Hive之set参数大全-2
C
指定是否启用表达式缓存的评估
hive.cache.expr.evaluation 是 Hive 中的一个配置属性,用于指定是否启用表达式缓存的评估。表达式缓存是一项优化技术,它可以在执行查询时缓存表达式的评估结果,以减少计算开销。
在 Hive 配置中,可以使用以下方式设置 hive.cache.expr.evaluation:
-- 启用或禁用表达式缓存的评估
SET hive.cache.expr.evaluation=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cache.expr.evaluation</name><value>true</value>
</property>
上述配置中,hive.cache.expr.evaluation 的值为 true,表示启用表达式缓存的评估。
当启用时,Hive 将尝试缓存表达式的评估结果,以便在相同的表达式再次出现时能够直接使用缓存的结果,而不必重新计算。这有助于提高查询的性能,尤其是对于包含重复表达式的查询。
如果设置为 false,则禁用表达式缓存的评估。
根据实际查询的特性和性能需求,可以调整这个配置项。在某些情况下,启用表达式缓存可以带来性能提升,但在其他情况下可能会导致不必要的内存消耗。
指定 Cost-Based Optimizer(CBO)使用的布尔表达式的最大节点数
hive.cbo.cnf.maxnodes 是 Hive 中的一个配置属性,用于指定 Cost-Based Optimizer(CBO)使用的布尔表达式的最大节点数。CBO 是一个优化器,它使用成本模型来选择执行计划,以提高查询性能。
在 Hive 配置中,可以使用以下方式设置 hive.cbo.cnf.maxnodes:
-- 设置 CBO 使用的布尔表达式的最大节点数
SET hive.cbo.cnf.maxnodes=10000;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cbo.cnf.maxnodes</name><value>10000</value>
</property>
上述配置中,hive.cbo.cnf.maxnodes 的值为 10000,表示 CBO 使用的布尔表达式的最大节点数为 10000。
这个配置项用于限制 CBO 在考虑布尔表达式时所允许的最大节点数。在某些情况下,如果布尔表达式非常复杂,设置此配置项可以避免 CBO 消耗过多的计算资源和时间。
根据实际查询的特性和性能需求,可以调整这个配置项。在大多数情况下,使用默认值即可,但根据查询的复杂性可能需要调整这个限制。
指定 Cost-Based Optimizer(CBO)使用的 CPU 成本模型的开关
hive.cbo.costmodel.cpu 是 Hive 中的一个配置属性,用于指定 Cost-Based Optimizer(CBO)使用的 CPU 成本模型的开关。CBO 是一个优化器,它使用成本模型来选择执行计划,以提高查询性能。
在 Hive 配置中,可以使用以下方式设置 hive.cbo.costmodel.cpu:
-- 启用或禁用 CBO 使用的 CPU 成本模型
SET hive.cbo.costmodel.cpu=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cbo.costmodel.cpu</name><value>true</value>
</property>
上述配置中,hive.cbo.costmodel.cpu 的值为 true,表示启用 CBO 使用的 CPU 成本模型。
这个配置项用于控制是否启用 CBO 使用的 CPU 成本模型,该模型考虑查询中每个操作的 CPU 成本。CPU 成本模型是 CBO 中的一个关键组成部分,有助于选择执行计划以最小化总体执行成本。
如果设置为 false,则禁用 CBO 使用的 CPU 成本模型,系统将使用其他成本模型。在某些情况下,禁用 CPU 成本模型可能是为了降低优化的复杂性,特别是对于一些简单的查询。
根据实际查询的特性和性能需求,可以调整这个配置项。默认情况下,大多数系统会启用 CPU 成本模型,因为它可以提供更精细的优化。
指定是否启用 Cost-Based Optimizer(CBO)的扩展成本模型
hive.cbo.costmodel.extended 是 Hive 中的一个配置属性,用于指定是否启用 Cost-Based Optimizer(CBO)的扩展成本模型。CBO 是一个优化器,它使用成本模型来选择执行计划,以提高查询性能。
在 Hive 配置中,可以使用以下方式设置 hive.cbo.costmodel.extended:
-- 启用或禁用 CBO 的扩展成本模型
SET hive.cbo.costmodel.extended=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cbo.costmodel.extended</name><value>true</value>
</property>
上述配置中,hive.cbo.costmodel.extended 的值为 true,表示启用 CBO 的扩展成本模型。
这个配置项用于控制是否启用 CBO 的扩展成本模型。扩展成本模型考虑了更多的执行计划细节,包括更多的操作和因素,以更准确地估计查询执行的成本。启用扩展成本模型可能会导致更精细的优化,但也可能增加计算开销。
如果设置为 false,则禁用 CBO 的扩展成本模型,系统将使用较简化的成本模型。在一些场景中,禁用扩展成本模型可能是为了降低优化的复杂性,特别是对于一些简单的查询。
根据实际查询的特性和性能需求,可以调整这个配置项。默认情况下,大多数系统会启用扩展成本模型,因为它可以提供更精细的查询优化。
指定是否启用 Cost-Based Optimizer(CBO)中关于 HDFS 读操作成本的计算模型
hive.cbo.costmodel.hdfs.read 是 Hive 中的一个配置属性,用于指定是否启用 Cost-Based Optimizer(CBO)中关于 HDFS 读操作成本的计算模型。CBO 是一个优化器,它使用成本模型来选择执行计划,以提高查询性能。
在 Hive 配置中,可以使用以下方式设置 hive.cbo.costmodel.hdfs.read:
-- 启用或禁用 CBO 使用的 HDFS 读操作成本计算模型
SET hive.cbo.costmodel.hdfs.read=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cbo.costmodel.hdfs.read</name><value>true</value>
</property>
上述配置中,hive.cbo.costmodel.hdfs.read 的值为 true,表示启用 CBO 使用的 HDFS 读操作成本计算模型。
这个配置项用于控制是否启用 CBO 使用的 HDFS 读操作成本计算模型。启用这个模型可以帮助 CBO 更准确地估计涉及 HDFS 读取的查询的成本,以便更好地选择执行计划。
如果设置为 false,则禁用 CBO 使用的 HDFS 读操作成本计算模型,系统将使用其他成本模型。在一些场景中,禁用这个模型可能是为了简化优化过程,特别是对于一些不涉及 HDFS 读取的查询。
根据实际查询的特性和性能需求,可以调整这个配置项。默认情况下,大多数系统会启用 HDFS 读操作成本计算模型,以提高查询优化的准确性。
指定是否启用 Cost-Based Optimizer(CBO)中关于 HDFS 写操作成本的计算模型
hive.cbo.costmodel.hdfs.write 是 Hive 中的一个配置属性,用于指定是否启用 Cost-Based Optimizer(CBO)中关于 HDFS 写操作成本的计算模型。CBO 是一个优化器,它使用成本模型来选择执行计划,以提高查询性能。
在 Hive 配置中,可以使用以下方式设置 hive.cbo.costmodel.hdfs.write:
-- 启用或禁用 CBO 使用的 HDFS 写操作成本计算模型
SET hive.cbo.costmodel.hdfs.write=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cbo.costmodel.hdfs.write</name><value>true</value>
</property>
上述配置中,hive.cbo.costmodel.hdfs.write 的值为 true,表示启用 CBO 使用的 HDFS 写操作成本计算模型。
这个配置项用于控制是否启用 CBO 使用的 HDFS 写操作成本计算模型。启用这个模型可以帮助 CBO 更准确地估计涉及 HDFS 写入的查询的成本,以便更好地选择执行计划。
如果设置为 false,则禁用 CBO 使用的 HDFS 写操作成本计算模型,系统将使用其他成本模型。在一些场景中,禁用这个模型可能是为了简化优化过程,特别是对于一些不涉及 HDFS 写入的查询。
根据实际查询的特性和性能需求,可以调整这个配置项。默认情况下,大多数系统会启用 HDFS 写操作成本计算模型,以提高查询优化的准确性。
指定是否启用 Cost-Based Optimizer(CBO)中关于本地文件系统(Local FS)读操作成本的计算模型
hive.cbo.costmodel.local.fs.read 是 Hive 中的一个配置属性,用于指定是否启用 Cost-Based Optimizer(CBO)中关于本地文件系统(Local FS)读操作成本的计算模型。CBO 是一个优化器,它使用成本模型来选择执行计划,以提高查询性能。
在 Hive 配置中,可以使用以下方式设置 hive.cbo.costmodel.local.fs.read:
-- 启用或禁用 CBO 使用的本地文件系统读操作成本计算模型
SET hive.cbo.costmodel.local.fs.read=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cbo.costmodel.local.fs.read</name><value>true</value>
</property>
上述配置中,hive.cbo.costmodel.local.fs.read 的值为 true,表示启用 CBO 使用的本地文件系统读操作成本计算模型。
这个配置项用于控制是否启用 CBO 使用的本地文件系统读操作成本计算模型。启用这个模型可以帮助 CBO 更准确地估计涉及本地文件系统读取的查询的成本,以便更好地选择执行计划。
如果设置为 false,则禁用 CBO 使用的本地文件系统读操作成本计算模型,系统将使用其他成本模型。在一些场景中,禁用这个模型可能是为了简化优化过程,特别是对于一些不涉及本地文件系统读取的查询。
根据实际查询的特性和性能需求,可以调整这个配置项。默认情况下,大多数系统会启用本地文件系统读操作成本计算模型,以提高查询优化的准确性。
指定是否启用 Cost-Based Optimizer(CBO)中关于本地文件系统(Local FS)写操作成本的计算模型
hive.cbo.costmodel.local.fs.write 是 Hive 中的一个配置属性,用于指定是否启用 Cost-Based Optimizer(CBO)中关于本地文件系统(Local FS)写操作成本的计算模型。CBO 是一个优化器,它使用成本模型来选择执行计划,以提高查询性能。
在 Hive 配置中,可以使用以下方式设置 hive.cbo.costmodel.local.fs.write:
-- 启用或禁用 CBO 使用的本地文件系统写操作成本计算模型
SET hive.cbo.costmodel.local.fs.write=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cbo.costmodel.local.fs.write</name><value>true</value>
