深入Pandas(二):高级数据处理技巧
文章目录
- 系列文章目录
- 引言
- 时间序列分析可视化示例
- 高级数据分析技术
- 分组与聚合操作
- 时间序列分析
- 高级数据操作
- 数据合并与重塑
- 示例:数据合并merge
- 示例:数据合并concat
- 示例:数据重塑 - 透视表
- 高级索引技巧
- 结论
系列文章目录
Python数据分析全攻略
深入Pandas: 数据分析的强大工具
所有的代码资源包括说明文档均上传至资源,可在文章顶部免费下载!!!
引言
在我们上一篇关于Pandas的博客中,我们已经浏览了这一强大Python数据分析库的基础特性和初级数据处理功能。我们了解到,Pandas以其直观的数据结构和简洁的数据操作流程,为数据科学家和分析师提供了一个极其有效的工具。然而,Pandas的真正魅力远不止于此。对于那些已经熟悉了Pandas基础功能的读者来说,更深层次的探索将揭开Pandas高级数据处理和分析能力的神秘面纱。
在这篇博客中,我们将深入探讨Pandas的高级功能,包括复杂数据的合并与重塑、高级索引技巧、以及高级数据分析技术。此外,我们还将着重介绍如何利用Pandas进行高效的时间序列分析,并通过数据可视化技术将这些分析结果生动呈现。本篇内容旨在为那些希望提升自己在Pandas应用能力上的读者提供实用的指导和灵感。
时间序列分析可视化示例
高级数据分析技术
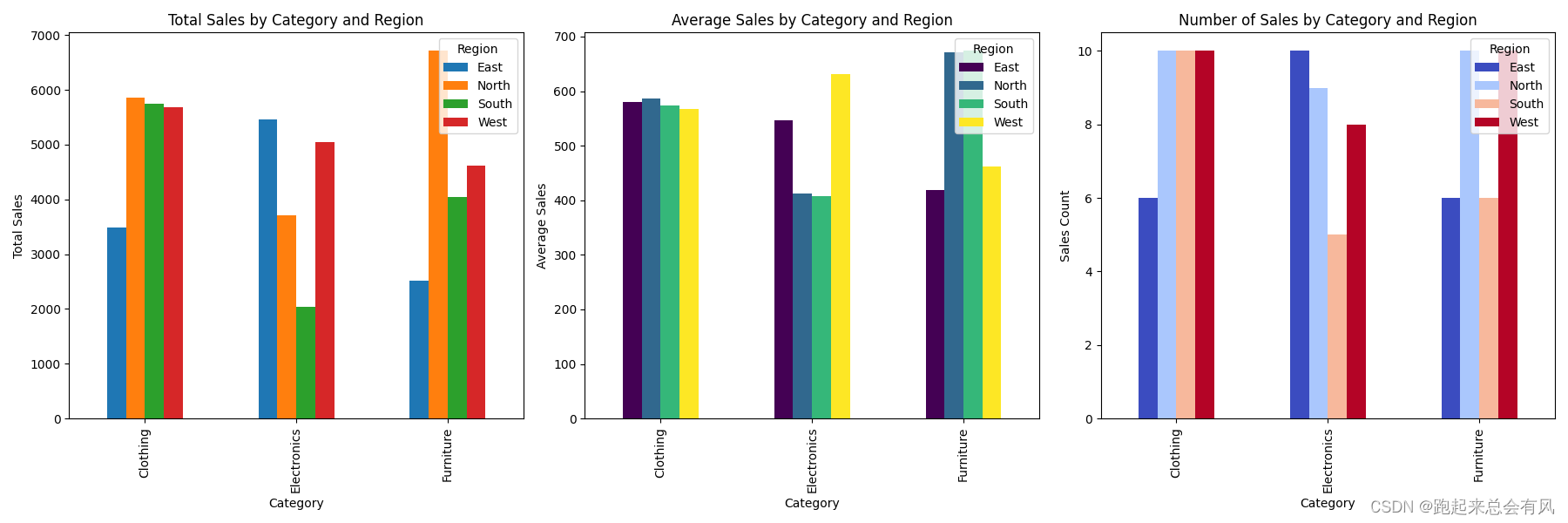
分组与聚合操作
Pandas的groupby功能非常强大,它允许按照某些条件将数据分组,并对每组数据进行聚合操作。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 创建一个包含多列的DataFrame
df = pd.DataFrame({'Date': pd.date_range(start='2023-01-01', periods=100, freq='D'),'Category': np.random.choice(['Electronics', 'Clothing', 'Furniture'], 100),'Region': np.random.choice(['North', 'South', 'East', 'West'], 100),'Sales': np.random.randint(100, 1000, size=100)
})# 使用groupby进行分组,按照'Category'和'Region'列
grouped = df.groupby(['Category', 'Region'])# 对每组数据进行多种聚合操作
agg_df = grouped['Sales'].agg([np.sum, np.mean, np.count_nonzero])# 设置画布大小
plt.figure(figsize=(18, 6))# 第一个图表:销售总额
plt.subplot(1, 3, 1) # 1行3列,第1个
agg_df['sum'].unstack().plot(kind='bar', ax=plt.gca())
plt.title('Total Sales by Category and Region')
plt.ylabel('Total Sales')# 第二个图表:销售平均值
plt.subplot(1, 3, 2) # 1行3列,第2个
agg_df['mean'].unstack().plot(kind='bar', colormap='viridis', ax=plt.gca())
plt.title('Average Sales by Category and Region')
plt.ylabel('Average Sales')# 第三个图表:销售次数
plt.subplot(1, 3, 3) # 1行3列,第3个
