 1628, 1649, 1906, 2006, 2123, 2171, 2216, 2309, 2352, 2358, 2386, 2404, 2411, 2513, 2628, 2663, 2744], "id": "train_01", "word_start_chars": [0, 3, 11, 18, 23, 26, 34, 42, 47, 49, 55, 65, 74, 85, 89, 98, 109, 114, 117, 126, 129, 139, 144, 151, 158, 161, 171, 174, 179, 187, 192, 198, 209, 219, 227, 231, 235, 243, 247, 250, 262, 265, 271, 273, 281, 284, 299, 302, 306, 315, 321, 324, 335, 345, 352, 362, 367, 370, 380, 390, 397, 401, 411, 416, 426, 432, 437, 445, 451, 455, 466, 473, 477, 485, 487, 489, 492, 495, 499, 507, 511, 516, 531, 539, 542, 545, 549, 553, 557, 565, 569, 572, 574, 576, 580, 591, 594, 600, 610, 619, 623, 627, 631, 636, 638, 643, 652, 654, 657, 662, 670, 681, 687, 691, 700, 704, 707, 710, 714, 720, 725, 732, 736, 743, 746, 753, 756, 762, 765, 769, 778, 784, 786, 789, 794, 796, 805, 810, 816, 819, 822, 827, 840, 846, 855, 858, 862, 868, 875, 877, 885, 889, 896, 902, 907, 911, 917, 921, 928, 933, 940, 944, 946, 953, 962, 966, 980, 985, 988, 996, 1002, 1009, 1011, 1020, 1029, 1037, 1046, 1052, 1060, 1065, 1073, 1077, 1084, 1089, 1095, 1106, 1117, 1123, 1129, 1138, 1145, 1156, 1171, 1173, 1177, 1179, 1182, 1186, 1190, 1198, 1200, 1204, 1213, 1220, 1223, 1230, 1234, 1243, 1249, 1253, 1256, 1259, 1268, 1279, 1289, 1291, 1300, 1307, 1314, 1324, 1326, 1337, 1340, 1345, 1352, 1356, 1366, 1369, 1375, 1379, 1384, 1386, 1393, 1398, 1401, 1407, 1414, 1416, 1424, 1429, 1438, 1445, 1448, 1456, 1460, 1468, 1476, 1485, 1488, 1491, 1494, 1499, 1509, 1511, 1519, 1522, 1530, 1542, 1548, 1556, 1558, 1568, 1583, 1585, 1587, 1589, 1594, 1601, 1605, 1613, 1620, 1629, 1632, 1641, 1643, 1647, 1650, 1653, 1664, 1675, 1679, 1697, 1708, 1712, 1716, 1719, 1730, 1734, 1740, 1746, 1751, 1757, 1761, 1766, 1782, 1785, 1789, 1796, 1807, 1817, 1819, 1825, 1830, 1835, 1840, 1846, 1849, 1858, 1866, 1868, 1870, 1884, 1892, 1900, 1903, 1907, 1913, 1916, 1925, 1928, 1933, 1938, 1950, 1953, 1960, 1968, 1973, 1984, 1991, 1997, 1999, 2007, 2015, 2022, 2025, 2034, 2040, 2044, 2048, 2055, 2058, 2064, 2071, 2076, 2082, 2088, 2090, 2094, 2104, 2112, 2117, 2124, 2135, 2142, 2145, 2155, 2158, 2164, 2172, 2177, 2183, 2193, 2203, 2210, 2217, 2219, 2221, 2226, 2229, 2234, 2237, 2240, 2250, 2258, 2261, 2264, 2268, 2274, 2284, 2288, 2294, 2297, 2302, 2310, 2313, 2318, 2320, 2322, 2328, 2337, 2345, 2347, 2353, 2355, 2359, 2361, 2370, 2375, 2381, 2387, 2392, 2395, 2399, 2405, 2407, 2412, 2416, 2420, 2428, 2431, 2439, 2446, 2453, 2459, 2468, 2479, 2489, 2492, 2498, 2504, 2506, 2514, 2521, 2531, 2538, 2544, 2553, 2556, 2564, 2572, 2575, 2579, 2583, 2591, 2594, 2601, 2614, 2619, 2621, 2629, 2638, 2645, 2651, 2656, 2664, 2669, 2674, 2676, 2683, 2688, 2691, 2697, 2705, 2707, 2710, 2718, 2721, 2727, 2734, 2737, 2745, 2752, 2754, 2759, 2762, 2770, 2773, 2781, 2789], "word_end_chars": [2, 10, 17, 22, 25, 33, 41, 46, 48, 54, 64, 73, 84, 88, 97, 108, 113, 116, 125, 128, 138, 143, 150, 157, 160, 170, 173, 178, 186, 191, 197, 208, 218, 226, 230, 234, 242, 246, 249, 261, 264, 270, 272, 280, 283, 298, 301, 305, 314, 320, 323, 334, 344, 351, 361, 366, 369, 379, 389, 396, 400, 410, 415, 425, 431, 436, 444, 450, 454, 465, 472, 476, 484, 486, 488, 491, 494, 498, 506, 510, 515, 530, 538, 541, 544, 548, 552, 556, 564, 568, 571, 573, 575, 579, 590, 593, 599, 609, 618, 622, 626, 630, 635, 637, 642, 651, 653, 656, 661, 669, 680, 686, 690, 699, 703, 706, 709, 713, 719, 724, 731, 735, 742, 745, 752, 755, 761, 764, 768, 777, 783, 785, 788, 793, 795, 804, 809, 815, 818, 821, 826, 839, 845, 854, 857, 861, 867, 874, 876, 884, 888, 895, 901, 906, 910, 916, 920, 927, 932, 939, 943, 945, 952, 961, 965, 979, 984, 987, 995, 1001, 1008, 1010, 1019, 1028, 1036, 1045, 1051, 1059, 1064, 1072, 1076, 1083, 1088, 1094, 1105, 1116, 1122, 1128, 1137, 1144, 1155, 1170, 1172, 1176, 1178, 1181, 1185, 1189, 1197, 1199, 1203, 1212, 1219, 1222, 1229, 1233, 1242, 1248, 1252, 1255, 1258, 1267, 1278, 1288, 1290, 1299, 1306, 1313, 1323, 1325, 1336, 1339, 1344, 1351, 1355, 1365, 1368, 1374, 1378, 1383, 1385, 1392, 1397, 1400, 1406, 1413, 1415, 1423, 1428, 1437, 1444, 1447, 1455, 1459, 1467, 1475, 1484, 1487, 1490, 1493, 1498, 1508, 1510, 1518, 1521, 1529, 1541, 1547, 1555, 1557, 1567, 1582, 1584, 1586, 1588, 1593, 1600, 1604, 1612, 1619, 1628, 1631, 1640, 1642, 1646, 1649, 1652, 1663, 1674, 1678, 1696, 1707, 1711, 1715, 1718, 1729, 1733, 1739, 1745, 1750, 1756, 1760, 1765, 1781, 1784, 1788, 1795, 1806, 1816, 1818, 1824, 1829, 1834, 1839, 1845, 1848, 1857, 1865, 1867, 1869, 1883, 1891, 1899, 1902, 1906, 1912, 1915, 1924, 1927, 1932, 1937, 1949, 1952, 1959, 1967, 1972, 1983, 1990, 1996, 1998, 2006, 2014, 2021, 2024, 2033, 2039, 2043, 2047, 2054, 2057, 2063, 2070, 2075, 2081, 2087, 2089, 2093, 2103, 2111, 2116, 2123, 2134, 2141, 2144, 2154, 2157, 2163, 2171, 2176, 2182, 2192, 2202, 2209, 2216, 2218, 2220, 2225, 2228, 2233, 2236, 2239, 2249, 2257, 2260, 2263, 2267, 2273, 2283, 2287, 2293, 2296, 2301, 2309, 2312, 2317, 2319, 2321, 2327, 2336, 2344, 2346, 2352, 2354, 2358, 2360, 2369, 2374, 2380, 2386, 2391, 2394, 2398, 2404, 2406, 2411, 2415, 2419, 2427, 2430, 2438, 2445, 2452, 2458, 2467, 2478, 2488, 2491, 2497, 2503, 2505, 2513, 2520, 2530, 2537, 2543, 2552, 2555, 2563, 2571, 2574, 2578, 2582, 2590, 2593, 2600, 2613, 2618, 2620, 2628, 2637, 2644, 2650, 2655, 2663, 2668, 2673, 2675, 2682, 2687, 2690, 2696, 2704, 2706, 2709, 2717, 2720, 2726, 2733, 2736, 2744, 2751, 2753, 2758, 2761, 2769, 2772, 2780, 2788, 2790]}
3 代码部分
3.0 模型参数
调用了transformer中的默认参数对象,继承了相关的参数项。
ModelArguments, DataTrainingArguments, TrainingArguments
所以,整个模型中的参数是偏多的
3.1 数据预处理
1、数据加载使用的是
dataset中自带的函数:load_dataset()
2、Tokenizer工具: 分词
add_prefix_space参数的默认值取决于所使用的tokenizer。对于大多数预训练模型,包括BERT和RoBERTa等模型,其默认值为False,因为它们不需要在输入序列前添加空格。而对于一些预训练模型,例如GPT-2和XLNet等模型,其默认值为True,因为它们需要在输入序列前添加空格。在使用tokenizer对象时,可以通过设置add_prefix_space参数来覆盖默认值,以指定是否在输入序列前添加空格。
3.2 模型方法
在整个方法中,用到的embedding有:
实体类型的embedding是:每个实体描述的CLS token对应的token。 h_CLS