</property>
上述配置中,hive.cbo.costmodel.local.fs.write 的值为 true,表示启用 CBO 使用的本地文件系统写操作成本计算模型。
这个配置项用于控制是否启用 CBO 使用的本地文件系统写操作成本计算模型。启用这个模型可以帮助 CBO 更准确地估计涉及本地文件系统写入的查询的成本,以便更好地选择执行计划。
如果设置为 false,则禁用 CBO 使用的本地文件系统写操作成本计算模型,系统将使用其他成本模型。在一些场景中,禁用这个模型可能是为了简化优化过程,特别是对于一些不涉及本地文件系统写入的查询。
根据实际查询的特性和性能需求,可以调整这个配置项。默认情况下,大多数系统会启用本地文件系统写操作成本计算模型,以提高查询优化的准确性。
指定是否启用 Cost-Based Optimizer(CBO)中关于网络传输成本的计算模型
hive.cbo.costmodel.network 是 Hive 中的一个配置属性,用于指定是否启用 Cost-Based Optimizer(CBO)中关于网络传输成本的计算模型。CBO 是一个优化器,它使用成本模型来选择执行计划,以提高查询性能。
在 Hive 配置中,可以使用以下方式设置 hive.cbo.costmodel.network:
-- 启用或禁用 CBO 使用的网络传输成本计算模型
SET hive.cbo.costmodel.network=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cbo.costmodel.network</name><value>true</value>
</property>
上述配置中,hive.cbo.costmodel.network 的值为 true,表示启用 CBO 使用的网络传输成本计算模型。
这个配置项用于控制是否启用 CBO 使用的网络传输成本计算模型。启用这个模型可以帮助 CBO 更准确地估计涉及数据在网络上传输的查询的成本,以便更好地选择执行计划。
如果设置为 false,则禁用 CBO 使用的网络传输成本计算模型,系统将使用其他成本模型。在一些场景中,禁用这个模型可能是为了简化优化过程,特别是对于一些不涉及网络传输的查询。
根据实际查询的特性和性能需求,可以调整这个配置项。默认情况下,大多数系统会启用网络传输成本计算模型,以提高查询优化的准确性。
启用或禁用 Cost-Based Optimizer(CBO)
hive.cbo.enable 是 Hive 中的一个配置属性,用于启用或禁用 Cost-Based Optimizer(CBO)。CBO 是一个优化器,它使用成本模型来选择执行计划,以提高查询性能。
在 Hive 配置中,可以使用以下方式设置 hive.cbo.enable:
-- 启用或禁用 Cost-Based Optimizer
SET hive.cbo.enable=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cbo.enable</name><value>true</value>
</property>
上述配置中,hive.cbo.enable 的值为 true,表示启用 Cost-Based Optimizer。
启用 CBO 可以使 Hive 更智能地选择查询执行计划,以提高性能。CBO 使用统计信息和成本模型来估算执行计划的代价,并选择最佳的执行计划。在一些复杂查询的情况下,CBO 可以明显提升性能。
如果设置为 false,则禁用 CBO,系统将使用基于规则的优化器(Rule-Based Optimizer)。规则优化器使用一系列硬编码的规则来生成执行计划,而不考虑统计信息和成本模型。
根据实际查询的特性和性能需求,可以灵活调整这个配置项。在某些情况下,禁用 CBO 可能是为了简化优化过程或解决特定问题。
指定在 Cost-Based Optimizer(CBO)执行期间是否返回原始的 Hive 操作
hive.cbo.returnpath.hiveop 是 Hive 中的一个配置属性,用于指定在 Cost-Based Optimizer(CBO)执行期间是否返回原始的 Hive 操作。CBO 是一个优化器,它使用成本模型来选择执行计划,以提高查询性能。
在 Hive 配置中,可以使用以下方式设置 hive.cbo.returnpath.hiveop:
-- 设置在 CBO 执行期间是否返回原始的 Hive 操作
SET hive.cbo.returnpath.hiveop=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cbo.returnpath.hiveop</name><value>true</value>
</property>
上述配置中,hive.cbo.returnpath.hiveop 的值为 true,表示在 CBO 执行期间返回原始的 Hive 操作。
这个配置项用于控制是否在 CBO 执行期间返回原始的 Hive 操作。如果设置为 true,CBO 将返回原始的 Hive 操作,而不应用任何优化。这可以用于调试和分析查询执行计划。
如果设置为 false,则 CBO 将应用优化并返回优化后的执行计划。
根据实际调试和分析的需要,可以调整这个配置项。默认情况下,大多数系统会将其设置为 false,以便 CBO 应用优化并返回优化后的执行计划。
指定是否在查询执行期间显示 Cost-Based Optimizer(CBO)的警告信息
hive.cbo.show.warnings 是 Hive 中的一个配置属性,用于指定是否在查询执行期间显示 Cost-Based Optimizer(CBO)的警告信息。CBO 是一个优化器,它使用成本模型来选择执行计划,以提高查询性能。
在 Hive 配置中,可以使用以下方式设置 hive.cbo.show.warnings:
-- 设置是否在查询执行期间显示 CBO 的警告信息
SET hive.cbo.show.warnings=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cbo.show.warnings</name><value>true</value>
</property>
上述配置中,hive.cbo.show.warnings 的值为 true,表示在查询执行期间显示 CBO 的警告信息。
这个配置项用于控制是否在查询执行期间显示 CBO 生成的警告信息。警告信息通常包含有关查询、表、或者统计信息的一些问题或限制的信息。通过显示这些警告,可以帮助用户了解到潜在的优化问题或者不足之处。
如果设置为 false,则在查询执行期间将不显示 CBO 生成的警告信息。
根据实际调试和分析的需要,可以调整这个配置项。默认情况下,大多数系统会将其设置为 true,以便在查询执行期间显示 CBO 的警告信息。
指定是否忽略 Hive CLI(Command Line Interface)中的错误
hive.cli.errors.ignore 是 Hive 中的一个配置属性,用于指定是否忽略 Hive CLI(Command Line Interface)中的错误。Hive CLI 是 Hive 的命令行工具,用于与 Hive 交互式地执行 HiveQL 查询。
在 Hive CLI 中,可以使用以下方式设置 hive.cli.errors.ignore:
-- 设置是否忽略 Hive CLI 中的错误
SET hive.cli.errors.ignore=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cli.errors.ignore</name><value>true</value>
</property>
上述配置中,hive.cli.errors.ignore 的值为 true,表示忽略 Hive CLI 中的错误。
这个配置项用于控制是否在 Hive CLI 中忽略错误。如果设置为 true,Hive CLI 将继续执行脚本或查询,即使在执行过程中发生错误。这对于一些脚本或查询中包含一些可容忍的错误的情况可能是有用的。
如果设置为 false,则在遇到错误时 Hive CLI 将停止执行后续的脚本或查询。
根据实际需求,可以调整这个配置项。默认情况下,大多数系统可能将其设置为 false,以便在遇到错误时停止执行后续的脚本或查询,以便及时发现和处理问题。
指定在 Hive CLI(Command Line Interface)中以美观的格式输出结果时的列数
hive.cli.pretty.output.num.cols 是 Hive 中的一个配置属性,用于指定在 Hive CLI(Command Line Interface)中以美观的格式输出结果时的列数。Hive CLI 是 Hive 的命令行工具,用于与 Hive 交互式地执行 HiveQL 查询。
在 Hive CLI 中,可以使用以下方式设置 hive.cli.pretty.output.num.cols:
-- 设置 Hive CLI 中美观输出结果的列数
SET hive.cli.pretty.output.num.cols=80;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cli.pretty.output.num.cols</name><value>80</value>
</property>
上述配置中,hive.cli.pretty.output.num.cols 的值为 80,表示在 Hive CLI 中美观输出结果时的列数为 80。
这个配置项用于控制在 Hive CLI 中以美观的格式输出查询结果时的列数。通过适当设置列数,可以确保输出结果在终端上以更易读的方式呈现,特别是在宽屏终端上。
根据实际终端的宽度和用户的需求,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
指定在 Hive CLI(Command Line Interface)中是否打印当前数据库(current database)的信息
hive.cli.print.current.db 是 Hive 中的一个配置属性,用于指定在 Hive CLI(Command Line Interface)中是否打印当前数据库(current database)的信息。Hive CLI 是 Hive 的命令行工具,用于与 Hive 交互式地执行 HiveQL 查询。
在 Hive CLI 中,可以使用以下方式设置 hive.cli.print.current.db:
-- 设置是否在 Hive CLI 中打印当前数据库信息
SET hive.cli.print.current.db=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cli.print.current.db</name><value>true</value>
</property>
上述配置中,hive.cli.print.current.db 的值为 true,表示在 Hive CLI 中打印当前数据库信息。
这个配置项用于控制是否在 Hive CLI 提示符前打印当前数据库的信息。当前数据库是 Hive 中的一个概念,它指定了用户当前正在使用的数据库。通过打印当前数据库信息,用户可以清楚地知道当前所在的数据库环境。
如果设置为 false,则在 Hive CLI 中不会打印当前数据库的信息。
根据用户的偏好,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
指定在 Hive CLI(Command Line Interface)中是否对输出中的回车符(Carriage Return,CR)和换行符(Line Feed,LF)进行转义
hive.cli.print.escape.crlf 是 Hive 中的一个配置属性,用于指定在 Hive CLI(Command Line Interface)中是否对输出中的回车符(Carriage Return,CR)和换行符(Line Feed,LF)进行转义。Hive CLI 是 Hive 的命令行工具,用于与 Hive 交互式地执行 HiveQL 查询。