agg_df['count_nonzero'].unstack().plot(kind='bar', colormap='coolwarm', ax=plt.gca())
plt.title('Number of Sales by Category and Region')
plt.ylabel('Sales Count')plt.tight_layout() # 调整子图布局
plt.show()
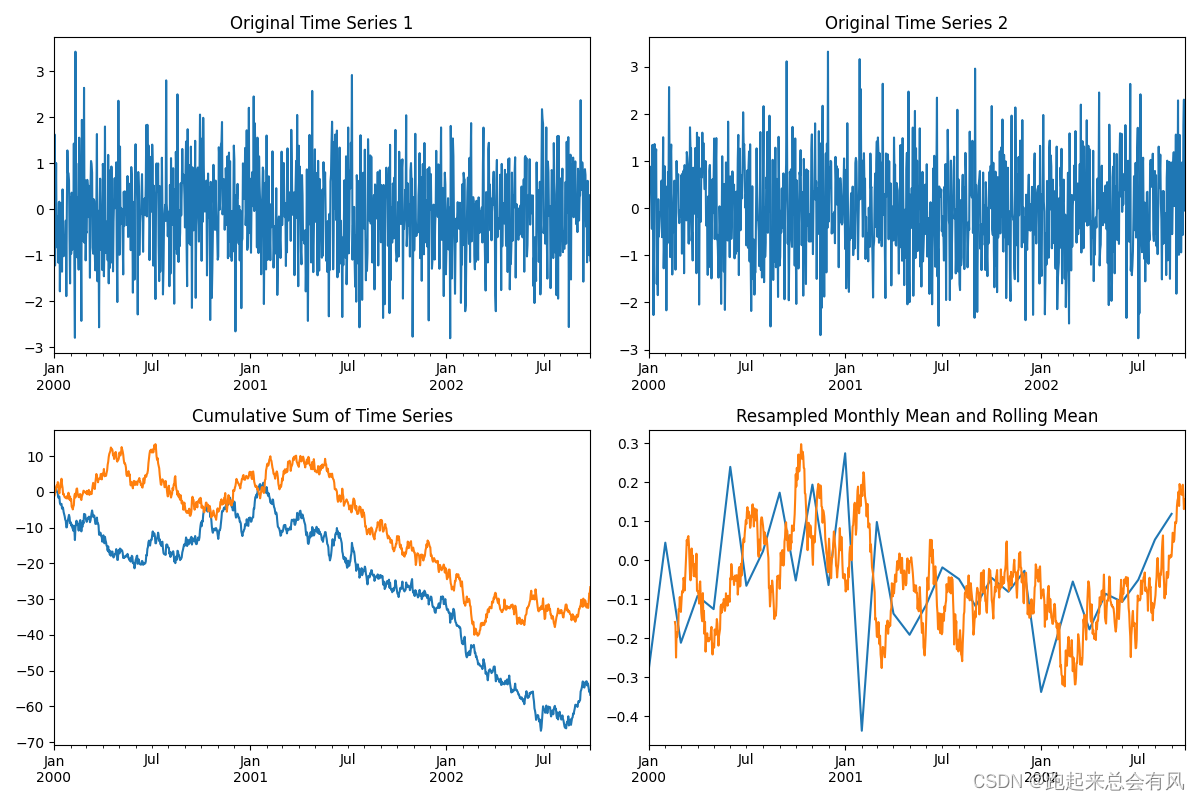
时间序列分析
Pandas提供了强大的时间序列处理能力,包括日期范围生成、频率转换、窗口函数等。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 生成两个时间序列数据
ts1 = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))
ts2 = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1000))# 累计和
ts1_cumsum = ts1.cumsum()
ts2_cumsum = ts2.cumsum()# 重采样并计算均值
ts1_resampled = ts1.resample('M').mean()
ts2_resampled = ts2.resample('M').mean()# 使用滚动窗口计算(例如:窗口大小为50)
roll_mean = ts1.rolling(window=50).mean()# 数据可视化
plt.figure(figsize=(12, 8))# 绘制原始数据
plt.subplot(2, 2, 1)
ts1.plot()
plt.title('Original Time Series 1')plt.subplot(2, 2, 2)
ts2.plot()
plt.title('Original Time Series 2')# 绘制累计和
plt.subplot(2, 2, 3)
ts1_cumsum.plot()
ts2_cumsum.plot()
plt.title('Cumulative Sum of Time Series')# 绘制重采样数据和滚动平均
plt.subplot(2, 2, 4)
ts1_resampled.plot()
roll_mean.plot()
plt.title('Resampled Monthly Mean and Rolling Mean')plt.tight_layout()
plt.show()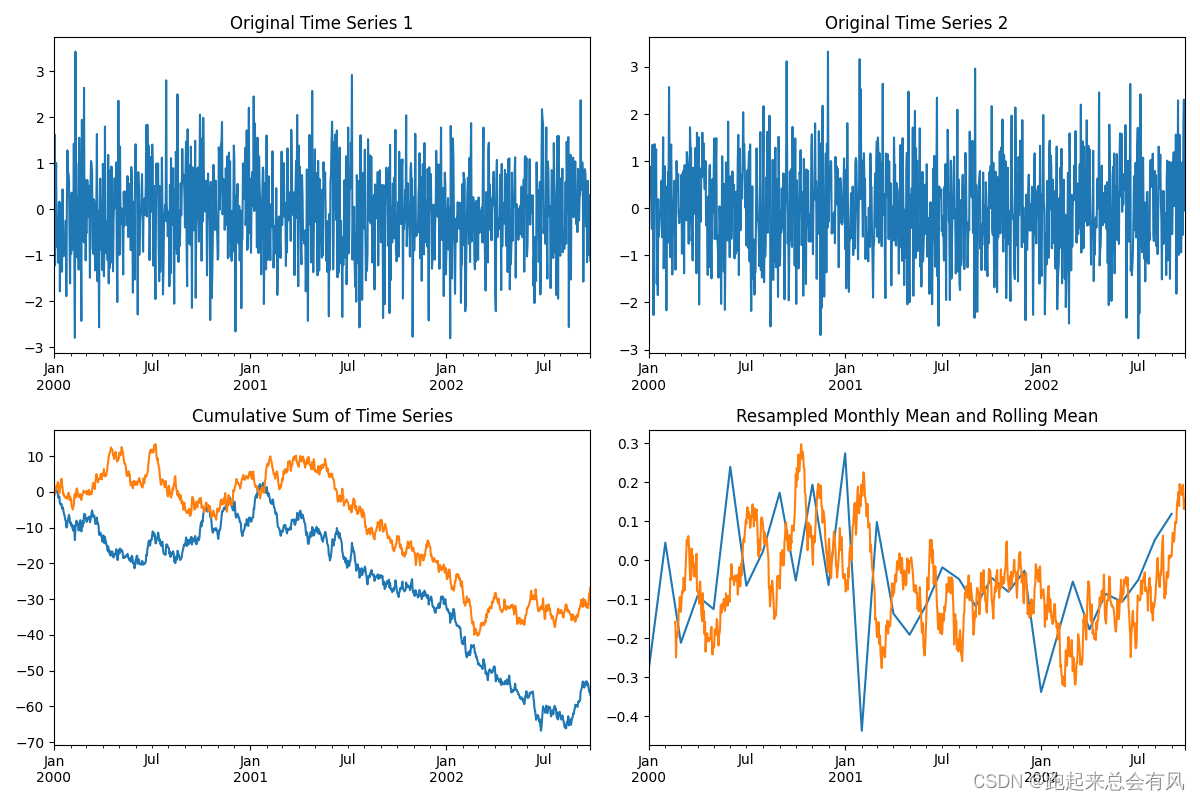
高级数据操作
数据合并与重塑
Pandas提供了多种数据合并和重塑的方法,如merge、concat和pivot_table等。
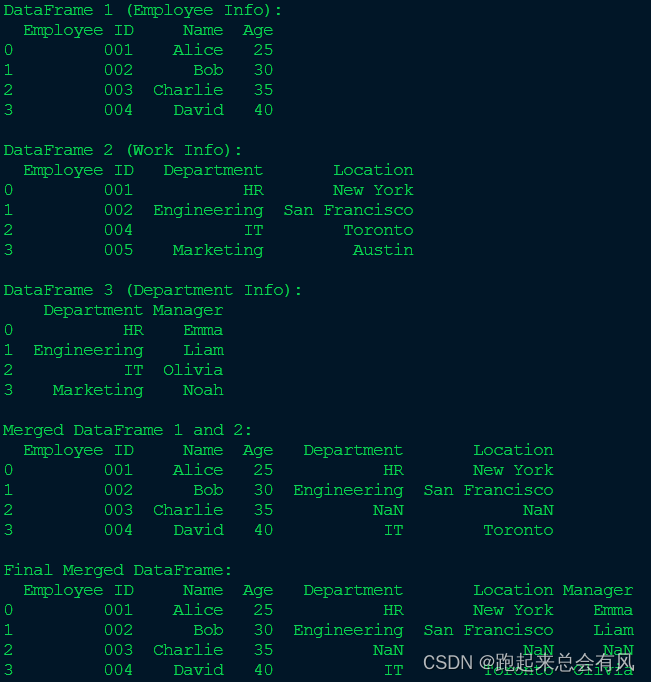
示例:数据合并merge
import pandas as pd# 创建第一个DataFrame:员工ID、姓名和年龄
df1 = pd.DataFrame({'Employee ID': ['001', '002', '003', '004'],'Name': ['Alice', 'Bob', 'Charlie', 'David'],'Age': [25, 30, 35, 40]
})# 创建第二个DataFrame:员工ID、部门和工作地点
df2 = pd.DataFrame({'Employee ID': ['001', '002', '004', '005'],'Department': ['HR', 'Engineering', 'IT', 'Marketing'],'Location': ['New York', 'San Francisco', 'Toronto', 'Austin']
})# 创建第三个DataFrame:部门和部门经理