text文本中每个token的embedding是:hidden state的最后一层的输出
span的embedding是:
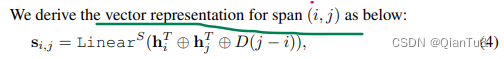
entity type识别中,每个起始位置判断时,使用的向量模型:

综上,我们一共使用了
四个linear函数,做了representation的映射表示学习。
3.1.1 定义
表示的学习
# 实体类型start位置索引识别的linear层
self.type_start_linear = torch.nn.Linear(hf_config.hidden_size, config.linear_size)
# 实体类型end位置索引识别的linear层
self.type_end_linear = torch.nn.Linear(hf_config.hidden_size, config.linear_size)
# 整个span识别实体识别的embedding中linear层
self.type_span_linear = torch.nn.Linear(hf_config.hidden_size, config.linear_size)
# text中token的start位置索引识别的linear层
self.start_linear = torch.nn.Linear(hf_config.hidden_size, config.linear_size)
# text中token的end位置索引识别的linear层
self.end_linear = torch.nn.Linear(hf_config.hidden_size, config.linear_size)
# span识别中text的span的表示学习,span由起始位置。
if config.use_span_width_embedding:self.span_linear = torch.nn.Linear(hf_config.hidden_size * 2 + config.linear_size, config.linear_size)self.width_embeddings = torch.nn.Embedding(config.max_span_width, config.linear_size, padding_idx=0)
else:self.span_linear = torch.nn.Linear(hf_config.hidden_size * 2, config.linear_size)self.width_embeddings = None
权重项的学习