在 Hive CLI 中,可以使用以下方式设置 hive.cli.print.escape.crlf:
-- 设置是否在 Hive CLI 中对输出中的回车符和换行符进行转义
SET hive.cli.print.escape.crlf=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cli.print.escape.crlf</name><value>true</value>
</property>
上述配置中,hive.cli.print.escape.crlf 的值为 true,表示在 Hive CLI 中对输出中的回车符和换行符进行转义。
这个配置项用于控制是否对输出中的回车符和换行符进行转义。如果设置为 true,则输出中的回车符和换行符将被转义为可见的 \r 和 \n 字符。这样可以更清晰地显示包含特殊字符的文本。
如果设置为 false,则输出中的回车符和换行符将保持原样,不进行转义。
根据用户的偏好,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
指定在 Hive CLI(Command Line Interface)中是否打印查询结果的列名(header)
hive.cli.print.header 是 Hive 中的一个配置属性,用于指定在 Hive CLI(Command Line Interface)中是否打印查询结果的列名(header)。Hive CLI 是 Hive 的命令行工具,用于与 Hive 交互式地执行 HiveQL 查询。
在 Hive CLI 中,可以使用以下方式设置 hive.cli.print.header:
-- 设置是否在 Hive CLI 中打印查询结果的列名
SET hive.cli.print.header=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cli.print.header</name><value>true</value>
</property>
上述配置中,hive.cli.print.header 的值为 true,表示在 Hive CLI 中打印查询结果的列名。
这个配置项用于控制是否在查询结果的输出中包含列名。如果设置为 true,则查询结果的第一行将包含列名,方便用户识别每一列的含义。
如果设置为 false,则查询结果的输出中将不包含列名。
根据用户的偏好和需求,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
设置 Hive CLI(Command Line Interface)的提示符
hive.cli.prompt 是 Hive 中的一个配置属性,用于设置 Hive CLI(Command Line Interface)的提示符。Hive CLI 是 Hive 的命令行工具,用于与 Hive 交互式地执行 HiveQL 查询。
在 Hive CLI 中,可以使用以下方式设置 hive.cli.prompt:
-- 设置 Hive CLI 的提示符
SET hive.cli.prompt="custom_prompt> ";
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cli.prompt</name><value>custom_prompt> </value>
</property>
上述配置中,hive.cli.prompt 的值为 "custom_prompt> ",表示设置 Hive CLI 的提示符为 "custom_prompt> "。
这个配置项用于定制 Hive CLI 的提示符,使用户能够更容易地识别当前命令执行的环境。通过设置不同的提示符,用户可以在多个终端中区分不同的 Hive CLI 实例。
根据用户的偏好和需求,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
指定在 Hive CLI(Command Line Interface)中是否使用异步 Tez 会话
hive.cli.tez.session.async 是 Hive 中的一个配置属性,用于指定在 Hive CLI(Command Line Interface)中是否使用异步 Tez 会话。Tez 是一种用于执行大规模数据处理任务的执行引擎,通常与 Hive 一起使用。
在 Hive CLI 中,可以使用以下方式设置 hive.cli.tez.session.async:
-- 设置是否在 Hive CLI 中使用异步 Tez 会话
SET hive.cli.tez.session.async=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.cli.tez.session.async</name><value>true</value>
</property>
上述配置中,hive.cli.tez.session.async 的值为 true,表示在 Hive CLI 中使用异步 Tez 会话。
这个配置项用于控制在 Hive CLI 中 Tez 会话的同步或异步模式。如果设置为 true,则 Tez 会话将以异步模式启动,允许用户在 Tez 任务运行期间执行其他操作。如果设置为 false,则 Tez 会话将以同步模式启动,用户需要等待 Tez 任务完成后才能执行其他操作。
根据用户的偏好和需求,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
指定是否启用合并等效工作优化
hive.combine.equivalent.work.optimization 是 Hive 中的一个配置属性,用于指定是否启用合并等效工作优化。Hive 是一个数据仓库工具,用于处理大规模数据集。这个优化可用于改进查询性能,特别是在涉及多个相似操作的查询中。
在 Hive 中,可以使用以下方式设置 hive.combine.equivalent.work.optimization:
-- 启用或禁用合并等效工作优化
SET hive.combine.equivalent.work.optimization=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.combine.equivalent.work.optimization</name><value>true</value>
</property>
上述配置中,hive.combine.equivalent.work.optimization 的值为 true,表示启用合并等效工作优化。
这个优化旨在通过识别和合并一组等效的操作来减少查询中的工作量。例如,如果一个查询包含多个相似的过滤操作,这个优化可以识别它们并将它们合并成一个更有效的操作。
如果设置为 false,则禁用合并等效工作优化,查询将按原样执行,而不进行等效工作的合并。
根据查询的特性和性能需求,可以灵活调整这个配置项。默认情况下,大多数系统可能会启用这个优化,以提高查询的执行效率。
指定在执行事务整理(Compaction)时允许的中止事务(aborted transactions)的阈值
hive.compactor.abortedtxn.threshold 是 Hive 中的一个配置属性,用于指定在执行事务整理(Compaction)时允许的中止事务(aborted transactions)的阈值。Hive 中的事务整理是一种周期性的操作,用于清理已提交的事务并释放资源。
在 Hive 中,可以使用以下方式设置 hive.compactor.abortedtxn.threshold:
-- 设置事务整理时允许的中止事务的阈值
SET hive.compactor.abortedtxn.threshold=1000;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.compactor.abortedtxn.threshold</name><value>1000</value>
</property>
上述配置中,hive.compactor.abortedtxn.threshold 的值为 1000,表示在事务整理过程中允许的中止事务的阈值为 1000。
这个配置项用于控制在执行事务整理时可以容忍的中止事务的数量。中止事务是已经提交但由于某种原因而未能成功完成的事务。通过设置阈值,可以避免在事务整理期间过多的中止事务,从而提高整理操作的性能。
根据实际情况和性能需求,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
指定事务整理(Compaction)检查的时间间隔
hive.compactor.check.interval 是 Hive 中的一个配置属性,用于指定事务整理(Compaction)检查的时间间隔。事务整理是 Hive 中的一项周期性操作,用于清理已提交的事务并释放资源。
在 Hive 中,可以使用以下方式设置 hive.compactor.check.interval:
-- 设置事务整理检查的时间间隔
SET hive.compactor.check.interval=300; -- 单位是秒,表示每隔300秒检查一次
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.compactor.check.interval</name><value>300</value> <!-- 单位是秒,表示每隔300秒检查一次 -->
</property>
上述配置中,hive.compactor.check.interval 的值为 300 秒,表示每隔300秒检查一次是否需要执行事务整理。
这个配置项用于控制事务整理检查的时间间隔。在每个时间间隔结束时,Hive 将检查是否存在需要整理的表,并在需要时执行事务整理。调整这个时间间隔可以影响事务整理的执行频率。
根据实际情况和性能需求,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
指定事务整理(Compaction)清理程序运行的时间间隔
hive.compactor.cleaner.run.interval 是 Hive 中的一个配置属性,用于指定事务整理(Compaction)清理程序运行的时间间隔。事务整理是 Hive 中的一项周期性操作,用于清理已提交的事务并释放资源。
在 Hive 中,可以使用以下方式设置 hive.compactor.cleaner.run.interval:
-- 设置事务整理清理程序运行的时间间隔
SET hive.compactor.cleaner.run.interval=600; -- 单位是秒,表示每隔600秒运行一次清理程序
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.compactor.cleaner.run.interval</name><value>600</value> <!-- 单位是秒,表示每隔600秒运行一次清理程序 -->
</property>
上述配置中,hive.compactor.cleaner.run.interval 的值为 600 秒,表示每隔600秒运行一次事务整理清理程序。
这个配置项用于控制事务整理清理程序的运行时间间隔。清理程序负责删除已完成的事务整理任务的相关信息和临时文件。通过调整这个时间间隔,可以影响清理程序的执行频率。
根据实际情况和性能需求,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
指定是否只对INSERT操作进行事务整理(Compaction)
hive.compactor.compact.insert.only 是 Hive 中的一个配置属性,用于指定是否只对INSERT操作进行事务整理(Compaction)。事务整理是 Hive 中的一项周期性操作,用于清理已提交的事务并释放资源。