df3 = pd.DataFrame({'Department': ['HR', 'Engineering', 'IT', 'Marketing'],'Manager': ['Emma', 'Liam', 'Olivia', 'Noah']
})# 打印合并前的DataFrame
print("DataFrame 1 (Employee Info):")
print(df1)
print("\nDataFrame 2 (Work Info):")
print(df2)
print("\nDataFrame 3 (Department Info):")
print(df3)# 使用merge函数合并df1和df2
merged_df1 = pd.merge(df1, df2, on='Employee ID', how='left')# 打印第一次合并后的DataFrame
print("\nMerged DataFrame 1 and 2:")
print(merged_df1)# 再次使用merge合并merged_df1和df3
final_merged_df = pd.merge(merged_df1, df3, on='Department', how='left')# 打印最终合并后的DataFrame
print("\nFinal Merged DataFrame:")
print(final_merged_df)
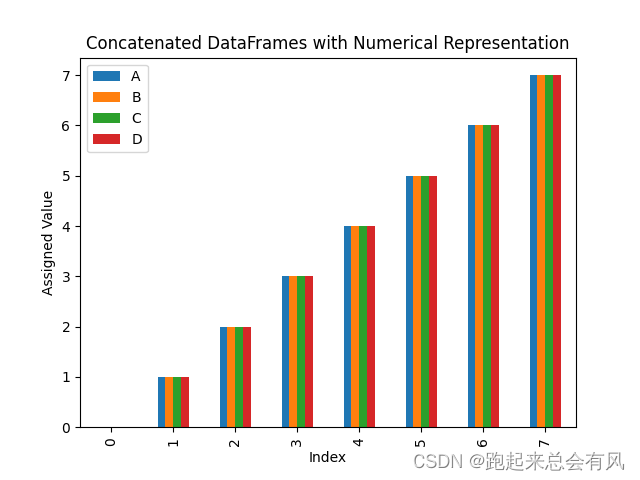
示例:数据合并concat
import pandas as pd
import matplotlib.pyplot as plt# 示例数据集
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']},index=[0, 1, 2, 3])df2 = pd.DataFrame({'A': ['A4', 'A5', 'A6', 'A7'],'B': ['B4', 'B5', 'B6', 'B7'],'C': ['C4', 'C5', 'C6', 'C7'],'D': ['D4', 'D5', 'D6', 'D7']},index=[4, 5, 6, 7])# 使用concat进行数据合并
result = pd.concat([df1, df2])# 为每个唯一的字符串分配一个唯一的整数
for column in result.columns:result[column] = result[column].astype('category').cat.codes# 可视化合并后的数据
result.plot(kind='bar')
plt.title("Concatenated DataFrames with Numerical Representation")
plt.xlabel("Index")
plt.ylabel("Assigned Value")
plt.show()
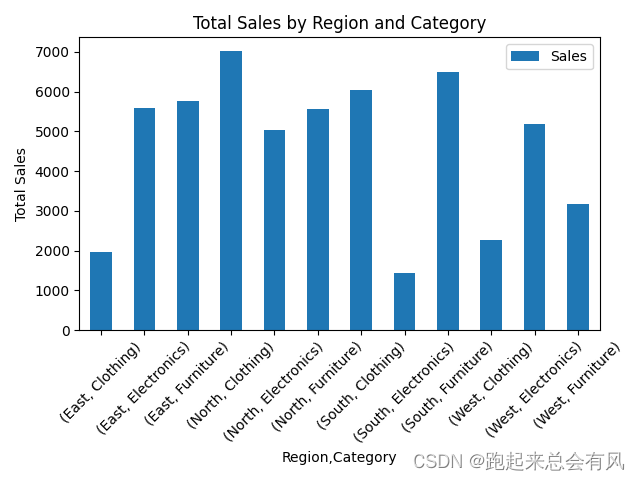
示例:数据重塑 - 透视表
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 创建一个包含日期、产品类别、地区和销售额的DataFrame
data = {'Date': pd.date_range(start='2023-01-01', periods=100, freq='D'),'Category': np.random.choice(['Electronics', 'Clothing', 'Furniture'], 100),'Region': np.random.choice(['North', 'South', 'East', 'West'], 100),'Sales': np.random.randint(100, 1000, size=100)
}
df = pd.DataFrame(data)# 创建透视表