标绿部分的实现
self.start_logit_scale = torch.nn.Parameter(torch.ones([]) * np.log(1 / config.init_temperature))#单项损失函数中权重量,标量张量
self.end_logit_scale = torch.nn.Parameter(torch.ones([]) * np.log(1 / config.init_temperature))
self.span_logit_scale = torch.nn.Parameter(torch.ones([]) * np.log(1 / config.init_temperature))
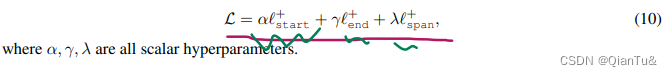
这张图片中标绿部分的权重好像是直接给定的。
self.start_loss_weight = config.start_loss_weightself.end_loss_weight = config.end_loss_weightself.span_loss_weight = config.span_loss_weight
双塔模型
text和实体type 的encoder的学习
self.text_encoder = AutoModel.from_pretrained(config.pretrained_model_name_or_path,config=hf_config,add_pooling_layer=False)
self.type_encoder = AutoModel.from_pretrained(config.pretrained_model_name_or_path,config=hf_config,add_pooling_layer=False)3.2.2 forward
每个位置部分是start或者end的索引概率:
# batch_size x num_types x seq_lengthstart_scores = self.start_logit_scale.exp() * type_start_output.unsqueeze(0) @ sequence_start_output.transpose(1, 2)# text中每个位置的token是对应type的起始位置的概率'''这段代码的意义是通过执行矩阵乘法来计算每个文本序列中每个位置作为答案起点的分数,即start_scores。具体来说,代码首先执行以下步骤:调用PyTorch中的exp()方法将self.start_logit_scale中的所有元素取指数。将上一步中得到的张量与type_start_output.unsqueeze(0)执行矩阵乘法,即将self.start_logit_scale中的每个元素分别乘以type_start_output中的每个元素,并将结果相加,得到一个形状为(1, seq_len)的张量。将上一步得到的张量与sequence_start_output.transpose(1, 2)执行矩阵乘法,即将上一步中得到的张量中的每个元素分别乘以sequence_start_output中的每个元素,并将结果相加,得到一个形状为(1, seq_len)的张量。最终得到的start_scores张量的形状为(1, seq_len),其中第i个元素表示第i个位置作为答案起点的分数。我们可以使用softmax函数对start_scores进行归一化,得到每个位置作为答案起点的概率分布。在模型的训练和推理过程中,我们可以使用start_scores来选择最有可能的答案起点。'''end_scores = self.end_logit_scale.exp() * type_end_output.unsqueeze(0) @ sequence_end_output.transpose(1, 2)
3.3 损失函数
3.4 训练与推理
在代码中的训练和推理部分,使用的是集成的trainer工具包。
在使用Transformer模型进行自然语言处理任务时,可以使用Hugging Face提供的Trainer类来进行模型的训练和评估。Trainer类封装了训练和评估过程中的大量细节,使得用户可以更加方便地进行模型的训练和评估。下面是使用Trainer类进行模型训练和评估的一般步骤:
准备数据集:首先需要将数据集转换为可以被模型接受的格式。对于文本分类等任务,可以使用Hugging
Face提供的Dataset类和DataLoader类将数据集转换为可以被模型接受的格式。定义模型和优化器:使用Hugging Face提供的AutoModel类加载预训练的Transformer模型,同时定义优化器和损失函数。
定义训练参数:使用Hugging Face提供的TrainingArguments类定义训练参数,例如学习率、训练轮数等。
创建Trainer实例:使用Hugging Face提供的Trainer类创建一个Trainer实例。
开始训练:使用Trainer实例的train()方法开始训练模型。
评估模型:训练完成后,可以使用Trainer实例的evaluate()方法评估模型的性能。
以下是一个简单的使用Trainer进行模型训练和评估的示例代码:
from transformers import AutoModel, AutoTokenizer, Trainer, TrainingArguments
import torch# 1. 准备数据集
train_dataset = ...
val_dataset = ...
data_collator = ...# 2. 定义模型和优化器
model_name = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
optimizer = torch.optim.AdamW(model.parameters(), lr=5e-5)
loss_fn = ...# 3. 定义训练参数
training_args = TrainingArguments(output_dir="./results",evaluation_strategy="steps",eval_steps=500,save_steps=500,num_train_epochs=3,learning_rate=5e-5,per_device_train_batch_size=16,per_device_eval_batch_size=64,warmup_steps=500,weight_decay=0.01,
)# 4. 创建Trainer实例
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=val_dataset,data_collator=data_collator,optimizer=optimizer,compute_metrics=compute_metrics,callbacks=[],
)# 5. 开始训练
trainer.train()# 6. 评估模型
trainer.evaluate()Ablation study
训练实例
D:\Anocada\envs\pythonProject\python.exe E:/PythonProject_2023/pythonProject_SIM/binder-main/run_ner.py
03/02/2023 22:39:10 - WARNING - __main__ - Process rank: -1, device: cuda:0, n_gpu: 1, distributed training: False, 16-bits training: True
03/02/2023 22:39:10 - INFO - __main__ - Training/evaluation parameters TrainingArguments(
_n_gpu=1,
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=False,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=1,
dataloader_pin_memory=True,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
ddp_timeout=1800,
debug=[],
deepspeed=None,
disable_tqdm=False,
do_eval=True,
do_predict=True,
do_train=True,
eval_accumulation_steps=None,
eval_delay=0,
eval_steps=100,
evaluation_strategy=steps,
fp16=True,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
fsdp=[],
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
gradient_accumulation_steps=1,
gradient_checkpointing=False,
greater_is_better=True,
group_by_length=False,
half_precision_backend=auto,
hub_model_id=None,
hub_private_repo=False,
hub_strategy=every_save,
hub_token=<HUB_TOKEN>,
ignore_data_skip=False,
include_inputs_for_metrics=False,
jit_mode_eval=False,
label_names=['ner'],
label_smoothing_factor=0.0,
learning_rate=3e-05,
length_column_name=length,
load_best_model_at_end=True,
local_rank=-1,
log_level=passive,
log_level_replica=passive,
log_on_each_node=True,
logging_dir=/tmp/conll03\runs\Mar02_22-39-10_DESKTOP-44EL6IH,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=10,
logging_strategy=steps,
lr_scheduler_type=linear,
max_grad_norm=1.0,
max_steps=-1,
metric_for_best_model=f1,
mp_parameters=,
no_cuda=False,
num_train_epochs=20,
optim=adamw_torch,
optim_args=None,
output_dir=/tmp/conll03,
overwrite_output_dir=True,
past_index=-1,
per_device_eval_batch_size=8,
per_device_train_batch_size=8,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=<PUSH_TO_HUB_TOKEN>,
ray_scope=last,
remove_unused_columns=True,
report_to=[],
resume_from_checkpoint=None,
run_name=base-run,
save_on_each_node=False,
save_steps=100,
save_strategy=steps,
save_total_limit=1,
seed=42,
sharded_ddp=[],
skip_memory_metrics=True,
tf32=None,
torch_compile=False,
torch_compile_backend=None,
torch_compile_mode=None,
torchdynamo=None,
tpu_metrics_debug=False,
tpu_num_cores=None,
use_ipex=False,
use_legacy_prediction_loop=False,
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.0,
xpu_backend=None,
)
03/02/2023 22:39:18 - WARNING - datasets.builder - Using custom data configuration default-a33b9b3f9ebc66c0
03/02/2023 22:39:18 - INFO - datasets.builder - Overwrite dataset info from restored data version.
03/02/2023 22:39:18 - INFO - datasets.info - Loading Dataset info from E:/PythonProject_2023/pythonProject_SIM/binder-main/pretrained model\json\default-a33b9b3f9ebc66c0\0.0.0\e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab
03/02/2023 22:39:18 - WARNING - datasets.builder - Found cached dataset json (E:/PythonProject_2023/pythonProject_SIM/binder-main/pretrained model/json/default-a33b9b3f9ebc66c0/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab)
03/02/2023 22:39:18 - INFO - datasets.info - Loading Dataset info from E:/PythonProject_2023/pythonProject_SIM/binder-main/pretrained model/json/default-a33b9b3f9ebc66c0/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab
03/02/2023 22:39:18 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at E:/PythonProject_2023/pythonProject_SIM/binder-main/pretrained model/json/default-a33b9b3f9ebc66c0/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab\cache-3dd16664e4cd502f.arrow
03/02/2023 22:39:18 - WARNING - datasets.arrow_dataset - Loading cached sorted indices for dataset at E:/PythonProject_2023/pythonProject_SIM/binder-main/pretrained model/json/default-a33b9b3f9ebc66c0/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab\cache-9b3867899aa5d37f.arrow
03/02/2023 22:39:18 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at E:/PythonProject_2023/pythonProject_SIM/binder-main/pretrained model/json/default-a33b9b3f9ebc66c0/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab\cache-cd523ff19679cbd4.arrow
Running tokenizer on train dataset: 0%| | 0/1 [00:00<?, ?ba/s]03/02/2023 22:39:43 - INFO - datasets.arrow_dataset - Caching processed dataset at E:/PythonProject_2023/pythonProject_SIM/binder-main/pretrained model/json/default-c212c66a12ff2e9f/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab\cache-e0af4479030ebcb8.arrow
Running tokenizer on train dataset: 100%|██████████| 1/1 [01:51<00:00, 111.38s/ba]
Running tokenizer on validation dataset: 0%| | 0/1 [00:00<?, ?ba/s]03/02/2023 22:41:12 - INFO - datasets.arrow_dataset - Caching processed dataset at E:/PythonProject_2023/pythonProject_SIM/binder-main/pretrained model/json/default-c212c66a12ff2e9f/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab\cache-ba5b02e5239fff1d.arrow
Running tokenizer on validation dataset: 100%|██████████| 1/1 [00:00<00:00, 1.62ba/s]
Running tokenizer on prediction dataset: 0%| | 0/1 [00:00<?, ?ba/s]03/02/2023 22:41:13 - INFO - datasets.arrow_dataset - Caching processed dataset at E:/PythonProject_2023/pythonProject_SIM/binder-main/pretrained model/json/default-c212c66a12ff2e9f/0.0.0/e6070c77f18f01a5ad4551a8b7edfba20b8438b7cad4d94e6ad9378022ce4aab\cache-318430783f03d51b.arrow
Running tokenizer on prediction dataset: 100%|██████████| 1/1 [00:00<00:00, 1.98ba/s]
[INFO|trainer.py:565] 2023-03-02 22:41:14,222 >> Using cuda_amp half precision backend
[INFO|trainer.py:711] 2023-03-02 22:41:14,223 >> The following columns in the training set don't have a corresponding argument in `Binder.forward` and have been ignored: token_start_mask, token_end_mask. If token_start_mask, token_end_mask are not expected by `Binder.forward`, you can safely ignore this message.
[INFO|trainer.py:1650] 2023-03-02 22:41:14,232 >> ***** Running training *****
[INFO|trainer.py:1651] 2023-03-02 22:41:14,232 >> Num examples = 1547
[INFO|trainer.py:1652] 2023-03-02 22:41:14,232 >> Num Epochs = 20
[INFO|trainer.py:1653] 2023-03-02 22:41:14,232 >> Instantaneous batch size per device = 8
[INFO|trainer.py:1654] 2023-03-02 22:41:14,232 >> Total train batch size (w. parallel, distributed & accumulation) = 8
[INFO|trainer.py:1655] 2023-03-02 22:41:14,232 >> Gradient Accumulation steps = 1
[INFO|trainer.py:1656] 2023-03-02 22:41:14,233 >> Total optimization steps = 3880
[INFO|trainer.py:1658] 2023-03-02 22:41:14,237 >> Number of trainable parameters = 2161775390%| | 10/3880 [00:16<1:01:16, 1.05it/s]{'loss': 5.772, 'learning_rate': 2.9938144329896908e-05, 'epoch': 0.05}1%| | 20/3880 [00:25<57:31, 1.12it/s]{'loss': 3.2224, 'learning_rate': 2.9860824742268043e-05, 'epoch': 0.1}1%| | 30/3880 [00:34<56:55, 1.13it/s]{'loss': 2.7578, 'learning_rate': 2.9783505154639177e-05, 'epoch': 0.15}1%| | 40/3880 [00:43<1:05:21, 1.02s/it]{'loss': 2.397, 'learning_rate': 2.9706185567010312e-05, 'epoch': 0.21}1%|▏ | 50/3880 [00:52<59:42, 1.07it/s]{'loss': 2.1432, 'learning_rate': 2.9628865979381447e-05, 'epoch': 0.26}2%|▏ | 60/3880 [01:01<57:31, 1.11it/s]{'loss': 1.9551, 'learning_rate': 2.955154639175258e-05, 'epoch': 0.31}2%|▏ | 70/3880 [01:11<58:53, 1.08it/s]{'loss': 1.9147, 'learning_rate': 2.947422680412371e-05, 'epoch': 0.36}2%|▏ | 80/3880 [01:20<57:13, 1.11it/s]{'loss': 1.8418, 'learning_rate': 2.9396907216494844e-05, 'epoch': 0.41}2%|▏ | 90/3880 [01:29<59:00, 1.07it/s]{'loss': 1.4955, 'learning_rate': 2.931958762886598e-05, 'epoch': 0.46}3%|▎ | 100/3880 [01:38<55:58, 1.13it/s][INFO|trainer.py:711] 2023-03-02 22:42:52,527 >> The following columns in the evaluation set don't have a corresponding argument in `Binder.forward` and have been ignored: token_start_mask, token_end_mask, example_id, offset_mapping, split. If token_start_mask, token_end_mask, example_id, offset_mapping, split are not expected by `Binder.forward`, you can safely ignore this message.
{'loss': 1.467, 'learning_rate': 2.9242268041237113e-05, 'epoch': 0.52}
[INFO|trainer.py:2964] 2023-03-02 22:42:52,528 >> ***** Running Evaluation *****
[INFO|trainer.py:2966] 2023-03-02 22:42:52,528 >> Num examples = 384
[INFO|trainer.py:2969] 2023-03-02 22:42:52,529 >> Batch size = 80%| | 0/48 [00:00<?, ?it/s]6%|▋ | 3/48 [00:00<00:02, 19.40it/s]10%|█ | 5/48 [00:00<00:02, 17.02it/s]15%|█▍ | 7/48 [00:00<00:02, 15.75it/s]19%|█▉ | 9/48 [00:00<00:02, 15.45it/s]23%|██▎ | 11/48 [00:00<00:02, 15.26it/s]27%|██▋ | 13/48 [00:00<00:02, 14.99it/s]31%|███▏ | 15/48 [00:00<00:02, 14.95it/s]35%|███▌ | 17/48 [00:01<00:02, 14.48it/s]40%|███▉ | 19/48 [00:01<00:02, 13.92it/s]44%|████▍ | 21/48 [00:01<00:01, 14.21it/s]48%|████▊ | 23/48 [00:01<00:01, 13.71it/s]52%|█████▏ | 25/48 [00:01<00:01, 13.55it/s]56%|█████▋ | 27/48 [00:01<00:01, 13.92it/s]60%|██████ | 29/48 [00:01<00:01, 14.16it/s]65%|██████▍ | 31/48 [00:02<00:01, 14.42it/s]69%|██████▉ | 33/48 [00:02<00:01, 14.55it/s]73%|███████▎ | 35/48 [00:02<00:00, 14.48it/s]77%|███████▋ | 37/48 [00:02<00:00, 14.02it/s]81%|████████▏ | 39/48 [00:02<00:00, 14.26it/s]85%|████████▌ | 41/48 [00:02<00:00, 14.47it/s]90%|████████▉ | 43/48 [00:02<00:00, 14.60it/s]94%|█████████▍| 45/48 [00:03<00:00, 14.72it/s]03/02/2023 23:56:07 - INFO - __main__ - *** Evaluate ***98%|█████████▊| 47/48 [00:03<00:00, 15.04it/s]03/02/2023 23:56:16 - INFO - src.utils - Post-processing 216 example predictions split into 384 features.