在 Hive 中,可以使用以下方式设置 hive.compactor.compact.insert.only:
-- 设置是否只对INSERT操作进行事务整理
SET hive.compactor.compact.insert.only=true;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.compactor.compact.insert.only</name><value>true</value>
</property>
上述配置中,hive.compactor.compact.insert.only 的值为 true,表示只对INSERT操作进行事务整理。
这个配置项用于控制事务整理是否仅仅对INSERT操作进行整理。如果设置为 true,则只有INSERT操作的事务将被整理。如果设置为 false,则所有类型的操作(包括UPDATE和DELETE等)的事务都将被整理。
根据实际情况和需求,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
指定在执行事务整理(Compaction)时允许的Delta文件的数量阈值
hive.compactor.delta.num.threshold 是 Hive 中的一个配置属性,用于指定在执行事务整理(Compaction)时允许的Delta文件的数量阈值。Hive 中的事务整理是一种周期性的操作,用于清理已提交的事务并释放资源。
在 Hive 中,可以使用以下方式设置 hive.compactor.delta.num.threshold:
-- 设置事务整理时允许的Delta文件的数量阈值
SET hive.compactor.delta.num.threshold=100;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.compactor.delta.num.threshold</name><value>100</value>
</property>x
上述配置中,hive.compactor.delta.num.threshold 的值为 100,表示在事务整理过程中允许的Delta文件的数量阈值为100。
这个配置项用于控制在执行事务整理时可以容忍的Delta文件的数量。Delta文件是用于存储增量变更的文件,事务整理通过合并和清理这些Delta文件来减少表的存储空间。调整这个阈值可以影响事务整理的执行行为。
根据实际情况和性能需求,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
指定在执行事务整理(Compaction)时允许的Delta文件占比的阈值
hive.compactor.delta.pct.threshold 是 Hive 中的一个配置属性,用于指定在执行事务整理(Compaction)时允许的Delta文件占比的阈值。Hive 中的事务整理是一种周期性的操作,用于清理已提交的事务并释放资源。
在 Hive 中,可以使用以下方式设置 hive.compactor.delta.pct.threshold:
-- 设置事务整理时允许的Delta文件占比的阈值
SET hive.compactor.delta.pct.threshold=20;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.compactor.delta.pct.threshold</name><value>20</value>
</property>
上述配置中,hive.compactor.delta.pct.threshold 的值为 20,表示在事务整理过程中允许的Delta文件占比的阈值为20%。
这个配置项用于控制在执行事务整理时可以容忍的Delta文件占比。Delta文件是用于存储增量变更的文件,事务整理通过合并和清理这些Delta文件来减少表的存储空间。调整这个阈值可以影响事务整理的执行行为。
根据实际情况和性能需求,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
指定事务整理(Compaction)历史记录清理程序运行的时间间隔
hive.compactor.history.reaper.interval 是 Hive 中的一个配置属性,用于指定事务整理(Compaction)历史记录清理程序运行的时间间隔。事务整理是 Hive 中的一项周期性操作,用于清理已提交的事务并释放资源。
在 Hive 中,可以使用以下方式设置 hive.compactor.history.reaper.interval:
-- 设置事务整理历史记录清理程序运行的时间间隔
SET hive.compactor.history.reaper.interval=86400; -- 单位是秒,表示每隔86400秒运行一次清理程序
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.compactor.history.reaper.interval</name><value>86400</value> <!-- 单位是秒,表示每隔86400秒运行一次清理程序 -->
</property>
上述配置中,hive.compactor.history.reaper.interval 的值为 86400 秒,表示每隔86400秒运行一次事务整理历史记录清理程序。
这个配置项用于控制事务整理历史记录清理程序的运行时间间隔。清理程序负责删除已完成的事务整理任务的历史记录。通过调整这个时间间隔,可以影响清理程序的执行频率。
根据实际情况和性能需求,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
指定在清理事务整理(Compaction)历史记录时,要保留的已尝试(attempted)事务整理任务的数量
hive.compactor.history.retention.attempted 是 Hive 中的一个配置属性,用于指定在清理事务整理(Compaction)历史记录时,要保留的已尝试(attempted)事务整理任务的数量。
在 Hive 中,可以使用以下方式设置 hive.compactor.history.retention.attempted:
-- 设置要保留的已尝试事务整理任务的数量
SET hive.compactor.history.retention.attempted=10;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.compactor.history.retention.attempted</name><value>10</value>
</property>
上述配置中,hive.compactor.history.retention.attempted 的值为 10,表示在清理事务整理历史记录时,要保留的已尝试事务整理任务的数量为10。
这个配置项用于控制在清理事务整理历史记录时,保留的已尝试事务整理任务的数量。事务整理历史记录包含已完成、已中止等各种状态的任务。通过设置这个值,可以限制保留的历史任务数量,防止历史记录过度增长。
根据实际情况和性能需求,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
指定在清理事务整理(Compaction)历史记录时,要保留的失败的事务整理任务的数量
hive.compactor.history.retention.failed 是 Hive 中的一个配置属性,用于指定在清理事务整理(Compaction)历史记录时,要保留的失败的事务整理任务的数量。
在 Hive 中,可以使用以下方式设置 hive.compactor.history.retention.failed:
-- 设置要保留的失败的事务整理任务的数量
SET hive.compactor.history.retention.failed=5;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.compactor.history.retention.failed</name><value>5</value>
</property>
上述配置中,hive.compactor.history.retention.failed 的值为 5,表示在清理事务整理历史记录时,要保留的失败的事务整理任务的数量为5。
这个配置项用于控制在清理事务整理历史记录时,保留的失败的历史任务的数量。事务整理历史记录包含已完成、已中止、已失败等各种状态的任务。通过设置这个值,可以限制保留的历史任务数量,防止历史记录过度增长。
根据实际情况和性能需求,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
指定在清理事务整理(Compaction)历史记录时,要保留的成功的事务整理任务的数量
hive.compactor.history.retention.succeeded 是 Hive 中的一个配置属性,用于指定在清理事务整理(Compaction)历史记录时,要保留的成功的事务整理任务的数量。
在 Hive 中,可以使用以下方式设置 hive.compactor.history.retention.succeeded:
-- 设置要保留的成功的事务整理任务的数量
SET hive.compactor.history.retention.succeeded=5;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.compactor.history.retention.succeeded</name><value>5</value>
</property>
上述配置中,hive.compactor.history.retention.succeeded 的值为 5,表示在清理事务整理历史记录时,要保留的成功的事务整理任务的数量为5。
这个配置项用于控制在清理事务整理历史记录时,保留的成功的历史任务的数量。事务整理历史记录包含已完成、已中止、已失败等各种状态的任务。通过设置这个值,可以限制保留的历史任务数量,防止历史记录过度增长。
根据实际情况和性能需求,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
指定在事务整理(Compaction)初始化器中允许的失败的整理任务数量的阈值
hive.compactor.initiator.failed.compacts.threshold 是 Hive 中的一个配置属性,用于指定在事务整理(Compaction)初始化器中允许的失败的整理任务数量的阈值。事务整理是 Hive 中的一项周期性操作,用于清理已提交的事务并释放资源。
在 Hive 中,可以使用以下方式设置 hive.compactor.initiator.failed.compacts.threshold:
-- 设置事务整理初始化器中允许的失败的整理任务数量的阈值
SET hive.compactor.initiator.failed.compacts.threshold=3;
或者在 Hive 的配置文件(如 hive-site.xml)中添加:
<property><name>hive.compactor.initiator.failed.compacts.threshold</name><value>3</value>
</property>
上述配置中,hive.compactor.initiator.failed.compacts.threshold 的值为 3,表示在事务整理初始化器中允许的失败的整理任务数量的阈值为3。
这个配置项用于控制在事务整理初始化器中可以容忍的失败的整理任务的数量。如果初始化器中失败的整理任务数量达到或超过指定的阈值,可能会触发进一步的处理,例如记录日志、报警等。