pivot_table = df.pivot_table(values='Sales', index=['Region', 'Category'], aggfunc=[np.sum, np.mean])# 设置图表的大小
plt.figure(figsize=(12, 8)) # 绘制图表
pivot_table['sum'].plot(kind='bar', title='Total Sales by Region and Category')
plt.ylabel('Total Sales')# 调整横坐标标签的角度
plt.xticks(rotation=45)plt.tight_layout()
plt.savefig('pivot_table.png', format='png') # 保存图表为图片# plt.show() # 显示图表
高级索引技巧
Pandas支持多级索引(Hierarchical indexing),它允许在一个轴上拥有多个(两个以上)索引级别。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 创建一个带有多级索引的DataFrame
index = pd.MultiIndex.from_tuples([('a', 1), ('a', 2), ('b', 1), ('b', 2), ('a', 3), ('b', 3)], names=['group', 'subgroup'])
df = pd.DataFrame(np.random.randn(6, 2), index=index, columns=['data1', 'data2'])# 使用groupby和unstack对数据进行处理
grouped = df.groupby(level=0).mean() # 计算每个主组的平均值
unstacked = df.unstack() # 将多级索引数据结构转换为宽格式# 设置画布大小
plt.figure(figsize=(18, 6))# 第一个图表:主组的平均值
plt.subplot(1, 3, 1) # 1行3列,第1个
grouped.plot(kind='bar', ax=plt.gca())
plt.title('Mean of data1 and data2 for each group')# 第二个图表:每个子组的data1数据
plt.subplot(1, 3, 2) # 1行3列,第2个
unstacked['data1'].plot(kind='bar', ax=plt.gca())
plt.title('Data1 for each subgroup')# 第三个图表:每个子组的data2数据
plt.subplot(1, 3, 3) # 1行3列,第3个
unstacked['data2'].plot(kind='bar', ax=plt.gca())
plt.title('Data2 for each subgroup')# 显示图表
plt.tight_layout()
plt.show()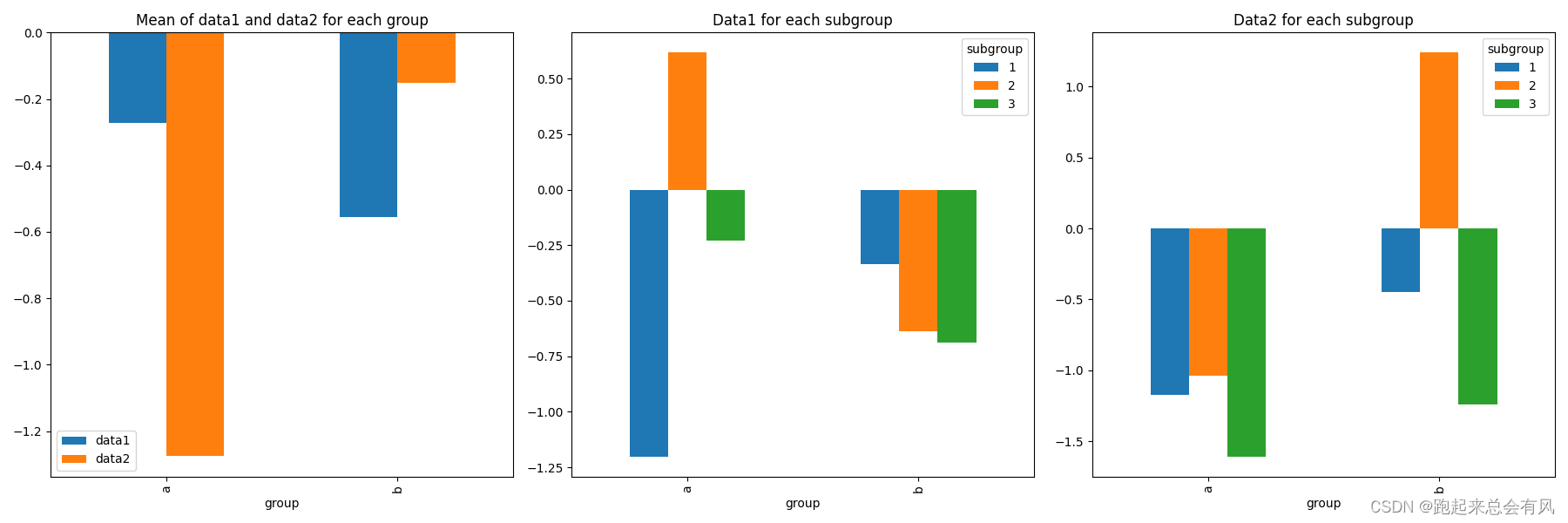
结论
通过本篇的学习,相信读者对Pandas的高级功能有了更深的了解和掌握。Pandas的高级数据处理和分析功能,使得处理复杂数据变得更加简单高效。无论是数据科学家、分析师还是Python开发者,掌握这些高级技巧都将大大提升工作效率和分析能力。
Pandas的高级功能不仅限于本文所述,它还有许多其他强大的功能等待探索。希望读者能够在实践中不断发掘Pandas的潜力,并将其应用于各自的数据分析任务中。
相关文章:
深入Pandas(二):高级数据处理技巧
文章目录 系列文章目录引言时间序列分析可视化示例 高级数据分析技术分组与聚合操作时间序列分析 高级数据操作数据合并与重塑示例:数据合并merge示例:数据合并concat示例:数据重塑 - 透视表 高级索引技巧 结论 系列文章目录 Python数据分析…...