03/02/2023 23:56:18 - INFO - src.utils - ***** all (5942) *****
03/02/2023 23:56:18 - INFO - src.utils - F1 = 95.8%, Precision = 96.2%, Recall = 95.5% (for span)
03/02/2023 23:56:18 - INFO - src.utils - F1 = 96.5%, Precision = 96.8%, Recall = 96.1% (for start)
03/02/2023 23:56:18 - INFO - src.utils - F1 = 96.5%, Precision = 96.9%, Recall = 96.2% (for end)
03/02/2023 23:56:18 - INFO - src.utils - ***** PER (1842) *****
03/02/2023 23:56:18 - INFO - src.utils - F1 = 97.6%, Precision = 98.0%, Recall = 97.2% (for span)
03/02/2023 23:56:18 - INFO - src.utils - F1 = 98.3%, Precision = 98.7%, Recall = 97.9% (for start)
03/02/2023 23:56:18 - INFO - src.utils - F1 = 98.3%, Precision = 98.7%, Recall = 97.9% (for end)
03/02/2023 23:56:18 - INFO - src.utils - ***** LOC (1837) *****
03/02/2023 23:56:18 - INFO - src.utils - F1 = 97.5%, Precision = 98.2%, Recall = 96.8% (for span)
03/02/2023 23:56:18 - INFO - src.utils - F1 = 97.6%, Precision = 98.3%, Recall = 96.9% (for start)
03/02/2023 23:56:18 - INFO - src.utils - F1 = 97.7%, Precision = 98.4%, Recall = 97.0% (for end)
03/02/2023 23:56:18 - INFO - src.utils - ***** ORG (1341) *****
03/02/2023 23:56:18 - INFO - src.utils - F1 = 94.6%, Precision = 94.8%, Recall = 94.5% (for span)
03/02/2023 23:56:18 - INFO - src.utils - F1 = 95.5%, Precision = 95.7%, Recall = 95.4% (for start)
03/02/2023 23:56:18 - INFO - src.utils - F1 = 95.2%, Precision = 95.4%, Recall = 95.1% (for end)
03/02/2023 23:56:18 - INFO - src.utils - ***** MISC (922) *****
03/02/2023 23:56:18 - INFO - src.utils - F1 = 90.9%, Precision = 90.6%, Recall = 91.1% (for span)
03/02/2023 23:56:18 - INFO - src.utils - F1 = 92.0%, Precision = 91.8%, Recall = 92.3% (for start)
03/02/2023 23:56:18 - INFO - src.utils - F1 = 92.7%, Precision = 92.4%, Recall = 93.0% (for end)
03/02/2023 23:56:18 - INFO - src.utils - Saving predictions to /tmp/conll03\eval_predictions.json.
03/02/2023 23:56:18 - INFO - src.utils - Saving metrics to /tmp/conll03\eval_metrics.json.
***** eval metrics *****epoch = 20.0eval_f1 = 0.9584eval_precision = 0.9617eval_recall = 0.9551eval_samples = 384
03/02/2023 23:56:18 - INFO - __main__ - *** Predict ***
100%|██████████| 48/48 [00:06<00:00, 7.73it/s]
[INFO|trainer.py:711] 2023-03-02 23:56:18,486 >> The following columns in the test set don't have a corresponding argument in `Binder.forward` and have been ignored: token_start_mask, token_end_mask, example_id, offset_mapping, split. If token_start_mask, token_end_mask, example_id, offset_mapping, split are not expected by `Binder.forward`, you can safely ignore this message.
[INFO|trainer.py:2964] 2023-03-02 23:56:18,488 >> ***** Running Prediction *****
[INFO|trainer.py:2966] 2023-03-02 23:56:18,488 >> Num examples = 373
[INFO|trainer.py:2969] 2023-03-02 23:56:18,488 >> Batch size = 898%|█████████▊| 46/47 [00:02<00:00, 15.20it/s]03/02/2023 23:56:27 - INFO - src.utils - Post-processing 231 example predictions split into 373 features.
03/02/2023 23:56:29 - INFO - src.utils - ***** all (5648) *****
03/02/2023 23:56:29 - INFO - src.utils - F1 = 91.8%, Precision = 92.2%, Recall = 91.4% (for span)
03/02/2023 23:56:29 - INFO - src.utils - F1 = 92.8%, Precision = 93.2%, Recall = 92.4% (for start)
03/02/2023 23:56:29 - INFO - src.utils - F1 = 92.9%, Precision = 93.3%, Recall = 92.6% (for end)
03/02/2023 23:56:29 - INFO - src.utils - ***** LOC (1668) *****
03/02/2023 23:56:29 - INFO - src.utils - F1 = 93.1%, Precision = 93.7%, Recall = 92.6% (for span)
03/02/2023 23:56:29 - INFO - src.utils - F1 = 93.7%, Precision = 94.2%, Recall = 93.1% (for start)
03/02/2023 23:56:29 - INFO - src.utils - F1 = 93.4%, Precision = 94.0%, Recall = 92.9% (for end)
03/02/2023 23:56:29 - INFO - src.utils - ***** ORG (1661) *****
03/02/2023 23:56:29 - INFO - src.utils - F1 = 90.4%, Precision = 90.3%, Recall = 90.5% (for span)
03/02/2023 23:56:29 - INFO - src.utils - F1 = 91.5%, Precision = 91.4%, Recall = 91.6% (for start)
03/02/2023 23:56:29 - INFO - src.utils - F1 = 91.9%, Precision = 91.8%, Recall = 92.0% (for end)
03/02/2023 23:56:29 - INFO - src.utils - ***** PER (1617) *****
03/02/2023 23:56:29 - INFO - src.utils - F1 = 96.0%, Precision = 97.2%, Recall = 94.8% (for span)
03/02/2023 23:56:29 - INFO - src.utils - F1 = 97.1%, Precision = 98.3%, Recall = 95.9% (for start)
03/02/2023 23:56:29 - INFO - src.utils - F1 = 97.3%, Precision = 98.5%, Recall = 96.1% (for end)
03/02/2023 23:56:29 - INFO - src.utils - ***** MISC (702) *****
03/02/2023 23:56:29 - INFO - src.utils - F1 = 82.5%, Precision = 81.9%, Recall = 83.0% (for span)
03/02/2023 23:56:29 - INFO - src.utils - F1 = 84.3%, Precision = 83.7%, Recall = 84.9% (for start)
03/02/2023 23:56:29 - INFO - src.utils - F1 = 84.4%, Precision = 83.8%, Recall = 85.0% (for end)
03/02/2023 23:56:29 - INFO - src.utils - Saving predictions to /tmp/conll03\predict_predictions.json.
03/02/2023 23:56:29 - INFO - src.utils - Saving metrics to /tmp/conll03\predict_metrics.json.
***** predict metrics *****epoch = 20.0predict_samples = 373test_f1 = 0.918test_precision = 0.9218test_recall = 0.9143
[INFO|modelcard.py:449] 2023-03-02 23:56:30,832 >> Dropping the following result as it does not have all the necessary fields:
{'dataset': {'name': 'CoNLL2003 conf\\conll03.json', 'type': 'CoNLL2003', 'args': 'conf\\conll03.json'}}
100%|██████████| 47/47 [00:06<00:00, 6.72it/s]
相关文章:
论文复现-2:代码部分
以CONLL03数据集为例 文章目录1 整体框架2 数据结构2.1 原始数据集2.2 处理之后的数据集3 代码部分3.0 模型参数3.1 数据预处理3.2 模型方法3.1.1 定义表示的学习权重项的学习双塔模型3.2.2 forward3.3 损失函数3.4 训练与推理Ablation study训练实例1 整体框架 任务是实体识别…...
Linux开放的端口太多了?教你一招找出所有开放的端口,然后直接干掉!
基于服务器安全性维护的目的,查看所有开放的端口是通常采取的第一步,从中检查出可疑或者不必要的端口并将其关掉。关于查看开放的端口,方法不止一种,比如lsof 命令,还可以使用 ss 命令。 查看开放的端口 今天我们就介…...