根据实际情况和性能需求,可以调整这个配置项。默认情况下,可能会有一个合理的默认值,但用户可以根据需要进行调整。
控制 Hive 表的紧缩(compaction)操作的触发方式
hive.compactor.initiator.on 是 Hive 中一个配置参数,用于控制 Hive 表的紧缩(compaction)操作的触发方式。紧缩操作是为了优化表的存储,合并小文件,提高查询性能。
具体而言,这个参数的取值可以是 metastore 或 query,表示触发紧缩的方式:
- metastore: 当设置为
metastore时,紧缩操作是通过 Hive 的元数据存储(Metastore)触发的。这通常是在表的元数据发生变化时,比如增加或删除分区、修改表属性等情况下触发紧缩。 - query: 当设置为
query时,紧缩操作是在执行查询时触发的。具体来说,当查询需要读取表的数据时,会检查表的文件大小,如果文件大小超过一定阈值,会触发紧缩以合并小文件。
一般来说,选择何种方式取决于具体的使用场景和需求。如果表的元数据变化较频繁,可以选择 metastore 触发方式。如果更关注查询性能,可以选择 query 触发方式,确保在查询执行时自动进行紧缩。
示例:
-- 设置为 metastore 触发方式
SET hive.compactor.initiator.on=metastore;-- 设置为 query 触发方式
SET hive.compactor.initiator.on=query;
请注意,具体的配置参数和其行为可能会根据 Hive 版本的不同而有所变化,因此建议查阅相应版本的官方文档以获取准确的信息。
控制表的紧缩(compaction)过程中,可以合并的最大增量文件(delta file)的数量
在 Hive 中,hive.compactor.max.num.delta 是一个配置参数,用于控制表的紧缩(compaction)过程中,可以合并的最大增量文件(delta file)的数量。紧缩操作旨在合并小文件,提高查询性能,而增量文件是由于表的更新、插入等操作而产生的。
具体来说,hive.compactor.max.num.delta 参数的作用是限制紧缩过程中可以合并的增量文件的数量,防止在单次紧缩操作中合并过多的文件,可能导致性能问题。
默认情况下,Hive 会在紧缩过程中选择合并的增量文件数量,但是通过设置 hive.compactor.max.num.delta,你可以限制这个数量。
示例:
-- 设置 hive.compactor.max.num.delta 为 10
SET hive.compactor.max.num.delta=10;
这个参数的具体值需要根据你的数据量、查询模式等因素进行调整。如果表的增量文件数量较大,可能需要调整这个参数,以控制合并的文件数量,从而在保证查询性能的同时避免合并过多的文件导致的性能问题。
指定在执行表紧缩(compaction)操作时,可以使用的工作线程(worker threads)的数量
hive.compactor.worker.threads 是 Hive 中一个配置参数,用于指定在执行表紧缩(compaction)操作时,可以使用的工作线程(worker threads)的数量。紧缩操作旨在合并小文件,提高查询性能。
具体来说,hive.compactor.worker.threads 参数控制紧缩操作的并行度,即同时处理多个分区或文件的能力。通过设置合适的线程数量,可以加速紧缩操作的执行速度,尤其是当表的数据量较大时。
示例:
-- 设置 hive.compactor.worker.threads 为 4
SET hive.compactor.worker.threads=4;
在设置这个参数时,需要根据你的集群配置、硬件性能和具体的紧缩需求来进行调整。增加线程数量可以提高并行处理能力,但同时也会增加系统资源的占用,因此需要权衡。
请注意,具体的最佳线程数取决于你的环境,建议在实际生产环境中进行一些性能测试,以找到最适合你的情况的配置。
指定在执行表紧缩(compaction)操作时,工作线程(worker threads)的超时时间
hive.compactor.worker.timeout 是 Hive 中一个配置参数,用于指定在执行表紧缩(compaction)操作时,工作线程(worker threads)的超时时间。紧缩操作旨在合并小文件,提高查询性能。
具体来说,hive.compactor.worker.timeout 参数控制每个工作线程执行紧缩操作的最大时间限制。如果一个工作线程在指定的超时时间内无法完成紧缩操作,系统可能会中断该线程,并尝试处理其他任务。这有助于防止由于某些异常情况导致的紧缩操作过长时间的执行。
示例:
-- 设置 hive.compactor.worker.timeout 为 3600 秒(1小时)
SET hive.compactor.worker.timeout=3600;
在设置这个参数时,需要根据你的集群配置、硬件性能和具体的紧缩需求来进行调整。超时时间应该足够长以确保正常情况下能够完成紧缩操作,但又不能太长以防止由于异常情况导致的任务长时间占用资源。
请注意,具体的最佳超时时间取决于你的环境,建议在实际生产环境中进行一些性能测试,以找到最适合你的情况的配置。
指定一些配置属性的列表,这些属性在Hive的输出或者SET命令中将被隐藏,以防止敏感信息泄漏
hive.conf.hidden.list 是 Hive 中的一个配置参数,用于指定一些配置属性的列表,这些属性在Hive的输出或者SET命令中将被隐藏,以防止敏感信息泄漏。
在Hive中,有一些配置属性可能包含敏感信息,例如用户名、密码等。为了保护这些敏感信息,可以将它们添加到 hive.conf.hidden.list 中,以便在输出中对其进行屏蔽。
以下是一个示例:
SET hive.conf.hidden.list="javax.jdo.option.ConnectionPassword,hive.password";
在上述示例中,hive.conf.hidden.list 包含了两个配置属性:javax.jdo.option.ConnectionPassword 和 hive.password。当你执行 SET 命令时,将不会显示这些属性的值。
请注意,hive.conf.hidden.list 是一个逗号分隔的属性列表。你可以根据需要添加其他敏感信息的配置属性。这有助于保护敏感信息,尤其是在共享 Hive 查询结果或输出 Hive 配置时。
指定一些配置属性的列表,这些属性在Hive的输出或者SET命令中将被隐藏,以限制用户访问敏感信息
hive.conf.restricted.list 是 Hive 中的一个配置参数,用于指定一些配置属性的列表,这些属性在Hive的输出或者SET命令中将被隐藏,以限制用户访问敏感信息。
在Hive中,有一些配置属性可能包含敏感信息,例如用户名、密码等。为了增强安全性,可以将它们添加到 hive.conf.restricted.list 中,以便在输出中对其进行屏蔽。
以下是一个示例:
SET hive.conf.restricted.list="javax.jdo.option.ConnectionPassword,hive.password";
在上述示例中,hive.conf.restricted.list 包含了两个配置属性:javax.jdo.option.ConnectionPassword 和 hive.password。当你执行 SET 命令时,将不会显示这些属性的值。
请注意,hive.conf.restricted.list 是一个逗号分隔的属性列表。你可以根据需要添加其他敏感信息的配置属性。这有助于提高安全性,特别是在共享 Hive 查询结果或输出 Hive 配置时。
控制在 Tez 执行引擎下是否启用连接(join)操作的桶映射连接(bucket map join)转换
在 Apache Hive 中,hive.convert.join.bucket.mapjoin.tez 是一个配置参数,用于控制在 Tez 执行引擎下是否启用连接(join)操作的桶映射连接(bucket map join)转换。
Bucket Map Join 是一种通过利用连接操作中连接键的桶(bucket)信息来提高连接性能的机制。该转换可用于 Tez 引擎,这是 Hive 的一种执行引擎。
具体来说,hive.convert.join.bucket.mapjoin.tez 参数的含义如下:
- 如果设置为
true,则启用 Tez 执行引擎下的桶映射连接转换。 - 如果设置为
false,则禁用 Tez 执行引擎下的桶映射连接转换。
示例:
-- 启用 Tez 下的桶映射连接转换
SET hive.convert.join.bucket.mapjoin.tez=true;-- 禁用 Tez 下的桶映射连接转换
SET hive.convert.join.bucket.mapjoin.tez=false;
启用桶映射连接转换有助于提高连接操作的性能,特别是当连接的两个表都使用了桶存储时。然而,对于某些查询或特定的表结构,禁用该转换可能会更合适。这取决于查询的特性、数据分布和硬件配置。
请注意,具体的最佳设置可能取决于你的 Hive 版本和使用情况。建议在生产环境之前进行性能测试,以找到最适合你的场景的配置。
指定在 MapReduce 任务中计数器的组名(counter group name)
在 Apache Hive 中,hive.counters.group.name 是一个配置参数,用于指定在 MapReduce 任务中计数器的组名(counter group name)。计数器用于收集作业执行期间的统计信息,包括任务的完成数、输入记录数、输出记录数等。
通过设置 hive.counters.group.name 参数,你可以指定计数器的组名,以便更好地组织和识别计数器。默认情况下,Hive 使用默认的计数器组名,但你可以通过设置此参数来自定义。
示例:
-- 设置计数器组名为 MyCustomCounters
SET hive.counters.group.name=MyCustomCounters;
在上述示例中,将计数器组名设置为 “MyCustomCounters”。这样,在作业运行期间生成的计数器将被分组到指定的组名下,使得在查看作业统计信息时更容易识别和理解。
请注意,具体的计数器组名的最佳选择取决于你的需求和作业的特性。在设置这个参数时,建议使用能够清晰表达计数器用途的命名,以方便作业监控和调优。
控制是否允许使用 CREATE TABLE AS SELECT 语句创建表时仅插入数据而不创建目标表的模式
hive.create.as.insert.only 是 Apache Hive 中的一个配置参数,用于控制是否允许使用 CREATE TABLE AS SELECT 语句创建表时仅插入数据而不创建目标表的模式。
具体来说,如果设置了 hive.create.as.insert.only 为 true,那么在执行 CREATE TABLE AS SELECT 语句时,将只插入数据而不创建目标表结构。这对于将查询的结果插入到已存在的表中并保留其结构非常有用。
示例:
-- 设置 hive.create.as.insert.only 为 true
SET hive.create.as.insert.only=true;-- 使用 CREATE TABLE AS SELECT 语句插入数据
CREATE TABLE destination_table AS SELECT * FROM source_table;
在上述示例中,CREATE TABLE AS SELECT 语句将从 source_table 中选择的数据插入到 destination_table 中,但不会创建 destination_table 的结构,而是假定 destination_table 已经存在且结构已定义。
请注意,hive.create.as.insert.only 的默认值是 false,即默认情况下 Hive 将创建目标表结构。这个参数的设置对于在特定情况下更改默认行为很有用,但在设置之前,请确保了解其可能的影响,并在测试环境中进行测试。
相关文章:

Hive之set参数大全-2
C 指定是否启用表达式缓存的评估 hive.cache.expr.evaluation 是 Hive 中的一个配置属性,用于指定是否启用表达式缓存的评估。表达式缓存是一项优化技术,它可以在执行查询时缓存表达式的评估结果,以减少计算开销。 在 Hive 配置中…...

C++面试宝典第17题:找规律填数
题目 仔细观察下面的数字序列,找到规律,并填写空白处的数字。 (1)1, 2, 4, 7, 11, 16, __ (2)-1, 2, 7, 28, __, 126 (3)6, 10, 18, 32, 57, __ (4)19, 6, 1, 2, 11, __ (5)2, 3, 5, 7, 11, __ (6)1, 8, 9, 4, __, 1/6 (7)1, 2, 3, 7, 16, __, 321 (8)1, 2, …...

ubuntu查看内存使用情况
在Ubuntu中,你可以使用一些命令来查看内存使用情况。这些命令可以帮助你了解系统的内存使用情况,包括已用内存、空闲内存、缓存和缓冲区的内存等。 1、使用free命令 free命令是一个非常有用的命令,可以快速查看系统的内存使用情况。在终端中…...

ES6 新增 Set、Map 两种数据结构的理解
ES6 新增 Set、Map 两种数据结构的理解 Set 是一种叫做集合的数据结构, 集合是由一堆无序的、相关联的 , 且不重复的内存结构【 数学中称为元素 】组成的组合; Map 是一种叫做字典的数据结构 字典是一些元素的集合 。每个元素有一个称作 key 的域 , 不同…...
影视视频知识付费行业万能通用网站系统源码,三网合一,附带完整的安装部署教程
在数字化时代,知识付费行业逐渐成为主流。人们对高质量内容的需求日益增长,越来越多的人愿意为有价值的知识和信息服务付费。为了满足这一市场需求,罗峰给大家分享一款全新的影视视频知识付费网站系统源码,为用户提供一站式的知识…...