实验8 分析HTTP协议和DNS
实验8 分析HTTP协议和DNS 一、 实验目的及任务 熟悉并掌握wireshark的基本操作,了解网络协议实体间的交互以及报文交换。分析HTTP协议分析DNS协议 二、 实验设备 与因特网连接的计算机网络系统;主机操作系统为Windows;wireshark等软件。 …...

Talk | EMNLP 2023 最佳长论文:以标签为锚-从信息流动的视角分析上下文学习
本期为TechBeat人工智能社区第561期线上Talk。 北京时间1月4日(周四)20:00,北京大学博士生—王乐安的Talk已准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “以标签为锚-从信息流动的视角分析上下文学习”,介绍了他的团队在上下文学…...
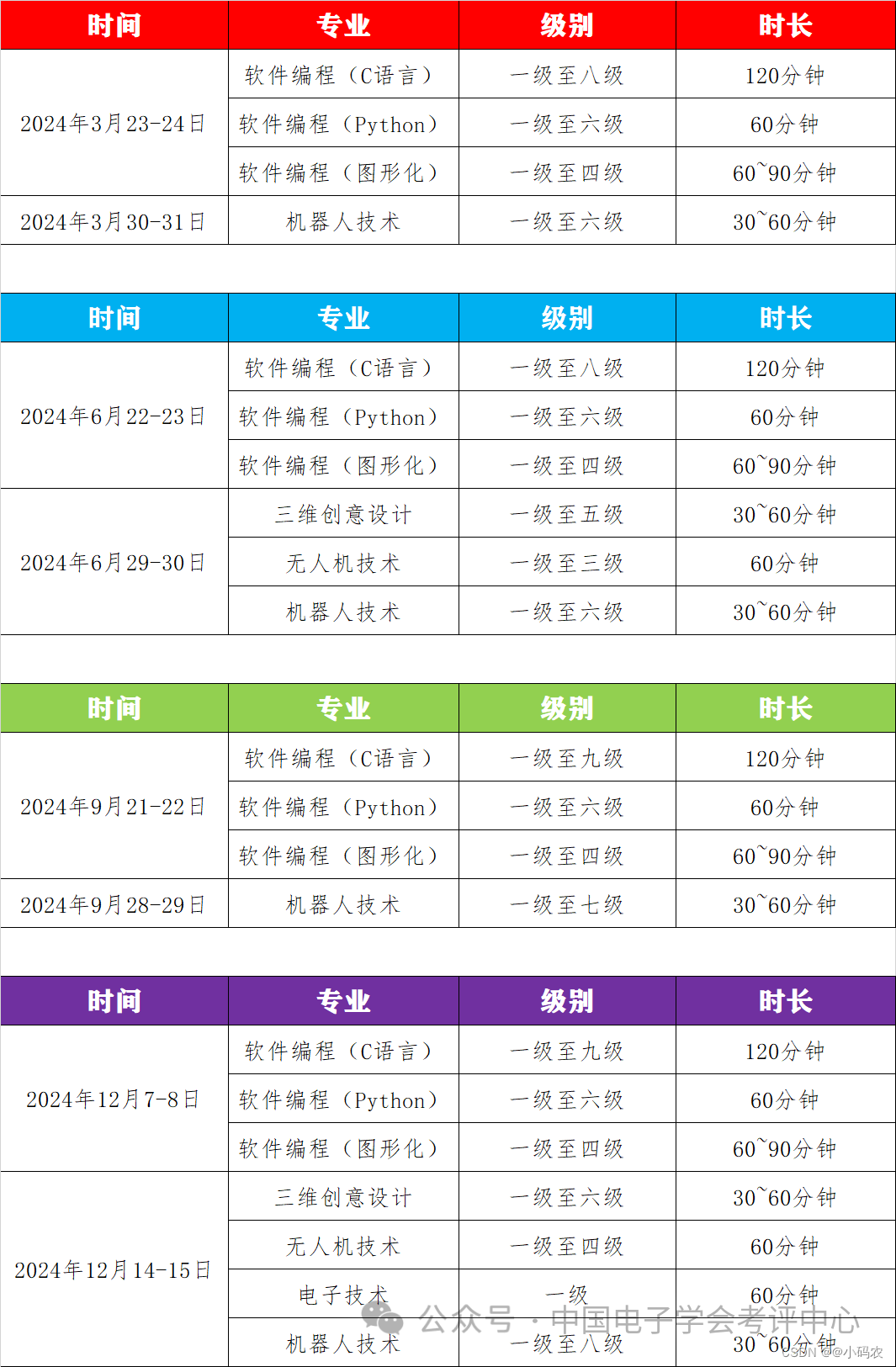
2024年中国电子学会青少年编程等级考试安排的通知
各有关单位、全体考生: 中国电子学会青少年等级考试(以下简称等级考试)是中国电子学会为落实《全民科学素质行动规划纲要》,提升青少年电子信息科学素质水平而开展的社会化评价项目。等级考试自2011年启动以来,作为中国电子学会科…...
 质量刚体的在坐标系下运动)
[足式机器人]Part3 机构运动学与动力学分析与建模 Ch00-2(2) 质量刚体的在坐标系下运动
本文仅供学习使用,总结很多本现有讲述运动学或动力学书籍后的总结,从矢量的角度进行分析,方法比较传统,但更易理解,并且现有的看似抽象方法,两者本质上并无不同。 2024年底本人学位论文发表后方可摘抄 若有…...
【亚马逊云科技】自家的AI助手 - Amazon Q
写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成…...
网络安全—SSL安全访问应用
文章目录 网络拓扑部署CA服务器颁发证书开启Web服务安装IIS服务修改Web默认网页 申请Web证书前提准备申请文件生成申请web证书开始安装web证书 客户机访问web默认网站使用HTTP使用HTTPS 为客户机安装浏览器证书 环境:Windows Server 2003 网络拓扑 这里使用NAT还是…...