mysql集群简介
集群的好处 高可用性:故障检测及迁移,多节点备份。 可伸缩性:新增数据库节点便利,方便扩容。 负载均衡:切换某服务访问某节点,分摊单个节点的数据库压力。 集群要考虑的风险 网络分裂:群集还…...

装饰器模式
概述 当我们编写软件时,有时我们会遇到需要在不修改现有代码的情况下添加新功能的情况。这时,我们可以使用装饰器模式。 装饰器模式是一种结构性设计模式,它允许我们在不改变对象接口的情况下动态地向对象添加功能。装饰器模式通过创建一个…...

21 Nacos客户端本地缓存及故障转移
Nacos客户端本地缓存及故障转移 在Nacos本地缓存的时候有的时候必然会出现一些故障,这些故障就需要进行处理,涉及到的核心类为ServiceInfoHolder和FailoverReactor。 本地缓存有两方面,第一方面是从注册中心获得实例信息会缓存在内存当中&a…...

遍历读取文件夹下的所有文件
遍历读取文件夹下的所有文件 例如,读取文件夹下,子文件夹的所有的jpg文件: import glob path "./database/20230302/night/*/*.jpg"#设置自己的文件夹路径以及文件 image_files glob.glob(path, recursiveTrue)for image_file …...
nexus安装与入门
安装 nexus-3.31.1-01-unix.tar.gz 链接:https://pan.baidu.com/s/1YrJMwpGxmu8N2d7XMl6fSg 提取码:kfeh 上传到服务器,解压 tar -zvxf nexus-3.31.1-01-unix.tar.gz进入bin目录,启动 ./nexus start查看状态 ./nexus status默…...
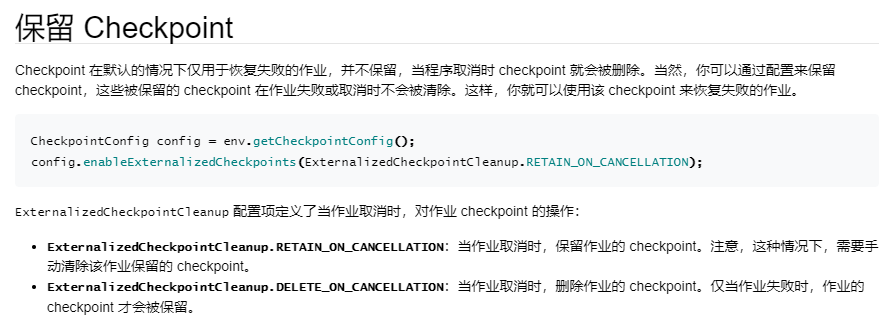
Flink SQL Checkpoint 学习总结
前言 学习总结Flink SQL Checkpoint的使用,主要目的是为了验证Flink SQL流式任务挂掉后,重启时还可以继续从上次的运行状态恢复。 验证方式 Flink SQL流式增量读取Hudi表然后sink MySQL表,任务启动后处于running状态,先查看sin…...
2023年“楚怡杯“湖南省职业院校技能竞赛“网络安全”竞赛任务书
2023年“楚怡杯“湖南省职业院校技能竞赛“网络安全”竞赛任务书 一、竞赛时间 总计:360分钟 竞赛阶段竞赛阶段 任务阶段 竞赛任务 竞赛时间 分值 A模块 A-1 登录安全加固 180分钟 200分 A-2 本地安全策略配置 A-3 流量完整性保护 A-4 事件监控 …...