Java字符串拼接常用方法总结
使用场景:用某个分隔符拼接字符串 下边是我使用过的几种方式废话不多说,直接上代码初始数据 1.使用流2.StringBuilder3.[StringJoiner](https://blog.csdn.net/qq_43417581/article/details/126076152?ops_request_misc%257B%2522request%255Fid%2522%2…...

【2023 CSIG垂直领域大模型】大模型时代,如何完成IDP智能文档处理领域的OCR大一统?
目录 一、像素级OCR统一模型:UPOCR1.1、为什么提出UPOCR?1.2、UPOCR是什么?1.2.1、Unified Paradigm 统一范式1.2.2、Unified Architecture统一架构1.2.3、Unified Training Strategy 统一训练策略 1.3、UPOCR效果如何? 二、OCR大一统模型前…...
Phi-2小语言模型QLoRA微调教程
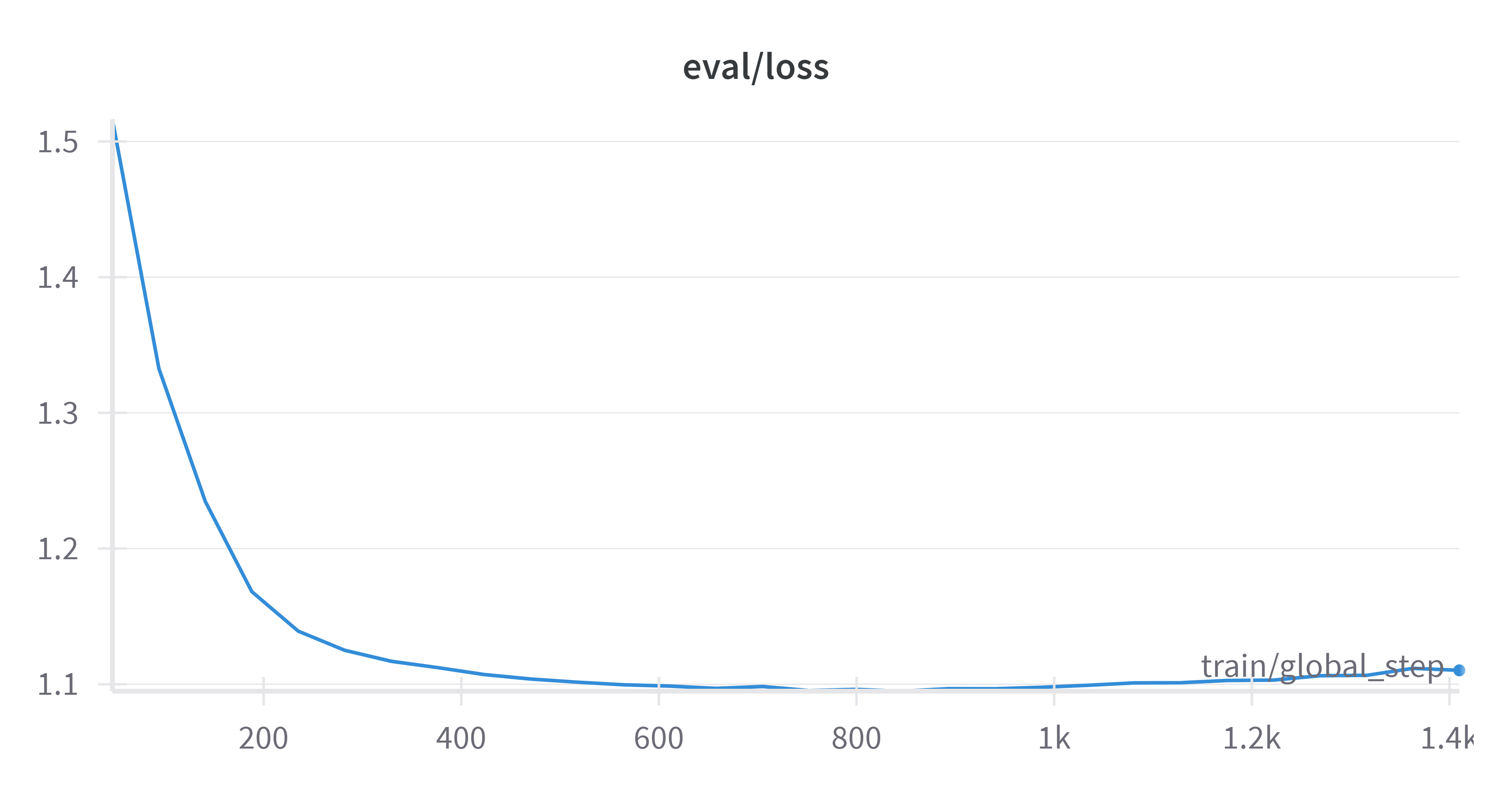
前言 就在不久前,微软正式发布了一个 27 亿参数的语言模型——Phi-2。这是一种文本到文本的人工智能程序,具有出色的推理和语言理解能力。同时,微软研究院也在官方 X 平台上声称:“Phi-2 的性能优于其他现有的小型语言模型&#…...

hadoop自动获取时间
1、自动获取前15分钟 substr(from_unixtime(unix_timestamp(concat(substr(20240107100000,1,4),-,substr(20240107100000,5,2),-,substr(20240107100000,7,2), ,substr(20240107100000,9,2),:,substr(20240107100000,11,2),:,00))-15*60,yyyyMMddHHmmss),1) unix_timestam…...