Qt5.14.2实现将html文件转换为pdf文件
文章目录 简介源码widget.cppwidget.uihtml文件演示效果简介 QPdfWriter是Qt框架中用于创建和写入PDF文件的类。它允许您在您的Qt应用程序中动态生成并输出PDF文档,以便进行打印、保存或导出。 QPdfWriter类提供了以下一些常用的函数和方法,可以让您创建和定制PDF文件: 构…...
Minecraft教程:使用MCSM面板搭建我的世界私服并实现远程联机
文章目录 前言1. 安装JAVA2. MCSManager安装3.局域网访问MCSM4.创建我的世界服务器5.局域网联机测试6.安装cpolar内网穿透7. 配置公网访问地址8.远程联机测试9. 配置固定远程联机端口地址9.1 保留一个固定tcp地址9.2 配置固定公网TCP地址9.3 使用固定公网地址远程联机 前言 Li…...
springboot学生成绩管理系统源码和论文
随着信息技术和网络技术的飞速发展,人类已进入全新信息化时代,传统管理技术已无法高效,便捷地管理信息。为了迎合时代需求,优化管理效率,各种各样的管理系统应运而生,各行各业相继进入信息管理时代…...

w20webshell之文件上传
1.什么是文件上传? 将本地文件传输到指定位置。2.什么是webshell 给恶意脚本提供运行环境3.文件上传所需要的条件 a.文件成功上传,未被删除 b.知道文件路径 c.文件所在系统支持脚本运行4.文件上传流程 支持任意文件上传的文件上传 a.恶意文件上传成功 b.…...