MyBatis中主键回填的两种实现方式
主键回填其实是一个非常常见的需求,特别是在数据添加的过程中,我们经常需要添加完数据之后,需要获取刚刚添加的数据 id,无论是 Jdbc 还是各种各样的数据库框架都对此提供了相关的支持,本文我就来和和大家分享下数据库主…...

Windows11如何打开ie浏览器
目录1.背景:2.方法一:在 edge 中配置使用 ie 模式3.方法二:通过 Internet 选项 打开1.背景: 昨天电脑自动从win10升级为win11了,突然发现电脑找不到ie浏览器了,打开全都是直接跳转到 edge 浏览器࿰…...

Linux:进程间通信
目录 进程间通信目的 进程间通信分类 管道 System V IPC POSIX IPC 什么是管道 站在文件描述符角度-深度理解管道 管道使用 管道通信的四种情况 管道通信的特点 进程池管理 命名管道 创建一个命名管道 命名管道的打开规则 命名管道通信实例 匿名管道与命名管道的…...

【java】将LAC改造成Elasticsearch分词插件
目录 为什么要将LAC改造成ES插件? 怎么将LAC改造成ES插件? 确认LAC java接口能work 搭建ES插件开发调试环境 编写插件 生成插件 安装、运行插件 linux版本的动态链接库生成 总结 参考文档 为什么要将LAC改造成ES插件? ES是著名的非…...
)
TPM 2.0实例探索3 —— LUKS磁盘加密(5)
接前文:TPM 2.0实例探索3 —— LUKS磁盘加密(4) 本文大部分内容参考: Code Sample: Protecting secret data and keys using Intel Platform... 二、LUKS磁盘加密实例 4. 将密码存储于TPM的PCR 现在将TPM非易失性存储器中保护…...
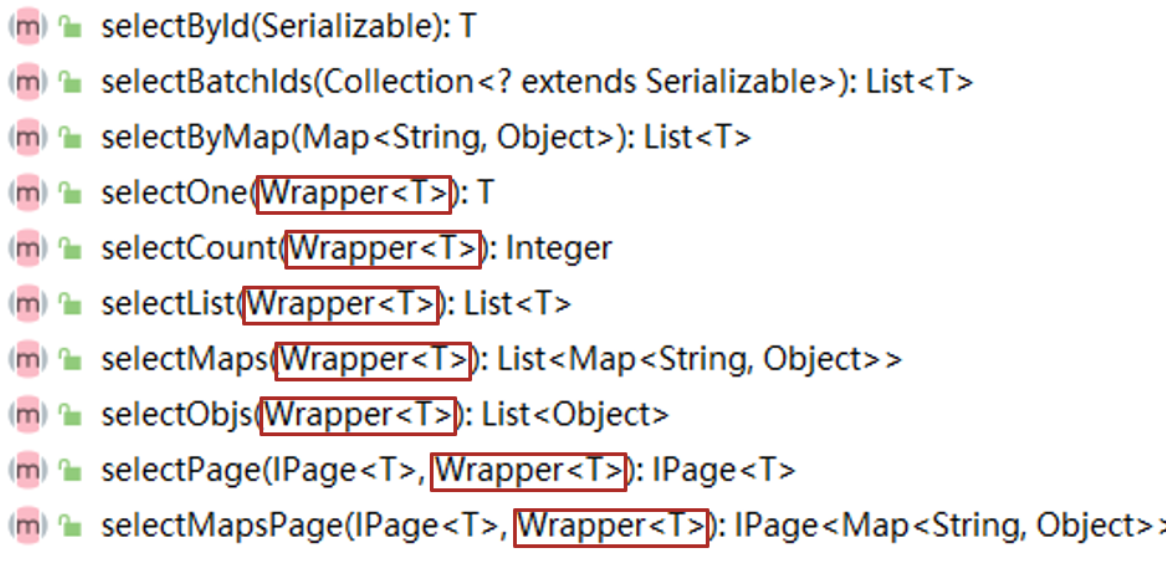
mybatisplus复习(黑马)
学习目标能够基于MyBatisPlus完成标准Dao开发能够掌握MyBatisPlus的条件查询能够掌握MyBatisPlus的字段映射与表名映射能够掌握id生成策略控制能够理解代码生成器的相关配置一、MyBatisPlus简介MyBatisPlus(简称MP)是基于MyBatis框架基础上开发的增强型工…...

【数据聚类|深度聚类】Deep Comprehensive Correlation Mining for Image Clustering(DCCM)论文研读
Abstract 翻译 最近出现的深度无监督方法使我们能够联合学习表示和对未标记数据进行聚类。这些深度聚类方法主要关注样本之间的相关性,例如选择高精度对来逐步调整特征表示,而忽略了其他有用的相关性。本文提出了一种新的聚类框架,称为深度全面相关挖掘(DCCM),从三个方面…...

CE认证机构有哪些机构?
CE认证机构有哪些机构? 所有出口欧盟的产品都需要办理CE证明,而电子电器以及玩具是强制性要做CE认证。很多人以为只有办理欧盟NB公告机构的CE认证才可以被承认,实际上并不是。那么,除了NB公告上的机构,还有哪些认证机…...
解决方法)
MYSQL5.7:Access denied for user ‘root‘@‘localhost‘ (using password:YES)解决方法
一、打开MySQL目录下的my.ini文件,在文件的[mysqld]下面添加一行 skip-grant-tables,保存并关闭文件;skip-grant-tables :跳过密码登录,登录时无需密码。my.ini :一般在和bin同目录下,如果没有的话可自己创…...