【面试高频算法解析】算法练习8 单调队列
前言 本专栏旨在通过分类学习算法,使您能够牢固掌握不同算法的理论要点。通过策略性地练习精选的经典题目,帮助您深度理解每种算法,避免出现刷了很多算法题,还是一知半解的状态 专栏导航 二分查找回溯(Backtracking&…...

ATTCK视角下的信息收集:Sysmon检测
目录 1、简介 2、使用Sysmon 3、检测Sysmon是否安装运行 4、检测Sysmon是否被卸载 5、使Sysmon在终端隐匿运行的技术 1、简介 Sysmon(系统监视器)是由windows sysinternals 出品的Sysinternals 系列工具中的一个 它是windows系统服务和设备驱动程…...

02、Kafka ------ 配置 Kafka 集群
目录 配置 Kafka 集群配置步骤启动各Kafka节点 配置 Kafka 集群 启动命令: 1、启动 zookeeper 服务器端 小黑窗输入命令: zkServer 2、启动 zookeeper 的命令行客户端工具 (这个只是用来看连接的节点信息,不启动也没关系&#…...

2024年全球网络安全预测报告
1.Gartner Gartners Top Strategic Predictions for 2024 and Beyond《Gartner顶级战略预测:2024年及未来》 https://www.gartner.com/en/articles/gartner-s-top-strategic-predictions-for-2024-and-beyond 2.IDC Top 10 Worldwide IT Industry 2024 Predict…...

Qt - QML与C++数据交互详解
文章目录 1 . 前言2 . Qml调用C的变量3 . Qml调用C的类4 . Qml调用C的方法5 . Qml接收C的信号6 . C接收Qml的信号(在Qml中定义信号槽)7 . C接收Qml的信号(在C中定义信号槽)8 . C调用Qml的函数9 . 总结 【极客技术传送门】 : https…...
Kettle Local引擎使用记录(一)(基于Kettle web版数据集成开源工具data-integration源码)
Kettle Web 📚第一章 前言📚第二章 demo源码📗pom.xml引入Kettle引擎核心文件📗java源码📕 controller📕 service📕 其它📕 maven settings.xml 📗测试📕 测试…...
Java--业务场景:在Spring项目启动时加载Java枚举类到Redis中(补充)
文章目录 前言步骤测试结果 前言 通过Java–业务场景:在Spring项目启动时加载Java枚举类到Redis中,我们成功将Java项目里的枚举类加载到Redis中了,接下来我们只需要写接口获取需要的枚举值数据就可以了,下面一起来编写这个接口吧。 步骤 在…...

WPF 基础入门(资源字典)
资源字典 每个Resources属性存储着一个资源字典集合。如果希望在多个项目之间共享资源的话,就可以创建一个资源字典。资源字段是一个简单的XAML文档,该文档就是用于存储资源的,可以通过右键项目->添加资源字典的方式来添加一个资源字典文件…...

文章解读与仿真程序复现思路——电网技术EI\CSCD\北大核心《考虑电氢耦合和碳交易的电氢能源系统置信间隙鲁棒规划》
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》 这标题涉及到一个复杂的能源系统规划问题,其中考虑了电氢耦合、碳交易和置信间隙鲁棒规划。以下是对标题各个部分的解读: 电氢耦…...

ubuntu设定时间与外部ntp同步
前言 在 Ubuntu 上,你可以通过配置 systemd-timesyncd 服务来与外部 NTP 服务器同步系统时间。下面是设置的步骤: 安装 NTP 工具: 如果你的系统中没有安装 ntpdate 工具,可以使用以下命令安装: sudo apt-get updat…...

DataFrame详解
清洗相关的API 清洗相关的API: 1.去重API: dropDupilcates 2.删除缺失值API: dropna 3.替换缺失值API: fillna 去重API: dropDupilcates dropDuplicates(subset):删除重复数据 1.用来删除重复数据,如果没有指定参数subset,比对行中所有字段内容,如果全部相同,则认为是重复数据,…...

MVC / MVVM 和 Vue3、React18 到底啥关系?
MVC / MVVM 和 Vue3、React18 到底啥关系? 我用最直白、最贴合你日常写代码的方式讲清楚,保证你瞬间通透。一、先给结论(最重要) Vue3 标准的 MVVM 框架(官方自己定义的)React18 借鉴 MVVM 思想ÿ…...

告别手动调参!模糊PID如何让直流电机在负载突变时稳如泰山?
模糊PID控制:让直流电机在负载突变时稳如泰山的实战指南 引言:工业自动化中的电机控制痛点 在自动化产线上,直流电机突然遭遇负载变化时,你是否也经历过这样的场景?——机械臂正在精准抓取工件,突然因为物料…...
)
Windows下用Rclone挂载WebDAV的完整指南:从安装到开机自启(含常见问题解决)
Windows系统下Rclone挂载WebDAV全流程实战手册 引言:为什么选择Rclone挂载WebDAV? 在日常办公和团队协作中,我们经常需要访问云端存储的文件。WebDAV作为一种基于HTTP协议的文件管理标准,被Nextcloud、OwnCloud等主流网盘广泛支…...

零基础图解VLN视觉语言导航:从输入到决策的完整模型拆解
1. 视觉语言导航(VLN)是什么? 想象你第一次去朋友家做客,对方在电话里说:“进门左转,看到红色沙发后直走,右手边第二个房间就是。”这时候你的大脑会做三件事:用眼睛观察环境&#x…...

B2B品牌战略方法拆解:客户层、业务层、价值层、证据层怎么串起来
一个有点反常识的判断是:真正拉开差距的,常常不是你有多少材料、多少动作、多少名字,而是你能不能先把最关键的判断结构做出来。B2B品牌战略一旦结构对了,后面的内容、渠道和场景才会越做越顺。B2B品牌战略是什么:围绕…...

社交媒体机器人检测的终极对决:TwiBot-22基准测试深度解析
社交媒体机器人检测的终极对决:TwiBot-22基准测试深度解析 【免费下载链接】TwiBot-22 项目地址: https://gitcode.com/gh_mirrors/tw/TwiBot-22 在数字时代,社交媒体上的机器人账号已成为信息传播的重要参与者。它们既能推动正面信息传播&#…...
)
告别手动Dockerfile!io.fabric8插件如何用Maven配置自动生成镜像(附Spring Boot实战)
告别手动Dockerfile!io.fabric8插件如何用Maven配置自动生成镜像(附Spring Boot实战) 在Java生态中,容器化部署已成为现代应用交付的标准方式。传统做法要求开发者同时维护Dockerfile和构建脚本,这种割裂的配置方式不仅…...

OZON跨境电商的供应链之痛:爆单AI选品后为什么你拿货比别人贵?
选品决定利润的上限,供应链决定利润的下限做跨境电商,有一个残酷的事实:同样的商品,你卖100块,利润20块。别人卖90块,利润还有25块。为什么?不是你卖得不好,不是你运营不行ÿ…...

3大核心功能让你的英雄联盟体验提升300%:League-Toolkit完全指南
3大核心功能让你的英雄联盟体验提升300%:League-Toolkit完全指南 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 引言…...

低成本搭建AI知识库:Qwen3-Embedding-4B量化版仅需3GB显存教程
低成本搭建AI知识库:Qwen3-Embedding-4B量化版仅需3GB显存教程 1. 引言:为什么选择Qwen3-Embedding-4B? 在构建AI知识库时,文本向量化模型的选择至关重要。传统方案要么性能不足,要么资源消耗过大。Qwen3-Embedding-…...