【Redis】非关系型数据库之Redis的主从复制、哨兵和集群高可用
目录 一、主从复制、哨兵、集群的区别 二、主从复制 2.1主从复制的作用 2.2主从复制的原理 2.3主从复制的实操 步骤一:环境准备 步骤二:安装Redis以及配置文件修改 Redis的主从配置文件都一样 步骤四:验证主从复制 三、哨兵 3.1哨兵…...
从私有Git仓库的搭建到命令的使用及部署再到分支管理
一、版本控制系统/版本控制器 1. 版本控制系统: git 分布式 —没有中心代码库,所有机器之间的地位同等(每台机器上都有相同的代码) svn 集中管理的 —有中心代码库,其他都是客户端 2.git与svn介绍 1.git属于分布…...
mysql基础-常用函数汇总
目录 1. 查询技巧 2. 时间函数 2.1 now() 2.2 current_date() 2.3 时间差timestampdiff()与datediff() 2.4 其他时间函数 3. 字符函数 3.1 截取函数 3.2 分割函数 3.3 left与right函数 3.4 其他函数 4. 数字函数 5. …...

COCO数据格式的json文件内容
COCO(Common Objects in Context)数据集现在有3种标注类型:object instances(目标实例), object keypoints(目标上的关键点), 和image captions(看图说话),使用JSON文件存储,包含了对图像中目标的边界框、类别标签、分割掩码等信息。 COCO标注文件是一个包含多个字…...