单目运算符、双目运算符、三目运算符
单目运算符是什么 单目运算符是指运算所需变量为一个的运算符 又叫一元运算符,其中有逻辑非运算符:!、按位取 反运算符:~、自增自减运算符:,-等。 逻辑非运算符【!】、按位取反运算符【~】、 自…...
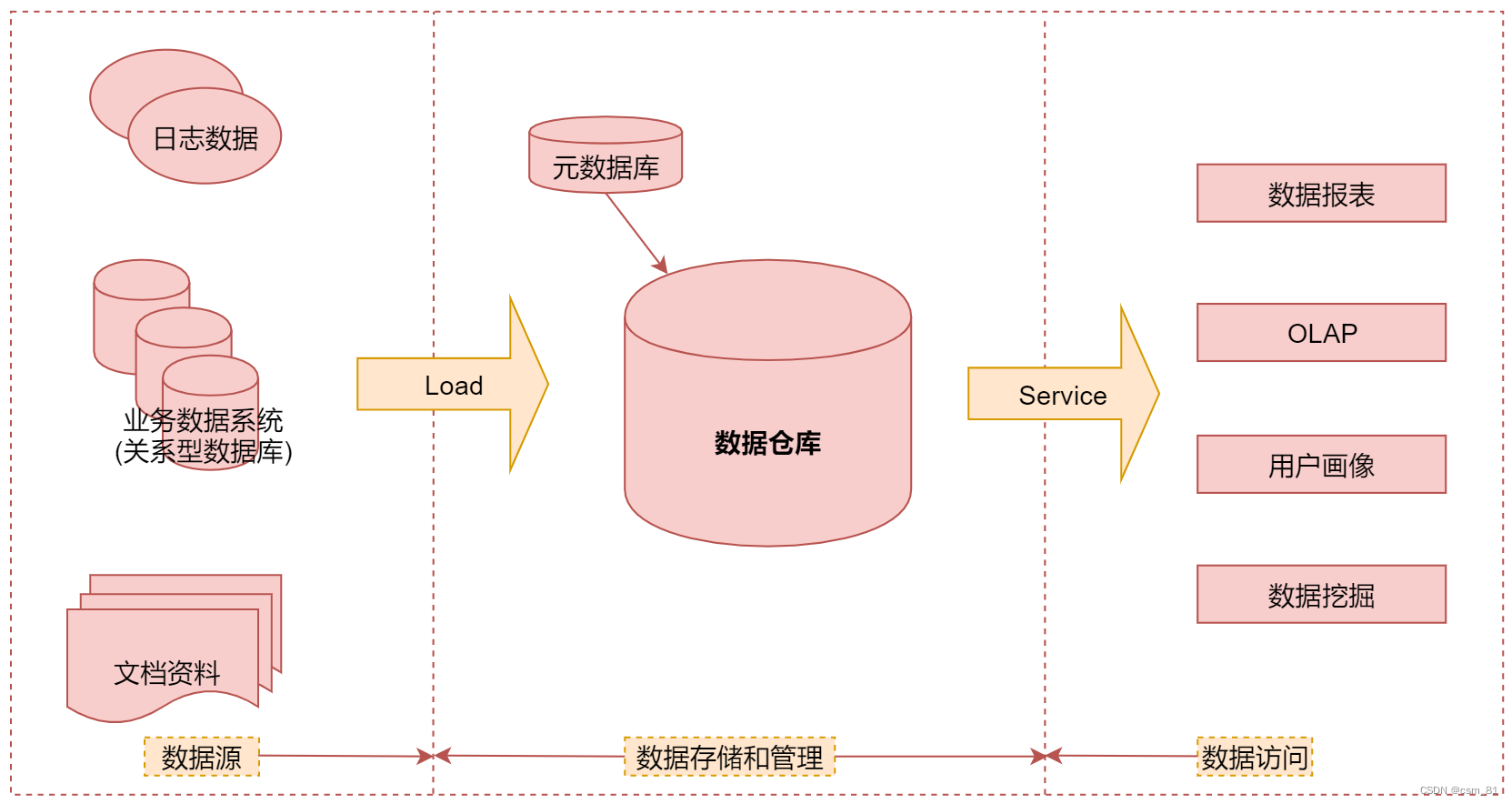
离线数据仓库项目搭建——准备篇
文章目录(一)什么是数据仓库(二)数据仓库基础知识(三)数据仓库建模方式(1)星行模型(2)雪花模型(3)星型模型 VS 雪花模型(四…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...

极致精简,功能强大的PDF编辑工具
这是一款功能全面的PDF编辑工具 你只需要导入一份PDF格式文件 就可以快速的对它进行插入 批注编辑保护转换等各种操作 而且无需登录 也可以直接使用 在插入选项中可以进行插入文字图片 页面页眉页脚页码文档背景水印视频音频等 在批注选项中可以管理批注隐藏批注 高亮显示 文本…...

skills CANN开源社区贡献技能包开发指南
前言 开源社区的健康运转,不仅依赖核心代码的贡献,还需要降低贡献门槛、提供清晰的指南和自动化工具。skills仓库是CANN开源社区的"贡献技能包",提供了一系列辅助脚本、代码模板、CI检查和文档生成工具,帮助新手快速上…...

3分钟掌握JetBrains IDE试用期重置:终极完整指南
3分钟掌握JetBrains IDE试用期重置:终极完整指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter JetBrains IDE试用期重置工具(ide-eval-resetter)是一个开源项目,专…...

Facebook登录协议逆向解析:appsecret_proof与e2e加密机制
1. 这不是“爬虫教程”,而是一次对现代Web身份协议的解剖实验你有没有试过,在调试一个Facebook登录集成时,浏览器Network面板里突然冒出一串带sig、access_token、e2e、c_user的请求,参数长度动辄上千字符,加密方式五花…...

Claude Code + LM Studio + CC-Switch 本地自动化编程部署指南
Claude Code LM Studio CC-Switch 本地自动化编程部署指南 本指南汇总了在 Windows 本地环境下,使用 Claude Code 配合 LM Studio 本地模型、CC-Switch 代理进行自动化编程开发的完整配置方案。 目录 硬件与模型选型LM Studio 本地模型部署CC-Switch 代理配置Cla…...

面试官问LinkedBlockingQueue和ArrayBlockingQueue区别?别只答有界无界了,这3个实战坑才是重点
面试官追问LinkedBlockingQueue与ArrayBlockingQueue?别只答基础区别,这3个实战陷阱才是关键 当面试官抛出"LinkedBlockingQueue和ArrayBlockingQueue有什么区别"这个问题时,80%的候选人会条件反射般回答"一个有界一个无界&qu…...

在github上快速接入taotoken大模型api的python调用教程
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在GitHub上快速接入Taotoken大模型API的Python调用教程 对于希望快速集成大模型能力的开发者而言,找到一个统一、便捷的…...

2023B卷,最佳植树距离
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:华为OD面试 文章目录 一、🍀前言 1.1 ☘️题目详情 1.2 ☘️参考解题答案 一、🍀前言 2023B卷,最佳植树距离。 1.1 ☘️题目详情 题目: 小明在直…...

5分钟搞定Android Studio中文界面:终极免费汉化完整指南
5分钟搞定Android Studio中文界面:终极免费汉化完整指南 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 还在为Androi…...