AI-数学-高中-3.二次函数的根的分布问题的解题方法
原作者学习视频:二次】3二次函数根分布问题(中档)_哔哩哔哩_bilibili 一、伟达定理(根与0比较的二次函数) 示例: 二、画图法: 1.开口方向的确定,有的示例可能存在向上、下两种情况…...

golang中gorm使用
前言 记录下go语言操作mysql数据库,选用gorm,gorm是一个流行的对象关系映射(ORM)库,用于简化与数据库的交互。 接入步骤 安装gorm:首先,你需要使用Go模块来安装gorm。在终端中运行以下命令&…...

centoss7安装mysql详细教程
【MySQL系列】在Centos7环境安装MySQL_centos7安装mysql-CSDN博客 【MySQL系列】在Centos7环境安装MySQL_centos7安装mysql-CSDN博客 【MySQL系列】在Centos7环境安装MySQL_centos7安装mysql-CSDN博客...

SpringBoot-拓展
邮件 依赖 <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-mail</artifactId>配置 spring.mail.username邮箱 spring.mail.password授权码 spring.mail.hostsmtp.qq.com # 开启加密验证 spring.mail.properties.mai…...
用于查询性能预测的计划结构深度神经网络模型--大数据计算基础大作业
用于查询性能预测的计划结构深度神经网络模型 论文阅读和复现 24.【X1.1】 在关系数据库查询优化领域,对查询时间的估计准确性直接决定了查询优化结果,进而影响到数据库整体的查询效率。但由于数据库自身的复杂性,查询时间受到数据分布、数据…...

AI智能体密钥安全管理:AgentVault架构解析与实战指南
1. 项目概述:一个为AI智能体打造的“保险箱”最近在折腾AI智能体(Agent)应用开发的朋友,估计都绕不开一个核心痛点:如何安全、可靠地管理智能体运行过程中需要用到的各种密钥、凭证和敏感数据?无论是调用Op…...

JVM调优实战:让你的服务性能提升50%
一、背景 线上一个核心订单服务,QPS 3000左右,经常出现接口超时告警。监控显示: 平均RT: 180ms(要求<100ms)Full GC频率: 每天20次,每次STW 1.5sCPU使用率: 峰值85%服务规格: 8C16G,堆内存…...

纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书
纯视觉纵深无感管控,落地硐室无人少人化透明值守模式技术白皮书副标题:摒弃井下繁杂传感布设,依靠暗光三维实景重构、深部空间无感感知、盲区跨镜无痕跟踪、身体指纹生物核验,实现井下 24 小时无人值守、全域透明运维前言矿山井下…...

终极指南:如何为PotPlayer配置百度翻译插件实现实时字幕翻译
终极指南:如何为PotPlayer配置百度翻译插件实现实时字幕翻译 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu PotPlayer_Sub…...

从开源AI导师项目GURU-Ai拆解:如何构建具备教学能力的智能体
1. 项目概述:一个“AI导师”的诞生与定位最近在GitHub上看到一个挺有意思的项目,叫“Guru322/GURU-Ai”。光看名字,你可能会觉得这又是一个平平无奇的AI工具仓库。但点进去细看,你会发现它的野心不小——它想做的不是又一个聊天机…...

Windows上运行Swift代码的三种实战路径
1. 为什么Windows开发者需要Swift? Swift作为苹果生态的主力编程语言,近年来在服务端开发、机器学习等领域的应用越来越广泛。但很多刚接触Swift的Windows开发者会发现:官方文档里压根没提Windows支持!这其实是因为Swift最初就是…...

结构化数字工作空间:提升创意工作效率的目录设计与自动化实践
1. 项目概述:一个为创意工作者量身定制的数字工作空间 如果你是一名设计师、开发者、内容创作者,或者任何需要处理大量数字资产、管理复杂项目流程的创意工作者,那么“Workspace-di-Yivo”这个名字可能会让你眼前一亮。这不仅仅是一个简单的文…...
)
用STM32+LoRa+阿里云IoT Studio,我DIY了一个低成本畜牧电子围栏(附完整代码)
基于STM32与LoRa的智能畜牧围栏系统开发实战 在广袤的牧区,牲畜走失一直是困扰牧民的核心问题。传统物理围栏不仅成本高昂,在草原这类开放地形中实施难度也很大。本文将详细介绍如何利用STM32微控制器、LoRa远距离通信模块和阿里云IoT Studio平台&#x…...

基于Electron的ChatGPT桌面客户端开发:架构、功能与进阶实践
1. 项目概述:一个开源桌面客户端的诞生与价值如果你和我一样,在日常开发、写作或者处理一些需要深度思考的任务时,经常需要和ChatGPT这样的AI助手对话,那你一定对在浏览器里反复切换标签页、刷新页面、管理冗长的对话历史感到厌烦…...

SuperDuper框架:AI应用开发的组件化与数据库原生集成实践
1. 项目概述:一个颠覆传统AI应用构建的“超级”框架如果你正在为构建一个集成了多种AI模型、数据库和前后端逻辑的复杂应用而感到头疼,那么superduper-io/superduper这个项目,很可能就是你一直在寻找的“瑞士军刀”。简单来说,它不…...